Today is International Volunteer Day. And because I’m in the middle of my (magical) sabbatical, I’ve had no difficulty dedicating what would have been the entire workday to a variety of volunteer activities for the benefit of Three Rings, the nonprofit I founded 22 years ago for the purpose of making volunteer management, and therefore volunteering, easier.
Liveblogging my day

I’m pretty sure that most folks don’t know what my voluntary work at Three Rings involves1, and so I decided I’d celebrate this year’s International Volunteer Day by live-blogging what I got up to in a series of notes throughout the day (1, 2, 3, 4, 5, 6, 7, 8)2.
Maybe, I figured, doing so might provide more of an insight into what a developer/devops role at Three Rings looks like.
Regression-testing a fix
My first task for the day related to a bugfix that we’re looking to deploy. Right now, there’s a problem which sometimes stops the “mail merge” fields in emails sent by Three Rings3. We have a candidate fix, but because it’s proposed as a hotfix (i.e. for deployment directly to production), it requires a more-thorough review process involving more volunteer developers than code which will be made available for beta testing first.
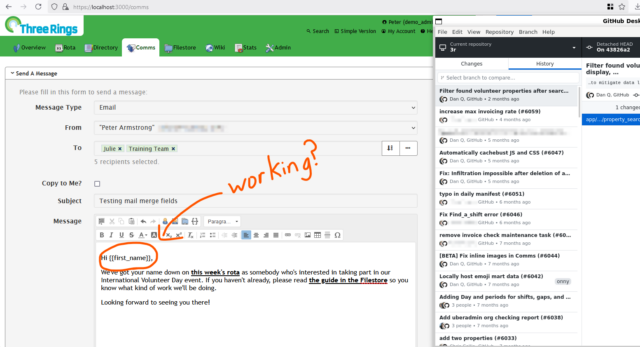
It turned out that everything was alright, so I reported back to my fellow reviewers about how I’d tested and what my results had been. Once some more eyes have hit the tests and the new/changed code, that’ll hopefully be ready-to-launch.

Other code reviews
There were also a couple of other code reviews that demanded my attention, so I moved on to those next.
Preparing new infrastructure
Next week we’re scheduled to do a big migration of server infrastructure to help provide more future growing-room: it’s exciting, but also a little scary4!
Not all of our developer volunteers also wear a “devops” hat, but a few of us do5. It’s quite a satisfying role – devops can feel like tidying and organising, and just as a physical space can feel clean, simple, and functional when it’s carefully and minimalistically laid out, a well-organised cluster of servers humming along in exactly the way they should can be a highly-satisfying thing to be responsible for, too.
Sorting the post
It’s not all techy work, though. And while it’s true that Three Rings has a good group of less-nerdy6 people to handle many of the non-programming tasks that you need to run a voluntary organisation like ours, it’s also true that many of us wear multiple hats and pull our weight in several different roles.

Today, for example, I pulled the recent dead-tree-type post out of our intray and filtered it. Somebody’s got to do these admin tasks, and today I figured it should be me.
Improving our contact form
When people are stuck with Three Rings, or considering using it, or have feature suggestions, or anything else, we encourage them to fill in our contact form. The results of that make their way into our ticketing system where Support Team volunteers help people with whatever it is they need7. They asked if they could have a Slack notification when the form was filled, to grab their attention all the quicker if they were already online, so I obliged and added one.
That quick improvement done, it was time to move on to a task both bigger and more-exciting:
Wrapping up a new feature
I’ve recently been working on an upcoming new feature for Three Rings. Inspired by only occasional user requests, this idea’s been sitting in our (long!) backlog for a while now8: a way to edit the details of volunteers in your organisation in bulk, as though they were in a spreadsheet.
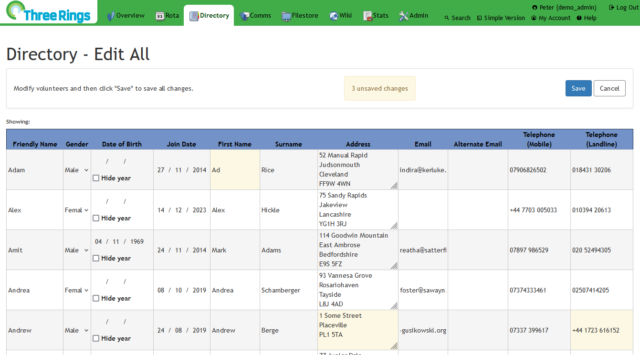
I’ve been working on this feature by a series of iterations since the end of October, periodically demonstrating it to other Three Rings volunteers and getting early feedback. In the last round of demonstrations (plus a little user testing, at an in-person Three Rings event) I solicited opinions on how the new feature should be presented, and who it should be made available to9.
So this afternoon I was working on bits of the user interface and, delightfully, got the feature to a point where I only need to update the test instructions and it’ll be ready for a full review and consideration for inclusion in our next milestone release, early next year. Hurrah!

Reflecting on my day
I don’t normally get this much Three Rings work done in a day. Even since my sabbatical started, I don’t always get so productive a day10, and when I’m working normally I’d probably only get maybe one or two of these achievements done in a typical week.
So I’m hugely appreciative that my employer encourages staff to take a three-month sabbatical every five years. Because it gives me the opportunity have days like this International Volunteer Day, where I can spend the whole day throwing myself headlong at some valuable volunteering efforts and come out the other side with the satisfaction that I gave my time to make the world a very slightly better place.
If you’re not already volunteering somewhere, I’d highly recommend that you consider it. Volunteering can be purposeful, enriching, and hugely satisfying. Happy International Volunteer Day!
Footnotes
1 In fact, most of the charities who use Three Rings’ services are surprised to discover that we’re a voluntary organisation at all, because we provide the kinds of uptime guarantee, tech support response times, software quality etc. that they might have come to expect from much-richer organisations with a much larger – and paid! – staff. That we’re a voluntary organisation helping voluntary organisations is so unusual that sometimes people have been unsure how to handle us: one time, for example, a helpline charity that was considering making use of us declared us “unsustainable” without a commercial model. At some point in the last decade or two they saw that we’ve outlasted many other services of our type, most of them commercial, and realised: yeah, okay, it turns out we’re in this for the long haul.
2 Gosh: a nine-post day is gonna keep throwing the stats of my recent streak all over the place, isn’t it?
3 My use of italics for Three Rings isn’t arbitrary, but I’ll admit it is confusing. “Three Rings” is the name of our nonprofit. “Three Rings” is the name of the software service we provide. Branding is hard when your company name and product name are the same. And it’s even harder when all of your users insist on abbreviating both to “3R”. 🙄
4 With around 60,000 volunteers depending on Three Rings to coordinate their efforts, the pressure is always on to minimise downtime. I’ve spent many hours over the last few weeks running and re-running through practice runs of the migration strategy before I take the lead on it next week.
5 That said, one of the big things I’ve been pushing for in our new infrastructure is new tools to make it easier for our developers to do “server stuff” like deploying new releases, in an effort to bring us closer to the dream of a continuous integration pipeline. Some day!
6 Or “normal people”, as they might call themselves.
7 The Support Team are a wonderful and hard-working group of volunteers, who aim to reply to every contact within 24 hours, 365 days a year, and often manage a lot faster than that. They’re at the front-line of what makes Three Rings a brilliant system.
8 While we curate a backlog of user requests and prioritise them based on the optimisation ratio of amount-of-good-done to the amount-of-effort-expected, our developer volunteers enjoy a huge amount of autonomy about what tasks they choose to pick up. It’s not unknown for developers who also volunteer at other organisations (that might be users of Three Rings) to spend a disproportionate amount of time on features that their organisation would benefit from, and that’s fine… so long as the new feature will also benefit at least a large minority of the other organisations that depend on Three Rings. Also, crucially: we try to ensure that new features never inconvenience existing users and the ways in which they work. That’s increasingly challenging in our 22-year-old software tool, but it’s important to us that we’re not like your favourite eCommerce or social networking service that dramatically change their user interface every other year or drop features without warning nor consideration for who might depend upon them.
9 The new feature’s secured such that it works for everybody: if you accessed it as a volunteer with low privileges, you might be able to see virtually nothing about most of the other volunteers and be able to edit only a few details about yourself, for example. But that’d be a pretty-confusing interface, so we concluded that it probably didn’t need to be made available to all volunteers but only those with certain levels of access. We can always revisit later.
10 After all, sometimes I’ve been too busy adding Nex support to CapsulePress, coming up with server naming schemes that don’t suck, teaching myself to like a new flavour or crisps, wearing old clothes, getting thrown off by the combination of timezone moves during daylight savings changes, implementing a 2000-year old algorithm in JavaScript, visiting Spain including PortAventura (and writing more JavaScript for some reason), trying to persuade the children to go to bed, fretting over my sad car, eating quesapizzas, XPath-scraping a friend’s blog, teaching the kids to play Arimaa, enumerating my domain names, playing OpenTTD, not writing a story, considering the twelfth and twentieth amendments, walking the dog in the snow, learning about horse-powered locomotives, teaching my mum to geohash, unlocking graticules, getting caught out by floods, trying to summon a train, geohashing in forests, enjoying gorgeous views, crawling under bridges, getting muddy, boating, in hospital after injuring my arm, or just drinking.




















![A browser's debug console executes $x('//*[@id="posts"]//a') , and gets 14 results.](https://bcdn.danq.me/_q23u/2024/11/adam-k-xpath-1-640x188.png)