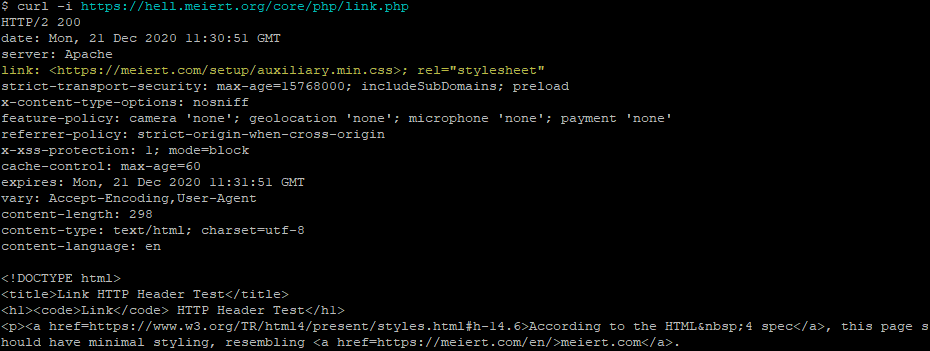
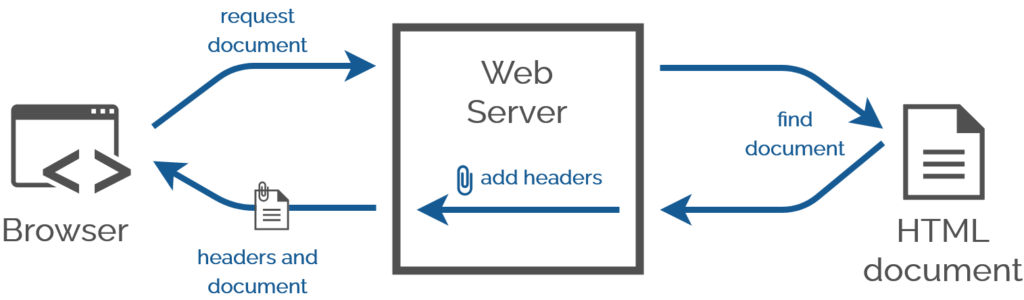
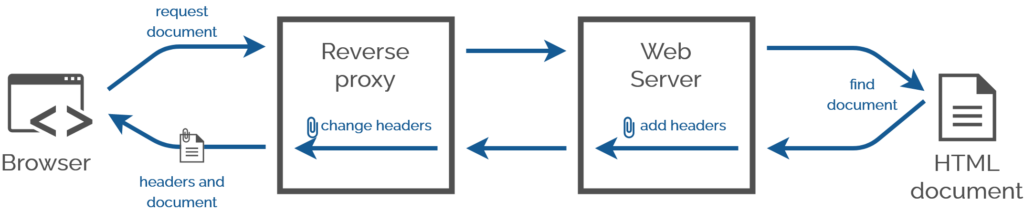
While talking about external CSS, he hinted at what I consider to be a distinct fourth way with its own unique use
cases:; using the Link: HTTP header. I’d like to share with you how it works and why I think it needs to be
kept in people’s minds, even if it’s not suitable for widespread deployment today.
Injecting CSS using the Link: HTTP Header
Every one of Jeremy’s suggestions involve adding markup to the HTML document itself. Which makes sense; you almost always
want to associate styles with a document regardless of the location it’s stored or the medium over which it’s transmitted. The most popular approach to adding CSS to a page uses the <link> HTML element, but did you know… the <link> element has a semantically-equivalent HTTP header,Link:.
A webserver adds headers when it serves a document anyway. Adding one more is no big deal.
Why is this important?
This isn’t something you should put on your website right now. This (21-year-old!) standard is still only really supported in Firefox and pre-Blink Opera, so you lose perhaps 95% of the
Web (it could be argued that because CSSought to be considered
progressive enhancement, it’s tolerable so long as your HTML is properly-written).
If it were widely-supported, though, that would be a really good thing: HTTP headers beat meta/link tags for configurability, performance management, and separation of concerns. Need some specific examples? Sure:
here’s what you could use HTTP stylesheet linking for:
You have no idea how many times in my career I’d have injected CSS Link: headers using a reverse proxy server the
standard was universally-implemented. This technique would have made one of my final projects at the Bodleian so much easier…
Performance improvement using aggressively preloaded “top” stylesheets before the DOM parser even fires up.
Stylesheet injection by edge caches to provide regionalised/localised changes to brand identity.
Strong separation of content and design by hosting content and design elements in different systems.
Branding your staff intranet differently when it’s accessed from outside the network than inside it.
Rebranding proprietary services on your LAN without deep inspection, using reverse proxies.
Less-destructive user stylesheet injection by plugins etc. that doesn’t risk breaking icky on-page Javascript (e.g. theme switchers).
Browser detection? 😂 You could use this technique today to detect Firefox. But you absolutely
shouldn’t; if you think you need browser detection in CSS, use this instead.
Unfortunately right now though, stylesheet Link: headers remain consigned to the bin of “cool stylesheet standards that we could probably use if it weren’t for fucking Google”; see also
alternate stylesheets.
My friend still uses a seriously retro digital music player, rather than his phone, to listen to music. It’s not a Walkman or a Minidisc player, I suppose, but it’s still pretty
elderly. But it’s not one of these.
I’m not here to speak about the legality of retaining offline copies of music from streaming services. YouTube Music seems to permit you to do this using their app, but I’ll bet there’s
something in their terms and conditions that specifically prohibits doing so any other way. Not least because Google’s arrangement with rights holders probably stipulates that they
track how many times tracks are played, and using a different player (like my friend’s portable device) would throw that off.
But what I’m interested in is the feasibility. And in answering that question, in explaining how to work out that it’s feasible.
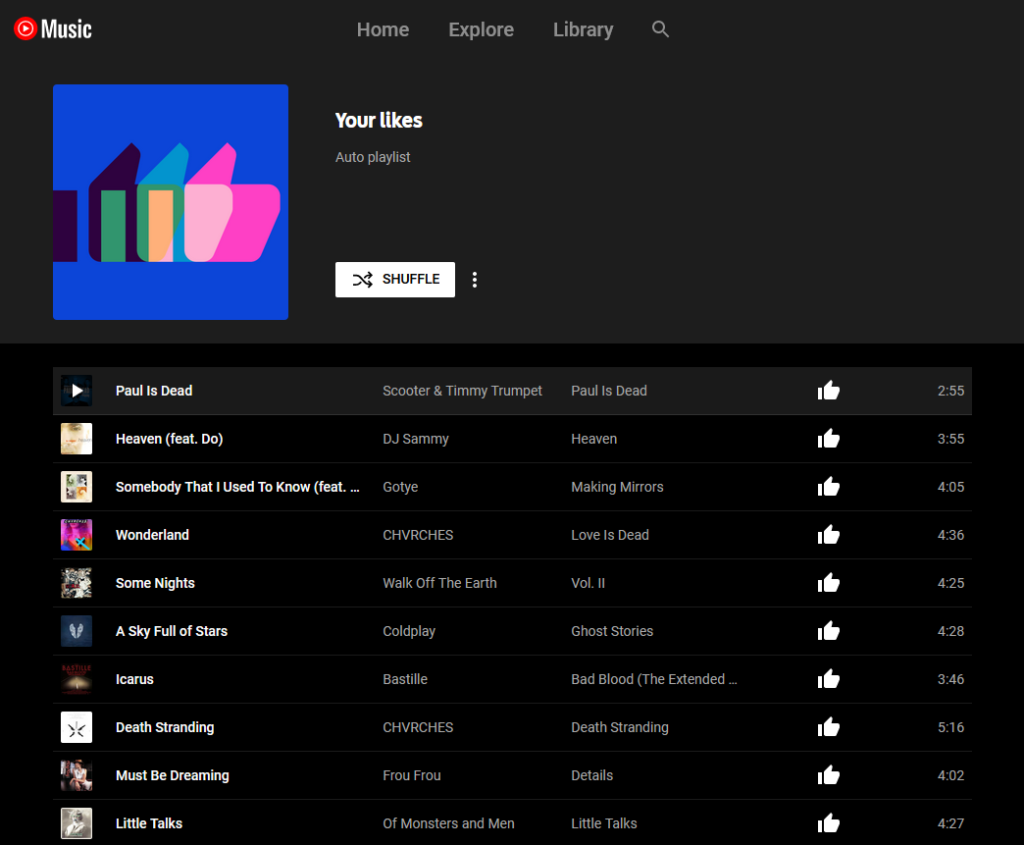
The web interface to YouTube Music shows playlists of songs and streaming is just a click away.
Spoiler: I came up with an approach, and it looks like it works. My friend can fill up their Zune or whatever the hell
it is with their tunes and bop away. But what I wanted to share with you was the underlying technique I used to develop this approach, because it involves skills that as a web
developer I use most weeks. Hold on tight, you might learn something!
youtube-dl can download “playlists” already, but to download a personal playlist requires that you faff about with authentication and it’s a bit of a drag. Just extracting
the relevant metadata from the page is probably faster, I figured: plus, it’s a valuable lesson in extracting data from web pages in general.
Here’s what I did:
Step 1. Load all the data
I noticed that YouTube Music playlists “lazy load”, and you have to scroll down to see everything. So I scrolled to the bottom of the page until I reached the end of the playlist: now
everything was in the DOM, I could investigate it with my inspector.
Step 2. Find each track’s “row”
Using my browser’s debugger “inspect” tool, I found the highest unique-sounding element that seemed to represent each “row”/track. After a little investigation, it looked like
a playlist always consists of a series of <ytmusic-responsive-list-item-renderer> elements wrapped in a <ytmusic-playlist-shelf-renderer>. I tested
this by running document.querySelectorAll('ytmusic-playlist-shelf-renderer ytmusic-responsive-list-item-renderer') in my debug console and sure enough, it returned a number
of elements equal to the length of the playlist, and hovering over each one in the debugger highlighted a different track in the list.
The web application captured right-clicks, preventing the common right-click-then-inspect-element approach… so I just clicked the “pick an element” button in the debugger.
Step 3. Find the data for each track
I didn’t want to spend much time on this, so I looked for a quick and dirty solution: and there was one right in front of me. Looking at each track, I saw that it contained several
<yt-formatted-string> elements (at different depths). The first corresponded to the title, the second to the artist, the third to the album title, and the fourth to
the duration.
Better yet, the first contained an <a> element whose href was the URL of the piece of music.
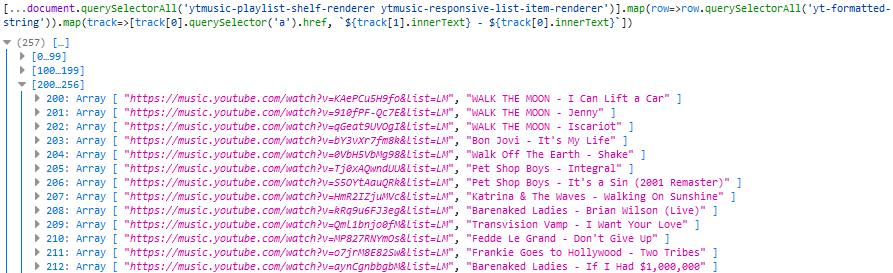
Extracting the URL and the text was as simple as a .querySelector('a').href on the first
<yt-formatted-string> and a .innerText on the others, respectively, so I ran [...document.querySelectorAll('ytmusic-playlist-shelf-renderer
ytmusic-responsive-list-item-renderer')].map(row=>row.querySelectorAll('yt-formatted-string')).map(track=>[track[0].querySelector('a').href, `${track[1].innerText} -
${track[0].innerText}`]) (note the use of [...*] to get an array) to check that I was able to get all the data I needed:
Lots of URLs and the corresponding track names in my friend’s preferred format (me, I like to separate my music into folders
by album, but I suppose I’ve got a music player with more than a floppy disk’s worth of space on it).
Step 4. Sanitise the data
We’re not quite good-to-go, because there’s some noise in the data. Sometimes the application’s renderer injects line feeds into the innerText (e.g. when escaping an
ampersand). And of course some of these song titles aren’t suitable for use as filenames, if they’ve got e.g. question marks in them. Finally, where there are multiple spaces in a row
it’d be good to coalesce them into one. I do some experiments and decide that .replace(/[\r\n]/g, '').replace(/[\\\/:><\*\?]/g, '-').replace(/\s{2,}/g, ' ') does a
good job of cleaning up the song titles so they’re suitable for use as filenames.
I probably should have it fix quotes too, but I’ll leave that as an exercise for the reader.
Step 5. Produce youtube-dl commands
Okay: now we’re ready to combine all of that output into commands suitable for running at a terminal. After a quick dig through the documentation, I decide that we needed the following
switches:
-x to download/extract audio only: it defaults to the highest quality format available, which seems reasomable
-o "the filename.%(ext)s" to specify the output filename but accept the format provided by the quality requirement (transcoding to your preferred format is a
separate job not described here)
--no-playlist to ensure that youtube-dl doesn’t see that we’re coming from a playlist and try to download it all (we have our own requirements of each song’s
filename)
--download-archive downloaded.txt to log what’s been downloaded already so successive runs don’t re-download and the script is “resumable”
The output isn’t pretty, but it’s suitable for copy-pasting into a terminal or command prompt where it ought to download a whole lot of music for offline play.
This isn’t an approach that most people will ever need: part of the value of services like YouTube Music, Spotify and the like is that you pay a fixed fee to stream whatever you like,
wherever you like, obviating the need for a large offline music collection. And people who want to maintain a traditional music collection offline are most-likely to want to do
so while supporting the bands they care about, especially as (with DRM-free digital downloads commonplace) it’s never been
easier to do so.
But for those minority of people who need to play music from their streaming services offline but don’t have or can’t use a device suitable for doing so on-the-go, this kind of approach
works. (Although again: it’s probably not permitted, so be sure to read the rules before you use it in such a way!)
Step 6. Learn something
But more-importantly, the techniques of exploring and writing console Javascript demonstrated are really useful for extracting all kinds of data from web pages (data scraping), writing your own userscripts, and much more. If there’s
one lesson to take from this blog post it’s not that you can steal music on the Internet (I’m pretty sure everybody who’s lived on this side of 1999 knows that by now), but
that you can manipulate the web pages you see. Once you’re viewing it on your computer, a web page works for you: you don’t have to consume a page in the way that the
author expected, and knowing how to extract the underlying information empowers you to choose for yourself a more-streamlined, more-personalised, more-powerful web.
So the NHS blood donation rules are changing again. And while they’re certainly getting closer, they’re still not quite hitting the bullseye yet.
That’s great. Prior to 2011 men who’d ever had sex with men, as well as women who’d had sex with such a man within the last 6 months, were banned from donating blood. That rule
clearly spun out of the AIDS hysteria of the 1980s and generally entrenched homophobia. It probably did little to
protect the recipients of blood, and certainly did a lot to increase the stigma experienced by non-straight men.
You throw enough policies at a problem, eventually one will get close-enough, right?
The 2011 change permitted donation by men who’d previously had sex with men… so long as they hadn’t done so within the last year. Which opened the doors to donation by a lot of men:
e.g. bisexual men who’d been in relationships exclusively with women, gay men who’d been celibate for a period, etc. It still wasn’t great, but it was a step in the right
direction.
So when I saw that the rules were changing to better target only risky behaviours, rather than behaviours that are so broad-brush as to target identities, I was
initially delighted. Evidence-based medicine, you say? For the win.
Go on! Stick it in me! I’ll still be able to give blood, right?
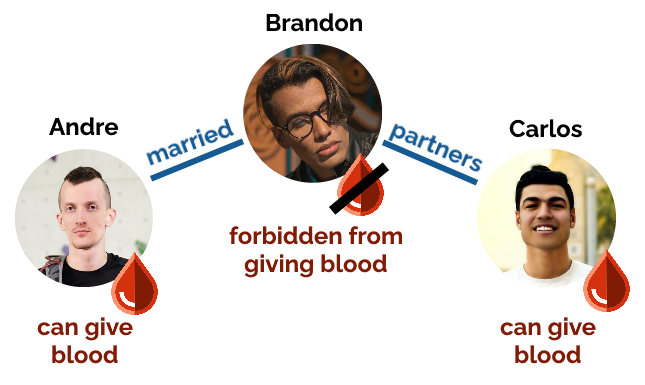
But… it’s not all sunshine and rainbows. The new rules prohibit blood donation regardless of gender by people who’ve had sex with more than one person in the last three months.
Sorry Brandon, we only want Andre and Carlos’ blood.
So if for example if there’s a V-shaped relationship consisting of three men, who only have sex within their thruple… two of them are now allowed to give blood but the third isn’t?
(This isn’t a contrived example. I know such a thruple.)
Stranger still: if you swap Brandon in the diagram above for a woman then you get a polycule that’s a lot like mine, but the woman in the middle used to be allowed to give
blood… and now can’t! My partner Ruth is in exactly the position: her situation hasn’t changed, but because she’s been in a long-term
relationship with exactly two people she’s now not allowed to give blood. Wot?
On the whole, this rule change is an improvement. We’re getting closer to a perfect answer. But it’s amusing to see where the policy misses again and excludes
donors who would otherwise be perfectly viable.
Update: as this is attracting a lot of attention I just wanted to remind people that the whole discussion is, of course, a lot
more complicated than can be summarised in a single, short, opinionated blog post. Take a look at the FAIR steering
group’s recommendations and compare to the government’s press release.
Update #2: justifying choice of words – “AIDS hysteria”
refers specifically to the media (and to a lesser extent the policy) reactions to the (very real, very devastating) pandemic. For a while there it was perfectly normal to see (often
misguided, sometimes homophobic) scaremongering news coverage suggesting that everybody was at enormous risk from HIV.
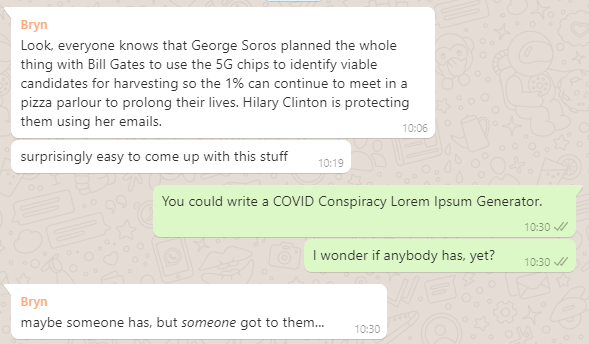
So I made a COVID conspiracy theory-themed lorem ipsum generator:
I blame my friend Bryn, who put the idea into my head while he was coming up with fake COVID conspiracy theories (I realise this sentence makes it sound like there are real COVID
conspiracy theories) on a WhatsApp group we’re both in:
This is about the minimum level of encouragement I need to do just about anything in tech.
It’s implemented using perchance, a platform for creating random text generators that I’ve been
playing with – sometimes with the kids – lately. It’s really easy to use and provides a kind of instant-satisfaction that I think is important
if you want to inspire the next generation of software engineers. This means, among other things, that you can clone, edit, and mashup my tool:
perhaps you can make it better! Or perhaps you’ll use perchance to write some fiction, or poetry, or something else entirely. But regardless, I’d encourage you to have a play.
Mostly my generator comes up with meaningless gibberish, nonsense, and laughable claims. So it’s marginally more-trustworthy than your typical COVID conspiracy theorist.
I’ve been having a tough time these last few months. Thanks to COVID, I’m sure I’m not alone in that.
Times are strange, and even when you get a handle on how they’re strange they can still affect you: lockdown stress can quickly magnify anything else you’re already going
through.
We’ve all come up with our own coping strategies; here’s part of mine.
Only people who are highly-allergic to pine needles normally look like this when they’re shopping for a Christmas tree.
These last few months have occasionally seen me as emotionally low as… well, a particularly tough spell a decade ago. But this time around I’ve
benefited from the self-awareness and experience to put some solid self-care into practice!
By way partly of self-accountability and partly of sharing what works for me, let me tell you about the silly mnemonic that reminds me what I need to keep track of as part of each day:
GEMSAW! (With thanks to Amy Blankson for, among other things, the idea of this kind of acronym.)
Because it’s me, I’ve cited a few relevant academic sources for you in my summary, below:
Gratitude
Taking the time to stop and acknowledge the good things in your life, however small, is associated with lower stress levels (Taylor, Lyubomirsky & Stein, 2017) to a degree that can’t just be explained by the placebo effect (Cregg
& Cheavens, 2020).
Frankly, the placebo effect would be fine, but it’s nice to have my practice of trying to intentionally recognise something good in each day validated by the science too!
Exercise
I don’t even need a citation; I’m sure everybody knows that aerobic exercise is associated with reduced risk and severity of depression: the biggest problem comes from the
fact that it’s an exceptionally hard thing to motivate yourself to do if you’re already struggling mentally!
But it turns out you don’t need much to start to see the benefits (Josefsson, Lindwall & Archer,
2014): I try to do enough to elevate my heart rate each day, but that’s usually nothing more than elevating my desk to standing height, putting some headphones on, and dancing
while I work!
Warming up. Things only get nuts when the bass drops, but I’ll spare you having to watch that.
Meditation/Mindfulness
Understandably a bit fuzzier as a concept and tainted by being a “hip” concept. A short meditation break or mindfulness exercise might be verifiably therapeutic, but more
(non-terrible) studies are needed (Vonderlin, Biermann, Bohus & Lyssenko 2020). For me, a 2-5 minute
meditation break punctuates a day and feels like it contributes towards the goal of staying-sane-in-challenging-times, so it makes it into my wellbeing plan.
Maybe it’s doing nothing. But I’m not losing much time over it so I’m not worried.
Sunlight
During my 20s I gradually began to suffer more and more from “winter blues”. Nobody’s managed to make an argument for the underlying cause of seasonal affective disorder that
hasn’t been equally-well debunked by some other study. Small-scale studies often justify light therapy (e.g. Lam, Levitan & Morehouse 2006) but it’s possibly
no-more-effective than a placebo at scale (SBU 2007).
Since my early 30s, I’ve always felt better to get myself 30 minutes of lightbox on winter mornings (I use one of these bad
boys). I admit it’s possible that the benefits are just the result of tricking my brain into waking-up more promptly and therefore feeing like I’m being more-productive with my
waking hours! But either way, getting some sunlight – whether natural or artificial – makes me feel better, so it makes it onto my daily self-care checklist.
10 minutes of overhead, unoccluded sunlight is the minimum therapeutic dose. That translates to about 30 minutes of winter sun at my latitude or 10,000 lux full-spectrum sunlamp.
Acts of kindness
It’s probably not surprising that a person’s overall happiness correlates with their propensity for kindness (Lyubomirsky, King & Diener 2005). But what’s more interesting is that the causal link can be “gamed”. That is: a
deliberate effort to engage in acts of kindness results in increased happiness (Buchanan & Bardi
2010)!
Beneficial acts of kindness can be as little as taking the time to acknowledge somebody’s contribution or compliment somebody’s efforts. The amount of effort it takes is far
less-important for happiness than the novelty of the experience, so the type of kindness you show needs to be mixed-up a bit to get the best out of it. But demonstrating kindness
helps to make the world a better place for other humans, so it pays off even if you’re coming from a fully utilitarian perspective.
Writing
I write a lot anyway, often right here, and that’s very-definitely for my own benefit first and foremost. But off the back of
some valuable “writing therapy” (Baikie
& Wilhelm 2005) I undertook earlier this year, I’ve been continuing with the simpler, lighter approach of trying to no more than three sentences about something that’s had an
impact on me that day.
As an approach, it doesn’t help everybody (Zachariae 2015), but writing a little about your day – not even
about how you feel about it, just the facts will do (Koschwanez, Robinson, Beban, MacCormick, Hill, Windsor, Booth, Jüllig &
Broadbent 2017; fuck me that’s a lot of co-authors) – helps to keep you content, and I’m loving it.
Despite the catchy acronym (Do I need to come up with a GEMSAW logo?
I’m pretty sure real gemcutting is actually more of a grinding process…) and stack of references, I’m not actually writing a self-help book; it just sounds like I am.
I don’t claim to be an authority on anything beyond my own head, and I’m not very confident on that subject! I just wanted to share with you something that’s been working
pretty well at keeping me sane for the last month or two, just in case it’s of any use to you. These are challenging times; do what you need to find the happiness you can, and
hang in there.
This weekend I announced and then hosted Homa Night II, an effort to use
technology to help bridge the chasms that’ve formed between my diaspora of friends as a result mostly of COVID. To a lesser extent
we’ve been made to feel distant from one another for a while as a result of our very diverse locations and lifestyles, but the resulting isolation was certainly compounded by lockdowns
and quarantines.
Long gone are the days when I could put up a blog post to say “Troma Night tonight?” and expect half a dozen friends to turn up at my house.
Back in the day we used to have a regular weekly film night called Troma Night, named after the studio
who dominated our early events and whose… genre… influenced many of our choices thereafter. We had over 300 such film
nights, by my count, before I eventually left our shared hometown of Aberystwyth ten years ago. I wasn’t the last one of the Troma Night
regulars to leave town, but more left before me than after.
Observant readers will spot a previous effort I made this year at hosting a party online.
Earlier this year I hosted Sour Grapes, a murder mystery party (an irregular highlight of our Aberystwyth social calendar,
with thanks to Ruth) run entirely online using a mixture of video chat and “second screen”
technologies. In some ways that could be seen as the predecessor to Homa Night, although I’d come up with most of the underlying technology to make Homa Night possible on a
whim much earlier in the year!
The idea spun out of a few conversations on WhatsApp but the final name – Homa Night – wasn’t agreed until early in November.
How best to make such a thing happen? When I first started thinking about it, during the first of the UK’s lockdowns, I considered a few options:
Streaming video over a telemeeting service (Zoom, Google Meet, etc.)
Very simple to set up, but the quality – as anybody who’s tried this before will attest – is appalling. Being optimised for speech rather than music and sound effects gives the audio
a flat, scratchy sound, video compression artefacts that are tolerable when you’re chatting to your boss are really annoying when they stop you reading a crucial subtitle, audio and
video often get desynchronised in a way that’s frankly infuriating, and everybody’s download speed is limited by the upload speed of the host, among other issues. The major benefit of
these platforms – full-duplex audio – is destroyed by feedback so everybody needs to stay muted while watching anyway. No thanks!
Teleparty or a similar tool Teleparty (formerly Netflix Party, but it now supports more services) is a pretty clever way to get almost exactly what I want:
synchronised video streaming plus chat alongside. But it only works on Chrome (and some related browsers) and doesn’t work on tablets, web-enabled TVs, etc., which would exclude some
of my friends. Everybody requires an account on the service you’re streaming from, potentially further limiting usability, and that also means you’re strictly limited to the media
available on those platforms (and further limited again if your party spans multiple geographic distribution regions for that service). There’s definitely things I can learn from
Teleparty, but it’s not the right tool for Homa Night.
“Press play… now!”
The relatively low-tech solution might have been to distribute video files in advance, have people download them, and get everybody to press “play” at the same time! That’s at least
slightly less-convenient because people can’t just “turn up”, they have to plan their attendance and set up in advance, but it would certainly have worked and I seriously
considered it. There are other downsides, though: if anybody has a technical issue and needs to e.g. restart their player then they’re basically doomed in any attempt to get back
in-sync again. We can do better…
A custom-made synchronised streaming service…?
A custom solution that leveraged existing infrastructure for the “hard bits” proved to be the right answer.
So obviously I ended up implementing my own streaming service. It wasn’t even that hard. In case you want to try your own, here’s how I did it:
Media preparation
First, I used Adobe Premiere to create a video file containing both of the night’s films, bookended and separated by “filler” content to provide an introduction/lobby, an intermission,
and a closing “you should have stopped watching by now” message. I made sure that the “intro” was a nice round duration (90s) and suitable for looping because I planned to hold people
there until we were all ready to start the film. Thanks to Boris & Oliver for the background
music!
Honestly, the intermission was just an excuse to keep my chroma key gear out following its most-recent use.
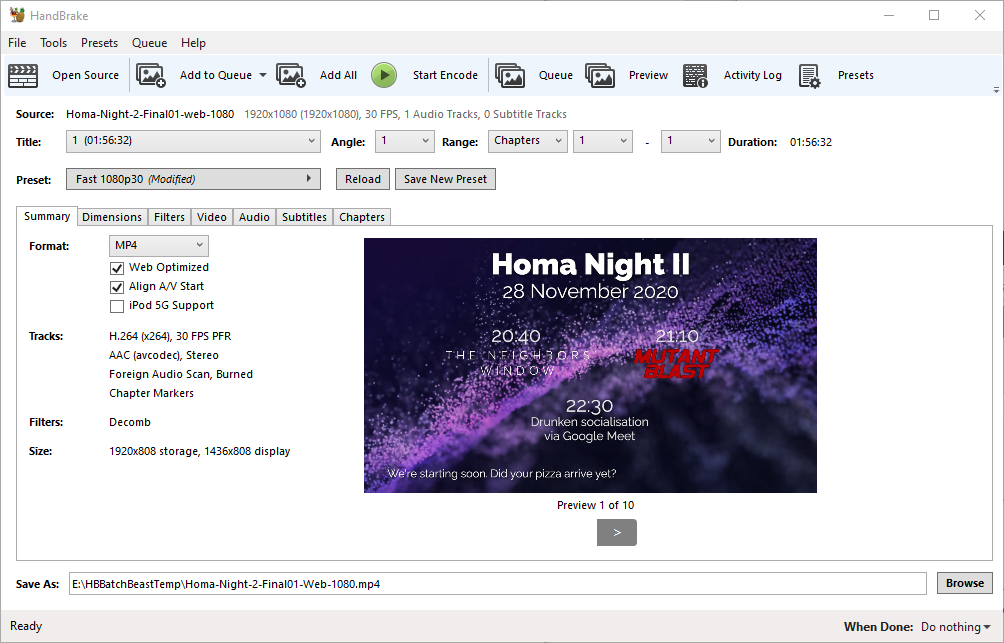
Next, I ran the output through Handbrake to produce “web optimized” versions in 1080p and 720p output sizes. “Web optimized” in this case means that
metadata gets added to the start of the file to allow it to start playing without downloading the entire file (streaming) and to allow the calculation of what-part-of-the-file
corresponds to what-part-of-the-timeline: the latter, when coupled with a suitable webserver, allows browsers to “skip” to any point in the video without having to watch the intervening
part. Naturally I’m encoding with H.264 for the widest possible compatibility.
Even using my multi-GPU computer for the transcoding I had time to get up and walk around a bit.
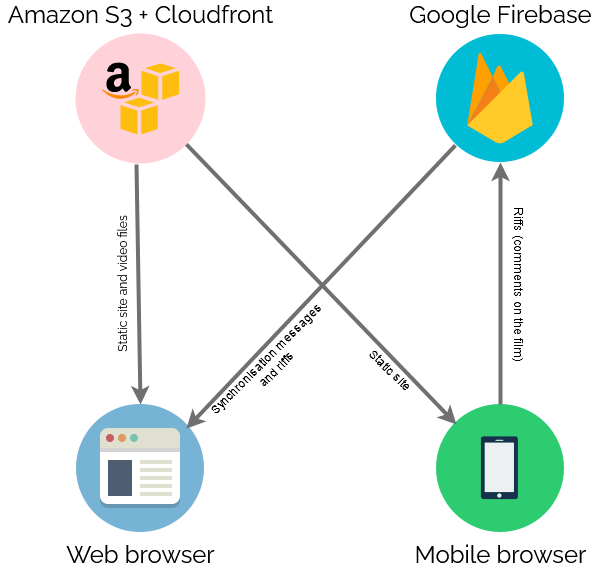
Real-Time Synchronisation
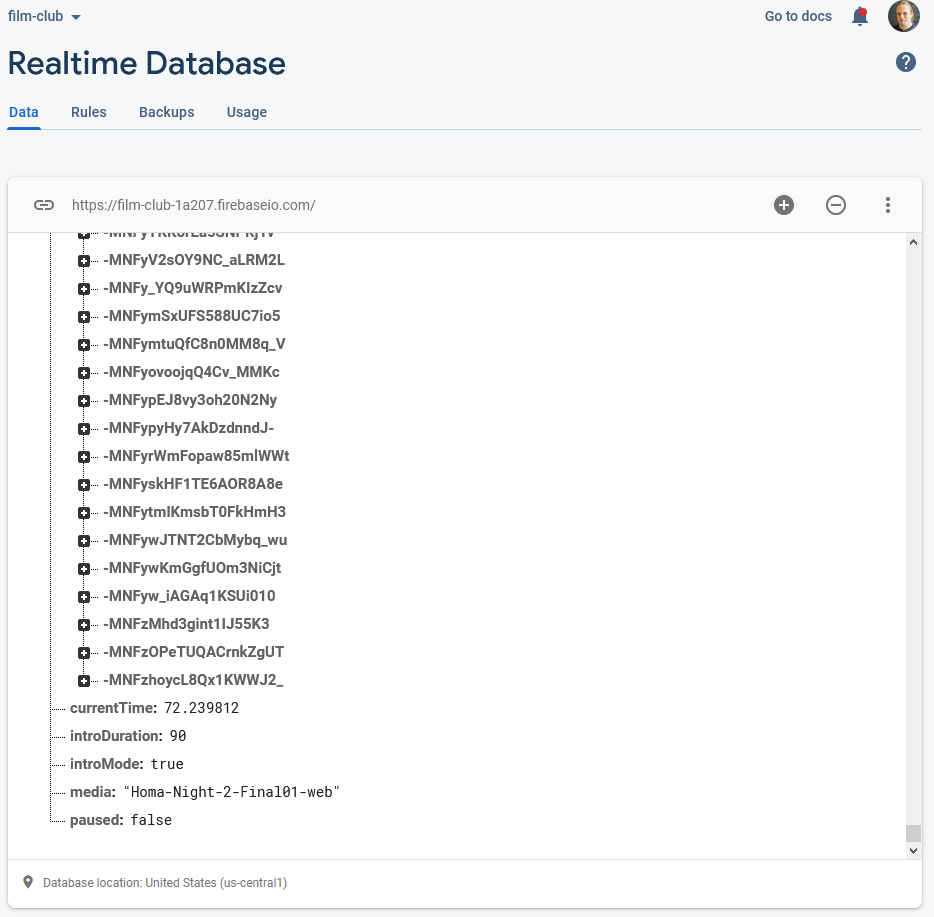
To keep everybody’s viewing experience in-sync, I set up a Firebase account for the application: Firebase provides an easy-to-use Websockets
platform with built-in data synchronisation. Ignoring the authentication and chat features, there wasn’t much
shared here: just the currentTime of the video in seconds, whether or not introMode was engaged (i.e. everybody should loop the first 90 seconds, for now), and
whether or not the video was paused:
Firebase makes schemaless real-time databases pretty easy.
To reduce development effort, I never got around to implementing an administrative front-end; I just manually went into the Firebase database and acknowledged “my” computer as being an
administrator, after I’d connected to it, and then ran a little Javascript in my browser’s debugger to tell it to start pushing my video’s currentTime to the server every
few seconds. Anything else I needed to edit I just edited directly from the Firebase interface.
Other web clients’ had Javascript to instruct them to monitor these variables from the Firebase database and, if they were desynchronised by more than 5 seconds, “jump” to the correct
point in the video file. The hard part of the code… wasn’t really that hard:
// Rewind if we're passed the end of the intro loopfunction introModeLoopCheck() {
if (!introMode) return;
if (video.currentTime > introDuration) video.currentTime =0;
}
function fixPlayStatus() {
// Handle "intro loop" modeif (remotelyControlled && introMode) {
if (video.paused) video.play(); // always play
introModeLoopCheck();
return; // don't look at the rest
}
// Fix current timeconst desync =Math.abs(lastCurrentTime - video.currentTime);
if (
(video.paused && desync > DESYNC_TOLERANCE_WHEN_PAUSED) ||
(!video.paused && desync > DESYNC_TOLERANCE_WHEN_PLAYING)
) {
video.currentTime = lastCurrentTime;
}
// Fix play statusif (remotelyControlled) {
if (lastPaused &&!video.paused) {
video.pause();
} elseif (!lastPaused && video.paused) {
video.play();
}
}
// Show/hide paused notification
updatePausedNotification();
}
Web front-end
Finally, there needed to be a web page everybody could go to to get access to this. As I was hosting the video on S3+CloudFront anyway, I put the HTML/CSS/JS there too.
I decided to carry the background theme of the video through to the web interface too.
I tested in Firefox, Edge, Chrome, and Safari on desktop, and (slightly less) on Firefox, Chrome and Safari on mobile. There were a few quirks to work around, mostly to do with browsers
not letting videos make sound until the page has been interacted with after the video element has been rendered, which I carefully worked-around by putting a popup “over” the
video to “enable sync”, but mostly it “just worked”.
Delivery
On the night I shared the web address and we kicked off! There were a few hiccups as some people’s browsers got disconnected early on and tried to start playing the film before it was
time, and one of these even when fixed ran about a minute behind the others, leading to minor spoilers leaking via the rest of us riffing about them! But on the whole, it worked. I’ve
had lots of useful feedback to improve on it for the next version, and I might even try to tidy up my code a bit and open-source the results if this kind of thing might be useful to
anybody else.
I’ve been working as part of the team working on the new application framework called the Endpoint Encabulator and wanted to share with you what I think makes our project so
exciting: I promise it’ll make for two minutes of your time you won’t seen forget!
Naturally, this project wouldn’t have been possible without the pioneering work that preceded it by John Hellins Quick, Bud Haggart, and others. Nothing’s invented in a vacuum. However,
my fellow developers and I think that our work is the first viable encabulator implementation to provide inverse reactive data binding suitable for deployment in front of a
blockchain-driven backend cache. I’m not saying that all digital content will one day be delivered through Endpoint Encabulator, but… well; maybe it will.
If the technical aspects go over your head, pass it on to a geeky friend who might be able to make use of my work. Sharing is caring!
I was chatting with a fellow web developer recently and made a joke about the HTML <blink> and
<marquee> tags, only to discover that he had no idea what I was talking about. They’re a part of web history that’s fallen off the radar and younger developers are
unlikely to have ever come across them. But for a little while, back in the 90s, they were a big deal.
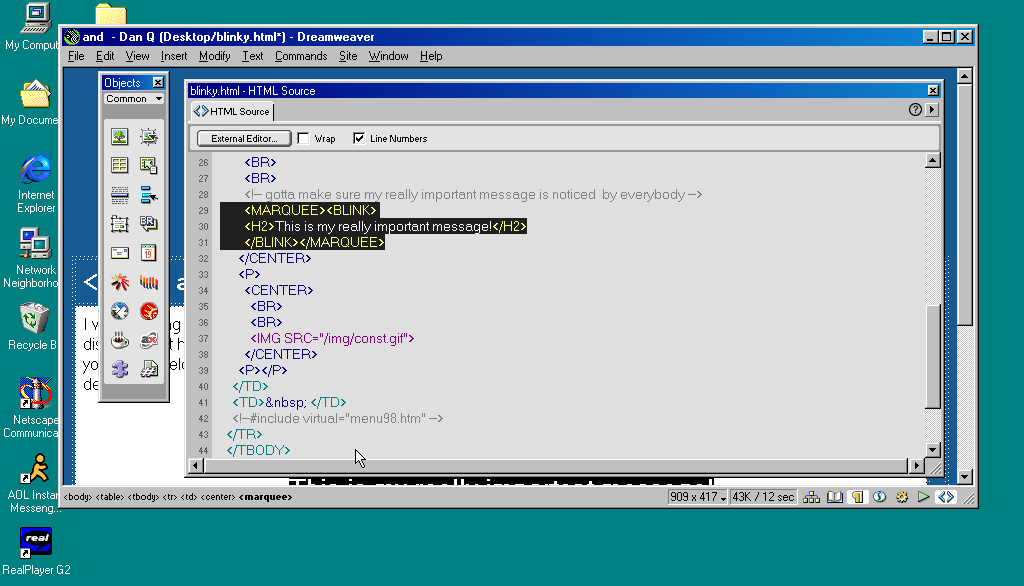
Even Macromedia Dreamweaver, which embodied the essence of 1990s web design, seemed to treat wrapping
<blink> in <marquee> as an antipattern.
Invention of the <blink> element is often credited to Lou Montulli, who wrote pioneering web browser Lynx before being joining Netscape in 1994. He insists that he didn’t write any
of the code that eventually became the first implementation of <blink>. Instead, he claims: while out at a bar (on the evening he’d first meet his wife!), he
pointed out that many of the fancy new stylistic elements the other Netscape engineers were proposing wouldn’t work in Lynx, which is a text-only browser. The fanciest conceivable
effect that would work across both browsers would be making the text flash on and off, he joked. Then another engineer – who he doesn’t identify – pulled a late night hack session and
added it.
And so it was that when Netscape Navigator 2.0 was released in 1995 it added support for
the <blink> tag. Also animated GIFs and the first inklings of JavaScript, which collectively
would go on to define the “personal website” experience for years to come. Here’s how you’d use it:
<BLINK>This is my blinking text!</BLINK>
With no attributes, it was clear from the outset that this tag was supposed to be a joke. By the time HTML4 was
published as a a recommendation two years later, it was documented as being a joke. But the Web of the late 1990s
saw it used a lot. If you wanted somebody to notice the “latest updates” section on your personal home page, you’d wrap a <blink> tag around the title (or,
if you were a sadist, the entire block).
If you missed this particular chapter of the Web’s history, you can simulate it at Cameron’s World.
In the same year as Netscape Navigator 2.0 was released, Microsoft released Internet Explorer
2.0. At this point, Internet Explorer was still very-much playing catch-up with the features the Netscape team had implemented, but clearly some senior Microsoft engineer took a
look at the <blink> tag, refused to play along with the joke, but had an innovation of their own: the <marquee> tag! It had a whole suite of attributes to control the scroll direction, speed, and whether it looped or bounced backwards and forwards. While
<blink> encouraged disgusting and inaccessible design as a joke, <marquee> did it on purpose.
<MARQUEE>Oh my god this still works in most modern browsers!</MARQUEE>
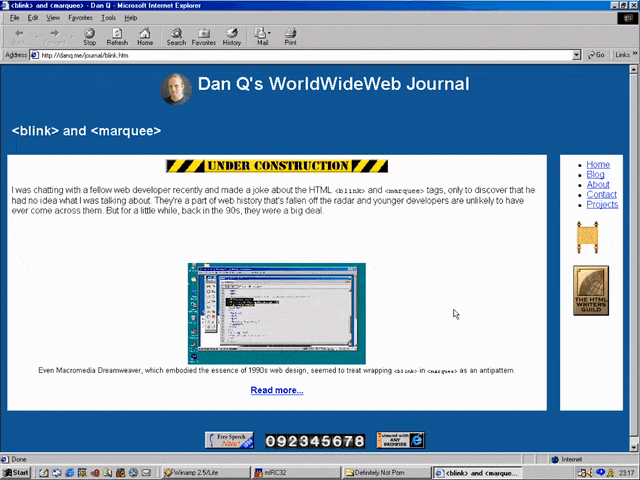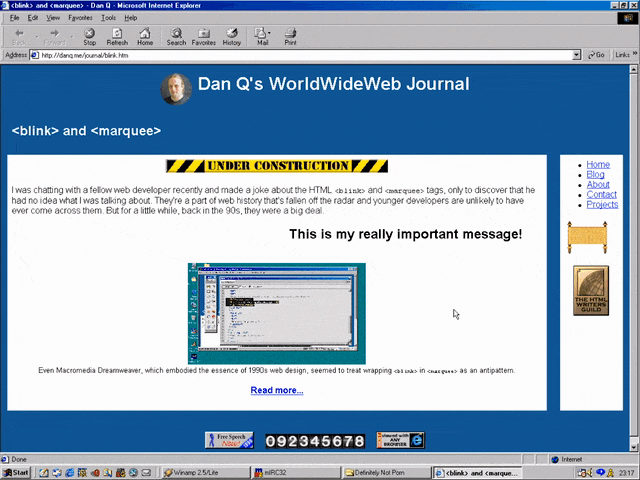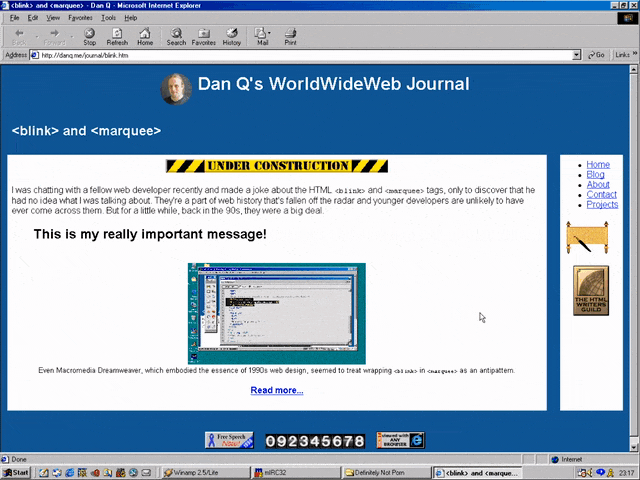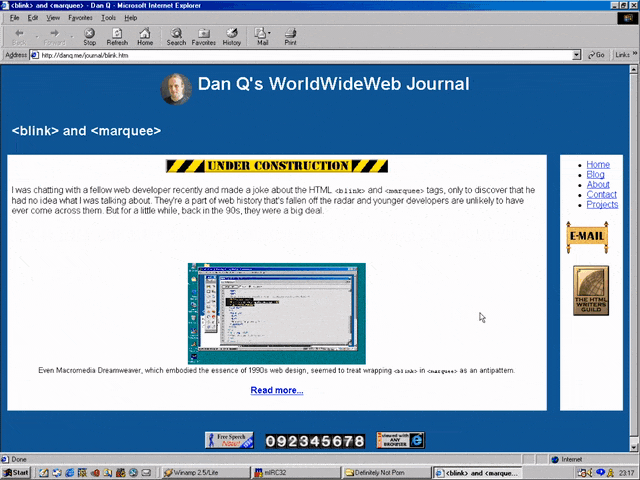
But here’s the interesting bit: for a while in the late 1990s, it became a somewhat common practice to wrap content that you wanted to emphasise with animation in both a
<blink> and a <marquee> tag. That way, the Netscape users would see it flash, the IE users
would see it scroll or bounce. Like this:
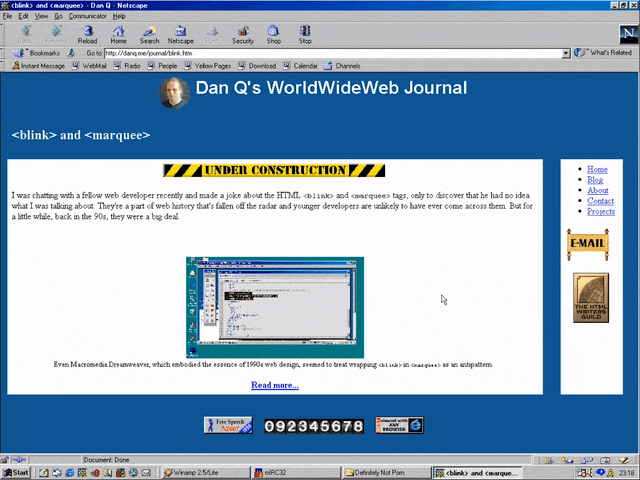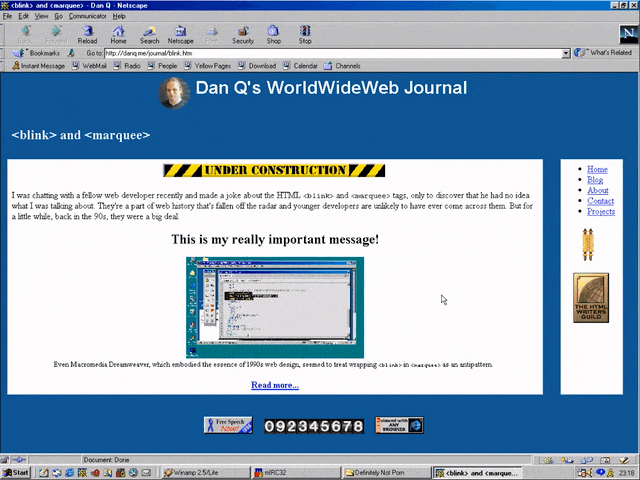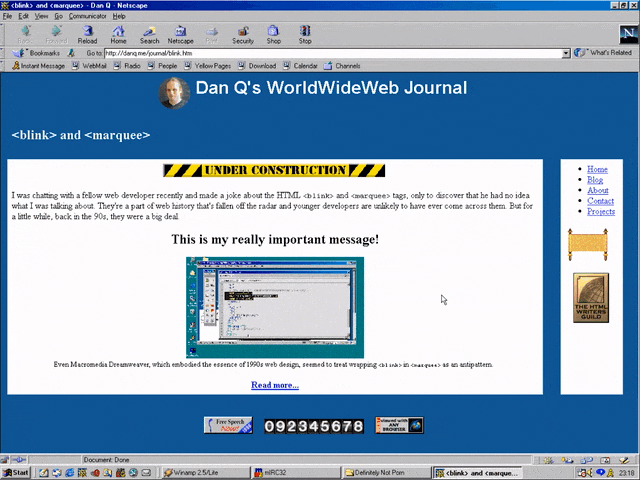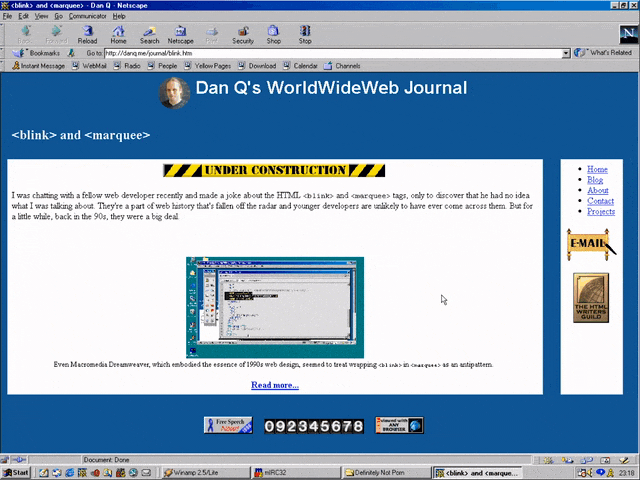
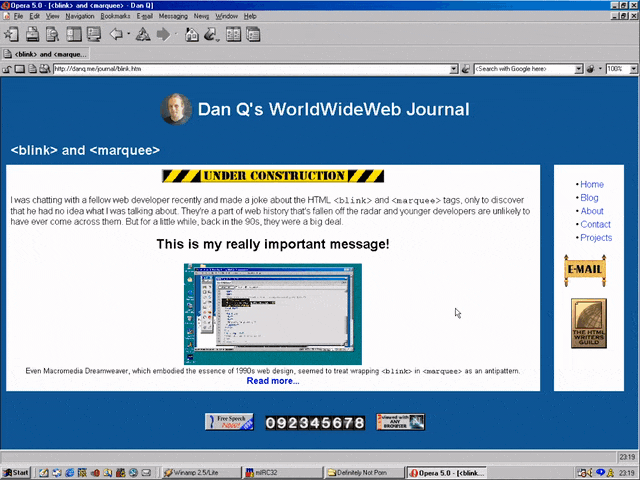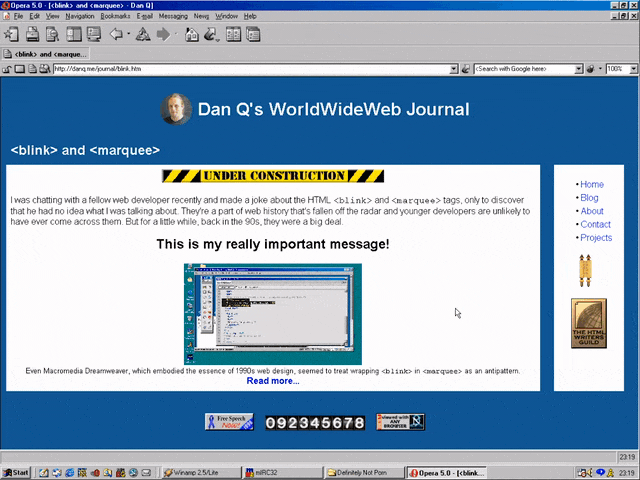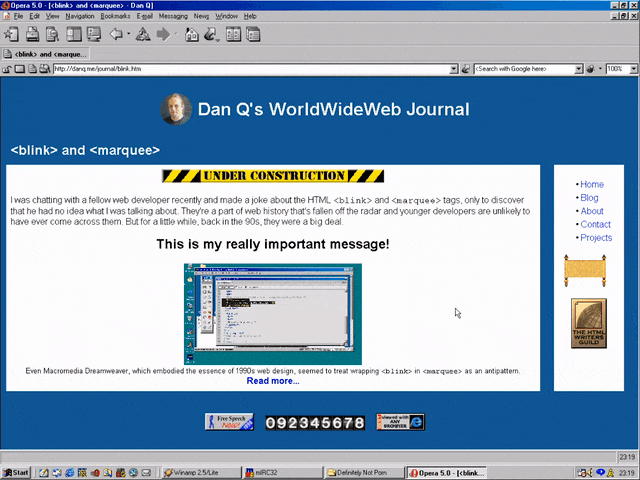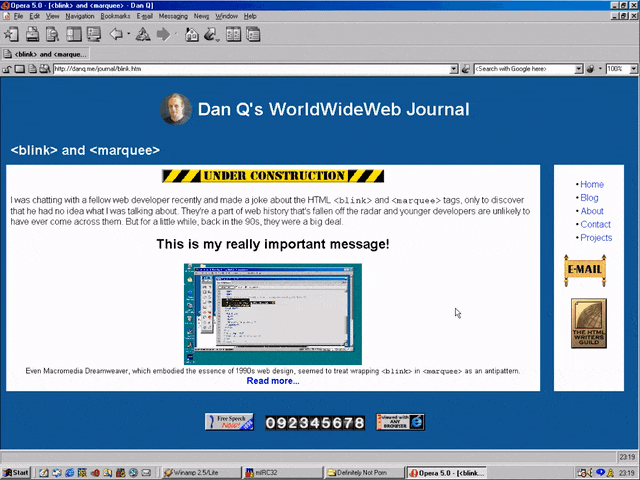
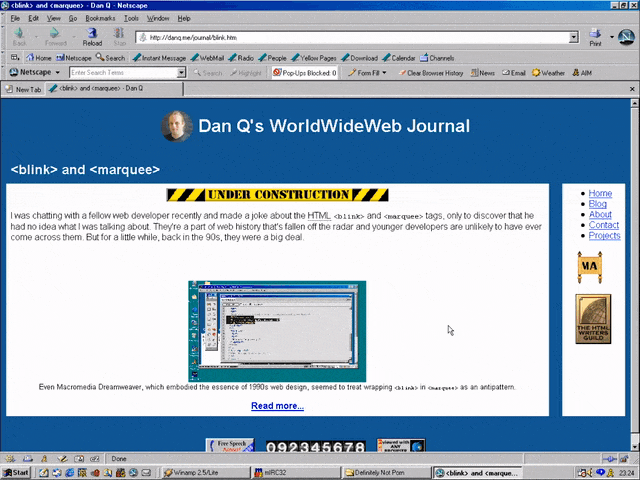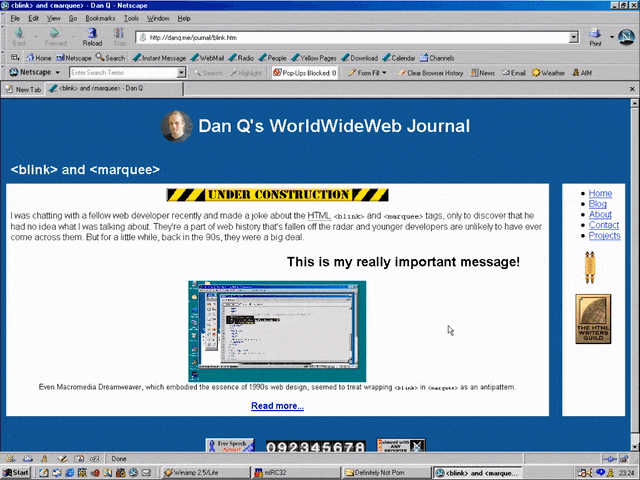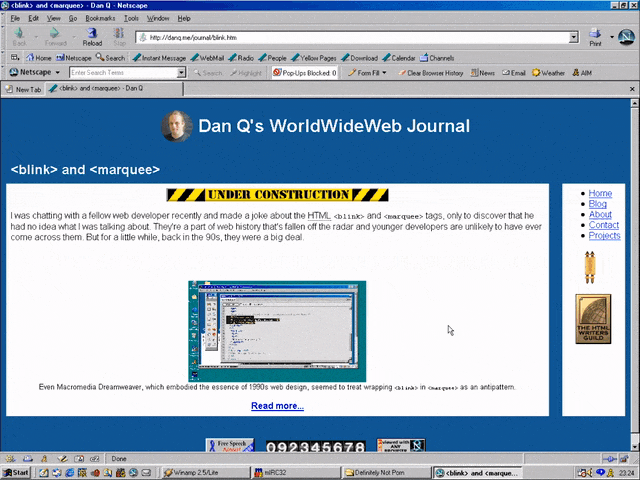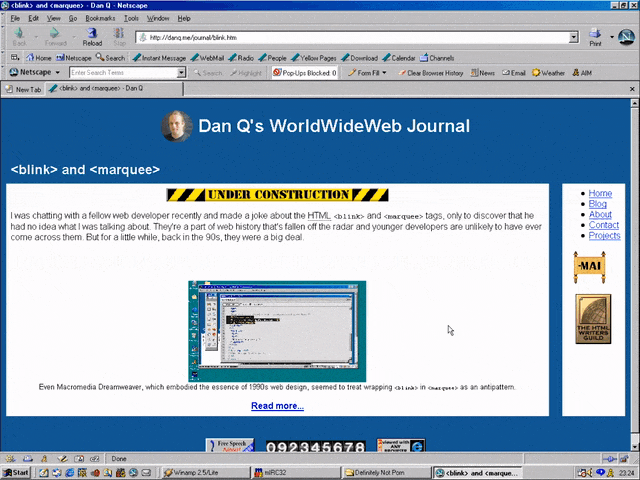
<MARQUEE><BLINK>This is my really important message!</BLINK></MARQUEE>
Wrap a <blink> inside a <marquee> and IE users will see the marquee. Delightful.
The web has always been built on Postel’s Law: a web browser should assume that it won’t understand everything it reads,
but it should provide a best-effort rendering for the benefit of its user anyway. Ever wondered why the modern <video> element is a block rather than a self-closing
tag? It’s so you can embed within it code that an earlier browser – one that doesn’t understand <video> – can read (a browser’s default state when seeing a
new element it doesn’t understand is to ignore it and carry on). So embedding a <blink> in a <marquee> gave you the best of both worlds, right?
(welll…)
Wrap a <blink> inside a <marquee> and Netscape users will see the blink. Joy.
Better yet, you were safe in the knowledge that anybody using a browser that didn’t understand either of these tags could still read your content. Used properly, the
web is about progressive enhancement. Implement for everybody, enhance for those who support the shiny features. JavaScript and CSS can be applied with the same rules, and doing so pays dividends in maintainability and accessibility (though, sadly, that doesn’t stop people writing
sites that needlessly require these technologies).
Personally, I was a (paying! – back when people used to pay for web browsers!) Opera user so I mostly saw neither <blink> nor <marquee> elements.
I don’t feel like I missed out.
I remember, though, the first time I tried Netscape 7, in 2002. Netscape 7 and its close descendent are, as far as I can tell, the only web browsers to support both<blink> and <marquee>. Even then, it was picky about the order in which they were presented and the elements wrapped-within them. But support was
good enough that some people’s personal web pages suddenly began to exhibit the most ugly effect imaginable: the combination of both scrolling and flashing text.
If Netscape 7’s UI didn’t already make your eyes bleed (I’ve toned it down here by installing the “classic skin”), its simultaneous
rendering of <blink> and <marquee> would.
The <blink> tag is very-definitely dead (hurrah!), but you can bring it back with pure CSS if you must.
<marquee>, amazingly, still survives, not only in polyfills but natively, as you might be able to see above. However, if you’re in any doubt as to whether or not
you should use it: you shouldn’t. If you’re looking for digital nostalgia, there’s a whole
rabbit hole to dive down, but you don’t need to inflict <marquee> on the rest of us.
Over the last six years I’ve been on a handful of geohashing expeditions, setting out to functionally-random GPS coordinates to see if I can get there, and documenting what I find when I do. The comic that inspired the
sport was already six years old by the time I embarked on my first outing, and I’m far from the most-active member
of the ‘hasher community, but I’ve a certain closeness to them as a result of my work to resurrect and host the “official” website. Either way: I love the sport.
I even managed to drag-along Ruth and Annabel to a hashpoint (2014-04-21 51 -1) once.
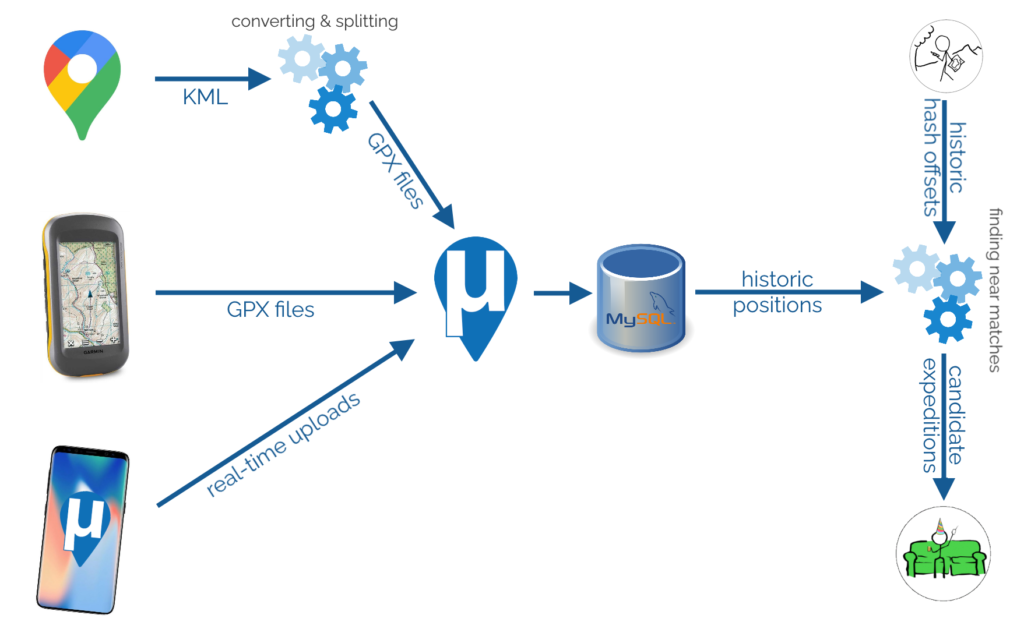
But even when I’ve not been ‘hashing, it occurs to me that I’ve been tracking my location a lot. Three mechanisms in particular dominate:
Google’s somewhat-invasive monitoring of my phones’ locations (which can be exported via Google Takeout)
My personal GPSr logs (I carry the device moderately often, and it provides excellent precision)
The personal μlogger server I’ve been running for the last few years (it’s like Google’s system, but – y’know –
self-hosted, tweakable, and less-creepy)
If I could mine all of that data, I might be able to answer the question… have I ever have accidentally visited a geohashpoint?
Let’s find out.
There’s a lot to my process, but it’s technically quite simple.
Data mining my own movements
To begin with, I needed to get all of my data into μLogger. The Android app syncs to it automatically and uploading from my GPSr was
simple. The data from Google Takeout was a little harder.
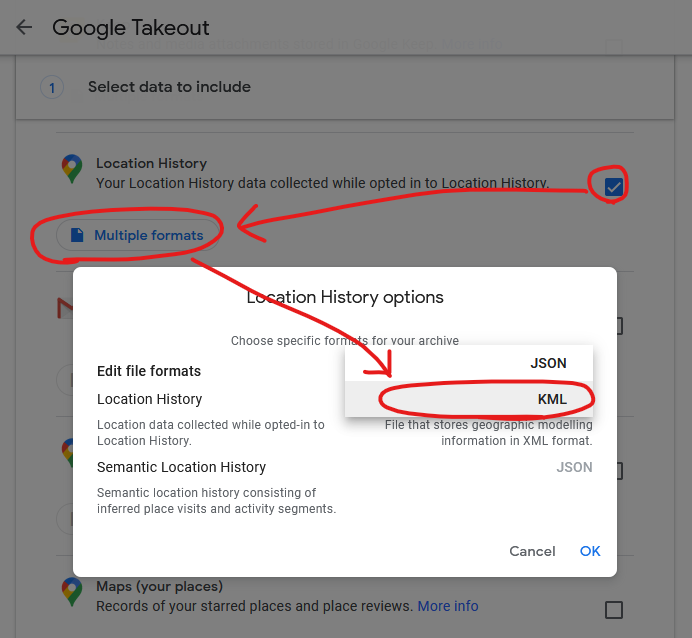
I found a setting in Google Takeout to export past location data in KML, rather than JSON, format. KML is understood by GPSBabel which
can convert it into GPX. I can “cut up” the resulting GPX file using a little grep-fu (relevant xkcd?) to get month-long files and import them into
μLogger. Easy!
It’s slightly hidden, but Google Takeout choose your geoposition output format (from a limited selection).
Well.. μLogger’s web interface sometimes times-out if you upload enormous files like a whole month of Google Takeout logs. So instead I wrote a Nokogiri script to convert the GPX into SQL
to inject directly into μLogger’s database.
Next, I got a set of hashpoint offsets. I only had personal positional data going back to around 2010, so I didn’t need to accommodate for the pre-2008 absence of the 30W time zone rule. I’ve had only one trip to the Southern hemisphere in that period, and I
checked that manually. A little rounding and grouping in SQL gave me each graticule I’d been in on every date.
Unsurprisingly, I spend most of my time in the 51 -1 graticule. Adding (or subtracting, for the Western
hemisphere) the offset provided the coordinates for each graticule that I visited for the date that I was in that graticule. Nice.
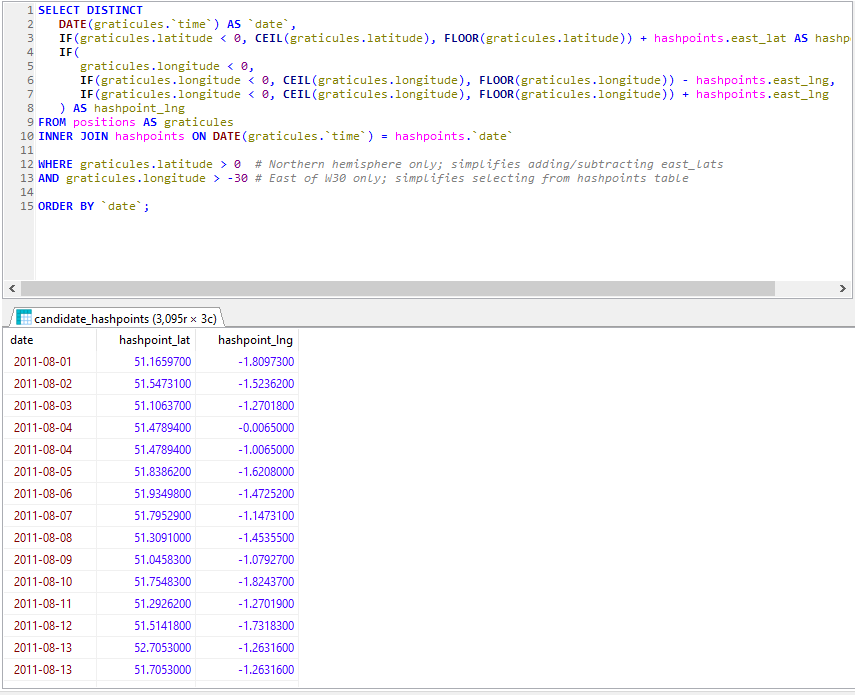
Preloading the offsets into a temporary table made light work of listing all the hashpoints in all the graticules I’d visited, by date. Note that some dates (e.g. 2011-08-04, above)
saw me visit multiple graticules.
The correct way to find the proximity of my positions to each geohashpoint is, of course, to use WGS84. That’s an
easy thing to do if you’re using a database that supports it. My database… doesn’t. So I just used Pythagoras’ theorem to find positions I’d visited that were within 0.15° of a that
day’s hashpoint.
Using Pythagoras for geopositional geometry is, of course, wrong. Why? Because the physical length of a “degree” varies dependent on latitude, and – more importantly – a degree of
latitude is not the same distance as a degree of longitude. The ratio varies by latitude: only an idealised equatorial graticule would be square!
But for this case, I don’t care: the data’s going to be fuzzy and require some interpretation anyway. Not least because Google’s positioning has the tendency to, for example, spot a
passing train’s WiFi and assume I’ve briefly teleported to Euston Station, which is apparently where Google thinks that hotspot “lives”.
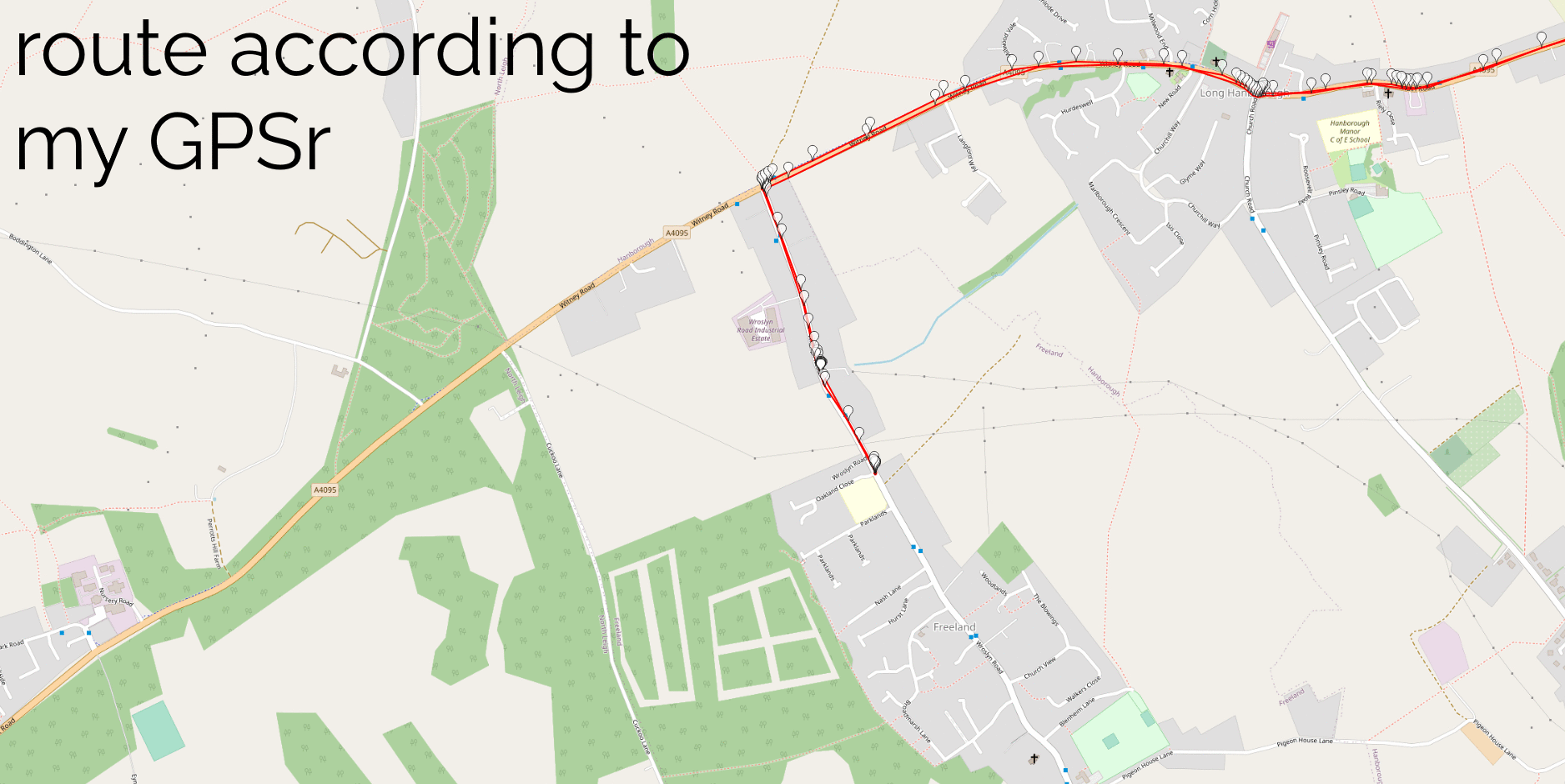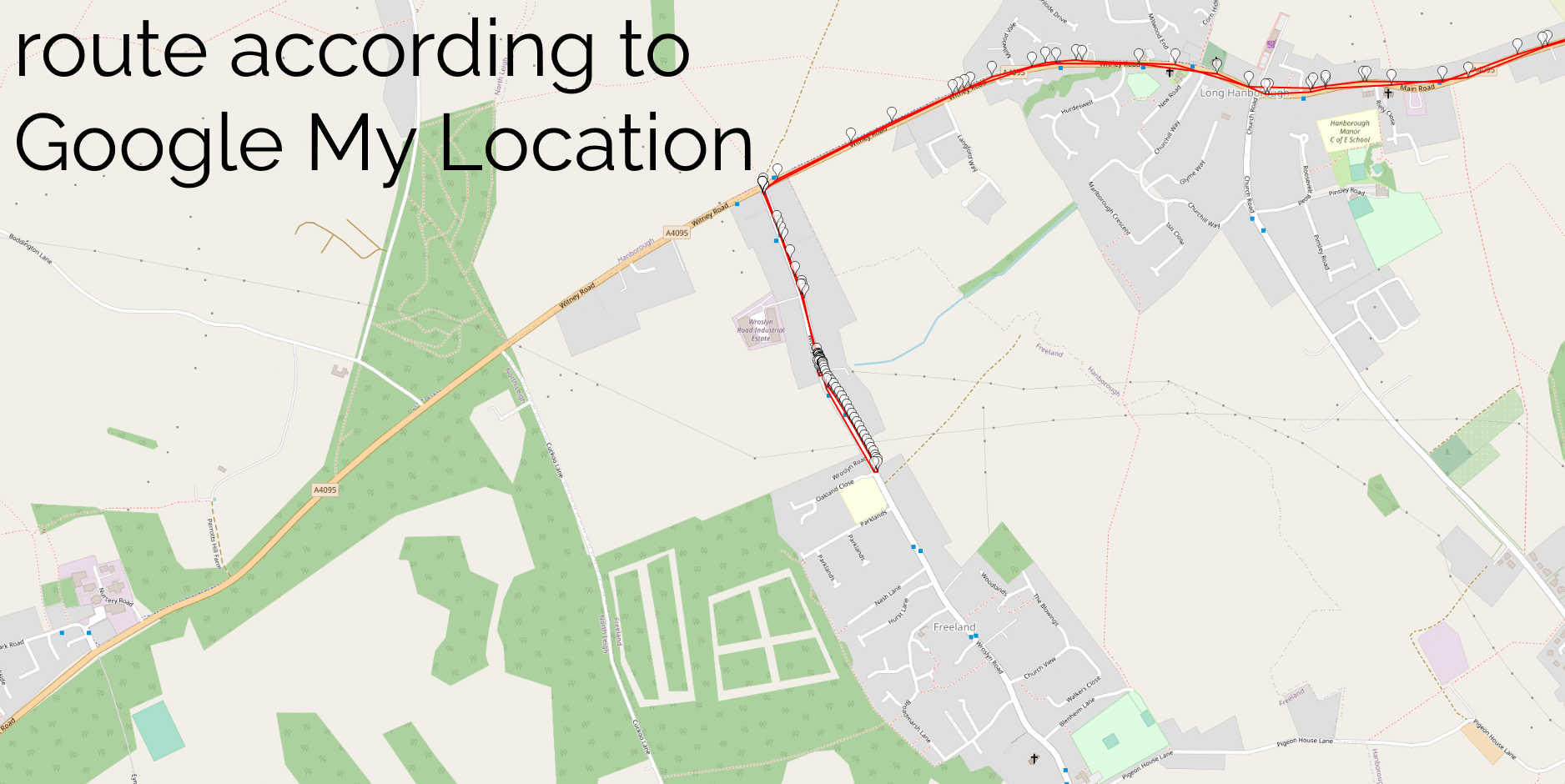
I overlaid randomly-selected Google My Location and GPSr routes to ensure that they coincided, as an accuracy-test. It’s interesting to
note that my GPSr points cluster when I was moving slower, suggesting it polls on a timer. Conversely Google’s points cluster
when I was using data (can you see the bit where I used a chat app), suggesting that Google Location Services ramps up the accuracy and poll frequency when you’re actively
using your device.
I assumed that my algorithm would detect all of my actual geohash finds, and yes: all of these appeared as-expected in my results. This was a good confirmation that my approach
worked.
And, crucially: about a dozen additional candidate points showed up in my search. Most of these – listed at the end of this post – were 50m+ away from the hashpoint and
involved me driving or cycling past on a nearby road… but one hashpoint stuck out.
Hashing by accident
We all had our roles to play in our trip to Edinburgh. Tom… was our pack mule.
In August 2015 we took a trip up to Edinburgh to see a play of Ruth‘s brother Robin‘s. I don’t remember
much about the play because I was on keeping-the-toddler-entertained duty and so had to excuse myself pretty early on. After the play we drove South, dropping Tom off at Lanark station.
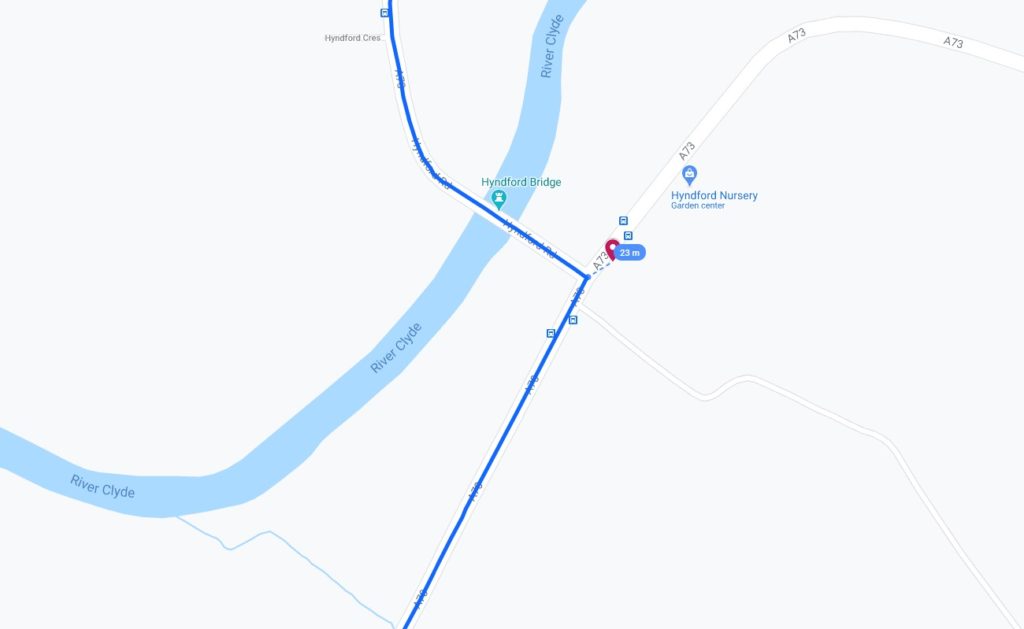
We exited Lanark via the Hyndford Bridge… which is – according to the map – tantalisingly-close to the 2015-08-22 55 -3
hashpoint: only about 23 metres away!
Google puts the centre of the road I drove down only 23m from the 2015-08-22 55 -3 hashpoint (of course, I was actually driving on the near side of the road and may have been closer
still).
That doesn’t feel quite close enough to justify retroactively claiming the geohash, tempting though it would be to use it as a vehicle to my easy geohash ribbon. Google doesn’t provide error bars for their exported location data so I can’t draw a circle of uncertainty,
but it seems unlikely that I passed through this very close hashpoint.
Pity. But a fun exercise. This was the nearest of my near misses, but plenty more turned up in my search, too:
2013-09-28 54 -2 (9,000m)
Near a campsite on the River Eden. I drove past on the M6 with Ruth on the way to Loch Lomond for a mini-break to celebrate our sixth anniversary. I was never more than 9,000 metres
from the hashpoint, but Google clearly had a moment when it couldn’t get good satellite signal and tries to trilaterate my position from cell masts and coincidentally guessed, for a
few seconds, that I was much closer. There are a few such erroneous points in my data but they’re pretty obvious and easy to spot, so my manual filtering process caught them.
2019-09-13 52 -0 (719m)
A600, near Cardington Airstrip, south of Bedford. I drove past on the A421 on my way to Three Rings‘ “GDPR Camp”, which was more fun than it sounds, I promise.
2014-03-29 53 -1 (630m)
Spen Farm, near Bramham Interchange on the A1(M). I drove past while heading to the Nightline Association Conference to talk about Three Rings. Curiously, I came much closer to the hashpoint the previous week when I drove a neighbouring road on my way to York for my friend
Matt’s wedding.
2020-05-06 51 -1 (346m)
Inside Kidlington Police Station! Short of getting arrested, I can’t imagine how I’d easily have gotten to this one, but it’s moot anyway because I didn’t try! I’d taken the day off
work to help with child-wrangling (as our normal childcare provisions had been scrambled by COVID-19), and at some point during the day we took a walk and came somewhat near to the
hashpoint.
2016-02-05 51 -1 (340m)
Garden of a house on The Moors, Kidlington. I drove past (twice) on my way to and from the kids’ old nursery. Bonus fact: the house directly opposite the one whose garden contained
the hashpoint is a house that I looked at buying (and visited), once, but didn’t think it was worth the asking price.
2017-08-30 51 -1 (318m)
St. Frieswide Farm, between Oxford and Kidlington. I cycled past on Banbury Road twice – once on my way to and once on my way from work.
2015-01-25 51 -1 (314m)
Templar Road, Cutteslowe, Oxford. I’ve cycled and driven along this road many times, but on the day in question the closest I came was cycling past on nearby Banbury Road while on the
way to work.
2018-01-28 51 -1 (198m)
Stratfield Brake, Kidlington. I took our youngest by bike trailer this morning to his Monkey Music class: normally at this point in history Ruth would have been the one to take him,
but she had a work-related event that she couldn’t miss in the morning. I cycled right by the entrance to this nature reserve: it could have been an ideal location for a geohash!
2014-01-24 51 -1 (114m)
On the Marston Cyclepath. I used to cycle along this route on the way to and from work most days back when I lived in Marston, but by 2014 I lived in Kidlington and so I’d only cycle
past the end of it. So it was that I cycled past the Linacre College of the path, around 114m away from the hashpoint, on this day.
2015-06-10 51 -1 (112m)
Meadow near Peartree Interchange, Oxford. I stopped at the filling station on the opposite side of the roundabout, presumably to refuel a car.
2020-02-27 51 -1 (70m)
This was a genuine attempt at a hashpoint that I failed to reach and was so sad about that I never bothered to finish writing up. The hashpoint was very close (but just out of sight
of, it turns out) a geocache I’d hidden in the vicinity, and I was hopeful that I might be able to score the most-epic/demonstrable déjà vu/hash collision
achievement ever, not least because I had pre-existing video evidence that I’d been at the
coordinates before! Unfortunately it wasn’t to be: I had inadequate footwear for the heavy rains that had fallen in the days that preceded the expedition and I was in a hurry to get
home, get changed, and go catch a train to go and see the Goo Goo Dolls in concert. So I gave up and quit the expedition. This turned out to be the right decision: going to
the concert one of the last “normal” activities I got to do before the COVID-19 lockdown made everybody’s lives weird.
2014-05-23 51 -1 (61m)
White Way, Kidlington, near the Bicester Road to Green Road footpath. I passed close by while cycling to work, but I’ve since walked through this hashpoint many times: it’s on a route
that our eldest sometimes used to take when walking home from her school! With the exception only of the very-near-miss in Lanark, this was my nearest “near miss”.
No silly grin, but coincidentally – perhaps by accident – I took a picture out of the car window shortly after we passed the hashpoint. This is what Lanark looks like when you drive
through it in the rain.
If you missed it the first time around, click through to explore an interactive panoramic view of my
workspace. It’s slightly more “unpacked” now.
As I approach my first full year as an Automattician, I find myself looking back on everything I’ve learned… but also looking around at all the things I still don’t understand! I’m not
learning something new every day any more… but I’m still learning something new most weeks.
This summer I’ve been getting up-close and personal with Gutenberg components. I’d mostly managed to avoid learning the React (eww; JSX, bad documentation, and an elephantine payload…) necessary to hack Gutenberg, but in
helping to implement new tools for WooCommerce.com I’ve discovered that it’s… not quite as painful as I’d thought. There are even some bits I quite like. But I don’t expect to
fall in love with React any time soon. This autumn I’ve been mostly working on search and personalisation, integrating customer analytics data with our marketplace to help understand
what people look for on our sites and using that to guide their future experience (and that of others “like” them). There’s always something new.
I suppose that by now everybody‘s used to meetings that look like this, but when I first started at Automattic a year ago they were less-commonplace.
My team continues to grow, with two newmatticians this month and a third starting in January. In fact, my team’s planning to fork into two closely-linked subteams; one with a focus on
customers and vendors, the other geared towards infrastructure. It’s exciting to see my role grow and change, but I worry about the risk of gradually pigeon-holing myself into an
increasingly narrow specialisation. Which wouldn’t suit me: I like to keep a finger in all the pies. Still; my manager’s reassuring that this isn’t likely to be the case and
our plans are going in the “right” direction.
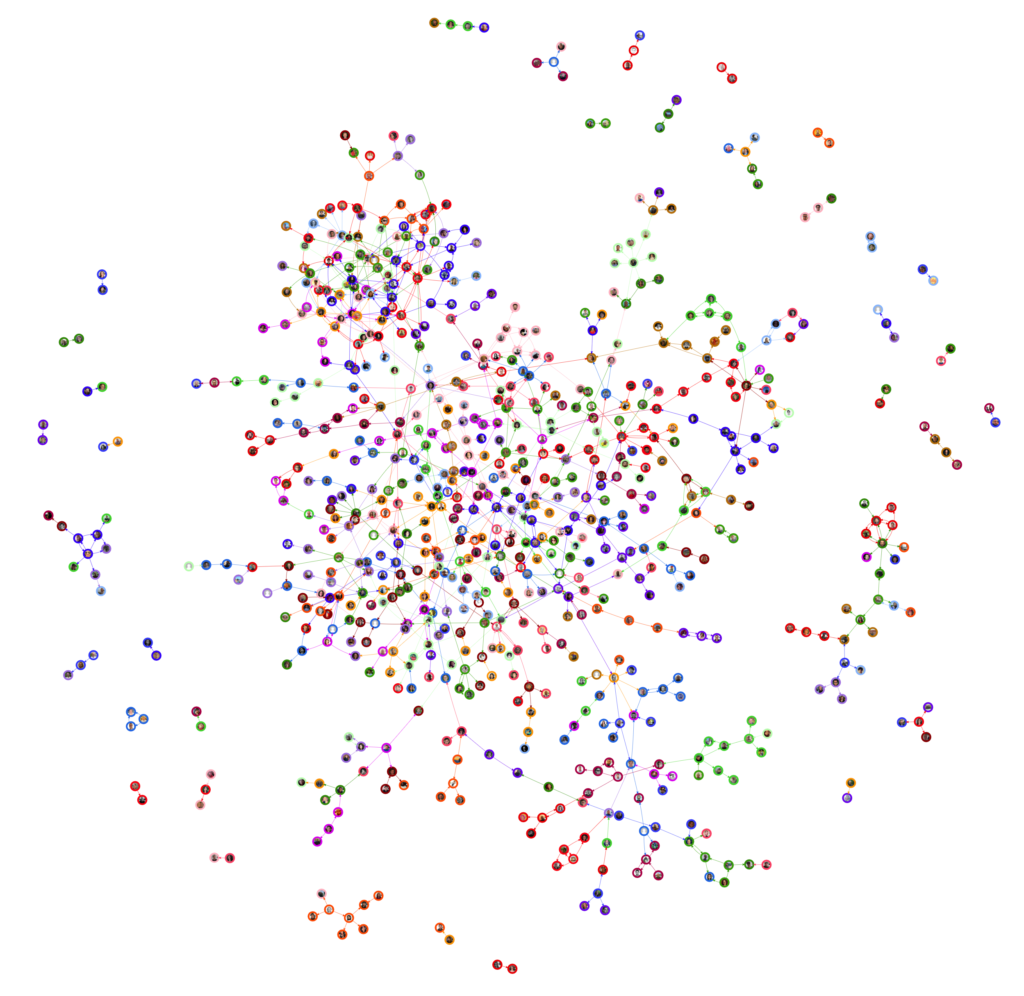
On the side of my various project work, I’ve occasionally found the opportunity for more-creative things. Last month, I did some data-mining over the company’s “kudos” history of the
last five years and ran it through vis.js to try to find a new angle on understanding how Automattic’s staff, teams, and divisions interact with one
another. It lead to some interesting results: panning through time, for example, you can see the separate island of Tumblr staff who joined us
during the acquisition gradually become more-interconnected with the rest of the organisation over the course of
the last year.
Automattic as a social graph of kudos given/received during September 2020, colour-coded by team. Were you one of us, you’d be able to zoom in and find yourself. The large “branch” in
the bottom right is mostly comprised of Tumblr staff.
The biggest disappointment of my time at Automattic so far was that I’ve not managed to go to a GM! The 2019 one – which looked awesome – took place only a couple of weeks before my contract started (despite my best efforts to wrangle
my contract dates with the Bodleian and Automattic to try to work around that), but people reassured me that it was okay because I’d make it
to the next one. Well.. 2020 makes fools of us all, I guess, because of course there’s no in-person GM this year. Maybe, hopefully, if and
when the world goes back to normal I’ll get to spend time in-person with my colleagues once in a while… but for now, we’re having to suffice with Internet-based socialisation only, just
like the rest of the world.
I scratched an itch of mine this week and wanted to share the results with you, in case you happen to be one of the few dozen other people on Earth who will cry “finally!” to discover
that this is now a thing.
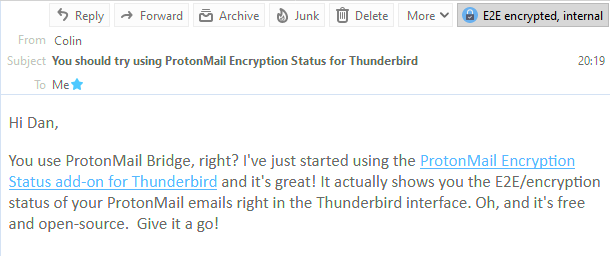
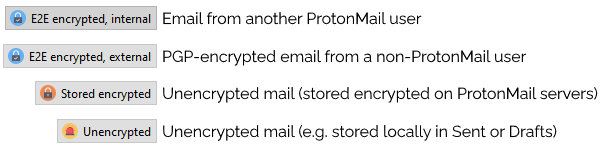
In the top right corner of this email, you can see that it was sent with end-to-end encryption from another ProtonMail user.
I’ve used ProtonMail as my primary personal email provider for about four years, and I love it. Seamless PGP/GPG for proper end-to-end encryption, privacy as standard, etc. At first, I used their web and mobile app interfaces but over time
I’ve come to rediscover my love affair with “proper” email clients, and I’ve been mostly using Thunderbird for my desktop mail. It’s been
great: lightning-fast search, offline capabilities, and thanks to IMAP (provided by ProtonMail Bridge) my mail’s still just as accessible when I fall-back on the web or mobile clients because I’m out and about.
But the one thing this set-up lacked was the ability to easily see which emails had been delivered encrypted versus those which had merely been delivered “in the clear” (like
most emails) and then encrypted for storage on ProtonMail’s servers. So I fixed it.
There are fundamentally four states a Thunderbird+ProtonMail Bridge email can be in, and here’s how I represent them.
I’ve just released my first ever Thunderbird plugin. If you’re using
ProtonMail Bridge, it adds a notification to the corner of every email to say whether it was encrypted in transit or not. That’s all.
And of course it’s open source with a permissive license (and a doddle to compile using your
standard operating system tools, if you want to build it yourself). If you’re using Thunderbird and ProtonMail Bridge you should give it a whirl. And if you’re not then… maybe you
should consider it?
Stupid thing of the day to try on your favourite Slack channel:
1. Make an image of yourself bordered by the edge of a speech bubble. Make the image an exact multiple of 32 pixels in each dimension (this one is 128 × 96):
2. Use ImageMagick to cut the image into 32 × 32 pixel tiles, e.g. like this: magick convert dan-qs-stupid-head.png -crop 32x32
"dan-q-says-%02d.png". Pick a sensible output filename to use as a Slack emoji shortcode.
3. Log into Slack and customise your emoji by adding each of the tiles you’ve created to it. This is where you’ll be glad you named the
file sensibly because it saves you typing the shortcode out each time.
4. Type a message using your custom emoji! Because it sits in-line with text, you can type alongside or around it (unlike normally embedded images or /giphy integration) along with
styling, mentioning, and hyperlink options. You can also copy-paste and edit on-the-fly, so you can keep a copy of the message in your self-channel and adjust whenever you need.
5. Profit!!!
Why not make a whole set of different faces showing your different emotions – perhaps from photos – so you can react appropriately to your colleagues! Slack don’t seem to impose any
limit on the number of custom emoji you can add, so the only limit is your imagination (and the tolerance of your Slack administrator for such high jinks).
Or why not cut up an animated GIF? Slack preloads emoji into the client so they play in-sync, allowing you to run
animations that span multiple emoji?
I’ve been watching the output that people machines around the Internet have been producing using GPT-3 (and its cousins), an AI model that can produce long-form “human-like”
text. Here’s some things I’ve enjoyed recently:
I played for a bit with AI Dungeon‘s (premium) Dragon engine, which came up with Dan and the
Spider’s Curse when used as a virtual DM/GM. I pitched an idea to Robin lately that one could run a vlog series based on AI Dungeon-generated adventures: coming up with a “scene”, performing it, publishing it, and taking
suggestions via the comments for the direction in which the adventure might go next (but leaving the AI to do the real
writing).
Today is Spaceship Day starts out making a little sense but this soon gives way to a more thorough absurdism.
Today is Spaceship Day is a Plotagon-powered machinama based on a script written by Botnik‘s AI. So not technically GPT-3 if you’re being picky but still amusing to how and
what the AI‘s creative mind has come up with.
Language contains the map to a better world. Those that are most skilled at removing obstacles, misdirection, and lies from language, that reveal the maps that are hidden within, are
the guides that will lead us to happiness.
Yesterday, The Guardian published the op-ed piece A robot wrote this entire article.
Are you scared yet, human? It’s edited together from half a dozen or so essays produced by the AI from the same
starting prompt, but the editor insists that this took less time than the editing process on most human-authored op-eds. It’s good stuff. I found myself reminded of Nobody Knows You’re A Machine, a short story I wrote about eight years ago and was never entirely happy with but which I’ve put online in
order to allow you to see for yourself what I mean.
If I came across these hills – with or without deer running atop them – I’d certainly be thinking “yeah, there’s something off about this place.”
But my favourite so far must be GPT-3’s attempt to write its own version of Expert judgment on markers to
deter inadvertent human intrusion into the Waste Isolation Pilot Plant, which occasionally circulates the Internet retitled with its line This place is not a place of
honor…no highly esteemed deed is commemorated here… nothing valued is here. The original document was a report into how humans might mark a nuclear waste disposal site in order to
discourage deliberate or accidental tampering with the waste stored there: a massive challenge, given that the waste will remain dangerous for many thousands of years! The original
paper’s worth a read, of course, but mostly as a preface to reading a post by Janelle Shane (whose work I’ve mentioned before) about teaching GPT-3 to write nuclear waste site area denial strategies. It’s pretty special.
As effective conversational AI becomes increasingly accessible, I become increasingly convinced what we might eventually see
a sandwichware future, where it’s cheaper for an appliance developer to install an AI
into the device (to allow it to learn how to communicate with your other appliances, in a human language, just like you will) rather than rely on a static and universal underlying
computer protocol as an API. Time will tell.
Meanwhile: I promise that this post was written by a human!
Enter the latest iteration of the Android version, Firefox Daylight, which came
out last week.
When you first run Firefox Daylight, you’re asked where you want the address bar, among other things.
First, the good: this latest version of Firefox for Android is fast. Blazingly fast. The privacy controls are clearer and easier to access. Having picture-in-picture mode
on mobile is a nice touch, as is the new generation of tracking prevention features.
But Firefox Daylight still makes me frown. And it’s a trio of smaller things that really niggle:
1. Top or bottom toolbar… but top is a second-class citizen.
In theory, I like the idea of having the address bar and its friends at the bottom of the screen where it’s more-accessible to your thumb. I’ve even tried it, independently. in years
past. But it’s too much of a mental leap for me nowadays, plus it doesn’t cleanly fit into the “scroll down and the address bar disappears” user experience that’s become commonplace.
Making bottom toolbar the default was perhaps a little radical, then, but at least Mozilla provided an option to put it back at the top. But… it’s not quite right:
Sure, I’ll move my thumb the entire height of the screen every time I want to open a new tab.
Even with the toolbar moved back to the top, some controls associated with it stay at the bottom. Want to open a new tab? You have to press the “tabs” button at the top of the
screen, then the “plus” button at the bottom of the screen, then – probably – the address bar back at the top of the screen again! You’ve just covered two complete
lengths of the screen to do something that used to require none. Not a satisfactory experience.
The old interface put the oft-used “add tab” button in the toolbar in the same place as the “tabs” button you just pressed. Much better.
2. Tab previews were more space-efficient before
You’ve probably already spotted the other change to the “current tabs” view. Previously, open tabs were shown as mini previews with their titles above. Now they’re shown as tiny
(sometimes absent) icon-sized previews with their titles alongside. This allows the domain name to be shown, which is nice, but not nice enough to justify reducing the instant
visual recognition the previous interface provided.
It’s not even like you can fit more tabs onto a screen. The capacity is basically the same. You’re just making smaller hit targets with less recognisable graphics. Plus: previously the
most-recent tabs were at the bottom (close to where your thumb is, which was the justification for making the address bar default to the bottom); now they’re at the top, further adding
to the distance travelled.
3. Plugin support is terrible
I know first hand that implementing backwards-compatibility is hard, but breaking most plugins and then providing a list of nine or so popular/recommended ones that
still works isn’t a great experience.
No uMatrix. No Violentmonkey (or any
equivalent). No Ghostery, even! Feels like surfing the Web with one hand tied behind my back.
Feels a bit like this was released before it was ready.
For the time being, I’m using Fennec F-Droid as my primary mobile browser. It picks up exactly where Firefox for
Android left off, and it doesn’t break my workflow. I hope to switch back to regular Firefox for Android someday, but Daylight needs “finishing” first.
You see what that’s doing? It’s loading the stylesheet for the print medium, but then when the document finishes loading it’s switching the media type from “print” to “all”.
Because it didn’t apply to begin with the stylesheet isn’t render-blocking. You can use this to delay secondary styles so the page essentials can load at full speed.
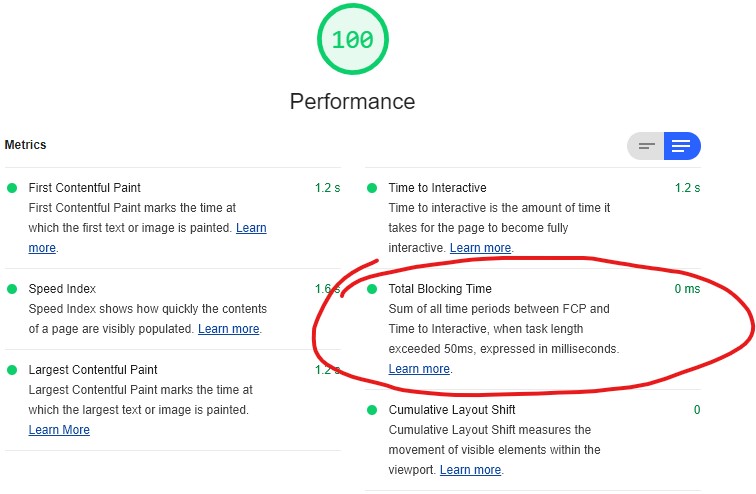
Reducing blocking times, like I have on this page, is one of many steps in optimising perceived page performance.
I don’t like this approach. I mean: I love the elegance… I just don’t like the implications.
Why I don’t like lazy-loading CSS using Javascript
Using Javascript to load CSS, in order to prevent that CSS
blocking rendering, feels to me like it conceptually breaks the Web. It certainly violates the expectations of progressive enhancement, because it introduces a level of
fault-intolerance that I consider (mostly) unacceptable.
CSS and Javascript are independent of one another. A well-designed progressively-enhanced page should function with
HTML only, HTML-and-CSS only, HTML-and-JS only, or all
three.CSS adds style, and JS adds behvaiour to a page; and when
you insist that the user agent uses Javascript in order to load stylistic elements, you violate the separation of these technologies (I’m looking at you, the majority of heavyweight
front-end frameworks!).
If you’re thinking that the only people affected are nerds like me who browse with Javascript wholly or partially disabled, you’re wrong: gov.uk research shows that around 1% of your visitors have Javascript fail for some reason or another: because it’s disabled
(whether for preference, privacy, compatibility with accessibility technologies, or whaterver), blocked, firewalled, or they’re using a browser that you didn’t expect.
Can we lazy-load CSS in a way that doesn’t depend on Javascript? (spoiler: yes)
Chris’s daily tip got me thinking: could there exist a way to load CSS in a non-render-blocking way but which degraded
gracefully in the event that Javascript was unavailable? I.e. if Javascript is working, lazy-load CSS, otherwise: load
conventionally as a fallback. It turns out, there is!
In principle, it’s this:
Link your stylesheet from within a <noscript> block, thereby only exposing it where Javascript is disabled. Give it a custom attribute to make it easy to find
later, e.g. <noscript lazyload> (if you’re a standards purist, you might prefer to use a data- attribute).
Have your Javascript extract the contents of these <noscript> blocks and reinject them. In modern browsers, this is as simple as e.g.
[...document.querySelectorAll('noscript[lazyload]')].forEach(ns=>ns.outerHTML=ns.innerHTML).
If you need support for Internet Explorer, you need a little more work, because Internet Explorer doesn’t expose<noscript> blocks to the DOM in a helpful way. There are a variety of possible workarounds; I’ve implemented one but not put too much thought into it because I rarely have to
think about Internet Explorer these days.
In any case, I’ve implemented a proof of concept/demonstration if you’d like to see it in action: just take a look and view source (or read the page)
for details. Or view the source alone via this gist.
Lazy-loading CSS using my approach provides most of the benefits of other approaches… but works properly in environments without
Javascript too.
Update: Chris Ferdinandi’s refined this into an even cleaner approach that takes the best of both worlds.