I had an errand to run in the Windrush Place estate on the other side of the A40, and the geopup needed a walk, so I opted to park the car over in Witney so my four-legged friend and I
could walk the remaining way over to Curbridge and find this cache.
The first challenge was, of course, getting over the pedestrian-unfriendly roundabout and across be bridge to Curbridge, but the second challenge wasn’t much easier. Which bit of the
church was the extension? It wasn’t immediately clear and we had to make a few guesses before our numbers lined up to anything believable.
Finally, we set off. The geohound went crazy, and I soon realised why: our route was taking us almost exactly past the doggy daycare she
attends twice a week. It was strange enough for me to find myself at a GZ I pass several times a week, but it must have been even stranger for the doggo, whose keen nose could
probably tell that we’d unexpectedly come by somewhere so familiar to her!
The coordinates were bang on and I soon had the cache in hand. Thanks for a lovely walk and the opportunity to explore on foot a place previously only familiar to me by car.
SL, TFTC!
Last month my pest of a dog destroyed my slippers, and it was more-disruptive to my life than I would have anticipated.
Look what you did, you troublemaker.
Sure, they were just a pair of slippers1, but they’d
become part of my routine, and their absence had an impact.
Routines are important, and that’s especially true when you work from home. After I first moved to Oxford and started doing entirely remote work for the first time, I found the transition challenging2.
To feel more “normal”, I introduced an artificial “commute” into my day: going out of my front door and walking around the block in the morning, and then doing the same thing in reverse
in the evening.
My original remote working office, circa 2010.
It turns out that in the 2020s my slippers had come to serve a similar purpose – “bookending” my day – as my artificial commute had over a decade earlier. I’d slip them on when I was at
my desk and working, and slide them off when my workday was done. With my “work” desk being literally the same space as my “not work” desk, the slippers were a psychological reminder of
which “mode” I was in. People talk about putting on “hats” as a metaphor for different roles and personas they hold, but for me… the distinction was literal footwear.
And so after a furry little monster (who for various reasons hadn’t had her customary walk yet that day and was probably feeling a little frustrated) destroyed my slippers… it actually
tripped me up3. I’d be doing
something work-related and my feet would go wandering, of their own accord, to try to find their comfortable slip-ons, and when they failed, my brain would be briefly tricked
into glancing down to look for them, momentarily breaking my flow. Or I’d be distracted by something non-work-related and fail to get back into the zone without the warm, toe-hugging
reminder of what I should be doing.
It wasn’t a huge impact. But it wasn’t nothing either.
The bleppy little beast hasn’t expressed an interest in my replacement slippers, yet. Probably because they’re still acquiring the smell of my feet, which I’m guessing is
what interested her in the first place.
So I got myself a new pair of slippers. They’re a different design, and I’m not so keen on the lack of an enclosed heel, but they solved the productivity and focus problem I was facing.
It’s strange how such a little thing can have such a big impact.
Oh! And d’ya know what? This is my hundredth blog post of the year so far! Coming on only the 73rd day of the year, this is my fastest run at
#100DaysToOffload yet (my previous best was last year, when I managed the same on 22 April). 73 is exactly a fifth of 365, so… I guess I’m on
track for a mammoth 500 posts this year? Which would be my second-busiest blogging year ever, after 2018. Let’s see how I get on…4
Footnotes
1 They were actually quite a nice pair of slippers. JTA got them for me as a gift a few years back, and they lived either on my feet or under my desk ever since.
2 I was working remotely for a company where everybody else was working
in-person. That kind of hybrid setup is a lot harder to do “right”, as many companies in this post-Covid-lockdowns age have discovered, and it’s understandable that I found it
somewhat isolating. I’m glad to say that the experience of working for my current employer – who are entirely distributed –
is much more-supportive.
3 Figuratively, not literally. Although I would probably have literally tripped
over had I tried to wear the tattered remains of my shredded slippers!
I didn’t know how to solve the puzzle, but I did know how to write a computer program to solve it for me. That would probably be even more fun, and I could argue that it didn’t
actually count as cheating. I didn’t want the solution to reveal itself to me before I’d had a chance to systematically hunt it down, so I dived across the room to turn off the
console.
I wanted to have a shower but I was worried that if I did then inspiration might strike and I might figure out the answer myself. So I ran upstairs to my office, hit my Pomodoro
timer, scrolled Twitter to warm up my brain, took a break, made a JIRA board, Slacked my wife a status update, no reply, she must be out of signal. Finally I fired up my preferred
assistive professional tool. Time to have a real vacation.
…
Obviously, I’d be a fan of playing your single-player video game any damn way you like. But beyond that, I see Robert’s point: there are some
puzzles that are just as much (or more) fun to write a program to solve than to solve as a human. Digital jigsaws would be an obvious
and ongoing example, for me, but I’ve also enjoyed “solving” Hangman (not strictly a single-player game, but
my “solution” isn’t really applicable to human opponents anyway), Mastermind (this is single-player, in my personal
opinion – fight me! – the codemaster doesn’t technically have anything “real” to do; their only purpose is to hold secret information), and I never got into Sudoku principally because I
found implementing a solver much more fun that being a solver.
Anyway: Robert’s post shows that he’s got too much time on his hands when his wife and kids are away, and it’s pretty fun.
I decided to take my meeting with my coach today in our house’s new library, which my metamour
JTA has recently been working hard on decorating, constructing, and filling with books. The room’s not quite finished, but it made for a brilliant space for a bit of quiet
reflection and self-growth work.
(Incidentally: I might be treating “lives in a house with a library” as a measure of personal success. Like: this is what winning at life looks like, right? Because whatever
else goes wrong, at least you can go hide in the library!)
I’ve been trying to comment more on other people’s blogs. It’s tough, because comment forms continue to wane in popularity, and it’s not always clear who’ll accept Webmentions, but
there’s often the option of a good old-fashioned email or a fediverse ping.
It occurred to me that I follow a significant number of personal blogs, and my privacy systems mean I’m a bit of a ghost to most analytics systems they might use, so the only way they’d
ever know I was there would be if I said so.
Plus, the Internet is better when it’s social. There are some great people out there, and I’m enjoying meeting them!
(You’re welcome to throw comments, Webmentions, or emails my way, of course, too!)
Being on your phone all the time and while also not being on your phone all the time has never been more important.
“It is as if you were on your phone” is a phone-based experience for pretending to be on your phone without needing to be on your phone. All from the comfort of your phone.
Relax and blend in with familiar gestures and realistic human behaviour.
When I tried this fun and experimental game, I was struck by a feeling of deja vu. Was this really new? It felt ever so familiar.
Turns out, it draws a lot of inspiration from its 2016 prequel, It is as if you were playing
chess. Which I’d completely forgotten about until just now.
It really is almost as if I were on my phone.
Anyway, It is as if you were on your phone is… well, it’s certainly a faithful simulation of what it would be like to be on my phone. If you saw me, you’d genuinely think that
I was on my phone, even though in reality I was just playing It is as if you were on your phone on my phone. That’s how accurate it is.
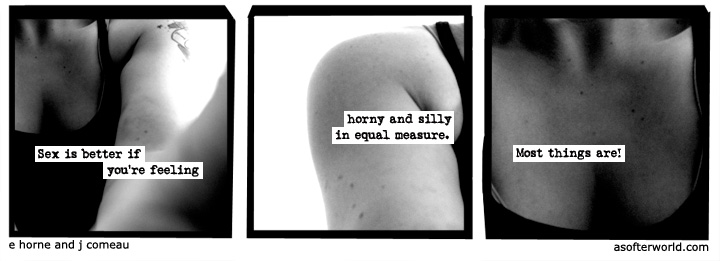
This year it’ll be 10 years since webcomic A Softer World ended its 12-year run. If you missed it, you can still go back and read them all, starting from asofterworld.com/index.php?id=1
But in the meantime, here’s one of my very favourites:
Did not attempt to find, today: an angler was sitting almost right at the GZ, enjoying the peace and quiet that my geokid would have quickly disrupted! So we moved on…
My partner Ruth is, by installments, attempting to walk the entire Thames Path. Today, I’m on transport support so I’ve driven ahead of her to
Culham Lock and the dog and I are walking back to meet her Abingdon Lock before we both come back down this way.
I mostly expect to target geocaches on my return journey, when I’ll also have a geokid with me, but this one basically leapt out at me as soon as I spotted the titular hiding place in
an otherwise empty GZ! So I swiped, signed, and returned it while the geopup checked out the local smells. TFTC!
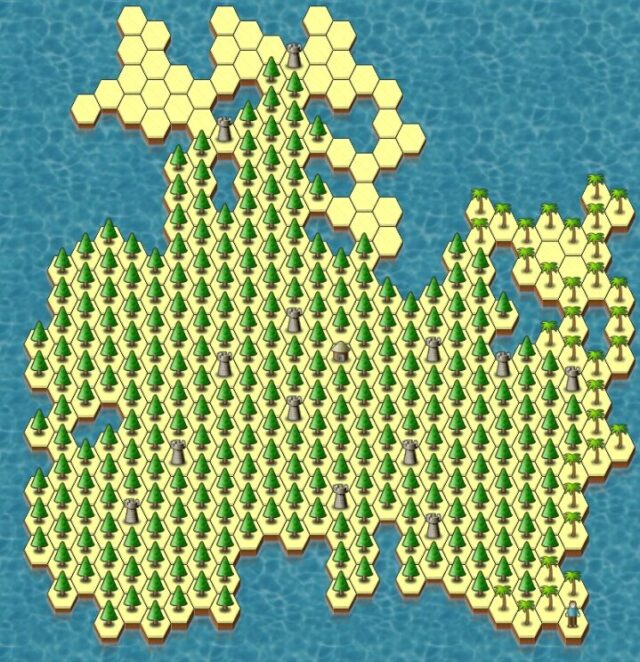
I’ve been playing Sean O’Connor’s Slay for around 30 years (!), but somehow it took until today, on the Android version,
before I tried my hand at “rewilding” the game world.
The rules of the game make trees… a bad thing: you earn no income from hexes with them. But by the time I was winning this map anyway, I figured that encouraging growback would be a
pleasant way to finish the round.
Play your videogames any damn way you want. Don’t let anybody tell you there’s a right or wrong way to enjoy a single-player game. Today I took a strategy wargame and grew a forest. How
will you play?
My love of the yesterweb forced me to teach myself just-enough Blender to make an animation for a stupid thing: an 88×31 button representing “me” (and, I suppose, my blog, whenever I
next end up redesigning its theme).



![A notebook is held in front of terminal output. The terminal begins with 'Start position: [0,4]' and then shows a series of 5×5 grids containing numbers: one, labelled 'Route:', shows random grid of the numbers 0 through 24; the second, labelled 'Puzzle:', contains 1s, 2s, and 3s, corresponding perhaps to the orthagonal distances between consecutive numbers from the first grid; the third, whose title is obscured by the notebook, shows the same thing again but with 'walls' drawn in ASCII art between some of the numbers. The notebook in front contains hand-drawn sketches of similar grids with arrows "jumping" around between them.](https://bcdn.danq.me/_q23u/2025/03/20250313_100059-640x487.jpg)