As part of the preparing to leave the Bodleian I’ve been revisiting a lot of the documentation I’ve written over the last eight
years. It occurred to me that I’ve never written publicly about how the Bodleian’s digital signage/interactives actually work; there are possible lessons to learn.
The Bodleian‘s digital signage is perhaps more-diverse, both in terms of technology and audience, than that of most organisations. We’ve got
signs in areas that are exclusively reader-facing to help students and academics find what they’re looking for, signs in publicly accessible rooms that advertise and educate, and signs
in gallery spaces upon which we try to present engaging and often-interactive content to support exhibitions.
Getting an extra touchscreen for the office for prototyping/user testing purposes was great, even when it wasn’t showing MLP: FiM.
Throughout those three spheres, we’ve routinely delivered a diversity of content (let’s just ignore the countdown clock, for now…). Traditional
directional signage, advertisements, games, digital exhibitions, interpretation, feedback surveys…
In the vast majority of cases – and this is where the Bodleian’s been unusual (though certainly not unique) among cultural sector institutions – we’ve created
those in-house rather than outsourcing them.
Using off-the-shelf technology also allows the Bodleian to in-house much of their hardware maintenance, as a secondary part of other job roles. Singing into your screwdriver remains
optional, though.
To do this economically – the volume of work on interactive signage is inconsistent throughout the year – we needed to align the skills required with skills used elsewhere in the
organisation. To do this, we use the web as our medium! Collectively, the Bodleian’s Digital Communications team already had at least some experience in programming, web design, graphic
design, research, user testing, copyediting etc.: the essential toolkit for web application development.
Whether you were playing Pong on the video wall at the back or testing your Middle-earth knowledge on the touchscreen at the front… behind the
scenes you were interacting with a web page I wrote.
By shifting our digital signage platform to lean heavily on web technologies, we were able to leverage talented people we already had to produce things that we might otherwise
have had to outsource. This, in turn, meant that more exhibitions and displays get digital enhancement, on a shorter turnaround.
It also means that there’s a tighter integration between exhibition content and content for web and social media: it’s easier for us to re-use content across multiple platforms.
Sometimes we’ve even made our digital interactives, or adapted version of them, available directly online, allowing our exhibitions to reach people that can’t get to our physical spaces
at all.
Because we’re able to produce our own content on-demand, even our smaller, shorter-duration displays can have hands-on digital interactives associated with them.
On to the technology! We’re using a real mixture of tech: when it’s donated or reclaimed from previous projects (and when the bidding and acquisition processes are, well… as you’d
expect at the University of Oxford), you learn not to say no to freebies. Our fleet includes:
Samsung Android tablets with freestanding kiosk frames. We run the excellent-value Kiosk Browser Lockdown app on
these, which loads on boot and prevents access to anything but a specified website.
OnelanNTBs connected to a mixture of
touch and non-touch screens, wall-mounted or in kiosk frames. We use Onelan’s standard digital signage features as well as – for interactive content – their built-in touch-capable web
browser.
Dell PCs of the standard variety supplied by University IT services, connected to wall-mounted touch screens, running Google Chrome in Kiosk Mode. More on this below.
The browsers’ responsive simulators are invaluable when we’re targeting signage at five (!) different resolutions.
When you’re developing content for a very small number of browsers and a limited set of screen sizes, you quickly learn to throw a lot of “best practice” web development out of the
window. You’ll never come across a text browser or screen reader, so alt-text doesn’t matter. You’ll never have to rescale responsively, so you might as well absolutely-position almost
everything. The devices are all your own, so you never need to ask permission to store cookies. And because you control the platform, you can get away with making configuration tweaks
to e.g. allow autoplaying videos with audio. Coming from a conventional web developer background to producing digital signage content makes feels incredibly lazy.
Helping your users see your interactive as “app-like” rather than “web-like” encourages them to feel comfortable engaging with it in ways uncharacteristic of web pages. In our Shakespeare’s Dead interactive, for example, we started the experience in the middle of a long horizontally-scrolling “page”, which might
feel very unusual in a conventional browser.
Using Chrome to run digital signage requires, in the Bodleian’s case, a couple of configuration tweaks and the right command-line switches. We use:
chrome://flags/#overscroll-history-navigation – disabling this prevents users from triggering “back”/”forward” by swiping with two fingers
chrome://flags/#pull-to-refresh – disabling this prevents the user from triggering a “refresh” by scrolling up beyond the top of the page (this only happens on some
kinds of devices)
chrome://flags/#system-keyboard-lock – we don’t use attached keyboards, but if you do, you might want to set this flag so you can use the keyboard.lock()
API to intercept e.g. ALT+F4 so users can’t escape the application
running on startup with e.g. chrome --kiosk --noerrdialogs --allow-file-access-from-files --disable-touch-drag-drop --incognito https://example.com/some/url
Kisok mode makes the browser run fullscreen and prevents e.g. opening additional tabs, giving an instant “app-like” experience. As we don’t have keyboards attached to our
digital signage, this also prevents visitors from closing Chrome.
Turning off error dialogs reduces the risk that an error will result in an unslightly message to the user.
Enabling “file access from files” allows content hosted at file:// addresses to access content at other file:// addresses, which makes it possible to write “offline” sites
(sometimes useful where we’re serving large videos or on previous occasions when WiFi has been shaky) that can still take advantage of features like the Fetch API.
Unless you need drag-and-drop, it’s simpler to disable it; this prevents a user long-press-and-dragging an image around the screen.
Incognito mode ensures that the browser doesn’t remember what site was showing last time it ran; our computers often end up switched off at the wall at the end of the day, and
without this the browser will offer to load the site it had open last time, when it runs.
We usually host our interactives directly on the web, at “secret” addresses, and this is generally preferable to us as we can more-easily make on-the-fly adjustments to
content (plus it makes it easier to hook up analytic tools).
Be sure to test the capabilities of your hardware! Our Onelan NTBs, unlike your desktop PCs, can’t handle multitouch input, which
affects the design of our user interfaces for these devices.
Meanwhile, in the application’s CSS code, we set * { user-select: none; } to prevent the user from highlighting
text by selecting it with their finger. We also make heavy use of absolutely-sized/positioned, overflow: hidden blocks to ensure that scrollbars never appear, and
CSS animations to make content feel dynamic and to draw attention to particular elements.
There’s no substitute for good testing. And there’s no stress-testing quite like letting a 5 year-old loose on your work.
Altogether, this approach gives the Bodleian the capability to produce engaging interactive content at low cost and using the existing skills of their digital and exhibitions teams.
It’s not an approach that would work for every cultural institution: in particular, some of the Bodleian’s sister institutions already
outsource the technical parts of their web work, and so don’t have the expertise in-house to share with a web-powered digital signage solution.
A few minor CSS tweaks to make the buttons finger-friendly and our Halloween game Shadows Out Of
Time, which I’d already made web-friendly, was touchscreen-ready too. I wonder if they’ll get this one out again, this
Halloween?
But for those museums that can fit into this model – or can adapt to do so in future – using the web to produce interactive digital content and digital signage is a highly
cost-effective way to engage with visitors, even (or especially!) when dealing with short-lived and/or rotating displays.
It’s also been among my favourite parts of my job at the Bod these last 8½ years, and I’m sure I’ll miss it!
I wasn’t sure that my whiteboard at the Bodleian, which reminds my co-workers exactly how many days I’ve got left in the office, was
attracting as much attention as it needed to. If I don’t know what my colleagues don’t know about how I do my job, I can’t write it into my handover notes.
Tick, tick, tick, tick, boom.
So I repurposed a bit of digital signage in the office with a bit of Javascript to produce a live countdown. There’s a lot of code out there to produce countdown timers, but mine
had some very specific requirements that nothing else seems to “just do”. Mine needed to:
Only count down during days that I’m expected to be in the office.
Only count down during working hours.
Carry on seamlessly after a reboot.
[insert Countdown theme song here]
Naturally, I’ve open-sourced it in case anybody else needs one, ever. It’s pretty basic, of course,
because I’ve only got a hundred and fifty-something hours to finish a lot of things so I only wanted to throw a half hour at this while I ate my lunch! But if you want one,
just put in an array of your working dates, the time you start each day, and the number of hours in your workday, and it’ll tick away.
I recently announced that I’d accepted a job offer from Automattic and I’ll be
starting work there in October. As I first decided to apply for the job 128 days ago – a nice round number – I thought I’d share with you my journey over the
last 128 days.
Automattic conduct their entire interview process via Slack online chat. I’ve still never spoken to any of my new co-workers by phone, let alone seen them in person. This is both
amazing and terrifying.
Here’s my timeline so far:
Application (days -179 to -178)
Like many geeks, I keep a list of companies that I’ve fantasised about working for some day: mine includes the Mozilla Foundation and DuckDuckGo, for example, as well as Automattic Inc. In case it’s not obvious, I like companies that I feel make the Web a better place! Just out of
interest, I was taking a look at what was going on at each of them. My role at the Bodleian, I realised a while ago, is likely to evolve
into something different probably in the second-half of 2020 and I’d decided that when it does, that would probably be the point at which I should start looking for a new challenge.
What I’d intended to do on this day 128 days ago, which we’ll call “day -179”, was to flick through the careers pages of these and a few other companies, just to get a better
understanding of what kinds of skills they were looking for. I didn’t plan on applying for new jobs yet: that was a task for next-year-Dan.
I love working here, but over the last 8 years I feel like I’ve “solved” all of the most-interesting problems.
But then, during a deep-dive into the things that make Automattic unique (now best-explained perhaps by this episode of the Distributed podcast), something clicked for me. I’d loved the creed for as long as I’d known about it, but today was the day that I finally got it, I think. That was it: I’d drunk the Kool-Aid,
and it was time to send off an application.
I sat up past midnight on day -179, sending my application by email in the small hours of day -178. In addition to attaching a copy of my CV I wrote a little under 2,000 words about why I think I’m near-uniquely qualified to work for them: my experience of distributed/remote working with
SmartData and (especially) Three Rings, my determination to remain a multidisciplinary full-stack developer despite increasing pressure to “pick a side”, my contributions towards (and use, since almost its beginning of) WordPress, and of course the diverse portfolio of projects large and
small I’ve worked on over my last couple of decades as a software engineer.
VR experiments are among the more-unusual things I’ve worked on at the Bodleian (let’s not forget that, strictly, I’m a web developer).
At the time of my application (though no longer, as a result of changes aimed at improving
gender equality) the process also insisted that I include a “secret” in my application, which could be obtained by following some instructions and with only a modest
understanding of HTTP. It could probably be worked out even by a developer who didn’t, with a little of the kind of
research that’s pretty common when you’re working as a coder. This was a nice and simple filtering feature which I imagine helps to reduce the number of spurious applications that must
be read: cute, I thought.
Fun and simple, and yet an effective way to filter out the worst of the spurious applications.
I received an automated reply less that a minute later, and an invitation to a Slack-based initial interview about a day and a half after that. That felt like an incredibly-fast
turnaround, and I was quite impressed with the responsiveness of what must necessarily be a reasonably-complex filtering and process-management process… or perhaps my idea of what
counts as “fast” in HR has been warped by years in a relatively slow-moving and bureaucratic academic environment!
Initial Interview (day -158)
I’ve got experience on both sides of the interview table, and I maintain that there’s no single “right” way to recruit – all approaches suck in different ways – but the approaches used by companies like Automattic (and for
example Bytemark, who I’ve shared details of before) at least
show a willingness to explore, understand, and adopt a diversity of modern practices. Automattic’s recruitment process for developers is a five-step (or something like that) process, with the first two stages being the application and the initial interview.
My initial interview took place 20 days after my application: entirely over text-based chat on Slack, of course.
For all you know, your interviewer might be hanging out in the same cafe or co-working space as you. But they probably aren’t. Right?
The initial interview covered things like:
Basic/conversational questions: Why I’d applied to Automattic, what interested me about working for them, and my awareness of things that were going on at the company
at the moment.
Working style/soft skills: Questions about handling competing priorities in projects, supporting co-workers, preferred working and development styles, and the like.
Technical/implementation: How to realise particular ideas, how to go about debugging a specific problem and what the most-likely causes are, understanding
clients/audiences, comprehension of different kinds of stacks.
My questions/lightweight chat: I had the opportunity to ask questions of my own, and a number of mine probed my interviewer as an individual: I felt we’d “clicked”
over parts of our experience as developers, and I was keen to chat about some up-and-coming web technologies and compare our experiences of them! The whole interview felt about as
casual and friendly as an interview ever does, and my interviewer worked hard to put me at ease.
Skills Test (day -154)
At the end of the interview, I was immediately invited to the next stage: a “skills test”: I’d be given access to a private GitHub repository and a
briefing. In my case, I was given a partially-implemented WordPress plugin to work on: I was asked to –
add a little functionality and unit tests to demonstrate it,
improve performance of an existing feature,
perform a security audit on the entire thing,
answer a technical question about it (this question was the single closest thing to a “classic programmer test question” that I experienced), and
suggest improvements for the plugin’s underlying architecture.
I was asked to spend no more than six hours on the task, and I opted to schedule this as a block of time on a day -154: a day that I’d have otherwise been doing freelance work. An
alternative might have been to eat up a couple of my evenings, and I’m pretty sure my interviewer would have been fine with whatever way I chose to manage my time – after all, a
distributed workforce must by necessity be managed firstly by results, not by approach.
Scheduling my code test for a period when the kids were out of the house allowed me to avoid this kind of juggling act.
My amazingly-friendly “human wrangler” (HR rep), ever-present in my Slack channel and consistently full of encouragement and joy,
brought in an additional technical person who reviewed my code and provided feedback. He quite-rightly pulled me up on my coding standards (I hadn’t brushed-up on the code style guide), somewhat-monolithic commits, and a few theoretical error conditions that I hadn’t
accounted for, but praised the other parts of my work.
Most-importantly, he stated that he was happy to recommend that I be moved forward to the next stage: phew!
Trial (days -147 through -98)
Of all the things that make Automattic’s hiring process especially unusual and interesting, even among hip Silicon Valley(-ish, can a 100%
“distributed” company really be described in terms of its location?) startups, probably the most (in)famous is the trial contract. Starting from day -147, near the end of May, I was
hired by Automattic as a contractor, given a project and a 40-hour deadline, at $25 USD per hour within which to (effectively) prove myself.
As awesome as it is to be paid to interview with a company, what’s far more-important is the experience of working this way. Automattic’s an unusual company, using an
unusual workforce, in an unusual way: I’ve no doubt that many people simply aren’t a good fit for distributed working; at least not yet. (I’ve all kinds of thoughts about the
future of remote and distributed working based on my varied experience with which I’ll bore you another time.) Using an extended trial as an recruitment filter provides a level of
transparency that’s seen almost nowhere else. Let’s not forget that an interview is not just about a company finding the right employee for them but about a candidate finding the right
company for them, and a large part of that comes down to a workplace culture that’s hard to define; instead, it needs to be experienced.
For all that a traditional bricks-and-mortar employer might balk at the notion of having to pay a prospective candidate up to $1,000 only to then reject them, in addition to normal
recruitment costs, that’s a pittance compared to the costs of hiring the wrong candidate! And for a company with an unusual culture, the risks are multiplied: what if
you hire somebody who simply can’t hack the distributed lifestyle?
Page 1 of 6, all written in the USA dialect of legalese, but the important part is right there at the top: the job title is
“Trial Code Wrangler”. Yeah.
It was close to this point, though, that I realised that I’d made a terrible mistake. With an especially busy period at both the Bodleian and at Three Rings and deadlines
looming in my masters degree, as well as an imminent planned anniversary break with Ruth, this was
not the time to be taking on an additional piece of contract work! I spoke to my human wrangler and my technical supervisor in the Slack channel dedicated to that purpose and explained
that I’d be spreading my up-to-40-hours over a long period, and they were very understanding. In my case, I spent a total of 31½ hours over six-and-a-bit weeks working on a project
clearly selected to feel representative of the kinds of technical problems their developers face.
That’s reassuring to me: one of the single biggest arguments against using “trials” as a recruitment strategy is that they discriminate against candidates who, for whatever reason,
might be unable to spare the time for such an endeavour, which in turn disproportionately discriminates against candidates with roles caring for other (e.g. with children) or who
already work long hours. This is still a problem here, of course, but it is significantly mitigated by Automattic’s willingness to show significant flexibility with their candidates.
I was given wider Slack access, being “let loose” from the confines of my personal/interview channel and exposed to a handful of other communities. I was allowed to mingle amongst not
only the other developers on trial (they have their own channel!) but also other full-time staff. This proved useful – early on I had a technical question and (bravely) shouted out on
the relevant channel to get some tips! After every meaningful block of work I wrote up my progress via a P2 created for that purpose, and I shared my
checkins with my supervisors, cumulating at about the 20-hour mark in a pull request that I felt was not-perfect-but-okay…
I’m normally more of a command-line git users, but I actually really came to appreciate the GitHub Desktop diff interface while describing my commits during this project.
…and then watched it get torn to pieces in a code review.
Everything my supervisor said was fair, but firm. The technologies I was working with during my trial were ones on which I was rusty and, moreover, on which I hadn’t enjoyed the benefit
of a code review in many, many years. I’ve done a lot of work solo or as the only person in my team with experience of the languages I was working in, and I’d developed a lot
of bad habits. I made a second run at the pull request but still got shot down, having failed to cover all the requirements of the project (I’d misunderstood a big one, early on, and
hadn’t done a very good job of clarifying) and having used a particularly dirty hack to work-around a unit testing issue (in my defence I knew what I’d done there was bad, and my aim
was to seek support about the best place to find documentation that might help me solve it).
I felt deflated, but pressed on. My third attempt at a pull request was “accepted”, but my tech supervisor expressed concerns about the to-and-fro it had taken me to get there.
Finally, in early July (day -101), my interview team went away to deliberate about me. I genuinely couldn’t tell which way it would go, and I’ve never in my life been so nervous to hear
back about a job.
A large part of this is, of course, the high esteem in which I hold Automattic and the associated imposter syndrome I talked about
previously, which had only been reinforced by the talented and knowledgable folks there I’d gotten to speak to during my trial. Another part was seeing their recruitment standards
in action: having a shared space with other candidate developers meant that I could see other programmers who seemed, superficially, to be doing okay get eliminated from their
trials – reality TV style! – as we went along. And finally, there was the fact that this remained one of my list of “dream companies”:
if I didn’t cut it by this point in my career, would I ever?
Two days later, on day -99, I shared what felt like an appropriate My Little Pony: Friendship is Magic GIF with
the interview team via Slack.
It took 72 hours after the completion of my trial before I heard back.
I was to be recommended for hire.
On day -98 I literally jumped for joy. This was a hugely exciting moment.
It was late in the day, but not too late to pour myself a congratulatory Caol Ila.
OMGOMGOMGOMG.
Final Interview (day -94)
A lot of blog posts about getting recruited by Automattic talk about the final interview being with CEO Matt Mullenweg himself, which I’d always thought must be an unsustainable use of his time once you get into the multiple-hundreds of employees. It looks like I’m
not the only one who thought this, because somewhere along the line the policy seems to have changed and my final interview was instead with a human wrangler (another
super-friendly one!).
That was a slightly-disappointing twist, because I’ve been a stalker fanboy of Matt’s for almost 15 years… but I’ll probably get to meet him at some point or other now
anyway. Plus, this way seems way-more logical: despite Matt’s claims to the contrary, it’s hard to see Automattic as a “startup” any longer (by age alone: they’re two years
older than Twitter and a similar age to Facebook).
The final interview felt mostly procedural: How did I find the process? Am I willing to travel for work? What could have been done differently/better?
Conveniently, I’d been so enthralled by the exotic hiring process that I’d kept copious notes throughout the process, and – appreciating the potential value of honest, contemporaneous
feedback – made a point of sharing them with the Human League (that’s genuinely what Automattic’s HR department are called, I kid you
not) before the decision was announced as to whether or not I was to be hired… but as close as possible to it, so that it could not influence it. My thinking was this: this
way, my report couldn’t help but be honest and unbiased by the result of the process. Running an unusual recruitment strategy like theirs, I figured, makes it harder to get
honest and immediate feedback: you don’t get any body language cues from your candidates, for a start. I knew that if it were my company, I’d want to know how it was working
not only from those I hired (who’d be biased in favour it it) and from those who were rejected (who’d be biased against it and less-likely to be willing to provide in-depth feedback in
general).
I guess I wanted to “give back” to Automattic regardless of the result: I learned a lot about myself during the process and especially during the trial, and I was grateful for
it!
Show me the money!
One part of the final interview, though, was particularly challenging for me, even though my research had lead me to anticipate it. I’m talking about the big question that
basically every US tech firm asks but only a minority of British ones do: what are your salary expectations?
As a Brit, that’s a fundamentally awkward question… I guess that we somehow integrated a feudalistic class system into a genetic code: we don’t expect our lords to pay us
peasants, just to leave us with enough grain for the winter after the tithes are in and to protect us from the bandits from the next county over, right? Also: I’ve known for a long
while that I’m chronically underpaid in my current role. The University of Oxford is a great employer in many ways but if you stay with them for any length of time then it has to be for
love of their culture and their people, not for the money (indeed: it’s love of my work and colleagues that kept me there for the 8+ years I
was!).
I’m pretty sure that most Brits are at least a little uncomfortable, even, when Dennis gives lip to King Arthur in Monty Python and the Holy Grail.
Were this an in-person interview, I’d have mumbled and shuffled my feet: you know, the British way. But luckily, Slack made it easy at least for me to instead awkwardly copy-paste some
research I’d done on StackOverflow, without which, I wouldn’t have had a clue what I’m allegedly-worth! My human wrangler took my garbled nonsense away to do some internal
research of her own and came back three hours later with an offer. Automattic’s offer was very fair to the extent that I was glad to have somewhere to sit down and process it
before responding (shh… nobody tell them that I am more motivated by impact than money!): I hadn’t been
emotionally prepared for the possibility that they might haggle upwards.
Three months on from writing my application, via the longest, most self-reflective, most intense, most interesting recruitment process I’ve ever experienced… I had a contract awaiting
my signature. And I was sitting on the edge of the bath, trying to explain to my five year-old why I’d suddenly gone weak at the knees.
I wanted to insert another picture of the outside of my office at the Bodleian here, but a search of my photo library gave me this one and it was too adorable to not-share.
Getting Access (day -63)
A month later – a couple of weeks ago, and a month into my three-month notice period at the Bodleian – I started getting access to Auttomatic’s computer systems. The ramp-up to getting
started seems to come in waves as each internal process kicks off, and this was the moment that I got the chance to introduce myself to my team-to-be.
I can see my team… and they can see me? /nervous wave/
I’d been spending occasional evenings reading bits of the Automattic Field Guide – sort-of a living staff handbook for Automatticians – and this was the moment when I discovered that a
lot of the links I’d previously been unable to follow had suddenly started working. You remember that bit in $yourFavouriteHackerMovie where suddenly the screen
flashes up “access granted”, probably in a green terminal font or else in the centre of a geometric shape and invariably accompanied by a computerised voice? It felt like that. I still
couldn’t see everything – crucially, I still couldn’t see the plans my new colleagues were making for a team meetup in South Africa and had to rely on Slack chats with my new
line manager to work out where in the world I’d be come November! – but I was getting there.
Getting Ready (day -51)
The Human League gave me a checklist of things to start doing before I started, like getting bank account details to the finance department. (Nobody’s been able to confirm nor denied
this for me yet, but I’m willing to bet that, if programmers are Code Wranglers, devops are Systems Wranglers, and HR are Human
Wranglers, then the finance team must refer to themselves as Money Wranglers, right?)
They also encouraged me to get set up on their email, expenses, and travel booking systems, and they gave me the password to put an order proposal in on their computer hardware ordering
system. They also made sure I’d run through their Conflict of Interest checks, which I’d done early on because for various reasons I was in a more-complicated-than-most position.
(Incidentally, I’ve checked and the legal team definitely don’t call themselves Law Wranglers, but that’s probably because lawyers understand that Words Have Power and must be
used correctly, in their field!)
Wait wait wait… let me get this straight… you’ve never met me nor spoken to me on the phone and you’re willing to post a high-end dev box to me? A month and a half before I
start working for you?
So that’s what I did this week, on day -51 of my employment with Automattic. I threw a couple of hours at setting up all the things I’d need set-up before day 0, nice and early.
I’m not saying that I’m counting down the days until I get to start working with this amazing, wildly-eccentric, offbeat, world-changing bunch… but I’m not not saying that,
either.
Yesterday I recommended that you go read Aaron Uglum‘s webcomic LABS which had just completed its final strip. I’m a big fan of “completed”
webcomics – they feel binge-able in the same way as a complete Netflix series does! – but Spencer quickly pointed out that it’s annoying
for we enlightened modern RSS users who hook RSS up to everything to have to binge completed comics in a different way to reading ongoing ones: what he wanted was an RSS feed covering the entire history of LABS.
With apologies to Aaron Uglum who I hope won’t mind me adapting his comic in this way.
So naturally (after the intense heatwave woke me early this morning anyway) I made one: complete RSS feed of
LABS. And, of course, I open-sourced the code I used to generate it so that others can jumpstart their
projects to make static RSS feeds from completed webcomics, too.
Even if you’re not going to read it via this medium, you should go read LABS.
In October of this year – after eight years, six months, and five days with the Bodleian Libraries – I’ll be leaving for pastures new. Owing to a
combination of my current work schedule, holidays, childcare commitments and conferences, I’ve got fewer than 29 days left in the office.
I’ve been keeping a countdown on my whiteboard to remind my colleagues to hurry up and ask me anything they need in order to survive in my absence.
Instead, I’ll be starting work with Automattic Inc.. You might not have heard of them, but you’ve definitely used some of their
products, either directly or indirectly. Ever hear of WordPress.com, WooCommerce, Gravatar or Longreads? Yeah; that’s the guys.
It’s a gear stick. For an automatic car. ‘Cos I’m “shifting into Automattic”. D’you get it? Do you? Do you?
I’m filled with a mixture of joyous excitement and mild trepidation. It’s mostly the former, thankfully, but there’s still a little nervousness there too. Mostly it’s a kind of imposter syndrome, I guess: Automattic have for many, many years been on my “list of companies I’d love to work for, someday”, and
the nature of their organisation means that they have their pick of many of the smartest and most-talented geeks in the world. How do I measure up?
During my final months I’m taking the opportunity to explore bits of the libraries I’ve not been to before. Y’know, before they revoke my keycard.
It’s funny: early in my career, I never had any issue of imposter syndrome. I guess that when I was young and still thought I knew everything – fuelled by a little talent and a lot of
good fortune in getting a head-start on my peers – I couldn’t yet conceive of how much further I had to go. It took until I was well-established in my industry before I could begin to
know quite how much I didn’t know. I’d like to think that the second decade of my work as a developer has been dominated by unlearning all of the things that I did wrong, while flying
by the seat of my pants, in the first decade.
I’ll be mostly remote-working for Automattic, so I can guarantee that my office won’t be as pretty as my one at the Bod was. Far fewer Muses on the roof, too.
I’m sure I’ll have lots more to share about my post-Bodleian life in due course, but for now I’ve got lots of projects to wrap up and a job description to rewrite (I’m recommending that
I’m not replaced “like-for-like”, and in any case: my job description at the Bodleian does not lately describe even-remotely what I actually do), and a lot of documentation to
bring up-to-date. Perhaps then this upcoming change will feel “real”.
With IndieWebCamp Oxford 2019 scheduled to take place during the
Summer of Hacks, I drew a diagram (click to embiggen) of the current ecosystem that powers and propogates the
content on DanQ.me. It’s mostly for my own benefit – to be able to get a big-picture view of the ways my website talks to the world and plan for what improvements I
might be able to make in the future… but it also works as a vehicle to explain what my personal corner of the IndieWeb does and how it does it.
Here’s a summary:
DanQ.me
Since fifteen years ago today, DanQ.me has been powered by a self-hosted WordPress installation. I
know that WordPress isn’t “hip” on the IndieWeb this week and that if you’re not on the JAMstack you’re yesterday’s news, but at 15 years and counting my
love affair with WordPress has lasted longer than any romantic relationship I’ve ever had with another human being, so I’m sticking with it. What’s cool in Web technologies comes and
goes, but what’s important is solid, dependable tools that do what you need them to, and between WordPress, half a dozen off-the-shelf plugins and about a dozen homemade ones I’ve got
everything I need right here.
I’d been “blogging” – not that we called it that, yet – since late 1998, but my original collection of content-mangling Perl scripts wasn’t all that. More history…
I write articles (long posts like this) and notes (short, “tweet-like” updates) directly into the site, and just occasionally
other kinds of content. But for the most part, different kinds of content come from different parts of the ecosystem, as described below.
RSS reader
DanQ.me sits at the centre of the diagram, but it’s worth remembering that the diagram is deliberately incomplete: it only contains information flows directly relevant to my blog (and
it doesn’t even contain all of those!). The last time I tried to draw a diagram like this that described my online life in general, then my RSS reader found its way to the centre. Which figures: my RSS reader is usually the first
and often the last place I visit on the Internet, and I’ve worked hard to funnel everything through it.
129 unread items is a reasonable-sized queue: I try to process to “RSS zero”, but there are invariably things I want to return to on a second-pass and I’ve not yet reimplemented the
“snooze button” I added to my previous RSS reader.
Right now I’m using FreshRSS – plus a handful of plugins, including some homemade ones – as my RSS reader: I switched from Tiny Tiny RSS about a year ago to take advantage of FreshRSS’s excellent responsive
themes, among other features. Because some websites don’t have RSS feeds, even where they ought to, I use my own tool
RSSey to retroactively “fix” people’s websites for them, dynamically adding feeds for my
consumption. It’s also a nice reminder that open source and remixability were cornerstones of the original Web. My RSS reader
collates information from a variety of sources and additionally gives me a one-click mechanism to push content I enjoy to my blog as a repost.
QTube
QTube is my video hosting platform; it’s a PeerTube node. If you haven’t seen it, that’s fine: most content
on it is consumed indirectly either through my YouTube channel or directly on my blog as posts of the “video” kind. Also, I don’t actually vlog very often. When I do publish videos onto QTube, their republication onto YouTube or DanQ.me is optional: sometimes I plan to
use a video inside an article post, for example, and so don’t need to republish it by itself.
I’m gradually exporting or re-uploading my backlog of YouTube videos from my current and previous channels to QTube in an effort to
recentralise and regain control over their hosting, but I’m in no real hurry. PeerTube certainly makes it easy, though!
Link Shortener
I operate a private link shortener which I mostly use for the expected purpose: to make links shorter and so easier to read out and memorise or else to make them take up less space in a
chat window. But soon after I set it up, many years ago, I realised that it could also act as a mechanism to push content to my RSS reader to “read later”. And by the time I’m using it for that, I figured, I might as well also be using it to repost content to my blog
from sources that aren’t things my RSS reader subscribes to. This leads to a process that’s perhaps unnecessarily
complex: if I want to share a link with you as a repost, I’ll push it into my link shortener and mark it as going “to me”, then I’ll tell my RSS reader to push it to my blog and there it’ll be published to the world! But it works and it’s fast enough: I’m not in the habit
of reposting things that are time-critical anyway.
Checkins
You know your sport is fringe when you need to reference another fringe sport to describe it. “Geohashing? It’s… a little like geocaching, but…”
I’ve been involved in brainstorming ways in which the act of finding (or failing to find, etc.) a geocache or reaching (or failing to
reach) a geohashpoint could best be represented as a “checkin“, and last year I open-sourced my plugin for pulling logs (with as much automation as is permitted by the terms of service of some of the
silos involved) from geocaching websites and posting them to WordPress blogs: effectively PESOS-for-geocaching. I’d prefer to be publishing on my own blog in the first instance, but syndicating my adventures from various
silos into my blog is “good enough”.
Syndication
New notes get pushed out to my Twitter account, for the benefit of my Twitter-using friends. Articles get advertised on Facebook, Twitter and LiveJournal (yes, really) in teaser form, for the benefit of friends
who prefer to get notifications via those platforms. Facebook have been fucking around with their APIs and terms of
service lately and this is now less-automatic than it used to be, which is a bit of an annoyance. My RSS feeds carry copies
of content out to people who prefer to subscribe via that medium, and I’ve also been using this to power an experimental MailChimp “daily digest” mailing list of “what Dan’s been up to”
to a small number of friends, right in their email inboxes: I’ve not made it available to everybody yet, but if you’re happy to help test it then give me a shout
and I’ll hook you up.
Most days don’t see an email sent or see an email with only one item, but some days – like this one – are busier. I still need to update the brand colours here, too!
Finally, a couple of IFTTT recipes push my articles and my reposts to Reddit communities: I don’t
really use Reddit myself, any more, but I’ve got friends in a few places there who prefer to keep up-to-date with what I’m up to via that medium. For historical reasons, my reposts to
Reddit don’t go directly via my blog’s RSS feeds but “shortcut” directly from my RSS reader: this is suboptimal because I don’t get to tweak post titles for Reddit but it’s not a big deal.
What IFTTT does isn’t magic, but it’s often indistinguishable from it.
I used to syndicate content to Google+ (before it joined the long list of Things Google Have Killed) and to Ello
(but it never got much traction there). I’ve probably historically syndicated to other places too: I’ve certainly manually-republished content to other blogs, from time to time, too.
I use Ryan Barrett‘s excellent Brid.gy to convert Twitter replies and likes back into Webmentions for publication as comments on my blog. This used to work for Facebook, too, but again: Facebook
fucked it over. I’ve occasionally manually backfed significant Facebook comments, but it’s not ideal: I might like to look at using similar technologies to RSSey to subvert
Facebook’s limitations.
I’ve never had a need for Brid.gy’s “publishing” (i.e. POSSE) features, but its backfeed features “just work”, and it’s awesome.
Reintegration
I’ve routinely retroactively reintegrated content that I’ve produced elsewhere on the Web. This includes my previous blogs (which is why you can browse my archives, right here on this
site, all the way back to some of the cringeworthy angsty-teenager posts I made in the 1990s) but also some Reddit posts,
some replies originally posted directly to other people’s blogs, all my old del.icio.us bookmarks, long-form forum
posts, posts I made to mailing lists and newsgroups, and more. As a result, there’s a lot of backdated content on this site, nowadays: almost a million words, and significantly
more than the 600,000 or so I counted a few years ago, before my biggest push for reintegration!
Cumulative wordcount per day, by content type. The lion’s share has always been articles, but reposts are creeping up as I’ve been writing more about the things I reshare, lately.
It’d be interesting to graph the differentiation of this chart to see the periods of my life that I was writing the most: I have a hypothesis, and centralising my own content under my
control makes it easier
Why do I do this? Because I really, really like owning my identity online! I’ve tried the “big” silo alternatives like Facebook, Twitter, Medium, Instagram etc., and they’ve eventually
always lead to disappointment, either because they get shut down or otherwise made-unusable, because
of inappropriately-applied “real names” policies, because they give too much power to
untrustworthy companies, because they impose arbitrary limitations on my content, because they manipulate output
promotion (and exacerbate filter bubbles), or because they make the walls of their walled gardens taller and stop you integrating with them how you used to.
A handful of silos have shown themselves to be more-trustworthy than the average – in particular, eschewing techniques that promote “lock-in” – and I’d love to tell you more about them
and what I think you should look for in a silo, another time. But for now: suffice to say that just like I don’t use YouTube like most people do, I
elect not to use Facebook or Twitter in the conventional ways either. And it’s awesome, thanks.
There are plenty of reasons that people choose to take control of their own Web presence – and everybody who puts content online ought to consider
it – but I imagine that few individuals have such a complicated publishing ecosystem as I do! Now you’ve got a picture of how my digital content production workflow works, and
perhaps start owning your online identity, too.
We might never have been very good at keeping track of the exact date our relationship began in Edinburgh twelve years ago, but that doesn’t
stop Ruth and I from celebrating it, often with a trip away very-approximately in the summer. This year, we marked the occasion with a return to Scotland, cycling our way around and between Glasgow and Edinburgh.
We got rained on quite a lot, early in our trip, but that didn’t slow our exploration.
Even sharing a lightweight conventional bike and a powerful e-bike, travelling under your own steam makes you pack lightly. We were able to get everything we needed – including packing
for the diversity of weather we’d been told to expect – in a couple of pannier bags and a backpack, and pedalled our way down to Oxford Parkway station to start our journey.
And because we’re oh-so-classy when we go on an anniversary break, I brought a four-pack for us to drink while we waited for the train.
In anticipation of our trip and as a gift to me, Ruth had arranged for tickets on the Caledonian Sleeper train from London
to Glasgow and returning from Edinburgh to London to bookend our adventure. A previous sleeper train ticket she’d purchased, for Robin as part of
Challenge Robin II, had lead to enormous difficulties when the train got cancelled… but how often can sleeper trains get cancelled, anyway?
Well this can’t be good.
Turns out… more-often than you’d think. We cycled across London and got to Euston Station just in time to order dinner and pour a glass of wine before we received an email to let
us know that our train had been cancelled.
Station staff advised us that instead of a nice fast train full of beds they’d arranged for a grotty slow bus full of disappointment. It took quite a bit of standing-around and waiting
to speak to the right people before anybody could even confirm that we’d be able to stow our bikes on the bus, without which our plans would have been completely scuppered. Not a great
start!
Hey look, a bag full of apologies in the form of snacks.
Eight uncomfortable hours of tedious motorway (and the opportunity to wave at Oxford as we went back past it) and two service stations later, we finally reached Glasgow.
Despite being tired and in spite of the threatening stormclouds gathering above, we pushed on with our plans to explore Glasgow. We opted to put our trust into random exploration –
aided by responses to weirdly-phrased questions to Google Assistant about what we should see or do – to deliver us serendipitous discoveries, and this plan worked well for us. Glasgow’s
network of cycle paths and routes seems to be effectively-managed and sprawls across the city, and getting around was incredibly easy (although it’s hilly enough that I found plenty of
opportunities to require the lowest gears my bike could offer).
Nothing else yet being open in Glasgow, we started our journey where many tens of thousands of Victorian-era Glaswegians finished theirs.
We kicked off by marvelling at the extravagance of the memorials at Glasgow Necropolis, a sprawling 19th-century cemetery covering an
entire hill near the city’s cathedral. Especially towards the top of the hill the crypts and monuments give the impression that the dead were competing as to who could leave the
most-conspicuous marker behind, but there are gems of subtler and more-attractive Gothic architecture to be seen, too. Finding a convenient nearby geocache completed the experience.
I learned that Wee Willie Winkie wasn’t the anonymously-authored folk rhyme that I’d assumed but was written by
a man called William Miller. Who knew?
Pushing on, we headed downriver in search of further adventure… and breakfast. The latter was provided by the delightful Meat Up Deli, who make a spectacularly-good omelette. There, in
the shadow of Partick Station, Ruth expressed surprise at the prevalence of railway stations in Glasgow; she, like many folks, hadn’t known that Glasgow is served by an underground train network, But I too would get to learn things I hadn’t known about the subway at our next destination.
The River Clyde is served by an excellent cycle path and runs through the former industrial heart of the city.
We visited the Riverside Museum, whose exhibitions are dedicated to the history of transport and industry,
with a strong local focus. It’s a terrifically-engaging museum which does a better-than-usual job of bringing history to life through carefully-constructed experiences. We spent much of
the time remarking on how much the kids would love it… but then remembering that the fact that we were able to enjoy stopping and read the interpretative signage and not just have to
sprint around after the tiny terrors was mostly thanks to their absence! It’s worth visiting twice, if we find ourselves up here in future with the little tykes.
“Coronation” Tram #1173 was worth a visit, but – as my smile shows – huge tram-fan Ruth had made me board a lot of restored trams by this point. And yes, observant reader: I
am still wearing yesterday’s t-shirt, having been so-far unable to find somewhere sensible to change since the motorway journey.
It’s also where I learned something new about the Glasgow Subway: its original implementation – in effect until 1935 – was cable-driven! A steam engine on the South side of the circular
network drove a pair of cables – one clockwise, one anticlockwise, each 6½ miles long – around the loop, between the tracks. To start the train, a driver would pull a lever which would
cause a clamp to “grab” the continuously-running cable (gently, to prevent jerking forwards!); to stop, he’d release the clamp and apply the brakes. This solution resulted in
mechanically-simple subway trains: the system’s similar to that used for some of the surviving parts of San Franciso’s original tram network.
We noticed “no spitting” signs all over all of the replica public transport at the museum. Turns out Glasgow had perhaps the worst tuberculosis outbreak in the UK, so encouraging
people to keep their fluids to themselves was a big deal.
Equally impressive as the Riverside Museum is The Tall Ship accompanying it, comprising the barque Glenlee converted into a floating museum about
itself and about the maritime history of its age.
I tried my hand at being helmsman of the Glenlee, but the staff wouldn’t let me unmoor her from the dock so we didn’t get very far. Also, I have no idea how to sail a ship. I can
capsize a windsurfer; that’s got to be similar, right?
This, again, was an incredibly well-managed bit of culture, with virtually the entire ship accessible to visitors, right down into the hold and engine room, and with a great amount of
effort put into producing an engaging experience supported by a mixture of interactive replicas (Ruth particularly enjoyed loading cargo into a hoist, which I’m pretty sure was designed
for children), video, audio, historical sets, contemporary accounts, and all the workings of a real, functional sailing vessel.
Plus, you can ring the ship’s bell!
After lunch at the museum’s cafe, we doubled-back along the dockside to a distillery we’d spotted on the way past. The Clydeside Distillery
is a relative newcomer to the world of whisky – starting in 2017, their first casks are still several years’ aging away from being ready for consumption, but that’s not stopping them
from performing tours covering the history of their building (it’s an old pumphouse that used to operate the swingbridge over the now-filled-in Queen’s Dock) and distillery, cumulating
in a whisky tasting session (although not yet including their own single malt, of course).
“Still” working on the finished product.
This was the first time Ruth and I had attended a professionally-organised whisky-tasting together since 2012, when we did so not once
but twice in the same week. Fortunately, it turns out that we hadn’t forgotten how to drink whisky; we’d both kept our hand in in the meantime.
<hic> Oh, and we got to keep our tasting-glasses as souvenirs, which was a nice touch.
Thus far we’d been lucky that the rain had mostly held-off, at least while we’d been outdoors. But as we wrapped up in Glasgow and began our cycle ride down the towpath of the Forth & Clyde Canal, the weather turned quickly through bleak to ugly to downright atrocious. The amber flood warning we’d been given gave way to what forecasters and the media called a “weather bomb”: an hours-long torrential downpour that limited visibility and soaked everything
left out in it.
You know: things like us.
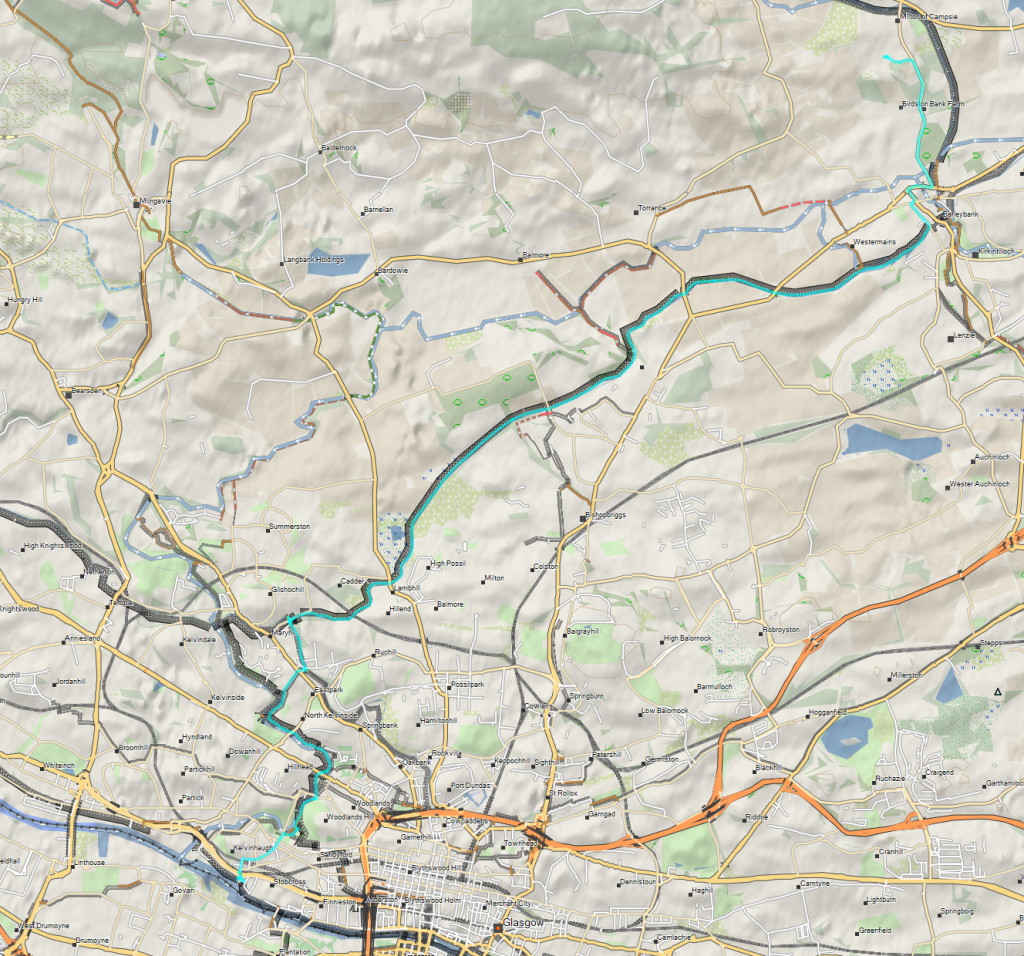
Our journey from Glasgow took us along the Forth & Clyde Canal towpath to Milton of Campsie, near Kirkintilloch. Download GPX tracklog.
Our bags held up against the storm, thankfully, but despite an allegedly-waterproof covering Ruth and I both got thoroughly drenched. By the time we reached our destination of Kincaid House Hotel we were both exhausted (not helped by a lack of sleep the previous night during our rail-replacement-bus journey) and soaking wet
right through to our skin. My boots squelched with every step as we shuffled uncomfortably like drowned rats into a hotel foyer way too-fancy for bedraggled waifs like us.
I don’t have any photos from this leg of the journey because it was too wet to use a camera. Just imagine a picture of me underwater and you’ll get the idea. Instead, then, here’s a
photo of my boots drying on a radiator.
We didn’t even have the energy to make it down to dinner, instead having room service delivered to the room while we took turns at warming up with the help of a piping hot bath. If I
can sing the praises of Kincaid House in just one way, though, it’s that the food provided by room service was absolutely on-par with what I’d expect from their restaurant: none of the
half-hearted approach I’ve experienced elsewhere to guests who happen to be too knackered (and in my case: lacking appropriate footwear that’s not filled with water) to drag themselves
to a meal.
When we finally got to see it outside of the pouring rain, it turns out that the hotel was quite pretty. Our room is in the top right (including a nook extending into the turret). If
you look closely you’ll see that the third, fifth, and seventh windows on the upper floor are fake: they cover areas that have since their original construction been converted to
en suite bathrooms.
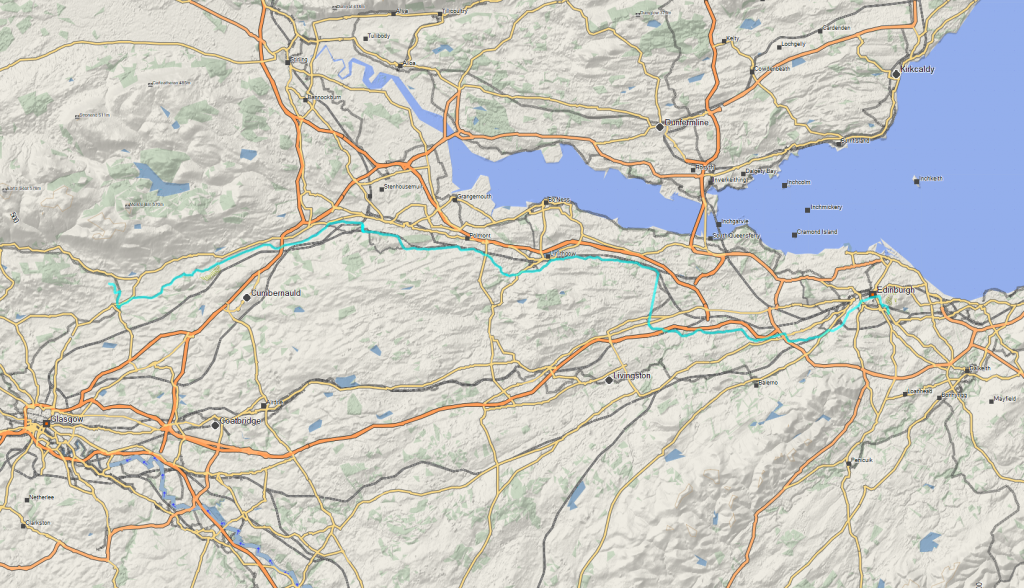
Our second day of cycling was to be our longest, covering the 87½ km (54½ mile) stretch of riverside and towpath between Milton of Campsie and our next night’s accommodation on the
South side of Edinburgh. We were wonderfully relieved to discover that the previous day’s epic dump of rain had used-up the clouds’ supply in a single day and the forecast was far more
agreeable: cycling 55 miles during a downpour did not sound like a fun idea for either of us!
The longest day’s cycling of our trip had intimidated me right from the planning stage, but a steady pace – and an improvement in the weather – put it well within our grasp. Download GPX tracklog.
Kicking off by following the Strathkelvin Railway Path, Ruth and I were able to enjoy verdant
countryside alongside a beautiful brook. The signs of the area’s industrial past are increasingly well-concealed – a rotting fence made of old railway sleepers here; the remains of a
long-dead stone bridge there – and nature has reclaimed the land dividing this former-railway-now-cycleway from the farmland surrounding it. Stopping briefly for another geocache we made good progress down to Barleybank where we were able to rejoin the canal towpath.
Our day’s journey began following Glazert Water towards its confluence with the River Kelvin. It’s really quite pretty around
here.
This is where we began to appreciate the real beauty of the Scottish lowlands. I’m a big fan of a mountain, but there’s also a real charm to the rolling wet countryside of the
Lanarkshire valleys. The Forth & Clyde towpath is wonderfully maintained – perhaps even better than the canal itself, which is suffering in patches from a bloom of spring reeds – and
makes for easy cycling.
Downstream from Kilsyth the Kelvin is fed by a crisscrossing network of burns rolling down the hills and through a marsh.
Outside of moorings at the odd village we’d pass, we saw no boats along most of the inland parts of the Forth & Clyde canal. We didn’t see many joggers, or dog-walkers, or indeed
anybody for long stretches.
The sun climbed into the sky and we found ourselves alone on the towpath for miles at a time.
The canal was also teeming with wildlife. We had to circumnavigate a swarm of frogs, spotted varied waterfowl including a heron who’d decided that atop a footbridge was the perfect
place to stand and a siskin that made itself scarce as soon as it spotted us, and saw evidence of water voles in the vicinity. The rushes and woodland all around but especially on the
non-towpath side of the canal seemed especially popular with the local fauna as a place broadly left alone by humans.
We only had a few seconds to take pictures of this swan family before the parents put themselves between us and the cygnets and started moving more-aggressively towards us.
The canal meanders peacefully, flat and lock-free, around the contours of the Kelvin valley all the way up to the end of the river. There, it drops through Wyndford Lock into the valley
of Bonny Water, from which the rivers flow into the Forth. From a hydrogeological perspective, this is the half-way point between Edinburgh and Glasgow.
We stopped for a moment to look at Wyndford Lock, where a Scottish Canals worker was using the gates to adjust the water levels following the previous day’s floods.
Seven years ago, I got the chance to visit the Falkirk Wheel, but Ruth had never
been so we took the opportunity to visit again. The Wheel is a very unusual design of boat lift: a pair of counterbalanced rotating arms swap places to move entire sections of the canal
from the lower to upper level, and vice-versa. It’s significantly faster to navigate than a flight of locks (indeed, there used to be a massive flight of eleven locks a little
way to the East, until they were filled in and replaced with parts of the Wester Hailes estate of Falkirk), wastes no water, and – because it’s always in a state of balance – uses next
to no energy to operate: the hydraulics which push it oppose only air resistance and friction.
A photo can’t really do justice to the size of the Falkirk Wheel: by the time you’re close enough to appreciate what it is, you’re too close to fit it into frame.
So naturally, we took a boat ride up and down the wheel, recharged our batteries (metaphorically; the e-bike’s battery would get a top-up later in the day) at the visitor centre cafe,
and enjoyed listening-in to conversations to hear the “oh, I get it” moments of people – mostly from parts of the world without a significant operating canal network, in their defence –
learning how a pound lock works for the first time. It’s a “lucky 10,000” thing.
Looking East from the top of the Falkirk Wheel we could make out Grangemouth, the Kelpies, and – in the distance –
Edinburgh: our destination!
Pressing on, we cycled up the hill. We felt a bit cheated, given that we’d just been up and down pedal-free on the boat tour, and this back-and-forth manoeuvrer confused my GPSr – which was already having difficulty with our insistence on sticking to the towpath despite all the road-based
“shortcuts” it was suggesting – no end!
The first of our afternoon tunnels began right at the top of the Falkirk Wheel. Echo… cho… ho… o…
From the top of the Wheel we passed through Rough Castle Tunnel and up onto the towpath of the Union Canal. This took us right underneath the remains of the Antonine Wall, the lesser-known sibling of Hadrian’s Wall and the absolute furthest extent, albeit short-lived, of the Roman Empire on
this island. (It only took the Romans eight years to realise that holding back the Caledonian Confederacy was a lot harder work than their replacement plan: giving most of what is now
Southern Scotland to the Brythonic Celts and making the defence of the Northern border into their problem.)
The Union Canal is higher, narrower, and windier than the Forth & Clyde.
A particular joy of this section of waterway was the Falkirk Tunnel, a very long tunnel broad enough that the towpath follows through it, comprised of a mixture of hewn rock and masonry
arches and very variable in height (during construction, unstable parts of what would have been the ceiling had to be dug away, making it far roomier than most narrowboat canal
tunnels).
Don’t be fooled by the green light: this tunnel is unmanaged and the light is alternating between red and green to tell boaters to use their own damn common sense.
Wet, cold, slippery, narrow, and cobblestoned for the benefit of the horses that no-longer pull boats through this passage, we needed to dismount and push our bikes through. This proved
especially challenging when we met other cyclists coming in the other direction, especially as our e-bike (as the designated “cargo bike”) was configured in what we came to lovingly
call “fat ass” configuration: with pannier bags sticking out widely and awkwardly on both sides.
Water pours in through the ceiling of the Falkirk Tunnel through a combination of man-made (ventilation) and eroded shafts.
This is probably the oldest tunnel in Scotland, known with certainty to predate any of the nation’s railway tunnels. The handrail was added far later (obviously, as it would interfere
with the reins of a horse), as were the mounted electric lights. As such, this must have been a genuinely challenging navigation hazard for the horse-drawn narrowboats it was built to
accommodate!
I had a few tries at getting a photo of the pair of us where neither of us looked silly, but failed. So here’s one where only Ruth looks silly (albeit clearly delighted at where she
is).
On the other side the canal passes over mighty aqueducts spanning a series of wooded valleys, and also providing us with yet another geocaching opportunity. We were very selective about our geocache stops on this trip; there
were so many candidates but we needed to make progress to ensure that we made it to Edinburgh in good time.
We took lunch and shandy at Bridge 49 where we also bought a painting depicting one of the bridges on the Union Canal and negotiated with the
proprietor an arrangement to post it to us (as we certainly didn’t have space for it in our bags!), continuing a family tradition of us buying art from and of places we take holidays
to. They let us recharge our batteries (literal this time: we plugged the e-bike in to ensure it’d have enough charge to make it the rest of the way without excessive rationing of
power). Eventually, our bodies and bikes refuelled, we pressed on into the afternoon.
One aqueduct spanned the River Almond, which Three Ringers might recognise by its Gaelic name, Amain.
For all that we might scoff at the overly-ornate, sometimes gaudy architecture of the Victorian era – like the often-ostentatious monuments of the Necropolis we visited early in our
adventure – it’s still awe-inspiring to see their engineering ingenuity. When you stand on a 200-year-old aqueduct that’s still standing, still functional, and still objectively
beautiful, it’s easy to draw unflattering comparisons to the things we build today in our short-term-thinking, “throwaway” culture. Even the design of the Falkirk Wheel’s, whose fate is
directly linked to these duocentenarian marvels, only called for a 120-year lifespan. How old is your house? How long can your car be kept functioning? Long-term thinking has given way
to short-term solutions, and I’m not convinced that it’s for the better.
Like the Falkirk Wheel, it’s hard to convey the scale of these aqueducts in pictures, especially those taken on their span! They’re especially impressive when you remember
that they were built over two centuries ago, without the benefits of many modern facilities.
Eventually, and one further (especially sneaky) geocache later, a total of around 66 “canal miles”, one monsoon, and one sleep
from the Glasgow station where we dismounted our bus, we reached the end of the Union Canal in Edinburgh.
There we checked in to the highly-recommendable 94DR guest house where our host Paul and his dog Molly demonstrated their ability to instantly-befriend
just-about anybody.
We figured that a “sharer” cocktail at the Salisbury Arms would be about the right amount for two people, but were pleasantly (?) surprised when what turned up was a punchbowl.
We went out for food and drinks at a local gastropub, and took a brief amble part-way up Arthur’s Seat (but not too far… we had just cycled fifty-something miles), of which our
hotel room enjoyed a wonderful view, and went to bed.
For some reason I felt the need to look like I was performing some kind of interpretive dance while presenting our hotel room at 94DR to Ruth.
The following morning we cycled out to Craigmillar Castle: Edinburgh’s other castle,
and a fantastic (and surprisingly-intact) example of late medieval castle-building.
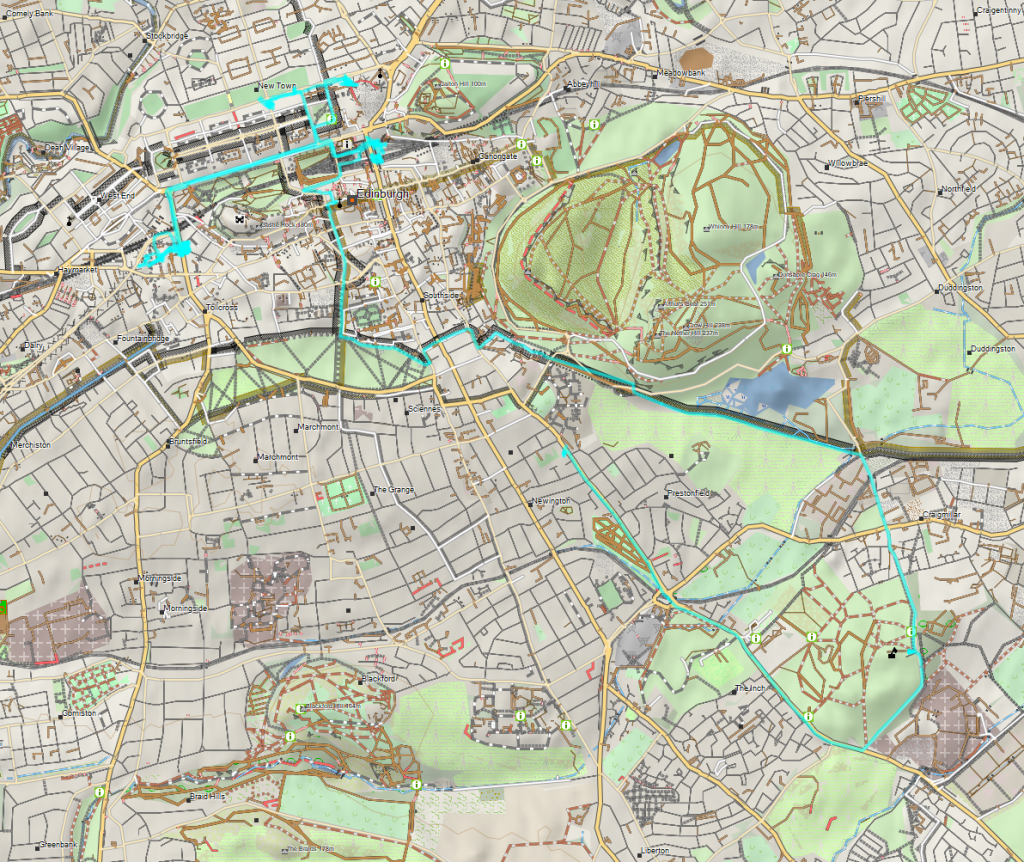
We covered about 20km (12½ miles) while exploring Edinburgh, but at least it was punctuated by lots of activities. Download GPX tracklog.
This place is a sprawling warren of chambers and dungeons with a wonderful and complicated history. I feel almost ashamed to not have even known that it existed before now:
I’ve been to Edinburgh enough times that I feel like I ought to have visited, and I’m glad that I’ve finally had the chance to discover and explore it.
Does this picture give you Knightmare vibes? It gives me Knightmare vibes. “Take three steps forwards… it’s
okay, there’s nothing to fall off of.”
Edinburgh’s a remarkable city: it feels like it gives way swiftly, but not abruptly, to the surrounding countryside, and – thanks to the hills and forests – once you’re outside of
suburbia you could easily forget how close you are to Scotland’s capital.
From atop Craigmillar Castle it was hard to imagine a time at which there’d have been little but moorland and fields spanning the league between there and the capital.
In addition to a wonderful touch with history and a virtual geocache, Craigmillar Castle also provided with a
delightful route back to the city centre. “The Innocent Railway” – an 1830s stretch
of the Edinburgh and Dalkeith Railway which retained a tradition of horse-drawn carriages long after they’d gone out of fashion elsewhere – once connected Craigmillar to Holyrood Park
Road along the edge of what is now Bawsinch and Duddington Nature Reserve, and has long since been converted into a cycleway.
The 520-metre long Innocent Tunnel may have been the first public railway tunnel in Britain. Since 1994, it’s been a cycle path.
Making the most of our time in the city, we hit up a spa (that Ruth had secretly booked as a surprise for me) in the afternoon followed by an escape room – The Tesla Cube – in the evening. The former involved a relaxing soak, a stress-busting massage, and a chill lounge in a
rooftop pool. The latter undid all of the good of this by comprising of us running around frantically barking updates at one another and eventually rocking the week’s highscore for the
game. Turns out we make a pretty good pair at escape rooms.
If we look pretty tired at this point, it’s because we are. (Fun fact, my phone insisted that we ought to take this picture again because, as it said “somebody blinked”.)
After a light dinner at the excellent vegan cafe Holy Cow (who somehow sell a banana bread that is vegan, gluten-free, and sugar-free: by the
time you add no eggs, dairy, flour or sugar, isn’t banana bread just a mashed banana?) and a quick trip to buy some supplies, we rode to Waverley Station to find out if we’d at least be
able to get a sleeper train home and hoping for not-another-bus.
I had their kidney-bean burger. It was delicious.
We got a train this time, at least, but the journey wasn’t without its (unnecessary) stresses. We were allowed past the check-in gates and to queue to load our bikes into their
designated storage space but only after waiting for this to become available (for some reason it wasn’t immediately, even though the door was open and crew were standing there) were we
told that our tickets needed to be taken back to the check-in gates (which had now developed a queue of their own) and something done to them before they could be accepted. Then they
reprogrammed the train’s digital displays incorrectly, so we boarded coach B but then it turned into coach E once we were inside, leading to confused passengers trying to take one
another’s rooms… it later turned back into coach B, which apparently reset the digital locks on everybody’s doors so some passengers who’d already put their luggage into a room
now found that they weren’t allowed into that room…
We were surprised to discover that our sleeper from Edinburgh to London had the same crew as the one we’d not been able to get to Glasgow earlier in the week. So they got to hear us
complain at them for a second time, albeit for different reasons.
…all of which tied-up the crew and prevented them from dealing with deeper issues like the fact that the room we’d been allocated (a room with twin bunks) wasn’t what we’d paid for (a
double room). And so once their seemingly-skeleton crew had solved all of their initial technical problems they still needed to go back and rearrange us and several other customers in a
sliding-puzzle-game into one another’s rooms in order to give everybody what they’d actually booked in the first place.
In conclusion: a combination of bad signage, technical troubles, and understaffing made our train journey South only slightly less stressful than our bus journey North had been. I’ve
sort-of been put off sleeper trains.
The room itself, once we finally got it, was reasonable, although it was reminiscent of time spent in small camper vans where using one piece of furniture first means folding away a
different piece of furniture.
After a reasonable night’s sleep – certainly better than a bus! – we arrived in London, ate some breakfast, took a brief cycle around Regent’s Park, and then found our way to Marylebone
to catch a train home.
Getting our bikes onto the train back to Oxford from London was, amazingly, easier than getting them onto the sleeper train on which we’d specifically booked a space for them.
All in all it was a spectacular and highly-memorable adventure, illustrative of the joy of leaving planning to good-luck, the perseverance of wet cyclists, the ingenuity of Victorian
engineers, the beauty of the Scottish lowlands, the cycle-friendliness of Glasgow, and – sadly – the sheer incompetence of the operators of sleeper trains.
I was watching a recent YouTube video by Derek Muller (Veritasium),
My Video Went Viral. Here’s Why, and I came to a realisation: I don’t watch YouTube like most people
– probably including you! – watch YouTube. And as a result, my perspective on what YouTube is and does is fundamentally biased from the way that others probably think
about it.
The Veritasium video My Video Went Viral. Here’s Why is really good and you should definitely watch at least 7 minutes of it in order to influence the algorithm.
The magic moment came for me when his video explained that the “subscribe” button doesn’t do what I’d assumed it does. I’m probably not alone in my assumptions: I’ll
bet that people who use the “subscribe” button as YouTube intend don’t all realise that it works the way that it does.
Like many, I’d assumed the “subscribe” buttons says “I want to know about everything this creator publishes”. But that’s not what actually happens. YouTube wrangles your subscription
list and (especially) your recommendations based on their own metrics using an opaque algorithm. I knew, of course, that they used such a thing to manage the list of recommended
next-watches… but I didn’t realise how big an influence it was having on the way that most YouTube users choose what they’ll watch!
“YouTube started doing some experiments… where they would change what was recommended to your subscribers. No longer was a subscription like ‘I want to see every video by this
person’; it was more of a suggestion…”
YouTube’s metrics for “what to show to you” is, of course, biased by your subscriptions. But it’s also biased by what’s “trending” (which in turn is based on watch time and
click-through-rate), what people-who-watch-the-things-you-watch watch, subscription commonalities, regional trends, what your contacts are interested in, and… who knows what else! AAA
YouTubers try to “game” it, but the goalposts are moving. And the struggle to stay on-top, especially after a fluke viral hit, leads to the application of increasingly desperate and
clickbaity measures.
This is a battle to which I’ve been mostly oblivious, until now, because I don’t watch YouTube like you watch YouTube.
“You could be a little bit disappointed in the way the game is working right now… I challenge you to think of a better way.”
Hold my beer.
Tom Scott produced an underappreciated sci-fi short last year describing a
theoretical AI which, in 2028, caused problems as a result of its single-minded focus. What we’re seeing in YouTube right
now is a simpler example, but illustrates the problem well: optimising YouTube’s algorithm for any factor or combination of factors other than a user’s stated preference (subscriptions)
will necessarily result in the promotion of videos to a user other than, and at the expense of, the ones by creators that they’ve subscribed to. And there are so many things
that YouTube could use as influencing factors. Off the top of my head, there’s:
Number of views
Number of likes
Ratio of likes to dislikes
Number of tracked shares
Number of saves
Length of view
Click-through rate on advertisements
Recency
Subscriber count
Subscriber engagement
Popularity amongst your friends
Popularity amongst your demographic
Click-through-ratio
Etc., etc., etc.
A Veritasium video I haven’t watched yet? Thanks, RSS reader.
But this is all alien to me. Why? Well: here’s how I use YouTube:
Subscription: I subscribe to creators via RSS. My RSS reader doesn’t implement YouTube’s algorithm, of course, so it just gives me exactly what I subscribe to – no more, no less.It’s not perfect
(for example, it pisses me off every time it tells me about an upcoming “premiere”, a YouTube feature I don’t care about even a little), but apart from that it’s great! If I’m
on-the-move and can’t watch something as long as involved TheraminTrees‘ latest deep-thinker, my RSS reader remembers so I can watch it later at my convenience. I can have National Geographic‘s videos “expire” if I don’t watch them within a week but Dr. Doe‘s wait for me forever. And I can implement my own filters if a feed isn’t showing exactly what I’m looking for (like I did to
strip the sport section from BBC News’ RSS feed). I’m in control.
Discovery: I don’t rely on YouTube’s algorithm to find me new content. I don’t mind being a day or two behind on what’s trending: I’m not sure I care at all? I’m far
more-interested in recommendations curated by a human. If I discover and subscribe to a channel on YouTube, it was usually (a) mentioned by another YouTuber or (b)
linked from a blog or community blog. I’m receiving recommendations from people I already respect, and they have a way higher hit-rate than YouTube’s recommendations.(I also sometimes
discover content because it’s exactly what I searched for, e.g. I’m looking for that tutorial on how to install a fiddly damn kiddy seat into the car, but this is unlikely to result
in a subscription.)
I for one welcome our content-recommending robot overlords. (So long as their biases can be configured by their users, not the networks that create them…)
This isn’t yet-another-argument that you should use RSS because it’s awesome. (Okay, so it is. RSS isn’t dead, and its killer feature is that its users get to choose
how it works. But there’s more I want to say.)
What I wanted to share was this reminder, for me, that the way you use a technology can totally blind you to the way others use it. I had no idea that many YouTube
creators and some YouTube subscribers felt increasingly like they were fighting YouTube’s algorithms, whose goals are different from their own, to get what they want. Now I can see it
everywhere! Why do schmoyoho always encourage me to press the notification bell and not just the subscribe button? Because for a
typical YouTube user, that’s the only way that they can be sure that their latest content will be seen!
“There is one way… to short-circuit this effect… ring that bell.”
If I may channel Yoda for a moment: No… there is another!
Of course, the business needs of YouTube mean that we’re not likely to see any change from them. So until either we have mainstream content-curating AIs that answer to their human owners rather than to commercial networks (robot butler, anybody?) or else the video fediverse catches on – and I don’t know which of those two are least-likely! – I guess I’ll stick to my algorithm-lite
subscription model for YouTube.
But at least now I’ll have a better understanding of why some of the channels I follow are changing the way they produce and market their content…
I love RSS, but it’s a minor niggle for me that if I subscribe to any of the
BBC News RSS feeds I invariably get all the sports
news, too. Which’d be fine if I gave even the slightest care about the world of sports, but I don’t.
If you’d like to see how I did it so you can host it yourself or adapt it for some similar purpose, the code’s below or on GitHub:
#!/usr/bin/env ruby# # Sample crontab:# # At 41 minutes past each hour, run the script and log the results# 41 * * * * ~/bbc-news-rss-filter-sport-out.rb > ~/bbc-news-rss-filter-sport-out.log 2>&1# Dependencies:# * open-uri - load remote URL content easily# * nokogiri - parse/filter XML# * b2 - command line tools, described below
require 'bundler/inline'
gemfile dosource'https://rubygems.org'gem'nokogiri'end
require 'open-uri'# Regular expression describing the GUIDs to reject from the resulting RSS feed# We want to drop everything from the "sport" section of the website
REJECT_GUIDS_MATCHING = /^https:\/\/www\.bbc\.co\.uk\/sport\//# Assumption: you're set up with a Backblaze B2 account with a bucket to which# you'd like to upload the resulting RSS file, and you've configured the 'b2'# command-line tool (https://www.backblaze.com/b2/docs/b2_authorize_account.html)
B2_BUCKET ='YOUR-BUCKET-NAME-GOES-HERE'
B2_FILENAME ='bbc-news-nosport.rss'# Load and filter the original RSS
rss = Nokogiri::XML(open('https://feeds.bbci.co.uk/news/rss.xml?edition=uk'))
rss.css('item').select{|item| item.css('guid').text =~ REJECT_GUIDS_MATCHING }.each(&:unlink)begin# Output resulting filtered RSS into a temporary file
temp_file = Tempfile.new
temp_file.write(rss.to_s)
temp_file.close# Upload filtered RSS to a Backblaze B2 bucket
result =`b2 upload_file --noProgress --contentType application/rss+xml #{B2_BUCKET}#{temp_file.path}#{B2_FILENAME}`putsTime.nowputs result.split("\n").select{|line| line =~ /^URL by file name:/}.join("\n")ensure# Tidy up after ourselves by ensuring we delete the temporary file
temp_file.close
temp_file.unlinkend
Filters it to remove all entries whose GUID matches a particular regular expression (removing all of those from the
“sport” section of the site)
Outputs the resulting feed into a temporary file
Uploads the temporary file to a bucket in Backblaze‘s “B2” repository (think: a better-value competitor S3); the bucket I’m using is
publicly-accessible so anybody’s RSS reader can subscribe to the feed
I like the versatility of the approach I’ve used here and its ability to perform arbitrary mutations on the feed. And I’m a big fan of Nokogiri. In some ways, this could be considered a
lower-impact, less real-time version of my tool RSSey. Aside from the fact that it won’t (easily) handle websites that require Javascript, this
approach could probably be used in exactly the same ways as RSSey, and with significantly less set-up: I might look into whether its functionality can be made more-generic so I can
start using it in more places.
When I write a blog post, it generally becomes a static thing: its content always
usually stays the same for the rest of its life (which is, in my case, pretty much forever). But sometimes, I go back and make an
amendment. When I make minor changes that don’t affect the overall meaning of the work, like fixing spelling mistakes and repointing broken links, I just edit the page, but for
more-significant changes I try to make it clear what’s changed and how.
This blog post from 2007, for example, was amended after its publication with the insertion of content at the top and the deletion
of content within.
Historically, I’d usually marked up deletions with the HTML <strike>/<s> elements (or
other visually-similar approaches) and insertions by clearly stating that a change had been made (usually accompanied by the date and/or time of the change), but this isn’t a good
example of semantic code. It also introduces an ambiguity when it clashes with the times I use <s> for comedic effect in the Web equivalent of the old caret-notation joke:
Be nice to this fool^H^H^H^Hgentleman, he's visiting from corporate HQ.
Better, then, to use the <ins> and <del> elements, which were designed for exactly this purpose and even accept attributes to specify the date/time
of the modification and to cite a resource that explains the change, e.g. <ins datetime="2019-05-03T09:00:00+00:00"
cite="https://alices-blog.example.com/2019/05/03/speaking.html">The last speaker slot has now been filled; thanks Alice</ins>. I’ve worked to retroactively add such
semantic markup to my historical posts where possible, but it’ll be an easier task going forwards.
Of course, no browser I’m aware of supports these attributes, which is a pity because the metadata they hold may well have value to a reader. In order to expose them I’ve added a little
bit of CSS that looks a little like this, which makes their details (where available) visible as a sort-of tooltip when hovering
over or tapping on an affected area. Give it a go with the edits at the top of this post!
ins[datetime],del[datetime]{position:relative;}ins[datetime]::before,del[datetime]::before{position:absolute;top:-24px;font-size:12px;color:#fff;border-radius:4px;padding:2px6px;opacity:0;transition:opacity0.25s;
hyphens:none;/* suppresses sitewide line break hyphenation rules */white-space:nowrap;/* suppresses extraneous line breaks in Chrome */}ins[datetime]:hover::before,del[datetime]:hover::before{opacity:0.75;}ins[datetime]::before{content:'inserted 'attr(datetime)''attr(cite);background:#050;/* insertions are white-on-green */}del[datetime]::before{content:'deleted 'attr(datetime)''attr(cite);background:#500;/* deletions are white-on-red */}
CSS facilitating the display of <ins>/<del> datetimes and citations on hover or touch.
I’m aware that the intended use-case of <ins>/<del> is change management, and that the expectation is that the “final” version of a
document wouldn’t be expected to show all of the changes that had been made to it. Such a thing could be simulated, I suppose, by appropriately hiding and styling the
<ins>/<del> blocks on the client-side, and that’s something I might look into in future, but in practice my edits are typically small and rare
enough that nobody would feel inconvenienced by their inclusion/highlighting: after all, nobody’s complained so far and I’ve been doing exactly that, albeit in a non-semantic way, for
many years!
I’m also slightly conscious that my approach to the “tooltip” might cause it to obstruct interactivity with something directly above an insertion or deletion: e.g. making a hyperlink
inaccessible. I’ve tested with a variety of browsers and devices and it doesn’t seem to happen (my line height works in my favour) but it’s something I’ll need to be mindful of if I
change my typographic design significantly in the future.
A final observation: I love the CSS attr() function, and I’ve been using it (and counter()) for all
kinds of interesting things lately, but it annoys me that I can only use it in a content: statement. It’d be amazingly valuable to be able to treat integer-like attribute
values as integers and combine it with a calc() in order to facilitate more-dynamic styling of arbitrary sets of HTML elements. Maybe one day…
For the time being, I’m happy enough with my new insertion/deletion markers. If you’d like to see them in use in their natural environment, see the final paragraph of my 2012 review of The Signal and The Noise.
I’m increasingly convinced that Friedemann Friese‘s 2009 board game Power Grid: Factory Manager (BoardGameGeek) presents gamers with a highly-digestible model of the energy economy in a capitalist society.
In Factory Manager, players aim to financially-optimise a factory over time, growing production and delivery capacity through upgrades in workflow, space, energy, and staff
efficiency. An essential driving factor in the game is that energy costs will rise sharply throughout. Although it’s not always clear in advance when or by how much, this increase in
the cost of energy is always at the forefront of the savvy player’s mind as it’s one of the biggest factors that will ultimately impact their profit.
8 $money per $unit of electricity I use? That’s a rip off! Or a great deal! I don’t know!
Given that players aim to optimise for turnover towards the end of the game (and as a secondary goal, for the tie-breaker: at a specific point five rounds after the game begins) and not
for business sustainability, the game perhaps-accidentally reasonably-well represents the idea of “flipping” a business for a profit. Like many business-themed games, it favours
capitalism… which makes sense – money is an obvious and quantifiable way to keep score in a board game! – but it still bears repeating.
There’s one further mechanic in Factory Manager that needs to be understood: a player’s ability to control the order in which they take their turn and their capacity to
participate in the equipment auctions that take place at the start of each round is determined by their manpower-efficiency in the previous round. That is: a player who
operates a highly-automated factory running on a skeleton staff benefits from being in the strongest position for determining turn order and auctions in their next turn.
My staff room is empty. How about yours?
The combination of these rules leads to an interesting twist: in the final turn – when energy costs are at their highest and there’s no benefit to holding-back staff to
monopolise the auction phase in the nonexistent subsequent turn – it often makes most sense strategically to play what I call the “sweatshop strategy”. The player switches off
the automated production lines to save on the electricity bill, drags in all the seasonal workers they can muster, dusts off the old manpower-inefficient machines mouldering in the
basement, and gets their army of workers cranking out widgets!
With indefinitely-increasing energy prices and functionally-flat staff costs, the rules of the game would always eventually reach the point at which it is most cost-effective
to switch to slave cheap labour rather than robots. but Factory Manager‘s fixed-duration means that this point often comes for all players in many games at the same
predictable point: a tipping point at which the free market backslides from automation to human labour to keep itself alive.
There are parallels in the real world. Earlier this month, Tim Watkins wrote:
The demise of the automated car wash may seem trivial next to these former triumphs of homo technologicus but it sits on the same continuum. It is just one of a gathering
list of technologies that we used to be able to use, but can no longer express (through market or state spending) a purpose for. More worrying, however, is the direction in which we
are willingly going in our collective decision to move from complexity to simplicity. The demise of the automated car wash has not followed a return to the practice of people
washing their own cars (or paying the neighbours’ kid to do it). Instead we have more or less happily accepted serfdom (the use of debt and blackmail to force people to work) and
slavery (the use of physical harm) as a reasonable means of keeping the cost of cleaning cars to a minimum (similar practices are also keeping the cost of food down in the UK).
This, too, is precisely what is expected when the surplus energy available to us declines.
I love Factory Manager, but after reading Watkins’ article, it’ll probably feel a little different to play it, now. It’s like that moment when, while reading the rules, I first
poured out the pieces of Puerto Rico. Looking through them, I thought for a moment about what the “colonist”
pieces – little brown wooden circles brought to players’ plantations on ships in a volume commensurate with the commercial demand for manpower – represented. And that realisation adds
an extra message to the game.
Beneath its (fabulous) gameplay, Factory Manager carries a deeper meaning encouraging the possibility of a discussion about capitalism, environmentalism, energy, and
sustainability. And as our society falters in its ability to fulfil the techno-utopian dream, that’s perhaps a discussion we need to be having.
Seriously, this film is awesome.
But for now, go watch Sorry to Bother You, where you’ll find further parallels… and at least you’ll get to laugh as you do
so.
As I’ve previously mentioned (sadly), Microsoft Edge is to drop its own rendering engine EdgeHTML and replace it with Blink, Google’s one (more
of my and others related sadness here, here, here, and here). Earlier this month, Microsoft made available the first prerelease versions of the browser, and I gave it a go.
At a glance, it looks exactly like you’d expect a Microsoft reskin of Chrome to look, right down to the harmonised version numbers.
All of the Chrome-like features you’d expect are there, including support for Chrome plugins, but Microsoft have also clearly worked to try to integrate as much as possible of the
important features that they felt were distinct to Edge in there, too. For example, Edge Blink supports SmartScreen filtering and uses Microsoft accounts for sync, and Incognito is of
course rebranded InPrivate.
But what really interested me was the approach that Edge Dev has taken with Progressive Web Apps.
NonStopHammerTi.me might not be the best PWA in the world, but it’s the best one linked from this blog post.
Edge Dev may go further than any other mainstream browser in its efforts to make Progressive Web Apps visible to the user, putting a plus sign (and sometimes an extended
install prompt) right in the address bar, rather than burying it deep in a menu. Once installed, Edge PWAs “just work” in
exactly the way that PWAs ought to, providing a simple and powerful user experience. Unlike some browsers, which
make installing PWAs on mobile devices far easier than on desktops, presumably in a misguided belief in the importance of
mobile “app culture”, it doesn’t discriminate against desktop users. It’s a slick and simple user experience all over.
Once installed, Edge immediately runs your new app (closing the tab it formerly occupied) and adds shortcut icons.
Feature support is stronger than it is for Progressive Web Apps delivered as standalone apps via the Windows Store, too, with the engine not falling over at the first sign of a modal
dialog for example. Hopefully (as I support one of these hybrid apps!) these too will begin to be handled properly when Edge Dev eventually achieves mainstream availability.
If you’ve got the “app” version installed, Edge provides a menu option to switch to that from any page on the conventional site (and cookies/state is retained across both).
But perhaps most-impressive is Edge Dev’s respect for the importance of URLs. If, having installed the progressive “app”
version of a site you subsequently revisit any address within its scope, you can switch to the app version via a link in the menu. I’d rather have seen a nudge in the address bar, where
the user might expect to see such things (based on that being where the original install icon was), but this is still a great feature… especially given that cookies and other
state maintainers are shared between the browser, meaning that performing such a switch in a properly-made application will result in the user carrying on from almost exactly where they
left off.
Unlike virtually every other PWA engine, Edge Dev’s provides a “Copy URL” feature even to apps without address bars, which is a killer feature for sharability.
Similarly, and also uncommonly forward-thinking, Progressive Web Apps installed as standalone applications from Edge Dev enjoy a “copy URL” option in their menu, even if the app runs without an address bar (e.g. as a result of a "display": "standalone" directive
in the manifest.json). This is a huge boost to sharability and is enormously (and unusually) respectful of the fact that addresses are the
Web’s killer feature! Furthermore, it respects the users’ choice to operate their “apps” in whatever way suits them best: in a browser (even a competing browser!), on their
mobile device, or wherever. Well done, Microsoft!
I’m still very sad overall that Edge is becoming part of the Chromium family of browsers. But if the silver lining is that we get a pioneering and powerful new Progressive Web App
engine then it can’t be all bad, can it?
You’ve probably seen the news about people taking a technological look at the issue of consent, lately. One thing that’s been
getting a lot of attention is the Tulipán Placer Consentido, an Argentinian condom which comes in a packet that requires the cooperation of two pairs of hands to open it.
Move your fingers just a bit lower. No… up a bit. Yes! Right there! That’s the spot!
One fundamental flaw with the concept that nobody seems to have pointed out (unless perhaps in Spanish), is that – even assuming the clever packaging works perfectly – all that you can
actually consent to with such a device is the use of a condom. Given that rape can be and often is committed coercively rather than physically – e.g. through fear, blackmail,
or obligation rather than by force – consent to use of a condom by one of the parties shouldn’t be conflated with consent to a sexual act: it may just be preferable to it
without, if that seems to be the alternative.
Indeed, all of these technical “solutions” to rape seem to focus on the wrong part of the process. Making sure that an agreement is established isn’t a hard problem,
algorithmically-speaking (digital signatures with split-key cryptography has given us perhaps the strongest possible solution to the problem for forty years now)! The hard problem here
is in getting people to think about what rape is and to act appropriately to one another. Y’know: it’s a people problem, not a technology problem! (Unshocker.)
“If it’s not a yes, it’s a no.” If you ignore the product, the ad itself is on-message.
But even though they’re perhaps functionally-useless, I’m still glad that people are making these product prototypes. As the news coverage kicked off by the #MeToo movement wanes, its valuable to keep that wave of news going: the issues faced by the victims of sexual assault and rape
haven’t gone away! Products like these may well be pointless in the real world, but they’re a vehicle to
keep talking about consent and its importance. Keeping the issue in the limelight is helpful, because it forces people to continually re-evaluate their position on sex and
consent, which makes for a healthy and progressive society.
So I’m looking forward to whatever stupid thing we come up with next. Bring it on, innovators! Just don’t take your invention too seriously: you’re not going to “fix” rape with
it, but at least you can keep us talking about it.
I’m not sure that I process death in the same way that “normal” people do. I blame my family.
My sisters and I have wished one another a “Happy Dead Dad Day” every 19 February since his death.
When my grandmother died in 2006 I was just in the process of packing up the car with Claire to
try to get up to visit her before the inevitable happened. I received the phone call to advise me that she’d passed, and – ten emotional
minutes later – Claire told me that she’d “never seen anybody go through the five stages of grief as fast as that
before”. Apparently I was a textbook example of the Kübler-Ross model, only at speed. Perhaps I should volunteer to stand in front of introductory psychology classes and feel things, or
something.
I guess there isn’t actually a market for Happy Dead Dad Day greetings cards?
Since my dad’s death seven years ago, I’ve marked Dead Dad Day every 19 February a way that’s definitely “mine”: with a pint or three of Guinness
(which my dad enjoyed… except if there were a cheaper Irish stout on draught because he never quite shook off his working-class roots) and some outdoors and ideally a hill, although
Oxfordshire makes the latter a little difficult. On the second anniversary of my dad’s death, I commemorated his love of setting out and checking the map later by making
my first geohashing expedition: it seemed appropriate that even without him, I could make a journey without either of us
being sure of either the route… or the destination.
Eating cornflakes together in the garden was a tradition of my dad and I’s since at least 23 years before this photo was taken.
As I implied at his funeral, I’ve always been far more-interested in celebrating life than
mourning death (that might be why I’m not always the best at supporting those in grief). I’m not saying that it isn’t sad
that he went before his time: it is. What’s worst, I think, is when I remember how close-but-not-quite he came to getting to meet his grandchildren… who’d have doubtless called him
“Grandpeter”.
We all get to live, and we’re all going to die, and I’d honestly be delighted if I thought that people might remember me with the same kind of smile (and just occasionally tear) that
finds my face every Dead Dad Day.




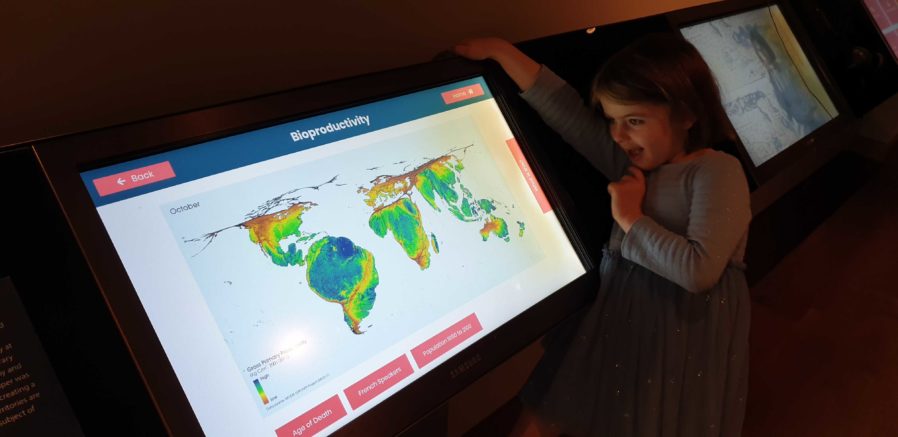

![You have [20] work days left to ask Dan that awkward question.](/_q23u/2019/09/20190903_152221-898x437.jpg)







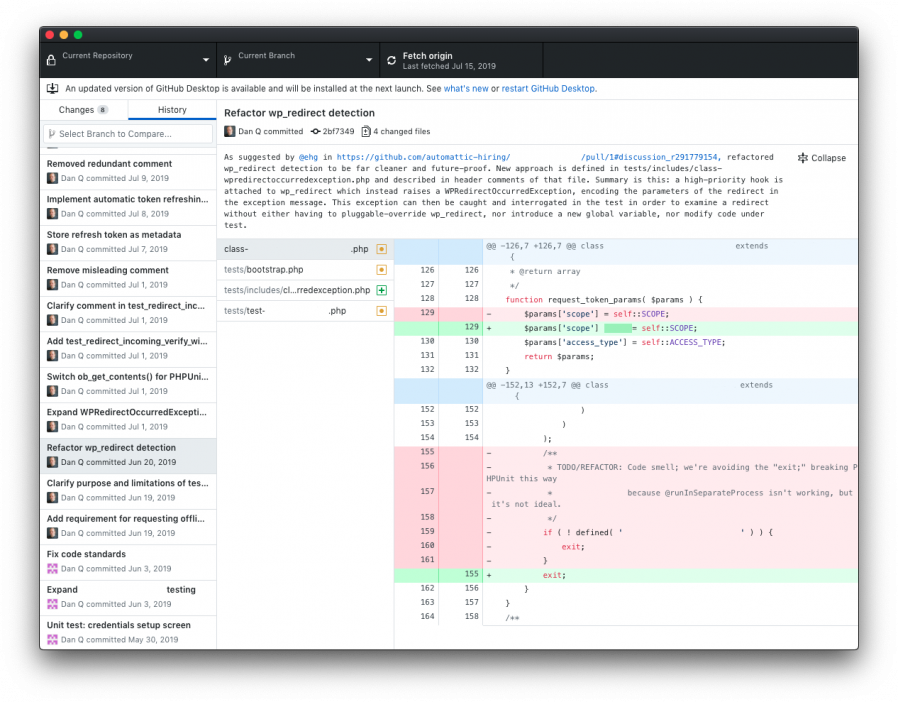
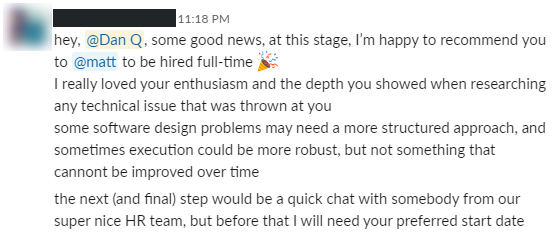







![Dan's whiteboard: "You have [29] work days left to ask Dan that awkward question".](/_q23u/2019/07/20190719_154737-1024x498.jpg)



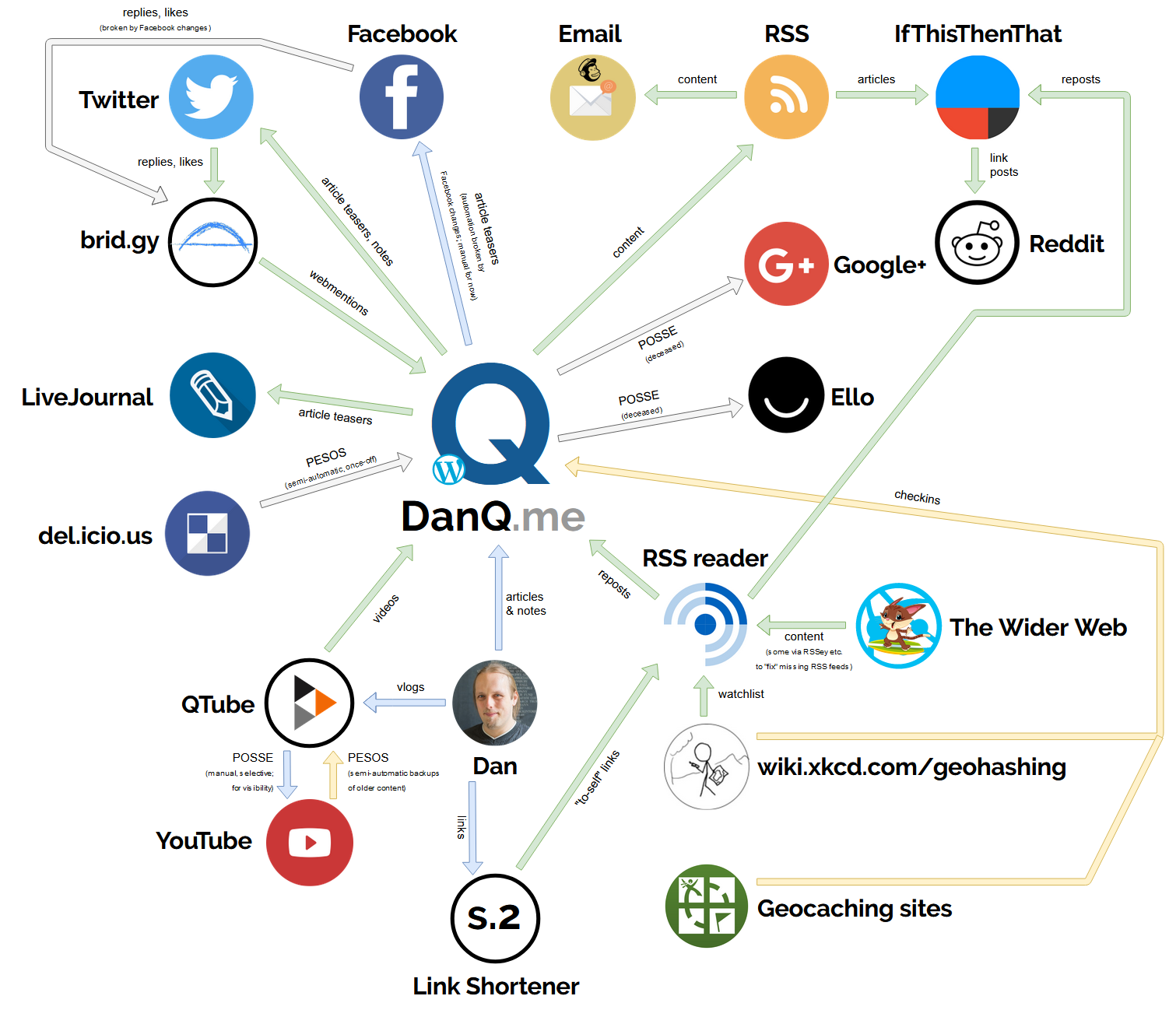
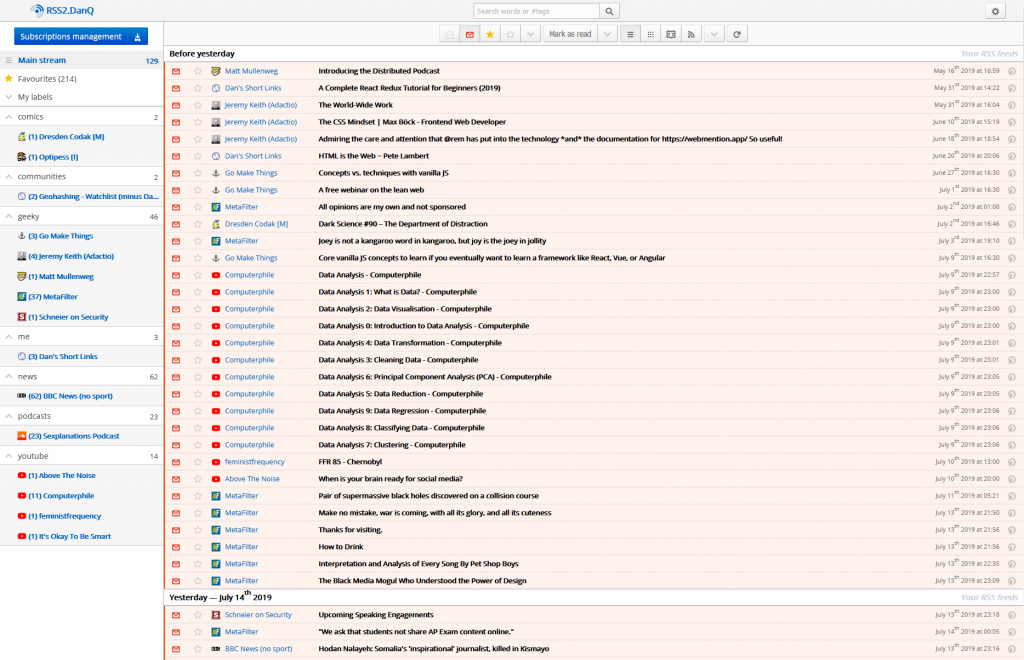

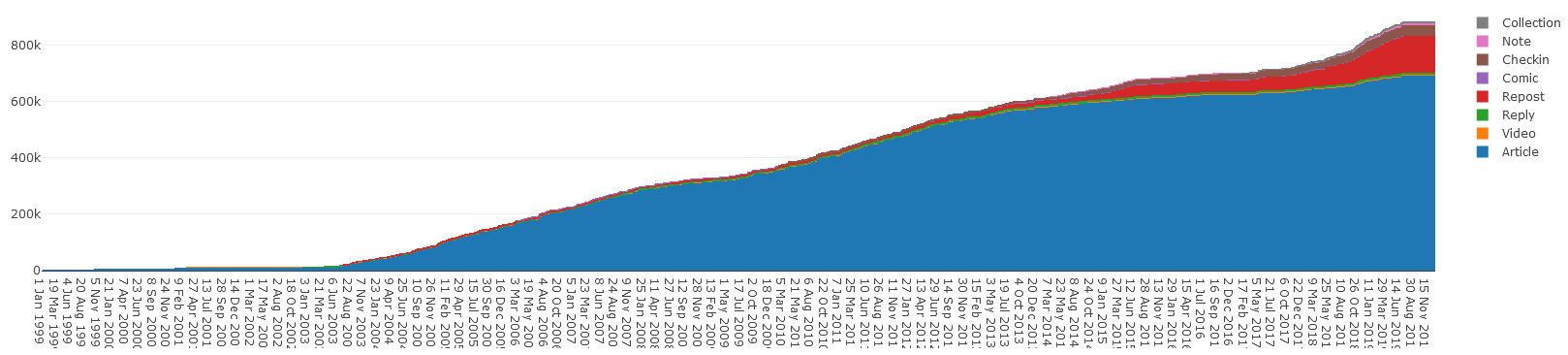


![Digital display board: "Passengers for the Caledonian Sleeper service tonight departing at 23:30 are being advised that the Glasgow portio [sic] of this service has been cancelled. For further information please see staff on"](/_q23u/2019/06/20190623_222859-1024x498.jpg)