That’s all you need to know. If you’re doing it, you’re doing it right. If you have decided to reclaim ownership of your place on the web, you’re doing it right. It doesn’t matter
how you did it. It doesn’t matter if you’re self-hosting or using a SAAS. It doesn’t matter if your content lives on a database or in a TXT file. It doesn’t matter if you did
everything yourself or you paid someone to do it for you. It doesn’t matter if you post once a day or once a year. What matters is that you’re doing it. Your effort is commendable.
You deserve to be thanked so, thank you.
Wonderful words from Manu, there, that I think every blogger needs to be told once in a while. You have permission to write stuff. There
isn’t a wrong way.
how do you find things you want to blog about? is it just about letting out one’s thoughts and feelings and some sort of catch-up to one’s latest projects?
probably will start a blog of my own soon™ :3
What an interesting question, and not one I’ve heard before.
I’ve not heard it before… probably because my blogging is… eclectic! Sometimes I blog about technology. Sometimes I blog about geocaching and geohashing. Sometimes I blog about what’s
going on in my life. Sometimes I blog about news, politics, and what’s going on in the world. Sometimes I blog just to share weird things I’ve seen on the Internet.
(I’ve sometimes worried that my approach to blogging alienates every conceivable audience. I mean: who wants to read all the topics above? But it helped me a lot to
remind myself that I blog, primarily, for myself. I am my own target audience! Everybody else comes second.)
I certainly have more things that I want to blog about than that I actually do. And even for the things I start, I often don’t finish: I’ve got
literally hundreds of incomplete drafts, and perhaps even more “concepts” noted down in Obsidian that I’ve never even started writing about.
It’s all a little skewed right now because I’ve kinda been trying to achieve the #100DaysToOffload challenge – which I’ve achieved for six consecutive years so far – in the first hundred days of 2026! Given that it’s called “100 Days To
Offload” I don’t feel like it’s legitimate to claim it for 100 blog posts that aren’t on different days (otherwise I’d have achieved it already, with about 149 in the first 82
days of this year).
So yeah: I’m currently working towards a hundred-day streak, and that’s almost certainly having me blog more than I might “organically”. To that
end, I’m often digging out old drafts and finalising them, right now, or else being more “impulsive” in my blogging, compared to the norm. This lunchtime, for example, I took a cycle,
and it gave me a sense of normalcy that’s been somewhat missing in my life recently, and I considered writing a blog post about the experience. Impulsive, y’see!
But in general… my “process”, such as it is… is that I just look at what interests me today. There’s no secret to blogging as prolifically as I do: you’ve
just got to start writing, and then keep writing. That’s all there is to it.
It adds a layer of humanity and personality to the Web. It introduces me to cool new people, and re-introduces me to cool people whom I’d crossed paths with at a distance: Joe’s one of
the latter, but I’ve now taken the time to ensure he’s in my RSS reader… and, by proxy, in my blogroll.
I don’t have a return address for anybody who posted anything to me, yet (obviously I’d have masked it out from the postcard if I had!), but I feel like I ought to buy some postcards
now too. It’s only a matter of time.
And hey, maybe there’s mileage in starting an Personal Web Postcards Club or something…
In January 2024 I participated in Bloganuary, a “write a blog post every day for a month” challenge organised by Automattic. I wasn’t
100% impressed by the prompts made available and was – as an employee of Automattic – shuffling towards trying to help make them better in a future year. To be part of the solution!
There’s definitely something in this ‘winter sun’ thing that seems to help me stay sane in the cold dark months. This morning, I’m blogging from a
hotel balcony in Peurtro de la Cruz, Tenerife.
Of course, two significant things changed since then:
As part of a sweeping range of redundancies, I was let go from my position at Automattic2,
and
Automattic ceased running Bloganuary: I’m guessing that the folks responsible for making it happen were among the many that Automattic decided to axe, or else their shifting
priorities – reflected by their waves of layoffs – are no longer compatible with providing that service to bloggers.
Ah well, I figured. I’d just do my own thing. I can write something for every day in January 2026, can’t I?
Generating a chart...
If this message doesn't go away, the JavaScript that makes this magic work probably isn't doing its job right: please tell Dan so he can fix it.
In general, I suppose I’ve been blogging more-frequently lately. Why is that? I guess it’s been a realisation that a blog post doesn’t always have to be polished to perfection.
I still write long-form posts which require research and planning, like setting up a network of Windows 3.x VMs just to get screenshots of what
programming then looked like or making that podcast episode with the music in it… but I’m also feeling more-free to just
express myself in the moment. To share things I see that look interesting or funny or
pretty, or just whatever I’m thinking. I’ve been using “kinds” to categorise my posts so it’s easy for people to avoid my more-inane stuff if
they like, but that’s a secondary consideration because ultimately… I blog for me.
Anyway… all of which is to say that I’ve been writing more and I’ve been loving it. The best way to read more of what I’m writing, if you’d like to, remains: by subscribing via RSS.
1 I’d anticipated having a lack of Internet access, but in fact 4G was widespread
throughout both islands and overall I managed to post something on every day except three in January 2025.
2 Based on friends I’ve spoken to, there seem to have been a lot more folks let go since;
the company seems to be shrinking quite a lot, which might go some way to explaining my second observation too.
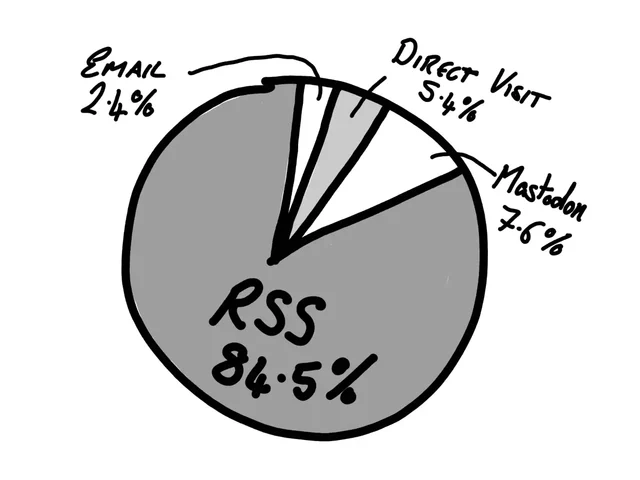
Well, quite a lot, actually. It tells me that there’s loads of you fine people reading the content on this site, which is very heart-warming. It also tells me that RSS is
by far the main way people consume my content. Which is also fantastic, as I think RSS is very
important and should always be a first class citizen when it comes to delivering content to people.
…
I didn’t get a chance to participate in Kev’s survey because, well, I don’t target
“RSS Zero” and I don’t always catch up on new articles – even by authors I follow closely – until up to a few weeks after they’re published1.
But needless to say, I’d have been in the majority: I follow Kev via my feed reader2.
But I was really interested by this approach to understanding your readership: like Kev, I don’t run any kind of analytics on my personal sites. But he’s onto something! If you
want to learn about people, why not just ask them?
Okay, there’s going to be a bias: maybe readers who subscribe by RSS are simply more-likely to respond to a survey? Or are more-likely to visit new articles quickly, which
was definitely a factor in this short-lived survey? It’s hard to be certain whether these or other factors might have thrown-off Kev’s results.
But then… what isn’t biased? Were Kev running, say, Google Analytics (or Fathom, or Strike, or Hector, or whatever)… then I wouldn’t show up in his results
because I block those trackers3
– another, different, kind of bias.
We can’t dodge such bias: not using popular analytics platforms, and not by surveying users. But one of these two options is, at least, respectful of your users’ privacy and bandwidth.
I’m tempted to run a similar survey myself. I might wait until after my long-overdue redesign – teased here – launches,
though. Although perhaps that’s just a procrastination stemming from my insecurity that I’ll hear, like, an embarrassingly-low number of responses like three or four and internalise it
as failing some kind of popularity contest4! Needs more thought.
Footnotes
1 I’m happy with this approach: I enjoy being able to treat my RSS reader as sort-of a
“magazine”, using my categorisations of feeds – which are partially expressed on my Blogroll page – as a theme. Like: “I’m going to spend 20 minutes
reading… tech blogs… or personal blogs by people I know personally… or indieweb-centric content… or news (without the sports, of course)…”
This approach makes consuming content online feel especially deliberate and intentional: very much like being in control of what I read and when.
3 In fact, I block all third-party JavaScript (and some first-party
JavaScript!) except where explicitly permitted, but even for sites that I do allow to load all such JavaScript I still have to manually enable analytics
trackers if I want them, which I don’t. Also… I sandbox almost all cookies, and I treat virtually all persistent cookies as session cookies and I
delete virtually all session cookies 15 seconds after I navigate away from a its sandbox domain or close its tab… so I’m moderately well-anonymised even where I do somehow
receive a tracking cookie.
4 Perhaps something to consider after things have gotten easier and I’ve caught up with my backlog a bit.
I’m not saying the plain-text is the best web experience. But it is an experience. Perfect if you like your browsing fast, simple, and readable. There are no
cookie banners, pop-ups, permission prompts, autoplaying videos, or garish colour schemes.
I’m certainly not the first person to do this, so I thought it might be fun to gather a list of websites which you browse in text-only mode.
…
Terence Eden’s maintaining a list of websites that are presented as, or are wholly or partially available via, plain text. Obviously my own text/plain
blog is among them, and is as far as I’m aware the only one to be entirely presented as text/plain.
Anyway, this inspired me to write a post of my own (on text/plain blog, of course!), in which I ask the question: what do we
consider plain text? Based on the sites in the list, Markdown is permissible as plain text, (for the purposes of Terence’s list), but this implies that “plain text” is a
spectrum of human-readability.
If Markdown’s fine, then presumably Gemtext would be too? How about BBCode? HTML and RTF are explicitly excluded by Terence’s rules,
but I’d argue that HTML 1.0 could be more human-readable than some of the more-sophisticated dialects of BBCode (or any Markdown that contains tables, unless those tables are laid-out
in a way that specifically facilitates human-readability)?
As I say in my post:
<-- More human-readable Less human-readable -->
|-----------|-----------|-----------|------------|-----------|-----------|-----------|-----------|
Plain text Gemtext Markdown BBCode HTML 1.0 Modern HTML RTF
This provocation is only intended to get you to think about “what does it mean for a markup language to be ‘human readable’?” Where do you draw the line?
But I’m pretty sure there are some people who’d rather receive updates to my blog via WhatsApp. And
now, they can. Here’s how I set up an RSS-to-WhatsApp gateway, in case you want to run one of your own2.
A Whapi account connected to your WhatsApp account3
– when you set up an account you’ll get a free trial; when it ends you need to find the link to say that you want to carry on with the free tier (or upgrade to the paid tier if you
expect to send more messages than the free tier’s limit)
A WhatsApp channel to which you want to push your RSS feed: I’d recommend that you make a newsletter (from the Updates tab in WhatsApp, press the kekab menu then
Create Channel) rather than a traditional group: groups are designed for multiple people to talk and discuss and everybody can see one another’s identity, but a newsletter
keeps everybody’s identity private and only allows the administrator(s) permission to post updates.
You probably want to use the kind of channel that’s for one-to-many ‘push’ communication, not a discussion group.
In Settings > Secrets and Variables > Actions, add two new Repository Secrets:
WHATSAPP_API_TOKEN: set to the token on your Whapi dashboard
WHATSAPP_CHANNEL: set to your newsletter ID (will look like 123456789012345678@newsletter) or group ID (will look
like 123456789012345678@g.us): you can get this from the Newsletters or Groups section of Whapi by executing a test GET /newsletters or GET /groups request4.
Do a test run: from the Actions tab select the “Process feeds” action and click “Run workflow”. If it finishes successfully (and you get the WhatsApp message), you’re done! If it
fails, click on the failed action and drill-in to the failed task to see the error message and correct accordingly.
By default, the processor will run on-demand and every 30 minutes, but you can modify that in.github/workflows/process-feeds.yml. It’s configured to send the single oldest
un-sent item in any of the RSS feeds it’s subscribed to, on each run (it tracks which ones it’s sent already by their guids, in a "seen": [...] array in
feeds.json): sending a single link per run ensures that WhatsApp’s link previews work as expected. At that rate, you could theoretically run it once every 10 minutes and
never hit the 150-messages-per-day limit of Whapi’s free tier5), but you’ll want to work out your own optimal rate based on the
anticipated update frequency of your feeds and the number of RSS-to-WhatsApp channels you’re running.
You can, of course, run it on your own infrastructure in a similar way. Just check out the repository to your local system with Ruby 3.2+ running, run bundle to install the
dependencies, then set up a cron job or some other automation to run ./process_feeds.rb. Doing this could be used to hook it up to your RSS feed updating pipeline, for
example, to check for new feed items right after a new post is published.
Footnotes
1 Their own incomprehensible, illogical, weird reasons.
2 I hope that the title gives it away, but you can do this completely for free.
So long as you keep your fork of the GitHub repository open-source then you can run GitHub Actions for free, and so long as you’re pushing out no more than 150 updates per day to no
more than 5 different channels in a month then you can do it within Whapi’s free tier: that’s probably fine for a personal blogger, and there’s a reasonable pricing structure (plus
some value-added extras) for companies that want to use this same workflow as part of a grander WhatsApp offering.
3 Setting this up requires giving Whapi access to your WhatsApp account. If you don’t like
the security implications of that, you could get a cheap eSIM, set that up with WhatsApp, and use that account: if you do this, just remember to “warm up” your new WhatsApp
account with some conversations with yourself so it doesn’t look so much like a spammer! Also note that the way Whapi works “uses up” one of the ~4 devices on which you can
simultaneously use WhatsApp Web/WhatsApp Desktop etc.
4 Prefer the command-line? So long as you’ve got curl and jq
then you can get a list of your newsletters (or groups) and their IDs with curl -H 'Authorization: Bearer YOUR_API_TOKEN' -H 'accept: application/json'
https://gate.whapi.cloud/newsletters?count=100 | jq '.newsletters[] | { id: .id, name: .name }' or curl -H 'Authorization: Bearer YOUR_API_TOKEN' -H 'accept:
application/json' https://gate.whapi.cloud/groups?count=100 | jq '.groups[] | { id: .id, name: .name }', respectively.
5 Going beyond the free tier would require sending one message, on average, every 9
minutes and 36 seconds.
A couple of weeks ago I blogged about setting up a PO Box and adding postal mail to the ways you can
contact me. I went for a “pay as you go” PO Box because I didn’t know if anybody would actually use it, but I’ve already received two delightful postcards and I couldn’t be more
thrilled.
The PO Box worked very well: I’m using UK Postbox principally because of their “pay as you go” rate (with a free tier in case you don’t receive
any mail at all, which I figured was a risk) but I was later pleased to discover they’re a nice company in other ways,
too. They scan the outside/one side of my mail as it arrives and I can optionally pay to scan the whole thing and/or to bundle and forward it on to me3.
I’ve started a new page to collect all the cards, including a (hopefully pretty-accessible) CSS-powered interactive “flipper” so you can turn them over, and
I’m hopeful that I might attract a few more as time goes on. Getting physical mail from “Internet friends” helps make the digital world feel a little bit smaller, and I
love it.
1 Florence’s RSS feed was missing a <![CDATA[ ... ]]> block around some
embedded HTML, which was causing the HTML to be evaluated “as if” it were XML, which – not being XHTML – it failed to do.
2 My suggestion was a variation of Derek Dingle’s Too Many Cards that I’ve been performing all over the place: it’s an immensely satisfying trick to perform, requiring a challenging but achievable set of sleights and
suitable to do without preparation and using a borrowed deck, which is pretty much the gold standard in card magic.
3 I’ve opted to have it forwarded: I’m wondering if I can combine all the postcards I get
into a single poster frame or something: maybe a double-sided one so the whole thing can be flipped to show the text, not just the fronts?
Last month I was on em’s personal site, where I discovered their contact page
lists not only the usual methods (email addresses, socials, contact forms etc.) but also a postal address1: how cool is that‽ I could have written in
their guestbook… but obviously I took the option to send a postcard instead!
Now I’ve set up a PO Box of my own, and I’ve love it if you feel up to saying “hi” via a postcard2.
As a bonus, it’s more-likely to get through than anything that has to face-off against my spam filter!
So, if you want to send me a letter or postcard (no parcels, nothing that needs a signature), my address is:
Dan Q
Unit 159610
PO Box 7169
Poole
BH15 9EL
United Kingdom
It makes me sad to see the gradual disappearance of the contact form from personal websites. They generally feel more convenient than email addresses, although this is
perhaps part of the reason that they come under attack from spammers in the first place! But also, they provide the potential for a new and different medium: the comments
area (and its outdated-but-beautiful cousin the guestbook).
Comments are, of course, an even more-obvious target for spammers because they can result in immediate feedback and additional readers for your message. Plus – if they’re allowed to
contain hyperlinks – a way of leeching some of the reputability off a legitimate site and redirecting it to the spammers’, in the eyes of search engines. Boo!
Well this was painful to write.
But I’ve got to admit: there have been many times that I’ve read an interesting article and not interacted with it simply because the bar to interaction (what… I have
to open my email client!?) was too high. I’d prefer to write a response on my blog and hope that webmention/pingback/trackback do their thing, but will they? I don’t know in
advance, unless the other party says so openly or I take a dive into their source code to check.
Your Experience May Vary
I’ve had both contact/comment forms and exposed email addresses on my website for many years… and I feel like I get aproximately the same amount
of spam on both, after filtering. The vast majority of it gets “caught”. Here’s what works for me:
My contact/comments forms use one of a variety of unobtrustive “honeypot”-style traps. These “reverse CAPTCHAs” attempt to trick bots into interacting with them in some
particular way while not inconveniencing humans.
Antispam Bee provides the first line of defence, but I’ve got a few tweaks of my own to help counteract the efforts of
determined spammers.
Once you’ve fallen into a honeypot it becomes much easier to block subsequent contacts with the same/similar content, address, (short-term) IP, or the poisoned cookie you’re given.
Keyword filtering provides a further line of defence. E.g. for contact forms that post directly back to the Web (i.e. comment forms, and perhaps a future guestbook form), content
with links goes into a moderation queue unless it shares a sender email with a previously-approved sender. For contact forms that result in an email, I’ve just got a few “scorer” rules
relating to geo IP, keywords, number and density of links, etc. that catch the most-insidious of spam to somehow slip through.
I also publish email addresses all over the place, but they’re content-specific. Like Kev, I anticipated spam and so use unique email addresses on
different pieces of content: if you want to reply-by-email to this post, for example, you’re encouraged to use the address
b27404@danq.me. But this approach has actually provided secondary benefits that are more-valuable:
The “scrapers” that spam me by email would routinely send email to multiple different @danq.me addresses at the same time. Humans don’t send the same identical message
to me to different addresses published on my site and from different senders, so my spam filter picks up on this rightaway.
As a fringe benefit, this helps me determine the topic on an email where it’s unclear. E.g. I’ve had humans email me to say “I tried to follow the guide on your page but it didn’t
work for me” and I wouldn’t have had a clue which page had they not reached out via a page-specific email alias.
I enjoy the potential offered by rotating the email address generation mechanism and later treating all previously-exposed addresses as email honeypots.
They’ve all got different “sender” addresses, but that fact that this series of emails were identical except for the different recipient aliases meant that catching them was very easy
for my spam filters.
Works For Me!
This strategy works for me: I get virtually no comment/contact form spam (though I do occasionally get a false positive and a human gets blocked as-if they were a robot), and very
little email spam (after my regular email filters have done their job, although again I sometimes get false positives, often where humans choose their subject lines poorly).
It might sound like my approach is complicated, but it’s really not. Adding a contact form honeypot is not significantly more-difficult than exposing automatically-rotating email
aliases, and for me it’s worth it: I love the convenience and ease-of-use of a good contact/comments form, and want to make that available to my visitors too!
(I also allow one-click reactions with emoji: did you see? Scroll down and send me a bumblebee! Nobody seems to have found a way to spam me with these, yet: it’s not a very expressive
medium, I guess!)
Today, for the first time ever, I simultaneously published a piece of content across five different media: a Weblog post, a video essay, a podcast episode, a Gemlog post, and a
Spartanlog post.
Must be about something important, right?
Nope, it’s a meandering journey to coming up with a design for a £5 coin that will never exist. Delightfully pointless. Being the Internet I want to see in the world.
Last month my pest of a dog destroyed my slippers, and it was more-disruptive to my life than I would have anticipated.
Look what you did, you troublemaker.
Sure, they were just a pair of slippers1, but they’d
become part of my routine, and their absence had an impact.
Routines are important, and that’s especially true when you work from home. After I first moved to Oxford and started doing entirely remote work for the first time, I found the transition challenging2.
To feel more “normal”, I introduced an artificial “commute” into my day: going out of my front door and walking around the block in the morning, and then doing the same thing in reverse
in the evening.
My original remote working office, circa 2010.
It turns out that in the 2020s my slippers had come to serve a similar purpose – “bookending” my day – as my artificial commute had over a decade earlier. I’d slip them on when I was at
my desk and working, and slide them off when my workday was done. With my “work” desk being literally the same space as my “not work” desk, the slippers were a psychological reminder of
which “mode” I was in. People talk about putting on “hats” as a metaphor for different roles and personas they hold, but for me… the distinction was literal footwear.
And so after a furry little monster (who for various reasons hadn’t had her customary walk yet that day and was probably feeling a little frustrated) destroyed my slippers… it actually
tripped me up3. I’d be doing
something work-related and my feet would go wandering, of their own accord, to try to find their comfortable slip-ons, and when they failed, my brain would be briefly tricked
into glancing down to look for them, momentarily breaking my flow. Or I’d be distracted by something non-work-related and fail to get back into the zone without the warm, toe-hugging
reminder of what I should be doing.
It wasn’t a huge impact. But it wasn’t nothing either.
The bleppy little beast hasn’t expressed an interest in my replacement slippers, yet. Probably because they’re still acquiring the smell of my feet, which I’m guessing is
what interested her in the first place.
So I got myself a new pair of slippers. They’re a different design, and I’m not so keen on the lack of an enclosed heel, but they solved the productivity and focus problem I was facing.
It’s strange how such a little thing can have such a big impact.
Oh! And d’ya know what? This is my hundredth blog post of the year so far! Coming on only the 73rd day of the year, this is my fastest run at
#100DaysToOffload yet (my previous best was last year, when I managed the same on 22 April). 73 is exactly a fifth of 365, so… I guess I’m on
track for a mammoth 500 posts this year? Which would be my second-busiest blogging year ever, after 2018. Let’s see how I get on…4
Footnotes
1 They were actually quite a nice pair of slippers. JTA got them for me as a gift a few years back, and they lived either on my feet or under my desk ever since.
2 I was working remotely for a company where everybody else was working
in-person. That kind of hybrid setup is a lot harder to do “right”, as many companies in this post-Covid-lockdowns age have discovered, and it’s understandable that I found it
somewhat isolating. I’m glad to say that the experience of working for my current employer – who are entirely distributed –
is much more-supportive.
3 Figuratively, not literally. Although I would probably have literally tripped
over had I tried to wear the tattered remains of my shredded slippers!
I’ve been trying to comment more on other people’s blogs. It’s tough, because comment forms continue to wane in popularity, and it’s not always clear who’ll accept Webmentions, but
there’s often the option of a good old-fashioned email or a fediverse ping.
It occurred to me that I follow a significant number of personal blogs, and my privacy systems mean I’m a bit of a ghost to most analytics systems they might use, so the only way they’d
ever know I was there would be if I said so.
Plus, the Internet is better when it’s social. There are some great people out there, and I’m enjoying meeting them!
(You’re welcome to throw comments, Webmentions, or emails my way, of course, too!)