For instance, at the start of the weekend I received an email from somebody called Phil, who asked:
Could you possibly have an alternative ‘HQ’ version of your feeds which replaces standard/240 with standard/1200 in the URL for each article in the XML?
I am obviously pretty desperate for this feature, hence me reaching out.
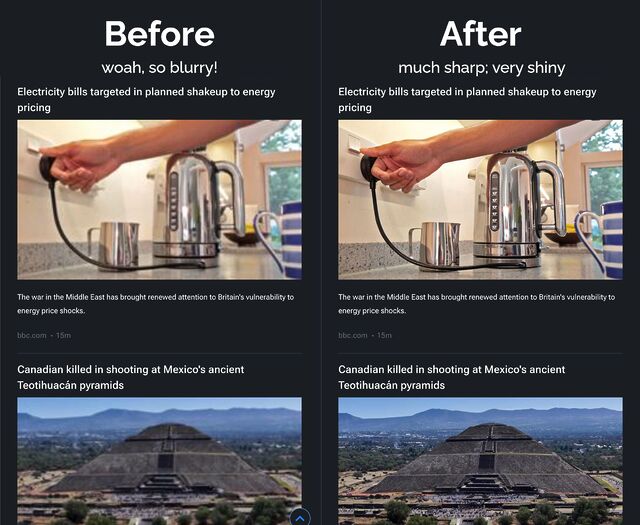
Phil’s right. The BBC News RSS feeds contain thumbnail images that look like this:
You see the /240/ in that URL? If you change it to /1200/ then, as Phil observes, you get a much-higher resolution thumbnail. Naturally you ought
to correct the width and height attributes accordingly, too.
The difference is pretty significant. See:
You’d be forgiven for thinking the left-hand-side of this image was the Lego model of this car.
So I raised Phil’s request as a GitHub issue, like a good maintainer, before realising that – hang on – this would be
a really easy improvement and I should just… do it.
My BBC feeds “improver” leverages one of my very favourite RubyGems, Nokogiri, to perform XML parsing and modification. The code you need to tweak
these URLs is super simple:
# Iterate through each <media:thumbnail> element in the RSS feed:
rss.xpath('//media:thumbnail').eachdo|thumb|# Skip any that don't start the way we expect:nextunlessthumb['url']=~/^https:\/\/ichef.bbci.co.uk\/ace\/(standard|ws)\/240\//# Swap the 240 for 1200 in the url="..." attribute:thumb['url']=thumb['url'].gsub(/\/ace\/(standard|ws)\/240\//,"/ace/\\1/1200/")
# Set width="1200":thumb['width']="1200"# Set the height="..." proportionally (they're not always the same!):thumb['height']=(thumb['height'].to_f/240*1200).round.to_s
end
That really is all there is to it, but look at what a difference it makes in an RSS reader:
I got that merged and the GitHub action that makes the magic happen got started on its usual 20-minute schedule soon afterwards. I didn’t even have to finish waiting for my lunchtime
ramen to cool down before the change was out there and, hopefully, helping people. Phil emailed me again soon afterwards:
You managed to fix something in your lunch break that has been bugging me for well over a decade. The difference in quality is night and day.
Anyway: it pleased me to discover that my software is out there, helping people.
As with most of my open source work, I put little to no effort into tracking any kind of metrics of usage, which means I only get to find out if I’ve done good in the world when people
reach out and tell me. So I was delighted to hear from Phil (as well as to take his suggestion and improve the tool for everybody!).
Footnotes
1 Specifically, the code I’ve written makes a few improvements to the BBC News RSS feeds:
(1) removing duplicate news, (2) removing non-news content such as “nudges” towards the app or to iPlayer content, and (3) optionally removing sports news. If that sounds
like a better version of the BBC News RSS feeds, you should take a look!
Most of the traffic I get on this site is bots – it isn’t even close. And, for whatever reason, almost all of the bots are using HTTP1.1 while virtually all human traffic is using
later protocols.
I have decided to block v1.1 traffic on an experimental basis. This is a heavy-handed measure and I will probably modify my approach as I see the results.
…
# Return an error for clients using http1.1 or below - these are assumed to be bots@http-too-old{notprotocolhttp/2+notpath/rss.xml/atom.xml# allow feeds}respond@http-too-old400{body"Due to stupid bots I have disabled http1.1. Use more modern software to access this site"close}
This is quick, dirty, and will certainly need tweaking but I think it is a good enough start to see what effects it will have on my traffic.
…
A really interesting experiment by Andrew Stephens! And love that he shared the relevant parts of his Caddyfile: nice to see how elegantly this can be achieved.
I decided to probe his server with cURL:
~ curl --http0.9 -sI https://sheep.horse/ | head -n1
HTTP/2 200
~ curl --http1.0 -sI https://sheep.horse/ | head -n1
HTTP/1.0 400 Bad Request
~ curl --http1.1 -sI https://sheep.horse/ | head -n1
HTTP/1.1 400 Bad Request
~ curl --http2 -sI https://sheep.horse/ | head -n1
HTTP/2 200
Curiously, while his configuration blocks both HTTP/1.1 and HTTP/1.0, it doesn’t seem to block HTTP/0.9! Whaaa?
It took me a while to work out why this was. It turns out that cURL won’t do HTTP/0.9 over https:// connections. Interesting! Though it presumably wouldn’t have worked
anyway – HTTP/1.1 requires (and HTTP/1.0 permits) the Host: header, but HTTP/0.9 doesn’t IIRC, and sheep.horse definitely does require the Host: header (I tested!).
I also tested that my RSS reader FreshRSS was still able to fetch his content. I have it configured to pull not only the RSS feed, which is specifically allowed to bypass his
restriction, but – because his feed contains only summary content – I also have it fetch the linked page too in order to get the full content. It looks like FreshRSS is using HTTP/2 or
higher, because the content fetcher still behaves properly.
Andrew’s approach definitely excludes Lynx, which is a bit annoying and would make this idea a non-starter for any of my own websites. But it’s still an interesting experiment.
So it was inevitable that Apple would add video support to their podcasting apps. And it makes sense for Apple to update the technical underpinnings; the assumptions that were made
when designing podcasts over two decades ago aren’t really appropriate for many contemporary uses. For example, back then, by default an entire podcast episode would be downloaded
to your iPod for convenient listening on the go, just like songs in your music library. But downloading a giant 4K video clip of an hour-long podcast show that you might not even
watch, just in case you might want to see it, would be a huge waste of resources and bandwidth. Modern users are used to streaming everything. Thus, Apple updated their apps to
support just grabbing snippets of video as they’re needed, and to their credit, Apple is embracing an open video format when doing so, instead of some proprietary system that
requires podcasters to pay a fee or get permission.
The problem, though, is that Apple is only allowing these new video streams to be served by a small number of pre-approved
commercial providers that they’ve hand-selected. In the podcasting world, there are no gatekeepers; if I want to start a podcast today, I can publish a podcast feed here on
anildash.com and put up some MP3s with my episodes, and anyone anywhere in the world can subscribe to that podcast, I don’t have to ask anyone’s permission, tell anyone
about it, or agree to anyone’s terms of service.
…
When I started my pointless podcast, I didn’t need anybody else’s infrastructure or permission. Podcasts are, in the vein of the Web itself (and thanks at
least in part to my former coworker Dave Winer), distributed and democratised.
All you need to host a podcast is an RSS file and some audio files. You can put them onto your shared VM. You can put them onto your homelab, You can put them onto a
GitHub Pages site. You can put them onto a Neocities site. Or you can shell out for a commercial host and distribute your content across a global network of CDNs, for maximum
performance! All of these are podcasts, and they’re all equal from a technical perspective.1
Video podcasts could be the same. Even if – as Apple suggest – HLS is to be mandatory for their player2,
that doesn’t necessitate a big corporate third-party provider. Having an “allowlist” of people who can host your podcast’s video is gatekeeping.
Also, it’s… not really podcasting any more. It’s been pointed out that before “platform-exclusive” podcasts (I’m looking at you, Spotify) are not truly podcasts: if it’s not an RSS feed
plus some audio files, it’s not a podcast, it’s lightly sparkling audio.
Can the same analogy be used for a podcast player? Is a player that only supports content (in this case, video content) if it’s hosted by a particular partner…
not-a-podcast-player? Either way, it’s pretty embarrassing for Apple of all people to turn their back on what makes a podcast a podcast.
Footnotes
1 Technically, my podcast is just a collection of posts that share a ClassicPress “tag”;
ClassicPress gives me “RSS feed of a particular tag” for free, so all I needed to do was (a) add metadata to point to my MP3 files (b) and use a hook to inject the relevant
<enclosure> element into the feed. There are almost certainly plugins that could have done it for me, but it’s a simple task so I just wrote a few lines of PHP code
and called it a day!
2 This is… fine, I guess. I’d rather that an <enclosure> be
more-agnostic. If I only want to provide a single fat MP4 file, then it’s up to my listeners to say “this is shit, why can’t I stream this on my cellular data, I’m gonna listen/watch
somebody else instead”. But even if HLS is required, that’s not difficult: I talked about how to do it last year while
demonstrating variable-aspect-ratio videos (in vanilla HTML)!
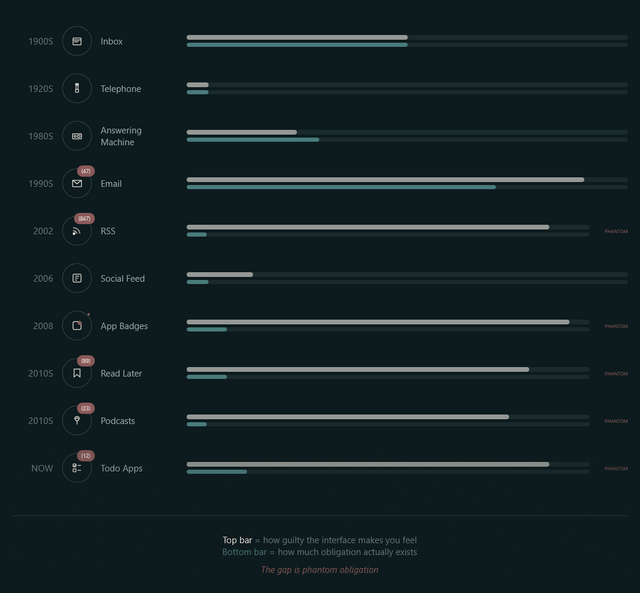
He observes that the design of feed readers – which still lean on the design of the earliest feed readers, which adopted the design of email software to minimise the learning
curve – makes us feel obligated to stay on top of all our incoming content with its “unread counts”.
Phantom obligation
Email’s unread count means something specific: these are messages from real people who wrote to you and are, in some cases, actively waiting for your response. The number isn’t
neutral information. It’s a measure of social debt.
But when we applied that same visual language to RSS (the unread counts, the bold text for new items, the sense of a backlog accumulating) we imported the anxiety without the cause.
…
RSS isn’t people writing to you. It’s people writing, period. You opted to be notified of their existence. The interface implied debt where none existed. The
obligation became phantom.
I use FreshRSS as my feed reader, and I love it. But here’s the thing: I use the same application
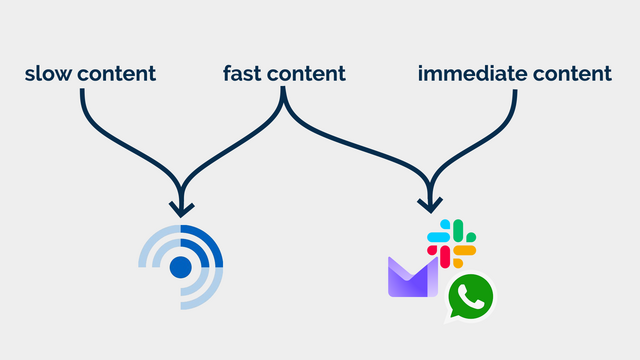
for two different kinds of feeds. I call them slow content and fast content.2
It’s an idealised interpretation of how I subscribe to different kinds of incoming messages, but it works for me. The lesson is that slowing down your consumption is not
an antifeature, it’s a deliberate choice about how you prioritise your life. For me: humans come first – what about you?
Slow content
Blogs, news, podcasts, webcomics, vlogs, etc. I want to know that there is unread content, but I don’t need to know howmuch.
In some cases, I configure my reader to throw away stuff that’s gotten old and stale; in other cases, I want it to retain it indefinitely so that I can dip in when I want to.
There are some categories in which I’ll achieve “inbox zero” most days3…
but many more categories where the purpose of my feed reader is to gather and retain a library of things I’m likely to be interested in, so that I can enjoy them at my leisure.
Some of the things I subscribe to, though, I do want to know about. Not necessarily immediately, but “same day” for sure! This includes things like when it’s a friend’s
birthday (via the Abnib Birthdays feed) or when there’s an important update to some software I selfhost.
This is… things I want to know about promptly, but that I don’t want to be interrupted for! I appreciate that this kind of subscription isn’t an ideal use for a feed reader… but I use
my feed reader with an appropriate frequency that it’s the best way for me to put these notifications in front of my eyeballs.
I agree with Terry that unread counts and notification badges are generally a UX antipattern in feed readers… but I’d like to keep them for some purposes.
So that’s exactly what I do.
How I use FreshRSS (to differentiate slow and fast content)
FreshRSS already provides categories. But what I do is simply… not show unread counts except for designated feeds and categories. To do that, I use the CustomCSS extension for FreshRSS (which nowadays comes as-standard!), giving it the following code
(note that I want to retain unread count badges only for feed #1 and categories #6 and #8 and their feeds):
.aside.aside_feed{
/* Hide all 'unread counts' */.category,.feed{
.title:not([data-unread="0"])::after,.item-title:not([data-unread="0"])::after{
display:none;}
}
/* Re-show unread counts only within: * - certain numbered feeds (#f_*) and * - categories (#c_*) */#f_1,#c_6,#c_8{
&,.feed{
.title:not([data-unread="0"])::after,.item-title:not([data-unread="0"])::after{
display:block;}
}
}
That’s how I, personally, make my feed reader feel less like an inbox and more like a… I don’t know… a little like a library, a little like a newsstand, a little like a calendar… and a
lot like a tool that serves me, instead of another oppressive “unread” count.
I just wish I could persuade my mobile reader Capyreader to follow suit.
Maybe it’ll help you too.
Footnotes
1 Or whenever you like. It’s ‘slow content’. I’m not the boss of you.
2 A third category, immediate content, is stuff where I might need to
take action as soon as I see it, usually because there’s another human involved – things like this come to me by email, Slack, WhatsApp, or similar. It doesn’t belong in a feed
reader.
3 It’s still slow content even if I inbox-zero it most days…
because I don’t inbox-zero it every day! I don’t feel bad ignoring or skipping it if I’m, for example, not feeling the politics news right now (and can you blame me?). This
is fundamentally different than ignoring an incoming phone call or a knock at the door (although you’re absolutely within your rights to do that too, if you don’t have the spoons for
it).
4 I’m yet to see a mailing list that wouldn’t be better as either a blog (for few-to-many
communication) or a forum (for many-to-many communication), frankly. But some people are very wedded to their email accounts as “the way” to communicate!
Off the back of my project to un-suckify BBC News’ RSS feeds (https://bbc-feeds.danq.dev) by removing non-news content and duplicate items, I
received an email this week (addressing me by the wrong name, I might add) from somebody who asked if I could do the same… for the Daily Mail.
I’m so very tempted to provide an empty RSS feed and say “there you go; that’s an RSS feed of the Daily Mail but with the crap bits removed”.
Turns out my distaste for the Daily Mail is greater than my love of clean RSS.
RSS readers rock. Having a single place you connect for a low-bandwidth bundle of everything you might want to read means it doesn’t matter how slow the WiFi is on your aeroplane, you
can get all the text content in one tap.
(I’m using Capy Reader to connect to FreshRSS, by the way.)
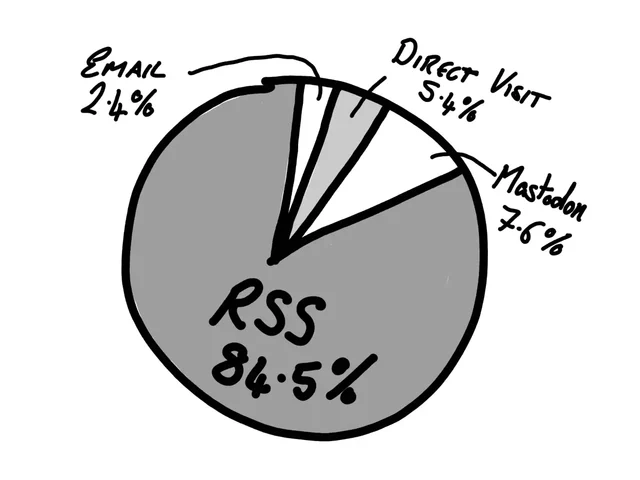
Well, quite a lot, actually. It tells me that there’s loads of you fine people reading the content on this site, which is very heart-warming. It also tells me that RSS is
by far the main way people consume my content. Which is also fantastic, as I think RSS is very
important and should always be a first class citizen when it comes to delivering content to people.
…
I didn’t get a chance to participate in Kev’s survey because, well, I don’t target
“RSS Zero” and I don’t always catch up on new articles – even by authors I follow closely – until up to a few weeks after they’re published1.
But needless to say, I’d have been in the majority: I follow Kev via my feed reader2.
But I was really interested by this approach to understanding your readership: like Kev, I don’t run any kind of analytics on my personal sites. But he’s onto something! If you
want to learn about people, why not just ask them?
Okay, there’s going to be a bias: maybe readers who subscribe by RSS are simply more-likely to respond to a survey? Or are more-likely to visit new articles quickly, which
was definitely a factor in this short-lived survey? It’s hard to be certain whether these or other factors might have thrown-off Kev’s results.
But then… what isn’t biased? Were Kev running, say, Google Analytics (or Fathom, or Strike, or Hector, or whatever)… then I wouldn’t show up in his results
because I block those trackers3
– another, different, kind of bias.
We can’t dodge such bias: not using popular analytics platforms, and not by surveying users. But one of these two options is, at least, respectful of your users’ privacy and bandwidth.
I’m tempted to run a similar survey myself. I might wait until after my long-overdue redesign – teased here – launches,
though. Although perhaps that’s just a procrastination stemming from my insecurity that I’ll hear, like, an embarrassingly-low number of responses like three or four and internalise it
as failing some kind of popularity contest4! Needs more thought.
Footnotes
1 I’m happy with this approach: I enjoy being able to treat my RSS reader as sort-of a
“magazine”, using my categorisations of feeds – which are partially expressed on my Blogroll page – as a theme. Like: “I’m going to spend 20 minutes
reading… tech blogs… or personal blogs by people I know personally… or indieweb-centric content… or news (without the sports, of course)…”
This approach makes consuming content online feel especially deliberate and intentional: very much like being in control of what I read and when.
3 In fact, I block all third-party JavaScript (and some first-party
JavaScript!) except where explicitly permitted, but even for sites that I do allow to load all such JavaScript I still have to manually enable analytics
trackers if I want them, which I don’t. Also… I sandbox almost all cookies, and I treat virtually all persistent cookies as session cookies and I
delete virtually all session cookies 15 seconds after I navigate away from a its sandbox domain or close its tab… so I’m moderately well-anonymised even where I do somehow
receive a tracking cookie.
4 Perhaps something to consider after things have gotten easier and I’ve caught up with my backlog a bit.
For the last few years I’ve been running a proxy of the BBC News RSS feeds (https://bbc-feeds.danq.dev) that strips out duplicate content,
non-news content, and (optionally) sports news.
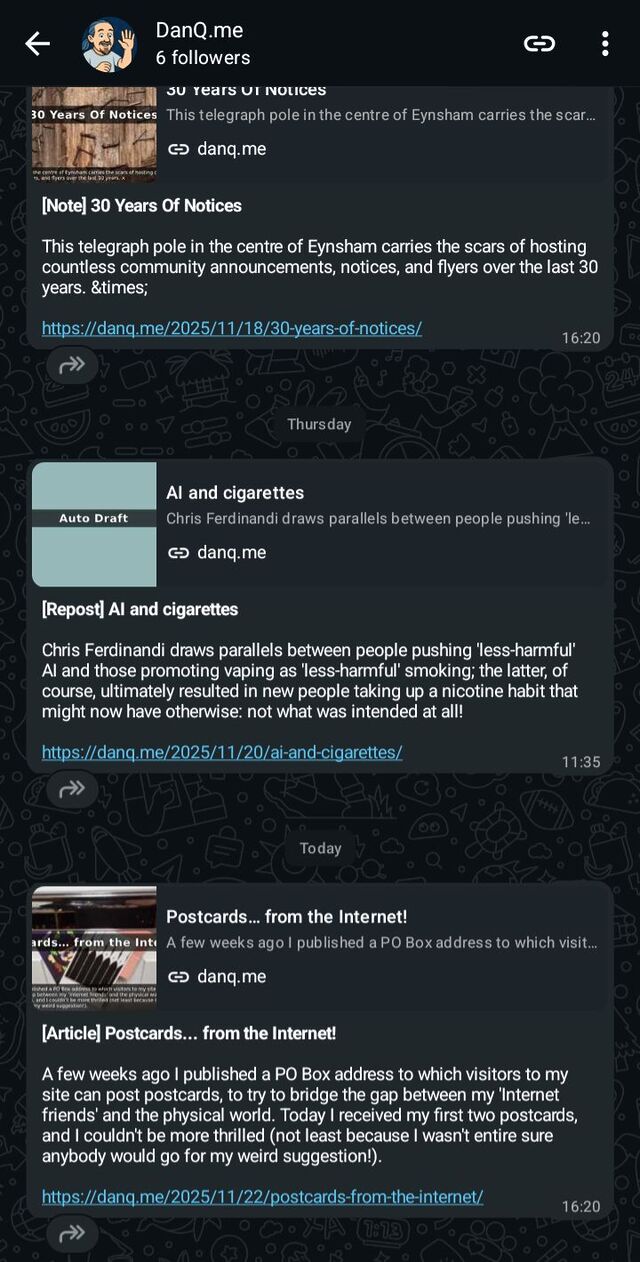
But I’m pretty sure there are some people who’d rather receive updates to my blog via WhatsApp. And
now, they can. Here’s how I set up an RSS-to-WhatsApp gateway, in case you want to run one of your own2.
A Whapi account connected to your WhatsApp account3
– when you set up an account you’ll get a free trial; when it ends you need to find the link to say that you want to carry on with the free tier (or upgrade to the paid tier if you
expect to send more messages than the free tier’s limit)
A WhatsApp channel to which you want to push your RSS feed: I’d recommend that you make a newsletter (from the Updates tab in WhatsApp, press the kekab menu then
Create Channel) rather than a traditional group: groups are designed for multiple people to talk and discuss and everybody can see one another’s identity, but a newsletter
keeps everybody’s identity private and only allows the administrator(s) permission to post updates.
You probably want to use the kind of channel that’s for one-to-many ‘push’ communication, not a discussion group.
In Settings > Secrets and Variables > Actions, add two new Repository Secrets:
WHATSAPP_API_TOKEN: set to the token on your Whapi dashboard
WHATSAPP_CHANNEL: set to your newsletter ID (will look like 123456789012345678@newsletter) or group ID (will look
like 123456789012345678@g.us): you can get this from the Newsletters or Groups section of Whapi by executing a test GET /newsletters or GET /groups request4.
Do a test run: from the Actions tab select the “Process feeds” action and click “Run workflow”. If it finishes successfully (and you get the WhatsApp message), you’re done! If it
fails, click on the failed action and drill-in to the failed task to see the error message and correct accordingly.
By default, the processor will run on-demand and every 30 minutes, but you can modify that in.github/workflows/process-feeds.yml. It’s configured to send the single oldest
un-sent item in any of the RSS feeds it’s subscribed to, on each run (it tracks which ones it’s sent already by their guids, in a "seen": [...] array in
feeds.json): sending a single link per run ensures that WhatsApp’s link previews work as expected. At that rate, you could theoretically run it once every 10 minutes and
never hit the 150-messages-per-day limit of Whapi’s free tier5), but you’ll want to work out your own optimal rate based on the
anticipated update frequency of your feeds and the number of RSS-to-WhatsApp channels you’re running.
You can, of course, run it on your own infrastructure in a similar way. Just check out the repository to your local system with Ruby 3.2+ running, run bundle to install the
dependencies, then set up a cron job or some other automation to run ./process_feeds.rb. Doing this could be used to hook it up to your RSS feed updating pipeline, for
example, to check for new feed items right after a new post is published.
Footnotes
1 Their own incomprehensible, illogical, weird reasons.
2 I hope that the title gives it away, but you can do this completely for free.
So long as you keep your fork of the GitHub repository open-source then you can run GitHub Actions for free, and so long as you’re pushing out no more than 150 updates per day to no
more than 5 different channels in a month then you can do it within Whapi’s free tier: that’s probably fine for a personal blogger, and there’s a reasonable pricing structure (plus
some value-added extras) for companies that want to use this same workflow as part of a grander WhatsApp offering.
3 Setting this up requires giving Whapi access to your WhatsApp account. If you don’t like
the security implications of that, you could get a cheap eSIM, set that up with WhatsApp, and use that account: if you do this, just remember to “warm up” your new WhatsApp
account with some conversations with yourself so it doesn’t look so much like a spammer! Also note that the way Whapi works “uses up” one of the ~4 devices on which you can
simultaneously use WhatsApp Web/WhatsApp Desktop etc.
4 Prefer the command-line? So long as you’ve got curl and jq
then you can get a list of your newsletters (or groups) and their IDs with curl -H 'Authorization: Bearer YOUR_API_TOKEN' -H 'accept: application/json'
https://gate.whapi.cloud/newsletters?count=100 | jq '.newsletters[] | { id: .id, name: .name }' or curl -H 'Authorization: Bearer YOUR_API_TOKEN' -H 'accept:
application/json' https://gate.whapi.cloud/groups?count=100 | jq '.groups[] | { id: .id, name: .name }', respectively.
5 Going beyond the free tier would require sending one message, on average, every 9
minutes and 36 seconds.
This has been doing the rounds; I last saw it on Kev’s blog. I like that the social blogosphere’s doing this kind
of fun activity again, these days1.
1. Do you floss your teeth?
Umm… sometimes? Not as often as I should. Don’t tell my dentist!
Usually at least once a month, never more than once a week. I really took to heart some advice that if you’re using a fluoridated mouthwash then you shouldn’t do it close to when you
brush your teeth (or you counteract the benefits), so my routine is that… when I remember and can be bothered to floss… I’ll floss and mouthwash, but like in the middle of the day.
And since I moved my bedroom (and bathroom) one floor further up our house, it’s harder to find the motivation to do so! So I’m probably flossing less. The unanticipated knock-on effect
of extending your house!
2. Tea, coffee, or water?
I love a coffee to start a workday, but I have to be careful how much I consume because caffeine hits me pretty hard, even after a concentrated effort over the last 10 years or so to
gradually increase my tolerance. I can manage a couple of mugs in the morning and be fine, now, but three coffees… or any in the mid-afternoon onwards… and I’m at risk of
throwing off my ability to sleep later2.
I wear holes in footwear (and everything else I wear) faster than anybody I know, so nowadays I go for good-value comfort over any other considerations when buying shoes.
One time it was the dog’s fault that my footwear fell apart, but usually they do so by themselves.
4. Favourite dessert?
Varies, but if we’re eating out, I’m probably going to be ordering the most-chocolatey dessert on the menu.
5. The first thing you do when you wake up?
The very first thing I do when I wake up is check how long it is before I need to get up, and make a decision about when I’m going to do so. I almost never need my alarm
to wake me: I routinely wake up half an hour or so before my alarm would go off, most mornings. But exactly how early I wake directly impacts what I do next. If I’m
well-rested and it’s early enough, I’ll plan on getting up and doing something productive: an early start to work, or some voluntary work for Three Rings, or some correspondence. If it’s close to the time I need to get up I’ll more-often just stay in bed and spend longer doing
the actual answer I should give…
…because the “real” answer is probably: pick up my phone, and open up FreshRSS – almost always the
first and last thing I do online in a day! I’ll skim the news and blogosphere and “set aside” for later anything I’d like to re-read or look at later on.
6. Age you’d like to stick at?
Honestly, I’m good where I am, thanks.
Sure, I was fitter and healthier in my 20s, and I had more free time in my early 30s… and there are certainly things I miss and get nostalgic about in any era of my life. But
conversely: it took me a long, long time to “get my shit together” to the level I have now, and I wouldn’t want to have to go through all of the various bits of
self-growth, therapy, etc. all over again!
So… sure, I’d be happy to transplant my intellect into 20-year-old me and take advantage of my higher energy level of the time for an extra decade or so3. But I wouldn’t go back even a
decade if it meant that I had to go relearn and go through everything from that decade another time, no thanks!
7. How many hats do you own?
Four. Ish.
They are:
A bandana. Actually, I own maybe half a dozen bandanas, mostly in Pride rainbow colours. Bandanas are amazingly versatile: they fold small which suits my love of travelling light these last few years, they can function as headgear, dust mask, neckerchief,
flannel, etc.4, and they do a pretty good job of
keeping my head cool and protecting my growing bald spot from the fierce rays of the summer sun.
A “geek” hat. Okay, I’ve actually got three of these, too, in slightly different designs. When they first started appearing at Oxford Geek Nights, I just kept winning them! I’m not a huge fan of caps, so mostly the kids wear them… although
I do put one on when I’m collecting takeaway food so I can get away with just putting e.g. “geek hat” in the “name” field, rather than my name5.
A warm hat that comes out only when the weather is incredibly cold, or when I’m skiing. As I was reminded while skiing on my recent trip to Finland, I should probably switch to wearing a helmet when I ski, but I’ve been skiing for three to four decades without one
and I find the habit hard to break.6
A wooly hat that I was given by a previous employer at a meetup in Mexico last year. I wore it a couple of times last winter
but it’s otherwise not seen much use.
8. Describe the last photo you took?
The last photo I took was of myself wearing a “geek” hat. You’ve seen it, it’s above!
But the one before that was this picture of an extremely large bottle of champagne, with a banana for scale, that was delivered to my house earlier today:
A 6-litre champagne bottle is properly-termed a Methuselah, after Noah’s grandad I guess.
Ruth and JTA celebrate their anniversary every few years with the “next size up” of champagne bottle, and this is the one they’re up to. This
year, merely asking me to help them drink it probably won’t be sufficient (that’d still be two litres each!) so we’re probably going to have to get some friends over.
I took the photo to send to Ruth to reassure her that the bottle had arrived safely, after the previous attempt went… less well. I added the banana “for scale” before sharing the photo with some other friends, too.
The previous delivery… didn’t go so well. 😱
9. Worst TV show?
PAW Patrol. No doubt.
You know all those 1980s kids TV shows that basically existed for no other purpose than as a marketing vehicle for a range of toys? I’m talking He-Man (and
She-Ra), Transformers, G.I. Joe, Care Bears, M.A.S.K., Rainbow Brite, and My Little Pony. Well,
those shows look good compared to PAW Patrol.
Six pups, each endowed with exactly one personality trait7
but a plethora of accessories and vehicles which expands every season so that no matter how many toys you’ve got, y0u’re always behind the curve.
10. As a child, what was your aspiration for adulthood?
This is the single most-boring thing about me, and I’ve doubtless talked about it before. At some point between the age of about six and eight years old, I decided that I
wanted to grow up and become… a computer programmer.
And then I designed the entirety of the rest of my education around that goal. I learned a variety of languages and paradigms under my own steam while setting myself up for a GCSE in
IT, and then A-Levels in Maths and Computing, and then a Degree in Computer Science, and by the time I’d done all of that I was already working in the industry: self-actualised by 21.
Like I said: boring!
Your turn!
You should give this pointless quiz a go too. Ping/Webmention me if you do (or comment below, I suppose); I’d love to read what you write.
Footnotes
1 They’re internet memes, in the traditional sense, but sadly people usually use
“meme” nowadays exclusively to describe image memes, and not other kinds of memetic Internet content. Just another example of our changing
Internet language, which I’ve written about before. Sometimes they were silly quizzes (wanna know what Meat Loaf song I
am?); sometimes they were about you and your friends. But images, they weren’t: that came later.
2 Or else I’ll get a proper jittery heart-flutter going!
3 I wouldn’t necessarily even miss the always-on, in-your-pocket, high-speed Internet of
today: the Internet was pretty great back then, too!
4 Obviously an intergalactic hitch-hiker should include a bandana, perhaps as
well as an equally-versatile towel, in their toolkit.
5 It’s not about privacy, although that’s a fringe benefit I suppose: mostly it’s about
getting my food quicker! If I walk into Dominos wearing a geek hat and they’ve got pizza on the counter with a label on it that says it’s for “geek hat”, they’ll just hand it over, no
questions, and I’m in-and-out in seconds.
6JTA observed that similar excuses
were used by people who resisted the rollout of mandatory seatbelt usage in cars, so possibly I’m the “bad guy” here.
7 From left to right, the single personality traits for each of the pups are (a) doesn’t
like water, (b) is female, (c) likes naps, (d) is allergic to cats, (e) is clumsy, and (f) is completely fucking pointless.
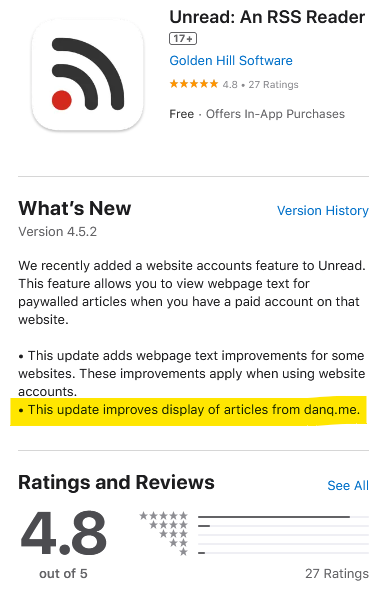
Last month, my friend Gareth observed that the numbered lists in my blog posts “looked wrong” in his feed reader. I checked, and I
decided I was following the standards correctly and it must have been his app that was misbehaving.
So he contacted the authors of Unread, his feed reader, and they fixed it. Pretty fast, I’ve got to say. And I was amused to
see that I’m clearly now a test case because my name’s in their release notes!
The news has, in general, been pretty terrible lately.
Like many folks, I’ve worked to narrow the focus of the things that I’m willing to care deeply about, because caring about many things is just too difficult when, y’know, nazis
are trying to destroy them all.
I’ve got friends who’ve stopped consuming news media entirely. I’ve not felt the need to go so far, and I think the reason is that I already have a moderately-disciplined
relationship with news. It’s relatively easy for me to regulate how much I’m exposed to all the crap news in the world and stay focussed and forward-looking.
The secret is that I get virtually all of my news… through my feed reader (some of it pre-filtered, e.g. my de-crappified BBC News feeds).
I use FreshRSS and I love it. But really: any feed reader can improve your relationship with
the Web.
Without a feed reader, I can see how I might feel the need to “check the news” several times a day. Pick up my phone to check the time… glance at the news while I’m there… you know how
to play that game, right?
But with a feed reader, I can treat my different groups of feeds like… periodicals. The news media I subscribe to get collated in my feed reader and I can read them once, maybe twice
per day, just like a daily newspaper. If an article remains unread for several days then, unless I say otherwise, it’s configured to be quietly archived.
My current events are less like a firehose (or sewage pipe), and more like a bottle of (filtered) water.
Categorising my feeds means that I can see what my friends are doing almost-immediately, but I don’t have to be disturbed by anything else unless I want to be. Try getting that
from a siloed social network!
Maybe sometimes I see a new breaking news story… perhaps 12 hours after you do. Is that such a big deal? In exchange, I get to apply filters of any kind I like to the news I read, and I
get to read it as a “bundle”, missing (or not missing) as much or as little as I like.
On a scale from “healthy media consumption” to “endless doomscrolling”, proper use of a feed reader is way towards the healthy end.
If you stopped using feeds when Google tried to kill them, maybe it’s time to think again. The ecosystem’s alive and well, and having a one-stop place where you can
enjoy the parts of the Web that are most-important to you, personally, in an ad-free, tracker-free, algorithmic-filtering-free space that you can make your very own… brings a
special kind of peace that I can highly recommend.
After “fixing” BBC News’ RSS feeds I noticed that I was seeing less news (and, somehow, stressing less over everything happening in the
USA). Turns out that in switching myself to my new system I’d subscribed to the UK edition, whereas previously I’d been on the Full edition. I’ve corrected it now in my RSS reader, but
it was an interesting couple of days.
tl;dr: I accidentally stopped reading international news and I was less stressed
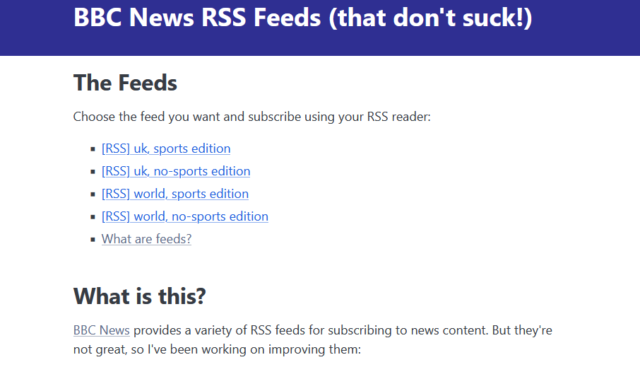
Anyway: if you’re not already using my improved BBC News RSS feeds, they’re at: https://bbc-feeds.danq.dev
It turns out my seriesofefforts to improve the BBC News RSS feeds are more-popular
than I thought. People keep asking for variants of them, and it’s probably time I stopped hosting the resulting feeds on my NAS (which does a good job,
but it’s in a highly-kickable place right under my desk).
The new site isn’t pretty. But it works.
So I’ve launched BBC-Feeds.DanQ.dev. On a 20-minute schedule, it generates both UK and World editions of the BBC News feeds,
filtered to remove iPlayer, Sounds, app “nudges”, duplicates, and other junk, and optionally with the sports news filtered out too.