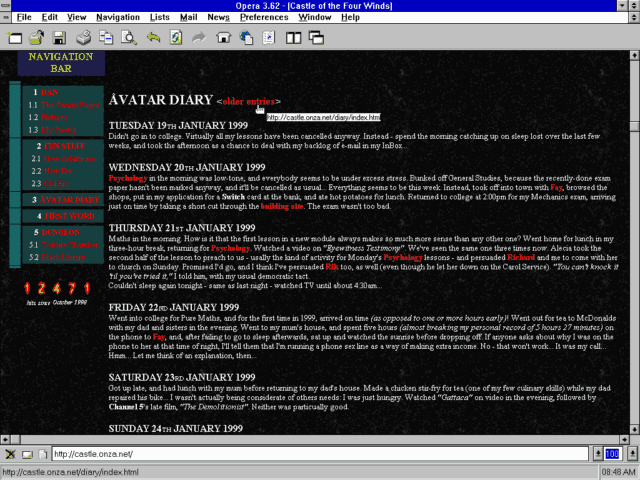
Observant readers might have noticed that some of my recent blog posts – like the one about special roads, my idea for pressure-cooking tea, and the one looking at the history of window tax in two countries1 – are also available as podcast.

Why?
Like my occasional video content, this isn’t designed to replace any of my blogging: it’s just a different medium for those that might prefer it.
For some stories, I guess that audio might be a better way to find out what I’ve been thinking about. Just like how the vlog version of my post about my favourite video game Easter Egg might be preferable because video as a medium is better suited to demonstrating a computer game, perhaps audio’s the right medium for some of the things I write about, too?
But as much as not, it’s just a continuation of my efforts to explore different media over which a WordPress blog can be delivered2. Also, y’know, my ongoing effort to do what I’m bad at in the hope that I might get better at a wider diversity of skills.
How?
Let’s start by understanding what a “podcast” actually is. It is, in essence, just an RSS feed (something you might have heard me talk about before…) with audio enclosures – basically, “attachments” – on each item. The idea was spearheaded by Dave Winer back in 2001 as a way of subscribing to rich media like audio or videos in such a way that slow Internet connections could pre-download content so you didn’t have to wait for it to buffer.3
Here’s what I had to do to add podcasting capability to my theme:
The tag
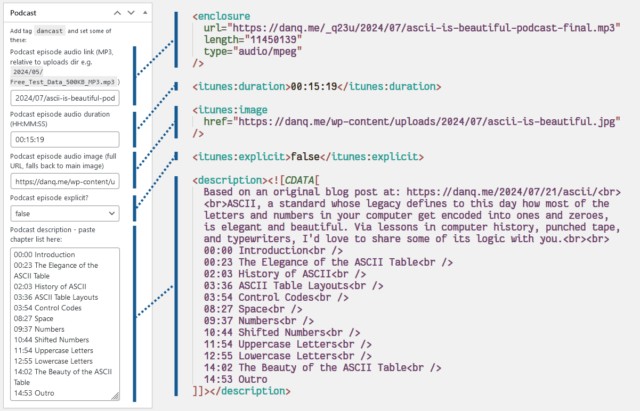
I use a post tag, dancast, to represent posts with accompanying podcast content4.
This way, I can add all the podcast-specific metadata only if the user requests the feed of that tag, and leave my regular feeds untampered . This means that you don’t
get the podcast enclosures in the regular subscription; that might not be what everybody would want, but it suits me to serve podcasts only to people who explicitly ask for
them.
It also means that I’m able to use a template, tag-dancast.php, in my theme to generate a customised page for listing podcast episodes.
The feed
Okay, onto the code (which I’ve open-sourced over here). I’ve use a series of standard WordPress hooks to add the functionality I need. The important bits are:
-
rss2_item– to add the<enclosure>,<itunes:duration>,<itunes:image>, and<itunes:explicit>elements to the feed, when requesting a feed with my nominated tag. Only<enclosure>is strictly required, but appeasing Apple Podcasts is worthwhile too. These are lifted directly from the post metadata. -
the_excerpt_rss– I have another piece of post metadata in which I can add a description of the podcast (in practice, a list of chapter times); this hook swaps out the existing excerpt for my custom one in podcast feeds. -
rss_enclosure– some podcast syndication platforms and players can’t cope with RSS feeds in which an item has multiple enclosures, so as a safety precaution I strip out any enclosures that WordPress has already added (e.g. the featured image). -
the_content_feed– my RSS feed usually contains the full text of every post, because I don’t like feeds that try to force you to go to the original web page5 and I don’t want to impose that on others. But for the podcast feed, the text content of the post is somewhat redundant so I drop it. -
rss2_ns– of critical importance of course is adding the relevant namespaces to your XML declaration. I use theitunesnamespace, which provides the widest compatibility for specifying metadata, but I also use the newerpodcastnamespace, which has growing compatibility and provides some modern features, most of which I don’t use except specifying a license. There’s no harm in supporting both. -
rss2_head– here’s where I put in the metadata for the podcast as a whole: license, category, type, and so on. Some of these fields are effectively essential for best support.
You’re welcome, of course, to lift any of all of the code for your own purposes. WordPress makes a perfectly reasonable platform for podcasting-alongside-blogging, in my experience.
What?
Finally, there’s the question of what to podcast about.
My intention is to use podcasting as an alternative medium to my traditional blog posts. But not every blog post is suitable for conversion into a podcast! Ones that rely on images (like my post about dithering) aren’t a great choice. Ones that have lots of code that you might like to copy-and-paste are especially unsuitable.

Also: sometimes I just can’t be bothered. It’s already some level of effort to write a blog post; it’s like an extra 25% effort on top of that to record, edit, and upload a podcast version of it.
That’s not nothing, so I’ve tended to reserve podcasts for blog posts that I think have a sort-of eccentric “general interest” vibe to them. When I learn something new and feel the need to write a thousand words about it… that’s the kind of content that makes it into a podcast episode.
Which is why I’ve been calling the endeavour “a podcast nobody asked for, about things only Dan Q cares about”. I’m capable of getting nerdsniped easily and can quickly find my way down a rabbit hole of learning. My podcast is, I guess, just a way of sharing my passion for trivial deep dives with the rest of the world.
My episodes are probably shorter than most podcasts: my longest so far is around fifteen minutes, but my shortest is only two and a half minutes and most are about seven. They’re meant to be a bite-size alternative to reading a post for people who prefer to put things in their ears than into their eyes.
Anyway: if you’re not listening already, you can subscribe from here or in your favourite podcasting app. Or you can just follow my blog as normal and look for a streamable copy of podcasts at the top of selected posts (like this one!).
Footnotes
1 I’ve also retroactively recorded a few older ones. Have a look/listen!
2 As well as Web-based non-textual content like audio (podcasts) and video (vlogs), my blog is wholly or partially available over a variety of more-exotic protocols: did you find me yet on Gemini (gemini://danq.me/), Spartan (spartan://danq.me/), Gopher (gopher://danq.me/), and even Finger
(finger://danq.me/, or run e.g. finger blog@danq.me from your command line)? Most of these are powered by my very own tool CapsulePress, and I’m itching to try a few more… how about a WordPress blog that’s accessible over FTP, NNTP, or DNS? I’m not even kidding when I say
I’ve got ideas for these…
3 Nowadays, we have specialised media decoder co-processors which reduce the size of media files. But more-importantly, today’s high-speed always-on Internet connections mean that you probably rarely need to make a conscious choice between streaming or downloading.
4 I actually intended to change the tag to podcast when I went-live,
but then I forgot, and now I can’t be bothered to change it. It’s only for my convenience, after all!
5 I’m very grateful that my favourite feed reader makes it possible to, for example, use a CSS selector to specify the page content it should pre-download for you! It means I get to spend more time in my feed reader.