Nowadays if you’re on a railway station and hear an announcement, it’s usually a computer stitching together samples. But back in the day, there used to be a human
with a Tannoy microphone sitting in the back office, telling you about the platform alternations and
destinations.
I had a friend who did it as a summer job, once. For years afterwards, he had a party trick that I always quite enjoyed: you’d say the name of a terminus station on a direct line from
Preston, e.g. Edinburgh Waverley, and he’d respond in his announcer-voice: “calling at Lancaster, Oxenholme the Lake District, Penrith, Carlisle, Lockerbie, Haymarket, and Edinburgh
Waverley”, listing all of the stops on that route. It was a quirky, beautiful, and unusual talent. Amazingly, when he came to re-apply for his job the next summer he didn’t get it,
which I always thought was a shame because he clearly deserved it: he could do the job blindfold!
There was a strange transitional period during which we had machines to do these announcements, but they weren’t that bright. Years later I found myself on Haymarket station waiting for
the next train after mine had been cancelled, when a robot voice came on to announce a platform alteration: the train to Glasgow would now be departing from platform 2, rather than
platform 1. A crowd of people stood up and shuffled their way over the footbridge to the opposite side of the tracks. A minute or so later, a human announcer apologised for the
inconvenience but explained that the train would be leaving from platform 1, and to disregard the previous announcement. Between then and the train’s arrival the computer tried twice
more to send everybody to the wrong platform, leading to a back-and-forth argument between the machine and the human somewhat reminiscient of the white zone/red zone scene from Airplane! It was funny perhaps only
because I wasn’t among the people whose train was in superposition.
Clearly even by then we’d reached the point where the machine was well-established and it was easier to openly argue with it than to dig out the manual and work out how to turn it off.
Nowadays it’s probably even moreso, but hopefully they’re less error-prone.

When people talk about how technological unemployment, they focus on the big changes, like how a tipping point with self-driving vehicles might one day revolutionise the haulage
industry… along with the social upheaval that comes along with forcing a career change on millions of drivers.
But in the real world, automation and technological change comes in salami slices. Horses and carts were seen alongside the automobile for decades. And you still find stations with
human announcers. Even the most radically-disruptive developments don’t revolutionise the world overnight. Change is inevitable, but with preparation, we can be ready for it.











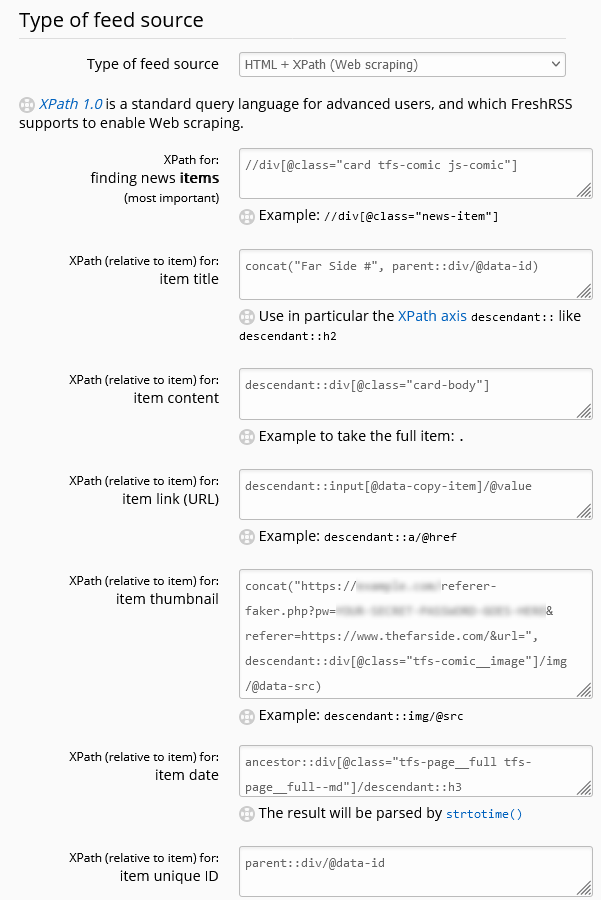
![Browser debugger running document.evaluate('//li[@class="blog__post-preview"]', document).iterateNext() on Beverley's weblog and getting the first blog entry.](https://bcdn.danq.me/_q23u/2022/09/debugger-select-from-xpath-1024x256.png)