As I’ve mentioned before, I’m a fan of Tailsteak‘s Forward comic. I’m not a fan of the author’s weird aversion to RSS, so I hacked a way around it first using an exploit in webcomic reader app Comic Chameleon (accidentally getting access to comics weeks in advance of their publication as a side-effect) and later by using my own tool RSSey.
But now I’m able to use my favourite feed reader FreshRSS to scrape websites directly – like I’ve done for The Far Side – I should switch to using this approach to subscribe to Forward, too:

Here’s the settings I came up with –
-
Feed URL:
http://forwardcomic.com/list.php -
Type of feed source:
HTML + XPath (Web scraping) -
XPath for finding news items:
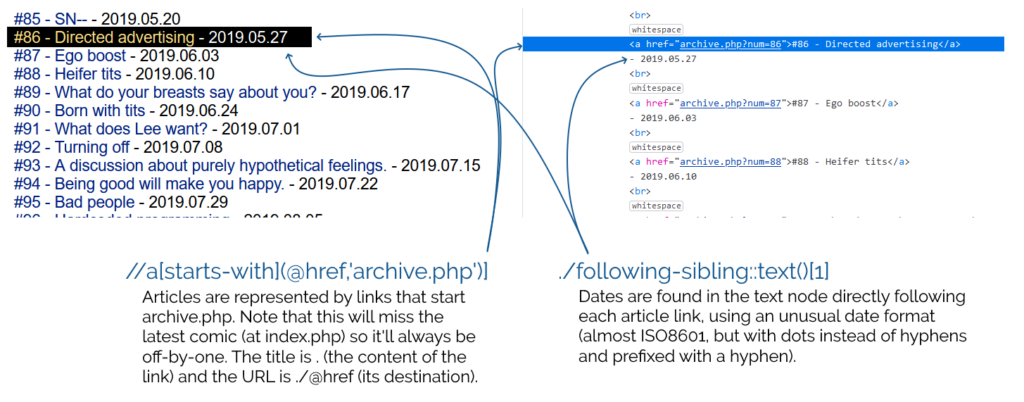
//a[starts-with(@href,'archive.php')] -
Item title:
. -
Item link (URL):
./@href -
Item date:
./following-sibling::text()[1] -
Custom date/time format:
- Y.m.d
<a>s
separated by <br>s rather than a <ul> and <li>s, for example, leaves something to be desired (and makes it harder to scrape,
too!).
I continue to love this “killer feature” of FreshRSS, but I’m beginning to see how it could go further – I wish I had the free time to contribute to its development!
I’d love to see a mechanism for exporting/importing feed configurations like this so that I could share them more-easily, for example. I’d also be delighted if I could expand on my XPath rules to load pages referenced by the results and get data from them, too, e.g. so I could use an image found by XPath on the “item link” page as the thumbnail image! These are things RSSey could do for me, but FreshRSS can’t… yet!
Nice article, again!
If you grab this fix https://github.com/FreshRSS/FreshRSS/pull/5238 (soon in edge), you can export the XPath settings of a feed as OPML by just adding `&a=opml` to the URL (no UI yet), like https://freshrss.example.net/i/?get=f_123&a=opml
Feedback welcome!
P.S. If you you use the “item thumbnail” XPath field, you should be able to get your thumbnail. If not, please open a ticket with a bit more info.
And you can load content from pages referenced by the results by taking advantage of our built-in function to add more content to truncated RSS feeds (option “Article CSS selector on original website”). 🤓
Hey, this is working great, except the updates always point to the previous comic. Is that happening for you too, or did I somehow mess something up? It still serves the same function at the end of the day, it just means one extra click to get to the new stuff.