Last month I was on em’s personal site, where I discovered their contact page
lists not only the usual methods (email addresses, socials, contact forms etc.) but also a postal address1: how cool is that‽ I could have written in
their guestbook… but obviously I took the option to send a postcard instead!
Now I’ve set up a PO Box of my own, and I’ve love it if you feel up to saying “hi” via a postcard2.
As a bonus, it’s more-likely to get through than anything that has to face-off against my spam filter!
So, if you want to send me a letter or postcard (no parcels, nothing that needs a signature), my address is:
Dan Q
Unit 159610
PO Box 7169
Poole
BH15 9EL
United Kingdom
I may have raved about other concept albums in the meantime (this one, for example…), but The Signal and the Noise still makes my top 101. I’ve listened to it twice this week, and I still love it.
But I probably love it differently than I used to.
Spy Numbers / One Time Pad remains my favourite pair of tracks on the album, as it always was: like so much of Andy’s music it tells a story that feels almost
like it belongs to a parallel universe… but that’s still relatable and compelling and delightful. And a fun little bop, too.
But In Potential, which I initially declared “a little weaker than the rest” of the album, has grown on me immensely over the course of the last decade. It presents an
optimistic, humanistic conclusion to the album that I look forward to every time. After John Frum Will Return and Checker Charlie open the album in a way that
warns us, almost prophetically, about the dangers of narrow target-lock thinking and AI dependence2, In Potential provides a beautiful and hopeful introspective
about humanity and encourages an attitude of… just being gentle and forgiving with ourselves, I guess.
So yeah, the whole thing remains fantastic. And better yet: Andy announced about six weeks ago that all of his
music is now available under a free/pay-what-you-like model, so if you missed it the first time around, now’s your opportunity to play catch-up!3
This has been doing the rounds; I last saw it on Kev’s blog. I like that the social blogosphere’s doing this kind
of fun activity again, these days1.
1. Do you floss your teeth?
Umm… sometimes? Not as often as I should. Don’t tell my dentist!
Usually at least once a month, never more than once a week. I really took to heart some advice that if you’re using a fluoridated mouthwash then you shouldn’t do it close to when you
brush your teeth (or you counteract the benefits), so my routine is that… when I remember and can be bothered to floss… I’ll floss and mouthwash, but like in the middle of the day.
And since I moved my bedroom (and bathroom) one floor further up our house, it’s harder to find the motivation to do so! So I’m probably flossing less. The unanticipated knock-on effect
of extending your house!
2. Tea, coffee, or water?
I love a coffee to start a workday, but I have to be careful how much I consume because caffeine hits me pretty hard, even after a concentrated effort over the last 10 years or so to
gradually increase my tolerance. I can manage a couple of mugs in the morning and be fine, now, but three coffees… or any in the mid-afternoon onwards… and I’m at risk of
throwing off my ability to sleep later2.
I wear holes in footwear (and everything else I wear) faster than anybody I know, so nowadays I go for good-value comfort over any other considerations when buying shoes.
One time it was the dog’s fault that my footwear fell apart, but usually they do so by themselves.
4. Favourite dessert?
Varies, but if we’re eating out, I’m probably going to be ordering the most-chocolatey dessert on the menu.
5. The first thing you do when you wake up?
The very first thing I do when I wake up is check how long it is before I need to get up, and make a decision about when I’m going to do so. I almost never need my alarm
to wake me: I routinely wake up half an hour or so before my alarm would go off, most mornings. But exactly how early I wake directly impacts what I do next. If I’m
well-rested and it’s early enough, I’ll plan on getting up and doing something productive: an early start to work, or some voluntary work for Three Rings, or some correspondence. If it’s close to the time I need to get up I’ll more-often just stay in bed and spend longer doing
the actual answer I should give…
…because the “real” answer is probably: pick up my phone, and open up FreshRSS – almost always the
first and last thing I do online in a day! I’ll skim the news and blogosphere and “set aside” for later anything I’d like to re-read or look at later on.
6. Age you’d like to stick at?
Honestly, I’m good where I am, thanks.
Sure, I was fitter and healthier in my 20s, and I had more free time in my early 30s… and there are certainly things I miss and get nostalgic about in any era of my life. But
conversely: it took me a long, long time to “get my shit together” to the level I have now, and I wouldn’t want to have to go through all of the various bits of
self-growth, therapy, etc. all over again!
So… sure, I’d be happy to transplant my intellect into 20-year-old me and take advantage of my higher energy level of the time for an extra decade or so3. But I wouldn’t go back even a
decade if it meant that I had to go relearn and go through everything from that decade another time, no thanks!
7. How many hats do you own?
Four. Ish.
They are:
A bandana. Actually, I own maybe half a dozen bandanas, mostly in Pride rainbow colours. Bandanas are amazingly versatile: they fold small which suits my love of travelling light these last few years, they can function as headgear, dust mask, neckerchief,
flannel, etc.4, and they do a pretty good job of
keeping my head cool and protecting my growing bald spot from the fierce rays of the summer sun.
A “geek” hat. Okay, I’ve actually got three of these, too, in slightly different designs. When they first started appearing at Oxford Geek Nights, I just kept winning them! I’m not a huge fan of caps, so mostly the kids wear them… although
I do put one on when I’m collecting takeaway food so I can get away with just putting e.g. “geek hat” in the “name” field, rather than my name5.
A warm hat that comes out only when the weather is incredibly cold, or when I’m skiing. As I was reminded while skiing on my recent trip to Finland, I should probably switch to wearing a helmet when I ski, but I’ve been skiing for three to four decades without one
and I find the habit hard to break.6
A wooly hat that I was given by a previous employer at a meetup in Mexico last year. I wore it a couple of times last winter
but it’s otherwise not seen much use.
8. Describe the last photo you took?
The last photo I took was of myself wearing a “geek” hat. You’ve seen it, it’s above!
But the one before that was this picture of an extremely large bottle of champagne, with a banana for scale, that was delivered to my house earlier today:
A 6-litre champagne bottle is properly-termed a Methuselah, after Noah’s grandad I guess.
Ruth and JTA celebrate their anniversary every few years with the “next size up” of champagne bottle, and this is the one they’re up to. This
year, merely asking me to help them drink it probably won’t be sufficient (that’d still be two litres each!) so we’re probably going to have to get some friends over.
I took the photo to send to Ruth to reassure her that the bottle had arrived safely, after the previous attempt went… less well. I added the banana “for scale” before sharing the photo with some other friends, too.
The previous delivery… didn’t go so well. 😱
9. Worst TV show?
PAW Patrol. No doubt.
You know all those 1980s kids TV shows that basically existed for no other purpose than as a marketing vehicle for a range of toys? I’m talking He-Man (and
She-Ra), Transformers, G.I. Joe, Care Bears, M.A.S.K., Rainbow Brite, and My Little Pony. Well,
those shows look good compared to PAW Patrol.
Six pups, each endowed with exactly one personality trait7
but a plethora of accessories and vehicles which expands every season so that no matter how many toys you’ve got, y0u’re always behind the curve.
10. As a child, what was your aspiration for adulthood?
This is the single most-boring thing about me, and I’ve doubtless talked about it before. At some point between the age of about six and eight years old, I decided that I
wanted to grow up and become… a computer programmer.
And then I designed the entirety of the rest of my education around that goal. I learned a variety of languages and paradigms under my own steam while setting myself up for a GCSE in
IT, and then A-Levels in Maths and Computing, and then a Degree in Computer Science, and by the time I’d done all of that I was already working in the industry: self-actualised by 21.
Like I said: boring!
Your turn!
You should give this pointless quiz a go too. Ping/Webmention me if you do (or comment below, I suppose); I’d love to read what you write.
Footnotes
1 They’re internet memes, in the traditional sense, but sadly people usually use
“meme” nowadays exclusively to describe image memes, and not other kinds of memetic Internet content. Just another example of our changing
Internet language, which I’ve written about before. Sometimes they were silly quizzes (wanna know what Meat Loaf song I
am?); sometimes they were about you and your friends. But images, they weren’t: that came later.
2 Or else I’ll get a proper jittery heart-flutter going!
3 I wouldn’t necessarily even miss the always-on, in-your-pocket, high-speed Internet of
today: the Internet was pretty great back then, too!
4 Obviously an intergalactic hitch-hiker should include a bandana, perhaps as
well as an equally-versatile towel, in their toolkit.
5 It’s not about privacy, although that’s a fringe benefit I suppose: mostly it’s about
getting my food quicker! If I walk into Dominos wearing a geek hat and they’ve got pizza on the counter with a label on it that says it’s for “geek hat”, they’ll just hand it over, no
questions, and I’m in-and-out in seconds.
6JTA observed that similar excuses
were used by people who resisted the rollout of mandatory seatbelt usage in cars, so possibly I’m the “bad guy” here.
7 From left to right, the single personality traits for each of the pups are (a) doesn’t
like water, (b) is female, (c) likes naps, (d) is allergic to cats, (e) is clumsy, and (f) is completely fucking pointless.
Very easy find for the kids and I after a delightful visit to the Tram Museum. We went to the coordinates and instantly saw the cache! SL, TFTC, and greetings from Oxfordshire, UK.
Found after an embarrassingly long hunt! After reading the hint I quickly spotted the correct hiding spot, but said to myself “no, it surely can’t be there” and moved on. Only
on my third time walking past it did I think to actually try it, and sure enough, there it was! SL, TFTC, and greetings from Oxfordshire, UK!
Third of three finds on this, my final morning here before my flight to Helsinki. Taking a brisk walk/slow jog up to Hotel Levi Panorama, but first, a QEF. TFTC, and greetings from
Oxfordshire, UK!
The second of three caches hunted on this, the final morning of my brief stay in Lapland. Found on the second host I tried. Greetings from Oxfordshire, UK. TFTC!
It’s the final morning of my short visit to Sirkka. Having 90 minutes until I need to set off for the airport, I decided to come out for a quick geocaching expedition first.
This was the first cache on my list, and I was so glad to choose it. A truly beautiful and well-maintained cache in a wonderful spot. FP awarded. TFTC!
Second “surprising Finnish confectionary” is Vihreät Kuulat Jaffa Cakes. I ran vihreät kuulat through a translation tool and apparently it means “green balls”, which doesn’t tell me
much.
Knowing it was neither lime nor apple (which were also available in the supermarket I visited) I had to try them, but I couldn’t place the flavour. They were tasty, though. We
finished eating them before I looked it up.
Turns out it’s pear flavour, which apparently I have a blind spot for (back
in 2013 at an “eat mystery food in the dark” restaurant I failed to identify that I was eating poached pears for dessert).
Now I need to be on the lookout for actual green balls.
Buying a bag of Haribo in Finland, I shouldn’t have been surprised (given the country’s love of salmiakki) that the black ones were liquorice flavoured.
And yet somehow, when I chucked a handful onto my mouth, I was.
(Not in a bad way. But definitely in a surprised way.)
It’s not often these days that I have the experience of “I didn’t know the Web could do that‽”
Once was when I saw DHTML Lemmings, for example, at a time when adding JavaScript to a page usually
meant you were doing nothing more-sophisticated than adding a tooltip/popover or switching the images in your mystery
meat navigation menu. Another was when I saw Google Earth’s browser-based implementation for the first time, performing 3D manipulations of a quality that I’d
previously only seen in dedicated applications.
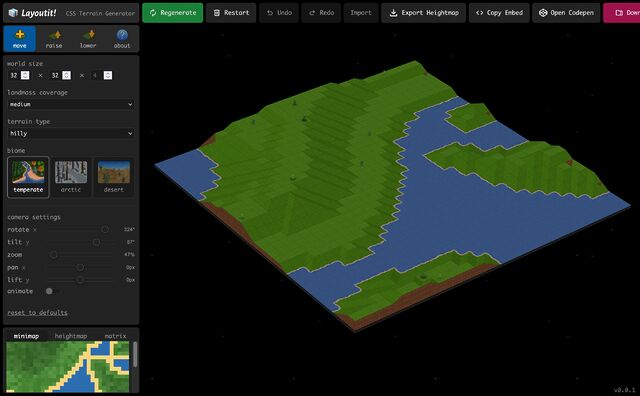
But I got that today when I played with Layoutit! Terra (from the folks behind one of the better CSS grid layout generators). It’d be
pretty cool if it were “just” a Transport Tycoon-like landscape generator and editor, but the thing that blew my mind was discovered that it’s implemented entirely in HTML and CSS… not
a line of JavaScript to be seen. Even speaking as somebody who played… and then reverse-engineered… things like Blackle Mori’s CSS Puzzle
Box, I can’t even begin to fathom how I’d begin to conceive of such a thing, let alone implement it.