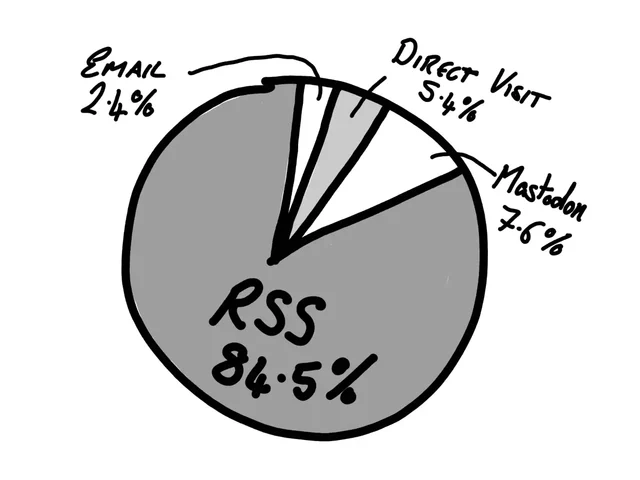
You don’t have to blog like me.
You don’t have to differentiate by post kind.
You don’t have to put full contents in your feed.
You don’t have to keep a library of “maybe-some-day”
drafts so long that you’ll never reach the bottom.
You don’t have to have a comments form.
Or reactions. Or webmentions.
Or a guestbook. Or drawings?
(But give me some way to say “hi, you’re cool!”)
You don’t have to have a feature image.
You don’t have to keep posts up forever.
You don’t have to have tags.
You don’t have to syndicate to the socials.
You don’t have to stick to one topic.
Or three. Or seventeen.
Or be able to answer “what’s your blog about?”
It’s yours, and that’s enough.
You don’t have to post on a schedule.
You don’t have to use your real name.
You don’t have to have a podcast.
You don’t have to tell everybody.
You don’t have to use any particular tool.
Bloggers who spend their time arguing
About vs vs ʕ•ᴥ•ʔ vs
Could be reading and writing instead.
You don’t have to have a plan to “monetize”.
You don’t have to write your own theme.
You don’t have to be run your own server.
You don’t have to make every post your best.
The Internet is ours.
It belongs to the humans.
Not to the companies and the robots.
To us.
And every human voice.
Every single human voice.
Makes the world a little richer.
You don’t have to blog like me.
(You don’t have to use “blog” as a verb.)
You just have to blog.
And if you mention your blog in the comments, below, I promise I’ll go read it.