What a curious question! For me, it’s perhaps best divided into public and private communication, for which I use very different media:
Public
I’ve written before about how this site – my blog – is the centre of my digital “ecosystem”. And while the technical details may have changed
since that post was published, the fundamentals have not: everything about my public communication revolves around this, right here.
When I vlog, the primary/first version is published here; secondary copies might appear e.g. on my YouTube
channel for visibility but the “official” version remains here
Content gets syndicated elsewhere via a variety of mechanisms, for visibility2.
This is what I’m talking about.
Private
For private communication online, I perhaps mostly use the following (in approximate order of volume):
Slack: we use Slack at Automattic; we use Slack at Three Rings; we’ve
even got a “household” instance running for The Green!3
WhatsApp: the UI‘s annoying (but improving), but its the go-to communications platform of my of my friends and
family, so it’s a big part of my online communications strategy.4
Email: Good old-fashioned email5. I prefer
to encrypt, or at least sign, my email: sure, PGP/GPG‘s not
perfect6, but it’s better than, y’know, not securing your email at
all.
Discord: I’m in a couple of Discord servers, but the only one I pay any reasonable amount of attention to is the Geohashing one.
Various videoconferencing tools including Google Meet, Zoom, and Around. Sometimes you’ve just gotta get (slightly more) face-to-face.
Signal: I feel like everybody’s on WhatsApp now, and the Signal app got annoying when it stopped being able to not only send but even receive SMS messages (which aren’t technically Internet messages, usually), but I still send/receive a few Signal messages in a typical month.
That’s a very different set of tech stacks than I use in my “public” communication!
Footnotes
1 My thinking is, at least in part: I’ve seen platforms come and go, and my blog’s
outlived them. I’ve seen platforms change their policies or technology in ways that undermine the content I put on them, but the stuff on my blog remains under my control and I can
“fix” it if I wish. Owning your data is awesome, although I perhaps do it to a
more-extreme extent than many.
2 I’ve used to joke that I syndicate content to e.g. Facebook to support readers who
haven’t learned yet to use a feed reader. I used to, and I still do, too.
3 A great thing about having a “personal” Slack installation is that you can hook up your
own integrations and bots to e.g. remind you to bring the milk in.
4 I’ve been experimenting with Texts to centralise
several of my other platforms; I’m not convinced by it yet, but I love the thinking! Long ago, I used to love using Pidgin for simultaneous access to
IRC, ICQ, MSN Messenger, Google Talk, Yahoo! Messenger and all that jazz, so I fully approve of the concept.
5 Okay, not actually old-fashioned because I’m not suggesting you use
UUCP to send mail to protonmail!danq!dan or DECnet to deliver to danq.me::dan or something!
6 Most of the metadata including sender, recipient, and in most cases even
subject is not encrypted.
Tracy Durnell’s post
about blogrolls really spoke to me. Like her, I used to think of a blogroll as a list of people you know personally (who happen to blog)1, but the number of bloggers among my immediate
in-person circle of friends has shrunk from several dozen to just a handful, and I dropped my blogroll in around 2008.
On the Internet, a blogger is only as alone as they choose to be.
But my connection to a wider circle has grown, and like Tracy I enjoy the “hardly strangers” connection I feel with the people I follow online. She writes:
While social media emphasizes the show-off stuff — the vacation in Puerto Vallarta, the full kitchen remodel, the night out on the town — on blogs it still seems that people are
sharing more than signalling. These small pleasures seem to be offered in a spirit of generosity — this is too beautiful not to share.
…
Although I may never interact with all the folks whose blogs I follow, reading the same blogger for a long time does build a (one-sided) connection. I may not know you, author,
but I am rooting for you. It’s a different modality of relationship than we may be used to in person, but it’s real: a parasocial relationship simmering with the potential for
deeper connection, but also satisfying as it exists.
At its core, blogging is a solitary activity with many (if not most) authors claiming that their blog is for them – myself included. Yet, the implication of audience cannot be
ignored. Indeed, the more an author embeds themself in the loose community of blogs, by reading and linking to others, the more that implication becomes reality even if not actively
pursued via comments or email.
To that end: I’ve started publishing my blogroll again! Follow that link and you’ll see an only-lightly-curated list of all the people (plus
some non-personal blogs, vlogs, and webcomics) I follow (that have updated their feeds within the last year2). Naturally, there’s an
OPML version too, and I’ve open-sourced the code I used to generate it (although I can’t imagine
anybody’s situation is enough like mine for it to be useful).
The page is a little flaky and there’s things I’d like to do to improve it, but I’d rather publish a basic version now and then come back to it with my gardening gloves on another time to improve it.
Maybe my blogroll has some folks on that you might recognise? Or else: maybe you’re only a single random-click away from somebody new you
never heard of before!
Footnotes
1 Possibly marked up with XFN to
indicate how you’re connected to one another, but I’ve always had a soft spot
for XFN.
Automattic has acquired the ActivityPub plugin for WordPress from German developer Matthias Pfefferle, who will be joining the company to continue improving support for federated platforms. Pfefferle, who is also the
author of the Webmention plugin, said his new role is to see how Automattic’s products can benefit from open protocols like
ActivityPub.
…
This is so exciting I might burst. Want to know why?
Matt Mullenweg‘s commitment to ActivityPub makes me happy. WordPress made Pingback and Trackback take off, back
in the day, and I believe that – in the same way – Automattic can help make ActivityPub more accessible and mainstream too.
Matthias Pfefferle is both an IndieWeb and an ActivityPub star; I use (and I’ve extented upon) a lot of code he’s written every day and
I sponsor him on Github! The chance that we get to work directly together is pretty slim, but it’s a chance right?
Susan A. Kitchens expressed concern that this could increase the level of
ActivityPub spam out there (which right now is very low). I worry about that too. But I’m still optimistic that we can make something awesome off the back of this acquisition and keep
the interpersonal Web federated, the way it ought to be.
This is a reply to a post published elsewhere. Its content might be duplicated as a traditional comment at the original source.
In his blog post “The ethics of syndicating comments using WebMentions”, Terence Eden said:
…
I want to see what people are writing in public about my posts. I also want to direct people to the conversations which are happening elsewhere on the web. But people – quite
rightly – might not want their content permanently stored by my site.
So I think I have a few options.
Do nothing. My site; my rules. If you don’t want me to grab your hot takes, don’t post them in public. (Feels a bit rude, TBQH.)
Be reactive. If someone asks me to remove their content, do so. (But, of course, how will they know I’ve made a copy?)
Stop syndicating comments. (I don’t wanna!)
Replace the verbatim comments with a link saying “Fred mentioned this article on Twitter” . (A bit of a disruptive experience for readers.)
Use oEmbed to capture the user’s comment and dynamically load it from the 3rd party site. That would update automatically if the user changes their name or deleted the
comment. (A massive faff to set up.)
…
Terence describes a problem that I’ve wrestled with myself. If somebody comments directly on my blog using the form at the bottom of a post, that’s a pretty strong indicator of
them giving their consent for their comment to be published at the bottom of that post (at my discretion). If somebody publicly replies somewhere my post is syndicated, that’s
less-obvious, but still pretty clear. If somebody merely mentions my post publicly, writing their own post and linking to mine… that’s a real fuzzy area.
I take a minimal approach; only capturing their full content if it’s short and otherwise trying to extract a snippet that contains the bit that mentioned my content, and I think that
works great. But Terence points out an important follow-up: what if the commenter deletes that content?
My approach so far has always been a reactive one – the second in Terence’s list – and I think it’s a morally-acceptable stance for a personal blogger. But I’m not sure it scales. I
find myself asking: what if a news outlet did this, taking my self-published feedback to their story and publishing it on their site, even if I later amended, retracted, or deleted it
on my own? If somebody’s making money out of my content, that feels different: I’ve always been clear that what I write on my blog is permissively-licensed, but that permissiveness is based on the prohibition of
commercial use of my content.
Perhaps down the line this can be solved technologically: something machine-readable akin to the <link rel="license" ...> tag could state an author’s preference for
how their content is syndicated by third parties they’ve mentioned, answering questions like:
Can you quote me, or just link to me? Who do these rules apply to? (Should we be attaching metadata to individual links?)
Should you inform me that you’ve done so, and if so: how (WebMention, etc.)?
If you (or your site) observe that my content has disappeared or changed for an extended time, should that be taken as revokation of consent to syndicate it?
Right now, the relevant technologies are not well-established enough to even begin this kind of work, but if a modern interconected federated web of personal websites takes off, it’s
the kind of question we might one day have to answer.
For now my gut feeling is that option #2 (reactive moderation of syndicated comments) is ethically-sufficient for personal websites. But I’ll be watching the feedback Terence (who
probably gets many more readers than I) receives in case my gut doesn’t represent the majority!
Just in time for Robin Sloan to give up on Spring ’83, earlier this month I finally got aroud to launching STS-6 (named for the first mission of the Space Shuttle Challenger in Spring 1983), my experimental Spring ’83 server. It’s
been a busy year; I had other things to do. But you might have guessed that something like this had been under my belt when I open-sourced a keygenerator for the protocol the other day.
If you’ve not played with Spring ’83, this post isn’t going to make much sense to you. Sorry.
My server is, as far as I can tell, very different from any others in a few key ways:
It does not allow third-party publishing at all. Some might argue that this undermines the aim of the exercise, but I disagree. My IndieWeb inclinations lead me to
favour “self-hosted” content, shared from its owners’ domain. Also: the specification clearly states that a server must implement a denylist… I guess my denylist simply includes all keys that are
not specifically permitted.
It’s geared towards dynamic content.My primary board self-publishes whenever I produce a new blog post, listing the most recent blog posts published. I have
another half-implemented which shows a summary of the most-recent post, and another which would would simply use a WordPress page as its basis – yes, this was content
management, but published over Spring ’83.
It provides helpers to streamline content production. It supports internal references to other boards you control using the format {{board:123}}which are
automatically converted to addresses referencing the public key of the “current” keypair for that board. This separates the concept of a board and its content template from that
board’s keypairs, making it easier to link to a board. To put it another way, STS-6 links are self-healing on the server-side (for local boards).
It helps automate content-fitting. Spring ’83 strictly requires a maximum board size of 2,217 bytes. STS-6 can be configured to fit a flexible amount of dynamic
content within a template area while respecting that limit. For my posts list board, the number of posts shown is moderated by the size of the resulting board: STS-6 adds more and
more links to the board until it’s too big, and then removes one!
It provides “hands-off” key management features. You can pregenerate a list of keys with different validity periods and the server will automatically cycle through
them as necessary, implementing and retroactively-modifying <link rel="next"> connections to keep them current.
I’m sure that there are those who would see this as automating something that was beautiful because it was handcrafted; I don’t know whether or not I agree, but had Spring ’83
taken off in a bigger way, it would always only have been a matter of time before somebody tried my approach.
From a design perspective, I enjoyed optimising an SVG image of my header so it could meaningfully fit into the board. It’s
pretty, and it’s tolerably lightweight.
If you want to see my server in action, patch this into your favourite Spring ’83 client:
https://s83.danq.dev/10c3ff2e8336307b0ac7673b34737b242b80e8aa63ce4ccba182469ea83e0623
A dead end?
Without Robin’s active participation, I feel that Spring ’83 is probably coming to a dead end. It’s been a lot of fun to play with and I’d love to see what ideas the experience of it
goes on to inspire next, but in its current form it’s one of those things that’s an interesting toy, but not something that’ll make serious waves.
In his last lab essay Robin already identified many of the key issues with the system (too complicated, no interpersonal-mentions, the challenge of keys-as-identifiers, etc.) and while
they’re all solvable without breaking the underlying mechanisms (mentions might be handled by Webmention, perhaps, etc.), I
understand the urge to take what was learned from this experiment and use it to help inform the decisions of the next one. Just as John Postel’s Quote of the Day protocol doesn’t see much use any more (although maybe if my
finger server could support QotD?) but went on to inspire the direction of many subsequent “call-and-response” protocols,
including HTTP, it’s okay if Spring ’83 disappears into obscurity, so long as we can learn what it did
well and build upon that.
Meanwhile: if you’re looking for a hot new “like the web but lighter” protocol, you should probably check out Gemini. (Incidentally, you
can find me at gemini://danq.me, but that’s something I’ll write about another day…)
In the light of the so-called “Twitter migration”, I’ve spent a lot of the last week helping people new to Mastodon/the Fediverse in general to understand it. Or at least, to understand
how it’s different from Twitter.1
If you’re among those jumping ship, by the way, can I recommend that you do two things:
Don’t stop after reading an article about what Mastodon is and how it works (start here!); please also read about the established
etiquette, and
Don’t come in with the expectation that it’s “like Twitter but…”, because the ways it’s not like Twitter are more-important (and nobody wants it to be more like Twitter).
The tools, protocols and culture of the fediverse were built by trans and queer feminists. Those people had already started to feel sidelined from their own project when people like
me started turning up a few year ago. This isn’t the first time fediverse users have had to deal with a significant state change and feeling of loss. Nevertheless, the basic
principles have mostly held up to now: the culture and technical systems were deliberately designed on principles of consent, agency, and community safety.
…
If the people who built the fediverse generally sought to protect users, corporate platforms like Twitter seek to control their users… [Academics and advertisers] can claim that
legally Twitter has the right to do whatever it wants with this data, and ethically users gave permission for this data to be used in any way when they ticked “I
agree” to the Terms of Service.
…
This attitude has moved with the new influx. Loudly proclaiming that content warnings are censorship, that functionality that has been deliberately unimplemented due to community
safety concerns are “missing” or “broken”, and that volunteer-run servers maintaining control over who they allow and under what conditions are “exclusionary”. No consideration is
given to why the norms and affordances of Mastodon and the broader fediverse exist, and whether the actor they are designed to protect against might be you.
I genuinely believe that the fediverse is among our best bets for making a break from the silos of the corporate Web, and to do that it has to scale – it’s only the speed at which it’s
being asked to do so that’s problematic.
Aside from what I’m already doing – trying to tutor (tootor?) new fediversians about how to integrate in an appropriate and respectful manner and doing a little to supporting the
expansion of the software that makes it tick… I wonder what more I could/should be doing.
Would my effort be best-spent be running a server (one not-just-for-me, I mean: abnib.social, anyone?), or should I use that time and money to support existing instances
directly? Should I brush up on my ActivityPub spec so I can be a more-useful developer, or am I better-placed to focus on tending my own digital garden first? Or maybe I’m looking at it
all wrong and I should be trying to dissuade people from piling-on to a system that might well not be right for them (nor they for it!)?
I don’t know the answers to these questions, but I’m hoping to work them out soon.
Addendum
It only occurred to me after the fact that I should mention that you can find me at @dan@danq.me.
Footnotes
1 Important: I’m no expert. I’ve been doing fediverse things for about 3 years but I’m
relatively quiet on Mastodon. Also, I’ve never really understood or gotten along with Twitter, so I’m even less an expert on that. Don’t assume that I’m
an authority on anything at all, and especially not social media.
My day usually starts in my feed reader, accessed via the FeedMe app from my mobile (although FreshRSS provides a reasonably good
responsive interface out-of-the-box!)
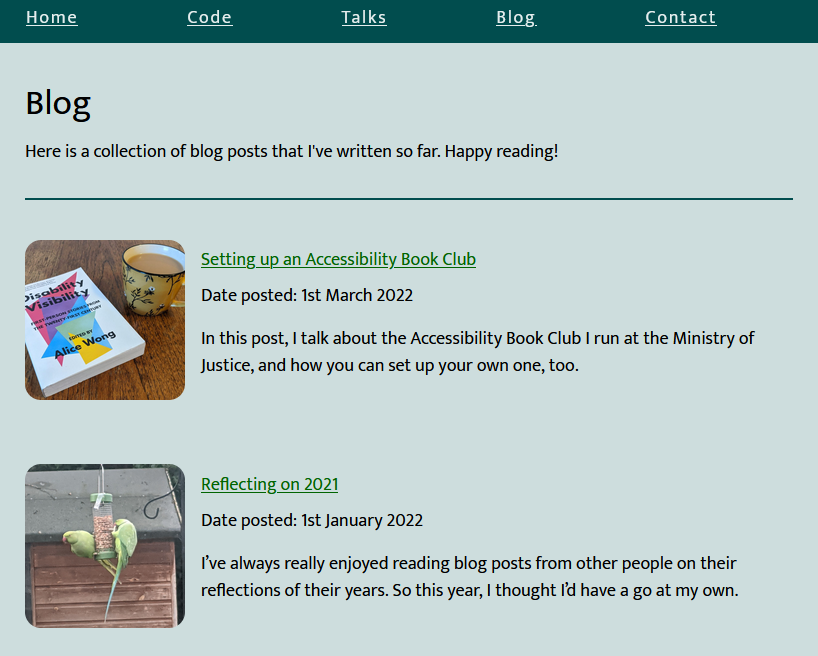
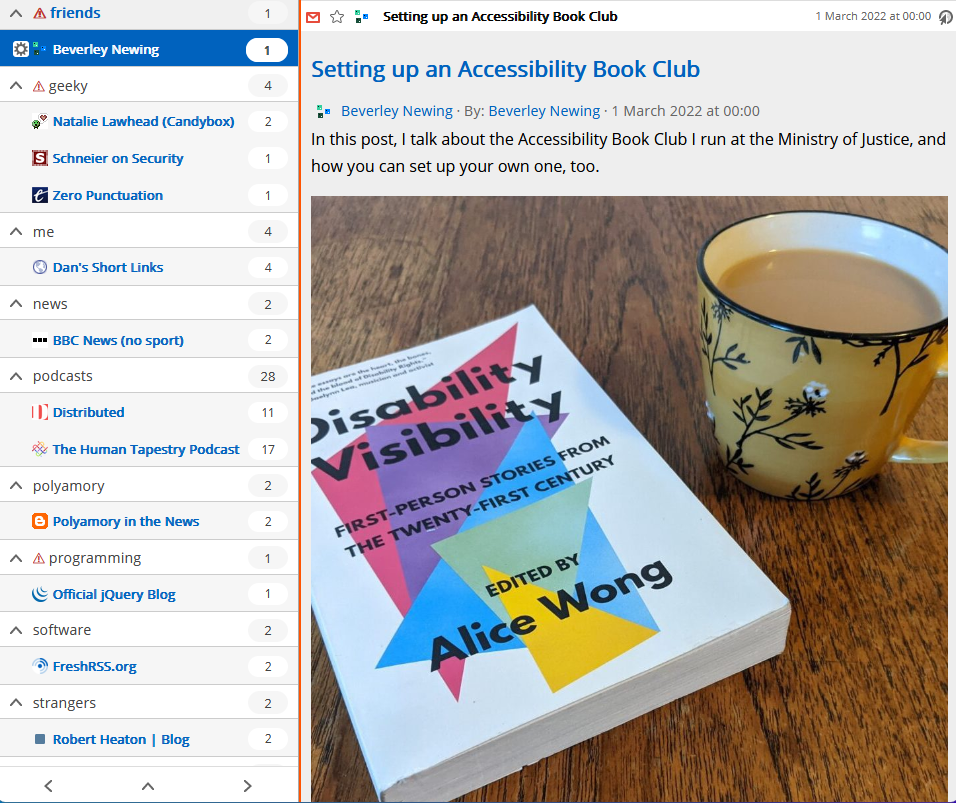
But with FreshRSS 1.20.0, I no longer have to maintain my own tool to get this brilliant functionality, and I’m overjoyed. Let’s look at how it works by re-subscribing to Beverley’s
blog but without a middleware tool.
This post is about to get pretty technical. If you don’t want to learn some XPath but just want to make a feed out of a web page, use a
graphical tool like FetchRSS.
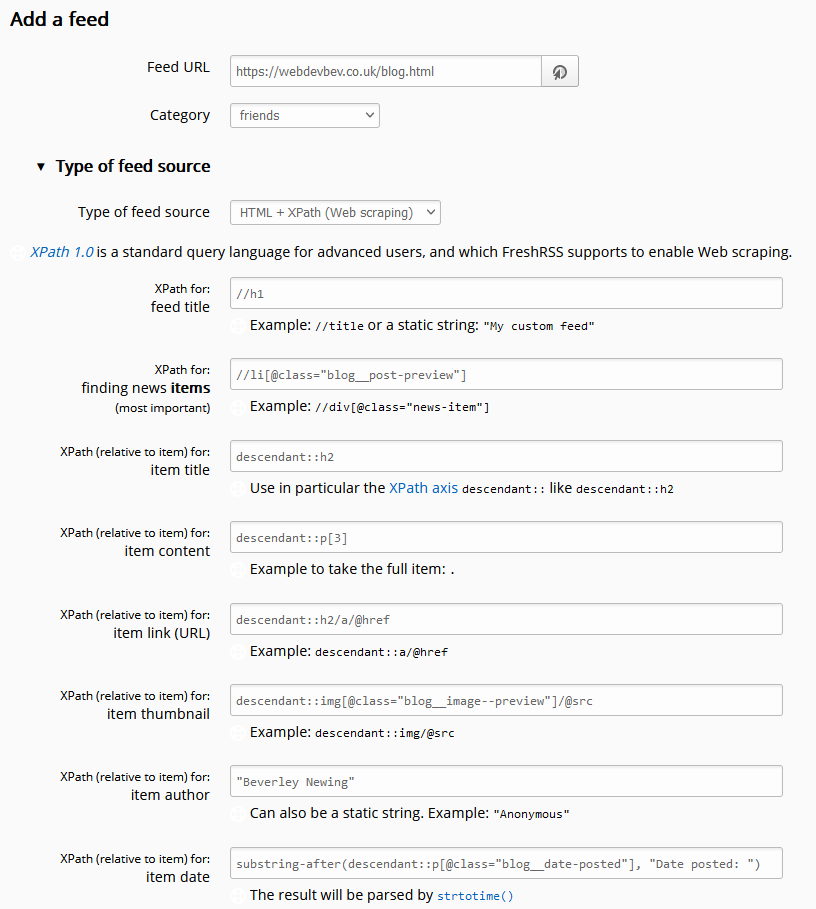
In the latest version of FreshRSS, when you add a new feed to your reader, a new section “Type of feed source” is available. Unfold it, and you can change from the default
(“RSS / Atom”) to the new option “HTML + XPath (Web scraping)”.
Put a human-readable page address rather than a feed address into the “Feed URL” field and fill these fields to tell FreshRSS
how to parse the page to get the content you want. Note that it doesn’t matter if the web page isn’t valid XML (e.g. missing
closing tags) because it’s going to get run through PHP’s
DOMDocument anyway which will “correct” for some really sloppy code if needed.
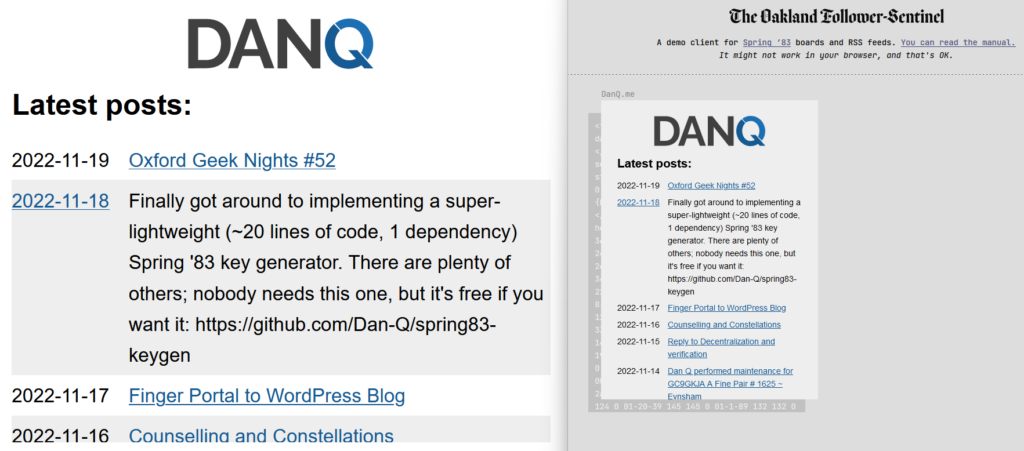
You can use your browser’s debugger to help check your XPath rules: here I’ve run document.evaluate('//li[@class="blog__post-preview"]', document).iterateNext() and
got back the first blog post on the page, so I know I’m on the right track.
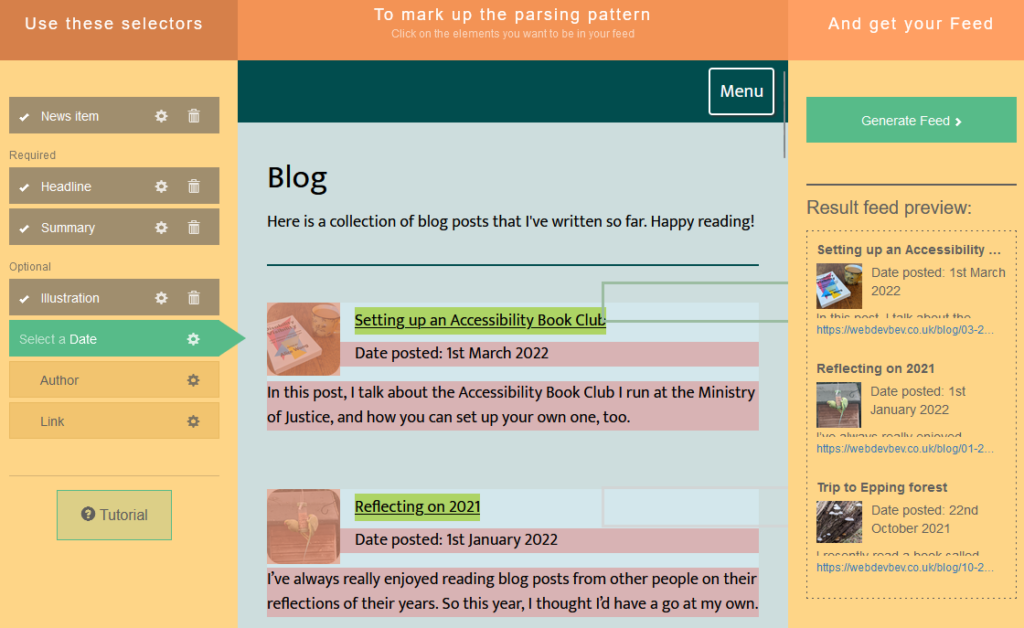
You’ll need to use XPath to express how to find a “feed item” on the page. Here’s the rules I used for https://webdevbev.co.uk/blog.html (many of these fields were optional – I didn’t have to do this much work):
Feed title://h1
I override this anyway in FreshRSS, so I could just have used the a string, but I wanted the XPath practice. There’s only one <h1> on the page, and it can be
considered the “title” of the feed.
Finding items://li[@class="blog__post-preview"]
Each “post” on the page is an <li class="blog__post-preview">.
Item titles:descendant::h2
Each post has a <h2> which is the post title. The descendant:: selector scopes the search to each post as found above.
Item content:descendant::p[3]
Beverley’s static site generator template puts the post summary in the third paragraph of the <li>, which we can select like this.
Item link:descendant::h2/a/@href
This expects a URL, so we need the /@href to make sure we get the value of the <h2><a
href="...">, rather than its contents.
Item thumbnail:descendant::img[@class="blog__image--preview"]/@src
Again, this expects a URL, which we get from the <img src="...">.
Item author:"Beverley Newing"
Beverley’s blog doesn’t host any guest posts, so I just use a string literal here.
Item date:substring-after(descendant::p[@class="blog__date-posted"], "Date posted: ")
This is the only complicated one: the published dates on Beverley’s blog aren’t explicitly marked-up, but part of a string that begins with the words “Date posted: “, so I use XPath’s
substring-after function to strtip this. The result gets passed to PHP’s
strtotime(), which is pretty tolerant of different date formats (although not of the words “Date posted:” it turns out!).
I’d love one day for FreshRSS to provide some kind of “preview” feature here so you can see what you’ll expect to get back, as you work. That, and support for different input types
(JSON, perhaps?), perhaps other selectors (I find CSS-style
selectors much simpler than XPath), and maybe even an option to execute Javascript on the page before scraping (I use this in my own toolchain, but that’s just because I want to have
my cake and eat it too). But this is still all pretty awesome.
I hope that this is just the beginning for this new killer feature in FreshRSS: there’s so much more it can be and do. But for now, I’m still mighty impressed that I can begin to
phase-out my use of my relatively resource-intensive feed-building middleware and use my feed reader to do more and more of the heavy lifting for which I love it so much.
I also love that this functionally adds h-feed support in by the back door. I’d still prefer there to be a “h-feed” option in the “Type of feed source” drop-down, but at least
I can add such support manually, now!
The finished result: Bev’s blog posts appear directly in my feed reader, even though they don’t have a feed, and now without going through the middleware I’d set up for that
purpose.
Footnotes
1 When I say RSS, I mean feed. Most of the feeds I subscribe to are RSS feeds, but some
are Atom feeds, h-feed, etc. But I can’t get over the old-fashioned name, and I don’t care to try.
That’s a really useful thing to have in this new age of the web, where Refererer: headers are no-longer commonly passed cross-domain and Google Search no longer provides the link: operator. If you want to know if I’ve ever
linked to your site, it’s a bit of a drag to find out.
To nobody’s surprise whatsoever, I’ve made a so many links to Wikipedia that I might be single-handedly responsible for their PageRank.
So, obviously, I’ve written an implementation for WordPress. It’s really basic right now, but the source code can be
found here if you want it. Install it as a plugin and run wp outbound-links to kick it off. It’s fast: it takes 3-5 seconds to parse the entirety of danq.me,
and I’ve got somewhere in the region of 5,000 posts to parse.
You can see the results at https://danq.me/.well-known/links – if you’ve ever wondered “has Dan ever linked to my site?”, now you can find the
answer.
If this could be useful to you, let’s collaborate on making this into an actually-useful plugin! Otherwise it’ll just languish “as-is”, which is good enough for my purposes.
As you might know if you were paying close attention in Summer 2019, I run a “URL
shortener” for my personal use. You may be familiar with public URL shorteners like TinyURL
and Bit.ly: my personal URL shortener is basically the same thing, except that only
I am able to make short-links with it. Compared to public ones, this means I’ve got a larger corpus of especially-short (e.g. 2/3 letter) codes available for my personal use. It also
means that I’m not dependent on the goodwill of a free siloed service and I can add exactly the features I want to it.
Little wonder then that my link shortener sat so close to me on my ecosystem diagram the other year.
For the last nine years my link shortener has been S.2, a tool I threw together in Ruby. It stores URLs in a
sequentially-numbered database table and then uses the Base62-encoding of the primary key as the “code” part of the short URL. Aside from the fact that when I create a short link it shows me a QR code to I can
easily “push” a page to my phone, it doesn’t really have any “special” features. It replaced S.1, from which it primarily differed by putting the code at the end of the URL rather than as part of the domain name, e.g. s.danq.me/a0 rather than a0.s.danq.me: I made the switch
because S.1 made HTTPS a real pain as well as only supporting Base36 (owing to the case-insensitivity of domain names).
But S.2’s gotten a little long in the tooth and as I’ve gotten busier/lazier, I’ve leant into using or adapting open source tools more-often than writing my own from scratch. So this
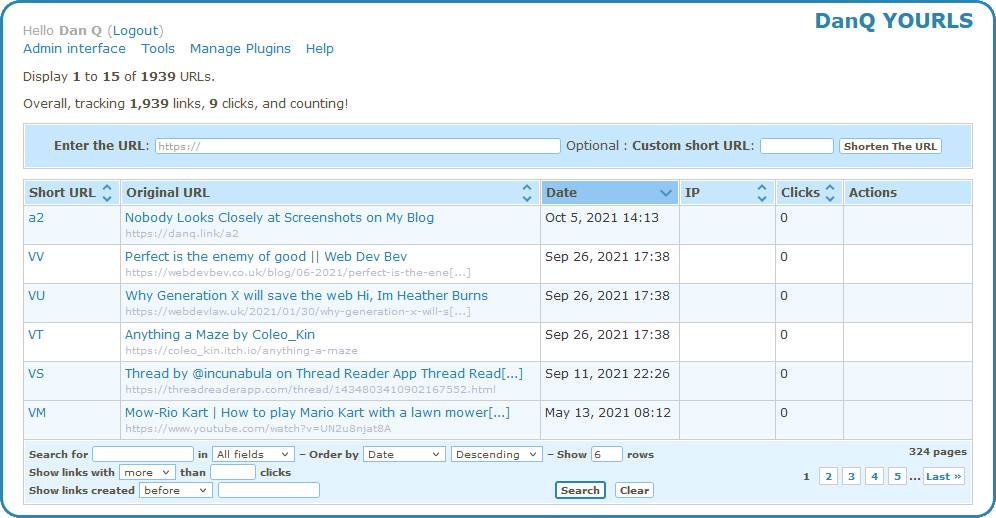
week I switched my URL shortener from S.2 to YOURLS.
YOURLs isn’t the prettiest tool in the world, but then it doesn’t have to be: only I ever see the interface pictured above!
One of the things that attracted to me to YOURLS was that it had a ready-to-go Docker image. I’m not the biggest fan of Docker in general,
but I do love the convenience of being able to deploy applications super-quickly to my household NAS. This makes installing and maintaining my personal URL shortener much easier than it
used to be (and it was pretty easy before!).
Another thing I liked about YOURLS is that it, like S.2, uses Base62 encoding. This meant that migrating my links from S.2 into YOURLS could be done with a simple cross-database
INSERT... SELECT statement:
One of S.1/S.2’s features was that it exposed an RSS feed at a secret URL for my reader to ingest. This was great, because it meant I could “push” something to my RSS reader to read or repost to my blog later. YOURLS doesn’t have such a feature, and I couldn’t find anything in the (extensive) list of plugins that would do it for me. I needed to write my own.
In some ways, subscribing “to yourself” is a strange thing to do. In other ways… shut up, I’ll do what I like.
I could have written a YOURLS plugin. Or I could have written a stack of code in Ruby, PHP, Javascript or
some other language to bridge these systems. But as I switched over my shortlink subdomain s.danq.me to its new home at danq.link, another idea came to me. I
have direct database access to YOURLS (and the table schema is super simple) and the command-line MariaDB client can output XML… could I simply write an XML
Transformation to convert database output directly into a valid RSS feed? Let’s give it a go!
I wrote a script like this and put it in my crontab:
mysql --xml yourls -e \"SELECT keyword, url, title, DATE_FORMAT(timestamp, '%a, %d %b %Y %T') AS pubdate FROM yourls_url ORDER BY timestamp DESC LIMIT 30"\
| xsltproc template.xslt - \
| xmllint --format - \
> output.rss.xml
The first part of that command connects to the yourls database, sets the output format to XML, and executes an
SQL statement to extract the most-recent 30 shortlinks. The DATE_FORMAT function is used to mould the datetime into
something approximating the RFC-822 standard for datetimes as required by
RSS. The output produced looks something like this:
<?xml version="1.0"?><resultsetstatement="SELECT keyword, url, title, timestamp FROM yourls_url ORDER BY timestamp DESC LIMIT 30"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"><row><fieldname="keyword">VV</field><fieldname="url">https://webdevbev.co.uk/blog/06-2021/perfect-is-the-enemy-of-good.html</field><fieldname="title"> Perfect is the enemy of good || Web Dev Bev</field><fieldname="timestamp">2021-09-26 17:38:32</field></row><row><fieldname="keyword">VU</field><fieldname="url">https://webdevlaw.uk/2021/01/30/why-generation-x-will-save-the-web/</field><fieldname="title">Why Generation X will save the web Hi, Im Heather Burns</field><fieldname="timestamp">2021-09-26 17:38:26</field></row><!-- ... etc. ... --></resultset>
We don’t see this, though. It’s piped directly into the second part of the command, which uses xsltproc to apply an XSLT to it. I was concerned that my XSLT
experience would be super rusty as I haven’t actually written any since working for my former employer SmartData back in around 2005! Back then, my coworker Alex and I spent many hours doing XML
backflips to implement a system that converted complex data outputs into PDF files via an XSL-FO intermediary.
I needn’t have worried, though. Firstly: it turns out I remember a lot more than I thought from that project a decade and a half ago! But secondly, this conversion from MySQL/MariaDB
XML output to RSS turned out to be pretty painless. Here’s the
template.xslt I ended up making:
<?xml version="1.0"?><xsl:stylesheetxmlns:xsl="http://www.w3.org/1999/XSL/Transform"version="1.0"><xsl:templatematch="resultset"><rssversion="2.0"xmlns:atom="http://www.w3.org/2005/Atom"><channel><title>Dan's Short Links</title><description>Links shortened by Dan using danq.link</description><link> [ MY RSS FEED URL ]</link><atom:linkhref=" [ MY RSS FEED URL ] "rel="self"type="application/rss+xml"/><lastBuildDate><xsl:value-ofselect="row/field[@name='pubdate']"/> UTC</lastBuildDate><pubDate><xsl:value-ofselect="row/field[@name='pubdate']"/> UTC</pubDate><ttl>1800</ttl><xsl:for-eachselect="row"><item><title><xsl:value-ofselect="field[@name='title']"/></title><link><xsl:value-ofselect="field[@name='url']"/></link><guid>https://danq.link/<xsl:value-ofselect="field[@name='keyword']"/></guid><pubDate><xsl:value-ofselect="field[@name='pubdate']"/> UTC</pubDate></item></xsl:for-each></channel></rss></xsl:template></xsl:stylesheet>
That uses the first (i.e. most-recent) shortlink’s timestamp as the feed’s pubDate, which makes sense: unless you’re going back and modifying links there’s no more-recent
changes than the creation date of the most-recent shortlink. Then it loops through the returned rows and creates an <item> for each; simple!
The final step in my command runs the output through xmllint to prettify it. That’s not strictly necessary, but it was useful while debugging and as the whole command takes
milliseconds to run once every quarter hour or so I’m not concerned about the overhead. Using these native binaries (plus a little configuration), chained together with pipes, had
already resulted in way faster performance (with less code) than if I’d implemented something using a scripting language, and the result is a reasonably elegant “scratch your
own itch”-type solution to the only outstanding barrier that was keeping me on S.2.
All that remained for me to do was set up a symlink so that the resulting output.rss.xml was accessible, over the web, to my RSS reader. I hope that next time I’m tempted to write a script to solve a problem like this I’ll remember that sometimes a chain of piped *nix
utilities can provide me a slicker, cleaner, and faster solution.
Update: Right as I finished writing this blog post I discovered that somebody had already solved this
problem using PHP code added to YOURLS; it’s just not packaged as a plugin so I didn’t see it earlier! Whether or not I
use this alternate approach or stick to what I’ve got, the process of implementing this YOURLS-database ➡ XML
➡ XSLT ➡ RSS chain was fun and
informative.
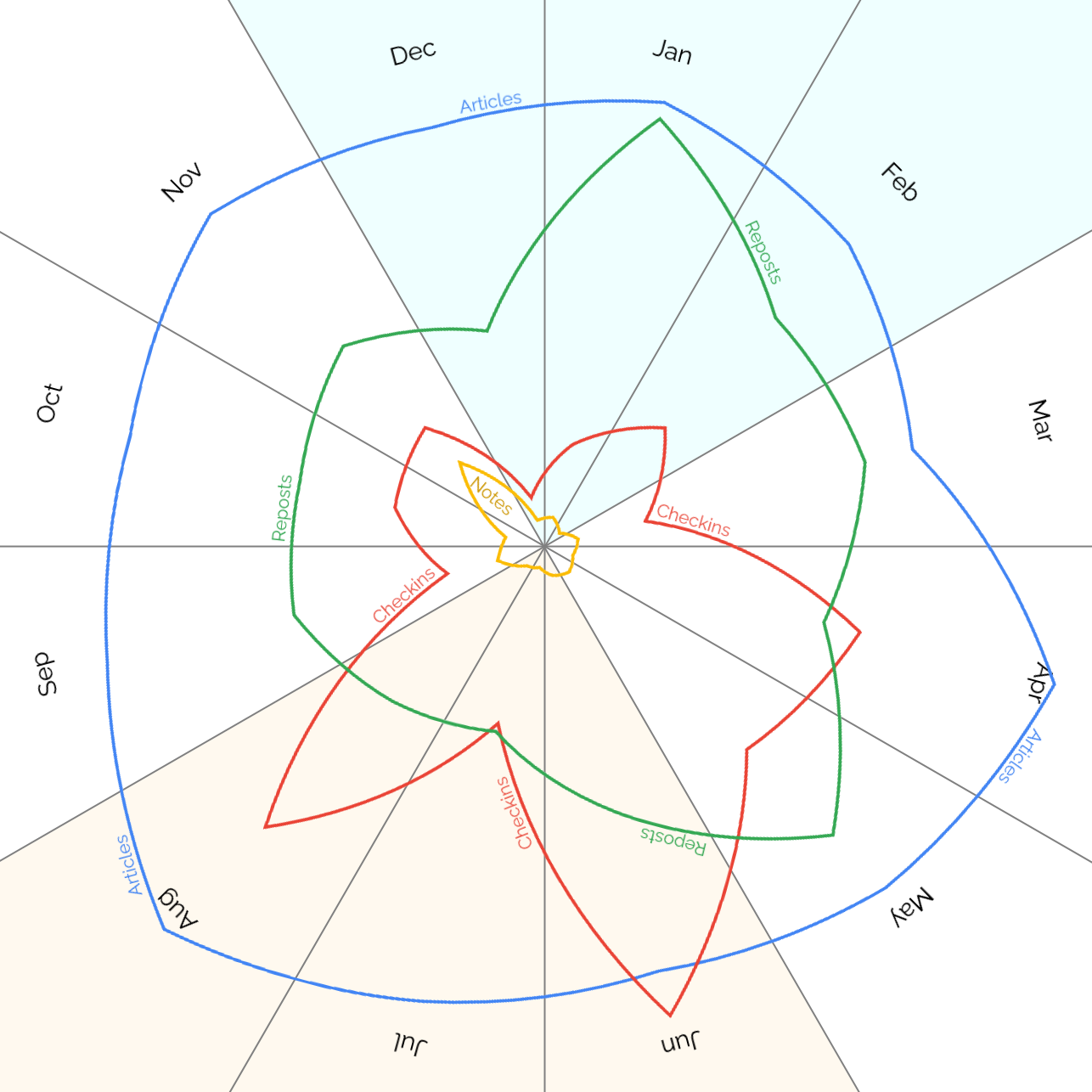
Unsurprisingly my checkins, which represent #geocaching/#geohashing activity,
grow in the spring and peak in the summer when the weather’s better!
At first I assumed the notes peak in November might have been thrown off by a single conference, e.g. musetech, but it turns out I’ve
just done more note-friendly things in Novembers, like Challenge Robin II and my Cape Town
meetup, which are enough to throw the numbers off.
My Facebook account was permanently banned on Wednesday along with all the people who take care of the Cork Skeptics page.
We’re still not sure why but it might have something to do with the Facebook algorithm used to detect far-right conspiracy groups.
…
If you have a Facebook account you should download your information too because it could happen to you too, even though you did nothing wrong. Go here and click the “Create File” button now.
Yeah, I know you won’t do it but you really should.
…
Great advice.
After I got banned from Facebook in 2011 (for using a “fake name”, which is actually my real name) I took a similar line of thinking: I
can’t trust Facebook (or Twitter, or Instagram, or whoever else) to be responsible custodians of my content, so I shan’t. Now, virtually all content I create is hosted
on my WordPress-powered blog, at my own domain, first and foremost… and syndicated copies may appear on various social media.
In a very few instances I go the other way around, producing content in silos and then copying it back to my blog: e.g. my geocaching/geohashing expeditions are posted first to their
respective sites (because it’s easiest and most-practical to do that using their apps, especially “in the field”), but then they get imported into my blog using a custom plugin. If any of these sites closes, deletes my data, adds paid tiers I’m not happy with, or just bans me from my
own account… I’m still set.
Backing up all your social content is a good strategy. Owning it all to begin with is an even better one, IMHO. See also: Indieweb.





![Browser debugger running document.evaluate('//li[@class="blog__post-preview"]', document).iterateNext() on Beverley's weblog and getting the first blog entry.](https://bcdn.danq.me/_q23u/2022/09/debugger-select-from-xpath-1024x256.png)


 Levelled up my blood donation game!
Levelled up my blood donation game!


{kind=link}