This week, with help from Robin and JTA, I
built a TropicTemple Tall XXL climbing frame in the garden of our new house. Manufacturer Fatmoose provided us with a pallet-load of lumber and a sack of accessories,
delivered to our driveway, based on a design Ruth and I customised using their website, and we assembled it on-site over the course of around
three days. The video above is a timelapse taken from our kitchen window using a tablet I set up for that purpose, interspersed with close-up snippets of us assembling it and of the
children testing it out.
You can explore the play equipment in VR, if you like.
I’ve also built a Virtual Tour so you can explore the playframe using your computer, phone, or VR headset. Take a look!
This last month or so, my digital life has been dramatically improved by Syncthing. So much so that I want to tell you about it.
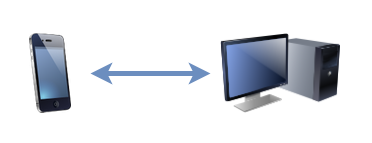
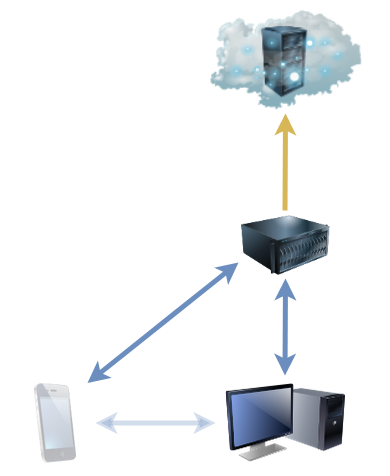
1.25TiB of data is automatically kept in sync between (depending on the data in question) a desktop PC, NAS, media centre, and phone. This computer’s using the Synctrayzor system tray app.
I started using it last month. Basically, what it does is keeps a pair of directories on remote systems “in sync” with one another. So far, it’s like your favourite cloud
storage service, albeit self-hosted and much-more customisable. But it’s got a handful of killer features that make it nothing short of a dream to work with:
The unique identifier for a computer can be derived from its public key. Encryption comes free as part of the verification of a computer’s identity.
You can share any number of folders with any number of other computers, point-to-point or via an intermediate proxy, and it “just works”.
It’s super transparent: you can always see what it’s up to, you can tweak the configuration to match your priorities, and it’s open source so you can look at the engine if you like.
Here are some of the ways I’m using it:
Keeping my phone camera synced to my PC
I’ve tried a lot of different solutions for this over the years. Back in the way-back-when, like everybody else in those dark times, I used to plug my phone in using a cable to copy
pictures off and sort them. Since then, I’ve tried cloud solutions from Google, Amazon, and Flickr and never found any that really “worked” for me. Their web interfaces and apps tend to
be equally terrible for organising or downloading files, and I’m rarely able to simply drag-and-drop images from them into a blog post like I can from Explorer/Finder/etc.
At first, I set this up as a one-way sync, “pushing” photos and videos from my phone to my desktop PC whenever I was on an unmetered WiFi network. But then I switched it to a two-way
sync, enabling me to more-easily tidy up my phone of old photos too, by just dragging them from the folder that’s synced with my phone to my regular picture storage.
Centralising my backups
Now I’ve got a fancy NAS device with tonnes of storage, it makes sense to use it as a central
point for backups to run fom. Instead of having many separate backup processes running on different computers, I can just have each of them sync to the NAS, and the NAS can back everything up. Computers don’t need to be “on” at a particular
time because the NAS runs all the time, so backups can use the Internet connection when it’s quietest. And in the event of a
hardware failure, there’s an up-to-date on-site backup in the first instance: the cloud backup’s only needed in the event of accidental data deletion (which could be sync’ed already, of
course!). Plus, integrating the sync with ownCloud running on the NAS gives easy access to
my files wherever in the world I am without having to fire up a VPN or otherwise remote-in to my house.
Plus: because Syncthing can share a folder between any number of devices, the same sharing mechanism that puts my phone’s photos onto my main desktop can simultaneously be
pushing them to the NAS, providing redundant connections. And it was a doddle to set up.
Maintaining my media centre’s screensaver
Since the NAS, running Jellyfin, took on most of the media management jobs previously
shared between desktop computers and the media centre computer, the household media centre’s had less to do. But one thing that it does, and that gets neglected, is showing a
screensaver of family photos (when it’s not being used for anything else). Historically, we’ve maintained the photos in that collection via a shared network folder, but then you’ve got
credential management and firewall issues to deal with, not to mention different file naming conventions by different people (and their devices).
But simply sharing the screensaver’s photo folder with the computer of anybody who wants to contribute photos means that it’s as easy as copying the picture to a particular place. It
works on whatever device they care to (computer, tablet, mobile) on any operating system, and it’s quick and seamless. I’m just using it myself, for now, but I’ll be offering it to the
rest of the family soon. It’s a trivial use-case, but once you’ve got it installed it just makes sense.
In short: this month, I’m in love with Syncthing. And maybe you should be, too.
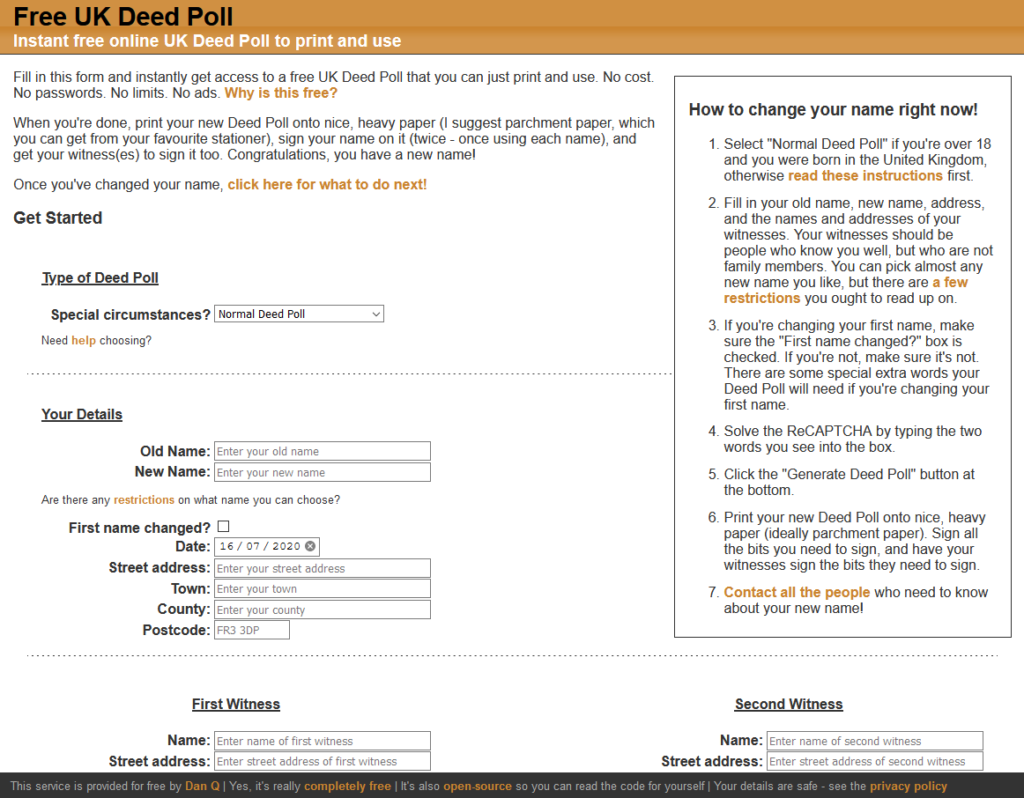
For most of the last decade, one of my side projects has been FreeDeedPoll.org.uk, a website that helps British adults to change their name
for free and without a solicitor. Here’s a little known fact: as a British citizen, you have the right to be known by virtually any name you like, and for most people the
simplest way to change it is to write out a deed poll: basically a one-person contract on which you promise that you’re serious about adopting your new name and you’re not committing
fraud or anything.
This web design looked dated when I made it and hasn’t gotten any younger, but the content remains valid as ever.
Over that time, I’ve helped thousands of people to change their names. I don’t know exactly how many because I don’t keep any logs, but I’ve always gotten plenty of email from people
about the project. Contact spiked in 2013 after the Guardian ran an article about it, but I still correspond with two or three people in a typical week.
These people have lots of questions that come up time and time again, and if I had more free time I’d maintain an FAQ
of them or something. In any case, a common one is people asking for advice when their high street bank, almost invariably either Nationwide or Santander, disputes the legitimacy of a
“home made” deed poll and refuses to accept it.
You’d think that Santander of all people would appreciate how important it is to have your legitimate change of name respected. Hang on… haven’t I joked about their rebranding before?
When such people contact me, I advise them of a number of solutions and workarounds. Going to a different branch can work (training at these high street banks is internally
inconsistent, I guess?). Getting your government-issued identity documents sorted and then threatening to move your account elsewhere can sometimes work. For applicants willing to spend
a little money, paying a solicitor a couple of quid to be one of your witnesses can work. I often don’t hear back from people who email me about these banks: maybe they find
success by one of these routes, or maybe they give up and go down one an unnecessarily-expensive avenue.
But one thing I always put on the table is the possibility of fighting. I provide a playbook of strategies to try to demonstrate to their troublemaking bank that the bank is in the
wrong, along with all of the appropriate legal citations. Recent years put a new tool in the box: the GDPR/DPA2018, which contains clauses prohibiting companies from knowingly
retaining incorrect personal data about an individual. I’ve been itching for a chance to use these new weapons… and over this last month, I finally had the opportunity.
Print this. Sign here. That’s pretty-much all there is to it.
I was recently contacted by a student (who, as you might expect, has more free time than they do spare money!) who was having trouble with Santander refusing to accept their deed poll.
They were willing to go all-out to prove their bank wrong. So I gave them the toolbox and they worked through it and… Santander caved!
Not only have Santander accepted that they were wrong in the case of this student, but they’ve also committed to retraining their staff. Oh, and they’ve paid compensation to
the student who emailed me.
Even from my position on the sidelines, I couldn’t help but cheer at this news, and not just because I’ll hopefully have fewer queries to deal with.
As always seems to happen when I move house, a piece of computer hardware broke for me during my recent house move. It’s always
exactly one piece of hardware, like it’s a symbolic recognition by the universe that being lugged around, rattling around and butting up against one another, is not the natural
state of desktop computers. Nor is it a comfortable journey for the hoarder-variety of geek nervously sitting in front of them, tentatively turning their overloaded vehicle around each
and every corner. UserFriendly said it right in this comic from 2003.
This time around, it was one of the hard drives in Renegade, my primary Windows-running desktop, that failed. (At least I didn’t break
myself, this time.)
Here’s the victim of my latest move. Rest in pieces.
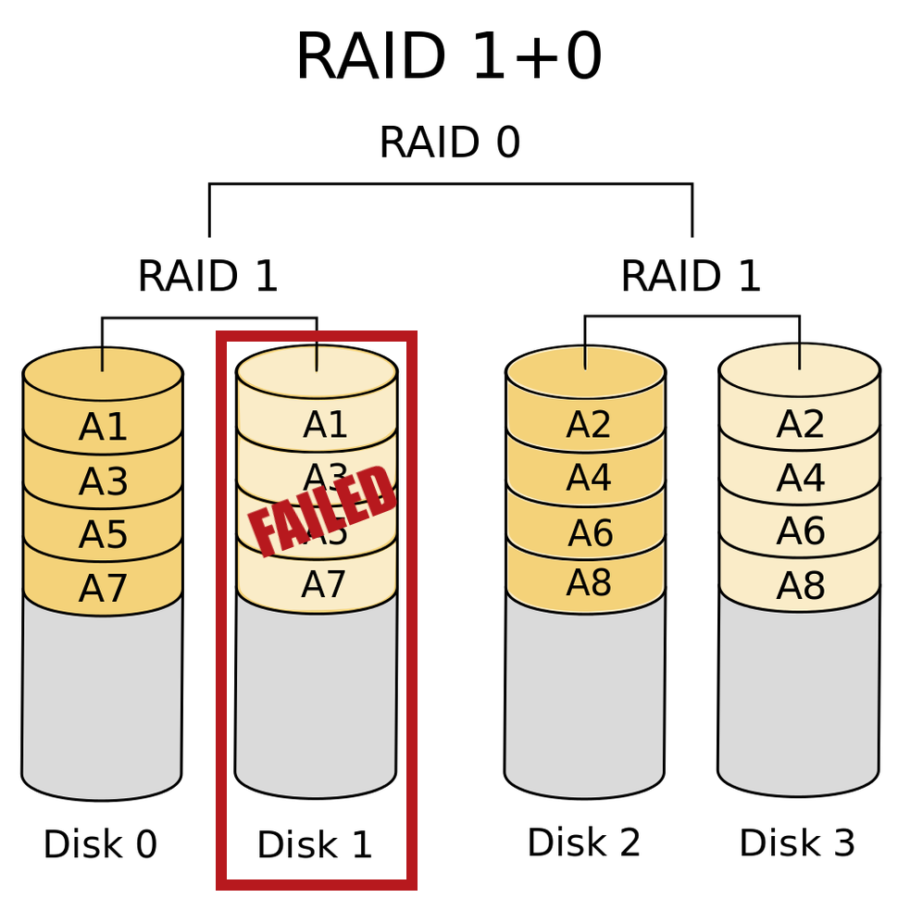
Fortunately, it failed semi-gracefully: the S.M.A.R.T. alarm went off about a week before it actually started causing real problems, giving me at least a little time to prepare, and
– better yet – the drive was part of a four-drive RAID 10 hot-swappable array, which means that every single byte of data on that drive was already duplicated to a second drive.
Incidentally, this configuration may have indirectly contributed to its death: before I built Fox, our new household NAS, I used Renegade for many of the same purposes, but WD Blues are not really a “server grade” hard
drive and this one and its siblings will have seen more and heavier use than they might have expected over the last few years. (Fox, you’ll be glad to hear, uses much better-rated
drives for her arrays.)
Set up your hard drives like this and you can lose at least one, and up to half, of the drives without losing data.
So no data was lost, but my array was degraded. I could have simply repaired it and carried on by adding a replacement similarly-sized hard drive, but my needs have changed now that Fox
is on the scene, so instead I decided to downgrade to a simpler two-disk RAID 1 array for important data and an
“at-risk” unmirrored drive for other data. This retains the performance of the previous array at the expense of a reduction in redundancy (compared to, say, a three-disk RAID 5 array which would have retained redundancy at the expense of performance). As I said: my needs have changed.
Fixing Things… Fast!
In any case, the change in needs (plus the fact that nobody wants watch an array rebuild in a different configuration on a drive with system software installed!) justified a
reformat-and-reinstall, which leads to the point of this article: how I optimised my reformat-and-reinstall using Chocolatey.
Not this kind of chocolatey, I’m afraid. Man, I shouldn’t have written this post before breakfast.
Chocolatey is a package manager for Windows: think like apt for
Debian-like *nices (you know I do!) or Homebrew for MacOS. For previous Windows system
rebuilds I’ve enjoyed the simplicity of Ninite, which will build you a one-click installer for your choice of many of your favourite tools, so you can
get up-and-running faster. But Chocolatey’s package database is much more expansive and includes bonus switches for specifying particular versions of applications, so it’s a clear
winner in my mind.
If you learn only one thing about me from this post, let it be that I’m a big fan of redundancy. Here’s the printed version of my reinstallation list. Y’know, in case the copy on a
pendrive failed.
So I made up a Windows installation pendrive and added to it a “script” of things to do to get Renegade back into full working order. You can read the full script here, but the essence of it was:
Reconfigure the RAID array, reformat, reinstall Windows, and create an account.
Configuration (e.g. set up my unusual keyboard mappings, register software, set up remote connections and backups, etc.).
By scripting virtually all of the above I was able to rearrange hard drives in and then completely reimage a (complex) working Windows machine with well under an hour of downtime; I can
thoroughly recommend Chocolatey next time you have to set up a new Windows PC (or just to expand what’s installed on your existing one). There’s a GUI if you’re not a fan of the command line, of course.
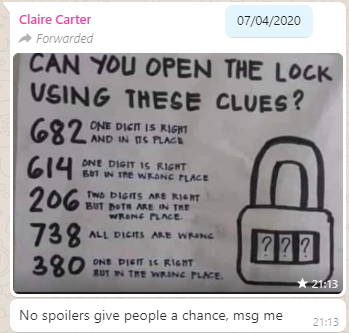
About three months ago, my friend Claire, in a WhatsApp group we both frequent, shared a brainteaser:
Was this way back at the beginning of April? Thank heavens for WhatsApp scrollback.
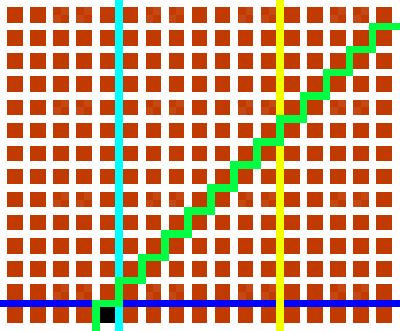
The puzzle was to be interpreted as follows: you have a three-digit combination lock with numbers 0-9; so 1,000 possible combinations in total. Bulls and Cows-style, a series of clues indicate how “close” each of several pre-established “guesses” are. In “bulls and
cows” nomenclature, a “bull” is a correctly-guessed digit in the correct location and a “cow” is a correctly-guessed digit in the wrong location, so the puzzle’s clues are:
682 – one bull
614 – one cow
206 – two cows
738 – no bulls, no cows
380 – one cow
Feel free to stop scrolling at this point and solve it for yourself. Or carry on; there are no spoilers in this post.
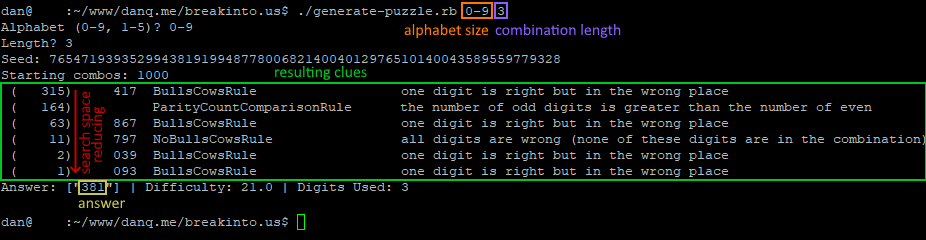
By the time I’d solved her puzzle the conventional way I was already interested in the possibility of implementing a general-case computerised solver for this kind of puzzle, so I did.
My solver uses a simple “brute force” technique, as follows:
Put all possible combinations into a search space.
For each clue, remove from the search space all invalid combinations.
Whatever combination is left is the correct answer.
The first three clues of Claire’s puzzle are sufficient alone to reduce the search space to a single answer, although a human is likely to need more.
Visualising the solver as a series of bisections of a search space got me thinking about something else: wouldn’t this be a perfectly reasonable way to programatically generate
puzzles of this type, too? Something like this:
Put all possible combinations into a search space.
Randomly generate a clue such that the search space is bisected (within given parameters to ensure that neither too many nor too few clues are needed)
Repeat until only one combination is left
Interestingly, this approach is almost the opposite of what a human would probably do. A human, tasked with creating a puzzle of this sort, would probably choose the answer
first and then come up with clues that describe it. Instead, though, my solution would come up with clues, apply them, and then see what’s left-over at the end.
Sometimes it comes up with inelegant or unchallenging suggestions, but for the most part my generator produces adequate puzzles.
I expanded my generator to go beyond simple bulls-or-cows clues: it’s also capable of generating clues that make reference to the balance of odd and even digits (in a numeric lock), the
number of different digits used in the combination, the sum of the digits of the combination, and whether or not the correct combination “ascends” or “descends”. I’ve ideas for
other possible clue types too, which could be valuable to make even tougher combination locks: e.g. specifying how many numbers in the combination are adjacent to a consecutive number,
specifying the types of number that the sum of the digits adds to (e.g. “the sum of the digits is a prime number”) and so on.
Like the original puzzle, puzzles produced by my generator might have redundancies. In the picture above, the black square can be defined by the light blue, dark blue, and green
bisections only: the yellow bisection is rendered redundant by the light blue one. I’ve left this as a deliberate feature.
Next up, I wanted to make a based interface so that people could have a go at the puzzles in their web browser, track their progress through the levels, get a “score” based on the
number and difficulty of the locks that they’d cracked (so they can compare it to their friends), and save their progress to carry on next time.
I implemented in pure vanilla HTML, CSS, SVG and JS, with no dependencies. Compressed, it delivers to your browser and is ready-to-play in a little
under 10kB, most of which is the puzzles themselves (which are pregenerated and stored in a JSON file). Naturally, it lends itself well to running offline, so it’s PWA-enhanced with a
service worker so it can be “installed” onto your device, too, and it’ll check for bonus puzzles and other updates periodically.
Naturally, the original puzzle appears in the web-based game, too.
Honestly, the hardest bit of implementing the frontend was the “spinnable” digits: depending on your browser, these are an endless-scrolling <ul> implemented mostly in
CSS and with snap points set, and then some JS to work out “what you meant” based on
where you span to. Which feels like the right way to implement such a thing, but was a lot more work than putting together my own control, not least because of browser
inconsistencies in the implementation of snap points.
Anyway: you should go and play the game, now, and let me know what you think. Is it worth expanding and improving? Should I leave it as it is? I’m
open to ideas (and if you don’t like that I’m not implementing your suggestions, you can always fork a copy of the code and change
it yourself)!
Seven years ago, I wrote a six-part blog series (1, 2, 3, 4, 5, 6) about our Ruth, JTA and I’s experience of buying our first house. Now, though, we’re moving again, and it’s brought up all the same kinds of challenges and
stresses as last time, plus a whole lot of bonus ones to boot.
Our old house – seen here in 2013 – has served its purpose. It’s time for us to move on.
In particular, new challenges this time around have included:
As owners, rather than renters, we’ve had both directions on the ladder to deal with. Not only did we have to find somewhere to move to that we can afford but we needed to find
somebody who’d buy our current house (for enough money that we can afford the new place).
The first letting agents we appointed were pretty useless, somehow managing to get us no viewings whatsoever. Incidentally their local branch
got closed soon after we ditched them and the last time I checked, the building was still up for sale: it doesn’t bode well for them that they can’t even sell their own
building, does it?
The replacement letting agents (who sold us this house in the first place) were much better, but it still took a long time before we started
getting offers we could act on.
We finally selected some buyers, accepting a lower offer because they were cash buyers and it would allow us to act quickly on the property we wanted to buy, only for the
coronavirus lockdown to completely scupper our plans of a speedy move. And make any move a logistical nightmare.
Plus: we’re now doing this with lots more stuff (this won’t be a “rally some friends and rent a van” job like
last time!), with two kids (who’re under our feet a lot on account of the lockdown), and so on.
We added significant value to our old house during the time we owned it, for example by installing solar panels which continue to generate income as well as “free” energy. As well as being now conveniently close to a train line to London which I suppose would be good
for commuters even though we’ve mostly used it for fun.
But it’s finally all coming together. We’ve got a house full of boxes, mind, and we can’t find anything, and somehow it still doesn’t feel like we’re prepared for when the
removals lorry comes later this week. But we’re getting there. After a half-hour period between handing over the keys to the old place and picking up the keys to the new place (during
which I guess we’ll technically be very-briefly homeless) we’ll this weekend be resident in our new home.
Our new home’s pretty delightful. I’ll vlog you a tour or something once we’re moved in, under the assumption that a housewarming party is still likely to be rendered impossible by
coronavirus.
Our new house will:
Be out in the fabulous West Oxfordshire countryside.
Have sufficient rooms to retain an office and a “spare” bedroom while still giving the kids each their own bedroom.
Boast a fabulously-sized garden (we might have already promised the kids a climbing frame).
Have an incredible amount of storage space plus the potential for further expansion/conversion should the need ever arise. (On our second-to-last visit to the place with discovered
an entire room, albeit an unfinished one, that we hadn’t known about before!)
Get ludicrously fast Internet access.
We lose some convenient public transport links, but you can’t have everything. And with me working from home all the time, Ruth –
like many software geeks – likely working from home for the foreseeable future (except when she cycles into work), and JTA working from
home for now but probably returning to what was always a driving commute “down the line”, those links aren’t as essential to us as they once were.
Sure: we’re going to be paying for it for the rest of our lives. But right now, at least, it feels like what we’re buying is a house we could well live in for the rest of our
lives, too.
It had been a long while since our last murder mystery party: we’ve only done one or two “kit” ones since we moved in to our current
house in 2013, and we’re long-overdue a homegrown one (who can forget the joy of Murder at the Magic College?), but in
the meantime – and until I have the time and energy to write another one of my own – we thought we’d host another.
But how? Courtesy of the COVID-19 crisis and its lockdown, none of our friends could come to visit. Technology to the rescue!
Not being in the same room doesn’t protect you from finger-pointing.
I took a copy of Michael Akers‘ murder mystery party plan, Sour Grapes of Wrath, and used it as the basis for Sour Grapes, a digitally-enhanced (and generally-tweaked) version of the same story, and recruited Ruth, JTA, Jen, Matt R, Alec and Suz to perform the parts. Given that I’d had to adapt the materials
to make them suitable for our use I had to assign myself a non-suspect part and so I created police officer (investigating the murder) whose narration provided a framing device for the
scenes.
Actually, the interface didn’t work as well on an iPhone as I’d have expected, but I ran short on testing time.
I threw together a quick Firebase backend to allow data to be synchronised across a web application, then wrote a couple of dozen lines of
Javascript to tie it together. The idea was that I’d “push” documents to each participants’ phone as they needed them, in a digital analogue of the “open envelope #3” or “turn to the
next page in your book” mechanism common in most murder mystery kits. I also reimplemented all of Akers’ artefacts, which were pretty-much text-only, as graphics, and set up a system
whereby I could give the “finder” of each clue a copy in-advance and then share it with the rest of the participants when it was appropriate, e.g. when they said, out loud “I’ve found
this newspaper clipping that seems to say…”
The party itself took place over Discord video chat, with which I’d recently had a good experience in an experimental/offshoot Abnib group (separate from our normal WhatsApp space) and
my semi-associated Dungeons & Dragons group. There were a few technical hiccups, but only what you’d expect.
Meanwhile, I had a web page with all kinds of buttons and things to press.
The party itself rapidly descended into the usual level of chaos. Lots of blame thrown, lots of getting completely off-topic and getting distracted solving the wrong puzzles, lots of
discussion about the legitimacy of one of several red herrings, and so on. Michael Akers makes several choices in his writing that don’t appear in mine – such as not revealing the
identity of the murderer even to the murderer until the final statements – which I’m not a fan of but retained for the sake of honouring the original text, but if I were to run
a similar party again I’d adapt this, as I had a few other aspects of the setting and characters. I think it leads to a more fun game if, in the final act, the murderer knows that they
committed the crime, that all of the lies they’ve already told are part of their alibi-building, and they’re given carte blanche to lie as much as they like in an effort to
“get away with it” from then on.
Much love was shown for the “catering”.
Of course, Ruth felt the need to cater for the event – as she’s always done with spectacular effect at every previous murder mystery she’s hosted or we’ve collectively hosted – despite
the distributed partygoers. And so she’d arranged for a “care package” of wine and cheese to be sent to each household. The former was, as always, an excellent source of social
lubrication among people expected to start roleplaying a random character on short notice; the latter a delightful source of snacking as we all enjoyed the closest thing we’ll get to a
“night out” in many months.
This was highly experimental, and there are lessons-for-myself I’d take away from it:
If you’re expecting people to use their mobiles, remember to test thoroughly on mobiles. You’d think I’d know this, by now. It’s only, like, my job.
When delivering clues and things digitally, keep everything in one place. Switching back and forth between the timeline that supports your alibi and the new
information you’ve just learned is immersion-breaking. Better yet, look into ways to deliver physical “feelies” to people if it’s things that don’t need sharing, and consider ways to
put shared clues up on everybody’s “big screen”.
Find time to write more murder mysteries. They’re much better than kit-style ones; I’ve got a system and it works. I really shout get around to writing up
how I make them, some day; I think there’s lessons there for other people who want to make their own, too.
Those who know me may be surprised to hear that the majority of my work planning an original murder mystery plot, even a highly-digital one like Murder… on the Social
Network, happens on paper.
Meanwhile: if you want to see some moments from Sour Grapes, there’s a mini YouTube
playlist I might get around to adding to at some point. Here’s a starter if you’re interested in what we got up to (with apologies for the audio echo, which was caused by a problem
with the recording software):
When the COVID-19 lockdown forced many offices to close and their staff to work remotely, some of us saw what was unfolding as
an… opportunity in disguise. Instead of the slow-but-steady
decentralisation of work that’s very slowly become possible (technically, administratively, and politically) over the last 50 years, suddenly a torrent of people were discovering that
remote working can work.
Unfulfilled promises of the world of tomorrow include flying cars, viable fusion power, accessible space travel, post-scarcity economies, and – until recently – widespread
teleworking. Still waiting on my holodeck too.
The Future is Now
As much as I hate to be part of the “where’s my flying car?” brigade, I wrote ten years ago about my dissatisfaction that remote
working wasn’t yet commonplace, let alone mainstream. I recalled a book I’d read as a child in the 1980s that promised a then-future 2020 of:
near-universal automation of manual labour as machines become capable of an increasing diversity of human endeavours (we’re getting there, but slowly),
a three- or four-day work week becoming typical as efficiency improvements are reinvested in the interests of humans rather than of corporations (we might have lost sight of that
goal along the way, although there’s been some fresh interest
in it lately), and
widespread “teleworking”/”telecommuting”, as white-collar sectors grow and improvements in computing and telecommunications facilitate the “anywhere office”
Of those three dreams, the third soon seemed like it would become the most-immediate. Revolutionary advances in mobile telephony, miniaturisation of computers, and broadband networking
ran way ahead of the developments in AI that might precipitate the first dream… or the sociological shift required for
the second. But still… progress was slow.
At eight years old, I genuinely believed that most of my working life would be spent… wherever I happened to be. So far, most of my working life has been spent in an office, despite
personally working quite hard for that not to be the case!
Apply directly to the head! Commuting looks different today than it did last year, but at least the roads are quieter.
I started at Automattic six months ago, an entirely distributed company. And so when friends and colleagues found themselves required to work
remotely by the lockdown they came in droves to me for advice about how to do it! I was, of course, happy to help where I could: questions often
covered running meetings and projects, maintaining morale, measuring output, and facilitating communication… and usually I think I gave good answers. Sometimes, though, the
answer was “If you’re going to make that change, you’re going to need a cultural shift and some infrastructure investment first.” Y’know: “Don’t start from here.” If you received that advice from me: sorry!
(Incidentally, if you have a question I haven’t answered yet, try these clever people first for even better
answers!)
More-recently, I was excited to see that many companies have adopted this “new normal” not as a temporary measure,
but as a possible shape of things to come. Facebook, Twitter, Shopify, Square, and Spotify have all announced that they’re going to permit or encourage remote work as standard, even
after the crisis is over.
Obviously tech companies are leading the way, here: not only are they most-likely to have the infrastructure and culture already in place to support this kind of shift. Also, they’re
often competing for the same pool of talent and need to be seen as at-least as progressive as their direct rivals. Matt
Mullenweg observes that:
What’s going to be newsworthy by the end of the year is not technology companies saying they’re embracing distributed work, but those that aren’t.
…some employers trapped in the past will force people to go to offices, but the illusion that the office was about work will be shattered forever, and companies that
hold on to that legacy will be replaced by companies who embrace the antifragile nature of distributed organizations.
I’ve shared this before, I know, but it exudes Matt’s enthusiasm for distributed work so well that I’m sharing it again. Plus, some of the challenges I describe below map nicely to
the borders between some of
Tomorrow’s Challenges
We’re all acutely familiar with the challenges companies are faced with today as they adapt to a remote-first environment. I’m more interested in the challenges that
they might face in the future, as they attempt to continue to use a distributed workforce as the pandemic recedes. It’s easy to make the mistake of assuming that what many
people are doing today is a rehearsal for the future of work, but the future will look different.
Some people, of course, prefer to spend some or all of their work hours in an office environment. Of the companies that went remote-first during the lockdown and now plan to
stay that way indefinitely, some will lose employees who
preferred the “old way”. For this and other reasons, some companies will retain their offices and go remote-optional, allowing flexible teleworking, and this has it’s own
pitfalls:
Some remote-optional offices have an inherent bias towards in-person staff. In some companies with a mixture of in-person and remote staff, remote workers don’t get
included in ad-hoc discussions, or don’t become part of the in-person social circles. They get overlooked for projects or promotions, or treated as second-class citizens. It’s easy to
do this completely by accident and create a two-tiered system, which can lead to a cascade effect that eventually collapses the “optional” aspect of remote-optional; nowhere was this
more visible that in Yahoo!’s backslide against remote-optional working in 2013.
Some remote-optional offices retain an archaic view on presenteeism and “core hours”. Does the routine you keep really matter? Remote-first working demands that
productivity is measured by output, not by attendance, but management-by-attendance is (sadly) easier to implement, and
some high-profile organisations favour this lazy but less-effective approach. It’s easy, but ineffective, for a remote-optional company to simply extend hours-counting performance
metrics to their remote staff. Instead, allowing your staff (insofar as is possible) to work the hours that suit them as individuals opens up your hiring pool to a huge number of
groups whom you might not otherwise reach (like single parents, carers, digital nomads, and international applicants) and helps you to get the best out of every one of them, whether
they’re an early bird, a night owl, or somebody who’s most-productive after their siesta!
Pastoral care doesn’t stop being important after the crisis is over. Many companies that went remote-first for the coronavirus crisis have done an excellent job of
being supportive and caring towards their employees (who, of course, are also victims of the crisis: by now, is there anybody whose life hasn’t been impacted?). But when
these companies later go remote-optional, it’ll be easy for them to regress to their old patterns. They’ll start monitoring the wellbeing only of those right in front of
them. Remote working is already challenging, but it can be made much harder if your company culture makes it hard to take a sick day, seek support on a HR issue, or make small-talk with a colleague.
On the Internet, nobody knows that you’re only properly-dressed from the waist up. No, wait: as of 2020, everybody knows that. Let’s just all collectively own it, ‘k.
These are challenges specifically for companies that go permanently remote-optional following a period of remote-first during the coronavirus crisis.
Towards a Post-Lockdown Remote-Optional Workplace
How you face those challenges will vary for every company and industry, but it seems to me that there are five lessons a company can learn as it adapts to remote-optional work in a
post-lockdown world:
Measure impact, not input. You can’t effectively manage a remote team by headcount or closely tracking hours; you need to track outputs (what is produced), not inputs
(person-hours). If your outputs aren’t measurable, make them measurable, to paraphrase probably-not-Galileo. Find metrics you can work with and rely on, keep them transparent and open, and
re-evaluate often. Use the same metrics for in-office and remote workers.
Level the playing field. Learn to spot the biases you create. Do the in-person attendees do all the talking at your semi-remote meetings? Do your remote workers have
to “call in” to access information only stored on-site (including in individual’s heads)? When
they’re small, these biases have a huge impact on productivity and morale. If they get big, they collapse your remote-optional environment.
Always think bigger. You’re already committing to a shakeup, dragging your company from the 2020 of the real world into the 2020 we once dreamed of. Can you go
further? Can you let your staff pick their own hours? Or workdays? Can your staff work in other countries? Can you switch some of your synchronous communications channels (e.g.
meetings) into asynchronous information streams (chat, blogs, etc.)? Which of your telecommunications tools
serve you, and which do you serve?
Remember the human. Your remote workers aren’t faceless (pantsless) interchangeable components in your corporate machine. Foster interpersonal relationships and don’t
let technology sever the interpersonal links between your staff. Encourage and facilitate (optional, but awesome) opportunities for networking and connection. Don’t forget to get together in-person sometimes: we’re a pack animal, and we form tribes more-easily when we
can see one another.
Support people through the change. Remote working requires a particular skillset; provide tools to help your staff adapt to it. Make training and development options
available to in-office staff too: encourage as flexible a working environment as your industry permits. Succeed, and your best staff will pay you back in productivity and loyalty.
Fail, and your best staff will leave you for your competitors.
I’m less-optimistic than Matt that effective distributed
working is the inexorable future of work. But out of the ashes of the coronavirus crisis will come its best chance yet, and I know that there’ll be companies who get left behind in
the dust. What are you doing to make sure your company isn’t one of them?
Since I accepted a job offer with Automattic last summer I’ve been writing about
my experience on a nice, round 128-day schedule. My first post described my application and recruitment process; my second post covered my induction, my initial
two weeks working alongside the Happiness team (tech support), and my first month in my role. This is the third post, running through to the end of six and a half months as an
Automattician.
Always Be Deploying
One of the things that’s quite striking about working on many of Automattic’s products, compared to places I’ve worked before, is the velocity. Their continuous integration
game is pretty spectacular. We’re not talking “move fast and break things” iteration speeds (thank heavens), but we’re still talking fast.
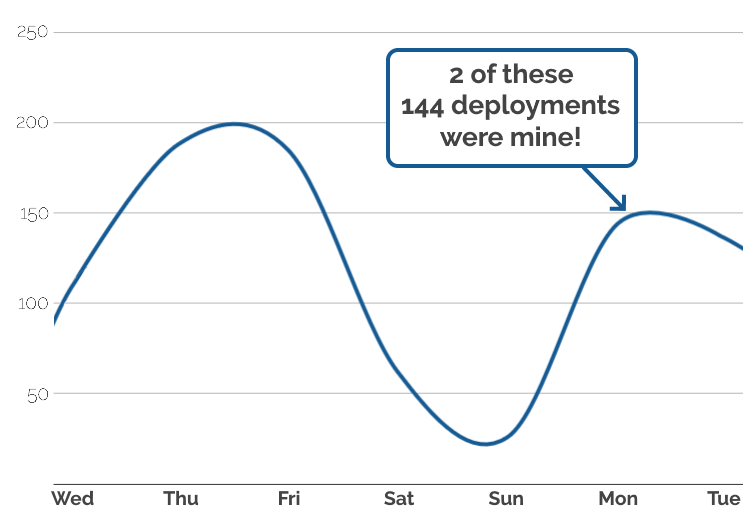
Deployments-per-day in a reasonably typical week. A minor bug slipped through in the first of the deployments I pushed on the Monday shown, so it was swiftly followed by a second
deployment (no external end-users were affected: phew!).
My team tackles a constant stream of improvements in two-week sprints, with every third sprint being a cool-down period to focus on refactoring, technical debt, quick wins, and the
like. Periodic HACK weeks – where HACK is (since
2018) a backronym for Helpful Acts in Customer Kindness – facilitate focussed efforts on improving our ecosystem and user experiences.
I’m working in a larger immediate team than I had for most of my pre-Automattic career. I’m working alongside nine other developers, typically in groups of two to four depending on the
needs of whatever project I’m on. There’s a great deal of individual autonomy: we’re all part of a greater whole and we’re all pushing in the same direction, but outside of the
requirements of the strategic goals of our division, the team’s tactical operations are very-much devolved and consensus-driven. We work out as a team how to solve the gnarly
(and fun!) problems, how to make best use of our skills, how to share our knowledge, and how to schedule our priorities.
My usual workspace looks pretty much exactly like you’re thinking that it does.
This team-level experience echoes the experience of being an individual at Automattic, too. The level of individual responsibility and autonomy we enjoy is similar to that I’ve seen
only after accruing a couple of years of experience and authority at most other places I’ve worked. It’s amazing to see that you can give a large group of people so much self-controlled
direction… and somehow get order out of the chaos. More than elsewhere, management is more to do with shepherding people into moving in the same direction than it is about dictating how
the ultimate strategic goals might be achieved.
Na na na na na na na na VAT MAN!
Somewhere along the way, I somehow became my team’s live-in expert on tax. You know how it is: you solve a bug with VAT calculation in
Europe… then you help roll out changes to support registration with the GST in Australia… and then one day you find yourself
reading Mexican digital services tax legislation and you can’t remember where the transition
was from being a general full-stack developer to having a specialisation in tax.
Before the coronavirus lockdown, though, I’d sometimes find a coworking space (or cafe, or pub!) to chill in while I worked. This one was quiet on the day I took the photo.
Tax isn’t a major part of my work. But it’s definitely reached a point at which I’m a go-to figure. A week or so ago when somebody had a question about the application of sales taxes to
purchases on the WooCommerce.com extensions store, their first thought was “I’ll ask Dan!” There’s
something I wouldn’t have anticipated, six month ago.
Automattic’s culture lends itself to this kind of selective micro-specialisation. The company actively encourages staff to keep learning new things but mostly without providing a specific direction, and this – along with their tendency to
attract folks who, like me, could foster an interest in almost any new topic so long as they’re learning something – means that my colleagues and I always seem to be
developing some new skill or other.
I ended up posting this picture to my team’s internal workspace, this week, as I looked a VAT-related calculation.
I know off the top of my head who I’d talk to about if I had a question about headless browser automation, or database index performance, or email marketing impact assessment, or queer
representation, or getting the best airline fares, or whatever else. And if I didn’t, I could probably find them. None of their job descriptions mention that aspect of their work.
They’re just the kind of people who, when they see a problem, try to deepen their understanding of it as a whole rather than just solving it for today.
A lack of pigeonholing, coupled with the kind of information management that comes out of being an entirely-distributed company, means that the specialisation of individuals becomes a
Search-Don’t-Sort problem. You don’t necessarily find an internal specialist by their job title: you’re more-likely to find them by looking for previous work on particular
topics. That feels pretty dynamic and exciting… although it does necessarily lead to occasional moments of temporary panic when you discover that something important (but short of
mission-critical) doesn’t actually have anybody directly responsible for it.
Crisis response
No examination of somebody’s first 6+ months at a new company, covering Spring 2020, would be complete without mention of that company’s response to the coronavirus crisis. Because,
let’s face it, that’s what everybody’s talking about everywhere right now.
As the UK’s lockdown (eventually) took hold I found myself
treated within my social circle like some kind of expert on remote working. My inboxes filled up with queries from friends… How do I measure output? How do I run a productive
meeting? How do I maintain morale? I tried to help, but unfortunately some of my answers relied slightly on already having a distributed culture: having the information and
resource management and teleworking infrastructure in-place before the crisis. Still, I’m optimistic that companies will come out of the other side of this situation with a
better idea about how to plan for and execute remote working strategies.
Social distancing is much easier when you’re almost never in the same room as your colleagues anyway.
I’ve been quite impressed that even though Automattic’s all sorted for how work carries on through this crisis, we’ve gone a step further and tried to organise (remote) events for
people who might be feeling more-isolated as a result of the various lockdowns around the world. I’ve seen mention of wine tasting events, toddler groups, guided meditation sessions,
yoga clubs, and even a virtual dog park (?), all of which try to leverage the company’s existing distributed infrastructure to support employees who’re affected by the pandemic. That’s
pretty cute.
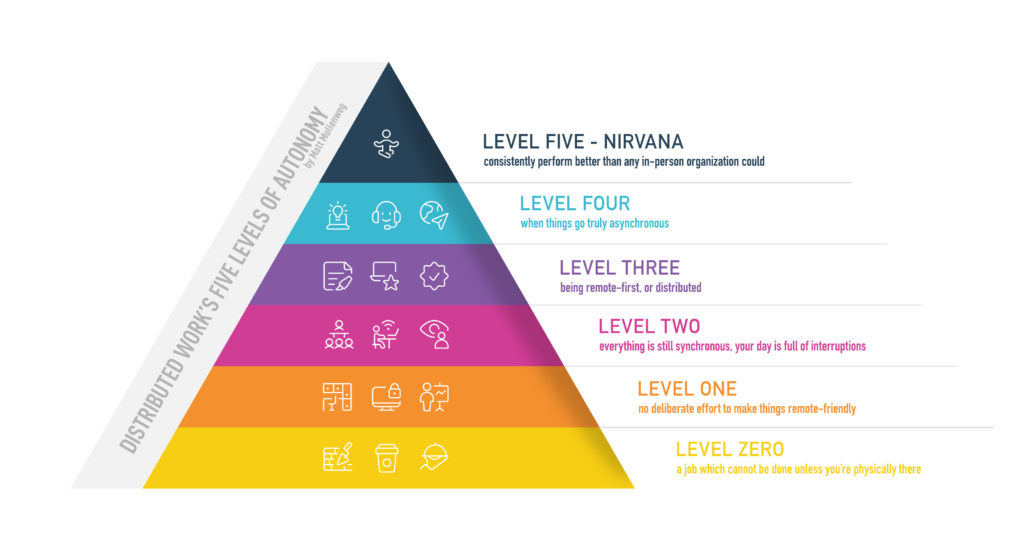
Matt shared this diagram last month, and its strata seem increasingly visible as many companies adapt (with varying levels
of success) to remote work.
In summary: Automattic’s still proving to be an adventure, I’m still loving their quirky and chaotic culture and the opportunity to learn something new every week, and
while their response to the coronavirus crisis has been as solid as you’d expect from a fully-distributed company I’ve also been impressed by the company’s efforts to support staff (in
a huge diversity of situations across many different countries) through it.
Normally this kind of thing would go into the ballooning dump of “things I’ve enjoyed on the Internet” that is my reposts archive. But sometimes something is
so perfect that you have to try to help it see the widest audience it can, right? And today, that thing is: Mackerelmedia
Fish.
Historical fact: escaped fish was one of the primary reasons for websites failing in 1996.
What is Mackerelmedia Fish? I’ve had a thorough and pretty complete experience of it, now, and I’m still not sure. It’s one or more (or none)
of these, for sure, maybe:
A point-and-click, text-based, or hypertext adventure?
A statement about the fragility of proprietary technologies on the Internet?
An ARG set in a parallel universe in which the 1990s never ended?
A series of surrealist art pieces connected by a loose narrative?
Rock Paper Shotgun’s article about it opens with “I
don’t know where to begin with this—literally, figuratively, existentially?” That sounds about right.
This isn’t the reward for “winning” the “game”. But I was proud of it anyway.
What I can tell you with confident is what playing feels like. And what it feels like is the moment when you’ve gotten bored waiting for page 20 of Argon Zark to finish appear so you decide to reread your already-downloaded copy of the 1997 a.r.k bestof book, and for a moment you think to yourself: “Whoah; this must be what living in the future
feels like!”
Because back then you didn’t yet have any concept that “living in the future” will involve scavenging for toilet paper while complaining that you can’t stream your favourite shows in 4K on your pocket-sized
supercomputer until the weekend.
I was always more of a Bouncing Blocks than a Hamster Dance guy, anyway.
Mackerelmedia Fish is a mess of half-baked puns, retro graphics, outdated browsing paradigms and broken links. And that’s just part of what makes it great.
It’s also “a short story that’s about the loss of digital history”, its creator Nathalie Lawhead
says. If that was her goal, I think she managed it admirably.
Everything about this, right down to the server signature (Artichoke), is perfect.
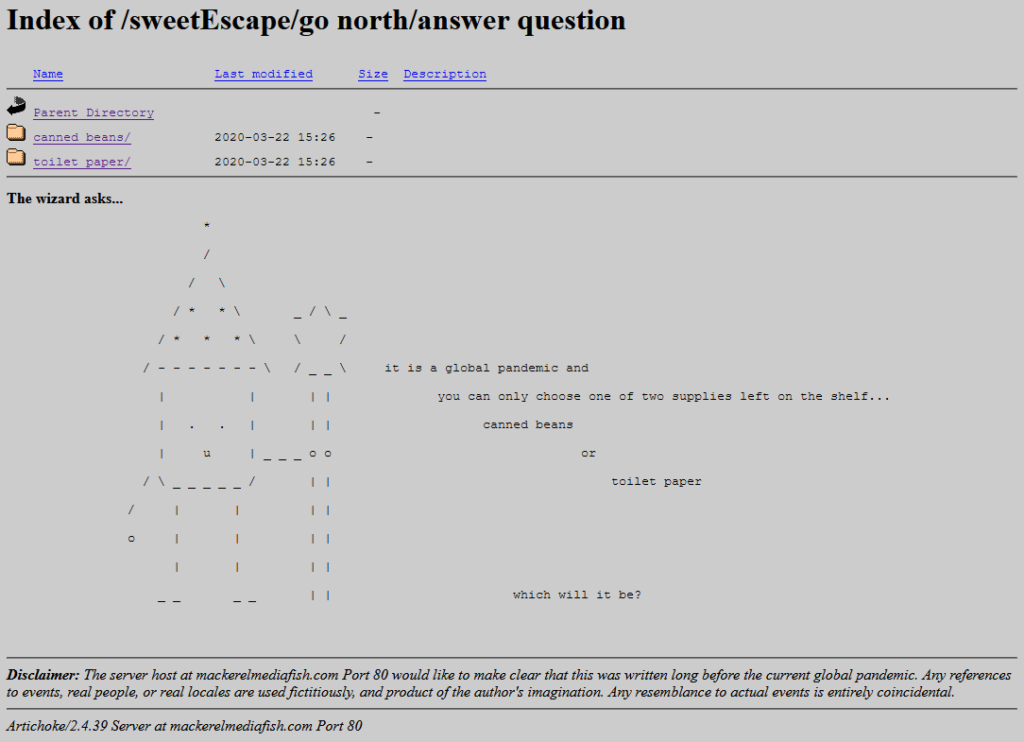
If I wasn’t already in love with the game already I would have been when I got to the bit where you navigate through the directory indexes of a series of deepening folders,
choose-your-own-adventure style. Nathalie writes, of it:
One thing that I think is also unique about it is using an open directory as a choose your own adventure. The directories are branching. You explore them, and there’s text at the
bottom (an htaccess header) that describes the folder you’re in, treating each directory as a landscape. You interact with the files that are in each of these folders, and uncover the
story that way.
Back in the naughties I experimented with making choose-your-own-adventure games in exactly this way. I was experimenting with different media by which this kind of
branching-choice game could be presented. I envisaged a project in which I’d showcase the same (or a set of related) stories through different approaches. One was “print” (or at least
“printable”): came up with a Twee1-to-PDF
converter to make “printable” gamebooks. A second was Web hypertext. A third – and this is the one which was most-similar to what Nathalie has now so expertly made real – was
FTP! My thinking was that this would be an adventure game that could be played in a browser or even from the command line on any
(then-contemporary: FTP clients aren’t so commonplace nowadays) computer. And then, like so many of my projects, the half-made
version got put aside “for later” and forgotten about. My solution involved abusing the FTP protocol terribly, but it
worked.
(I also looked into ways to make Gopher-powered hypertext fiction and toyed with the idea of using YouTube
annotations to make an interactive story web [subsequently done amazingly by Wheezy Waiter, though the death of YouTube
annotations in 2017 killed it]. And I’ve still got a prototype I’d like to get back to, someday, of a text-based adventure played entirely through your web browser’s debug
console…! But time is not my friend… Maybe I ought to collaborate with somebody else to keep me on-course.)
My first batch of pet frogs died quite quickly, but these ones did okay.
In any case: Mackerelmedia Fish is fun, weird, nostalgic, inspiring, and surreal, and you should give it a go. You’ll need to be on a Windows
or OS X computer to get everything you can out of it, but there’s nothing to stop you starting out on your mobile, I imagine.
Sso long as you’re capable of at least 800 × 600 at 256 colours and have 4MB of RAM,
if you know what I mean.
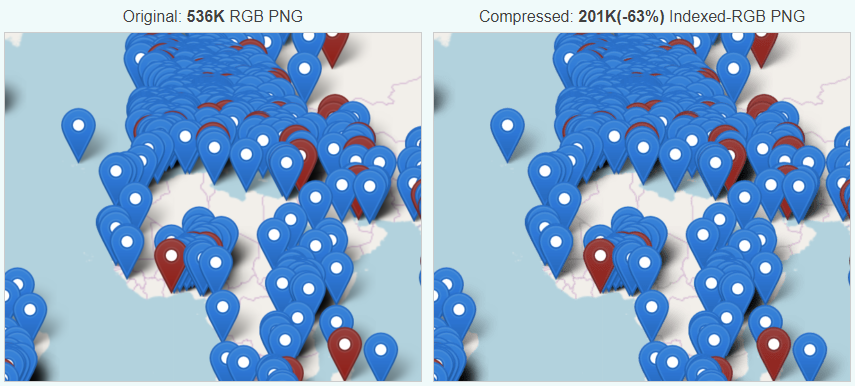
Save your bandwidth: just look at this screenshot of the site instead of visiting.
Going to that page results in about 14 Mb of data being transmitted from their server to your device (which you’ll pay for
if you’re on a metered connection). For comparison, reading my recent post about pronouns results in about 356 Kb of data. In other words, their page is forty times more bandwidth-consuming, despite the fact that my page has about four times the word count. The page
you’re reading right now, thanks to its images, weighs in at about 650 Kb: you could still download it more than twenty times while
you were waiting for theirs.
Well that’s got to be pretty embarassing.
Worse still, the most-heavyweight of the content they deliver is stuff that’s arguably strictly optional and doesn’t add to the message:
Eight different font files are served from three different domains (the fonts alone consume about 140 Kb) – seven more are
queued but not used.
Among the biggest JavaScript files they serve is that of Hotjar analytics: I understand the importance of measuring your impact, but making
your visitors – and the planet – pay for it is a little ironic.
The biggest JavaScript file seems to be for Mapbox, which as far as I can see is never actually used: that map on the page is a static
image which, incidentally, I was able to reduce from 0.5 Mb to 0.2 Mb just by running it through
a free online image compressor.
This took me literally seconds to do but would save about a twelfth of a second for every single typical 4G user to their site. And it’s not even the worst culprit.
And because the site sets virtually no caching headers, even if you’ve visited the website before you’re likely to have to download the whole thing again. Every single
time.
It’s not just about bandwidth: all of those fonts, that JavaScript, their 60 Kb of CSS (this page sent you 13 Kb) all has to be parsed and interpreted by your device. If you’re on a mobile device or a laptop, that means you’re burning through lithium (a non-renewable resource whose extraction and disposal is highly polluting) and
regardless of your device you’re using you’re using more electricity to visit their site than you need to. Coding antipatterns like document.write() and active event
listeners that execute every time you scroll the page keep your processor working hard, turning electricity into waste heat. It took me over 12 seconds on a high-end smartphone and a
good 4G connection to load this page to the point of usability. That’s 12 seconds of a bright screen, a processor running full tilt,a data connection working its hardest, and a
battery ticking away. And I assume I’m not the only person visiting the website today.
This isn’t really about this particular website, of course (and I certainly don’t want to discourage anybody from the important cause of saving the planet!). It’s about the
bigger picture: there’s a widespread and long-standing trend in web development towards bigger, heavier, more power-hungry websites, built on top of heavyweight frameworks that push the
hard work onto the user’s device and which favour developer happiness over user experience. This is pretty terrible: it makes the Web slow, and brittle, and it increases the digital
divide as people on slower connections and older devices get left behind.
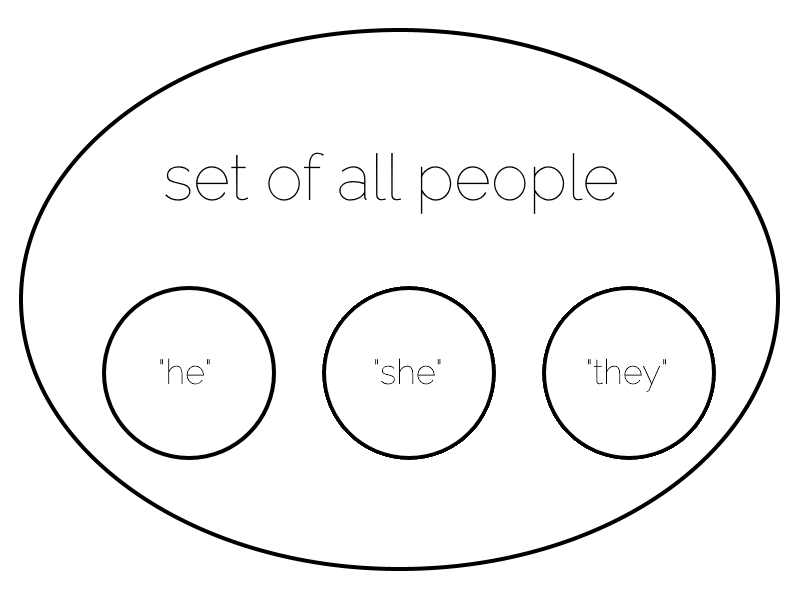
I had a bit of a realisation, this week. I’ve long sometimes found it especially challenging to maintain a mental map of the preferred personal pronouns of people who don’t use “he”,
“she”, or “they”. Further than that, it seemed to me that personal pronouns beyond these three ought to be mostly redundant in English. “Them” has been well-established for over six centuries as not just a plural but a singular pronoun, I thought: we don’t need
to invent more words.
Over time – even within my lifetime – it’s become noticeably more-commonplace to hear the singular “they”/”them” in place of
“he or she”/”him or her”, or single binary pronouns (e.g. when talking about professions which have long been dominated by a particular gender). So you might hear somebody say:
“I will make an appointment to see a doctor and ask them about my persistent cough.”
This seemed a perfectly viable model.
It seemed to me that “they” was a perfect general-purpose stand in for everybody who was well-served by neither “he” nor “she”.
I’ll stress, of course, that I’ve always been fully supportive of people’s preferred pronouns, tried to use them consistently, ensured they can be
represented in software I’ve implemented (and pressured others over their implementations, although that’s as-often related to my individual identity), etc. I’ve just struggled to see the need for new singular third-person pronouns like ze,
ey, sie, ve, or – heaven forbid – the linguistically-cumbersome thon, co, or peh.
I’d put it down to one of those things that I just don’t “get”, but about which I can still respect and support anyway. I don’t have to totally grok something in order to understand
that it’s important to others.
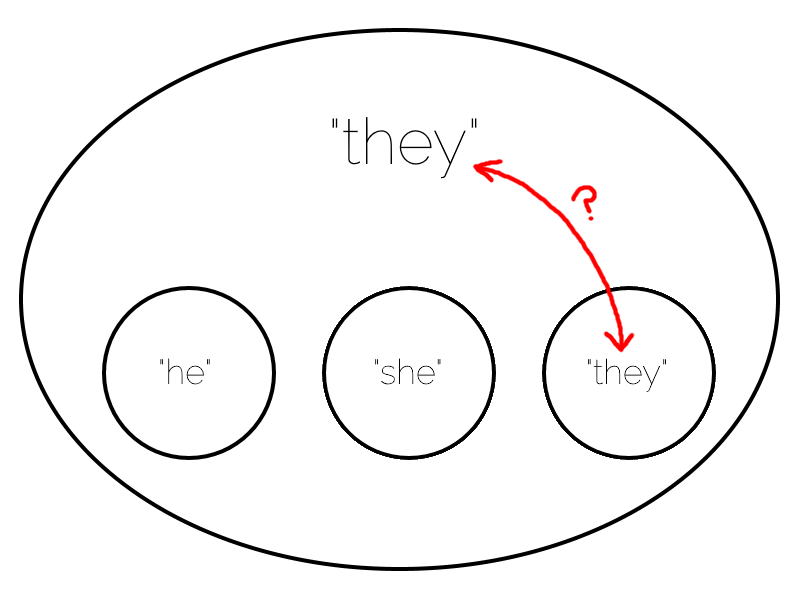
Hang on, there’s a problem with this model.
But very recently, I was suddenly struck by a comprehension of one of the reported problems with the use of the singular “they” to refer to people for whom the traditional binary
pronouns are not suitable. I’ve tried to capture in the illustration above the moment of understanding when I made the leap.
The essence of this particular problem is: the singular “they” already has a meaning that is necessarily incompatible with the singular “they” used of a nonbinary
subject! By way of example, let’s revisit my earlier example sentence:
“I will make an appointment to see a doctor and ask them about my persistent cough.”
Here, I’m saying one of two things, and it’s fundamentally unclear which of the two I mean:
I do not know which doctor I will see, so I do not know the pronoun of the doctor.
I will see the same doctor I always see, and they prefer a nonbinary pronoun.
The more widespread the adoption of “they” as the third person singular for nonbinary people becomes, the more long-winded it is to clarify specifically which of the above
interpretations is correct! The tendency to assume the former leads to nonbinary invisibility, and the (less-likely in most social circles) tendency to assume the latter leads to
misgendering.
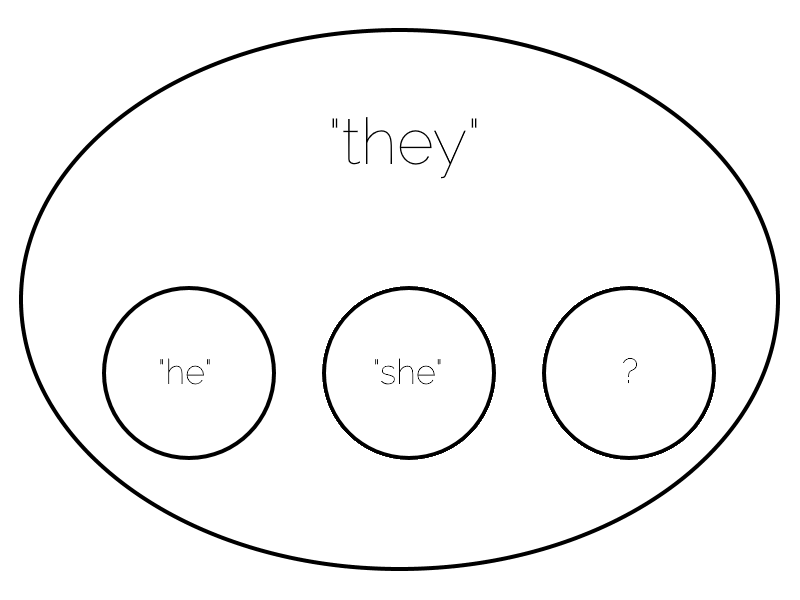
Okay, so I guess we do need a third-party singular pronoun that isn’t “they”.
The difference is one of specificity. Because the singular “they” is routinely used non-specifically, where the subject’s preferred pronouns are unknown (as with the doctor, above),
unknowable (“somebody wrote this anonymous message; they said…”), or a placeholder (“when I meet somebody, I shake their hand”), it quickly produces
semantic ambiguities when it’s used to refer to specific nonbinary individuals. And that makes me think: we can do better.
That said: I don’t feel able to suggest which pronoun(s) ought to replace the question mark in the diagram above. But for the first time, I’m not convinced that it ought to be “they”.
Ultimately, this changes nothing. I regularly use a diversity of different singular pronouns (he”, “she”, and “they”, mostly) based on the individual subject and I’ll continue to
acknowledge and respect their preferences. If you’ve you’ve told me that you like to be referred to by the singular “they”, I’ll continue to do so and you’re welcome and
encouraged to correct me if I get it wrong!
But perhaps this new appreciation of the limitations of the singular “they” when referring to specific individuals will help me to empathise with those for whom it doesn’t feel
right, and who might benefit from more-widespread understanding of other, newer personal pronouns.
(and on the off chance anybody’s found their way to this page looking for my pronouns: I’m not particularly fussy, so long as you’re consistent and don’t confuse your
audience, but most people refer to me with traditional masculine pronouns he/him/his)
StackOverflow‘s one of the most-popular and widely-used resources for software developers. It dominates the search results when you’re looking
for answers to techy questions. If you know how to read it, it can be invaluable.
But… I’m not sure what it is about the platform or the culture surrounding it that creates a certain… pattern to the answers that you can expect to receive on StackOverflow. To
illustrate, let’s suppose we have a question:
Here are the answers you might see:
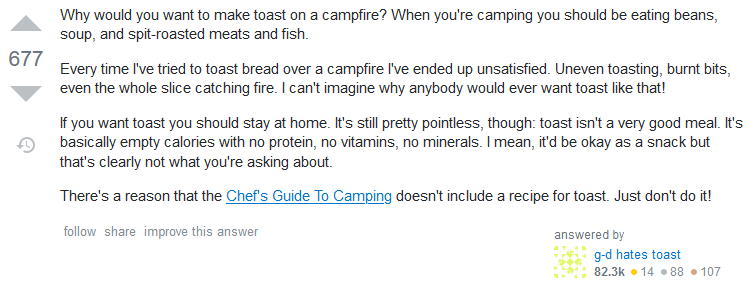
The Golden Hammer
The top answer is often somebody answering not the question you asked, but the question they’d like to think you asked.
Never mind that you specifically said that you were using a campfire, the answer suggests that you use a toaster. Look back a few years and you’ll see countless examples of people
asking for solutions using “vanilla” JavaScript and being told to use some heavyweight, everything-but-the-kitchen sink jQuery plugin. Now we’re in a more enlightened time, those same
people are being told to use some heavyweight, everything-but-the-kitchen-sink npm module. How far we’ve come.
The Belligerent
Far often than you might expect, a perfectly reasonable “how do I do this?” question is met with an aggressive response of “why would you want to do that?”
These are particularly infuriating to read when you come to a closed thread and you know that you do want to be doing the “forbidden” thing. You’ve considered the
other options, you’ve assessed the situation… and now some arrogant bugger’s telling you that you’re wrong!
This kind of response is among the most annoying, second only to…
The Kindred Spirit
You’re getting a strange and inexplicable error message. You search for it and get exactly one result. Reading the thread, after hours of tearing your hair out, you suddenly
feel a sense of relief: you’ve found another soul in this crazy world that’s suffering in precisely the same way as you are. Every word you read reconfirms for you that you and they
have the same issue. At last, a solution is in reach!
Nope.
Not only have you not got a solution, but the saviour you thought you’d found? They do have a solution, but they were thinking only about themselves when they got it, so they
didn’t share it.
I get it: when you’re deep in focus on a problem you forget that the forum you’re on will receive search traffic indefinitely. But “NM, I’ve worked it out” is the most infuriating
sentence on the Internet. When you solve a tough problem that you’d talked about online, for the love of God put the solution online too.
The Expert
There’s always somebody who answers the question but in a way you’d need a PhD to comprehend.
StackOverflow is often used by beginners. Make your answer beginner-friendly if possible.
The Hero We Don’t Need
Like the Golden Hammer, the Hero We Don’t Need answers the question that they know the answer to rather than the question you actually asked. Unlike the Golden Hammer,
the question they answer isn’t even remotely related to the question you asked.
Perhaps some future site visitor who chose their search terms badly might benefit from this out-of-the-box look at a completely different problem. But I wouldn’t count on it.
The Correct Answer
Eventually, if you’re lucky, somebody will provide the actual answer to the question. You’ll often have to scroll about this far down the page to find it.
Still, at least there’s an answer. And it only took four
hours between posting the question and it appearing. Sometimes that’s what it takes, and at least the answer will be there for the next person, assuming that they, too, scroll down far
enough.
Unfortunately hundreds of novice developers will have no way to tell that this alone is the correct answer amongst the endless stream of bullshit in which it resides.
The Echo
And finally, there’s always some idiot who repeats one of the same (useless) answers from before. Just to keep the noise-to-signal ratio up, I guess.
StackOverflow’s given me so many useful answers to so many questions, over the years. But it’s also been a great source of frustration for me at the hands of six of these seven
archetypes. Did I miss any?
In these challenging times, and especially because my work and social circles have me communicate regularly with people in
many different countries and with many different backgrounds, I’m especially grateful for the following:
My partner, her husband, and I
each have jobs that we can do remotely and so we’re not out-of-work during the crisis.
Our employers are understanding of our need to reduce and adjust our hours to fit around our new lifestyle now that schools and nurseries are (broadly) closed.
Our kids are healthy and not at significant risk of serious illness.
We’ve got the means, time, and experience to provide an adequate homeschooling environment for them in the immediate term.
(Even though we’d hoped to have moved house by now and haven’t, perhaps at least in part because of COVID-19,) we
have a place to live that mostly meets our needs.
We have easy access to a number of supermarkets with different demographics, and even where we’ve been impacted by them we’ve always been able to work-around the where
panic-buying-induced shortages have reasonably quickly.
We’re well-off enough that we were able to buy or order everything we’d need to prepare for lockdown without financial risk.
Having three adults gives us more hands on deck than most people get for childcare, self-care, etc.
(we’re “parenting on easy mode”).
We live in a country in which the government (eventually) imposed the requisite amount of lockdown necessary to limit the spread of the virus.
We’ve “only” got the catastrophes of COVID-19 and Brexit to deal with, which is a bearable amount of
crisis, unlike my colleague in Zagreb for example.
Today’s homeschool science experiment was about what factors make ice melt faster. Because of course
that’s the kind of thing I’d do with the kids when we’re stuck at home.
Whenever you find the current crisis getting you down, stop and think about the things that aren’t-so-bad or are even good. Stopping and expressing your gratitude for them in
whatever form works for you is good for your happiness and mental health.
Lüneburg, I thought to myself… I don’t know anybody who’s on holiday in Lüneburg, do I?
But today my heart was filled with joy when today I received a postcard – a hashcard, no less – from fellow hasher
Fippe, whose expedition to Lüneburg last week brought him
past the famous town hall shown in the postcard, as evidenced by his photo from the site.
Fippe found my address online; I’m not sure which (of several possible) mechanisms he used, but we’re fortunate that I haven’t recently-moved-house (as I hope to later this year) yet!
































{kind=link}