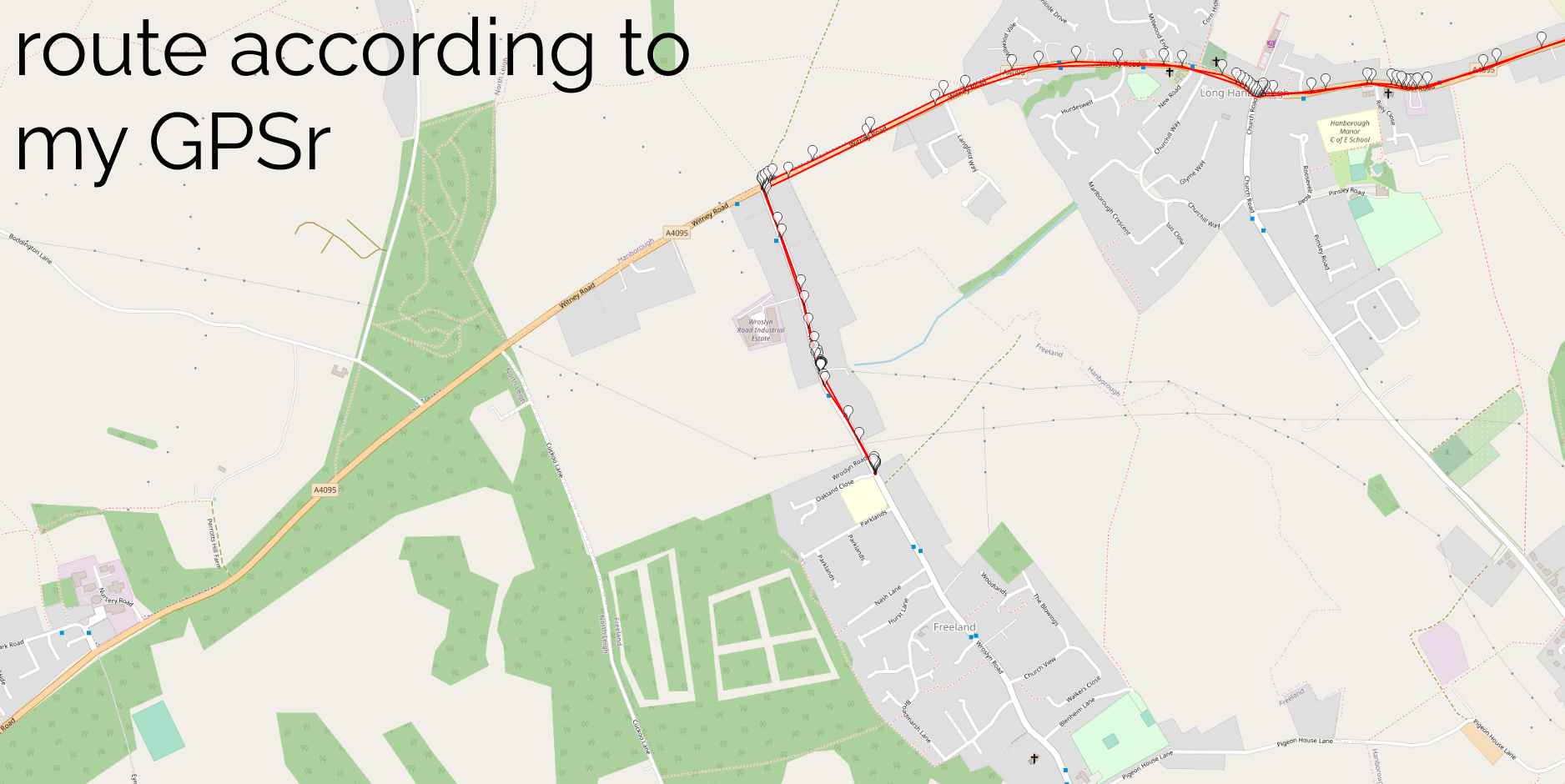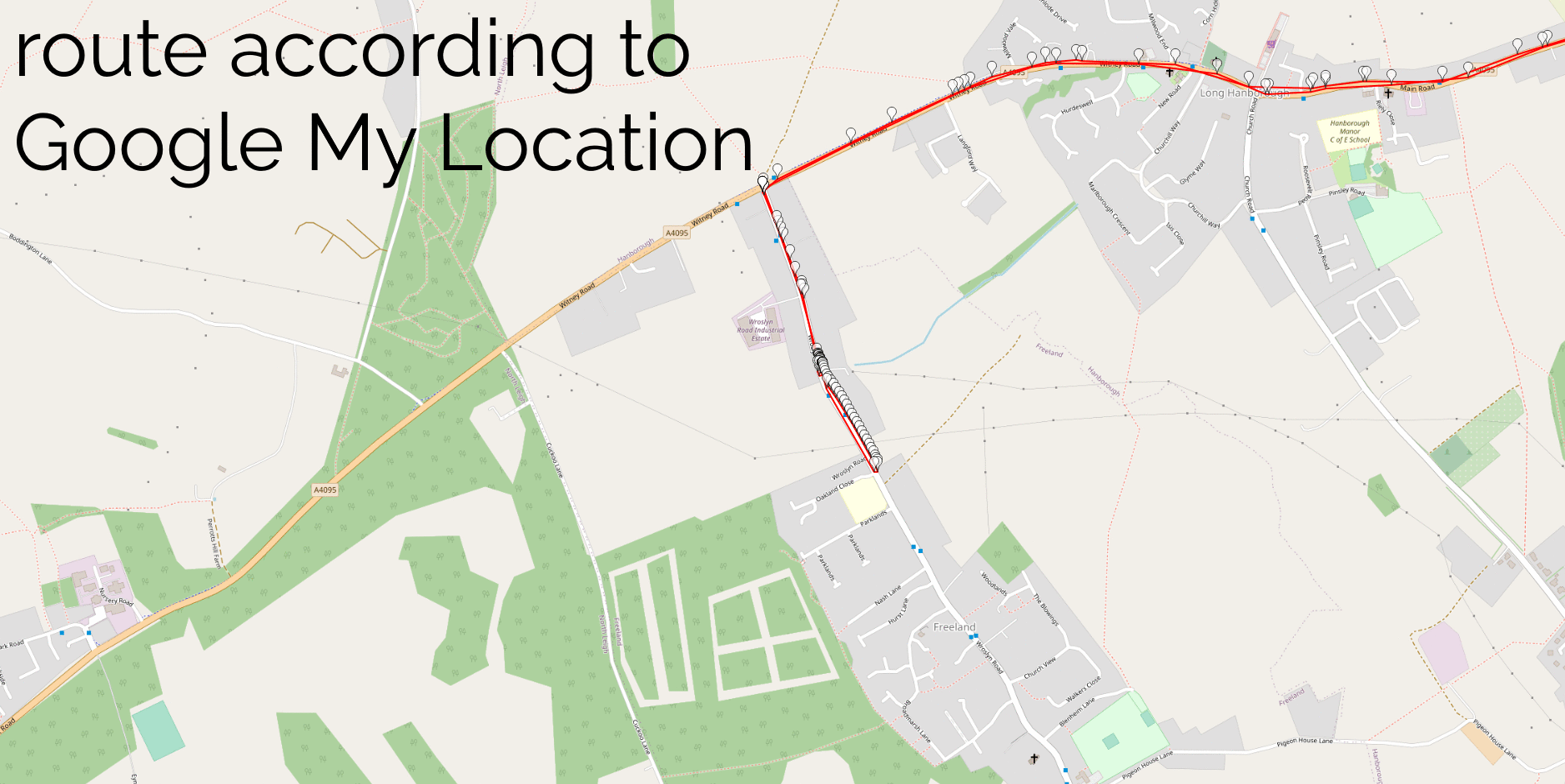
I’ve been having a tough time these last few months. Thanks to COVID, I’m sure I’m not alone in that.
Times are strange, and even when you get a handle on how they’re strange they can still affect you: lockdown stress can quickly magnify anything else you’re already going through.
We’ve all come up with our own coping strategies; here’s part of mine.

These last few months have occasionally seen me as emotionally low as… well, a particularly tough spell a decade ago. But this time around I’ve benefited from the self-awareness and experience to put some solid self-care into practice!
By way partly of self-accountability and partly of sharing what works for me, let me tell you about the silly mnemonic that reminds me what I need to keep track of as part of each day: GEMSAW! (With thanks to Amy Blankson for, among other things, the idea of this kind of acronym.)
Because it’s me, I’ve cited a few relevant academic sources for you in my summary, below:
-
Gratitude
Taking the time to stop and acknowledge the good things in your life, however small, is associated with lower stress levels (Taylor, Lyubomirsky & Stein, 2017) to a degree that can’t just be explained by the placebo effect (Cregg & Cheavens, 2020).
Frankly, the placebo effect would be fine, but it’s nice to have my practice of trying to intentionally recognise something good in each day validated by the science too! -
Exercise
I don’t even need a citation; I’m sure everybody knows that aerobic exercise is associated with reduced risk and severity of depression: the biggest problem comes from the fact that it’s an exceptionally hard thing to motivate yourself to do if you’re already struggling mentally!
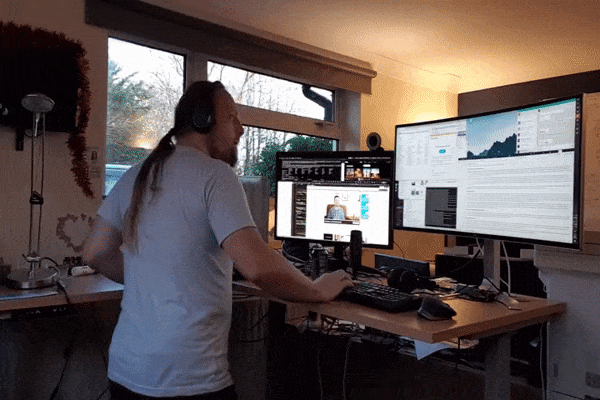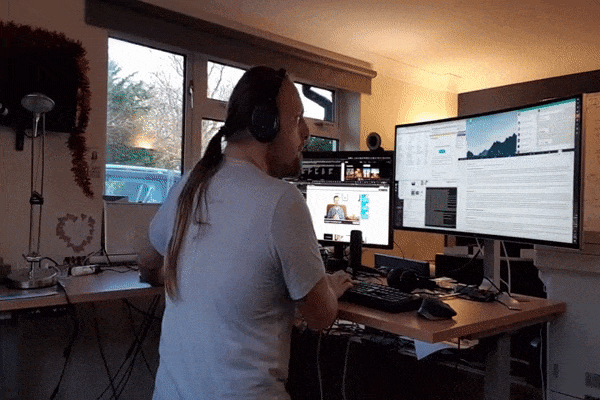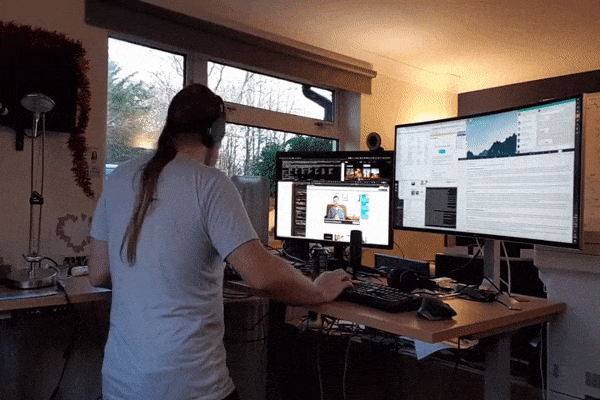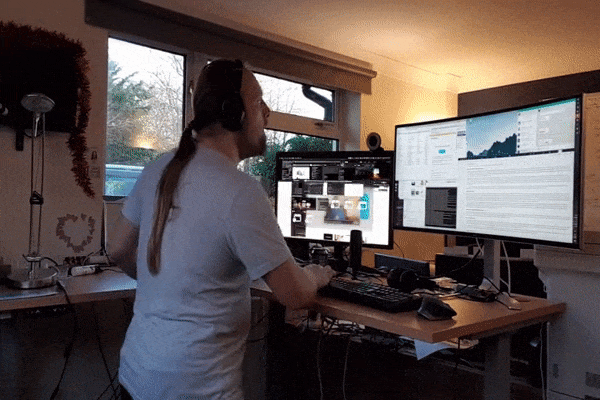
But it turns out you don’t need much to start to see the benefits (Josefsson, Lindwall & Archer, 2014): I try to do enough to elevate my heart rate each day, but that’s usually nothing more than elevating my desk to standing height, putting some headphones on, and dancing while I work!
-
Meditation/Mindfulness
Understandably a bit fuzzier as a concept and tainted by being a “hip” concept. A short meditation break or mindfulness exercise might be verifiably therapeutic, but more (non-terrible) studies are needed (Vonderlin, Biermann, Bohus & Lyssenko 2020). For me, a 2-5 minute meditation break punctuates a day and feels like it contributes towards the goal of staying-sane-in-challenging-times, so it makes it into my wellbeing plan.
Maybe it’s doing nothing. But I’m not losing much time over it so I’m not worried. -
Sunlight
During my 20s I gradually began to suffer more and more from “winter blues”. Nobody’s managed to make an argument for the underlying cause of seasonal affective disorder that hasn’t been equally-well debunked by some other study. Small-scale studies often justify light therapy (e.g. Lam, Levitan & Morehouse 2006) but it’s possibly no-more-effective than a placebo at scale (SBU 2007).
Since my early 30s, I’ve always felt better to get myself 30 minutes of lightbox on winter mornings (I use one of these bad boys). I admit it’s possible that the benefits are just the result of tricking my brain into waking-up more promptly and therefore feeing like I’m being more-productive with my waking hours! But either way, getting some sunlight – whether natural or artificial – makes me feel better, so it makes it onto my daily self-care checklist.

-
Acts of kindness
It’s probably not surprising that a person’s overall happiness correlates with their propensity for kindness (Lyubomirsky, King & Diener 2005). But what’s more interesting is that the causal link can be “gamed”. That is: a deliberate effort to engage in acts of kindness results in increased happiness (Buchanan & Bardi 2010)!
Beneficial acts of kindness can be as little as taking the time to acknowledge somebody’s contribution or compliment somebody’s efforts. The amount of effort it takes is far less-important for happiness than the novelty of the experience, so the type of kindness you show needs to be mixed-up a bit to get the best out of it. But demonstrating kindness helps to make the world a better place for other humans, so it pays off even if you’re coming from a fully utilitarian perspective. -
Writing
I write a lot anyway, often right here, and that’s very-definitely for my own benefit first and foremost. But off the back of some valuable “writing therapy” (Baikie & Wilhelm 2005) I undertook earlier this year, I’ve been continuing with the simpler, lighter approach of trying to no more than three sentences about something that’s had an impact on me that day.
As an approach, it doesn’t help everybody (Zachariae 2015), but writing a little about your day – not even about how you feel about it, just the facts will do (Koschwanez, Robinson, Beban, MacCormick, Hill, Windsor, Booth, Jüllig & Broadbent 2017; fuck me that’s a lot of co-authors) – helps to keep you content, and I’m loving it.
Despite the catchy acronym (Do I need to come up with a GEMSAW logo? I’m pretty sure real gemcutting is actually more of a grinding process…) and stack of references, I’m not actually writing a self-help book; it just sounds like I am.
I don’t claim to be an authority on anything beyond my own head, and I’m not very confident on that subject! I just wanted to share with you something that’s been working pretty well at keeping me sane for the last month or two, just in case it’s of any use to you. These are challenging times; do what you need to find the happiness you can, and hang in there.