A few yeras ago, I wanted to subscribe to The Far Side‘s “Daily Dose” via my RSS reader. The Far Side doesn’t have an RSS feed, so I implemented a proxy/middleware to bridge the two.
![Browser debugger running document.evaluate('//li[@class="blog__post-preview"]', document).iterateNext() on Beverley's weblog and getting the first blog entry.](https://bcdn.danq.me/_q23u/2022/09/debugger-select-from-xpath-1024x256.png)
It turns out that FreshRSS’s XPath Scraping is almost enough to achieve exactly what I want. The big problem is that the image server on The Far Side website tries to
prevent hotlinking by checking the Referer: header on requests, so we need a proxy to spoof that. I threw together a quick PHP program to act as a proxy (if
you don’t have this, you’ll have to click-through to read each comic), then configured my FreshRSS feed as follows:
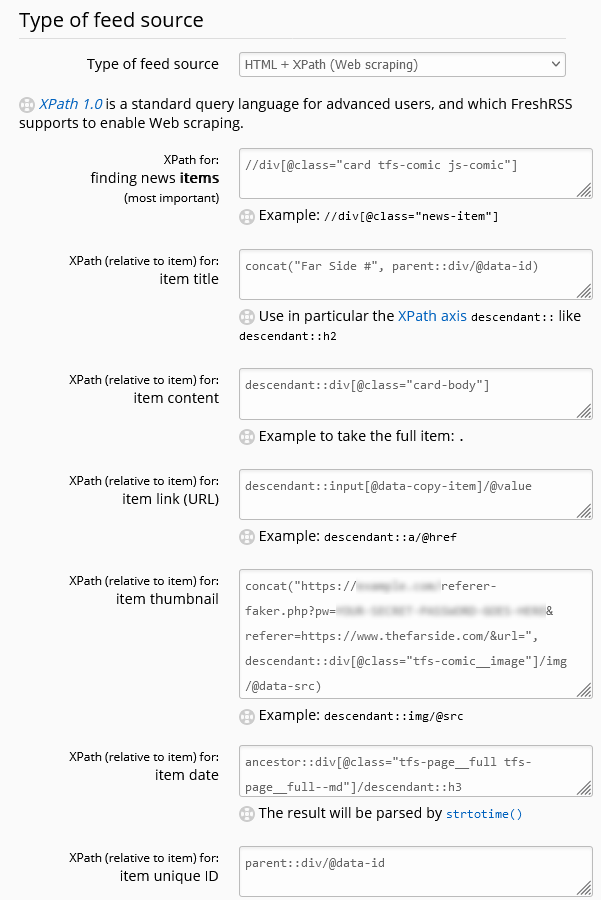
-
Feed URL:
https://www.thefarside.com/
The “Daily Dose” gets published to The Far Side‘s homepage each day. -
XPath for finding new items:
//div[@class="card tfs-comic js-comic"]
Finds each comic on the page. This is probably a little over-specific and brittle; I should probably switch to using thecontainsfunction at some point. I subsequently have to useparent::andancestor::selectors which is usually a sign that your screen-scraping is suboptimal, but in this case it’s necessary because it’s only at this deep level that we start seeing really specific classes. -
Item title:
concat("Far Side #", parent::div/@data-id)
The comics don’t have titles (“The one with the cow”?), but these seem to have unique IDs in thedata-idattribute of the parent<div>, so I’m using those as a reference. -
Item content:
descendant::div[@class="card-body"]
Within each item, the<div class="card-body">contains the comic and its text. The comic itself can’t be loaded this way for two reasons: (1) the<img src="...">just points to a placeholder (the site uses JavaScript-powered lazy-loading, ugh – the actual source is in thedata-srcattribute), and (2) as mentioned above, there’s anti-hotlink protection we need to work around. -
Item link:
descendant::input[@data-copy-item]/@value
Each comic does have a unique link which you can access by clicking the “share” button under it. This makes a hidden text<input>appear, which we can identify by the presence of thedata-copy-itemattribute. The contents of this textbox is the sharing URL for the comic. -
Item thumbnail:
concat("https://example.com/referer-faker.php?pw=YOUR-SECRET-PASSWORD-GOES-HERE&referer=https://www.thefarside.com/&url=", descendant::div[@class="tfs-comic__image"]/img/@data-src)
Here’s where I hook into my special proxy server, which spoofs theReferer:header to work around the anti-hotlinking code. If you wanted you might be able to come up with an alternative solution using a custom JavaScript loaded into your FreshRSS instance (there’s a plugin for that!), perhaps to load an iframe of the sharing URL? Or you can host a copy of my proxy server yourself (you can’t use mine, it’s got a password and that password isn’tYOUR-SECRET-PASSWORD-GOES-HERE!) -
Item date:
ancestor::div[@class="tfs-page__full tfs-page__full--md"]/descendant::h3
There’s nothing associating each comic with the date it appeared in the Daily Dose, so we have to ascend up to the top level of the page to find the date from the heading. -
Item unique ID:
parent::div/@data-id
Giving FreshRSS a unique ID can help it stop showing duplicates. We use the unique ID we discovered earlier; this way, if the Daily Dose does a re-run of something it already did since I subscribed, I won’t be shown it again. Omit this if you want to see reruns.

There’s a moral to this story: when you make your website deliberately hard to consume, fewer people will access it in the way you want! The Far Side‘s website is actively hostile to users (JavaScript lazy-loading, anti-right click scripts, hotlink protection, incorrect MIME types, no feeds etc.), and an inevitable consequence of that is that people like me will find and share workarounds to that hostility.
If you’re ad-supported or collect webstats and want to keep traffic “on your site” on this side of 2004, you should make it as easy as possible for people to subscribe to content. Consider The Oatmeal or Oglaf, for example, which offer RSS feeds that include only a partial thumbnail of each comic and a link through to the full thing. I don’t feel the need to screen-scrape those sites because they’ve given me a subscription option that works, and I routinely click-through to both of them to enjoy their latest content!
Conversely, the Far Side‘s aggressive anti-subscription technology ultimately means that there are fewer actual visitors to their website… because folks like me work to circumvent them.
And now you know how I did so.
Update: want the new content that’s being published to The Far Side in FreshRSS, too? I’ve got a recipe for that!
Do you know of a way to handle infinite scroll sites?
@No Body:
Shouldn’t be difficult, although probably not necessary for most people either (the most-recent content is usually at the top, so as long as your RSS polling interval is frequent enough you won’t need to see what’s past-the-scroll). But –
The ideal way would be to use your browser’s debugger to decipher what happens when you scroll. Presumably there’s an ajax request for more data which comes probably either as HTML or JSON, which then gets rendered to the page. And then implement an (RSSey?) script to poll that (constructed) address a few times. I basically did this for my old Far Side RSS generator, for which multiple pages needed polling IIRC.
An alternative way would be to use RSSey to script the puppeteer-powered browser to scroll to the bottom, wait a bit, repeat as needed, then parse the contents.
You probably can’t handle infinite scroll using FreshRSS alone, though. But again: most folks probably wouldn’t need to!
Hey, this is great! Thanks for this and the Forward comic one, I set them up in my FreshRSS install and they’re working great!
Any chance you’ve figured something out for the new stuff on The Far Side website? That one doesn’t even have a static new page, so it’s pretty thoroughly defeated me at every turn.
Hadn’t even noticed there was new stuff! I’ll take a look some day!
Yeah, it’s sporadic and there’s not a ton of it, but I’m not gonna complain about new Far Sides!
Yup, it’s absolutely achievable. I just knocked something together in about 20 minutes. Thanks for letting me know they existed!
I’ll publish an article to my blog within the next 24 hours explaining how it’s done. Why not subscribe to my RSS feed to hear about it as soon as I do? My RSS can be a little high-traffic, so if you just want the articles (longer-form stuff published here first and usually with a little research, unlike my checkins, notes etc.) you can get an RSS feed of just my articles… just sayin’!
Awesome, I’ll look out for it! As a diehard devotee of RSS feeds, I definitely appreciate that you have multiple RSS options for your site!
First off, huge thanks for posting this, I am currently testing out FreshRSS and my old way of getting the Farside feed didn’t work in FreshRSS so when googling for alternatives I stumbled across your posts. I am hosting your php script and seem to have it mostly working now. However, I seem to be getting a large empty space followed by the caption and then followed by the thumbnail. I am assuming the empty space is the empty placeholder for the comic itself as they look to be about the same size. Trying to suss out a way to hide the empty space. I tried changing the // Item content: descendant::div[@class=”card-body”] // to something referencing more specifically the caption class which did appear to hide the blank space but also hid the caption as well which isn’t ideal as the caption is needed on some of the comics.
So I kind of fixed this, I changed the // Item content: descendant::div[@class=”card-body”] // to // Item content: descendant::figure[@class=”figure tfs-comic__caption”] // but I noticed some comics not loading in but I also think this may have been an issue with the original settings as well. I know when I first set it up, nothing loaded in until the next day and then some showed up.
Thats all to techical for me how can i just get it sent to my tablet a bit easier
@David: Don’t know! When I have a technical problem I come up with a technical solution. If I think it might help others, I share it.
If I’ve found the same problem as somebody else but not the right solution for them… then I hope that when they find the right solution for them that they share it, too!