With visa complications and travel challenges, this is the very first time that my team – whom I’ve been working with for the last year – have ever all been in the same country, all at
the same time.
You can do a lot in a distributed work environment. But sometimes you just have to come together… in celebration of your achievements, in anticipation of what you’ll do next, and in aid
of doing those kinds of work that really benefit from a close, communal, same-timezone environment.
Hanging with my team at our meetup in Istanbul, this lunchtime I needed to do some accessibility testing…
(with apologies to anybody who doesn’t know that in user interface design, a “kebab menu” is one of those menu icons with a vertical line of three dots: a vertical
ellipsis)
I’m visiting Istanbul to meet with colleagues, but we took some time off from our meetings and work this afternoon to come and get lost in the Grand Bazaar. While browsing the amazing
diversity of stalls I found myself staring at the floors, which are made of the same kind of limestone as my kitchen floor (in which my kids love hunting for fossils!). Wouldn’t that
make a great Earthcache, I thought… and it turns out it anyway is one! So I spent a little while hunting for the best fossil I could find (I’d hoped for a gastropod of some kind, but
had to settle for a bivalve), and sent the answers to the CO. Fantastic stuff. TFTC! FP awarded. And,
possibly, FTF!
Istanbul is… sprawling. I stood on this footbridge, over the water, to try to comprehend the scale of the place, but it’s just massive. The hills, which help the tall buildings to tower
over you no matter where you stand, only serve to exaggerate the effect. Quite the spectacle of human settlement.
Gave up after an extended hunt, aided by the spoiler photo. All that’s hidden here is a discarded one food container. Hoping to find one of CO’s other nearby caches during my time here
in Istanbul, this week.
The news has, in general, been pretty terrible lately.
Like many folks, I’ve worked to narrow the focus of the things that I’m willing to care deeply about, because caring about many things is just too difficult when, y’know, nazis
are trying to destroy them all.
I’ve got friends who’ve stopped consuming news media entirely. I’ve not felt the need to go so far, and I think the reason is that I already have a moderately-disciplined
relationship with news. It’s relatively easy for me to regulate how much I’m exposed to all the crap news in the world and stay focussed and forward-looking.
The secret is that I get virtually all of my news… through my feed reader (some of it pre-filtered, e.g. my de-crappified BBC News feeds).
I use FreshRSS and I love it. But really: any feed reader can improve your relationship with
the Web.
Without a feed reader, I can see how I might feel the need to “check the news” several times a day. Pick up my phone to check the time… glance at the news while I’m there… you know how
to play that game, right?
But with a feed reader, I can treat my different groups of feeds like… periodicals. The news media I subscribe to get collated in my feed reader and I can read them once, maybe twice
per day, just like a daily newspaper. If an article remains unread for several days then, unless I say otherwise, it’s configured to be quietly archived.
My current events are less like a firehose (or sewage pipe), and more like a bottle of (filtered) water.
Categorising my feeds means that I can see what my friends are doing almost-immediately, but I don’t have to be disturbed by anything else unless I want to be. Try getting that
from a siloed social network!
Maybe sometimes I see a new breaking news story… perhaps 12 hours after you do. Is that such a big deal? In exchange, I get to apply filters of any kind I like to the news I read, and I
get to read it as a “bundle”, missing (or not missing) as much or as little as I like.
On a scale from “healthy media consumption” to “endless doomscrolling”, proper use of a feed reader is way towards the healthy end.
If you stopped using feeds when Google tried to kill them, maybe it’s time to think again. The ecosystem’s alive and well, and having a one-stop place where you can
enjoy the parts of the Web that are most-important to you, personally, in an ad-free, tracker-free, algorithmic-filtering-free space that you can make your very own… brings a
special kind of peace that I can highly recommend.
There are few moments of self-satisfaction so great as accidentally running a bath to both the perfect depth and the ideal temperature, after forgetting you’d started drawing the water
at all.
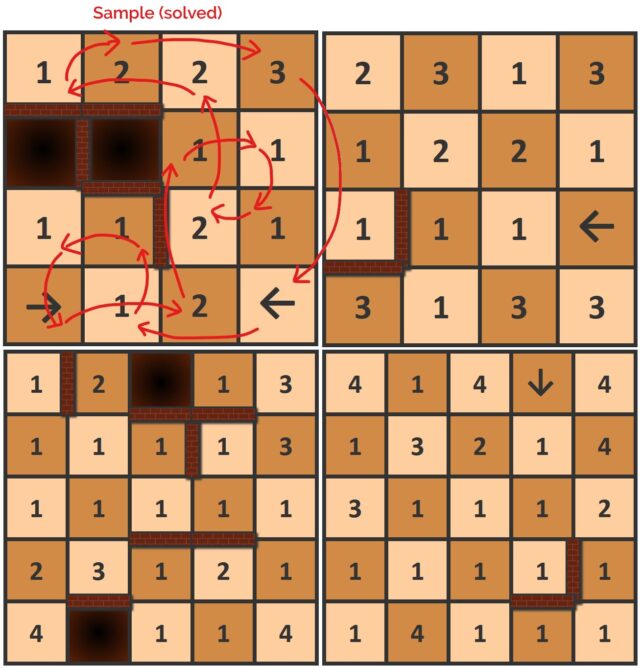
Made a little progress on the game idea I’d been experimenting with. The idea is to do find a series of orthogonal (like a rook in chess!)
moves that land on every square exactly once each before returning to the start, dodging walls and jumping pits.
But the squares have arrows (limiting the direction you can move out of them) or numbers (specifying the distance you must travel from them).
Every board is solvable, starting from any square. There’ll be a playable version to use on your device (with helpful features like “undo”) sometime soon, but for now you can give them
a go by hand, if you like this kind of puzzle!
The W3C‘s WebDX Community Group this week announced that they’ve reached a milestone with their web-features project. The project is an effort to catalogue browser support for Web features, to establish an
understanding of the baseline feature set that developers can rely on.
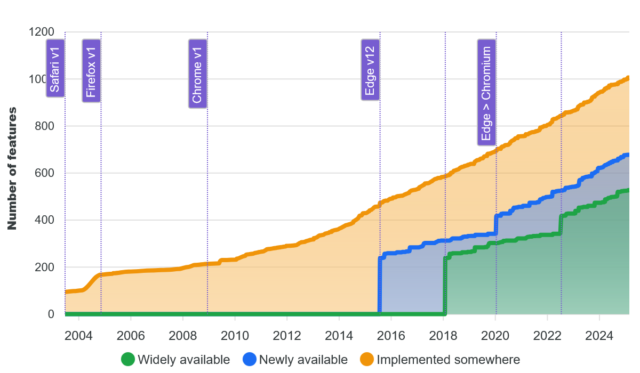
That’s great, and I’m in favour of the initiative. But I wonder about graphs like this one:
The graph shows the increase in time of the number of features available on the Web, broken down by how widespread they are implemented across the browser corpus.
The shape of that graph sort-of implies that… more features is better. And I’m not entirely convinced that’s true.
Does “more” imply “better”?
Don’t get me wrong, there are lots of Web features that are excellent. The kinds of things where it’s hard to remember how I did without them. CSS grids are for many purposes an
improvement on flexboxes; flexboxes were massively better than floats; and floats were an enormous leap forwards compared to using tables for layout! The “new” HTML5 input types are
wonderful, as are the revolutionary native elements for video, audio, etc. I’ll even sing the praises of some of the new JavaScript APIs (geolocation, web share, and push are
particular highlights).
But it’s not some kind of universal truth that “more features means better developer experience”. It’s already the case, for example, that getting started as a Web developer is
harder than it once was, and I’d argue harder than it ought to be. There exist complexities nowadays that are barriers to entry. Like the places where the promise of a
progressively-enhanced Web has failed (they’re rare, but they exist). Or the sheer plethora of features that come with caveats to their use that simply must be learned (yes, you need a
<meta name="viewport">; no, you can’t rely on JS to produce content).
Meanwhile, there are technologies that were standardised, and that we did need, but that never took off. The <keygen> element never got
implemented into the then-dominant Internet Explorer (there were other implementation problems too, but this one’s the killer). This made it functionally useless, which meant that its
standard never evolved and grew. As a result, its implementation in other browsers stagnated and it was eventually deprecated. Had it been implemented properly and iterated on, we’d
could’ve had something like WebAuthn over a decade earlier.
Which I guess goes to show that “more features is better” is only true if they’re the right features. Perhaps there’s some way of tracking the changing landscape of developer
experience on the Web that doesn’t simply count enumerate a baseline of widely-available features? I don’t know what it is, though!
A simple web
Mostly, the Web worked fine when it was simpler. And while some of the enhancements we’ve seen over the decades are indisputably an advancement, there are also plenty of places
where we’ve let new technologies lead us astray. Third-party cookies appeared as a naive consequence of first-party ones, but came to be used to undermine everybody’s privacy. Dynamic
DOM manipulation started out as a clever idea to help with things like form validation and now a significant number of websites can’t even show their images – or sometimes their text –
unless their JavaScript code gets downloaded and interpreted successfully.
Were you reading this article on Medium, you’d have downloaded ~5MB of data including 48 JS files and had 7 cookies set, just so you could… have most of the text covered with
popovers? (for comparison, reading it here takes about half a megabyte and the cookies are optional delicious)
A blog post, news article, or even an eCommerce site or social networking platform doesn’t need the vast majority of the Web’s “new” features. Those features are important for some Web
applications, but most of the time, we don’t need them. But somehow they end up being used anyway.
Whether or not the use of unnecessary new Web features is a net positive to developer experience is debatable. But it’s certainly not often to the benefit of user experience.
And that’s what I care about.
When I was a child, we had a cherry blossom tree in our garden. In late Spring, as the flowers began to wilt, I’d enjoy shaking it to make flutters of pink confetti rain down around me.
This tree, though, spotted on the school run this morning, is very early in its bloom. It feels like a happy reminder that Spring is beginning.
I noticed that automated emails from Steam weren’t doing alt-text very well. Some image links had no or inadequate alt-text. (Note that Steam don’t support opting for plain text rather
than HTML emails.)
I’m fortunate enough to depend upon alt-text never-to-rarely. But I prefer not to load remote images, so I still benefit from alt-text.
I filled out a support request to Steam layout out the specific examples I’d found of where they weren’t doing very well, and stressing why it’s (morally, legally, etc.) important to do
better.
And you know what: they quietly fixed it. When I received an email today telling me that something on my wishlist is on sale, it had reasonably-good alt-text throughout. Neat.
In light of Trump’s attempts to axe Voice of America, because it is, he claims,
“anti-Trump” (and because he’s so insecure that he can’t stand the thought that taxpayer dollars might go to anybody who disagrees with him in any way, for any reason), I’ve produced a
suggested update to the rules of Twilight Struggle for the inevitable 9th
printing:
I guess the Russian player gets to stretch their influence unchecked, anywhere they want, from 2025 onwards.
In the game, I mean.
Yet another blow to US soft power in order to appease the ego of convicted felon Donald Trump. Sigh.