


















With thanks to Ruth for the conversation that inspired these pictures, and apologies to the rest of the Internet for creating them.
With thanks to Ruth for the conversation that inspired these pictures, and apologies to the rest of the Internet for creating them.
I’m off work sick today: it’s just a cold, but it’s had a damn good go at wrecking my lungs and I feel pretty lousy. You know how when you’ve got too much of a brain-fog to trust yourself with production systems but you still want to write code (or is that just me?), so this morning I threw together a really, really stupid project which you can play online here.
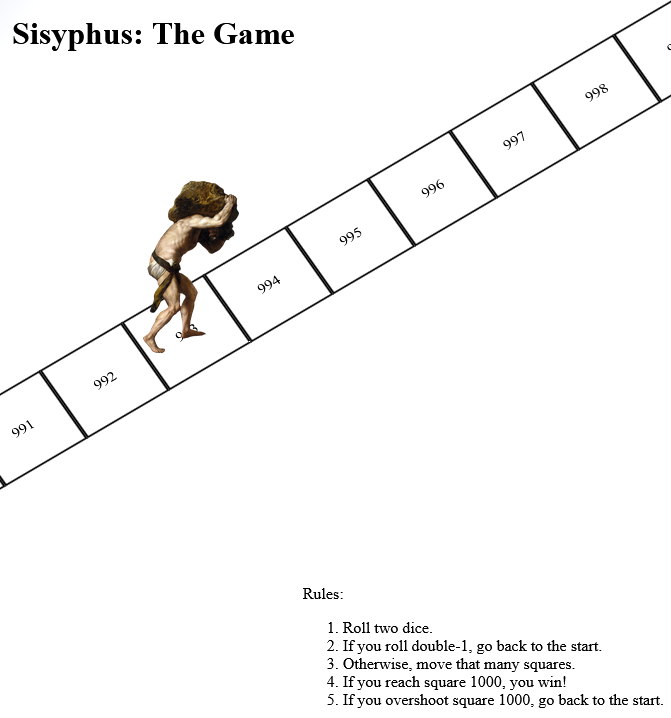
It’s inspired by a toot by Mason”Tailsteak” Williams (whom I’ve mentioned before once or twice). At first I thought I’d try to calculate the odds of winning at his proposed game, or how many times one might expect to play before winning, but I haven’t the brainpower for that in my snot-addled brain. So instead I threw together a terrible, terrible digital implementation.
Go play it if, like me, you’ve got nothing smarter that your brain can be doing today.
Just in time for Robin Sloan to give up on Spring ’83, earlier this month I finally got aroud to launching STS-6 (named for the first mission of the Space Shuttle Challenger in Spring 1983), my experimental Spring ’83 server. It’s been a busy year; I had other things to do. But you might have guessed that something like this had been under my belt when I open-sourced a keygenerator for the protocol the other day.
If you’ve not played with Spring ’83, this post isn’t going to make much sense to you. Sorry.
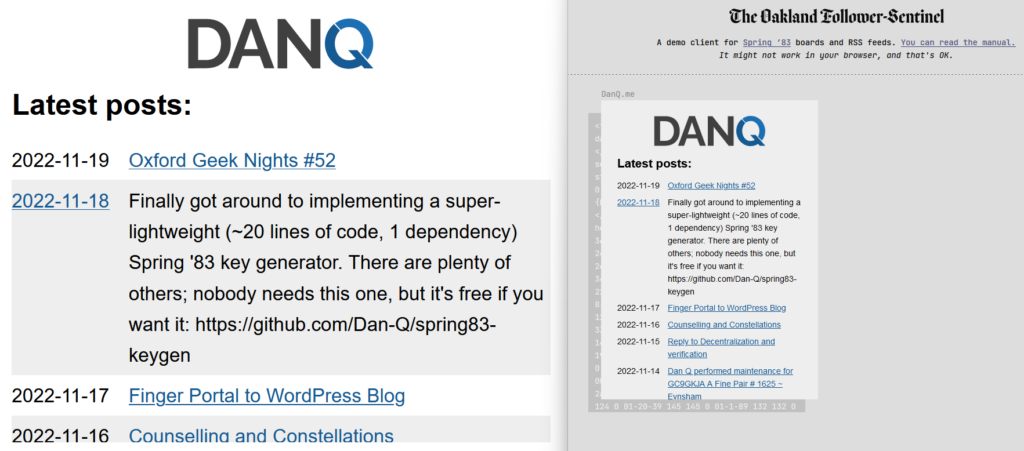
My server is, as far as I can tell, very different from any others in a few key ways:
{{board:123}}which are
automatically converted to addresses referencing the public key of the “current” keypair for that board. This separates the concept of a board and its content template from that
board’s keypairs, making it easier to link to a board. To put it another way, STS-6 links are self-healing on the server-side (for local boards).
<link rel="next"> connections to keep them current.
I’m sure that there are those who would see this as automating something that was beautiful because it was handcrafted; I don’t know whether or not I agree, but had Spring ’83 taken off in a bigger way, it would always only have been a matter of time before somebody tried my approach.
From a design perspective, I enjoyed optimising an SVG image of my header so it could meaningfully fit into the board. It’s pretty, and it’s tolerably lightweight.
If you want to see my server in action, patch this into your favourite Spring ’83 client:
https://s83.danq.dev/10c3ff2e8336307b0ac7673b34737b242b80e8aa63ce4ccba182469ea83e0623
Without Robin’s active participation, I feel that Spring ’83 is probably coming to a dead end. It’s been a lot of fun to play with and I’d love to see what ideas the experience of it goes on to inspire next, but in its current form it’s one of those things that’s an interesting toy, but not something that’ll make serious waves.
In his last lab essay Robin already identified many of the key issues with the system (too complicated, no interpersonal-mentions, the challenge of keys-as-identifiers, etc.) and while they’re all solvable without breaking the underlying mechanisms (mentions might be handled by Webmention, perhaps, etc.), I understand the urge to take what was learned from this experiment and use it to help inform the decisions of the next one. Just as John Postel’s Quote of the Day protocol doesn’t see much use any more (although maybe if my finger server could support QotD?) but went on to inspire the direction of many subsequent “call-and-response” protocols, including HTTP, it’s okay if Spring ’83 disappears into obscurity, so long as we can learn what it did well and build upon that.
Meanwhile: if you’re looking for a hot new “like the web but lighter” protocol, you should probably check out Gemini. (Incidentally, you can find me at gemini://danq.me, but that’s something I’ll write about another day…)
On Wednesday this week, three years and two months after Oxford Geek Nights #51, Oxford Geek Night #52. Originally scheduled for 15 April 2020 and then… postponed slightly because of the pandemic, its reapparance was an epic moment that I’m glad to have been a part of.

Ben Foxall also put in a sterling performance; hearing him talk – as usual – made me say “wow, I didn’t know you could do that with a web browser”. And there was more to learn, too: Jake Howard showed us how robots see, Steve Buckley inspired us to think about how technology can make our homes more energy-smart (this is really cool and sent me down a rabbithole of reading!), and Joe Wass showed adorable pictures of his kid exploring the user interface of his lockdown electronics project.

But mostly I just loved the chance to hang out with geeks again; chat to folks, make connections, and enjoy that special Oxford Geek Nights atmosphere. Also great to meet somebody from Perspectum, who look like they’d be great to work for and – after hearing about – I had in mind somebody to suggest for a job with them… but it looks like the company isn’t looking for anybody with their particular skills on this side of the pond. Still, one to watch.

Huge thanks are due to Torchbox, Perspectum and everybody in attendance for making this magical night possible!
Oh, and for anybody who’s interested, I’ve proposed to be a speaker at the next Oxford Geek Nights, which sounds like it’ll be towards Spring 2023. My title is “Yesterday’s Internet, Today!” which – spoilers! – might have something to do with the kind of technology I’ve been playing with recently, among other things. Hope to see you there!
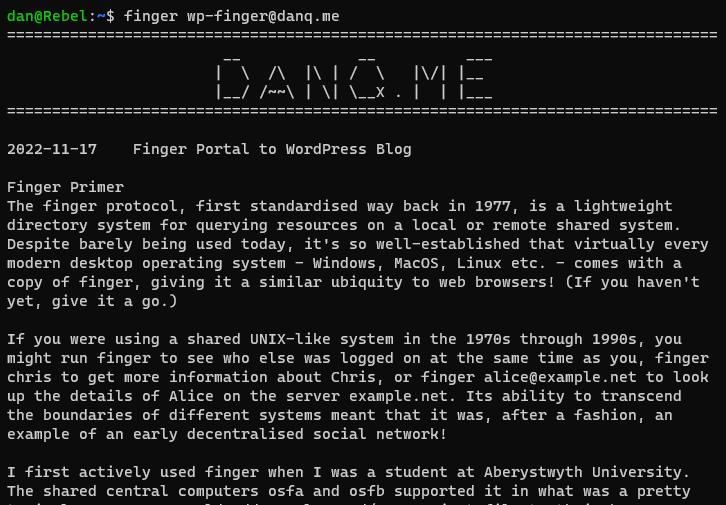
The finger protocol, first standardised way back in 1977, is a lightweight directory system
for querying resources on a local or remote shared system. Despite barely being used today, it’s so well-established that virtually every modern desktop operating system – Windows,
MacOS, Linux etc. – comes with a copy of finger, giving it a similar ubiquity to web browsers! (If you haven’t yet, give it a go.)
If you were using a shared UNIX-like system in the 1970s through 1990s, you might run finger to see who else was logged on at the same time as you, finger
chris to get more information about Chris, or finger alice@example.net to look up the details of Alice on the server example.net. Its ability to transcend the
boundaries of different systems meant that it was, after a fashion, an example of an early decentralised social network!
I first actively used finger when I was a student at Aberystwyth University. The shared central computers osfa and
osfb supported it in what was a pretty typical way: users could add a .plan and/or .project file to their home directory and the contents of these
would be output to anybody using finger to look up that user, along with other information like what department they belonged to. I’m simulating from memory so this won’t be remotely
accurate, but broadly speaking it looked a little like this –
$ finger dlq9@aber.ac.uk
Login: dlq9 Name: Dan Q
Directory: /users/9/d/dlq9 Department: Computer Science
Project:
Working on my BEng Software Engineering.
Plan:
_______
---' ____)____
______) Finger me!
_____)
(____)
---.__(___)
It’s not just about a directory of people, though: you could finger printers to see what their queues were like, finger a time server to ask what time it was,
finger a vending machine to see what drinks it
had available… even finger for a weather forecast where you are (this one still works as shown below; try it for your own location!) –
$ finger oxford@graph.no
-= Meteogram for Oxford, Oxfordshire, England, United Kingdom =-
'C Rain (mm)
12
11
10 ^^^=--=--
9^^^ ===
8 ^^^=== ====== ^^^
7 ====== ===============^^^ =--
6 =--=-----
5
4
3 | | | | | | | 1 mm
17 18 19 20 21 22 23 18/11 02 03 04 05 06 07_08_09_10_11_12_13_14 Hour
W W W W W W W W W W W W W W W W W W W W W W Wind dir.
6 6 7 7 7 7 7 7 6 6 6 5 5 4 4 4 4 5 6 6 5 5 Wind(m/s)
Legend left axis: - Sunny ^ Scattered = Clouded =V= Thunder # Fog
Legend right axis: | Rain ! Sleet * Snow
If you’d just like to play with finger, then finger.farm is a great starting point. They provide free finger hosting and they’re easy to use (try
finger dan@finger.farm to find me!). But I had something bigger in mind…
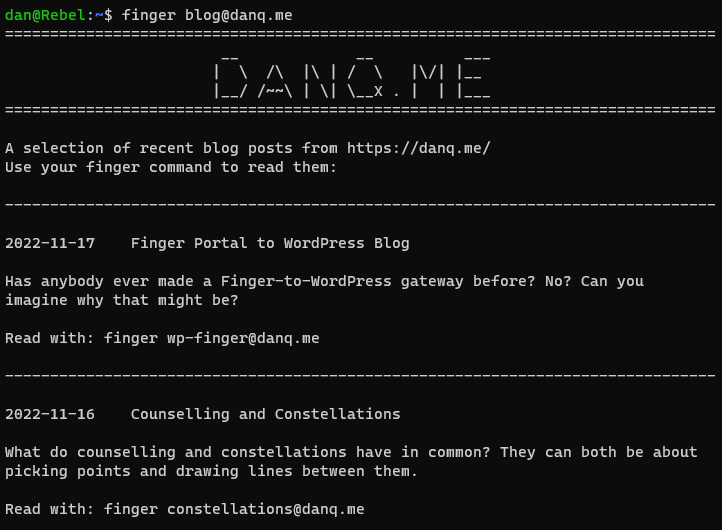
What if you could finger my blog. I.e. if you ran finger blog@danq.me you’d see a summary of some of my recent posts, along with additional
addresses you could finger to read the full content of each. This could be the world’s first finger-to-WordPress gateway; y’know, for
if you thought the world needed such a thing. Here’s how I did it:
efingerd; I’m using the Debian binaries.
ufw allow 1965; utf reload).
efingerd acts like a “typical” finger server, but it’s highly programmable to make it “smarter”. I:
/etc/efingerd/list to prevent any output from “listing” the server (finger @danq.me).
/etc/efingerd/list and /etc/efingerd/nouser(which are run when a request matches, or doesn’t match, a user account name) with
a call to my script: /usr/local/bin/finger-to-wordpress "$3". $3 holds the username that was requested, so we can act on it.
/usr/local/bin/finger-to-wordpress – a Ruby program that either (a) lists a selection of posts or (b) returns a specific post (stripping the
HTML tags)
In future, I might use some extra tags or metadata to enhance finger-friendly WordPress posts. The infrastructure’s in place already (I already have tags that I use to make
certain kinds of content available only via certain media – shh!). You might rightly as what the point is of this entire enterprise, of course, and you’d be well within your
rights to ask such a question. But I think the best answer available is “because Dan”.
If you want to see my blog in a whole new way, give it a go: run finger blog@danq.me on your computer and follow the instructions.
Over the last three or four years I’ve undertaken a couple of different rounds of psychotherapy. I liken the experience to that of spotting constellations in the night sky.

That’s probably the result of the goal I stated when going in to the first round: I’d like you to help while I take myself apart, try to understand how I work, and then put myself back together again.1 I’m trying to connect the dots between who-I-once-was and who-I-am-now and find causal influences.
As I’m sure you can imagine: with an opening statement like that I needed to contact a few different therapists before I found one who was compatible with my aims2. But then, I was always taught to get three quotes before hiring a professional.

It’s that “connecting the dots” that feels like constellation-spotting. A lot of the counselling work (and the “homework” that came afterwards) has stemmed from ideas like:
I suppose that what I’ve been doing is using the lens of retrospection to ask: “Hey, why am I like this? Is this part of it? And what impact did that have on me? Why can’t I see it?”
When you’re stargazing, sometimes you have to ask somebody to point out the shape in front of you before you can see it for yourself.

I haven’t yet finished this self-analytical journey, but I’m in an extended “homework” phase where I’m finding my own way: joining the dots for myself. Once somebody’s helped you find those constellations that mean something to you, it’s easier to pick them out when you stargaze alone.
1 To nobody’s surprise whatsoever, I can reveal that ever since I was a child I’ve enjoyed taking things apart to understand how they work. I wasn’t always so good at putting them back together again, though. My first alarm clock died that way, as did countless small clockwork and electronic toys.
2 I also used my introductory contact to lay out my counselling qualifications, in case they were a barrier for a potential therapist, but it turns out this wasn’t as much of a barrier as the fact that I arrived with a concrete mandate.
In the light of the so-called “Twitter migration”, I’ve spent a lot of the last week helping people new to Mastodon/the Fediverse in general to understand it. Or at least, to understand how it’s different from Twitter.1
If you’re among those jumping ship, by the way, can I recommend that you do two things:
The experience has filled me with feelings, for which I really appreciated that Hugh Rundle found such great words to share, comparing the surge of new users to September(ish) 1993:
…
The tools, protocols and culture of the fediverse were built by trans and queer feminists. Those people had already started to feel sidelined from their own project when people like me started turning up a few year ago. This isn’t the first time fediverse users have had to deal with a significant state change and feeling of loss. Nevertheless, the basic principles have mostly held up to now: the culture and technical systems were deliberately designed on principles of consent, agency, and community safety.
…
If the people who built the fediverse generally sought to protect users, corporate platforms like Twitter seek to control their users… [Academics and advertisers] can claim that legally Twitter has the right to do whatever it wants with this data, and ethically users gave permission for this data to be used in any way when they ticked “I agree” to the Terms of Service.
…
This attitude has moved with the new influx. Loudly proclaiming that content warnings are censorship, that functionality that has been deliberately unimplemented due to community safety concerns are “missing” or “broken”, and that volunteer-run servers maintaining control over who they allow and under what conditions are “exclusionary”. No consideration is given to why the norms and affordances of Mastodon and the broader fediverse exist, and whether the actor they are designed to protect against might be you.
…
I’d highly recommend you read the whole thing because it’s excellent.

I genuinely believe that the fediverse is among our best bets for making a break from the silos of the corporate Web, and to do that it has to scale – it’s only the speed at which it’s being asked to do so that’s problematic.
Aside from what I’m already doing – trying to tutor (tootor?) new fediversians about how to integrate in an appropriate and respectful manner and doing a little to supporting the expansion of the software that makes it tick… I wonder what more I could/should be doing.
Would my effort be best-spent be running a server (one not-just-for-me, I mean: abnib.social, anyone?), or should I use that time and money to support existing instances directly? Should I brush up on my ActivityPub spec so I can be a more-useful developer, or am I better-placed to focus on tending my own digital garden first? Or maybe I’m looking at it all wrong and I should be trying to dissuade people from piling-on to a system that might well not be right for them (nor they for it!)?
I don’t know the answers to these questions, but I’m hoping to work them out soon.
It only occurred to me after the fact that I should mention that you can find me at @dan@danq.me.
1 Important: I’m no expert. I’ve been doing fediverse things for about 3 years but I’m relatively quiet on Mastodon. Also, I’ve never really understood or gotten along with Twitter, so I’m even less an expert on that. Don’t assume that I’m an authority on anything at all, and especially not social media.
Your product, service, or organisation almost certainly has a priority of constituencies, even if it’s not written down or otherwise formally-encoded. A famous example would be that expressed in the Web Platform Design Principles. It dictates how you decide between two competing needs, all other things being equal.
At Three Rings, for example, our priority of constituencies might1 look like this:
These are all things we care about, but we’re talking about where we might choose to rank them, relative to one another.

The priorities of an organisation you’re involved with won’t be the same: perhaps it includes shareholders, regulatory compliance, different kinds of end-users, employees, profits, different measures of social good, or various measurable outputs. That’s fine: every system is different.
But what I’d challenge you to do is find ways to bisect your priorities. Invent scenarios that pit each constituency against itself another and discuss how they should be prioritised, all other things being equal.
Using the example above, I might ask “which is more important?” in each category:

The aim of the exercise isn’t to come up with a set of commandments for your company. If you come up with something you can codify, that’s great, but if you and your stakeholders just use it as an exercise in understanding the relative importance of different goals, that’s great too. Finding where people disagree is more-important than having a unifying creed2.
And of course this exercise applicable to more than just organisational priorities. Use it for projects or standards. Use it for systems where you’re the only participant, as a thought exercise. A priority of constituencies can be a beautiful thing, but you can understand it better if you’re willing to take it apart once in a while. Bisect your priorities, and see what you find.
1 Three Rings doesn’t have an explicit priority of constituencies: the example I give is based on my own interpretation, but I’m only a small part of the organisation.
2 Having a creed is awesome too, though, as I’ve said before.
This post is also available as a podcast. Listen here, download for later, or subscribe wherever you consume podcasts.
Somebody shared with me a tweet about the tragedy of being a Gen X’er and having to buy all your music again and again as formats evolve. Somebody else shared with me Kyla La Grange‘s cover of a particular song .Together… these reminded me that I’ve never told you the story of my first MP3…1
In the Summer of 1995 I bought the CD single of the (still excellent!) Set You Free by N-Trance.2 I’d heard about this new-fangled “MP3” audio format, so soon afterwards I decided to rip a copy of the song to my PC.
I was using a 66MHz 486SX CPU, and without an embedded FPU I didn’t
quite have the spare processing power to rip-and-encode in a single pass.3
So instead I first ripped to an uncompressed PCM .wav file and then performed the encoding: the former step
was done almost in real-time (I listened to the track as it ripped!), about 7 minutes. The latter step took about 20 minutes.
So… about half an hour in total, to rip a single song.

Creating a (what would now be considered an apalling) 32kHz mono-channel file, this meant that I briefly stored both a 27MB wave file and the final ~4MB MP3 file. 31MB might not sound huge, but I only had a total of 145MB of hard drive space at the time, so 31MB consumed over a fifth of my entire fixed storage! Even after deleting the intermediary wave file I was left with a single song consuming around 3% of my space, which is mind-boggling to think about in hindsight.
But it felt like magic. I called my friend Gary to tell him about it. “This is going to be massive!” I said. At the time, I meant for techy people: I could imagine a future in which, with more hard drive space, I’d keep all my music this way… or else bundle entire artists onto writable CDs in this new format, making albums obsolete. I never considered that over the coming decade or so the format would enter the public consciousness, let alone that it’d take off like it did.

The MP3 file I produced had a fault. Most of the way through the encoding process, I got bored and ran another program, and this must’ve interfered with the stream because there was an audible “blip” noise about 30 seconds from the end of the track. You’d have to be listening carefully to hear it, or else know what you were looking for, but it was there. I didn’t want to go through the whole process again, so I left it.
But that artefact uniquely identified that copy of what was, in the end, a popular song to have in your digital music collection. As the years went by and I traded MP3 files in bulk at LAN parties or on CD-Rs or, on at least one ocassion, on an Iomega Zip disk (remember those?), I’d ocassionally see
N-Trance - (Only Love Can) Set You Free.mp34 being passed around and play it, to see if it was “my”
copy.
Sometimes the ID3 tags had been changed because for example the previous owner had decided it deserved to be considered Genre: Dance instead of Genre: Trance5. But I could still identify that file because
of the audio fingerprint, distinct to the first MP3 I ever created.
I still had that file when I went to university (where it occupied a smaller proportion of my hard drive space) and hearing that distinctive “blip” would remind me about the ordeal that was involved in its creation. I don’t have it any more, but perhaps somebody else still does.
1 I might never have told this story on my blog, but eagle-eyed readers may remember that I’ve certainly hinted at it before now.
2 Rewatching that music video, I’m struck by a recollection of how crazy popular crossfades were on 1990s dance music videos. More than just a transition, I’m pretty sure that most of the frames of that video are mid-crossfade: it feels like I’m watching Kelly Llorenna hanging out of a sunroof but I accidentally left one of my eyeballs in a smoky nightclub and can still see out of it as well.
3 I initially tried to convert directly from red book format to an MP3 file, but the encoding process was too slow and the CD drive’s buffer filled up and didn’t get drained by the processor, which was still presumably bogged down with framing or fourier-transforming earlier parts of the track. The CD drive reasonably assumed that it wasn’t actually being used and spun-down the drive motor, and this caused it to lose its place in the track, killing the whole process and leaving me with about a 40 second recording.
4 Yes, that filename isn’t quite the correct title. I was wrong.
5 No, it’s clearly trance. They were wrong.
I’ve been spending a while running on reduced brain capacity lately so, to ease myself back into thinking like a programmer, I upgraded my preferred feed reader FreshRSS to version 1.20.0 – which was released a couple of weeks ago – and tried out what I believe is its killer new feature: HTML + XPath scraping.
I’ve been using RSS1 for about 20 years and I love it. It feels great to be able to curate my updates based on “what I care about”, and not on “what some social network thinks I should care about”, to keep things to read later, to prioritise effectively based on my own categorisation, to consume content offline and have my to-read list synchronise later, etc.
RSS never went away, of course (what do you think a podcast is?), but it got steamrollered out of the public eye by big companies who make their money out of keeping your eyes on their platforms and off the open Web. But it feels like it’s slowly coming back: even Substack – whose entire thing is that an email client is more-convenient than a feed reader for most people – launched an RSS reader this week!

I love RSS so much that I routinely retrofit other people’s websites with feeds just so I can subscribe to them: I even published the tool I use to do so! Whether filtering sports headlines out of BBC News, turning retro webcomics into “reading lists” so I can track my progress, or just working around sites that really should have feeds but refuse to, I just love sidestepping these “missing feeds”. My friend Beverley has a blog without any kind of feed, so I added one so I could subscribe to it. Magic.
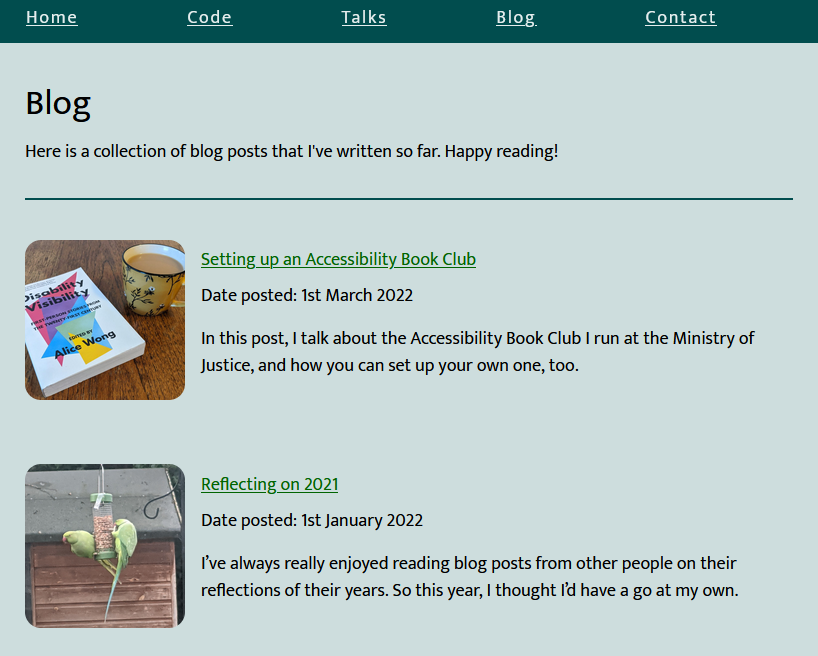
But with FreshRSS 1.20.0, I no longer have to maintain my own tool to get this brilliant functionality, and I’m overjoyed. Let’s look at how it works by re-subscribing to Beverley’s blog but without a middleware tool.
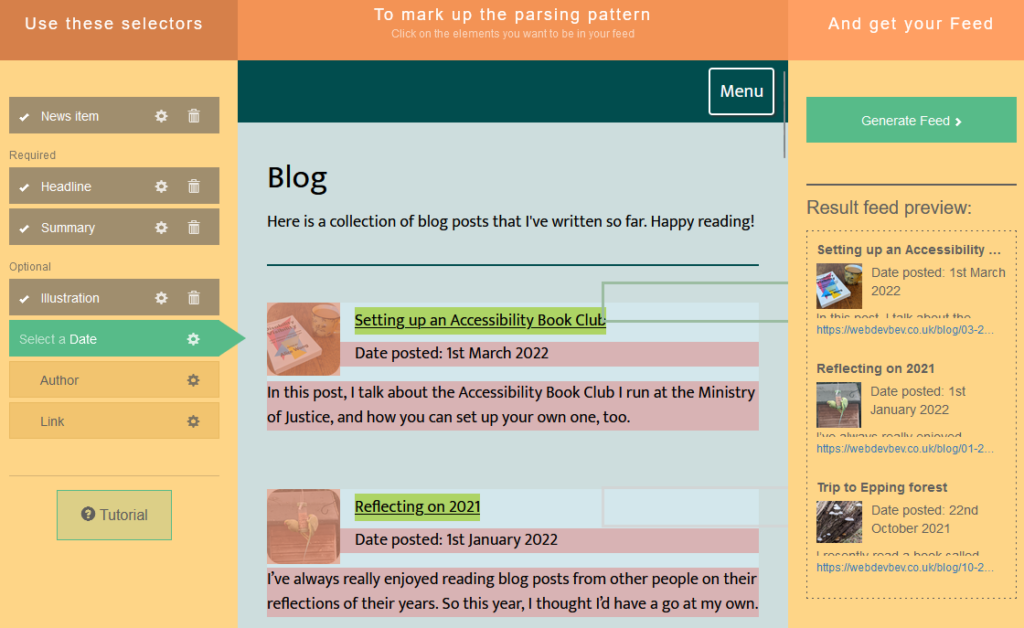
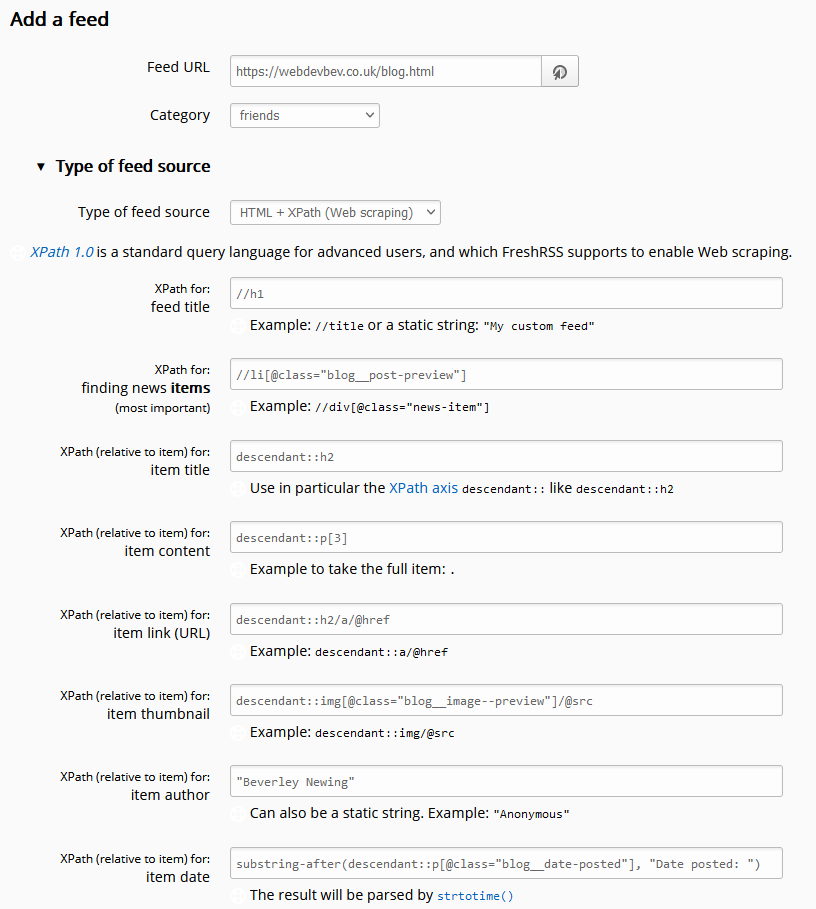
In the latest version of FreshRSS, when you add a new feed to your reader, a new section “Type of feed source” is available. Unfold it, and you can change from the default (“RSS / Atom”) to the new option “HTML + XPath (Web scraping)”. Put a human-readable page address rather than a feed address into the “Feed URL” field and fill these fields to tell FreshRSS how to parse the page to get the content you want. Note that it doesn’t matter if the web page isn’t valid XML (e.g. missing closing tags) because it’s going to get run through PHP’s DOMDocument anyway which will “correct” for some really sloppy code if needed.
![Browser debugger running document.evaluate('//li[@class="blog__post-preview"]', document).iterateNext() on Beverley's weblog and getting the first blog entry.](https://bcdn.danq.me/_q23u/2022/09/debugger-select-from-xpath-1024x256.png)
document.evaluate('//li[@class="blog__post-preview"]', document).iterateNext() and
got back the first blog post on the page, so I know I’m on the right track.
//h1
<h1> on the page, and it can be
considered the “title” of the feed.
//li[@class="blog__post-preview"]
<li class="blog__post-preview">.
descendant::h2
<h2> which is the post title. The descendant:: selector scopes the search to each post as found above.
descendant::p[3]
<li>, which we can select like this.
descendant::h2/a/@href
<h2><a
href="...">, rather than its contents.
descendant::img[@class="blog__image--preview"]/@src
<img src="...">.
"Beverley Newing"
substring-after(descendant::p[@class="blog__date-posted"], "Date posted: ")
substring-after function to strtip this. The result gets passed to PHP’s
strtotime(), which is pretty tolerant of different date formats (although not of the words “Date posted:” it turns out!).
I hope that this is just the beginning for this new killer feature in FreshRSS: there’s so much more it can be and do. But for now, I’m still mighty impressed that I can begin to phase-out my use of my relatively resource-intensive feed-building middleware and use my feed reader to do more and more of the heavy lifting for which I love it so much.
I also love that this functionally adds h-feed support in by the back door. I’d still prefer there to be a “h-feed” option in the “Type of feed source” drop-down, but at least I can add such support manually, now!
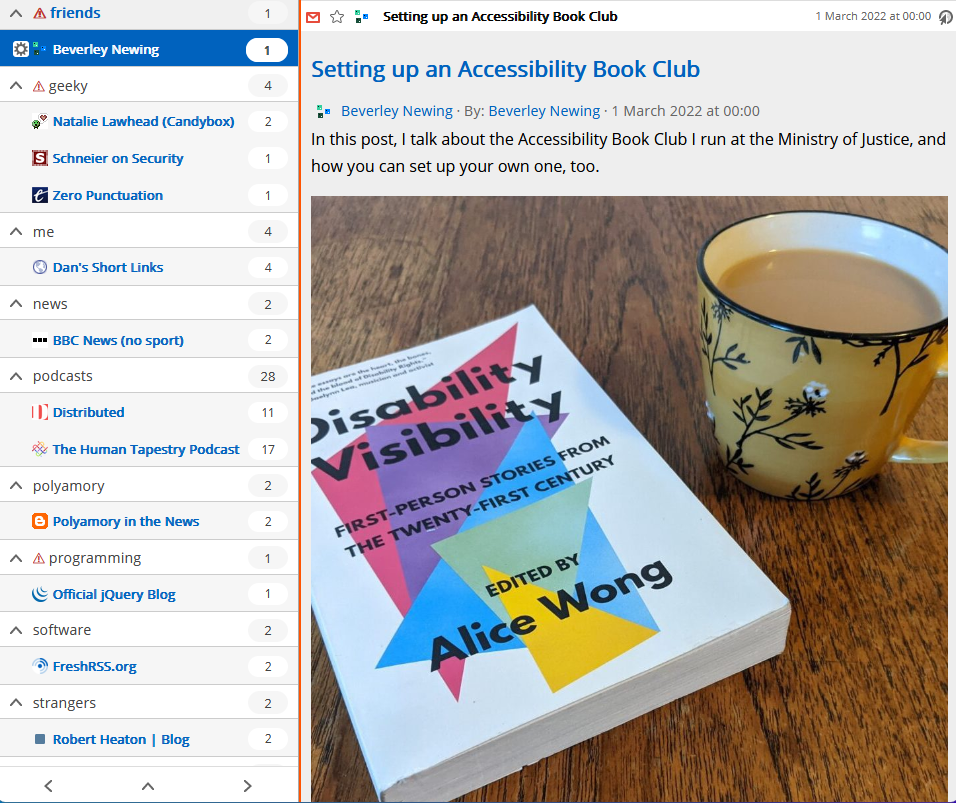
I managed to dodge infection for 922 days of the Covid pandemic1, but it caught up with me eventually.
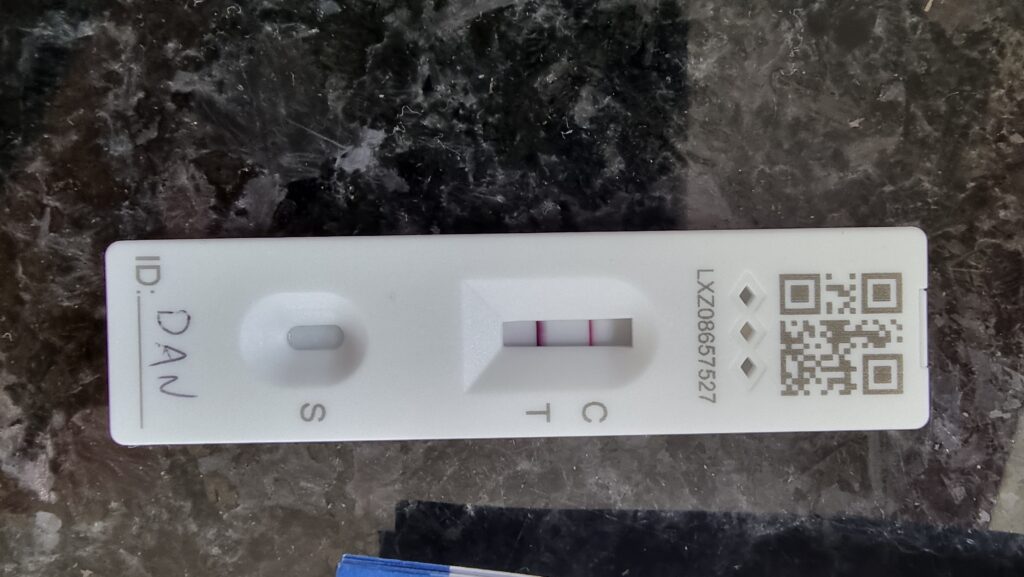
Frankly, it’s surprising that it took this long. We’ve always been careful, in accordance with guidance at any given time, nd we all got our jabs and boosters as soon as we were able… but conversely: we’ve got school-age children who naturally seem to be the biggest disease vectors imaginable. Our youngest, in fact, already had Covid, but the rest of us managed to dodge it perhaps thanks to all these precautions.
Luckily I’m not suffering too badly, probably thanks to the immunisation. It’s still not great, but I dread to think how it might have been without the benefit of the jab! A minor fever came and went, and then it’s just been a few days of coughing, exhaustion, and… the most-incredible level of brain-fog.

I’ve taken the week off work to recover, which was a wise choice. As well as getting rest, it’s meant that I’ve managed to avoid writing production code with my addled brain! Instead, I’ve spent a lot of time chilling in bed and watching all of the films that I’d been meaning to! This week, I’ve watched:

Anyway: hopefully next week I’ll be feeling more normal and my poor Covid-struck brain can be trusted with code again. Until then: time to try to rest some more.
1 Based on the World Health Organisation’s declaration of the outbreak being a pandemic on 11 March 2020 and my positive test on 19 September 2022, I stayed uninfected for two years, six months, one week, and one day. But who’s counting?
Via Jeremy Keith I today discovered Jim Nielsen‘s suggestion for a website’s /.well-known/links to be a place where it can host a JSON-formatted list of all of its outgoing links.
That’s a really useful thing to have in this new age of the web, where Refererer: headers are no-longer commonly passed cross-domain and Google Search no longer provides the link: operator. If you want to know if I’ve ever
linked to your site, it’s a bit of a drag to find out.

So, obviously, I’ve written an implementation for WordPress. It’s really basic right now, but the source code can be
found here if you want it. Install it as a plugin and run wp outbound-links to kick it off. It’s fast: it takes 3-5 seconds to parse the entirety of danq.me,
and I’ve got somewhere in the region of 5,000 posts to parse.
You can see the results at https://danq.me/.well-known/links – if you’ve ever wondered “has Dan ever linked to my site?”, now you can find the answer.
If this could be useful to you, let’s collaborate on making this into an actually-useful plugin! Otherwise it’ll just languish “as-is”, which is good enough for my purposes.
This post is also available as a video. If you'd prefer to watch/listen to me talk about this topic, give it a look.
This blog post is also available as a video. Would you prefer to watch/listen to me tell you about how I’ve implemented a tool to help me beat the kids when we play Mastermind?
I swear that I used to be good at Mastermind when I was a kid. But now, when it’s my turn to break the code that one of our kids has chosen, I fail more often than I succeed. That’s no good!

Maybe it’s because I’m distracted; multitasking doesn’t help problem-solving. Or it’s because we’re “Super” Mastermind, which differs from the one I had as a child in that eight (not six) peg colours are available and secret codes are permitted to have duplicate peg colours. These changes increase the possible permutations from 360 to 4,096, but the number of guesses allowed only goes up from 8 to 10. That’s hard.

Or maybe it’s just that I’ve gotten lazy and I’m now more-likely to try to “solve” a puzzle using a computer to try to crack a code using my brain alone. See for example my efforts to determine the hardest hangman words and make an adverserial hangman game, to generate solvable puzzles for my lock puzzle game, to cheat at online jigsaws, or to balance my D&D-themed Wordle clone.
Hey, that’s an idea. Let’s crack the code… by writing some code!

The search space for Super Mastermind isn’t enormous, and it lends itself to some highly-efficient computerised storage.
There are 8 different colours of peg. We can express these colours as a number between 0 and 7, in three bits of binary, like this:
| Decimal | Binary | Colour |
|---|---|---|
0
|
000
|
Red |
1
|
001
|
Orange |
2
|
010
|
Yellow |
3
|
011
|
Green |
4
|
100
|
Blue |
5
|
101
|
Pink |
6
|
110
|
Purple |
7
|
111
|
White |
There are four pegs in a row, so we can express any given combination of coloured pegs as a 12-bit binary number. E.g. 100 110 111 010 would represent the
permutation blue (100), purple (110), white (111), yellow (010). The total search space, therefore, is the range of numbers from
000000000000 through 111111111111… that is: decimal 0 through 4,095:
| Decimal | Binary | Colours |
|---|---|---|
0
|
000000000000
|
Red, red, red, red |
1
|
000000000001
|
Red, red, red, orange |
2
|
000000000010
|
Red, red, red, yellow |
| ………… | ||
4092
|
|
White, white, white, blue |
4093
|
|
White, white, white, pink |
4094
|
|
White, white, white, purple |
4095
|
|
White, white, white, white |
Whenever we make a guess, we get feedback in the form of two variables: each peg that is in the right place is a bull; each that represents a peg in the secret code but isn’t in the right place is a cow (the names come from Mastermind’s precursor, Bulls & Cows). Four bulls would be an immediate win (lucky!), any other combination of bulls and cows is still valuable information. Even a zero-score guess is valuable- potentially very valuable! – because it tells the player that none of the pegs they’ve guessed appear in the secret code.

The latest versions of Javascript support binary literals and bitwise operations, so we can encode and decode between arrays of four coloured pegs (numbers 0-7) and the number 0-4,095
representing the guess as shown below. Decoding uses an AND bitmask to filter to the requisite digits then divides by the order of magnitude. Encoding is just a reduce
function that bitshift-concatenates the numbers together.
116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 |
/** * Decode a candidate into four peg values by using binary bitwise operations. */ function decodeCandidate(candidate){ return [ (candidate & 0b111000000000) / 0b001000000000, (candidate & 0b000111000000) / 0b000001000000, (candidate & 0b000000111000) / 0b000000001000, (candidate & 0b000000000111) / 0b000000000001 ]; } /** * Given an array of four integers (0-7) to represent the pegs, in order, returns a single-number * candidate representation. */ function encodeCandidate(pegs) { return pegs.reduce((a, b)=>(a << 3) + b); } |
With this, we can simply:
Step 3’s the most important one there. Given a function getScore( solution, guess ) which returns an array of [ bulls, cows ] a given guess would
score if faced with a specific solution, that code would look like this (I’m convined there must be a more-performant way to eliminate candidates from the list with XOR
bitmasks, but I haven’t worked out what it is yet):
164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 |
/** * Given a guess (array of four integers from 0-7 to represent the pegs, in order) and the number * of bulls (number of pegs in the guess that are in the right place) and cows (number of pegs in the * guess that are correct but in the wrong place), eliminates from the candidates array all guesses * invalidated by this result. Return true if successful, false otherwise. */ function eliminateCandidates(guess, bulls, cows){ const newCandidatesList = data.candidates.filter(candidate=>{ const score = getScore(candidate, guess); return (score[0] == bulls) && (score[1] == cows); }); if(newCandidatesList.length == 0) { alert('That response would reduce the candidate list to zero.'); return false; } data.candidates = newCandidatesList; chooseNextGuess(); return true; } |
I continued in this fashion to write a full solution (source code). It uses ReefJS for component rendering and state management, and you can try it for yourself right in your web browser. If you play against the online version I mentioned you’ll need to transpose the colours in your head: the physical version I play with the kids has pink and purple pegs, but the online one replaces these with brown and black.
Let’s try it out against the online version:
As expected, my code works well-enough to win the game every time I’ve tried, both against computerised and in-person opponents. So – unless you’ve been actively thinking about the specifics of the algorithm I’ve employed – it might surprise you to discover that… my solution is very-much a suboptimal one!

A couple of games in, the suboptimality of my solution became pretty visible. Sure, it still won every game, but it was a blunt instrument, and anybody who’s seriously thought about games like this can tell you why. You know how when you play e.g. Wordle (but not in “hard mode”) you sometimes want to type in a word that can’t possibly be the solution because it’s the best way to rule in (or out) certain key letters? This kind of strategic search space bisection reduces the mean number of guesses you need to solve the puzzle, and the same’s true in Mastermind. But because my solver will only propose guesses from the list of candidate solutions, it can’t make this kind of improvement.

Search space bisection is also used in my adverserial hangman game, but in this case the aim is to split the search space in such a way that no matter what guess a player makes, they always find themselves in the larger remaining portion of the search space, to maximise the number of guesses they have to make. Y’know, because it’s evil.

There are mathematically-derived heuristics to optimise Mastermind strategy. The first of these came from none other than Donald Knuth (legend of computer science, mathematics, and pipe organs) back in 1977. His solution, published at probably the height of the game’s popularity in the amazingly-named Journal of Recreational Mathematics, guarantees a solution to the six-colour version of the game within five guesses. Ville [2013] solved an optimal solution for a seven-colour variant, but demonstrated how rapidly the tree of possible moves grows and the need for early pruning – even with powerful modern computers – to conserve memory. It’s a very enjoyable and readable paper.
But for my purposes, it’s unnecessary. My solver routinely wins within six, maybe seven guesses, and by nonchalantly glancing at my phone in-between my guesses I can now reliably guess our children’s codes quickly and easily. In the end, that’s what this was all about.
This post is also available as a video. If you'd prefer to watch/listen to me talk about this topic, give it a look.
This blog post is also available as a video. Would you prefer to watch/listen to me tell you about not being a “dog person”, but still loving one dog in particular?
I am not a “dog person”. I’m probably more of a “cat person”.

My mum has made pets of one or both of dogs or cats for most of her life. She puts the difference between the two in a way that really resonates for me. To paraphrase her:
When you’re feeling down and you’ve had a shitty day and you just need to wallow in your despair for a little bit… a pet dog will try to cheer you up. It’ll jump up at you, bring you toys, suggest that you go for a walk, try to pull your focus away from your misery and bring a smile to your face. A cat, though, will just come and sit and be melancholy with you. Its demeanour just wordlessly says: “You’re feeling crap? Me too: I only slept 16 hours today. Let’s feel crap together.”

So it surprised many when, earlier this year, our family was expanded with the addition of a puppy called Demmy. I guess we collectively figured that now we’d solved all the hard problems and the complexities of our work, volunteering, parenting, relationships, money etc. and our lives were completely simple, plain sailing, and stress-free, all of the time… that we now had the capacity to handle adding another tiny creature into our midst. Do you see the mistake in that logic? Maybe we should have, too.

It turns out that getting a puppy is a lot like having a toddler all over again. Your life adjusts around when they need to sleep, eat, and poop. You need to put time, effort, and thought into how to make and keep your house safe both for and from them. And, of course, they bring with them a black hole that eats disposable income.

They need to be supervised and entertained and educated (the latter of which may require some education yourself). They need to be socialised so they can interact nicely with others, learn the boundaries of their little world, and behave appropriately (even when they’re not on camera).

Even as they grow, their impact is significant. You need to think more-deeply about how, when and where you travel, work out who’s responsible for ensuring they’re walked (or carried!) and fed (not eaten!) and watched. You’ve got to keep them safe and healthy and stimulated. Thankfully they’re not as tiring to play with as children, but as with kids, the level of effort required is hard to anticipate until you have one.

But do you know what else they have in common with kids? You can’t help learning to love them.
It doesn’t matter what stupid thing they’re illicitly putting in their mouth, how many times you have to clean up after them, how frustrating it is that they can’t understand what you need from them in order to help them, or how much they whine about something that really isn’t that big a deal (again: #PuppyOrToddler?). It doesn’t even matter how much you’re “not a dog person”, whatever that means. They become part of your family, and you fall in love with them.

I’m not a “dog person”. But: while I ocassionally resent the trouble she causes, I still love our dog.
I’ve been playing with a Flic Hub LR and some Flic 2 buttons. They’re “smart home” buttons, but for me they’ve got a killer selling point: rather than locking you in to any particular cloud provider (although you can do this if you want), you can directly program the hub. This means you can produce smart integrations that run completely within the walls of your house.
Here’s some things I’ve been building:
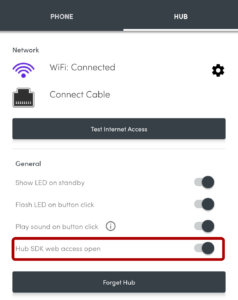
I run a Huginn instance on our household NAS. If you’ve not come across it before, Huginn is a bit like an open-source IFTTT: it’s got a steep learning curve, but it’s incredibly powerful for automation tasks. The first step, then, was to set up my Flic Hub LR to talk to Huginn.
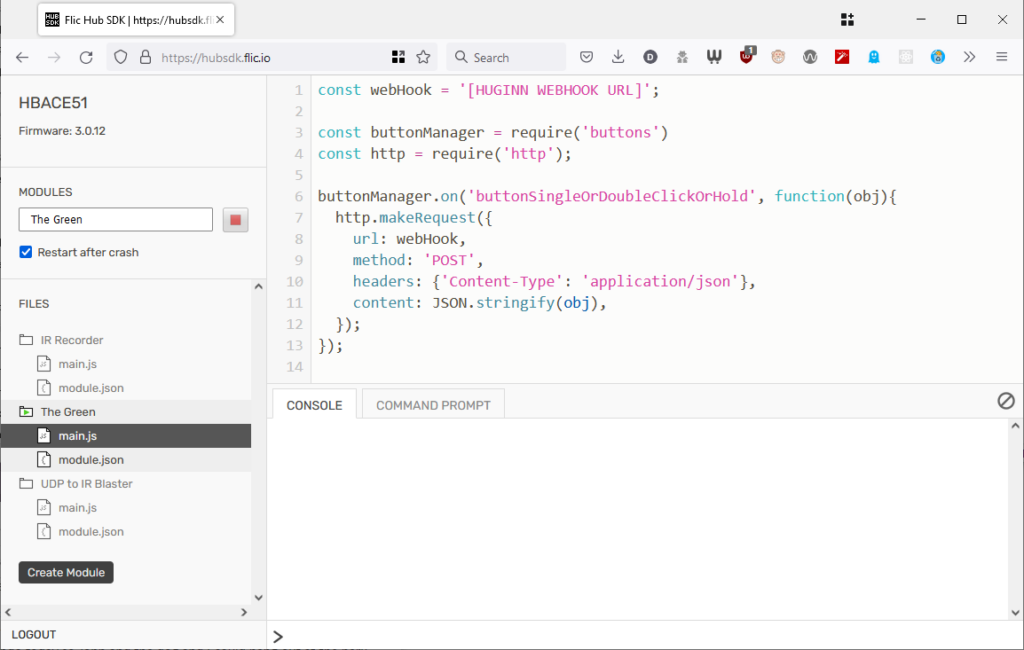
This was pretty simple: all I had to do was switch on “Hub SDK web access open” for the hub using the Flic app, then use the the web SDK to add this script to the hub. Now whenever a button was clicked, double-clicked, or held down, my Huginn installation would receive a webhook ping.
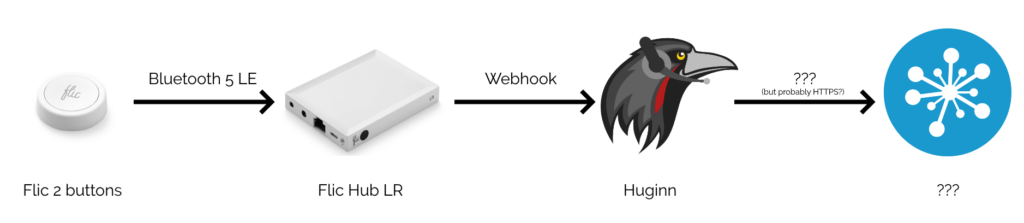
For convenience, I have all button-presses sent to the same Webhook, and use Trigger Agents to differentiate between buttons and press-types. This means I can re-use functionality within Huginn, e.g. having both a button press and some other input trigger a particular action.
By our front door, we have “in trays” for each of Ruth, JTA and I, as well as one for the bits of Three Rings‘ post that come to our house. Sometimes post sits in the in-trays for a long time because people don’t think to check them, or don’t know that something new’s been added.
I configured Huginn with a Trigger Agent to receive events from my webhook and filter down to just single clicks on specific buttons. The events emitted by these triggers are used to notify in-tray owners.
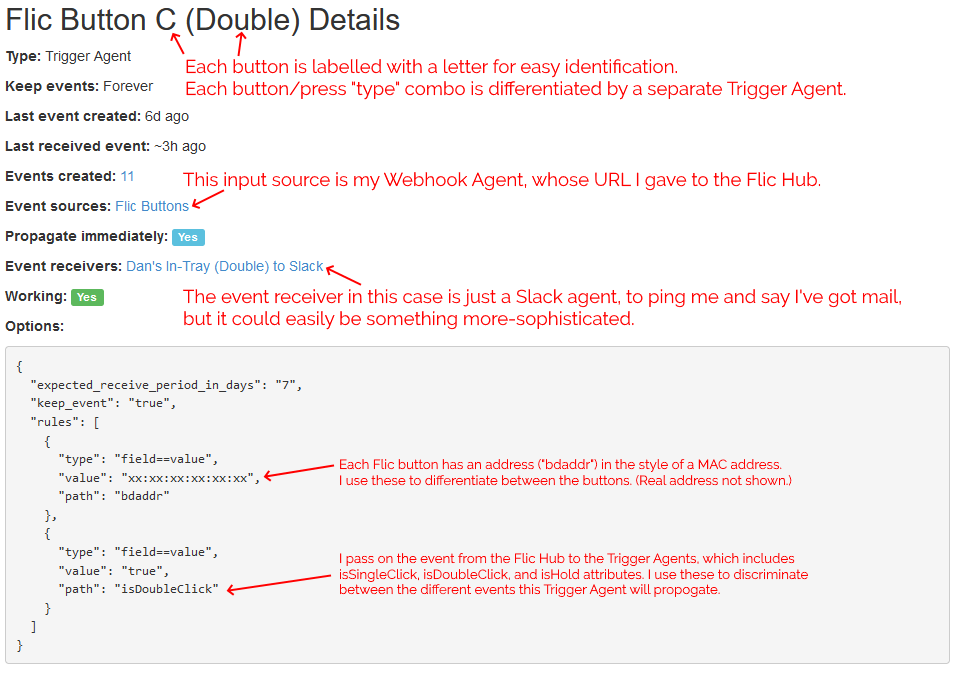
In my case, I’ve got pings being sent to mail recipients via Slack, but I could equally well be integrating to other (or additional) endpoints or even performing some conditional logic: e.g. if it’s during normal waking hours, send a Pushbullet notification to the recipient’s phone, otherwise send a message to an Arduino to turn on an LED strip along the top of the recipient’s in-tray.
I’m keeping it simple for now. I track three kinds of events (click = “post in your in-tray”, double-click = “I’ve cleared my in-tray”, hold = “parcel wouldn’t fit in your in-tray: look elsewhere for it”) and don’t do anything smarter than send notifications. But I think it’d be interesting to e.g. have a counter running so I could get a daily reminder (“There are 4 items in your in-tray.”) if I don’t touch them for a while, or something?
Following the same principle, and with the hope that the Flic buttons are weatherproof enough to work in a covered outdoor area, I’ve fitted one… to the top of the box our milkman delivers our milk into!

Most mornings, our milkman arrives by 7am, three times a week. But some mornings he’s later – sometimes as late as 10:30am, in extreme cases. If he comes during the school run the milk often gets forgotten until much later in the day, and with the current weather that puts it at risk of spoiling. Ironically, the box we use to help keep the milk cooler for longer on the doorstep works against us because it makes the freshly-delivered bottles less-visible.

I’m yet to see if the milkman will play along and press the button when he drops off the milk, but if he does: we’re set! A second possible bonus is that the kids love doing anything that allows them to press a button at the end of it, so I’m optimistic they’ll be more-willing to add “bring in the milk” to their chore lists if they get to double-click the button to say it’s been done!
I’m still playing with ideas for the next round of buttons. Could I set something up to streamline my work status, so my colleagues know when I’m not to be disturbed, away from my desk, or similar? Is there anything I can do to simplify online tabletop roleplaying games, e.g. by giving myself a desktop “next combat turn” button?

I’m quite excited by the fact that the Flic Hub can interact with an infrared transceiver, allowing it to control televisions and similar devices: I’d love to be able to use the volume controls on our media centre PC’s keyboard to control our TV’s soundbar: and because the Flic Hub can listen for UDP packets, I’m hopeful that something as simple as AutoHotkey can make this possible.
Or perhaps I could make a “universal remote” for our house, accessible as a mobile web app on our internal Intranet, for those occasions when you can’t even be bothered to stand up to pick up the remote from the other sofa. Or something that switched the TV back to the media centre’s AV input when consoles were powered-down, detected by their network activity? (Right now the TV automatically switches to the consoles when they’re powered-on, but not back again afterwards, and it bugs me!)
It feels like the only limit with these buttons is my imagination, and that’s awesome.