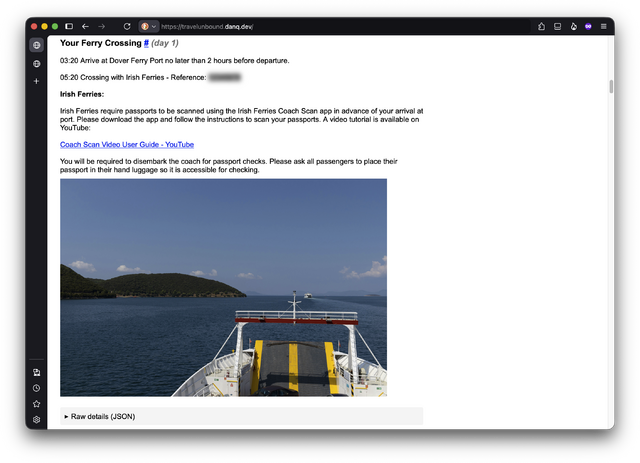
When my house flooded 149 days ago, a lot of things were damaged. The oak floors, for one, were completely wrecked, as the ground floor electrical ring, the skirting boards, one internal one, a few hundred books and small items, and a load of furniture. Since then we’ve lived in a few places – but mostly at the “Chicory House” – while the insurance company has been working on repairing and replacing everything that we’ve lost.
This week, we got back the piano.

Our insurance policy is “new for old”, but we own a handful of pieces of furniture whether it’s impractical or impossible to replace them like-for-like and we’ve instead petitioned for restoration. For example: our dining table is a bit of a family heirloom, a mahogany reading room desk formerly from the libraries of the University of Cambridge, adapted by Ruth‘s (carpenter) father into a dining table1.
Another example turns out to be our upright piano, which turns out to be a bit of a musical oddity: it’s got features, like it’s peculiar gravity-controlled overdampers that, among other characteristics, are pretty distinct to the Edwardian or perhaps inter-war construction techniques that were in vogue at the time2.

In any case: after a piano specialist wrote us a statement explaining that it simply wasn’t possible to “new-for-old” this because they don’t make them like this any more, the insurance company signed-off on us sending it away to what I lovingly called a “piano hospital”, where she’s enjoyed a complete overhaul.
And now, at last, it’s back with us: we could have kept it in storage until we’re ready to move back “home” (there’s still a lot of repair work to be done!), but having it moved twice is cheaper… plus it means we get it back sooner.

Personally, I’ve found it an enormous psychological relief to have the piano back, because I’ve missed it!
I started teaching myself to play the piano during the second Covid lockdown, looking for something to distract me from my inability to go outdoors and do things, and wanting to try to engage a different part of my brain. I was quickly hooked: I’d never learned any musical instrument before3, and I enjoyed having something I was (and still am!) pretty bad at which I could make slow incremental progress.
And so for several years, most days, I’d play about 10 minutes of piano. Not much: just a little each day usually while my lunch warmed up. But slowly but surely I reached the point that I could tolerate – or even enjoy! – hearing myself play4.
And then after the flood… I couldn’t. I’d get up from work to stretch my legs and my fingers would twitch in anticipation of fulfilling a routine that… I just didn’t get to, any more. I tried playing the electric piano at the local library but its headphones were damaged and the action didn’t feel right and… it just wasn’t the same. I wanted our piano back!

And now I’ve got it. And it feels fantastic. It’s a little different – the sustain pedal’s response is a lot better, but more nuanced, and I’m not used to it yet, for example. But it’s still a wonderful thing: like a family member coming home after a long period away.
Also: it feels like a small victory to have something back, following the flood, because the entire insurance/assessment/repair process continues to be so slow.
Our house may still be stuck with no floors and missing walls… but, five months later, the first things to be repaired are coming back to us. Maybe soon we’ll have, I don’t know, a working kitchen or the plumbing re-connected. Here’s hoping!
Footnotes
1 The transformation of the reading room desk – which once sported integrated reading lights – into a general-purpose table has been done so-effectively that you wouldn’t know to look at it that our largest piece of furniture had ever had another life… unless you lift the secret panel in its centre foot, at which point you’d discover a BS 546 plug still wired-in to it!
2 Don’t ask me to enumerate the particular features or how we know: JTA, plus our piano tuner, did the research that ultimately underpinned the argument that you couldn’t possibly acquire a like-for-like replacement for it. I just know how it feels and sounds.
3 I didn’t even play a recorder at school!
4 I fully appreciate that I will never be as good a pianist as, say, the average 8-year old who plays for their YouTube channel. I am fine with this. Like my blogging, my piano-playing is, first and foremost, for me and not for anybody else.

 A while back I decided that I should blog about each
book I read. Some of the other bloggers I enjoy do that, and it seems like a great way to both share your “reviews”
A while back I decided that I should blog about each
book I read. Some of the other bloggers I enjoy do that, and it seems like a great way to both share your “reviews”








{kind=link}
{kind=link}
{kind=link}
{kind=link}