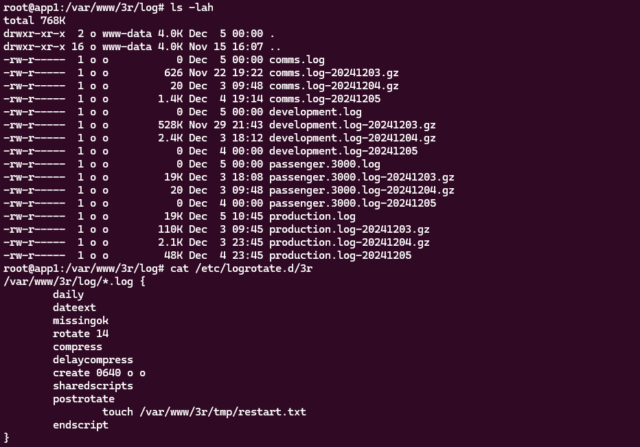
Since Kev Quirk made an adaptation of Ava‘s Blog Questions Challenge I’ve been seeing it everywhere in my blogosphere circle. I’ve gotta be the last person left on Earth to do it, but it has that old-school pass-it-along meme feel, like that 2006 one about describing your friends. I’ve not been tagged by name, but both Jeremy and Garrett did a broad “you” tag, so I’m taking it.
Why did you start blogging in the first place?
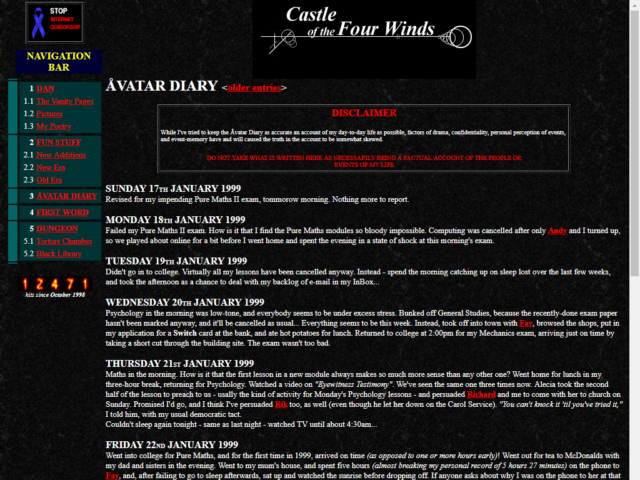
It felt like a natural evolution of my second vanity-site. It was 1998, and my site – Castle of the Four Winds – was home to a selection of the same kinds of random crap that everybody put on their homepages at the time. I figured I’d start keeping an online diary: the word “blog” hadn’t been coined yet, and its predecessor “weblog” had only been around for a year and I hadn’t come across it.
So I experimentally started posting a few times a week.
What platform are you using to manage your blog and why did you choose it? Have you blogged on other platforms before?
1998: Static HTML and a bit of Perl
When I started blogging my site was almost entirely plain HTML2. So my original “platform” was probably Emacs.
2000: Static files indexed by PHP
In the Summer of 2000 I registered avangel.com and moved my diary there. I was still storing posts in static files, but used PHP wrappers to share the structure and menus across the pages. It was a massive improvement.
Later, I moved everything to the (ill-advised?) domain name scatmania.org and reimplemented in pretty-much the same way. Until…
2003: Flip
The first real “blogging engine” I used was Flip.
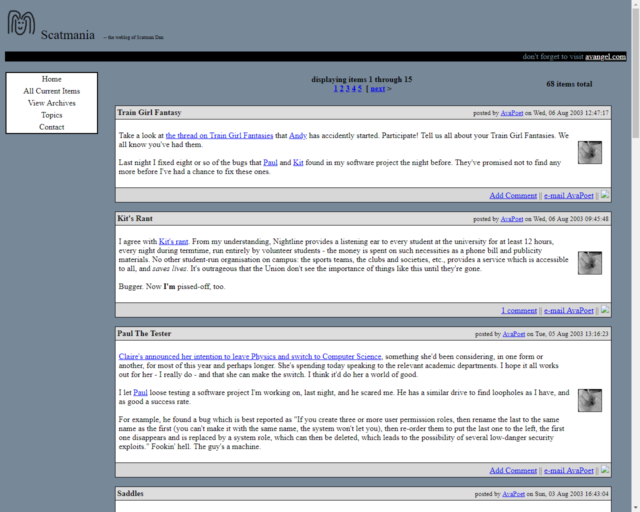
I liked Flip3: it had a raw simplicity that I’d later come to love in young versions of WordPress. And being able to edit from the Web was a huge improvement over having to edit files, especially when I was out and about: I managed to post from my dad’s BlackBerry while cycling across the Outer Hebrides, for example.
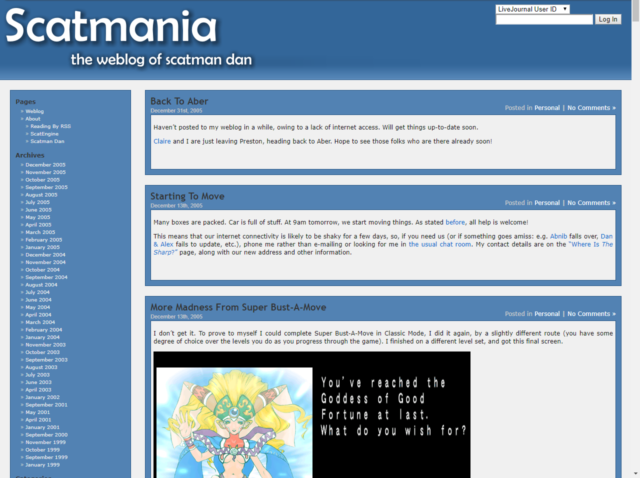
2004: WordPress
I’d have outgrown Flip eventually, but I got a nudge in that direction in July 2004. At the time, I was sharing a server with some friends and operated by Gareth, and something went wrong and the server went completely offline. The co-located server disappeared back to Gareth’s house, eventually, and while I’d recovered many of the posts from my own backups, 61 posts remain partially-incomplete to this day (if you happen to have a copy of any of them I’d love to see it!).
I brought my blog back online using WordPress, whose then-new release version 1.2 included an RSS-powered importer: this allowed me to write a little code to convert my entire previous archive into a fat RSS file and then import it wholesale. WordPress was, as remains, pretty magical – a universal blogging platform that evolved into a universal CMS – and I back in the day I occasionally argued online with Matt about technical aspects of the future direction of the project4.
Incidentally, if you’d like to see more of my blog’s design history over the last 26+ years, I shared a lot of screenshots back in 2018.
If you didn’t know better, you might well not know I’m running WordPress. My theme and custom plugins are… well, they’re an ecosystem all by themselves. And that’s before you even get to things like CapsulePress, my WordPress-to-Gopher/Gemini/Spartan/Nex bridge, the pile of scripts I use to sync-up with the Fediverse, the PWA I use to post notes while I’m on the move, and so on.
2025: ClassicPress
Earlier this year I experimentally switched to ClassicPress; a fork of WordPress. There’ll doubtless be lots more to say about that, down the line5, but here’s the skinny: I don’t use Gutenberg on my blog anyway6, I appreciate having my backend be almost as high-performance as I’ve worked to make my frontend, and I enjoy most of the feature differences7.
How do you write your posts? For example, in a local editing tool, or in a panel/dashboard that’s part of your blog?
With the exception of notes (most of which are written in a tool of my own creation and then pushed to one or both of my Mastodon and my blog simultaneously), I mostly write right into the WordPress/ClassicPress post editor.
I often write ideas, concepts, and first drafts into my Obsidian notebook and then copy/paste out when the time comes.
When do you feel most inspired to write?
There’s no particular pattern, though it feels like I’m most-inspired to write exactly when I should be prioritising something else! That’s why it’s so helpful to be able to write three sentences into Obsidian and then come back to it later!
I’ve been on a bit of a blogging kick these last few years, though. Last year I wrote a massive 436 posts, although that admittedly includes PESOS‘d checkins from geocaching and geohashing expeditions. I’m a fan of Kev’s #100DaysToOffload challenge, and I’m on course to achieve it earlier than ever before, this year (my sixth consecutive year: I do the challenge strictly by calendar years!), as this post is already by 48th… all within the first 38 days of this year8.
Do you publish immediately after writing, or do you let it simmer a bit as a draft?
A mixture of both. Probably most of my posts are written in a single sitting… or, at least, are written in a tab that stays open for the entire time during which it’s written.
But others spend a long time in-progress. You remember how almost a year ago I gave a talk about why Oxford’s area code is 01865? And I promised that there’d be a blog/vlog/maybe-podcast version of that talk later? Yeah: that’s been 90%-there and sitting in a draft pretty-much since then, just waiting for me to make the finishing touches (and record the vlog/podcast variants, if that’s the direction I decide to go in).
And I’ve dusted off drafts that’ve been much older than that, before, too. So it really is a mixture.
What’s your favourite post on your blog?
I couldn’t pick out a favourite that I wouldn’t change my mind about five minutes later. But a recent favourite might have been last Spring’s “Let Your Players Lead The Way”, which aimed to impart some of the things I’ve learned about gamemastering (especially) while being the dungeon master for The Levellers these last few years9.
Not only was it a post that had been a long time coming, and based on months of drafts and re-drafts, but also I really enjoyed writing some post-specific CSS to give it just a slightly more-magical feel.
Any future plans for your blog? Maybe a redesign, a move to another platform, or adding a new feature?
I want to redesign the homepage to be simpler, less-graphical, and more-informational. I’m not sure how that’s going to look, yet.
I’ve been wondering about integrating some of my personal-geotracking into the design (Aaron Parecki does an amazing job of this with his dynamic site background image, for example).
I’m playing with the idea of adding a guestbook, like it’s 1998 again or something.
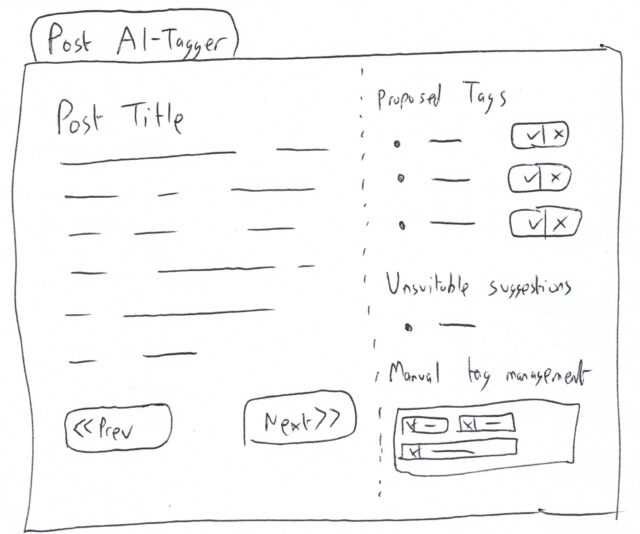
I’d like to tidy up my tagging taxonomy, and I’m not convinced AI is up to the task.
I need to decide how I feel about the emoji reactions feature I added in 2023. I’m still undecided. What do you think? 👍? 👎?
And as I mentioned: I’m experimenting with ClassicPress. It’s working out mostly-okay so far, but that’s a story for another post.
Next?
I feel like I’m the last person in the universe to do this quiz. But if you haven’t – and you have anything approximating a blog – then you should go next.
Footnotes
1 I wouldn’t recommend actually reading my older posts, though. I was a teenager, and it shows.
2 I had a slightly-fancier kind of hosting, by this point, that gave me a
cgi-bin directory into which I could compile binaries (in C) or write scripts (in Perl). My hit counter? That was a Perl script I adapted from Matt Wright’s counter.pl and “enhanced” with some flaming text using Corel
Photo-Paint.
3 While writing this post, I hunted down the original developer of Flip. He seems cool.
4 A year later he launched WordPress.com, which then evolved into the foundation of Automattic, and there soon came a point where I thought “I should work there, someday!” It took me a further 14 years before I applied for such a job, though.
5 Right off the bat, though, let me stress that trying ClassicPress is absolutely nothing to do with the drama in the WordPress space right now: in fact I’ve been planning to give it a try ever since the project got its shit together, re-forked WordPress, and released ClassicPress 2.0 a year ago.
6 I don’t have anything against Gutenberg – I use it on other blogs, and every day at work! – and Block Themes are magical… but I’ve never found any benefit to them here: I’ve no need for it, and I’ve got plugins I’ve written for my own use that I’ve never bothered to make Gutenberg-compatible.
7 My biggest gripe with ClassicPress so far is that in removing the jQuery dependency on
the post editor’s tag selector they’ve only replaced it with a <datalist>, which is neat and all but kills the ability to autocomplete multiple
comma-separated tags at once. But it looks like that’s getting fixed, so I’m going to hang in there for a bit
before I decide whether I’m sticking with ClassicPress or not.
8 I’ll save you from doing the maths: if I complete 48 posts in 38 days, I’d expect to complete 100 posts on my 80th day: as it’s not a leap year, that would be Friday 21 March 2025. Let’s see how I get on!
9 Although I’ve been horribly neglecting them for the last couple of months, for various reasons.