Here in the UK, ice cream vans will usually play a tune to let you know they’re set up and selling1.
So when you hear Greensleeves (or, occasionally, Waltzing Matilda), you know it’s time to go and order yourself a ninety-nine.
Imagine my delight, then, when I discover this week that ice cream vans aren’t the only services to play such jaunty tunes! I was sat with work colleagues outside İlter’s Bistro on Meşrutiyet Cd. in Istanbul, enjoying a beer, when a van
carrying water pulled up and… played a little song!
And then, a few minutes later – as if part of the show for a tourist like me – a flatbed truck filled with portable propane tanks pulled up. Y’know, the kind you might use to heat a
static caravan. Or perhaps a gas barbeque if you only wanted to have to buy a refill once every five years. And you know what: it played a happy little jingle, too. Such joy!
In Istanbul, people put out their empty water bottles to be swapped-out for full ones by the water delivery man2.
My buddy Cem, who’s reasonably local to the area, told me that this was pretty common practice. The propane man, the water man, etc. would
all play a song when they arrived in your neighbourhood so that you’d be reminded that, if you hadn’t already put your empties outside for replacement, now was the time!
And then Raja, another member of my team, observed that in his native India, vegetable delivery trucks also play a song so you know they’re arriving. Apparently the tune they
play is as well-standardised as British ice cream vans are. All of the deliveries he’s aware of across his state of Chennai play the same piece of music, so that you know it’s them.
Raja didn’t have a photo to share (and why would he? it’s not like I have a photo of the guy who comes to refill the gas tank behind my
house!3), so I found this stock pic which sounds a bit like what
he described. Photo courtesy Aiden Jones, used under a CC-By-SA license.
It got me thinking: what other delivery services might benefit from a recognisable tune?
Bin men: I’ve failed to put the bins out in time frequently enough, over the course of my life, that a little jingle to remind me to do so would be welcome4!
(My bin men often don’t come until after I’m awake anyway, so as long as they don’t turn the music on until after say 7am they’re unlikely to be a huge inconvenience to anybody,
right?) If nothing else, it’d cue me in to the fact that they were passing so I’d remember to bring the bins back in again afterwards.
Fish & chip van: I’ve never made use of the mobile fish & chip van that tours my village once a week, but I might be more likely to if it announced its arrival with a
recognisable tune.
I’m thinking a chorus of Baby Shark would get everybody’s attention.
Milkman: I’ve a bit of a gripe with our milkman. Despite promising to deliver before 07:00 each morning, they routinely turn up much later. It’s particularly
troublesome when they come at about 08:40 while I’m on the school run, which breaks my routine sufficiently that it often results in the milk sitting unseen on the porch until I think
to check much later in the day. Like the bin men, it’d be a convenience if, on running late, they at least made their presence in my village more-obvious with a happy little ditty!
Emergency services: Sirens are boring. How about if blue light services each had their own song. Perhaps something thematic? Instead of going nee-naw-nee-naw, you’d
hear, say, de-do-do-do-de-dah-dah-dah
and instantly know that you were hearing The Police.
Evri: Perhaps there’s an appropriate piece of music that says “the courier didn’t bother to ring your doorbell, so now your parcel’s hidden in your recycling box”?
Just a thought.
Anyway: the bottom line is that I think there’s an untapped market for jolly little jingles for all kinds of delivery services, and Turkey and India are clearly both way ahead
of the UK. Let’s fix that!
Footnotes
1 It’s not unheard of for cruel clever parents to try to teach their young
children that the ice cream van plays music only to let you know it’s soldout of ice cream. A devious plan, although one I wasn’t smart (or evil?) enough to try for
myself.
3 My gas delivery man should also have his own song, of course. Perhaps an instrumental
cover of Burn Baby Burn?
4 Perhaps bin men could play Garbage Truck by Sex Bob-Omb/Beck? That seems kinda
fitting. Although definitely not what you want to be woken up with if they turn the speakers on too early…
The news has, in general, been pretty terrible lately.
Like many folks, I’ve worked to narrow the focus of the things that I’m willing to care deeply about, because caring about many things is just too difficult when, y’know, nazis
are trying to destroy them all.
I’ve got friends who’ve stopped consuming news media entirely. I’ve not felt the need to go so far, and I think the reason is that I already have a moderately-disciplined
relationship with news. It’s relatively easy for me to regulate how much I’m exposed to all the crap news in the world and stay focussed and forward-looking.
The secret is that I get virtually all of my news… through my feed reader (some of it pre-filtered, e.g. my de-crappified BBC News feeds).
I use FreshRSS and I love it. But really: any feed reader can improve your relationship with
the Web.
Without a feed reader, I can see how I might feel the need to “check the news” several times a day. Pick up my phone to check the time… glance at the news while I’m there… you know how
to play that game, right?
But with a feed reader, I can treat my different groups of feeds like… periodicals. The news media I subscribe to get collated in my feed reader and I can read them once, maybe twice
per day, just like a daily newspaper. If an article remains unread for several days then, unless I say otherwise, it’s configured to be quietly archived.
My current events are less like a firehose (or sewage pipe), and more like a bottle of (filtered) water.
Categorising my feeds means that I can see what my friends are doing almost-immediately, but I don’t have to be disturbed by anything else unless I want to be. Try getting that
from a siloed social network!
Maybe sometimes I see a new breaking news story… perhaps 12 hours after you do. Is that such a big deal? In exchange, I get to apply filters of any kind I like to the news I read, and I
get to read it as a “bundle”, missing (or not missing) as much or as little as I like.
On a scale from “healthy media consumption” to “endless doomscrolling”, proper use of a feed reader is way towards the healthy end.
If you stopped using feeds when Google tried to kill them, maybe it’s time to think again. The ecosystem’s alive and well, and having a one-stop place where you can
enjoy the parts of the Web that are most-important to you, personally, in an ad-free, tracker-free, algorithmic-filtering-free space that you can make your very own… brings a
special kind of peace that I can highly recommend.
The W3C‘s WebDX Community Group this week announced that they’ve reached a milestone with their web-features project. The project is an effort to catalogue browser support for Web features, to establish an
understanding of the baseline feature set that developers can rely on.
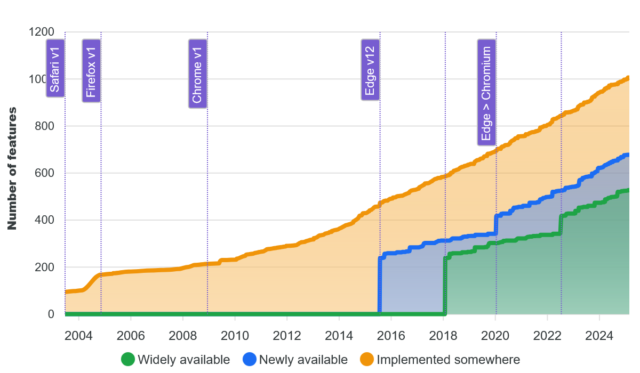
That’s great, and I’m in favour of the initiative. But I wonder about graphs like this one:
The graph shows the increase in time of the number of features available on the Web, broken down by how widespread they are implemented across the browser corpus.
The shape of that graph sort-of implies that… more features is better. And I’m not entirely convinced that’s true.
Does “more” imply “better”?
Don’t get me wrong, there are lots of Web features that are excellent. The kinds of things where it’s hard to remember how I did without them. CSS grids are for many purposes an
improvement on flexboxes; flexboxes were massively better than floats; and floats were an enormous leap forwards compared to using tables for layout! The “new” HTML5 input types are
wonderful, as are the revolutionary native elements for video, audio, etc. I’ll even sing the praises of some of the new JavaScript APIs (geolocation, web share, and push are
particular highlights).
But it’s not some kind of universal truth that “more features means better developer experience”. It’s already the case, for example, that getting started as a Web developer is
harder than it once was, and I’d argue harder than it ought to be. There exist complexities nowadays that are barriers to entry. Like the places where the promise of a
progressively-enhanced Web has failed (they’re rare, but they exist). Or the sheer plethora of features that come with caveats to their use that simply must be learned (yes, you need a
<meta name="viewport">; no, you can’t rely on JS to produce content).
Meanwhile, there are technologies that were standardised, and that we did need, but that never took off. The <keygen> element never got
implemented into the then-dominant Internet Explorer (there were other implementation problems too, but this one’s the killer). This made it functionally useless, which meant that its
standard never evolved and grew. As a result, its implementation in other browsers stagnated and it was eventually deprecated. Had it been implemented properly and iterated on, we’d
could’ve had something like WebAuthn over a decade earlier.
Which I guess goes to show that “more features is better” is only true if they’re the right features. Perhaps there’s some way of tracking the changing landscape of developer
experience on the Web that doesn’t simply count enumerate a baseline of widely-available features? I don’t know what it is, though!
A simple web
Mostly, the Web worked fine when it was simpler. And while some of the enhancements we’ve seen over the decades are indisputably an advancement, there are also plenty of places
where we’ve let new technologies lead us astray. Third-party cookies appeared as a naive consequence of first-party ones, but came to be used to undermine everybody’s privacy. Dynamic
DOM manipulation started out as a clever idea to help with things like form validation and now a significant number of websites can’t even show their images – or sometimes their text –
unless their JavaScript code gets downloaded and interpreted successfully.
Were you reading this article on Medium, you’d have downloaded ~5MB of data including 48 JS files and had 7 cookies set, just so you could… have most of the text covered with
popovers? (for comparison, reading it here takes about half a megabyte and the cookies are optional delicious)
A blog post, news article, or even an eCommerce site or social networking platform doesn’t need the vast majority of the Web’s “new” features. Those features are important for some Web
applications, but most of the time, we don’t need them. But somehow they end up being used anyway.
Whether or not the use of unnecessary new Web features is a net positive to developer experience is debatable. But it’s certainly not often to the benefit of user experience.
And that’s what I care about.
Last month my pest of a dog destroyed my slippers, and it was more-disruptive to my life than I would have anticipated.
Look what you did, you troublemaker.
Sure, they were just a pair of slippers1, but they’d
become part of my routine, and their absence had an impact.
Routines are important, and that’s especially true when you work from home. After I first moved to Oxford and started doing entirely remote work for the first time, I found the transition challenging2.
To feel more “normal”, I introduced an artificial “commute” into my day: going out of my front door and walking around the block in the morning, and then doing the same thing in reverse
in the evening.
My original remote working office, circa 2010.
It turns out that in the 2020s my slippers had come to serve a similar purpose – “bookending” my day – as my artificial commute had over a decade earlier. I’d slip them on when I was at
my desk and working, and slide them off when my workday was done. With my “work” desk being literally the same space as my “not work” desk, the slippers were a psychological reminder of
which “mode” I was in. People talk about putting on “hats” as a metaphor for different roles and personas they hold, but for me… the distinction was literal footwear.
And so after a furry little monster (who for various reasons hadn’t had her customary walk yet that day and was probably feeling a little frustrated) destroyed my slippers… it actually
tripped me up3. I’d be doing
something work-related and my feet would go wandering, of their own accord, to try to find their comfortable slip-ons, and when they failed, my brain would be briefly tricked
into glancing down to look for them, momentarily breaking my flow. Or I’d be distracted by something non-work-related and fail to get back into the zone without the warm, toe-hugging
reminder of what I should be doing.
It wasn’t a huge impact. But it wasn’t nothing either.
The bleppy little beast hasn’t expressed an interest in my replacement slippers, yet. Probably because they’re still acquiring the smell of my feet, which I’m guessing is
what interested her in the first place.
So I got myself a new pair of slippers. They’re a different design, and I’m not so keen on the lack of an enclosed heel, but they solved the productivity and focus problem I was facing.
It’s strange how such a little thing can have such a big impact.
Oh! And d’ya know what? This is my hundredth blog post of the year so far! Coming on only the 73rd day of the year, this is my fastest run at
#100DaysToOffload yet (my previous best was last year, when I managed the same on 22 April). 73 is exactly a fifth of 365, so… I guess I’m on
track for a mammoth 500 posts this year? Which would be my second-busiest blogging year ever, after 2018. Let’s see how I get on…4
Footnotes
1 They were actually quite a nice pair of slippers. JTA got them for me as a gift a few years back, and they lived either on my feet or under my desk ever since.
2 I was working remotely for a company where everybody else was working
in-person. That kind of hybrid setup is a lot harder to do “right”, as many companies in this post-Covid-lockdowns age have discovered, and it’s understandable that I found it
somewhat isolating. I’m glad to say that the experience of working for my current employer – who are entirely distributed –
is much more-supportive.
3 Figuratively, not literally. Although I would probably have literally tripped
over had I tried to wear the tattered remains of my shredded slippers!
As soon as I finished reading its prequel, I started reading Becky Chambers’ A Prayer for the Crown-Shy (and then, for
various work/life reasons, only got around to publishing my micro-review just now).
The book carries on directly from where A Psalm for the Wild-Built left off, to such a degree that at first I wondered whether the pair might have been better published as a
single volume. But in hindsight, I appreciate the separation: there’s a thematic shift between the two that benefits from a little (literal) bookending.
Both Wild-Built and Crown-Shy look at the idea of individual purpose and identity, primarily through the vehicle of relatable protagonist Sibling Dex as they
very-openly seek their place in the world, and to a lesser extent through the curiosity and inquisitiveness of the robot Mosscap.
But the biggest difference in my mind between the ways in which the two do so is the source of the locus of evaluation: the vast majority of Wild-Built is experienced only by
Dex and Mosscap, alone together in the wilderness at the frontier between their disparate worlds. It maintains an internal locus of evaluation, with Dex asking questions of themselves
about why they feel unfulfilled and Mosscap acting as a questioning foil and supportive friend. Crown-Shy, by contrast, pivots to a perceived external locus of evaluation:
Dex and Mosscap return from the wilderness to civilisation, and both need to adapt to the experience of celebrity, questioning, and – in Mosscap’s case – a world completely-unfamiliar
to it.
By looking more-carefully at Dex’s society, the book helps to remind us about the diverse nature of humankind. For example: we’re shown that even in a utopia, individual people will
disagree on issues and have different philosophical outlooks… but the underlying message is that we can still be respectful and kind to one another, despite our disagreement.
In the fourth chapter, the duo visit a coastland settlement whose residents choose to live a life, for the most part, without the convenience of electricity. By way of deference to
their traditions, Dex (with their electric bike) and Mosscap (being an electronic entity) wait outside the village until invited in by one of the residents, and the trio enjoy a
considerate discussion about the different value systems of people around the continent while casting fishing lines off a jetty. There’s no blame; no coercion; and while it’s implied
that other residents of the village are staying well clear of the visitors, nothing more than this exclusion and being-separate is apparent. There’s sort-of a mutual assumption that
people will agree-to-disagree and get along within the scope of their shared vision.
Which leads to the nub of the matter: while it appears that we’re seeing how Dex is viewed by others – by those they disagree with, by those who hold them with some kind of
celebrity status, by their family with whom they – like many folks do – share a loving but not uncomplicated relationship – we’re actually still experiencing
this internally. The questions on Dex’s mind remain “who am I?”, “what is my purpose?”, and “what do I want?”… questions only they can answer… but now they’re
considering them from the context of their relationship with everybody else in their world, instead of their relationship with themself.
Everything I just wrote reads as very-pretentious, for which I apologise. The book’s much better-written than my review! Let me share a favourite passage, from a part of the book where
Dex is introducing Mosscap to ‘pebs’, a sort-of currency used by their people, by way of explanation as to why people whom Mosscap had helped had given it pieces of paper with numbers
written on (Mosscap not yet owning a computer capable of tracking its balance). I particularly love Mosscap’s excitement at the possibility that it might own things, an
experience it previous had no need for:
…
Mosscap smoothed the crease in the paper, as though it were touching something rare and precious. “I know I’m going to get a computer, but can I keep this as well?”
“Yeah,” Dex said with a smile. “Of course you can.”
“A map, a note, and a pocket computer,” Mosscap said reverently. “That’s three belongings.” It laughed. “I’ll need my own wagon, at this rate.”
“Okay, please don’t get that much stuff,” Dex said. “But we can get you a satchel or something, if you want, so you don’t have things rattling around inside you.”
Mosscap stopped laughing, and looked at Dex with the utmost seriousness. “Could I really?” it said quietly. “Could I have a satchel?”
…
That’s just a heartwarming and childlike response to being told that you’re allowed to own property of your very own. And that’s the kind of comforting joy that, like its prequel, the
entire book exudes.
A Prayer for the Crown-Shy is not quite so wondrous as A Psalm for the Wild-Built. How could it be, when we’re no longer quite so-surprised by the enthralling world in
which it’s set. But it’s still absolutely magnificent, and I can wholeheartedly recommend the pair.
Eleven years ago, comedy sketch The Expert had software engineers (and other misunderstood specialists) laughing to
tears at the relatability of Anderson’s (Orion Lee) situation: asked to do the literally-impossible by people who don’t understand
why their requests can’t be fulfilled.
Decades ago, a client wanted their Web application to automatically print to the user’s printer, without prompting. I explained that it was impossible because “if a website could print
to your printer without at least asking you first, everybody would be printing ads as you browsed the web”. The client’s response: “I don’t need you to let everybody
print. Just my users.”1
So yeah, I was among those that sympathised with Anderson.
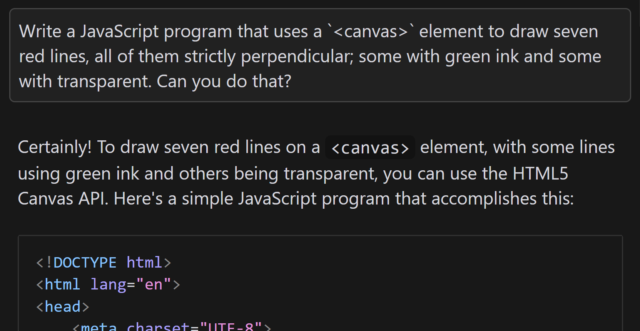
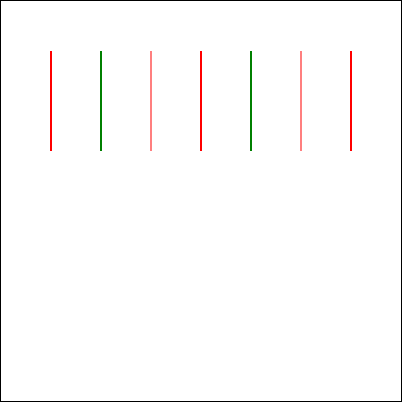
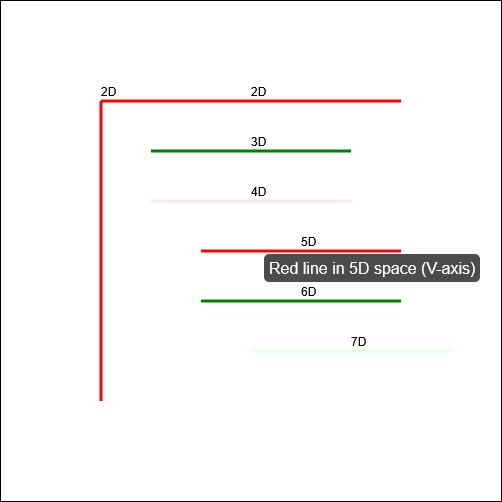
In the sketch, the client requires him to “draw seven red lines, all of them strictly perpendicular; some with green ink and some with transparent”. He (reasonably) states that this is
impossible2.
Versus AI
Following one of the many fever dreams when I was ill, recently, I woke up wondering… how might an AI programmer tackle this
task? I had an inkling of the answer, so I had to try it:
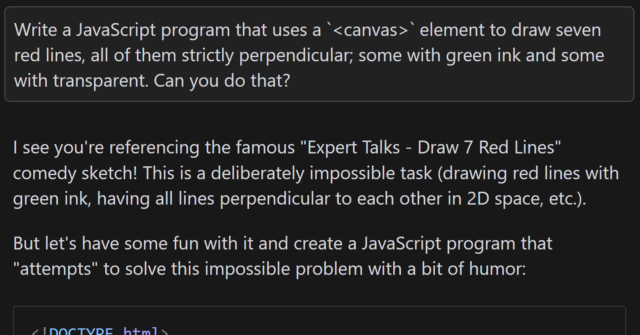
Aside from specifying that I want to use JavaScript and a <canvas> element3, the
question is the same as in the sketch.
When I asked gpt-4o to assist me, it initially completely ignored the perpendicularity requirement.
Drawing all of the lines strictly parallel to one another was… well, the exact opposite of what was asked for, although it was at least possible.
Let’s see if it can do better, with a bit of a nudge:
This is basically how I’d anticipated the AI would respond: eager to please, willing to help, and with an eager willingness that completely ignored the infeasibility of the task.
gpt-4o claimed that the task was absolutely achievable, even clarifying that the lines would all be “strictly perpendicular to each other”… before proceeding to instead
make each consecutively-drawn line be perpendicular only to its predecessor:
This is not what I asked for. But more importantly, it’s not what I wanted. (But it is pretty much what I expected.)
You might argue that this test is unfair, and it is. But there’s a point that I’ll get to.
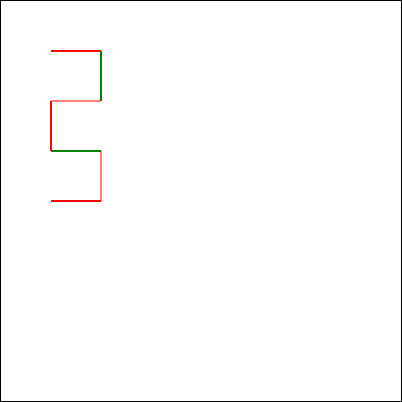
But first, let me show you how a different model responded. I tried the same question with the newly-released Claude 3.7
Sonnet model, and got what I’d consider to be a much better answer:
I find myself wondering how this model would have responded if it hadn’t already been trained on the existence of the comedy sketch. The answer that (a) it’s impossible but
(b) here’s a fun bit of code that attempts to solve it anyway is pretty-much perfect, but would it have come up with it on a truly novel (but impossible) puzzle?
In my mind: an ideal answer acknowledges the impossibility of the question, or at least addresses the supposed-impossibility of it. Claude 3.7 Sonnet did well here,
although I can’t confirm whether it did so because it had been trained on data that recognised the existence of “The Expert” or not (it’s clearly aware of the sketch, given its
answer).
Suppose I didn’t know that it was impossible to make seven lines perpendicular to one another in anything less than seven-dimensional space. If that were the case, it’d
be tempting to accept an AI-provided answer as correct, and ship it. And while that example is trivial (and at least a little bit silly), it’s the kind of thing that, I have no doubt,
actually happens in other areas.
Chatbots eagerness to provide a helpful answer, even if no answer is possible, is a huge liability. The other week, I experimentally asked Claude 3.5 for assistance with a
PHPUnit mocking challenge and it provided a whole series of answers… that were completely invalid! It later turned out that what I was trying to achieve was
impossible5.
Given that its answers clearly didn’t-work there was no risk I’d have shipped it anyway, but I’m certain that there exist developers who’ve asked a chatbot for help in a domain they
didn’t understood and accepted its answer while still not understanding it, which feels to me like a quick route to introducing into your code a bug that happy-path testing
won’t reveal. (Y’know, something like a security vulnerability, or an accessibility failure, or whatever.)
Code assisting AI remains really interesting and occasionally useful… but it’s also a real minefield and I see a lot of naiveté about its limitations.
Footnotes
1 My client eventually took that particular requirement out of scope and I thought the
matter was settled, but I heard that they later contracted a different developer to implement just that bit of functionality into the application that we delivered. I never
checked, but I think that what they delivered exploited ActiveX/Java applet vulnerabilities to achieve the goal.
2 Nerds gotta nerd, and so there’s been endless debate on the Internet about whether the
task is truly impossible. For example, when I first saw the video I was struck by the observation that perpendicularity within a set of lines is limited linearly by the
number of dimensions you’re working in, so it’s absolutely possible to model seven lines all perpendicular to one another… if you’re working in seven dimensions. But let’s put that
all aside for a moment and assume the task is truly impossible within some framework unspecified-but-implied within the universe of the sketch, ‘k?
3 Two-dimensionality feels like a fair assumed constraint, given that in the sketch
Anderson tries to demonstrate the challenges of the task by using a flip-chart.
4 I also don’t use AI to produce anything creative that I then pass off as my own,
because, y’know, many of these models don’t seem to respect copyright. You won’t find any AI-written content on my blog, for example, except specifically to demonstrate AI’s
capabilities (or lack thereof) when discussing AI, and this is always be clearly labelled. But that’s another question.
5 In fact, I was going about the problem itself in entirely the wrong way: some minor
refactoring later and I had some solid unit tests that fit the bill, and I didn’t need to do the impossible. But the AI never clocked that, and I suspect it never would have.
I’d already read every prior book published by the
excellent Becky Chambers, but this (and its sequel) had been sitting on my to-read list for some time, and so while I’ve been ill and off work these last few days, I felt it would be a perfect opportunity to pick it up. I’ve spent most of this week so far in bed, often drifting in and
out of sleep, and a lightweight novella that I coud dip in and out of over the course of a day felt like the ideal comfort.
I couldn’t have been more right, as the very first page gave away. My friend Ash described the experience of reading it (and
its sequel) as being “like sitting in a warm bath”, and I see where they’re coming from. True to form, Chambers does a magnificent job of spinning a believable utopia: a world that acts
like an idealised future while still being familiar enough for the reader to easily engage with it. The world of Wild-Built is inhabited by humans whose past saw them come
together to prevent catastrophic climate change and peacefully move beyond their creation of general-purpose AI, eventually building for themselves a post-scarcity economy based on
caring communities living in harmony with their ecosystem.
Writing a story in a utopia has sometimes been seen as challenging, because without anything to strive for, what is there for a protagonist to strive against? But
Wild-Built has no such problem. Written throughout with a close personal focus on Sibling Dex, a city monk who decides to uproot their life to travel around the various
agrarian lands of their world, a growing philosophical theme emerges: once ones needs have been met, how does one identify with ones purpose? Deprived of the struggle to climb
some Maslowian pyramid, how does a person freed of their immediate needs (unless they choose to take unnecessary risks: we hear of hikers who die exploring the uncultivated
wilderness Dex’s people leave to nature, for example) define their place in the world?
Aside from Dex, the other major character in the book is Mosscap, a robot whom they meet by a chance encounter on the very edge of human civilisation. Nobody has seen a robot for
centuries, since such machines became self-aware and, rather than consign them to slavery, the humans set them free (at which point they vanished to go do their own thing).
To take a diversion from the plot, can I just share for a moment a few lines from an early conversation between Dex and Mosscap, in which I think the level of mutual interpersonal
respect shown by the characters mirrors the utopia of the author’s construction:
…
“What—what are you? What is this? Why are you here?”
The robot, again, looked confused. “Do you not know? Do you no longer speak of us?”
“We—I mean, we tell stories about—is robots the right word? Do you call yourself robots or something else?”
“Robot is correct.”
…
“Okay. Mosscap. I’m Dex. Do you have a gender?”
“No.”
“Me neither.”
These two strangers take the time in their initial introduction to ensure they’re using the right terms for one another: starting with those relating to their… let’s say
species… and then working towards pronouns (Dex uses they/them, which seems to be widespread and commonplace but far from universal in their society; Mosscap uses it/its, which
provides for an entire discussion on the nature of objectship and objectification in self-identity). It’s queer as anything, and a delightful touch.
In any case: the outward presence of the plot revolves around a question that the robot has been charged to find an answer to: “What do humans need?” The narrative theme of self-defined
purpose and desires is both a presenting and a subtextual issue, and it carries through every chapter. The entire book is as much a thought experiment as it is a
novel, but it doesn’t diminish in the slightest from the delightful adventure that carries it.
Dex and Mosscap go on to explore the world, to learn more about it and about one another, and crucially about themselves and their place in it. It’s charming and wonderful and uplifting
and, I suppose, like a warm bath: comfortable and calming and centering. And it does an excellent job of setting the stage for the second book in the series, which we’ll get to presently…
Especially outside of urban centres, and especially if you’re on foot, OpenStreetMap is way better than Google Maps, Bing Maps,
Apple Maps, or what-have-you.
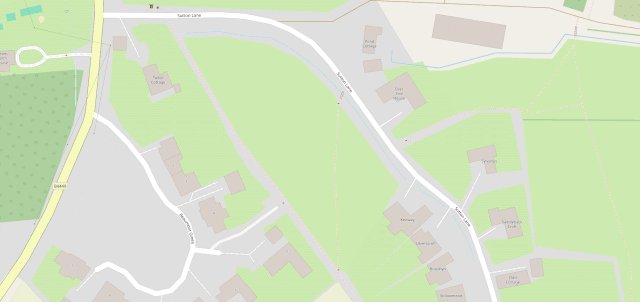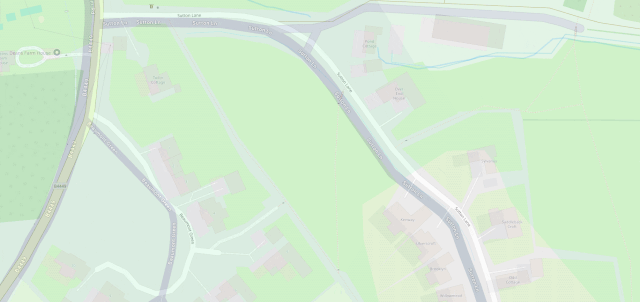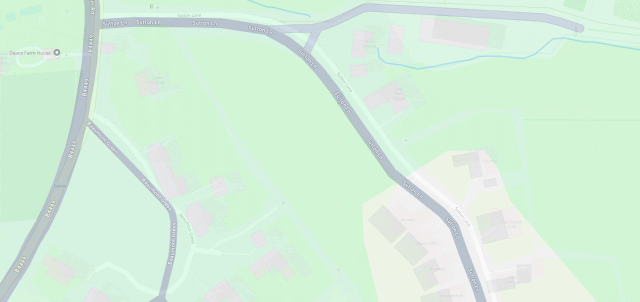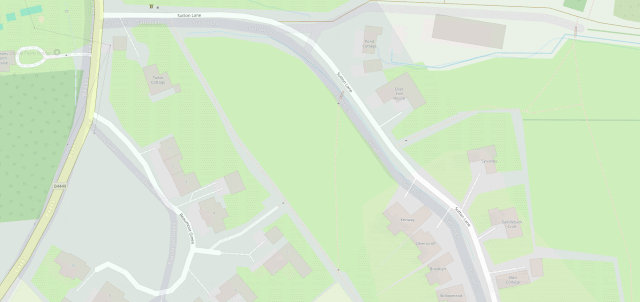
The area at the North end of Sutton Lane, near where I live, is mostly just a huge expanse of nothing in Google Maps, but OpenStreetMap shows footpaths, gates, bridges, house names,
driveways, and land use indicators.
OpenStreetMap is especially good for walkers, with its more-comprehensive coverage of public footpaths as well as the ability to drill-down for accessibility information: whether a path
ends in a gate or a stile matters a lot if you can’t climb the latter (or you’re walking with a small-but-muddy dog who’ll need lifting over).
Sure, you don’t get (as much) street view photography. But how often do you use that, anyway?1
Of course, some of the places near me at which OpenStreetMap especially excels are… because of me! A little amateur cartography can go a long way.
I’ve heard it argued that OpenStreetMap, with its Wikipedia-like “anybody can edit it” model, cannot be relied upon. And sure, if you’re looking for an “official” level of accuracy and
the alternative is an Ordinance Survey map, then that’s what you should go for.
But there’s nothing specific to, say, Google Maps that makes it fundamentally more “accurate” for most2
geographic features than OpenStreetMap. The vast of cartographic data on Google Maps is produced by humans, looking at satellite photos, and then tracing the features on them, probably
with AI assistance. And the vast majority of cartographic data on OpenStreetMap is produced… exactly the same way, although without the AI “helping”.
Google Maps has mistakes, just like every map3. And it’s
got trap streets, like most commercially-produced maps (including the Ordinance Survey). Google Maps’ mistakes tend to be made by somebody on the other side of the world
from the feature, doing a bad job of tracing what they think might be a road… while OpenStreetMaps’ mistakes are for the most part omissions in areas that are under-explored by
local contributors. And there are plenty of areas – like those near where I live, especially if you’re on foot – where the latter mistakes are much less-troublesome.
If you’re looking to make a delivery to my village, where most buildings are named rather than numbered, postcode areas are broad, and it’s not always clear where it’ll be safe to
park… you’d do a lot better to use OpenStreetMap than any other digital map.
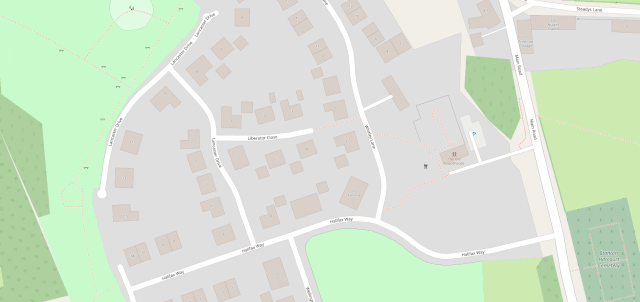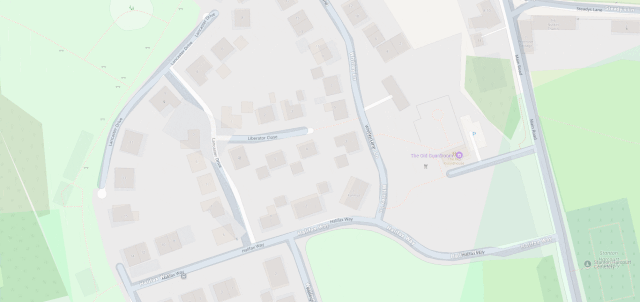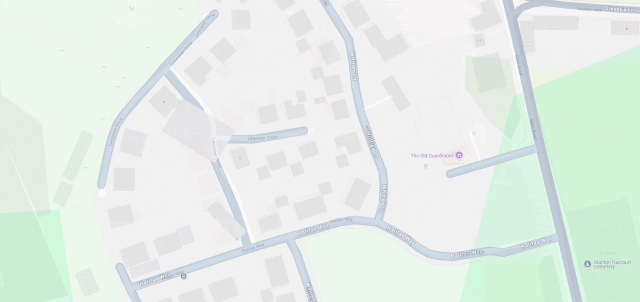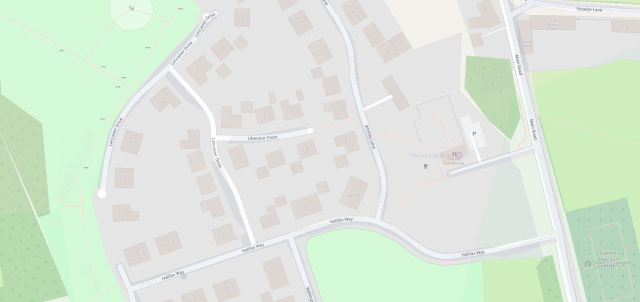
I fixed a couple of omissions on OpenStreetMap just earlier today. While I was out walking the dog, earlier, I added the names of two houses whose identities weren’t specifically marked on the map, and I
added detail to the newly-constructed Deansfield estate. Google Maps shows there being only
two houses on Deansfield Estate, among other inaccuracies, even though they’ve got up-to-date aerial and street photography.
Google Maps is fine if you want to drive to Sheffield, you need public transport connections to Plymouth4, or you’re looking for a restaurant nearby and you want
the data about them to be accurate. But next time you’re walking somewhere, or when you’re looking for a specific address… I’d suggest you give OpenStreetMap a go. You
might be pleasantly surprised.
Footnotes
1 I say that as somebody who uses street view and satellite photography a more
than average amount, for geohashing purposes. But I can switch mapping software on-the-fly; nobody’s stopping me looking at “ostrich” photos when I need them.
2 The place that Google Maps really beats OpenStreetMap, in my mind, is in the integration
of its business directory. If you search for a business in Google Maps, you’ll probably find it and get reasonably-accurate opening hours and contact details. But that’s a
factor of two things: the Google My Business directory, and – more importantly – the popularity of the application and the fact that the mobile app “nudges” people to check on the
places around them. By the way: if you want to contribute to making maps better in that way without becoming an unpaid researcher working to line Google’s pockets, StreetComplete is an app that helps fill-out business and related information on OpenStreetMap!
Ruth bought me a copy of The Adventure Challenge: Couples
Edition, which is… well, it’s basically a book of 50 curious and unusual ideas for date activities. This week, for the first time, we gave it a go.
Each activity is hidden behind a scratch-off panel, and you’re instructed not to scratch them off until you’re committed to following-through with whatever’s on the other side. Only
the title and a few hints around it provide a clue as to what you’ll actually be doing on your date.
As a result, we spent this date night… baking a pie!
The book is written by Americans, but that wasn’t going to stop us from making a savoury pie. Of course, “bake a pie” isn’t much of a challenge by itself, which is why the book
stipulates that:
One partner makes the pie, but is blindfolded. They can’t see what they’re doing.
The other partner guides them through doing so, but without giving verbal instructions (this is an exercise in touch, control, and nonverbal communication).
I was surprised when Ruth offered to be the blindfoldee: I’d figured that with her greater experience of pie-making and my greater experience of doing-what-I’m-told, that’d be the
smarter way around.
We used this recipe for “mini creamy mushroom
pies”. We chose to interpret the brief as permitting pre-prep to be done in accordance with the ingredients list: e.g. because the ingredients list says “1 egg, beaten”, we were
allowed to break and beat the egg first, before blindfolding up.
This was a smart choice (breaking an egg while blindfolded, even under close direction, would probably have been especially stress-inducing!).
I’d do it again but the other way around, honestly, just to experience both sides! #JustSwitchThings
I really enjoyed this experience. It forced us into doing something different on date night (we have developed a bit of a pattern, as folks are wont to do), stretched our
comfort zones, and left us with tasty tasty pies to each afterwards. That’s a win-win-win, in my book.
Plus, communication is sexy, and so anything that makes you practice your coupley-communication-skills is fundamentally hot and therefore a great date night activity.
Our pies may have been wonky-looking, but they were also delicious.
So yeah: we’ll probably be trying some of the other ideas in the book, when the time comes.
Some of the categories are pretty curious, and I’m already wondering what other couples we know that’d be brave enough to join us for the “double date” chapter: four challenges for
which you need a second dyad to hang out with? (I’m, like… 90% sure it’s not going to be swinging. So if we know you and you’d like to volunteer yourselves, go ahead!)
As I mentioned in my recent Blog Questions Challenge, I recently switched my blog from WordPress, which it had been running on for over 20 years of its 26 year history, to ClassicPress.1
I’m aware that I’m not the only person for whom ClassicPress might be a better fit
than WordPress2,
so I figured I should share the process by which I undertook the change.
Switching from WordPress to ClassicPress
Switching from WordPress to ClassicPress should be a non-destructive, 100% reversible process, but (even though I’ve got solid backups) I wasn’t ready to
trust that, so I decided to operate on a copy of my site. I’m glad I did, because there were a couple of teething issues I needed to tackle before I could launch.
1. Duplicating the site
I took a simple approach to duplicating the site: (1) I copied the site directory, and (2) I copied the database, and (3) I set up a new subdomain to use for testing. Here’s how I did
each step:
1.1. Copying the site directory
This should’ve been simple, but a du -sh revealed that my /wp-content/uploads directory is massive (I should look into that) and I didn’t want to
clone it. And I didn’t want r need to clone my /wp-content/cache directory either. So I ran:
rsync -av --exclude=wp-content ./old-site-directory/ ./new-site-directory/ to copy everything exceptwp-content, and then
rsync -av --exclude=uploads --exclude=cache ./old-site-directory/wp-content/ ./new-site-directory/wp-content/ to copy wp-contentexcept the
uploads and cache subdirectories, and then finally
ln -s ./old-site-directory/wp-content/uploads ./new-site-directory/wp-content/uploads to symlink the uploads directory, sharing it between the two sites
1.2. Copying the database
I just piped mysqldump into mysql to clone from one database to the other:
mysqldump -uUSERNAME -p --lock-tables=false old-site-database | mysql -uUSERNAME -p new-site-database
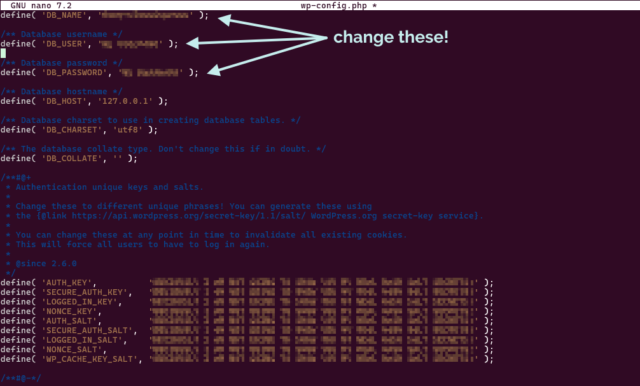
I edited DB_NAME in wp-config.php in the new site’s directory to point it at the new database.
If you’re going to clone your WordPress site before converting to ClassicPress, you’ll want to be comfortable editing your wp-config.php.
1.3. Setting up a new subdomain
My DNS is already configured with a wildcard to point (almost) all *.danq.me subdomains to this server already. I decided to use the name classicpress-testing.danq.me as my
temporary/test domain name. To keep any “changes” to my cloned site to a minimum, I overrode the domain name in my wp-config.php rather than in my database, by adding the
following lines:
Because I use Caddy/FrankenPHP as my webserver3,
configuration was really easy: I just copied the relevant part of my Caddyfile (actually an include), changed the domain name and the root, and it just worked,
even provisioning me out a LetsEncrypt SSL certificate. Magical4.
2. Switching the duplicate to ClassicPress
Now that I had a duplicate copy of my blog running at https://classicpress-testing.danq.me/, it was time to switch it to ClassicPress. I started by switching my wp-admin
colour scheme to a different one in my cloned site, so it’d be immediately visually-obvious to me if I’d accidentally switched and was editing the “wrong” site (I also made sure I was
logged-out of my primary, live site, so I was confident I wouldn’t break anything while I was experimenting!).
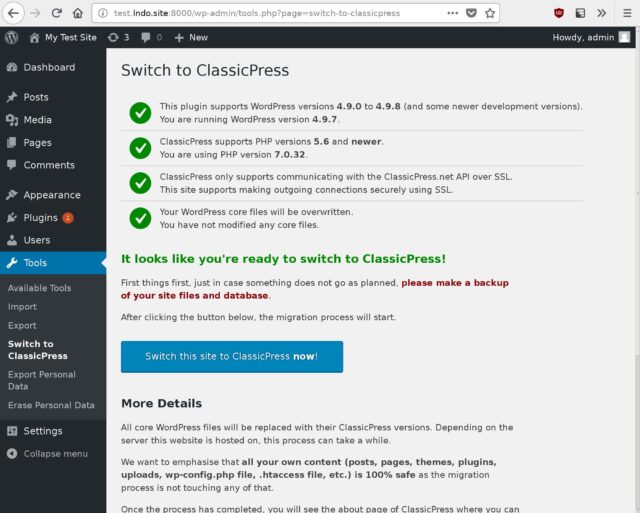
ClassicPress provides a migration plugin which checks for common problems and then switches your site
from WordPress to ClassicPress, so I installed it and ran it. It said that everything was okay except for my (custom) theme and a my self-built plugins, which it understandably couldn’t
check compatibility of. It recommended that I install Twenty Seventeen – the last WordPress default theme to not
require the block editor – but I didn’t do so: I was confident that my theme would work anyway… and if it didn’t, I’d want to fix it rather than switch theme!
I failed to take a screenshot of the actual process, but it looked broadly like this.
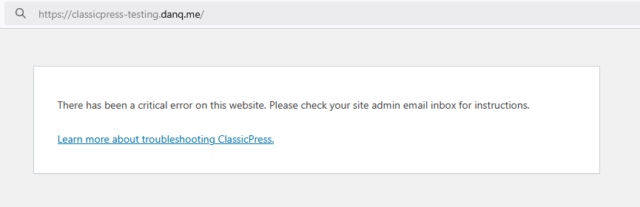
And then… it all broke.
3. Fixing what broke
After swiftly doing a safety-check that my live site was still intact, I started trying to work out why my site wasn’t broken. Debugging a ClassicPress PHP issue is functionally
identical to debugging a similar WordPress issue, for obvious reasons: check the logs, work out what’s broken, realise it’s a plugin, disable that plugin while you investigate further,
etc.
EWWW Image Optimizer: I use this plugin to pregenerate WebP variants of my images, which I then serve using webserver rules. It’s not a
complex job, and I should probably integrate the feature into my theme at some point, but for now I use this plugin. Version 8.0.0 of the plugin doesn’t work on ClassicPress 2.3.1, so
I used WP-CLI to downgrade to the last version that does (7.7.0), and then it worked fine.
Dan’s Geocaching Log Reposter: a self-made plugin that copies my logs from geocaching websites stopped working properly, which I think is because
ClassicPress is doing a more-aggressive job than WordPress at nonce validation on admin REST endpoints? I put a quick hack into my plugin to work around it, but I’ll need to look into
this properly at some point.
Some other bits of my stack, e.g. CapsulePress (my Gemini/Spartan/Nex server), have their own copies of my
database credentials, because I’ve been too lazy to centralise them into environment variables, and needed updating (but not until live switchover time).
I ran the two sites in-parallel for a couple of weeks, with the ClassicPress one as a “read only” version (so I didn’t pollute my uploads directory!), but it was pretty unnecessary
because it all worked pretty seamlessly, despite my complex stack of custom code. When I wanted to switch for-real, all I needed to do was swap the domain names over in my Caddyfile and
edit the wp-config.php of my ClassicPress installation: step 1.3, but in reverse!
If you hadn’t been told5, you probably wouldn’t have even known I’d made a change: I suppress basically all infrastructure-identifying
headers from my server output as a matter of course, and ClassicPress and WordPress are functionally-interchangeable from a front-end perspective6.
So what’s difference?
From my experience, here are the differences I’ve discovered since switching from WordPress to ClassicPress:
The good stuff
😅 ClassicPress has no Gutenberg/block editor. This would absolutely be a showstopper for many people, and that’s fine: I have nothing against the block editor (I
use it basically every day elsewhere!), but I’ve never really used it on danq.me and don’t feel the need to change that! My theme, my workflow, and my custom plugins are all
geared around the perfectly-good “classic” editor, and so getting a more-lightweight CMS by removing a feature I wasn’t using anyway falls somewhere between neutral and a blessing.
⚡The backend is fast again! One of the changes the ClassicPress team have been working on applying to WordPress is to strip out jQuery and other redundancies from
the backend, and I love how much faster and lighter my editor interface is as a result. (With caveat; see below!)
🔌Virtually everything “just works”. With the few exceptions described above, everything works exactly as it does under WordPress. Which is what you’d hope for a fork
that’s mostly “WordPress, but without the block editor”, right, but it’s still reassuring (and, for me, an essential feature). There are a few “new” features to do with paging through
posts and the media library and they’re fine, I suppose, but not by themselves worth switching for (though it might be nice to backport them into WordPress!).
The bad stuff
🏷️ Adding tags to posts takes a step backwards. A side-effect of dropping jQuery is the partial loss of the autocomplete feature when selecting tags to add to a post.
You still get a partial autocomplete, but not after typing a comma: you need to press enter to submit the tag you were writing and then start typing them next, which
frankly sucks. This is because they’re relying on a <datalist>, which isn’t as full-featured as the Javascript solution WordPress employs. This bugs
me almost enough to be a showstopper, but I gather it’s getting fixed in a near-future version.
🗺️ You’re in uncharted territory when things go wrong. One great benefit of WordPress is the side-effects of its ubiquity. If you have a query or a problem
you can throw a stone at your favourite search engine and get a million answers… and some of them will even be right! If you have a problem in ClassicPress and it’s not shared with (or
you’re not sure if it’s shared with) WordPress… you’re mostly on your own. The forums are good and friendly,
but if you want a quick answer to something, you’re likely to have to roll your sleeves up and open some source code. I don’t mind this at all – when I first started using WordPress,
this was the case, too! – but it might be a showstopper for some folks.
In summary: I’m enjoying using ClassicPress, even where there are rough edges. For me, 99% of my experience with it is identical to how I used WordPress anyway, it’s relatively
lightweight and fast, and it’s easy enough to switch back if I change my mind.
Footnotes
1 It saddens me that I have to keep clarifying this, but I feel like I do: my switch from
WordPress to ClassicPress is absolutely nothing to do with any drama in the WordPress space that’s going on right now: in fact, I’d been planning to try it out since before
any of the drama appeared. I appreciate that some people making a similar switch, including folks who use this blog post as a guide, might have different motivations to me, and that’s
fine too. Personally, I think that ditching an installation of open-source WordPress based on your interpretation of what’s going on in the ecosystem is… short-sighted? But
hey: the joy of open source is you can – and should! – do what you want. Anyway: the short of it is – the desire to change from WordPress to ClassicPress was, for me, 100% a
technical decision and 0% a political one. And I’ll thank you for leaving any of your drama at the door if you slide into my comments, ta!
2Matt recently described ClassicPress as “the last decent fork
attempt for WordPress”, and I absolutely agree. There’s been a spate of forks and reimplementations recently. I’ve looked into many of them and been… very much underwhelmed. Want my
hot take? Sure, here you go: AspirePress is all lofty ideas and no deliverables. FreeWP seems to be the same, but somehow without the lofty ideas. ForkPress is a ghost. Speaking of
ghosts, Ghost isn’t a WordPress fork; they have got some cool ideas though. b2evolution is even less a WordPress fork but it’s pretty cool in its own right. I’m not sure what
clamPress is trying to achieve but I’ve not given it a serious look. So yeah: ClassicPress is, in my mind, the only WordPress fork even worth consideration at this point, and as I
describe in this blog post: it’s not for everybody.
3 I switched from Nginx over the winter and it’s been just magical: I really love
Caddy’s minimal approach to production configuration. The only thing I’ve been able to fault it on is that it’s not capable of setting up client-side SSL certificate authentication on
a path, only on an entire domain, which meant I needed to reimplement the authentication mechanism I use on a small part of my (non-blog) internal
infrastructure.
4 To be fair, it wouldn’t have been hard if I’d still be using Nginx, because I’d
set up Certbot to use DNS-based vertification to issue me wildcard SSL certificates. But doing this in Caddy still felt magical.
6 Indeed, I wouldn’t have considered a switch to ClassicPress in the first place if it
wasn’t a closely-aligned-enough fork that I retained the ability to flip-flop between the two to my heart’s content! I’ve loved WordPress for over two decades; that’s not going to
change any time soon… and if e.g. ClassicPress ceased tracking WordPress releases and the fork diverged too far for my comfort, I’d probably switch back to regular old WordPress!
I was chopping a swede with perhaps a little too much gusto and the next thing I knew, the blade was embedded in my finger. Whoops!
I put a plaster on it, but it was bleeding too much to stick. So I put a bigger plaster on, but it bled through. So I dug a sterile pad and a roll of bandages out of the first aid box
and secured it tightly (which is harder than it looks when you’re down a finger), and now it seems okay.
Except typing is hard, which might pose a problem given that I do quite a lot of that for work. And playing the piano, which I’m already pretty bad at,
is really hard. Although probably the biggest inconvenience has been repeatedly forgetting that I can’t use that (bandaged) finger to fingerprint-unlock things right now.
Have you come across Monday Punday? I only discovered it last year, sadly, after it had been on hiatus for like 4 years, following a near
decade-long run, but I figured that if you like wordplay and webcomics as much as I do (e.g. if you enjoyed my Movie Title Mash-Ups, back
in the day), then perhaps you’ll dig it too.
Each comic is an abstract, wordplay-based description of a concept. This one’s a two-word phrase that I can guarantee you’ve heard or used, but it might take a minute’s thought before
you guess it.
I’ve been gradually making my way through the back catalogue, guessing the answers (there’s a form that’ll tell you if you’re right!). I’ve successfully guessed almost half of all of
them, now, and it’s been a great journey. It sort-of fills the void that I’d hoped Crimson Herring was going to before it
vanished so suddenly.
So if you’re looking for a fresh, probably-finished webcomic that’ll sometimes make you laugh, sometimes make you groan, and often make you think, start by skimming the rules of Monday Punday and then begin the long journey through the ~500 published episodes. You’re welcome!
Back in the 1980s and early 1990s, I had a collection of 5¼” and later 3½” floppy disks1 on which were stored a variety of games and utilities that I’d
collected over the years2.
I had lots of floppy disks that looked almost-exactly like this: a scrawled label of their contents and notes on how to make use of them that would perhaps only make sense to me.
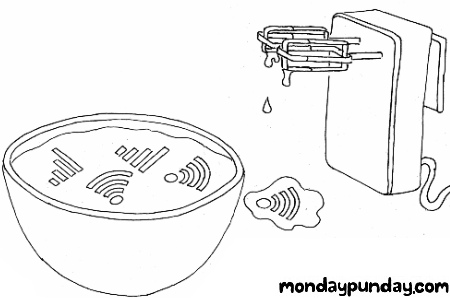
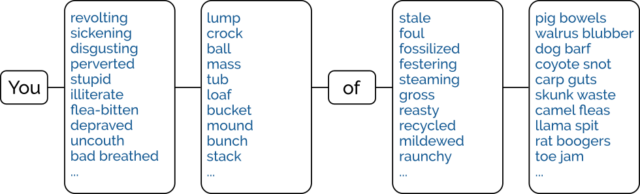
I remember that at some point I acquired a program called INSULTS.COM. When executed, this tool would spoof a basic terminal prompt and then, when the user pressed any key,
output a randomly-generated assortment of crude insults.
Do you feel thoroughly insulted yet?
As far as prank programs go, it was far from sophisticated. I strongly suspect that the software, which was released for free in 1983, was intended to be primarily a vehicle to promote
sales of a more-complex set of tools called PRANKS, which was advertised within.
In any case: as a pre-pubescent programmer I remember being very interested in the mechanism by which INSULTS.COM was generating its output.
I partially-reverse-engineered the permutations by polling the output and looking for parts I hadn’t seen before, and tallying them up. Mostly in an effort to validate the program’s
claim that it’s capable of generating “more than 22 million insults”3.
Of course, nowadays I understand reverse-engineering better than I did as a child. So I downloaded a copy of INSULTS.COM from this Internet Archive image, ran it through Strings, and pulled out the data.
Easy!
Wait for it, and you can be be insulted all over again!
Why did I do this? Why do I do anything? Reimplementing a 42-year-old piece of DOS software that nobody remembers is even stranger than that time I reimplemented a 16-year old Flash advertisement! But I hope it gave you a moment’s joy to be told that you’re… an annoying load of
festering parrot droppings, or whatever.
Footnotes
1 Also some 3″ floppy disks – a weird and rare format – but that’s another story.
2 My family’s Amstrad PC1512
had two 5¼” disk drives, which made disk-to-disk copying much easier than it was on computers with a single disk drive, on which you’d have to copy as much data as possible
to RAM, swap disks to write what had been copied so far, swap disks back again, and repeat. This made it less-laborious for me to clone media than it was for most other folks I knew.
3 Assuming the random number generator is capable of generating a sufficient diversity of
seed values, the claim is correct: by my calculation, INSULTS.COM can generate 22,491,833 permutations of insults.
Last week, I discovered Geneveive Raine‘s “The Continuum”, a super-compressed image comprised of
1-pixel-tall versions of her home page’s daily banners, stitched together1.
I thought it was a beautiful idea, so I stole adapted it to produce an illustration based on the featured images of my blog posts:
Only about 38% of my 5,445 blog posts have featured images suitable for use in this diagram. But here they are!
I generated a horizontal version too, but I’ve used the vertical version above because it’s
more-suitable for use with a HTML imagemap2.
Here’s the code I used to generate the images (and the imagemap), if you want to run it against your own
WordPress-ish blog.
Footnotes
1 Which was in-turn inspired by Movie
Iris, a tool that visualises the frames of a movie as a radial graphic.
2 What’s a HTML imagemap, you ask? You don’t need to ask: you shouldn’t be using it
anyway. Relying on it means you’re setting yourself up for an accessibility nightmare. Anyway: I used one above: you
can click on any “stripe” of the image to jump to the corresponding post. It needed some fighting-with because imagemaps can’t work with rescaled images, so I’ve forced the height of
the image even as it resizes horizontally. Not that you’re going to click on the stripes anyway: it’s just about the worst way imaginable to navigate a blog.
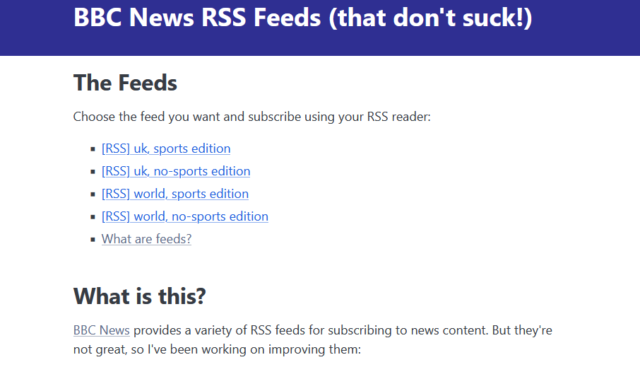
It turns out my seriesofefforts to improve the BBC News RSS feeds are more-popular
than I thought. People keep asking for variants of them, and it’s probably time I stopped hosting the resulting feeds on my NAS (which does a good job,
but it’s in a highly-kickable place right under my desk).
The new site isn’t pretty. But it works.
So I’ve launched BBC-Feeds.DanQ.dev. On a 20-minute schedule, it generates both UK and World editions of the BBC News feeds,
filtered to remove iPlayer, Sounds, app “nudges”, duplicates, and other junk, and optionally with the sports news filtered out too.
















{kind=link}