Microsoft engineers have been spotted committing code to Chromium, the backend of Google Chrome
and many other web browsers. This, among other things, has lead to speculation that Microsoft’s browser, Edge, might be planned to switch from its
current rendering engine (EdgeHTML) to Blink (Chromium’s). This is bad news.
This post, as it would appear if you were looking at it in Edge. Which you might be, I suppose.
The younger generation of web developers are likely to hail this as good news: one fewer engine to develop for and test in, they’re all already using Chrome or
something similar (and certainly not Edge) for development and debugging anyway, etc. The problem comes perhaps because they’re too young to remember the First Browser War and its aftermath. Let me summarise:
Once upon a time – let’s call it the mid-1990s – there were several web browsers: Netscape Navigator, Internet Explorer, Opera, etc. They all used different rendering
engines and so development was sometimes a bit of a pain, but only if you wanted to use the latest most cutting-edge features: if you were happy with the standard, established
features of the Web then your site would work anywhere, as has always been the case.
Then, everybody starting using just one browser: following some shady dealings and monopoly abuse, 90%+ of Web users started using just one web browser, Internet Explorer. By the time anybody took
notice, their rivals had been economically crippled beyond any reasonable chance of recovery, but the worst had yet to come…
Developers started targeting only that one browser: instead of making websites, developers started making “Internet Explorer sites” which were only tested in that one
browser or, worse yet, only worked at all in that browser, actively undermining the Web’s position as an open platform. As the grip of the monopoly grew tighter,
technological innovation was centred around this single platform, leading to decade-long knock-on
effects.
The Web ceased to grow new features: from the release of Internet Explorer 6 there were no significant developments in the technology of the Web for many years.
The lack of competition pushed us into a period of stagnation. A
decade and a half later, we’re only just (finally) finishing shaking off this unpleasant bit of our history.
History looks set to repeat itself. Substitute Chrome in place of Internet Explorer and update the references to other web browsers and the steps above could be our future history, too.
Right now, we’re somewhere in or around step #2 – Chrome is the dominant browser – and we’re starting to see the beginnings of step #3: more and more “Chrome only” sites.
More-alarmingly this time around, Google’s position in providing many major Web services allows them to “push” even harder for this kind of change, even just subtly: if you make the
switch from Chrome to e.g. Firefox (and you absolutely should) you might find that
YouTube runs slower for you because YouTube’s (Google) engineers favour Google’s web browser.
So these are the three browser engines we have: WebKit/Blink, Gecko, and EdgeHTML. We are unlikely to get any brand new bloodlines in the foreseeable future. This is it.
If we lose one of those browser engines, we lose its lineage, every permutation of that engine that would follow, and the unique takes on the Web it could allow for.
And it’s not likely to be replaced.
Imagine a planet populated only by hummingbirds, dolphins, and horses. Say all the dolphins died out. In the far, far future, hummingbirds or horses could evolve into something that
could swim in the ocean like a dolphin. Indeed, ichthyosaurs in the era of dinosaurs looked much like dolphins. But that creature would be very different from a true dolphin: even
ichthyosaurs never developed echolocation. We would wait a very long time (possibly forever) for a bloodline to evolve the traits we already have present in other bloodlines today.
So, why is it ok to stand by or even encourage the extinction of one of these valuable, unique lineages?
We have already lost one.
We used to have four major rendering engines, but Opera halted development of its own rendering engine Presto before adopting Blink.
Three left. Spend them wisely.
As much as I don’t like having to work-around the quirks in all of the different browsers I test in, daily, it’s way preferable to a return to the dark days of the Web circa
most of the first decade of this century. Please help keep browsers diverse: nobody wants to start seeing this shit –
The Bodleian has a specific remit for digital archiving… but sometimes they just like collecting stuff, too, I’m sure.
The team responsible for digital archiving had plans to spend World Digital Preservation Day running a stand in Blackwell Hall for some
time before I got involved. They’d asked my department about using the Heritage Window – the Bodleian’s 15-screen video wall – to show a carousel of slides with relevant content over
the course of the day. Or, they added, half-jokingly, “perhaps we could have Pong up there as it’ll be its 46th birthday?”
Free reign to play about with the Heritage Window while smarter people talk to the public about digital archives? Sure, sign me up.
But I didn’t take it as a joke. I took it as a challenge.
Emulating Pong is pretty easy. Emulating Pong perfectly is pretty hard. Indeed, a lot of the challenge in the preservation of (especially digital) archives in general is in
finding the best possible compromise in situations where perfect preservation is not possible. If these 8″ disks are degrading, is is acceptable to copy them onto a different medium? If this video file is unreadable in
modern devices, is it acceptable to re-encode it in a contemporary format? These are the kinds of questions that digital preservation specialists have to ask themselves all the damn
time.
The JS Gamepad API lets your web browser talk to controller devices.
Emulating Pong in a way that would work on the Heritage Window but be true to the original raised all kinds of complications. (Original) Pong’s aspect ratio doesn’t fit nicely on a 16:9
widescreen, much less on a 27:80 ultrawide. Like most games of its era, the speed is tied to the clock rate of the processor. And of course, it should be controlled using a
“dial”.
By the time I realised that there was no way that I could thoroughly replicate the experience of the original game, I decided to take a different track. Instead, I opted to
reimplement Pong. A reimplementation could stay true to the idea of Pong but serve as a jumping-off point for discussion about how the experience of playing the game
may be superficially “like Pong” but that this still wasn’t an example of digital preservation.
Bip… boop… boop… bip… boop… bip…
Here’s the skinny:
A web page, displayed full-screen, contains both a <canvas> (for the game, sized appropriately for a 3 × 3 section of the video wall) and a
<div> full of “slides” of static content to carousel alongside (filling a 2 × 3 section).
Javascript writes to the canvas, simulates the movement of the ball and paddles, and accepts input from the JS
Gamepad API (which is awesome, by the way). If there’s only one player, a (tough! – only three people managed to beat it over the course of the day!) AI plays the other paddle.
A pair of SNES controllers adapted for use as USB
controllers which I happened to own already.
Increasingly, the Bodleian’s spaces seem to be full of screens running Javascript applications I’ve written.
I felt that the day, event, and game were a success. A few dozen people played Pong and explored the other technology on display. Some got nostalgic about punch tape, huge floppy disks,
and even mechanical calculators. Many more talked to the digital archives folks and I about the challenges and importance of digital archiving. And a good time was had by all.
I’ve open-sourced the entire thing with a super-permissive license so you can deploy it yourself (you know, on your ultrawide
video wall) or adapt it as you see fit. Or if you’d just like to see it for yourself on your own computer, you can (but unless
you’re using a 4K monitor you’ll probably need to use your browser’s mobile/responsive design simulator set to 3200 × 1080 to make it fit your screen). If you don’t have
controllers attached, use W/S to control player 1 and the cursor keys for player 2 in a 2-player game.
It’s always been a bit of an inconvenience to have to do these things, but it’s never been a terrible burden: even when I fly internationally – which is probably the hardest
part of having my name – I’ve learned the tricks I need to minimise how often I’m selected for an excessive amount of unwanted “special treatment”.
I plan to make my first trip to the USA since my name change, next year. Place bets now on how that’ll go.
This year, though, for the very first time, my (stupid bloody) unusual name paid for itself. And not just in the trivial ways I’m used to, like being able to spot my badge instantly on
the registration table at conferences I go to or being able to fill out paper forms way faster than normal people. I mean in a concrete, financially-measurable way. Wanna hear?
So: I’ve a routine of checking my credit report with the major credit reference agencies every few years. I’ve been doing so since long before doing so became free (thanks GDPR); long even before
I changed my name: it just feels like good personal data housekeeping, and it’s interesting to see what shows up.
It started out with the electoral roll. How did it end up like this? It was only the electoral roll. It was only the electoral roll.
And so I noticed that my credit report with Equifax said that I wasn’t on the electoral roll. Which I clearly am. Given that my credit report’s pretty glowing, I wasn’t too worried, but
I thought I’d drop them an email and ask them to get it fixed: after all, sometimes lenders take this kind of thing into account. I wasn’t in any hurry, but then, it seems: neither were
they –
2 February 2016 – I originally contacted them
18 February 2016 – they emailed to say that they were looking into it and that it was taking a while
22 February 2016 – they emailed to say that they were still looking into it
13 July 2016 – they emailed to say that they were still looking into it (which was a bit of a surprise, because after so long I’d almost forgotten that I’d even asked)
14 July 2016 – they marked the issue as “closed”… wait, what?
Given that all they’d done for six months was email me occasionally to say that it was taking a while, it was a little insulting to then be told they’d solved it.
I wasn’t in a hurry, and 2017 was a bit of a crazy year for me (for Equifax too, as it happens), so I ignored it for a bit, and
then picked up the trail right after the GDPR came into force. After all, they were storing personal information
about me which was demonstrably incorrect and, continued to store and process it even after they’d been told that it was incorrect (it’d have been a violation of principle 4 of the DPA 1998, too, but the GDPR‘s got bigger teeth: if you’re going to sick the law on somebody, it’s better that it has bark and bite).
Throwing the book tip-of-the-day: don’t threaten, just explain what you require and under what legal basis you’re able to do so. Let lawyers do the tough stuff.
My anticipation was that my message of 13 July 2018 would get them to sit up and fix the issue. I’d assumed that it was probably related to my unusual name and that bugs in
their software were preventing them from joining-the-dots between my credit report and the Electoral Roll. I’d also assumed that this nudge would have them either fix their software… or
failing that, manually fix my data: that can’t be too hard, can it?
Apparently it can:
You want me to make it my problem, Equifax, and you want me to change my name on the Electoral Roll to match the incorrect name you use to refer to me in your systems?
Equifax’s suggested solution to the problem on my credit report? Change my name on the Electoral Roll to match the (incorrect) name they store in their systems (to work around
a limitation that prevents them from entering single-character surnames)!
At this point, they turned my send-a-complaint-once-every-few-years project into a a full blown rage. It’s one thing if you need me to be understanding of the time it can take to fix
the problems in your computer systems – I routinely develop software for large and bureaucratic organisations, I know the drill! – but telling me that your bugs are my problems
and telling me that I should lie to the government to work around them definitely isn’t okay.
Dear Equifax: No. No no no. No. Also, no. Now try again. Love Dan.
At this point, I was still expecting them to just fix the problem: if not the underlying technical issue then instead just hack a correction into my report. But clearly they considered
this, worked out what it’d cost them to do so, and decided that it was probably cheaper to negotiate with me to pay me to go away.
Which it was.
This week, I accepted a three-figure sum from Equifax as compensation for the inconvenience of the problem with my credit report (which now also has a note of correction, not that my
alleged absence from the Electoral Roll has ever caused my otherwise-fine report any trouble in the past anyway). Curiously, they didn’t attach any strings to the deal, such as not
courting publicity, so it’s perfectly okay for me to tell you about the experience. Maybe you know somebody who’s similarly afflicted: that their “unusual” name means that a
credit reference company can’t accurately report on all of their data. If so, perhaps you’d like to suggest that they take a look at their credit report too… just saying.
You can pay for me to go away, but it takes more for me to shut up. (A lesson my parents learned early on.)
Apparently Equifax think it’s cheaper to pay each individual they annoy than it is to fix their database problems. I’ll bet that, in the long run, that isn’t true. But in the meantime,
if they want to fund my recent trip to Cornwall, that’s fine by me.
After the success of Challenge Robin this summer – where Ruth and I blindfolded her brother
Robin and drove him out to the middle of nowhere without his phone or money and challenged him to find his way home – Robin’s been angling for a sequel. He even went so far as to suffix the title
of his blog post on the subject “(part 1)”, in the hopes perhaps that we’d find a way to repeat the experience.
I gather that Robin was particularly concerned by the combination of the recommendation to bring swimwear and the warning that he may have to leave mainland UK… especially given that
the challenge takes place in November.
In response to an email sent a week in advance of the challenge, Robin quickly prepared and returned a “permission slip” from his parents, although I’m skeptical that either of them
actually saw this document, let alone signed it.
I’m told that the “signatures” on this document accurately replicate the signature styles of Robin’s parents. I’m guessing he forged a lot of these kinds of notes.
With about a day to go before the challenge began, Robin’s phone will have received a number of instructional messages from a sender-ID called “Control”, instructing him of his first
actions and kicking off his adventure. He’d already committed to going to work on Friday with a bag fully-packed for whatever we might have in store for him, but he doubtless wouldn’t
have guessed quite how much work had been put into this operation.
We considered giving Robin’s contact the alias ‘Smiler’, but ‘Frowny’ seemed more-fitting for the part.
By 18:06 he still hadn’t arrived to meet his contact. Had this adventure fallen at the first hurdle? Only time would tell…
Update – Friday 9 November 18:45: Robin arrived late and apologetic to find his contact, “Frowny”, at the GBK at that address, was played by JTA.
After sufficient apologies he was allowed to be granted the clue we’d expected to give him earlier…
The pair ate and drank and “Frowny” handed Robin his first clue: a map pointing to Cornwall Gardens in Kensington and instructions on where to find the next clue when he got there. The
game was afoot!
I love the little “Frowny” face; it really make this prop.
Clearly he’d taken the idea of being prepared for anything to a level beyond what we’d expected. Among his other provisions, he was carrying a tent, sleeping bag, and passport!
“Clearly my mistake,” he told his contact, “Was giving intelligent people a challenge and then leaving them three months to plan.”
Update – Friday 9 November 19:53: In Cornwall Gardens, Robin found the note (delayed somewhat, perhaps by the growing dark) and began his treasure
trail.
The sign at Cornwall Gardens kickstarted a journey visiting a thematic series of blue plaques around London before eventually leading to the Paddington Bear statue at Paddington
Station…
Soon after, though, things started to go very wrong…
I’m not sure that this was even one of the ones he was supposed to photograph, but anyway…
Update – Friday 9 Novembr 20:40: Let’s take a diversion, and I’ll rely on JTA to keep Robin’s eyes away from this post for a bit. Here’s what was
supposed to happen:
Robin would follow a trail of clues around London which would give him key words whose names alluded to literature about Paddington (station) and Penzance. Eventually he’d find a
puzzle box and, upon solving it, discover inside tickets for the Paddington-to-Penzance overnight sleeper train.
Meanwhile, I’ve been rushing around the countryside near Penzance setting up an epic extension to the previous trail complete with puzzles, mixed-terrain hikes, highlands, islands,
lions, tigers and bears (oh my). Some of those might not really have been in the plan.
The storm was just starting as I climbed up to a cliff edge for an as-yet-undisclosed reason; it’s already looking pretty wild and getting wilder all the time!
So now we’re working out what to do next. Right now I’m holed-up in an undisclosed location near Penzance (the ultimate target of the challenge) and Robin’s all the way over in London.
We’re working on it, but this hasn’t been so successful as we might have liked.
Update – Saturday 10 November 07:58: We’ve managed to get Robin onto a series of different trains rather than the sleeper, so he’ll still get to
Penzance… eventually! Meanwhile, I’m adjusting the planned order of stages at this end to ensure that he can still get a decent hike in (weather permitting).
Update – Saturday 10 November 10:45: Originally, when Robin had been expected to arrive in Penzance via a sleeper train about three hours ago, he’d
have received his first instruction via The Gadget, which JTA gave him in London:
The Gadget is a cheap Android smartphone coupled to a beefy battery pack and running custom software I wrote for the challenge.
The Gadget’s primary purpose is to send realtime updates on Robin’s position so that I can plot it on a map (and report it to you guys!) and to issue him with hints so that he knows
where he’s headed next, without giving him access to a phone, Internet, navigation, maps, etc. The first instruction would be to head to Sullivan’s Diner for breakfast (where
I’ve asked staff to issue him with his first clue): cool eh? But now he’s only going to be arriving in the afternoon so I’m going to have to adapt on-the-fly. Luckily I’ve got a plan.
The first clue has a picture of the ruin of a hill fort a few miles away and vauge instructions on how to find it.
I’m going to meet Robin off his train and suggest he skips this first leg of the challenge, because the second leg is… sort-of time-critical…
Update – Saturday 10 November 13:29: Robin finally arrives in Penzance on a (further-delayed) train. I’ve given him a sausage sandwich at
Sullivan’s Diner (who then gave him the clue above), turned on The Gadget (so I’ve got live tracking of his location), and given him the next clue (the one he’d have gotten at
Roger’s Tower) and its accompanying prop.
Rushing off the train, carrying his tent, sleeping bag, clothes…
Armed with the clue, Robin quickly saw the challenge that faced him…
The second clue SHOULD have been read at Roger’s Tower and so the photo would have made more sense.
After all of these delays, there’s only about an hour and a half until the tide comes in enough to submerge the causeway to St. Michael’s Mount: the island he’s being sent to. And he’s
got to get there (about an hour’s walk away), across the causeway, find the next clue, and back across the causeway to avoid being stranded. The race is on.
He WOULD have found this at Roger’s Tower. Why yes, I am a geocacher: why do you ask?
Luckily, he’d been able to open the puzzle box and knows broadly where to look on the island for the next clue. How will he do? We’ll have to wait and see…
Update – Saturday 10 November 14:18: Robin made spectacular time sprinting along the coast to Longrock (although his route might have been
suboptimal). At 14:18 he began to cross to the island, but with only a little over half an hour until the tide began to cover the causeway, he’d have to hunt quickly for the password he
needed.
Each pin is 3 minutes apart. You do the maths.
At 14:22 he retreived the clue and put the password into The Gadget: now he had a new set of instructions – to get to a particular location without being told what it was… only a
real-time display of how far away it was. 7.5km and counting…
I THINK he’s the rightmost blob. I wish I’d brought a telephoto lens.
Update – Saturday 10 November 14:57: Robin’s making his way along the coast (at a more-reasonable pace now!). He’s sticking to the road rather
than the more-attractive coast path, so I’ve had “Control” give him a nudge via The Gadget to see if he’d prefer to try the more-scenic route: he’ll need to, at some point, if he’s to
find his way to the box I’ve hidden.
While not as steep as the gradient to Roger’s Tower would’ve been, the coast path isn’t without its steep bits, too.
Update – Saturday 10 November 16:50: No idea where Robin is; The Gadget’s GPS has gone all screwy.
One of these pins is probably right, right?
But it looks like he probably made it to Cudden Point, where the final clue was hidden. And then kept moving, suggesting that he retreived it without plunging over the cliff
and into the sea.
It’s not VERY well hidden, but it only had to survive a day. A stormy day, mind…
In it, he’ll have found a clue as to broadly where his bed is tonight, plus a final (very devious) puzzle box with the exact location.
The fourth clue basically says “your bed is THAT way, but you need to open THIS puzzle box to know exactly where”. Evil.
The sun is setting and Robin’s into the final stretch. Will he make it?
Update – Saturday 10 November 17:25: He’s going to make it! He’s actually going to make it! Looks like he’s under a mile away and heading in the
right direction!
It might not be clear to him yet that there’s a river in the way, but I’m sure he’ll find a bridge. Or swim.
Update – Saturday 10 November 17:55: He made it!
Success!
We’ve both got lots to say, so a full debrief will take place in a separate blog post.
You may recall that on Halloween I mentioned that the Bodleian had released a mini choose-your-own-adventure-like adventure game book, available freely online. I decided that this didn’t go quite far
enough and I’ve adapted it into a hypertext game, below. (This was also an excuse for me to play with Chapbook, Chris Klimas‘s new under-development story format for Twine.
If the thing you were waiting for before you experienced Shadows Out of Time was it to be playable in your browser, wait no longer: click here to play the game…
Unless they happened to bump into each other at QParty, the first time Ruth and JTA met my school friend Gary was at my dad’s funeral. Gary had seen mention of the death in the local paper and came to the wake. About 30 seconds later, Gary and I were reminiscing, exchanging anecdotes about our misspent youths, when
suddenly JTA blurted out: “Oh my God… you’re Sc… Sc-gary?”
Ever since then, my internal monologue has referred to Gary by the new nickname “Scgary”, but to understand why requires a little bit of history…
While one end of the hall in which we held my dad’s wake turned into an impromptu conference of public transport professionals, I was at the other end, talking to my friends.
Despite having been close for over a decade, Gary and I drifted apart somewhat after I moved to Aberystwyth in 1999, especially as I became more and more deeply involved with volunteering at Aberystwyth Nightline and the
resulting change in my social circle which soon was 90% comprised of fellow volunteers, (ultimately resulting in JTA’s “What,
Everyone?” moment). We still kept in touch, but our once more-intense relationship – which started in a primary school playground! – was put on a backburner as we tackled the next
big things in our lives.
This is what the recruitment page on the Aberystwyth Nightline website looked like after I’d improved it. The Web was younger, then.
Something I was always particularly interested both at Nightline and in the helplines I volunteered with subsequently was training. At Nightline, I proposed and pushed forward a
reimplementation of their traditional training programme that put a far greater focus on experience and practical skills and less on topical presentations. My experience as a trainee
and as a helpline volunteer had given me an appreciation of the fundamentals of listening and I wanted future
trainees to be able to benefit from this by giving them less time talking about listening and more time practising listening.
Nightline training wasn’t always like this, I promise. Well: except for the flipchart covered in brainstorming; that was pretty universal.
The primary mechanism by which helplines facilitate such practical training is through roleplaying. A trainer will pretend to be a caller and will talk to a trainee, after which the
pair (along with any other trainers or trainees who are observing) will debrief and talk about how it went. The only problem with switching wholesale to a roleplay/skills-driven
approach to training at Aberystwyth Nightline, as I saw it, was the approach that was historically taken to the generation of roleplay material, which favoured the use of anonymised
adaptations of real or imagined calls.
Roleplay scenarios must be realistic (so that they simulate the experience of genuine calls with sufficient accuracy that they are meaningful) but they must also be
effective (at promoting the growth of the skills that are needed to best-support callers). Those two criteria often come into conflict in roleplay scenarios: a caller who sits
in near-silence for 20 minutes may well be realistic, but there’s a limit to how much you can learn from sitting in silence; a roleplay which tests every facet of a trainee’s practical
knowledge provides efficiency, but does not reflect the content of any call that has ever really happened.
I spent a lot of my undergraduate degree in this poky little concrete box (most of it before the redecoration photographed above), and damned if I wasn’t going to share what I’d
learned from the experience.
I spent some time outlining the characteristics of best-practice roleplays and providing guidelines to help “train the trainers”. These included ideas, some of which were (then) a
little radical, like:
A roleplay should be based upon a character, not a story: if the trainer knows how the call is going to end, this constrains the opportunity for the
trainee to explore the space and experiment with listening concepts. A roleplay is necessarily improvisational: get into your character, let go of your preconceptions.
Avoid using emotionally-charged experiences from your own life: use your own experience, certainly, but put your own emotional baggage aside. Not only is it unfair to
your trainee (they’re not your therapist!) but it can be a can of worms in its own right – I’ve seen a (great) trainee help a trainer to make a personal breakthrough for which they
were perhaps not yet ready.
Don’t be afraid to make mistakes: you’re not infallible, and you neither need to be nor to present yourself as a perfect example of a volunteer. Be willing to learn
from the trainees (I’ve definitely made use of things I’ve learned from trainees in real calls I’ve taken at Samaritans) and create a space in which you can collectively discuss how
roleplays went, rather than simply critiquing them.
I might have inadvertently introduced other skills practice to take place during the breaks in Nightline training: several trainees learned to juggle under my instruction, or were
shown the basics of lock picking…
In order to demonstrate the concepts I was promoting, I wrote and demonstrated a significant number of sample roleplay ideas, many of which I (or others) would then go on to flesh-out
into full roleplays at training sessions. One of these for which I became well-known was entitled My Friend Scott.
The caller in this roleplay presents with suicidal ideation fuelled by feelings of guilt and loneliness following the accidental death, about six months prior, of his best friend Scott,
for which he feels responsible. Scott had been the caller’s best friend since childhood, and he’s fixated on the adventures that they’d had together. He clearly has a huge admiration
for his dead friend, bordering on infatuation, and blames himself not only for the death but for the resulting fracturing of their shared friendship group and his subsequent isolation.
(We’re close to getting back to the “Scgary story”, I promise. Hang in here.)
Gary, circa 1998, at the door to my mother’s house. Unlike Scott, Gary didn’t die “six months ago”-from-whenever. Hurray!
When I would perform this roleplay as the caller, I’d routinely flesh out Scott and the caller’s backstory with anecdotes from my own childhood and early-adulthood: it seemed important
to be able to fill in these kinds of details in order to demonstrate how important Scott was to the caller’s life. Things that I really did with any of several of my childhood
friends found their way, with or without embellishment, into the roleplay, like:
Building a raft on the local duck pond and paddling out to an island, only to have the raft disintegrate and have to swim back
An effort to dye a friend’s hair bright red which didn’t produce a terribly satisfactory result but did stain many parts of a bathroom
Camping in the garden, dragging out a desktop computer and extension cable to fully replicate the “in the wild” experience
Flooding my mother’s garden (which at that time was a long slope on clay soil) in order to make a muddy waterslide
Generating fake credit card numbers to facilitate repeated month-long free trials of an ISP‘s services
Riding on the bonnet of a friend’s first car, hanging on to the windscreen wipers, eventually (unsurprisingly) falling off and getting run over
That time Scott Gary and I tried to dye his hair red but mostly dyed what felt like everything else in the world.
Of course: none of the new Nightliners I trained knew which, if any, of these stories were real – that was never a part of the experience. But many were real, or had a morsel of truth.
And a reasonable number of them – four of those in the list above – were things that Gary and I had done together in our youth.
JTA’s surprise came from that strange feeling that occurs when two very parts of your life that you thought were completely separate suddenly and unexpectedly collide with one another
(I’m familiar with it). The anecdote that Gary had just shared about our teen years was one that exactly mirrored something
he’d heard me say during the My Friend Scott roleplay, and it briefly crashed his brain. Suddenly, this was Scott standing in front of him, and he’d been able to get
far enough through his sentence to begin saying that name (“Sc…”) before the crash stopped him in his tracks and he finished off with “…gary”.
Scott Gary always had a certain charm with young women. Who were these two and what were they doing in my bedroom? I don’t know, but if there’s an answer, then
Scott Gary is the answer.
I’m not sure whether or not Gary realises that, in my house at least, he’s to this day been called “Scgary”.
I bumped into him, completely by chance, while visiting my family in Preston this weekend. That reminded me that I’d long planned to tell this story: the story of Scgary, the imaginary
person who exists only in the minds of the tiny intersection of people who’ve both (a) met my friend Gary and know about some of the crazy shit we got up to together when we were young
and foolish and (b) trained as a volunteer at Aberystwyth Nightline during the window between me overhauling how training was provided and ceasing to be involved with the training
programme (as far as I’m aware, nobody is performing My Friend Scott in my absence, but it’s possible…).
That time Scott Gary (drunk) hooked up with my (even more drunk) then crush at my (drunken) 18th birthday party.
Gary asked me to give him a shout and meet up for a beer next time I’m in his neck of the woods, but it only occurred to me after I said goodbye that I’ve no idea what the best way to
reach him is, these days. Like many children of the 80s, I’ve still got the landline phone numbers memorised of all of my childhood friends, but even if that number is still
valid, it’d be his parents house!
I guess that I’ll let the Internet do the work for me: perhaps if I write this, here, he’ll find it, somehow. Hi, Scgary!
Here’s a thought: what’s the minimum number of votes your party would need to attract in order to be able to secure a majority of seats in the House of Commons and form a government?
Let’s try to work it out.
The 2017 general election reportedly enjoyed a 68.8% turnout. If we assume for simplicity’s sake that each constituency had the same turnout and that votes for candidates other than
yours are equally-divided amongst your opposition, that means that the number of votes you need to attract in a given constituency is:
68.8% × the size of its electorate ÷ the number of candidates (rounded up)
For example, if there was a constituency of 1,000 people, 688 (68.8%) would have voted. If there were 3 candidates in that constituency you’d need 688 ÷ 3 = 229⅓, which rounds up to 230 (because you need the plurality of the ballots) to vote for your candidate in order to secure the seat. If there are
only 2, you need 345 of them.
It would later turn out that Barry and Linda Johnson of 14 West Street had both indented to vote for the other candidate but got confused and voted for your candidate instead. In
response, 89% of the nation blame the pair of them for throwing the election.
The minimum number of votes you’d need would therefore be this number for each of the smallest 326 constituencies (326 is the fewest number of seats you can hold in the
650-seat House of Commons and guarantee a strict majority; in reality, a minority government can sometimes form a government but let’s not get into that right now). Constituencies vary
significantly in size, from only 21,769 registered voters in Na h-Eileanan an Iar (the Western Isles of Scotland, an SNP/Labour marginal) to 110,697 in the Isle of Wight (which
flip-flops between the Conservatives and the Liberals), but each is awarded exactly one seat, so if we’re talking about the minimum number of votes you need we can take the
smallest 326.
Win these constituencies and no others and you control the Commons, even though they’ve tiny populations. In other news, I think this is how we end up with a SNP/Plaid coalition
government.
By my calculation, with a voter turnout of 68.8% and assuming two parties field candidates, one can win a general election with only 7,375,016 votes; that’s 15.76% of
the electorate (or 11.23% of the total population). That’s right: you could win a general election with the support of a little over 1 in 10 of the population, so long as it’s the
right 1 in 10.
I used a spreadsheet and everything; that’s how you know you can trust me. And you can download it, below, and try it for yourself.
I’ll leave you to decide how you feel about that. In the meantime, here’s my working (and you can
tweak the turnout and number-of-parties fields to see how that affects things). My data comes from the following Wikipedia/Wikidata sources: [1], [2], [3], [4],
[5] mostly because the Office of National Statistics’ search engine is terrible.
A puzzle that the steam locomotive enthusiasts among you (you’re out there, right?) might stand a chance at solving:
The picture below is of “6040”, the last steam locomotive to be built for the Department of Railways New South Wales in Australia. She was in service as a coal/goods transporter from
1957 through 1967 before the increase in the use of diesel on the railways lead to the death of steam. She was eventually rescued and displayed by the New South Wales Railway Museum, which is where the photo was taken. There, starting from her 50th birthday, a team of volunteers have been
restoring her. But that’s perhaps not the thing that’s most-unusual about her, or her class (AD60).
New South Wales Government Railways’ AD60-class “6040”, with mystery pipes highlighted
I’ve highlighted on the photo a feature that you’ve probably never seen before, even if you’re of an inclination to go “Ooh, a steam loco: I’mma have a closer look at that!”.
What you’re seeing is an open pipe (with a funnel-like protrusion at one end) connecting the area behind the leading wheels to the cab. What’s it for? Have a think
about it as you read the rest of this post, and see if you can come up with the answer before I tell you the answer.
AD60 “6012”, seen in this 1950s photo, had not yet been fitted with the “mystery pipes”, which were added later.
These pipes weren’t initially fitted to “6040” nor to any of her 41 sisters: they were added later, once the need for them became apparent.
If you’re thinking “ventilation”, you’d be wrong, but I can see why you’d make that guess: the AD60 is an extremely long locomotive, and sometimes long steam locomotives
experience ventilation problems when going through tunnels. Indeed, this was a concern for the AD60 and some were fitted with ventilation pipes, but these carried air from the
front of the engine back to the cab, not from down near the wheels like this mystery pipe would. However, the pipe does connect through to the cab…
“City of Canberra”/”6029”, restored to functionality (seen here in 2015), either never had or wasn’t refitted during restoration with the mystery pipes.
It’s worth taking a moment though to consider why this is such a long locomotive, though: you may have noticed that it exhibits a rather unusual shape! The AD60 is a Garratt locomotive, an uncommon articulated design which places a single (usually relatively-large) boiler straddled in-between two steam
engines. Articulating a locomotive allows a longer design to safely take corners that were only rated for shorter vehicles (which can be important if your network rolled out
narrow-gauge everywhere to begin with, or if you put too many curves onto a mountain railway). Garratt (and other articulated steam) locos are a fascinating concept however you look at
them, but I’m going to try harder than usual to stay on-topic today.
Just go around the mountain! (Around and around and around…) Oh damn, I’ve gone off topic and now I’m thinking about OpenTTD.
And by the time you’re articulating a locomotive anyway, engineer Herbert William Garratt reasoned, you
might as well give it a huge boiler and two engines and give it the kind of power output you’d normally expect from double-heading your train. And it pretty-much worked, too!
Garratt-type articulated steam locomotives proved very popular in Africa, where some of the most-powerful ones constructed remained in service until 1980, mountainous parts of Asia, and
– to a lesser extent – in Australia.
Each of the forward and rear engine bogies in a Garratt design pivots independently; the boiler and cab are suspended between them.
Indeed: it’s the combination of length of this loco and its two (loud) engines that necessitated the addition of the “mystery pipe”. Can you work out what it is, yet? One final clue
before I give the game away – it’s a safety feature.
While you think about that, I direct your attention to this photo of the Я-class (of which only one was ever
built), which shows you what happens then the Soviet Union thought “Da, we have to be having one of these ‘Garratt’ steam engines with the bending… but we have also to be making it much
bigger than those capitalist dogs would.” What a monster!
Minutes of the meeting at which Cowper demonstrated his invention (click through for full text via Google Books).
In the 1840s, engineer Edward Alfred Cowper (who’d later go on to design the famous single-arch roof of Birmingham New
Street station which lasted until its redevelopment in the 1960s) invented a device called the railway detonator. A
detonator is a small explosive charge that can be attached to a railway line and which will explode when a train drives over it. The original idea – and still one in which they’re used
to this day – is that if a train breaks down or otherwise has to come to a halt in foggy conditions, they can be placed on the track behind. If another train comes along, the driver
will hear the distinctive “bangs” of the detonators which will warn them to put on the brakes and stop, and so avoid a collision with the stopped train ahead.
They’re the grown-up equivalent of those things kids used to be able to buy that went bang when you threw them on the ground (or,
in a great example of why kids shouldn’t be allowed to buy them, at least in the case of a childhood friend of mine, detonated them by biting them!).
But when your cab is behind not only the (long) boiler and (even longer and very loud) articulated engine of an AD60, there’s a very real risk that you won’t hear a detonator,
triggered by the front wheels of your loco. Your 264-tonnes of locomotive plus the weight of the entire train behind you can sail on through a trio of detonators and not even hear the
warning (though you’re probably likely to hear the bang that comes later, when you catch up with the obstruction ahead).
The mystery tubes on the AD60 were added to address this problem: they’re a noise-carrier! Connecting the area right behind the leading wheels to the drivers’ cab via a
long tube makes the driver more-able to hear what’s happening on the rails, specifically so that they can hear if the engine begins to roll over a detonator. That’s a crazy bit of
engineering, right? Installing a tube along most of the length of a locomotive just to carry the sound of the wheels (and anything they collide with) to the driver’s cab seems like a
bizarre step, but having already-constructed the vehicle in a way that introduced that potential safety problem, it was the simplest and lowest-cost retrofitting.
In other news: this is what happens when I finish the last exam I anticipate sitting in a long while, this week (I know I’ve said that before, last time I was in the position of finishing a final-exam-before-a-dissertation). Clearly my brain
chooses to celebrate not having to learn what I was studying for a bit by taking a break to learn something completely different.
Implemented a demonstrative XSS payload targetting a CMS (as a
teaching tool, to demonstrate how a series of minor security vulnerabilities can cascade into one huge one).
Gotten my ‘flu jab.
Not every day is like this. But sometimes, just sometimes, one can be.
As of next week, I’ll have been blogging for 20 years, or about 54% of my life. How did that happen?
I’d been “blogging” – not that we called it that, yet – since late 1998, but my original collection of content-mangling Perl scripts wasn’t all that. More history…
The mid-1990s were a very different time for the World Wide Web (yes, we still called it that, and sometimes we even described its use as “surfing”). Going “on the Internet” was a
calculated and deliberate action requiring tying up your phone line, minutes of “connecting” along with all of the associated screeching sounds if you hadn’t
turned off your modem’s loudspeaker, and you’d typically be paying twice for the experience: both a monthly fee to your ISP for the service and a per-minute charge to your phone company for the call.
It was into this environment that in 1994 I published my first web pages: as far as I know, nothing remains of them now. It wasn’t until 1998 that I signed up an account with UserActive (whose website looks almost the same today as it did then) who offered economical subdomain hosting with shell and CGI support and launched “Castle of the Four Winds”, a set of vanity pages that
included my first blog.
Except I didn’t call it a “blog”, of course, because it wasn’t until the following year that Peter Merholz invented the word (he also commemorated 20 years of blogging, this year). I didn’t even call it a “weblog”, because
that word was still relatively new and I wasn’t hip enough to be around people who said it, yet. It was self-described as an “online diary”, a name which only served to
reinforce the notion that I was writing principally for myself. In fact, it wasn’t until mid-1999 that I discovered that it was being more-widely read than just by me and my
circle of friends when I attracted a stalker who travelled across the UK to try to “surprise” me by turning up at places she expected to
find me, based on what I’d written online… which was exactly as creepy as it sounds.
AvAngel.com
While the world began to panic that the coming millennium was going to break all of the computers, I migrated Castle of the Four Winds’ content into AvAngel.com, a joint vanity site
venture with my friend Andy. Aside from its additional content (purity tests, funny stuff, risqué e-cards), what we hosted was mostly the same old stuff, and I continued to write
snippets about my life in what was now quite-clearly a “blog-like” format, with the most-recent posts at the top and separate pages for content too old for the front page. Looking back,
there’s still a certain naivety to these posts which exemplify the youth of the Web. For example, posts routinely referenced my friends by their email
addresses, because spam was yet to become a big enough problem that people didn’t much mind if you put their email address on a public webpage somewhere, and because email
addresses still carried with them a feeling of anonymity that ceased to be the case when we started using them for important things.
Technologically-speaking, too, this was a simpler time. Neither Javascript nor CSS support was widespread (nor
consistently-standardised) enough to rely upon for anything other than the simplest progressive enhancement unless you were willing to “pick a side” in what we’d subsequently call the
first browser war and put one of those apalling “best viewed in Internet Explorer” or “best viewed in Netscape Navigator” banners on your site. I’ve always been a believer in a
universal web (and my primary browser at the time was Opera, anyway, as it mostly-remained until Opera went wrong in 2013), and I didn’t have the energy to write everything twice, so our cool/dynamic
functionality came mostly from back-end (e.g. Perl, PHP) technologies.
Meanwhile, during my initial months as a student in Aberystwyth, I wrote a series of emails to friends back home entitled “Cool And Interesting Thing Of The Day To Do At The University
Of Wales, Aberystwyth”, and put copies of each onto my student webspace; I’ve since recovered these and integrated them into my unified blog.
Scatmania.org
In 2002 I’d bought the domain name scatmania.org – a reference to my university halls of residence nickname “Scatman Dan”; I genuinely didn’t consider the possibility that the name
might be considered scatalogical until later on. As I wanted to continue my blogging at an address that felt like it was solely mine (AvAngel.com having been originally shared with a
friend, although in practice over time it became associated only with me), this seemed like a good domain upon which to relaunch. And so, in
mid-2003 and powered by a short-lived and ill-fated blogging engine called Flip I did exactly that. WordPress, to which I’d subsequently migrate, hadn’t been invented yet and it wasn’t clear whether its predecessor,
b2/cafelog, would survive the troubles its author was experiencing.
From this point on, any web address for any post made to my blog still works to this day, despite multiple technological and infrastructural changes to my blog (and
some domain name shenanigans!) in the meantime. I’d come to be a big believer in the mantra that cool URIs don’t change: something that as far as possible I’ve committed to trying to upload in my blogging, my archiving, and my paid work since
then. I’m moderately confident that all extant links on the web that point to earlier posts are all under my control so they can (and in most cases have) been fixed
already, so I’m pretty close to having all my permalink URIs be “cool”, for now. You might hit a short chain of redirects,
but you’ll get to where you’re going.
And everything was fine, until one day in 2004 when it wasn’t. The server hosting scatmania.org died in a very bad way, and because
my backup strategy was woefully inadequate, I lost a lot of content. I’ve recovered quite a lot of it and put it back in-place, but some is probably gone forever.
One of the longest-lived web designs for scatmania.org paid homage to the original, but with more “blue” and a WordPress backing.
The resurrected site was powered by WordPress, and this was the first time that live database queries had been used to power my blog. Occasionally,
these days, when talking to younger, cooler developers, I’m tempted to follow the hip trend of reimplementing my blog as a static site, compiling a stack of host-anywhere HTML files based upon whatever-structure-I-like at the “backend”… but then I remember that I basically did that already for six
years and I’m far happier with my web presence today. I’ve nothing against static site systems (I’m quite partial to Middleman, myself,
although I’m also fond of Hugo) but they’re not right for this site, right now.
IndieAuth hadn’t been invented yet, but I was quite keen on the ideals of OpenID (I still am, really), and
so I implemented what was probably the first viable “install-anywhere” implementation of OpenID for WordPress – you can see part of it
functioning in the top-right of the screenshot above, where my (copious, at that time) LiveJournal-using friends were encouraged to sign in to my blog using their LiveJournal identity.
Nowadays, the majority of the WordPress plugins I use are ones I’ve written myself: my blog is powered by a CMS that’s more
“mine” than not!
I no longer have the images that made my 2006 redesign look even remotely attractive, so here it is mocked-up with block colours instead.
Over the course of the first decade of my blogging, a few trends had become apparent in my technical choices. For example:
I’ve always self-hosted my blog, rather than relying on a “blog as a service” or siloed social media platform like WordPress.com, Blogger, or LiveJournal.
I’ve preferred an approach of storing the “master” copy of my content on my own site and then (sometimes) syndicating it elsewhere: for
example, for the benefit of my friends who during their University years maintained a LiveJournal, for many years I had my blog cross-post to a LiveJournal account (and backfeed copies of comments back to my site).
I’ve favoured web standards that provided maximum interoperability (e.g. RSS with full content)
and longevity (serving HTML pages from permanent URLs, adding
“extra” functionality via progressive enhancement so as to ensure that content functioned e.g. without Javascript, with CSS
disabled or the specification evolved, etc.).
These were deliberate choices, but they didn’t require much consideration: growing up with a Web far less-sophisticated than today’s (e.g. truly stateless prior to the advent of
HTTP cookies) and seeing the chaos caused during the first browser war and the period of stagnation that followed, these choices seemed intuitive.
That body font is plain old Verdana, you know: I’ve always felt that it (plus full justification) was the right choice for this particular design, even though I regret other parts of
it (like the brightness!).
As you’d expect from a blog covering a period from somebody’s teen years through to their late thirties, there’ve been significant changes in the kinds of content I’ve posted (and the
tone with which I’ve done so) over the years, too. If you dip into 2003, for example, you’ll see the results of quiz memes and
unqualified daily minutiae alongside actual considered content. Go back
further, to early 1999, and it is (at best) meaningless wittering about the day-to-day life of a teenage student. It took until around
2009/2010 before I actually started focussing on writing content that specifically might be enjoyable for others to read (even where
that content was frankly silly) and only far more-recently-still that I’ve committed to the “mostly technical stuff, ocassional bits of ‘life’ stuff” focus that I have today.
I say “committed”, but of course I’m fully aware that whatever this blog is now, it’ll doubtless be something somewhat different if I’m still writing it in another two decades…
2014 may have included my most-prolific month of blogging, but 2003-2005 saw the most-consistent high-volume of content.
Once I reached the 2010s I started actually taking the time to think about the design of my blog and its meaning. Conceptually, all of my content is data-driven: database tables full of
different “kinds” of content and associated metadata, and that’s pretty-much ideal – it provides a strong separation between content and presentation and makes it possible to make
significant design changes with less work than might otherwise be expected. I’ve also always generally favoured a separation of concerns in web development and so I’m not a fan
of CSS design methodologies that encourage class names describing how things should appear, like Atomic CSS. Even where it results
in a performance hit, I’d far rather use CSS classes to describe what things are or represent. The single biggest
problem with this approach, to my mind, is that it violates the DRY principle… but that’s something that your CSS preprocessor’s there to fix for you, isn’t it?
But despite this philosophical outlook on the appropriate gap between content and presentation, it took until about 2010 before I actually attached any real significance to the
presentation at all! Until this point, I’d considered myself to have been more of a back-end than a front-end engineer, and felt that the most-important thing was to get the
content out there via an appropriate medium. After all, a site without content isn’t a site at all, but a site without design is (or at least should be) still intelligible
thanks to browser defaults! Remember, again, that I started web development at a time when stylesheets didn’t exist at all.
My previous implementations of my blog design had used simple designs, often adapted from open-source templates, in an effort to get them deployed as quickly as possible and move on to
the next task, but now, I felt, it was time to do a little more.
My 2010 relaunch put far more focus on the graphical design elements of my blog as well as providing a fully responsive design based on (then-new) CSS media queries. Alongside my
focus on separation of concerns in web development, I’m also quite opinionated on the idea that a responsive design has almost always been a superior solution to having a separate
“mobile site”.
For a few years, I was producing a new theme once per year. I experimented with different colours, fonts, and layouts, and decided (after some ad-hoc A/B testing) that my audience was
better-served by a “front” page than by being dropped directly into my blog archives as had previously been the case. Highlighting the latest few – and especially the very-latest – post
and other recent content increased the number of posts that a visitor would be likely to engage with in a single visit. I’ve always presumed that the reason for this is that regular
(but non-subscribing) readers are more-likely to be able to work out what they have and haven’t read already from summary text than from trying to decipher an entire post: possibly
because my blogging had (has!) become rather verbose.
My 2011 design, in hindsight, said more about my mood and state-of-mind at the time than it did about artistic choices: what’s with all the black backgrounds and seriffed fonts? Is
this a funeral parlour?
I went through a bit of a lull in blogging: I’ve joked that I spent more time on my 2010 and 2011 designs than I did on the sum total of the content that was published in between the
pair of them (which isn’t true… at least, not quite!). In the month I left Aberystwyth for Oxford, for example, I was doing all kinds of exciting and new things…
and yet I only wrote a total of two blog posts.
With RSS waning in popularity – which I can’t understand: RSS is amazing! – I began to crosspost to
social networks like Twitter and Google+ (although no longer to Google+, following the news of its imminent demise) to help those readers who prefer to get their content via these
media, but because I wasn’t producing much content, it probably didn’t make a significant difference anyway: the chance of a regular reader “missing” something must have been remarkably
slim.
The 2012 design featured “CSS peekaboo”: a transformation that caused my head to “hide” from you behind the search bar if your cursor got too close. Ruth, I hear, spent far too long playing with just this feature.
Nobody calls me “Scatman Dan” any more, and hadn’t for a long, long time. Given that my name is already awesome and unique
all by itself (having changed to be so during the era in which scatmania.org was my primary personal domain name), it felt like I had the opportunity to rebrand.
I moved my blog to a new domain, DanQ.me (which is nice and short, too) and came up with a new collection of colours, fonts, and layout choices that I felt better-reflected my identity…
and the fact that my blog was becoming less a place to record the mundane details of my daily life and more a place where I talk about (principally-web)
technology, security, and GPS games… and just occasionally about other topics like breadmaking and books. Also, it gave me a chance to get on top of the current trend in web design for big, clean, empty spaces, square corners, and using pictures
as the hook to a story.
The second design of my blog after moving to DanQ.me showed-off posts with big pictures, framed by lots of white-space.
I’ve been working harder this last year or two to re-integrate (in a PESOS-like way) into my blog content that I’ve published elsewhere, mostly geocaching logs and
geohashing expedition records, and I’ve also done so retroactively, so in addition to my first blog article on the subject
of geocaching, you can read my first ever cache log without switching to a different site nor relying upon the
continued existence and accessibility of that site. I’ve been working at being increasingly mindful of where my content is siloed outside of my control and reclaiming it by hosting it
here, on my blog.
Particular areas in which I produce content elsewhere but would like to at-least maintain a copy here, and would ideally publish here first and syndicate elsewhere, although I
appreciate that this is difficult, are:
Reddit, where I’ve written tens of thousands of words under a variety of accounts, but I don’t really pay attention to the site any more
I left Facebook in 2011 but I still have a backup of what was on my “Wall” at that point, which I could look into reintegrating into my
blog
I share a lot of the source code I write via my GitHub account, but I’m painfully aware that this is yet-another-silo that I ought to learn
not to depend upon (and it ought to be simple enough to mirror my repos on my own site!)
I’ve got a reasonable number of videos on two YouTube channels which are online by Google’s good graces (and potential for advertising
revenue); for a handful of technical reasons they’re a bit of a pain to self-host, but perhaps my blog could act as a secondary source to my own video content
I write business reviews on Google Maps which I should probably look into recovering from the hivemind and hosting here… in fact, I’ve
probably written plenty of reviews on other sites, too, like Amazon for example…
On two previous occasions I’ve maintained an online photo gallery; I might someday resurrect the concept, at least for the photos that used to be published on them
I’ve dabbled on a handful of other, often weirder, social networks before like Scuttlebutt (which has a genius concept, by the way) and
Ello, and ought to check if there’s anything “original” on there I should reintegrate
Going way, way back, there are a good number of usenet postings I’ve made over the last twenty-something years that I could reclaim, if I can find them…
(if you’re asking why I’m inclined to do all of these things: here’s why)
This looks familiar.
20 years and around 717,000 words worth of blogging down, it’s interesting to look back and see how things have changed: in my life, on the Web, and in the world in general. I’ve seen
many friends’ blogs come and go: they move into a new phase of their life and don’t feel like what they wrote before reflects them today, most often, and so they delete them… which is
fine, of course: it’s their content! But for me it’s always felt wrong to do so, for two reasons: firstly, it feels false to do so given that once something’s been put on the Web, it
might well be online forever – you can’t put the genie back in the bottle! And secondly: for me, it’s valuable to own everything I wrote before. Even the cringeworthy things I
wrote as a teenager who thought they knew everything and the antagonistic stuff I wrote in my early 20s but that I clearly wouldn’t stand by today is part of my history, and
hiding that would be a disservice to myself.
The 17-year-old who wrote my first blog posts two decades ago this month fully expected that the things he wrote would be online forever, and I don’t intend to take that away from him.
I’m sure that when I write a post in October 2038 looking back on the next two decades, I’ll roll my eyes at myself today, too, but for me: that’s part of the joy of a
long-running personal blog. It’s like a diary, but with a sense of accountability. It’s a space on the web that’s “mine” into which I can dump pretty-much whatever I like.
I love it: I’ve been blogging for over half of my life, and if I can get back to you in 2031 and tell you that I’ve by-then been doing so for two-thirds of my life, that would be a win.
This weekend, I attended part of Oxford’s first ever IndieWebCamp! As a long (long, long) time
proponent of IndieWeb philosophy (since long before anybody said “IndieWeb”, at least) I’ve got my personal web presence pretty-well sorted out.
Still, I loved the idea of attending and pushing some of my own tools even further: after all, a personal website isn’t “finished” until its owner says it is! One of the things I ended
up hacking on was pretty-predictable: enhancements to my recently-open-sourced geocaching PESOS tools… but the
other’s worth sharing too, I think.
Some of IndieWebCamp Oxford’s attendees share knowledge and hack code together.
I’ve recently been playing with WebVR – for my day job at the Bodleian, I swear! – and I was looking for
an excuse to try to expand some of what I’d learned into my personal blog, too. Given that I’ve recently acquired a Ricoh Theta
V I thought that this’d be the perfect opportunity to add WebVR-powered panoramas to this site. My goals were:
Entirely self-hosted; no external third-party dependencies
Must degrade gracefully (i.e. even if you’re using an older browser, don’t have Javascript enabled, etc.) it should at least show the original image
In plain-old browsers should support mouse (or touch) control to pan the scene
Where accelerators are available (e.g. mobiles), “magic window” support to allow twist-to-explore
And where “true” VR hardware (Cardboard, Vive, Rift etc.) with WebVR support is available, allow one-click use of that
It wouldn’t be a geeky hacky camp thingy if it didn’t finish at a bar.
Hopefully the images above are working for you and are “interactive”. Try click-and-dragging on them (or tilt your device), try fullscreen mode, and/or try WebVR mode if you’ve got
hardware that supports it. The mechanism of operation is slightly hacky but pretty simple: here’s how it works:
The image is inserted into the page as normal but with an extra CSS class of “vr360” and a data attribute pointing to the full-resolution image, e.g.:
<img class="vr360" src="/uploads/2018/09/R0010005_20180922182210-1024x512.jpg" alt="IndieWebCamp Oxford attendees at the pub" width="640" height="320"
data-vr360="/uploads/2018/09/R0010005_20180922182210.jpg" />
Some Javascript swaps-out images with this class for an iframe of the same size, showing a special page and passing the image filename after the hash, e.g.:
for(vr360 of document.querySelectorAll('.vr360')){
const width = parseInt(vr360.width);
const height = parseInt(vr360.height);
if(width == 0) width = '100%'; // Fallback for where width/height not specified,
if(height == 0) height = '100%'; // needed because of some quirks with Dan's lazy-loader
vr360.outerHTML = `<iframe src="/q23-content/themes/q18/vr360/#${vr360.dataset.vr360}" width="${width}" height="${height}" class="aligncenter" class="vr360-frame" style="min-width:
340px; min-height: 340px;"></iframe>`;
}
The iframe page loads this Javascript file. This loads three.js (to make 3D things easy)
and WebVR-polyfill (to fix browser quirks). Finally (scroll to the bottom of the code), it creates a camera in the centre
of a sphere, loads the image specified in the hash, flips it, and paints it onto the inside surface of the sphere, sets up controls, and turns the user loose on it. That’s all there is
to it!
You’re welcome to any of my code if you’d like a drop-in approach to hosting panoramic photographs on your own personal site. My solution’s pretty extensible if you want e.g.
interactive hotspots or contextual overlays – in fact, that – plus an easy route to editing the content for less-technical users – is pretty-much exactly what I’m working on for my day
job at the moment.
As an ocassional geocacher and geohasher, I’m encouraged to post logs describing my adventures, and each major provider wants me to post my logs into theirsilo (see e.g. my logs on geocaching.com, on opencache.uk, and on the geohashing wiki). But as a believer in
the ideals behind the IndieWeb (since long before anybody said “IndieWeb”), I’m opposed to keeping the only copy of content that I produce in an
environment controlled by somebody else (why?).
How do I reconcile this?
Just another hundred metres to the cache, then it’s time to freeze my ass back to base.
What I’d prefer would be to be able to write my logs here, on my own blog, and for my content to by syndicated via some process into the logging systems of the various silo sites I
prefer. This approach is called POSSE – Publish on Own Site, Syndicate
Elsewhere. In addition to the widely-described benefits of this syndication strategy, such a system would also make it possible for me to:
write single posts that represent the same location published on multiple silos (e.g. a visit to a geocache published on two different listing sites [e.g. 1, 2])
Applying such an tool would require some work as different silos have different acceptable content rules (geocaching.com, for example, effectively forbids mention of the existence of
other geocache listing sites), but that’d theoretically be workable.
The ideal solution would be POSSE-based.
Unfortunately, content rules aren’t the only factor making PESOS – writing content into each silo and then copying it
to my blog – preferable to POSSE. There’s also:
Not all of the silos offer suitable (published) APIs, and where they do, the APIs are all distinctly different.
Geocaching.com specifically forbids the use of unapproved automated robots to access the site (and almost
certainly wouldn’t approve the kind of tool that would be ideal).
The siloed services are well-supported by official and third-party apps with medium-specific logic which make them the best existing way to produce logs.
A PESOS-based solution is far easier to implement, in this case.
Needless to say: as much as I’d have loved to POSSE my geo* logs, PESOS will do.
Implementation
My implementation is a WordPress plugin which does two things. The first is that it provides a Javascript bookmarklet and an
accompanying dynamically-generated Javascript file (the former loads the latter) served from my blog’s domain. That Javascript file contains reference to every log already published to
my blog, so that the Javascript code can deliberately omit these logs from any import. When executed on a log listing page like those linked above, it copies all of the details of that
log into a form which submits them back to my blog, where it’s received by the second part of the plugin.
The import controls appear in a new, right-most column (GCVote is also visible running in my browser).
The second part of the plugin takes this data and creates a new draft post. My plugin is pretty opinionated on this part because it’s geared strongly towards my use-case, so if you want
to use it yourself you’ll probably want to tweak the code a little (e.g. it applies specific tags and names metadata fields a particular way).
When run on OpenCache.uk effectively the same interface is presented, even though the underlying mechanisms and data locations are different.
It’s not fully-automated and it’s not POSSE,but it’s “good enough” and it’s enabled me to synchronise all of my cache logs to my blog. I’ve plans to extend it to support other GPS game services to streamline my de-siloisation even further.
I’ve generally been pretty defensive of Microsoft Edge, the default web browser in Windows 10. Unlike its much-mocked
predecessor Internet Explorer, Edge is fast, clean, modern, and boasts good standards-compliance: all of the things that
Internet Explorer infamously failed at! I was genuinely surprised to see Edge fail to gain a significant market share in its first few years: it seemed to me
that everyday Windows users installed other browsers (mostly Chrome, which is causing its own problems) specifically because Internet Explorer was
so terrible, and that once their default browser was replaced with something moderately-good this would no longer be the case. But that’s not what’s happened. Maybe it’s because Edge’s
branding is too-remiscient of its terrible
predecessor or maybe just because Windows users have grown culturally-used to the idea that the first thing they should do on a new PC is download a different browser, but
whatever the reason, Edge is neglected. And for the most part, I’ve argued, that’s a shame.
I ranted at an Edge developer I met at a conference, once, about Edge’s weak TLS debugging tools that couldn’t identify an OCSP stapling issue that only affected Edge, but I thought
that was the worse of its bugs… until now…
But I’ve changed my tune this week after doing some research that demonstrates that a long-standing security issue of Internet Explorer is alive and well in Edge. This particular issue,
billed as a “feature” by Microsoft, is deliberately absent from virtually every other web browser.
About 5 years ago, Steve Gibson observed a special feature of EV (Extended Validation) SSL certificates used on HTTPS websites: that their
extra-special “green bar”/company name feature only appears if the root CA (certificate authority) is among the browser’s default trust store for EV certificate signing. That’s
a pretty-cool feature! It means that if you’re on a website where you’d expect to see a “green bar”, like Three Rings, PayPal, or HSBC, then if you don’t see the green bar one day it most-likely means that your
connection is being intercepted in the kind of way I described earlier this year, and everything you see or send including
passwords and credit card numbers could be at risk. This could be malicious software (or nonmalicious software: some antivirus software breaks EV certificates!) or it could be your friendly local
network admin’s middlebox (you trust your IT team, right?), but either way: at least you have a chance of noticing, right?
Firefox, like most browsers, shows the company name in the address bar when valid EV certificates are presented, and hides it when the validity of that certificate is put into
question by e.g. network sniffing tools set up by your IT department.
Browsers requiring that the EV certificate be signed by a one of a trusted list of CAs and not allowing that list to be manipulated (short of recompiling the browser from
scratch) is a great feature that – were it properly publicised and supported by good user interface design, which it isn’t – would go a long way to protecting web users from unwanted
surveillance by network administrators working for their employers, Internet service providers, and governments. Great! Except Internet Explorer went and fucked it up. As Gibson
reported, not only does Internet Explorer ignore the rule of not allowing administrators to override the contents of the trusted list but Microsoft even provides a tool to help them do it!
From top to bottom: Internet Explorer 11, Edge 17, Firefox 61, Chrome 68. Only Internet Explorer and Edge show the (illegitimate) certificate for “Barclays PLC”. Sorry, Barclays; I
had to spoof somebody.
I decided to replicate Gibson’s experiment to confirm his results with today’s browsers: I was also interested to see whether Edge had resolved this problem in Internet Explorer. My
full code and configuration can be found here. As is doubtless clear from the title of this post and the
screenshot above, Edge failed the test: it exhibits exactly the same troubling behaviour as Internet Explorer.
Thanks, Microsoft.
I also tried Safari (both on MacOS, above, and iOS, below) and it behaved as the other non-Microsoft browsers do (i.e. arguably more-correctly than IE or Edge).
I shan’t for a moment pretend that our current certification model isn’t without it’s problems – it’s deeply flawed; more on that in a future post – but that doesn’t give anybody an
excuse to get away with making it worse. When it became apparent that Internet Explorer was affected by the “feature” described above, we all collectively rolled our eyes
because we didn’t expect better of everybody’s least-favourite web browser. But for Edge to inherit this deliberate-fault, despite every other browser (even those that share its
certificate store) going in the opposite direction, is just insulting.
Earlier this year I found a mystery cable. But today, I’ve got an even bigger mystery. What the hell is this?
It’s a… thing?
I found it in a meeting room at work, tucked away in a corner. Aside from the power cord, there are no obvious interfaces to it.
There are two keyhole-shaped “buttons” which can be pressed down about 2cm and which spring back up (except when they jam, but I think they’re not supposed to).
My best bet is that it’s some kind of induction-based charger? I imagine some kind of device like a radio microphone or walkie-talkie that can be pushed-in to these holes and the button
“spring” is just about closing the hole when it’s not in use. But the box is old, based on the style of plug, cable, and general griminess of the hardware… not to mention that
it’s got a stack of PAT test stickers going back at least 11 years.
No real markings anywhere on it: there’s a small hole in the (metal) base and PAT test stickers.
I’ve plugged it in and tried “pressing” the buttons but it doesn’t appear to do anything, which supports my “induction charger” hypothesis. But what does it charge? I must
know!
Edit:The only Electrak I can find make lighting control systems. Could it be
something to do with lighting control? I can’t find anything that looks like this on their website, though.
The plugs apparently look something like this, although I can’t find any here.
Edit 3: Hang on a minute… the most-recent PAT test sticker indicates that it was tested in… November 2019. Now my working hypothesis is that this is some kind
of power supply system for a time machine we haven’t yet built. I’ve asked a number of colleagues what it’s for (i.e. what plugs into it) and nobody seems to have a clue.
For those that don’t know, the skinny version is this: in May 2008 an XKCD comic was published proposing (or at least joking about) a new game with a
name reminiscient of geocaching. To play the game, participants use a mathematical hashing function on the current date
and the most recent Dow Jones Industrial Average opening value to generate sets of random coordinates around the
globe and then try to find their way to them, hopefully experiencing adventures along the way. The nature of stock markets and hashing functions means that the coordinates for any given
day are effectively random and impossible to predict (far) in advance, so it’s sometimes described as a spontaneous adventure generator.
The XKCD comic that started it all.
Recently, I found myself wondering about how much of a disadvantage players are at if they live in very “wet” graticules. Residents of the Channel Islands graticule (49 -2), for example, are confined to two land masses surrounded entirely by water. And while it’s
true that water hashpoints can be visited if you’re determined enough, it’s still got to be considered to be
playing at a disadvantage compared to those of us lucky ones in landlocked graticules like mine (51 -1).
And because I’m me and so can’t comfortably leave a question unanswered, I wrote a program to try to answer it! It’s among the hackiest, dirtiest software solutions I’ve ever written,
so if it works for you then it’s a flipping miracle. What it does is:
Determines which OpenStreetMap tiles (the image files served to your browser when you use OpenStreetMap) cover the graticule in question, and downloads them.
Extracts information about the colour of each pixel in each tile.
Counts the proportion of “water blue” pixels to other pixels (this isn’t perfect, because it trips over things like ferry lines on the map as being “not water”, especially at low
zoom-levels).
Some parts of Worcester College Lake are identified as “not water” on account of the text overlay.
I mentioned it was hacky, right?
You can try it for yourself, if you’d like. You’ll need NodeJS, wget, wc, and ImageMagick – all pretty standard or easy-to-get things on a typical Linux box. Run with
node geohash-pcwater.js 51 -1, where 51 -1 is the identifier for the graticule you’re interested in. And in case you’re interested – the Swindon graticule (where I live) is
about 0.68% water, but the Channel Islands graticule is closer to 93.13% water. That’s no small disadvantage: sorry, Channel Islands geohashers!
Update 2018-08-22: discovered some prior art that takes a
somewhat-similar approach.




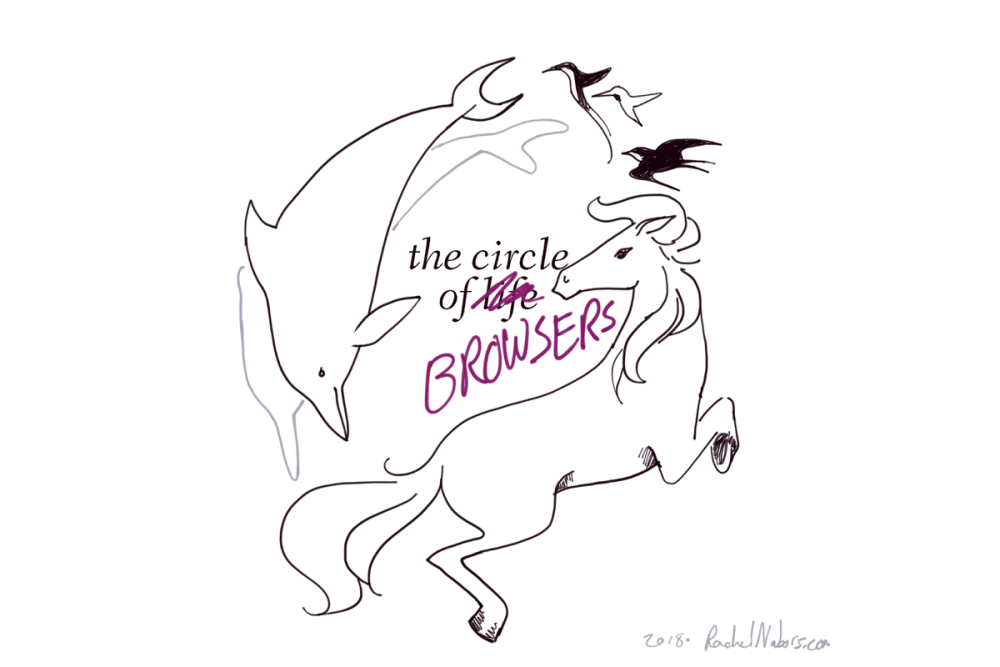






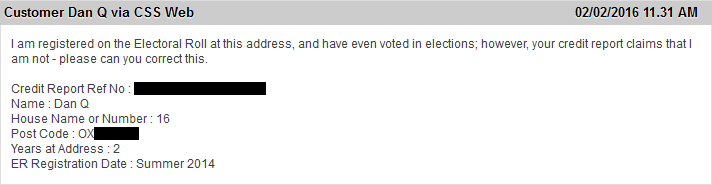
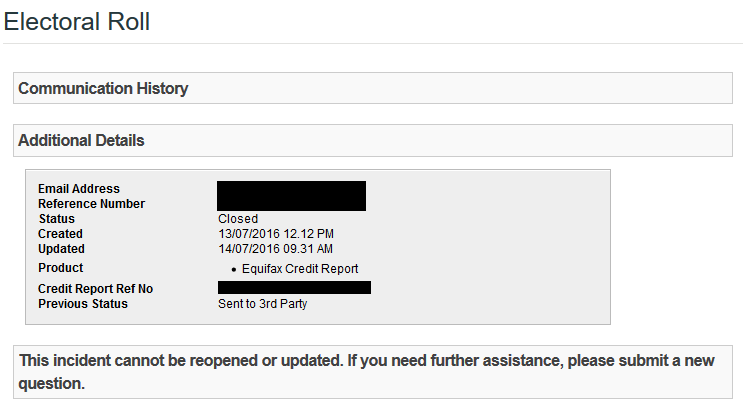
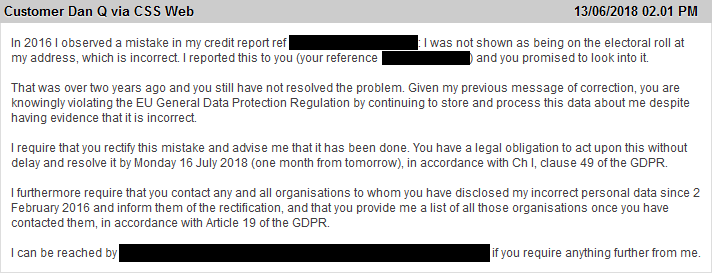
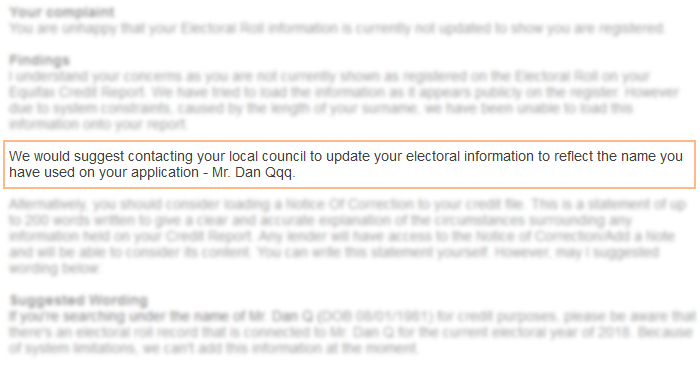
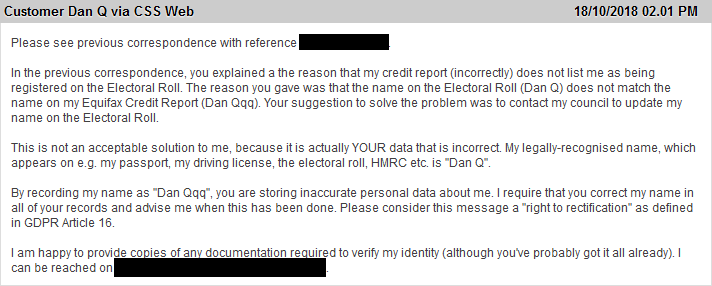


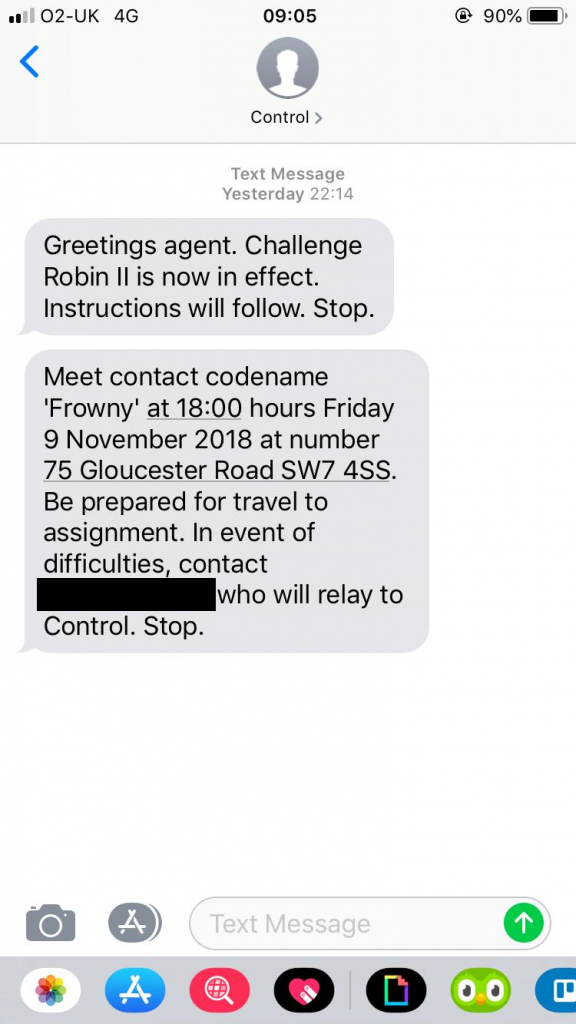










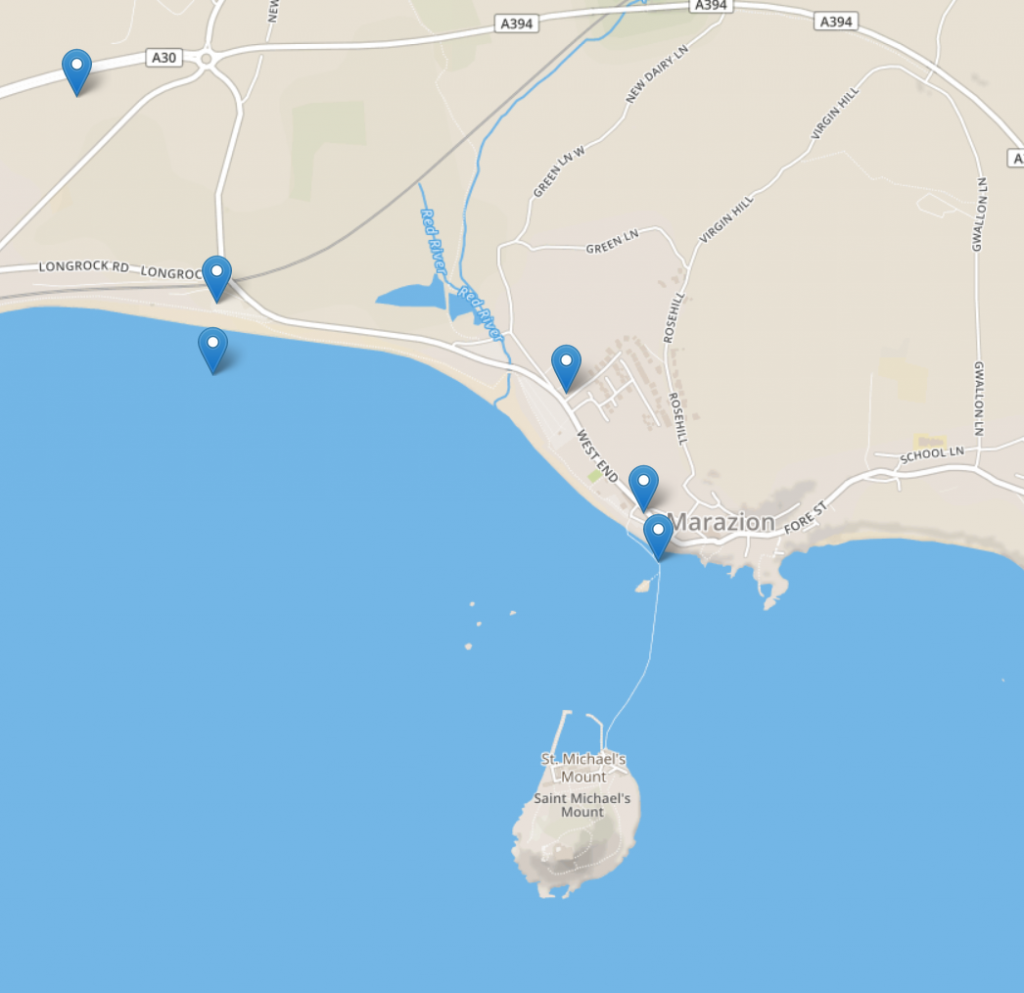

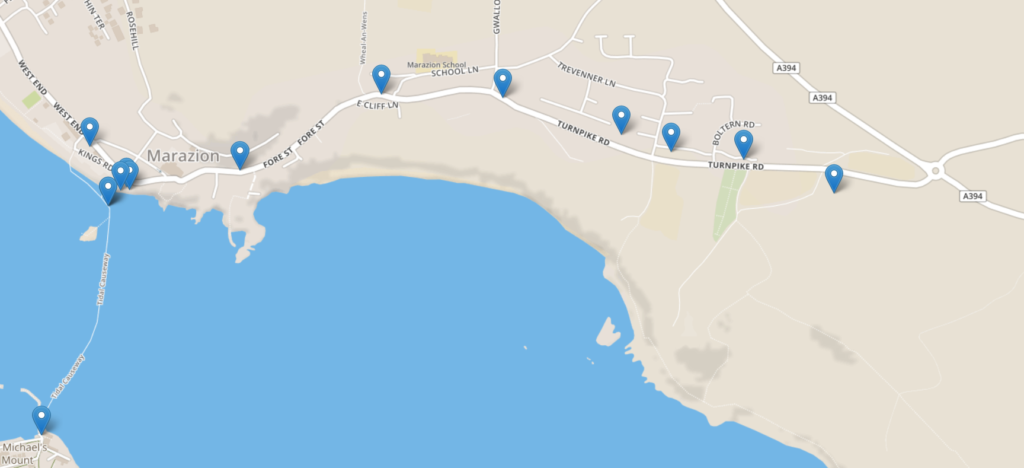
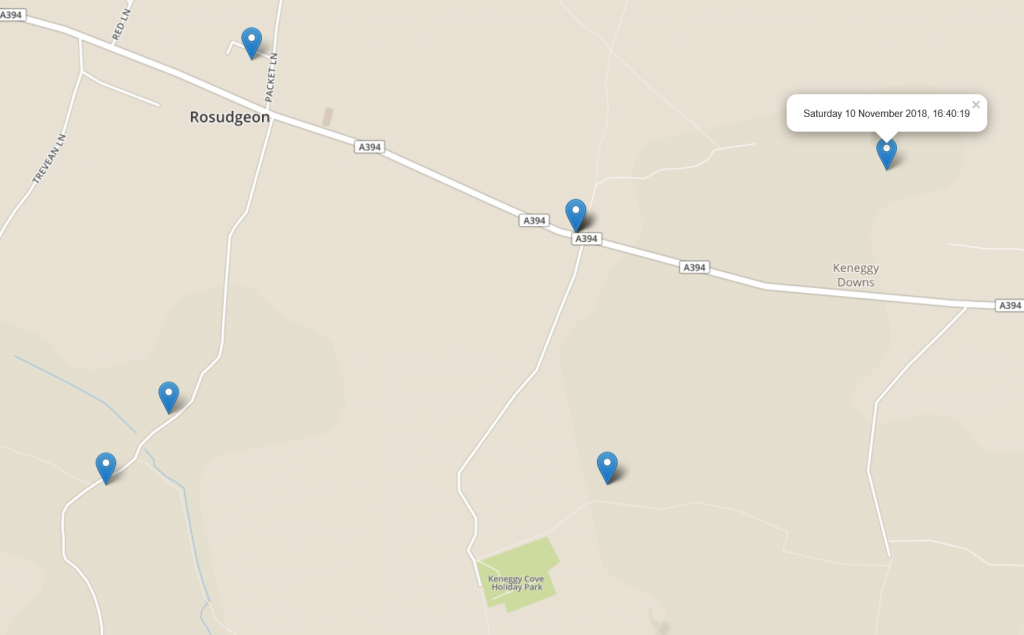


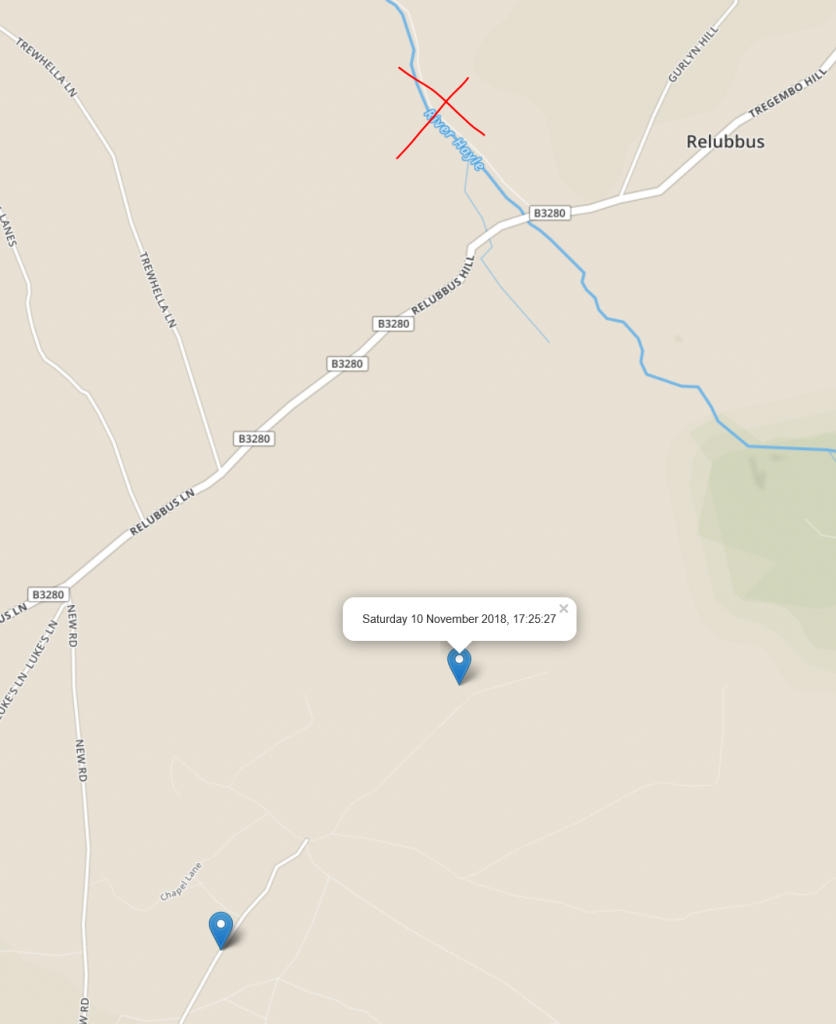











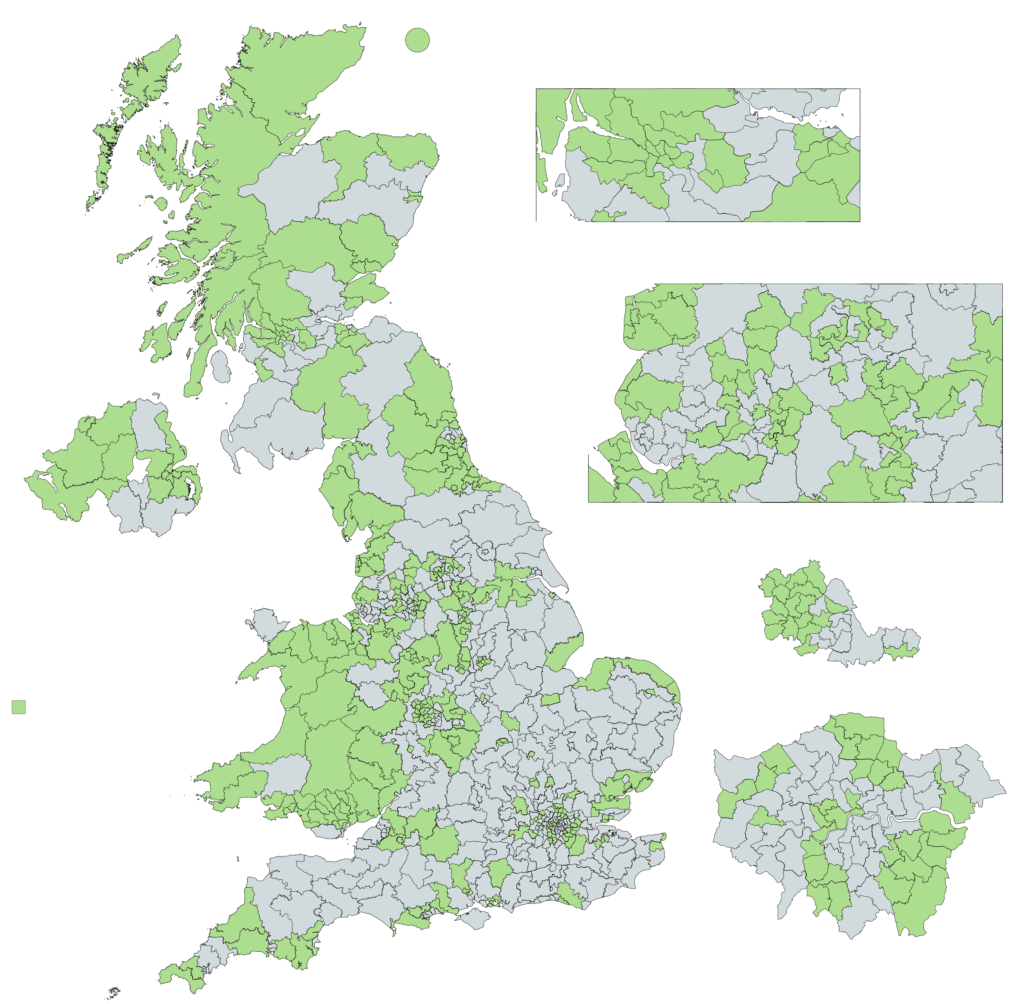
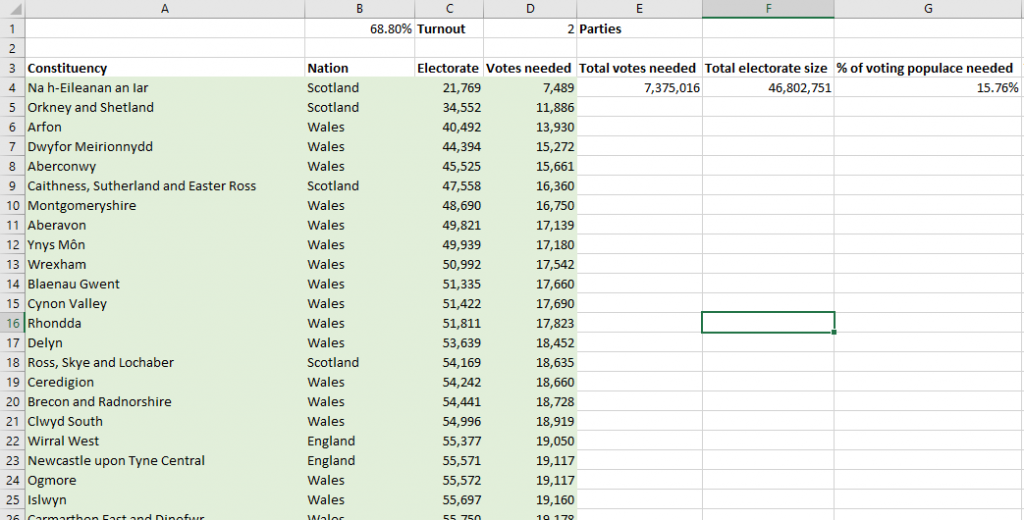




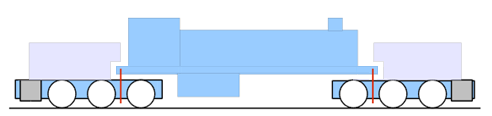




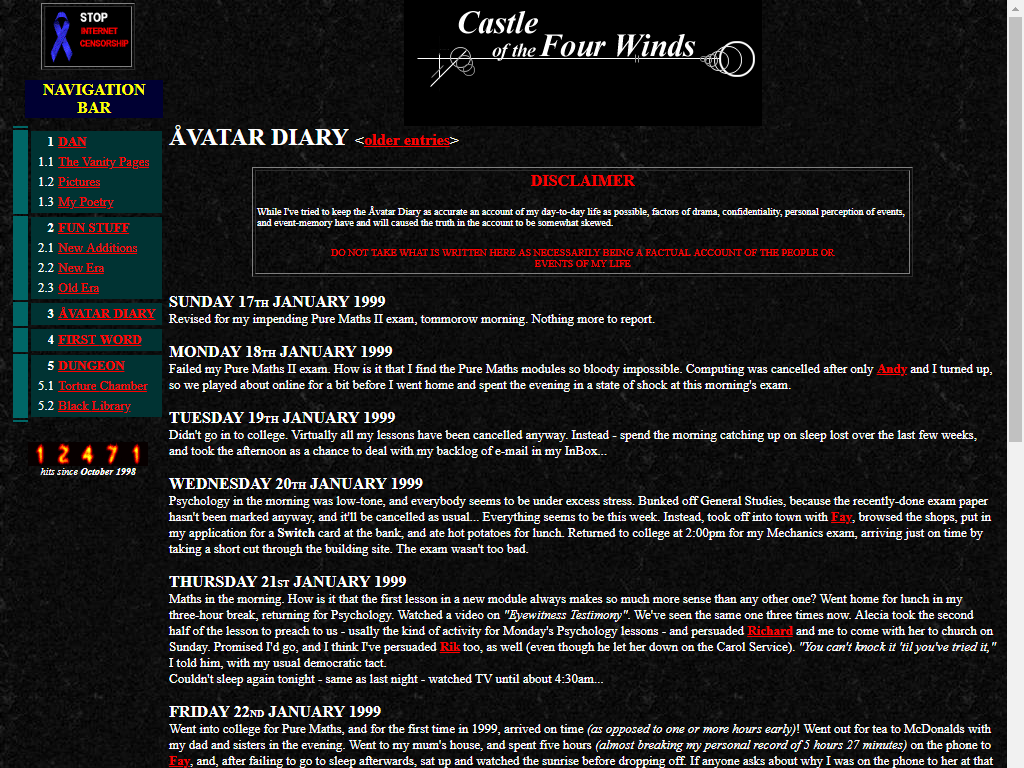

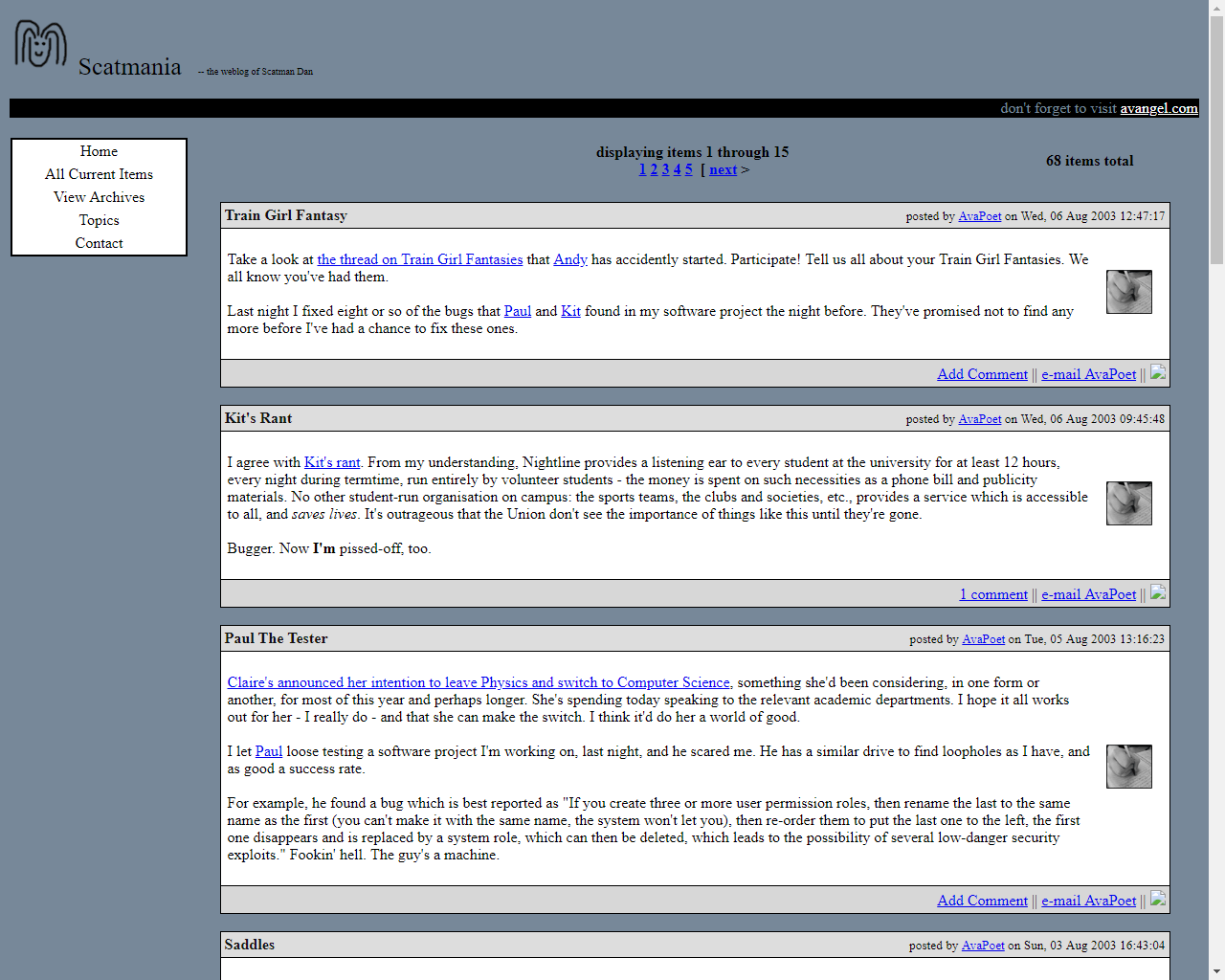
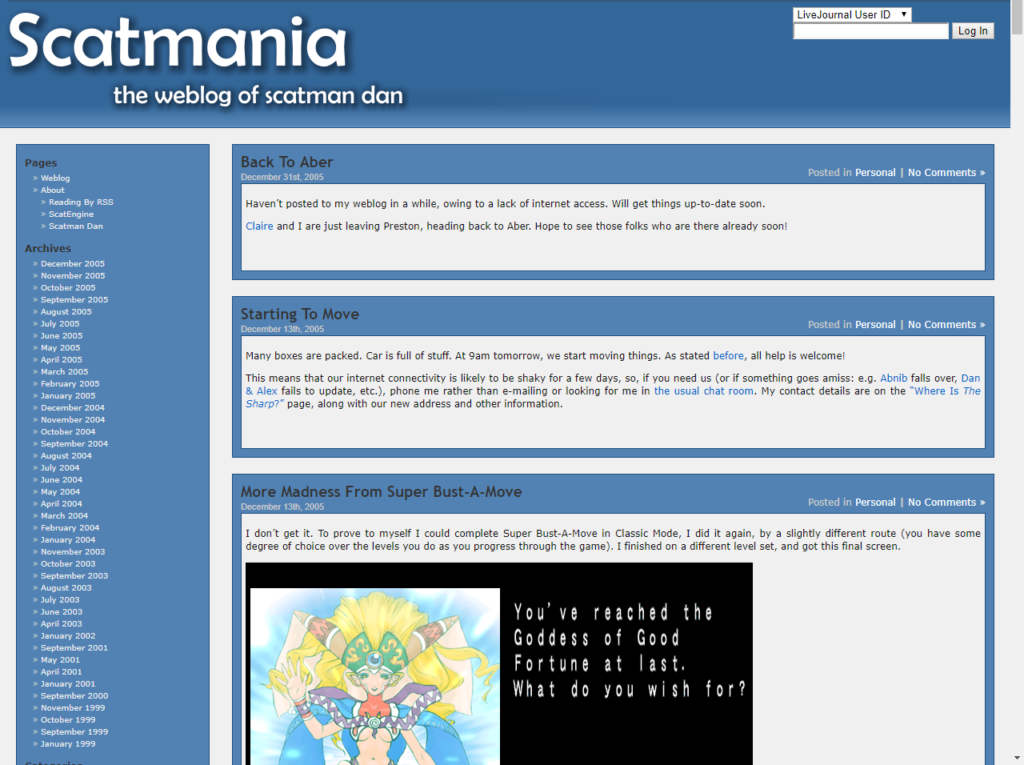
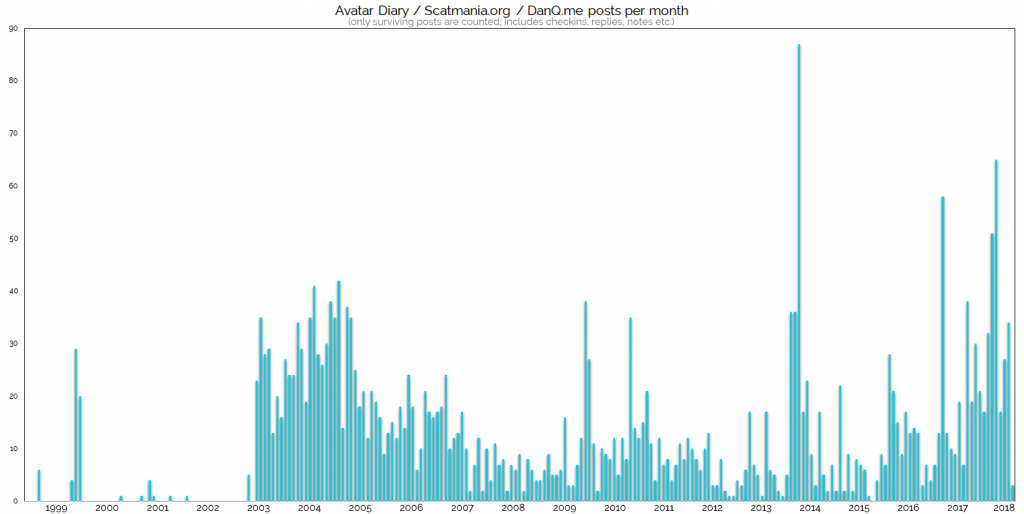




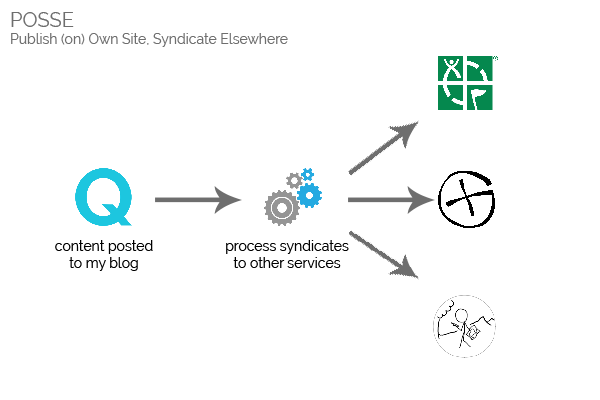
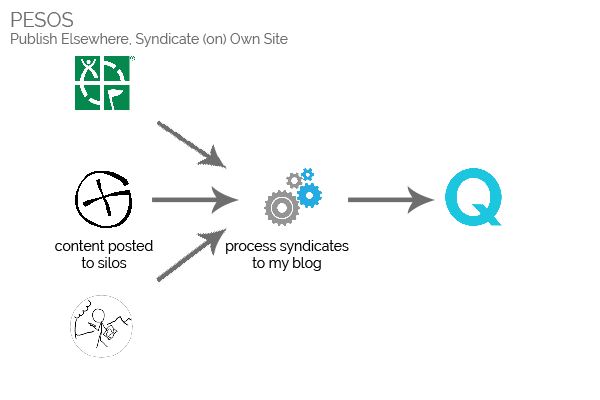
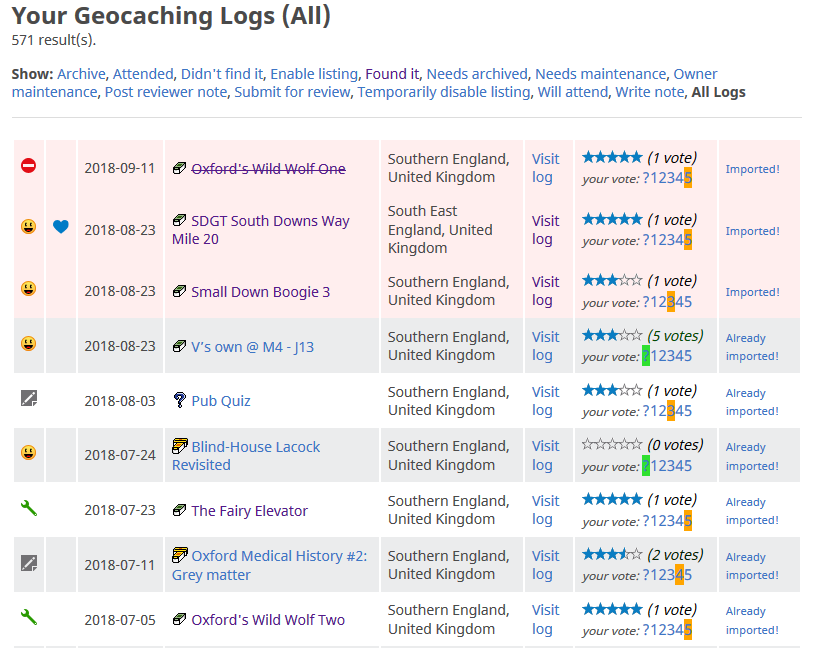
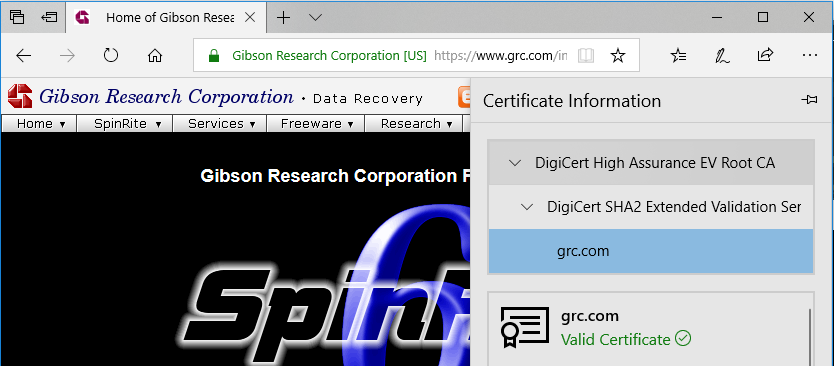
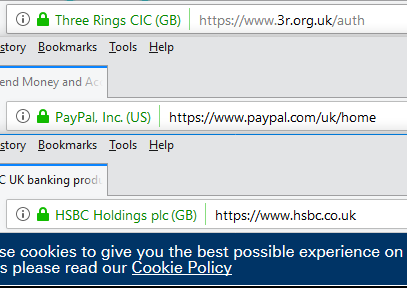
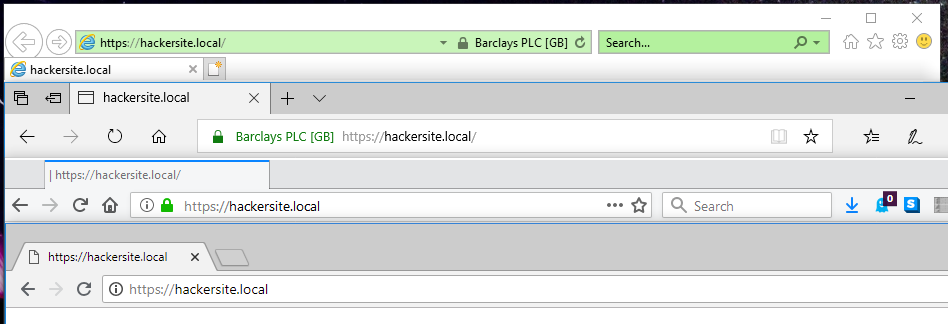
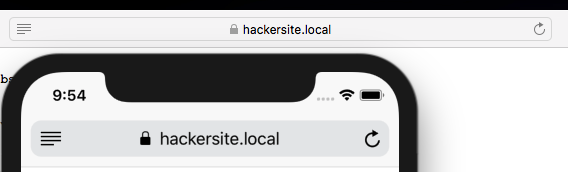





{kind=link}