A lot of attention is paid, often in retrospect, to the experience of the first times in our lives. The first laugh; the first kiss; the first day at your job1.
But for every first, there must inevitably be a last.
I recall a moment when I was… perhaps the age our eldest child is now. As I listened to the bats in our garden, my mother told me about how she couldn’t hear them as clearly as she
could when she was my age. The human ear isn’t well-equipped to hear that frequency that bats use, and while children can often pick out the sounds, the ability tends to fade with age.
“Helloooo? Are you even listening to me?”
This recollection came as I stayed up late the other month to watch the Perseids. I lay in the hammock in our garden under a fabulously clear sky as the sun finished setting, and –
after being still and quiet for a time – realised that the local bat colony were out foraging for insects. They flew around and very close to me, and it occurred to me that I
couldn’t hear them at all.
There must necessarily have been a “last time” that I heard a bat’s echolocation. I remember a time about ten years ago, at the first house in Oxford of
Ruth, JTA and I (along with
Paul), standing in the back garden and listening to those high-pitched chirps. But I can’t tell you when the very
last time was. At the time it will have felt unremarkable rather than noteworthy.
First times can often be identified contemporaneously. For example: I was able to acknowledge my first time on a looping rollercoaster at the time.
The Tower of Terror at Camelot, circa 1994, was my first looping rollercoaster2.
The ride was disassembled in 2000 and, minus its “tower” theming3lived on for a while as Twist ‘N’ Shout at Loudoun Castle in Ayrshire, Scotland before that park shut down. I
looked at some recent satellite photography and I’m confident it’s now been demolished.
Last times are often invisible at the time. You don’t see the significance of the everyday and routine except in hindsight.
I wonder what it would be like if we had the same level of consciousness of last times as we did of firsts. How differently might we treat a final phone call to a loved one or the
ultimate visit to a special place if we knew, at the time, that there would be no more?
Would such a world be more-comforting, providing closure at every turn? Or would it lead to a paralytic anticipatory grief: “I can’t visit my friend; what if I find out that
it’s the last time?”
Footnotes
1 While watching a wooden train toy jiggle down a length of string, reportedly; Sarah
Titlow, behind the school outbuilding, circa 1988; and five years ago this week, respectively.
2 Can’t see the loop? It’s inside the tower. A clever bit of design conceals the
inversion from outside the ride; also the track later re-enters the fort (on the left of the photo) to “thread the needle” through the centre of the loop. When they were running three
trains (two in motion at once) at the proper cadence, it was quite impressive as you’d loop around while a second train went through the middle, and then go through the middle while a
third train did the loop!
3 I’m told that the “tower” caught fire during disassembly and was destroyed.
I’ve spent the last week1 in Tulum, on Mexico’s beautiful Yucatan Peninsula, for an Automattic meetup.
And as usual for these kinds of work gatherings, it was magical (and, after many recent departures, a welcome opportunity to feel a closer
connection to those of us that remain).
Obviously, meeting in-person with my immediate team2 was a specific goal for the event.
Only after deciding the title of this blog post did I spot my own accidental wordplay. I mean that it was metaphorically magical, of course, but there also happened to
be more than a little magic performed there too, thanks to yours truly.
I made magic a theme of a “flash talk”. After that ~350 people was a suboptimal audience size for close-up magic and offering to later replicate
the trick I was describing in-person to anybody in the room… I ended up performing it many, many more times.
No, I mean that the whole thing felt magical. Like, I’ve discovered, every Automattic meetup I’ve been to has been. But this is perhaps especially true of the larger
ones like Vienna last year (where my “flash talk” topic was Finger for WordPress; turns out I love the excuse to listen to
other people’s nerdity and fly my own nerd flag a little).
There’s plenty of reasons it was a magical trip, as I’ll explain. But after arriving late and exhausted, this view from the doorstep of my bedroom the
following morning was a great start. I made a habit of a pre-breakfast swim each morning in the warm Caribbean waters.
Our events team, who are already some of the most thoughtful and considerate planners you might ever meet, had gone above and beyond in their choice of location. The all-inclusive
resort they’d booked out for pretty-much our exclusive use was a little isolated and not the kind of place I’d have chosen for a personal holiday. But it provided all of the facilities
my team, sibling teams, and division could desire for work, rest and play.
One day, I returned to my room and discovered that in the course of their tidying, the hotel’s housekeeping team had been asked to tidy up
any stray charging cables using reusable Automattic-branded cable ties. These are the kinds of nice touches that show how hard our events coordinators think about their work3!
As usual, an Automattic meetup proved to be a series of long but energising days comprising a mixture of directly work-related events, social team-building and networking opportunities,
chances for personal growth and to learn or practice skills, and a sweet sprinkling of fun and memorable activities.
A particular treat as a trip to swim through a cenote – caverns formed by sinkhole erosion of the limestone sediment by
rainwater, often considered sacred to the Maya – complete with fish, bats, and the ugliest spiders you’ll ever
see.4Harvey Mackay said5 that if you choose a job you love, you’ll never work a day in your life. That might not ring
true for me every day of my working life, but it certainly feels significant when I’m at Automattic meetups.
Work that feels like fun, and fun that contributes to work? Is that the secret sauce? My colleague Boro and I certainly tried to bring that energy to our workshop on the philosophy of
code reviews, pictured.
Our meetups might not feel like “work” (even when they clearly are!), but rather like… I don’t know… a holiday with 400 of the coolest, friendliest, most-interesting people you could
ever meet6… which just happens to have
an overarching theme of something that you love.
Recently-developed changes to strategic priorities, and the departure of a few of our colleagues during the recent aforementioned “realignment”, meant that my “superteam” – my team and
its siblings – had a lot to talk about. How can we work better together? How can we best meet the needs of the company while also remaining true to its open-source ideology? What will
our relationships with one another and with other parts of the organisation look like in the year to come?
All the best meetings take place in bars, right?
Every morning for a week I’d wake early and walk the soft warm sands and swim in the sea, before meeting with colleagues for breakfast. Then a day of networking and workshops, team-time
activities, meetings, and personal development, which gave way to evenings with so much on offer that FOMO was inevitable7.
I continue to appreciate the ways that Automattic provides the time and space for me to expand my horizons. Whether that’s at one end of a spectrum learning a new technical skill. or
at the other sitting-in on a “sound bath”8.
Automattic remains… automaggical to me. As I rapidly approach five years since I started here (more on that later, I promise,
because, well: five years is a pretty special anniversary at Automattic…), it’s still the case that routinely I get to learn new
things and expand myself while contributing to important and influential pieces of open source software.
Our meetups are merely an intense distillation of what makes Automattic magical on a day-to-day basis.
At home, I usually start my day with a skim of my RSS reader from bed. But with the sea calling to me, first, each morning of the Tulum
meetup, I instead had to suffice with reading my feeds from the nearest available hammock to the beach on my doorstep.
4 The spiders, which weave long thin strand webs that hang like tinsel from the cave roof,
catch and eat mosquitoes, which I’m definitely in favour of.
6 Also, partially-tame trash pandas, which joined
iguanas, agouti, sand pipers, and other wildlife around (and sometimes in) our accommodation.
7 I slightly feel like I missed-out by skipping the board gaming, and it sounds like the
movie party and the karaoke events were a blast too, but I stand by my choices to drink and dance and perform magic and chat about technology and open source and Star Wars
and blogging and music and travel and everything else that I found even the slightest opportunity to connect on with any of the amazing diverse and smart folks with whom I’m fortunate
enough to work.
8 While I completely reject the magical thinking espoused by our “sound bath” facilitator,
it was still a surprisingly relaxing and meditative experience. It was also a nice chill-out before going off to the higher-energy environment that came next at the poolside bar:
drinking cocktails and dancing to the bangin’ tunes being played by our DJ, my colleague Rua.
It became clear a good chunk of my Automattic colleagues disagreed with me and our actions.
So we decided to design the most generous buy-out package possible, we called it an Alignment Offer: if you resigned before 20:00 UTC on Thursday, October 3, 2024, you would receive
$30,000 or six months of salary, whichever is higher.
…
HR added some extra details to sweeten the deal; we wanted to make it as enticing as possible.
I’ve been asking people to vote with their wallet a lot recently, and this is another example!
…
This was a really bold move, and gave many people I know pause for consideration. “Quit today, and we’ll pay you six months salary,” could be a pretty high-value deal for some people,
and it was offered basically without further restriction2.
Every so often, though, I spend time with a company that is so original in its strategy, so determined in its execution, and so transparent in its thinking, that it makes my head
spin. Zappos is one of those companies
…
It’s a hard job, answering phones and talking to customers for hours at a time. So when Zappos hires new employees, it provides a four-week training period that immerses them in the
company’s strategy, culture, and obsession with customers. People get paid their full salary during this period.
After a week or so in this immersive experience, though, it’s time for what Zappos calls “The Offer.” The fast-growing company, which works hard to recruit people
to join, says to its newest employees: “If you quit today, we will pay you for the amount of time you’ve worked, plus we will offer you a $1,000 bonus.” Zappos actually bribes its
new employees to quit!
…
I’m sure you can see the parallel. What Zappos do routinely and Automattic did this week have a similar outcome
By reducing – not quite removing – the financial incentive to remain, they aim to filter their employees down to only those whose reason for being there is that they
believe in what the company does3. They’re trading money for
idealism.
Buried about half way through the Creed is the line I am more motivated by impact than money, which seems
quite fitting. Automattic has always been an idealistic company. This filtering effort helps validate that.
The effect of Automattic’s “if you don’t feel aligned with us, we’ll pay you to leave” offer has been significant: around 159 people – 8.4% of the company – resigned this week. At very
short notice, dozens of people I know and have worked with… disappeared from my immediate radar. It’s been… a lot.
I chose to stay. I still believe in Automattic’s mission, and I love my work and the people I do it with. But man… it makes you second-guess yourself when people you know, and respect,
and love, and agree with on so many things decide to take a deal like this and… quit4.
Departures have been experienced across virtually all divisions, but not always proportionally.
(These numbers are my own estimation and might not be entirely accurate.)
There’ve been some real heart-in-throat moments. A close colleague of mine started a message in a way that made me briefly panic that this was a goodbye, and it took until half way
through that I realised it was the opposite and I was able to start breathing again.
But I’m hopeful and optimistic that we’ll find our feet, rally our teams, win our battles, and redouble our efforts to make the Web a better place, democratise publishing (and
eCommerce!), and do it all with a commitment to open source. There’s tears today, but someday there’ll be happiness again.
Footnotes
1 For which the Internet quickly made me regret my choices, delivering a barrage of
personal attacks and straw man arguments, but I was grateful for the people who engaged in meaningful discourse.
2 For example, you could even opt to take the deal if you were on a performance
improvement plan, or if you were in your first week of work! If use these examples because I’m pretty confident that both of them occurred.
3 Of course, such a strategy can never be 100% effective, because people’s reasons for
remaining with an employer are as diverse as people are.
4 Of course their reasons for leaving are as diverse and multifaceted as others’ reasons
for staying might be! I’ve a colleague who spent some time mulling it over not because he isn’t happy working here but because he was close to retirement, for example.
tl;dr: I’m tidying up and consolidating my personal hosting; I’ve made a little progress, but I’ve got a way to go – fortunately I’ve got a sabbatical coming up at
work!
At the weekend, I kicked-off what will doubtless be a multi-week process of gradually tidying and consolidating some of the disparate digital things I run, around the Internet.
I’ve a long-standing habit of having an idea (e.g. gamebook-making tool Twinebook, lockpicking puzzle game Break Into Us, my Cheating Hangman game, and even FreeDeedPoll.org.uk!),
deploying it to one of several servers I run, and then finding it a huge headache when I inevitably need to upgrade or move said server because there’s such an insane diversity of
different things that need testing!
DNDle, my Wordle-clone where you have to guess the Dungeons & Dragons 5e monster’s stat block, is now hosted by GitHub Pages. Also, I
fixed an issue reported a month ago that meant that I was reporting Giant Scorpions as having a WIS of 19 instead of 9.
Abnib, which mostly reminds people of upcoming birthdays and serves as a dumping ground for any Abnib-related shit I produce, is now hosted by
GitHub Pages.
RockMonkey.org.uk, which doesn’t really do much any more, is now hosted by GitHub Pages.
Sour Grapes, the single-page promo for a (remote) murder mystery party I hosted during a COVID lockdown, is now hosted by GitHub
Pages.
A convenience-page for giving lost people directions to my house is now hosted by GitHub Pages.
Dan Q’s Things is now automatically built on a schedule and hosted by GitHub Pages.
Robin’s Improbable Blog, which spun out from 52 Reflect, wasn’t getting enough traffic to justify
“proper” hosting so now it sits in a Docker container on my NAS.
My μlogger server, which records my location based on pings from my phone, has also moved to my NAS. This has broken
Find Dan Q, but I’m not sure if I’ll continue with that in its current form anyway.
All of my various domain/subdomain redirects have been consolidated on, or are in the process of moving to, to a tinyLinode/Akamai
instance. It’s a super simple plain Nginx server that does virtually nothing except redirect people – this is where I’ll park the domains I register but haven’t found a use for yet, in
future.
I was pretty proud of EGXchange.org, but I’ll be first to admit that it’s among the stupider of my throwaway domains.
It turns out GitHub pages is a fine place to host simple, static websites that were open-source already. I’ve been working on improving my understanding of GitHub Actions
anyway as part of what I’ve been doing while wearing my work, volunteering, and personal hats, so switching some static build processes like DNDle’s to GitHub
Actions was a useful exercise.
Stuff I’m still to tidy…
There’s still a few things I need to tidy up to bring my personal hosting situation under control:
DanQ.me
You’re looking at it. But later this year, you might be looking at it… elsewhere?
This is the big one, because it’s not just a WordPress blog: it’s also a Gemini, Spartan, and Gopher server (thanks CapsulePress!), a Finger server, a general-purpose host to a stack of complex stuff only some of which is powered by Bloq (my WordPress/PHP integrations): e.g.
code to generate the maps that appear on my geopositioned posts, code to integrate with the Fediverse, a whole stack of configuration to make my caching work the way I want, etc.
FreeDeedPoll.org.uk
Right now this is a Ruby/Sinatra application, but I’ve got a (long-running) development branch that will make it run completely in the browser, which will further improve privacy, allow
it to run entirely-offline (with a service worker), and provide a basis for new features I’d like to provide down the line. I’m hoping to get to finishing this during my Automattic
sabbatical this winter.
The website’s basically unchanged for most of a decade and a half, and… umm… it looks it!
A secondary benefit of it becoming browser-based, of course, is that it can be hosted as a static site, which will allow me to move it to GitHub Pages too.
When I took over running the world’s geohashing hub from xkcd‘s Randall Munroe (and davean), I flung the site together on whatever hosting I had sitting
around at the time, but that’s given me some headaches. The outbound email transfer agent is a pain, for example, and it’s a hard host on which to apply upgrades. So I want to get that
moved somewhere better this winter too. It’s actually the last site left running on its current host, so it’ll save me a little money to get it moved, too!
Geohashing’s one of the strangest communities I’m honoured to be a part of. So it’d be nice to treat their primary website to a little more respect and attention.
Right now I run this on my NAS, but that turns out to be a pain sometimes because it means that if my home Internet goes down (e.g. thanks to a power cut, which we have from time to time), I lose access to the first and last place I
go on the Internet! So I’d quite like to move that to somewhere on the open Internet. Haven’t worked out where yet.
Next steps
It’s felt good so far to consolidate and tidy-up my personal web hosting (and to rediscover some old projects I’d forgotten about). There’s work still to do, but I’m expecting to spend
a few months not-doing-my-day-job very soon, so I’m hoping to find the opportunity to finish it then!
Back when I was a student in Aberystwyth, I used to receive a lot of bilingual emails from the University and its departments1.
I was reminded of this when I received an email this week from CACert, delivered in both English and German.
Simply putting one language after the other isn’t terribly exciting. Although to be fair, the content of this email wasn’t terribly exciting either.
Wouldn’t it be great if there were some kind of standard for multilingual emails? Your email client or device would maintain an “order of preference” of the languages that you
speak, and you’d automatically be shown the content in those languages, starting with the one you’re most-fluent in and working down.
It turns out that this is a (theoretically) solved problem. RFC8255 defines a mechanism for breaking an email into multiple
different languages in a way that a machine can understand and that ought to be backwards-compatible (so people whose email software doesn’t support it yet can still “get by”).
Here’s how it works:
You add a Content-Type: multipart/multilingual header with a defined boundary marker, just like you would for any other email with multiple “parts” (e.g. with a HTML
and a plain text version, or with text content and an attachment).
The first section is just a text/plain (or similar) part, containing e.g. some text to explain that this is a multilingual email, and if you’re seeing this
then your email client probably doesn’t support them, but you should just be able to scroll down (or else look at the attachments) to find content in the language you read.
Subsequent sections have:
Content-Disposition: inline, so that for most people using non-compliant email software they can just scroll down until they find a language they can read,
Content-Type: message/rfc822, so that an entire message can be embedded (which allows other headers, like the Subject:, to be translated too),
a Content-Language: header, specifying the ISO code of the language represented in that section, and
optionally, a Content-Translation-Type: header, specifying either original (this is the original text), human (this was translated by a
human), or automated (this was the result of machine translation) – this could be used to let a user say e.g. that they’d prefer a human translation to an automated
one, given the choice between two second languages.
Let’s see a sample email:
Content-Type: multipart/multilingual;
boundary=10867f6c7dbe49b2cfc5bf880d888ce1c1f898730130e7968995bea413a65664
To: <b24571@danq.me>
From: <rfc8255test-noreply@danq.link>
Subject: Does your email client support RFC8255?
Mime-Version: 1.0
Date: Fri, 27 Sep 2024 10:06:56 +0000
--10867f6c7dbe49b2cfc5bf880d888ce1c1f898730130e7968995bea413a65664
Content-Transfer-Encoding: quoted-printable
Content-Type: text/plain; charset=utf-8
This is a multipart message in multiple languages. Each part says the
same thing but in a different language. If your email client supports
RFC8255, you will see this message in your preferred language out of
those available. Otherwise, you will probably see each language after
one another or else each language in a separate attachment.
--10867f6c7dbe49b2cfc5bf880d888ce1c1f898730130e7968995bea413a65664
Content-Disposition: inline
Content-Type: message/rfc822
Content-Language: en
Content-Translation-Type: original
Subject: Does your email client support RFC8255?
Content-Type: text/plain; charset="UTF-8"
Content-Transfer-Encoding: 7bit
MIME-Version: 1.0
RFC8255 is a standard for sending email in multiple languages. This
is the original email in English. It is embedded alongside the same
content in a number of other languages.
--10867f6c7dbe49b2cfc5bf880d888ce1c1f898730130e7968995bea413a65664
Content-Disposition: inline
Content-Type: message/rfc822
Content-Language: fr
Content-Translation-Type: automated
Subject: Votre client de messagerie prend-il en charge la norme RFC8255?
Content-Type: text/plain; charset="UTF-8"
Content-Transfer-Encoding: 7bit
MIME-Version: 1.0
RFC8255 est une norme permettant d'envoyer des courriers
électroniques dans plusieurs langues. Le présent est le courriel
traduit en français. Il est intégré à côté du même contenu contenu
dans un certain nombre d'autres langues.
--10867f6c7dbe49b2cfc5bf880d888ce1c1f898730130e7968995bea413a65664--
Why not copy-paste this into a raw email and see how your favourite email client handles it! That’ll be fun, right?
Can I use it?
That proposed standard turns seven years old next month. Sooo… can we start using it?4
Turns out… not so much. I discovered that NeoMutt supports it:
NeoMutt’s implementation is basic, but it works: you can specify a preference order for languages and it respects it, and if you don’t then it shows all of the languages as a series
of attachments. It can apparently even be used to author compliant multilingual emails, although I didn’t get around to trying that.
Support in other clients is… variable.
A reasonable number of them don’t understand the multilingual directives but still show the email in a way that doesn’t suck:
Mozilla Thunderbird does a respectable job of showing each language’s subject and content, one after another.
Some shoot for the stars but blow up on the launch pad:
GMail displays all the content, but it pretends that the alternate versions are forwarded messages and adds a stack of meaningless blank headers to each. And then offers to
translate the result for you, even though the content is already right there in English.
Others still seem to be actively trying to make life harder for you:
ProtonMail’s Web interface shows only the fallback content, putting the remainder into .eml attachments… which is then won’t display, forcing you to download them and
find some other email client to look at them in!5
And still others just shit the bed at the idea that you might read an email like this one:
Outlook 365 does appallingly badly, showing the subject in the title bar, then the words “(No subject)”, then the message “This message might have been removed or deleted”. Just
great.
That’s just the clients I’ve tested, but I can’t imagine that others are much different. If you give it a go yourself with something I’ve not tried, then let me know!
I guess this means that standardised multilingual emails might be forever resigned to the “nice to have but it never took off so we went in a different direction” corner of the
Internet, along with the <keygen> HTML element and the concept of privacy.
Footnotes
1 I didn’t receive quite as much bilingual email as you might expect, given that the
University committed to delivering most of its correspondence in both English and Welsh. But I received a lot more than I do nowadays, for example
2 Although you might not guess it, given how many websites completely ignore your
Accept-Language header, even where it’s provided, and simply try to “guess” what language you want using IP geolocation or something, and then require that you find
whatever shitty bit of UI they’ve hidden their language selector behind if you want to change it, storing the result in a cookie so it inevitably gets lost and has to be set again the
next time you visit.
3 I suppose that if you were sending HTML emails then you might use the lang="..." attribute to mark up different parts of the message as being in different
languages. But that doesn’t solve all of the problems, and introduces a couple of fresh ones.
4 If it were a cool new CSS feature, you can guarantee that it’d be supported by every
major browser (except probably Safari) by now. But email doesn’t get so much love as the Web, sadly.
5 Worse yet, if you’re using ProtonMail with a third-party client, ProtonMail screws up
RFC8255 emails so badly that they don’t even work properly in e.g. NeoMutt any more! ProtonMail swaps the multipart/multilingual content type for
multipart/mixed and strips the Content-Language: headers, making the entire email objectively less-useful.
If you’re active in the WordPress space you’re probably aware that there’s a lot of drama going on right now between (a) WordPress hosting company WP Engine, (b) WordPress
hosting company (among quiteafewotherthings) Automattic1,
and (c) the WordPress Foundation.
If you’re not aware then, well: do a search across the tech news media to see the latest: any summary I could give you would be out-of-date by the time you read it anyway!
I tried to draw a better diagram with more of the relevant connections, but it quickly turned into spaghetti.
In particular, I think a lot of the conversation that he kicked off conflates three different aspects of WP Engine’s misbehaviour. That muddies the waters when it comes to
having a reasoned conversation about the issue3.
I’ve heard Matt speak a number of times, including in person… and I think he did a pretty bad job of expressing the problems with WP Engine during his Q&A at WCUS. In his defence,
it sounds like he may have been still trying to negotiate a better way forward until the very second he walked on stage that day.
I don’t think WP Engine is a particularly good company, and I personally wouldn’t use them for WordPress hosting. That’s not a new opinion for me: I wouldn’t have used them last year or
the year before, or the year before that either. And I broadly agree with what I think Matt tried to say, although not necessarily with the way he said it or the platform he
chose to say it upon.
Misdeeds
As I see it, WP Engine’s potential misdeeds fall into three distinct categories: moral, ethical4,
and legal.
Morally: don’t take without giving back
Matt observes that since WP Engine’s acquisition by huge tech-company-investor Silver Lake, WP Engine have made enormous profits from selling WordPress hosting as a service (and nothing else) while
making minimal to no contributions back to the open source platform that they depend upon.
If true, and it appears to be, this would violate the principle of reciprocity. If you benefit from somebody else’s
effort (and you’re able to) you’re morally-obliged to at least offer to give back in a manner commensurate to your relative level of resources.
The principle of reciprocity is a moral staple. This is evidenced by the fact that children (and some nonhuman animals) seem to be able to work it out for themselves
from first principles using nothing more than empathy. Companies, however aren’t usually so-capable. Photo courtesy Cotton.
Abuse of this principle is… sadly not-uncommon in business. Or in tech. Or in the world in general. A lightweight example might be the many millions of profitable companies that host
atop the Apache HTTP Server without donating a penny to the Apache Foundation. A heavier (and legally-backed) example might be Trump Social’s
implementation being based on a modified version of Mastodon’s code:
Mastodon’s license requires that their changes are shared publicly… but they don’t do until they’re sent threatening letters reminding them of their obligations.
I feel like it’s fair game to call out companies that act amorally, and encourage people to boycott them, so long as you do so without “punching down”.
Ethically: don’t exploit open source’s liberties as weaknesses
WP Engine also stand accused of altering the open source code that they host in ways that maximise their profit, to the detriment of both their customers and the original authors of
that code5.
It’s well established, for example, that WP Engine disable the “revisions” feature of WordPress6.
Personally, I don’t feel like this is as big a deal as Matt makes out that it is (I certainly wouldn’t go as far as saying “WP
Engine is not WordPress”): it’s pretty commonplace for large hosting companies to tweak the open source software that they host to better fit their architecture and business model.
But I agree that it does make WordPress as-provided by WP Engine significantly less good than would be expected from virtually any other host (most of which, by the way, provide much
better value-for-money at any price point).
There’s nothing to stop me from registering TurdPress.com and providing a premium WordPress web hosting solution with all the best features disabled: I could even disable
exports so that my customers wouldn’t even be able to easily leave my service for greener pastures! There’s nothing stop me… but that wouldn’t make it
right7.
It also looks like WP Engine may have made more-nefarious changes, e.g. modifying the referral links in open source code (the thing that earns money for the original authors of
that code) so that WP Engine can collect the revenue themselves when they deploy that code to their customers’ sites. That to me feels like it’s clearly into the zone ethical bad
practice. Within the open source community, it’s not okay to take somebody’s code, which they were kind enough to release under a liberal license, strip out the bits that provide
their income, and redistribute it, even just as a network service8.
Again, I think this is fair game to call out, even if it’s not something that anybody has a right to enforce legally. On which note…
Obviously, this is the part of the story you’re going to see the most news media about, because there’s reasonable odds it’ll end up in front of a judge at some point. There’s a good
chance that such a case might revolve around WP Engine’s willingness (and encouragement?) to allow their business to be called “WordPress Engine” and to capitalise on any confusion that
causes.
I’m not going to weigh in on the specifics of the legal case: I Am Not A Lawyer and all that. Naturally I agree with the underlying principle that one should not be allowed to profit
off another’s intellectual property, but I’ll leave discussion on whether or not that’s what WP Engine are doing as a conversation for folks with more legal-smarts than I. I’ve
certainly known people be confused by WP Engine’s name and branding, though, and think that they must be some kind of “officially-licensed” WordPress host: it happens.
If you’re following all of this drama as it unfolds… just remember to check your sources. There’s a lot of FUD floating around on the Internet right now9.
In summary…
With a reminder that I’m sharing my own opinion here and not that of my employer, here’s my thoughts on the recent WP Engine drama:
WP Engine certainly act in ways that are unethical and immoral and antithetical to the spirit of open source, and those are just a subset of the reasons that I wouldn’t use them as
a WordPress host.
Matt Mullenweg calling them out at WordCamp US doesn’t get his point across as well as I think he hoped it might, and probably won’t win him any popularity contests.
I’m not qualified to weigh in on whether or not WP Engine have violated the WordPress Foundation’s trademarks, but I suspect that they’ve benefitted from widespread confusion about
their status.
Footnotes
1 I suppose I ought to point out that Automattic is my employer, in case you didn’t know,
and point out that my opinions don’t necessarily represent theirs, etc. I’ve been involved with WordPress as an open source project for about four times as long as I’ve had any
connection to Automattic, though, and don’t always agree with them, so I’d hope that it’s a given that I’m speaking my own mind!
2 Though like Manu, I don’t
think that means that Matt should take the corresponding blog post down: I’m a digital preservationist, as might be evidenced by the unrepresentative-of-me and frankly embarrassing
things in the 25-year archives of this blog!
3 Fortunately the documents that the lawyers for both sides have been writing are much
clearer and more-specific, but that’s what you pay lawyers for, right?
4 There’s a huge amount of debate about the difference between morality and ethics, but
I’m using the definition that means that morality is based on what a social animal might be expected to decide for themselves is right, think e.g. the Golden Rule etc., whereas ethics is the code of conduct expected within a particular community. Take stealing, for example,
which covers the spectrum: that you shouldn’t deprive somebody else of something they need, is a moral issue; that we as a society deem such behaviour worthy of exclusion is an
ethical one; meanwhile the action of incarcerating burglars is part of our legal framework.
5 Not that nobody’s immune to making ethical mistakes. Not me, not you, not anybody else.
I remember when, back in 2005, Matt fucked up by injecting ads into WordPress (which at that point didn’t have a reliable source of
funding). But he did the right thing by backpedalling, undoing the harm, and apologising publicly and profusely.
6 WP Engine claim that they disable revisions for performance reasons, but that’s clearly
bullshit: it’s pretty obvious to me that this is about making hosting cheaper. Enabling revisions doesn’t have a performance impact on a properly-configured multisite hosting system,
and I know this from personal experience of running such things. But it does have a significant impact on how much space you need to allocate to your users, which has cost
implications at scale.
7 As an aside: if a court does rule that WP Engine is infringing upon
WordPress trademarks and they want a new company name to give their service a fresh start, they’re welcome to TurdPress.
8 I’d argue that it is okay to do so for personal-use though: the difference for
me comes when you’re making a profit off of it. It’s interesting to find these edge-cases in my own thinking!
9 A typical Reddit thread is about 25% lies-and-bullshit; but you can double that for a
typical thread talking about this topic!
Dungeons & Dragons players spend a lot of time rolling 20-sided polyhedral dice, known as D20s.
In general, they’re looking to roll as high as possible to successfully stab a wyvern, jump a chasm, pick a lock, charm a Duke1,
or whatever.
Submerging your dice set in the blood of a halfling is a sure-fire way to get luckier rolls.
Roll with advantage
Sometimes, a player gets to roll with advantage. In this case, the player rolls two dice, and takes the higher roll. This really boosts their chances of not-getting a
low roll. Do you know by how much?
I dreamed about this very question last night. And then, still in my dream, I came up with the answer2.
I woke up thinking about it3
and checked my working.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
2
2
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
3
3
3
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
4
4
4
4
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
5
5
5
5
5
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
6
6
6
6
6
6
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
7
7
7
7
7
7
7
7
8
9
10
11
12
13
14
15
16
17
18
19
20
8
8
8
8
8
8
8
8
8
9
10
11
12
13
14
15
16
17
18
19
20
9
9
9
9
9
9
9
9
9
9
10
11
12
13
14
15
16
17
18
19
20
10
10
10
10
10
10
10
10
10
10
10
11
12
13
14
15
16
17
18
19
20
11
11
11
11
11
11
11
11
11
11
11
11
12
13
14
15
16
17
18
19
20
12
12
12
12
12
12
12
12
12
12
12
12
12
13
14
15
16
17
18
19
20
13
13
13
13
13
13
13
13
13
13
13
13
13
13
14
15
16
17
18
19
20
14
14
14
14
14
14
14
14
14
14
14
14
14
14
14
15
16
17
18
19
20
15
15
15
15
15
15
15
15
15
15
15
15
15
15
15
15
16
17
18
19
20
16
16
16
16
16
16
16
16
16
16
16
16
16
16
16
16
16
17
18
19
20
17
17
17
17
17
17
17
17
17
17
17
17
17
17
17
17
17
17
18
19
20
18
18
18
18
18
18
18
18
18
18
18
18
18
18
18
18
18
18
18
19
20
19
19
19
19
19
19
19
19
19
19
19
19
19
19
19
19
19
19
19
19
20
20
20
20
20
20
20
20
20
20
20
20
20
20
20
20
20
20
20
20
20
20
Table illustrating the different permutations of two D20 rolls and the “advantage” result (i.e. the higher of the two).
The chance of getting a “natural 1” result on a D20 is 1 in 20… but when you roll with advantage, that goes down to 1 in 400: a huge improvement! The chance of rolling a 10 or 11 (2 in
20 chance of one or the other) remains the same. And the chance of a “crit” – 20 – goes up from 1 in 20 when rolling a single D20 to 39 in 400 – almost 10% – when rolling with
advantage.
You can see that in the table above: the headers along the top and left are the natural rolls, the intersections are the resulting values – the higher of the two.
The nice thing about the table above (which again: was how I visualised the question in my dream!) is it really helps to visualise why these numbers are what they are. The
general formula for calculating the chance of a given number when rolling D20 with advantage is ( n2 – (n-1)2 ) / 400. That is, the square of the number
you’re looking for, minus the square of the number one less than that, over 400 (the total number of permutations)4.
Why roll two dice when one massive one will do?
Knowing the probability matrix, it’s theoretically possible to construct a “D20 with Advantage” die5. Such a tool would
have 400 sides (one 1, three 2s, five 3s… and thirty-nine 20s). Rolling-with-advantage would be a single roll.
I don’t think anybody’s ever built a real 400-sided die, but Numberwang! claimed to have one.
This is probably a totally academic exercise. The only conceivable reason I can think of would be if you were implementing a computer system on which generating random numbers
was computationally-expensive, but memory was cheap: under this circumstance, you could pre-generate a 400-item array of possible results and randomly select from it.
But if anybody’s got a 3D printer capable of making a large tetrahectogon (yes, that’s what you call a 400-sided polygon – you learned something today!), I’d love to see an “Advantage
D20” in the flesh. Or if you’d just like to implement a 3D model for Dice Box that’d be fine too!
Footnotes
1 Or throw a fireball, recall an anecdote, navigate a rainforest, survive a poisoning,
sneak past a troll, swim through a magical swamp, hold on to a speeding aurochs, disarm a tripwire, fire a crossbow, mix a potion, appeal to one among a pantheon of gods, beat the
inn’s landlord at an arm-wrestling match, seduce a duergar guard, persuade a talking squirrel to spy on some bandits, hold open a heavy door, determine the nature of a curse, follow a
trail of blood, find a long-lost tome, win a drinking competition, pickpocket a sleeping ogre, bury a magic sword so deep that nobody will ever find it, pilot a spacefaring rowboat,
interpret a forgotten language, notice an imminent ambush, telepathically commune with a distant friend, accurately copy-out an ancient manuscript, perform a religious ritual, find
the secret button under the wizard’s desk, survive the blistering cold, entertain a gang of street urchins, push through a force field, resist mind control, and then compose a ballad
celebrating your adventure.
2 I don’t know what it says about me as a human being that sometimes I dream in
mathematics, but it perhaps shouldn’t be surprising given I’m nerdy enough to have previously recorded instances of dreaming in (a) Perl, and (b) Nethack (terminal mode).
3 When I woke up I also found that I had One Jump from Disney’s Aladdin stuck in my head, but I’m not
sure that’s relevant to the discussion of probability; however, it might still be a reasonable indicator of my mental state in general.
4 An alternative formula which is easier to read but harder to explain would be ( 2(n
– 1) + 1 ) / 400.
5 Or a “D20 with Disadvantage”: the table’s basically the inverse of the advantage one –
i.e. 1 in 400 chance of a 20 through to 39 in 400 chance of a 1.
I’m a big fan of blocking out uninterrupted time on your work calendar for focus activities, even if you don’t have a specific focus task to fill them with.
It can be enough to simple know that, for example, you’ve got a 2-hour slot every Friday morning that you can dedicate to whatever focus-demanding task you’ve got that week, whether
it’s a deep debugging session, self-guided training and development activities, or finally finishing that paper that’s just slightly lower priority than everything else on your
plate.
My work focus time is Friday mornings. It was originally put there so that it immediately followed my approximately-monthly coaching sessions, but it’s remained even since they
wandered elsewhere.
I appreciate that my colleagues respect that blocked period: I almost never receive meeting requests in that time. That’s probably because most people, particularly because we’re in
such a multi-timezone company, use their calendar’s “find a
suitable time for everybody” tool to find the best time for everyone and it sees that I’m “busy” and doesn’t suggest it.
If somebody does schedule a meeting that clashes with that block then, well, it’s probably pretty urgent!
But it turns out this strategy doesn’t work for everybody:
‘Urgent meetings only’ might not mean the same thing to you and I as it does to the not one, not two, not three, but four people who scheduled meetings that clash with it.
My partner recently showed me a portion of her calendar, observing that her scheduled focus time had been
overshadowed by four subsequently-created meetings that clashed with it. Four!
Maybe that’s an exception and this particular occasion really did call for a stack of back-to-back urgent meetings. Maybe everything was on fire. But whether or not this
particular occasion is representative for my partner, I’ve spoken to other friends who express the same experience: if they block out explicit non-meeting time on their
calendar, they get meeting requests for that time anyway. At many employers, “focus time” activities don’t seem to be widely-respected.
Maybe your workplace is the same. The correct solution probably involves a cultural shift: a company-wide declaration in favour of focus time as a valuable productivity tool
(which it is), possibly coupled with recommendations about how to schedule them sensitively, e.g. perhaps recommending a couple of periods in which they ought to be scheduled.
But for a moment, let’s consider a different option:
A silly solution?
Does your work culture doesn’t respect scheduled focus time but does respect scheduled meetings? This might seem to be the case in the picture above: note that the meetings
that clash with the focus time don’t clash with one another but tessellate nicely. Perhaps you need… fake meetings.
“Wow, what a busy afternoon Dan’s got. I’d better leave him be.”
Of course, creating fake meetings just so you can get some work done is actually creating more work. Wouldn’t it be better if there were some kind of service that could do it
for you?
Here’s the idea: a web service that exposes an API endpoint. You start by specifying a few things about the calendar you’d like to fill, for example:
What days/times you’d like to fill with “focus time”?
What industry you work in, to help making convincing (but generic) event names?
Whether you’d like the entire block consistently filled, or occasional small-but-useless gaps of up to 15 minutes inserted between them?
This results in a URL containing those parameters. Accessing that URL yields an iCalendar feed
containing those meetings. All you need to do is get your calendar software to subscribe to those events and they’ll appear in your calendar, “filling” your time.
So long as your iCalendar feed subscription refreshes often enough, you could even have an option to enable the events to self-delete e.g. 15 minutes before their start time, so that
you don’t panic when your meeting notification pops up right before they “start”!
This is the bit where you’re expecting me to tell you I made a thing
Normally, you’d expect me to pull the covers off some hilarious domain name I’ve chosen and reveal exactly the service I describe, but I’m not doing that today. There’s a few reasons
for that:
I’m not saying I think the prior art in this area is good, but it’s certainly good-enough.
Firstly, I’ve got enough too many pointless personal/side projects on the go already1. I don’t need another
distraction.
Secondly, it turns out others have already done 90% of the work. This
open-source project runs locally and fills calendars with (unnamed, private) blocks of varying lengths. This iOS app
does almost exactly what I described, albeit in an ad-hoc rather than fully-automated way. There’s no point me just doing the last 10% just to make a joke work.
And thirdly: while I searched for existing tools I discovered a significant number of people who confess online to creating fake meetings in their calendars! While some of these do
so for reasons like those I describe – i.e. to block out time and get more work done in an environment that doesn’t respect them simply blocking-out time – a lot of folks admit to doing
it just to “look busy”. That could be either the employee slacking off, or perhaps having to work around a manager with a presenteeism/input-measurement based outlook (which is a
terrible way to manage people). But either way: it’s a depressing reason to write software.
Nope
So yeah: I’m not going down that avenue.
But maybe if you’re in a field where you’d benefit from it, try blocking out some focus time in your calendar. I think it’s a fantastic idea, and I love that I’m employed somewhere that
I can do so and it works out.
Or if you’ve tried that and discovered that your workplace culture doesn’t respect it – if colleagues routinely book meetings into reserved spaces – maybe you should try fake
meetings and see if they’re any better-respected. But I’m afraid I can’t help you with that.
Three Rings operates a Web contact form to help people get in touch with us: the idea
is that it provides a quick and easy way to reach out if you’re a charity who might be able to make use of the system, a user who’s having difficulty with the features of the software,
or maybe a potential new volunteer willing to give your time to the project.
But then the volume of spam it received increased dramatically. We don’t want our support team volunteers to spend all
their time categorising spam: even if it doesn’t take long, it’s demoralising. So what could we do?
It’s clearly spam, but if it takes you 2 seconds to categorise it and there are 30 in your Inbox, that’s still a drag.
Our conventional antispam tools are configured pretty liberally: we don’t want to reject a contact from a legitimate user just because their message hits lots of scammy keywords (e.g.
if a user’s having difficulty logging in and has copy-pasted all of the error messages they received, that can look a lot like a password reset spoofing scam to a spam filter). And we
don’t want to add a CAPTCHA, because not only do those create a barrier to humans – while not necessarily reducing spam very much, nowadays – they’re often terrible for accessibility,
privacy, or both.
But it didn’t take much analysis to spot some patterns unique to our contact form and the questions it asks that might provide an opportunity. For example, we discovered that
spam messages would more-often-than-average:
Fill in both the “name” and (optional) “Three Rings username” field with the same value. While it’s cetainly possible for Three Rings users to have
a login username that’s identical to their name, it’s very rare. But automated form-fillers seem to disproportionately pair-up these two fields.
Fill the phone number field with a known-fake phone number or a non-internationalised phone number from a country in which we currently support no charities.
Legitimate non-UK contacts tend to put international-format phone numbers into this optional field, if they fill it at all. Spammers often put NANP (North American Numbering Plan)
numbers.
Include many links in the body of the message. A few links, especially if they’re to our services (e.g. when people are asking for help) is not-uncommon in legitimate
messages. Many links, few of which point to our servers, almost certainly means spam.
Choose the first option for the choose -one question “how can we help you?” Of course real humans sometimes pick this option too, but spammers almost always
choose it.
None of these characteristics alone, or any of the half dozen or so others we analysed (including invisible checks like honeypots and IP-based geofencing), are reason to
suspect a message of being spam. But taken together, they’re almost a sure thing.
To begin with, we assigned scores to each characteristic and automated the tagging of messages in our ticketing system with these scores. At this point, we didn’t do anything to block
such messages: we were just collecting data. Over time, this allowed us to find a safe “threshold” score above which a message was certainly spam.
Even when a message fails our customised spam checks, we only ‘soft-block’ it: telling the user their message was rejected and providing suggestions on working around that or emailing
us conventionally. Our experience shows that the spammers aren’t willing to work to overcome this additional hurdle, but on the very rare ocassion a human hits them, they are.
Once we’d found our threshold we were able to engage a soft-block of submissions that exceeded it, and immediately the volume of spam making it to the ticketing system dropped
considerably. Under 70 lines of PHP code (which sadly I can’t share with you) and we reduced our spam rate by over 80% while having, as far as we can see, no impact on the
false-positive rate.
Where conventional antispam solutions weren’t quite cutting it, implementing a few rules specific to our particular use-case made all the difference. Sometimes you’ve just got to roll
your sleeves up and look at the actual data you do/don’t want, and adapt your filters accordingly.
My life affords me less time for videogames than it used to, and so my tastes have changed accordingly:
I appreciate games that I can drop at a moment’s notice and pick up again some other time, without losing lots of progress1.
And if the game can remind me what it was I was trying to achieve when I come back… perhaps weeks or months later… that’s a bonus!
I’ve a reduced tolerance for dynamically-generated content (oh, you want me to fetch you another five nirnroot do you? – hard pass2):
if I might only get to throw 20 hours total at a game, I’d much prefer to spend that time exploring content deliberately and thoughtfully authored by a human.
And, y’know, it has to be fun. I rarely buy games on impulse anymore, and usually wait weeks or months after release dates even for titles I’ve been anticipating, to see
what the reviewers make of it.
That said, I’ve played three excellent videogames this year that I’d like to recommend to you (no spoilers):
Horizon: Forbidden West
I loved Horizon: Zero Dawn. Even if this review persuades you that you should play its sequel, Forbidden
West, you really oughta play Zero Dawn first3.
There’s a direct continuation of plot going on there that you’ll appreciate better that way. Also: Zero Dawn stands alone as a great game in its own right.
Horizon gives a lot to love, from a rich world and story, immersive environments, near-seamless loading, excellent voice acting, and a rewarding difficulty curve. But perhaps
all are second-place to what a kickass character the protagonist is.
The Horizon series tells the story of Aloy from her childhood onwards, growing up an outcast in a tribal society on a future Earth inhabited by robotic reimaginings of
creatures familiar to us today (albeit some of them extinct). Once relatively docile, a mysterious event known as the derangement, shortly before Aloy’s birth, made these
machines aggressive and dangerous, leading to a hostile world in which Aloy seeks to prove herself a worthy hunter to the tribe that cast her out.
All of which leads to a series of adventures that gradually explain the nature of the world and how it became that way, and provide a path by which Aloy can perhaps provide a brighter
future for humankind. It’s well-written and clever and you’ll fight and die over and over as you learn your way around the countless permutations of weapons, tools, traps, and
strategies that you’ll employ. But it’s the kind of learning curve that’s more rewarding than frustrating, and there are so many paths to victory that when I watch Ruth play she uses tactics that I’d never even conceived of.
Horizon: Forbidden West is like Zero Dawn but… more. More quests, more exploration, more machines, more characters, and more of the same story, answering questions
you might have found yourself thinking during the prequel. But it’s not just more-of-the-same.
Forbidden West is in some ways more-of-the-same, but it outgrows the mould of its predecessor, too. Faced with bigger challenges than she can take on by herself, Aloy comes to
assemble a team of trusted party members, and when you’re not out fighting giant robots or spelunking underwater caves or exploring the ruins of ancient San Francisco you’re working
alongside them, and that’s one of the places the game really shines. Your associates chatter to each other, grow and change, and each brings something special to the story that invites
you to care for each of them as individuals.
The musical score – cinematic in its scope – has been revamped too, and shows off its ability to adapt dynamically to different situations. Face off against one of the terrifying new
aquatic enemies and you’ll be treated to a nautical theme, for example. And the formulaic quests of the predecessor (get to the place, climb the thing…), which were already
fine, are riddled with new quirks and complexities to keep you thinking.
And finally: I love the game’s commitment to demonstrating the diversity of humanity: both speaking and background characters express a rarely-seen mixture of races, genders, and
sexualities, and the story sensitively and compassionately touches on issues of disability, neurodiversity, and transgender identity. It’s more presence than
representation (“Hey look, it’s Sappho and her friend!”), but it’s still much better than I’m used to seeing in major video game releases.
Thank Goodness You’re Here!
If ever I need to explain to an American colleague why that one time they visited London does not give them an understanding of what life is like in the North of England… this is the
videogame I’ll point them at.
Among the many language options available for the game are “English”, as you’d probably expect, and “Dialect”, which imposes a South Yorkshire accent to everything, as illustrated
here by the main menu.
A short, somewhat minigame-driven, absurd to the point of Monty Python-ism, wildly British comedy game, Thank Goodness You’re
Here! is a gem. It’s not challenging by any stretch of the imagination, but that only serves to turn focus even more on the weird and wonderful game world of Barnsworth (itself
clearly inspired by real-world Barnsley).
Playing a salesman sent to the town to meet the lord mayor, the player ends up stuck with nothing to do4,
and takes on a couple of dozen odd-jobs for the inhabitants of the town, meeting a mixed bag of stereotypes and tropes as they go along.
Ahm gowin t’shop to gi’ sumof Big Ron’s Big Pies! Y’wanout, buggerlugs? Players without a grounding in Yorkshire English, and especially non-Brits, might benefit from turning
the subtitles on.
Presented in a hand-drawn style that’s as distinctive and bizarre as it is an expression of the effort that must’ve gone into it, this game’s clearly a project of passion for
Yorkshire-based developers Coal Supper (yes, that’s really what they call themselves). I particularly enjoyed a recurring joke in which the
player is performing some chore (mowing grass for the park keeper, chopping spuds at the chippy) when the scene cuts to some typically-inanimate objects having a conversation (flowers,
potatoes) while the player’s actions bring them closer and closer in the background. But it’s hard to pick out a very favourite part from this wonderful, crazy, self-aware slice of
Northern life in game form.
Tactical Breach Wizards
Finally, I’ve got to sing the praises of Tactical Breach Wizards by Suspicious
Developments (who for some reason don’t bother to list it on their website; the closest thing to an official page for the project other than its Steam entry might be this launch announcement!)5, the
team behind Gunpoint and Heat Signature.
The game feels like a cross between XCOM/Xenonauts‘ turn-based tactical combat and Rainbow Six‘s special ops theme. Except instead of a squad of gun-toting
body-armoured military/police types, your squad is a team of wizards in a world in which magical combat specialists work alongside conventionally-equipped soldiers on missions where
their powers make all the difference.
Jen the Storm Witch primarily uses large static shocks to fling targets around: relatively harmless, unless she and her teammates have arranged for/tricked enemies to be standing next
to something they can be thrown into… or near a window they can be flung out of!
By itself, that could be enough: there’s certainly sufficient differences between all of the powers that the magic users exploit that you’ll find all kinds of ways to combine them. How
about having your teleport-capable medic blink themselves to a corner so your witch’s multi-step lightning bolt can use them as a channel to get around a corner and zap a target there?
Or what about using the time-manipulation powers of your Navy Seer (yes, really) to give your siege cleric enough actions that they can shield-push your opponent within range of the
turret you hacked? And so on.
But Tactical Breach Wizards, which stands somewhere between a tactical squad-based shooter and a deterministic positional puzzle game, goes beyond that by virtue of its
storytelling. Despite the limitations of the format, the game manages to pack in a lot of background and personality for every one of your team and even many of the NPCs too (Steve Clark, Traffic Warlock is a riot). Oh, and much of the dialogue is laugh-out-loud funny, to boot.
The dialogue between your teammates – most of it right as they’re about to breach a door – reads like lighthearted banter but exposes the underpinning backstory of the setting.
The writing’s great, to the extent that when I got to the epilogue – interactive segments during the credits where you can influence “what happens next” to each of the characters you’ve
come to know – I genuinely flip-flopped on a few of them to give some of them a greater opportunity to continue to feature in one another’s lives. Even though the game was clearly over.
It’s that compelling.
And puzzling out some of the tougher levels, especially if you’re going for the advanced (“Confidence”) challenges, too, is really fun. But with autosaves every turn, the opportunity to
skip and return to levels that are too challenging, and a within-turn “undo” feature that lets you explore different strategies before you commit to one, this is a great game for
someone who, like me, doesn’t have much time to dedicate to play.
So yeah: that’s what I’ve been up to in videogaming-time so far this year. Any suggestions for the autumn/winter?
Footnotes
1 If a game loads quickly that’s a bonus. I still play a little of my favourite variant of
the Sid Meier’s Civilization series – that is, Civilization V + Vox Populi (alongside a few quality-of-life mods) but I swear I’d play
more of it if it didn’t take so long to load. Even after hacking around it to dodge the launcher, logos, and introduction, my 8P+4E-core i7 processor takes ~80 seconds from clicking
to launch the game to having loaded my latest save, which if I’m only going to have time to play three turns is frustratingly long! Contrast Horizon: Forbidden West, which I
also mention in this post, a game 13 years younger and with much higher hardware requirements, which takes ~17 seconds to achieve the same. Possibly I’m overanalysing this…
2 This isn’t a criticism of the Elder Scrolls games specifically, but of the
relatively-lazy writing that goes into some videogames that feel like they’re using Perchance to come up with their quests, in order to stretch
the gameplay. I suppose a better example might have been the on-the-whole disappointment that was Starfield, but I figured an Elder Scrolls reference might be easier
to identify at-a-glance. Fetch-questing 100 tonnes of Beryllium just doesn’t have the same ring to it.
3 In fact, if you’re trying to consume the Horizon story as thoroughly as
possible and strictly in chronological order, you probably should read the graphic novel between one and the other, which covers some of the events that occur between the two.
4 Did you ever see the alternate ending to Far Cry 4, by the way? If you
did, you might appreciate that a similar trick can be used to shortcut Thank Goodness You’re Here! too…
5 They’re also missing a trick by using the domain they’ve registered,
wizards.cool, only to redirect to Steam.
Like my occasional video content, this isn’t designed to replace any of my blogging: it’s just a different medium for those that might prefer it.
For some stories, I guess that audio might be a better way to find out what I’ve been thinking about. Just like how the vlog version of my post about
my favourite video game Easter Egg might be preferable because video as a medium is better suited to demonstrating a computer game, perhaps
audio’s the right medium for some of the things I write about, too?
But as much as not, it’s just a continuation of my efforts to explore different media over which a WordPress blog can be delivered2.
Also, y’know, my ongoing effort to do what I’m bad at in the hope that I might get better at a wider diversity of skills.
How?
Let’s start by understanding what a “podcast” actually is. It is, in essence, just an RSS feed (something you might have heard me talk about before…) with audio enclosures – basically, “attachments” – on each item. The idea was spearheaded by Dave Winer back in 2001 as a
way of subscribing to rich media like audio or videos in such a way that slow Internet connections could pre-download content so you didn’t have to wait for it to buffer.3
Podcasts are pretty simple, even after you’ve bent over backwards to add all of the metadata that Apple Podcasts (formerly iTunes) expects to see. I looked at a couple of
WordPress plugins that claimed to be able to do the work for me, but eventually decided it was simple enough to just add some custom metadata fields that could then be included in my
feeds and tweak my theme code a little.
Here’s what I had to do to add podcasting capability to my theme:
The tag
I use a post tag, dancast, to represent posts with accompanying podcast content4.
This way, I can add all the podcast-specific metadata only if the user requests the feed of that tag, and leave my regular feeds untampered . This means that you don’t
get the podcast enclosures in the regular subscription; that might not be what everybody would want, but it suits me to serve podcasts only to people who explicitly ask for
them.
Okay, onto the code (which I’ve open-sourced over here). I’ve use a series of standard WordPress hooks to
add the functionality I need. The important bits are:
rss2_item – to add the <enclosure>, <itunes:duration>, <itunes:image>, and
<itunes:explicit> elements to the feed, when requesting a feed with my nominated tag. Only <enclosure> is strictly required, but appeasing Apple
Podcasts is worthwhile too. These are lifted directly from the post metadata.
the_excerpt_rss – I have another piece of post metadata in which I can add a description of the podcast (in practice, a list of chapter times); this hook
swaps out the existing excerpt for my custom one in podcast feeds.
rss_enclosure – some podcast syndication platforms and players can’t cope with RSS feeds in which an item has multiple enclosures, so as a
safety precaution I strip out any enclosures that WordPress has already added (e.g. the featured image).
the_content_feed – my RSS feed usually contains the full text of every post, because I don’t like feeds that try to force you to go to the
original web page5
and I don’t want to impose that on others. But for the podcast feed, the text content of the post is somewhat redundant so I drop it.
rss2_ns – of critical importance of course is adding the relevant namespaces to your XML declaration. I use the itunes namespace, which provides the widest compatibility for specifying metadata, but I also use the
newer podcast namespace, which has growing compatibility and provides some modern features, most of which I don’t
use except specifying a license. There’s no harm in supporting both.
rss2_head – here’s where I put in the metadata for the podcast as a whole: license, category, type, and so on. Some of these fields are
effectively essential for best support.
You’re welcome, of course, to lift any of all of the code for your own purposes. WordPress makes a perfectly reasonable platform for podcasting-alongside-blogging, in my experience.
What?
Finally, there’s the question of what to podcast about.
My intention is to use podcasting as an alternative medium to my traditional blog posts. But not every blog post is suitable for conversion into a podcast! Ones that rely on images
(like my post about dithering) aren’t a great choice. Ones that have lots of code that you might like to copy-and-paste are especially unsuitable.
You’re listening to Radio Dan. 100% Dan, 100% of the time.(Also I suppose you might be able to hear my dog snoring in the background…)
Also: sometimes I just can’t be bothered. It’s already some level of effort to write a blog post; it’s like an extra 25% effort on top of that to record, edit, and upload a podcast
version of it.
That’s not nothing, so I’ve tended to reserve podcasts for blog posts that I think have a sort-of eccentric “general interest” vibe to them. When I learn something new and feel the need
to write a thousand words about it… that’s the kind of content that makes it into a podcast episode.
Which is why I’ve been calling the endeavour “a podcast nobody asked for, about things only Dan Q cares about”. I’m capable of getting nerdsniped
easily and can quickly find my way down a rabbit hole of learning. My podcast is, I guess, just a way of sharing my passion for trivial deep dives with the rest of the world.
My episodes are probably shorter than most podcasts: my longest so far is around fifteen minutes, but my shortest is only two and a half minutes and most are about seven. They’re meant
to be a bite-size alternative to reading a post for people who prefer to put things in their ears than into their eyes.
Anyway: if you’re not listening already, you can subscribe from here or in your favourite podcasting app. Or you can just follow my blog as normal
and look for a streamable copy of podcasts at the top of selected posts (like this one!).
2 As well as Web-based non-textual content like audio (podcasts) and video (vlogs), my blog is wholly or partially available over a variety of more-exotic protocols: did you find me yet on Gemini (gemini://danq.me/), Spartan (spartan://danq.me/), Gopher (gopher://danq.me/), and even Finger
(finger://danq.me/, or run e.g. finger blog@danq.me from your command line)? Most of these are powered by my very own tool CapsulePress, and I’m itching to try a few more… how about a WordPress blog that’s accessible over FTP, NNTP, or DNS? I’m not even kidding when I say
I’ve got ideas for these…
3 Nowadays, we have specialised media decoder co-processors which reduce the size of media
files. But more-importantly, today’s high-speed always-on Internet connections mean that you probably rarely need to make a conscious choice between streaming or downloading.
4 I actually intended to change the tag to podcast when I went-live,
but then I forgot, and now I can’t be bothered to change it. It’s only for my convenience, after all!
Last month I implemented an alternative mode to view this website “like it’s 1999”, complete with with cursor trails, 88×31 buttons, tables for
layout1,
tiled backgrounds, and even a (fake) hit counter.
One thing I’d have liked to do for 1999 Mode but didn’t get around to would have been to make the images look like it was the 90s, too.
Back then, many Web users only had graphics hardware capable of displaying 256 distinct colours. Across different platforms and operating systems, they weren’t even necessarily
the same 256 colours2!
But the early Web agreed on a 216-colour palette that all those 8-bit systems could at least approximate pretty well.
I had an idea that I could make my images look “216-colour”-ish by using CSS to apply an SVG filter, but didn’t implement it.
But Spencer, a long-running source of excellent blog comments, stepped up and wrote an SVG
filter for me! I’ve tweaked 1999 Mode already to use it… and I’ve just got to say it’s excellent: huge thanks, Spencer!
The filter coerces colours to their nearest colour in the “Web safe” palette, resulting in things like this:
The flat surfaces are particularly impacted in this photo (as manipulated by the CSS SVG filter described above). Subtle hues and the gradients coalesce into slabs of colour, giving
them an unnatural and blocky appearance.
Plenty of pictures genuinely looked like that on the Web of the 1990s, especially if you happened to be using a computer only capable of 8-bit colour to view a page built by
somebody who hadn’t realised that not everybody would experience 24-bit colour like they did3.
Dithering
But not all images in the “Web safe” palette looked like this, because savvy web developers knew to dither their images when converting them to a limited palette.
Let’s have another go:
This image uses exactly the same 216-bit colour palette as the previous one, but looks a lot more “natural” thanks to the Floyd–Steinberg dithering algorithm.
Dithering introduces random noise to media4
in order to reduce the likelihood that a “block” will all be rounded to the same value. Instead; in our picture, a block of what would otherwise be the same colour ends up being rounded
to maybe half a dozen different colours, clustered together such that the ratio in a given part of the picture is, on average, a better approximation of the correct
colour.
The result is analogous to how halftone printing – the aesthetic of old comics and newspapers, with different-sized dots made from
few colours of ink – produces the illusion of a continuous gradient of colour so long as you look at it from far-enough away.
Zooming in makes it easy to see the noisy “speckling” effect in the dithered version, but from a distance it’s almost invisible.
The other year I read a spectacular article by Surma that explained in a very-approachable way
how and why different dithering algorithms produce the results they do. If you’ve any interest whatsoever in a deep dive or just want to know what blue noise is and why you
should care, I’d highly recommend it.
You used to see digital dithering everywhere, but nowadays it’s so rare that it leaps out as a revolutionary aesthetic when, for example, it gets used in
a video game.
Dithering can be so effective that it can even make an image “work” all the way down to 1-bit (i.e. true monochrome/black-and-white) colour. Here I’ve used Jarvis, Judice & Ninke’s dithering algorithm, which is highly-effective for picking out subtle colour differences in what would
otherwise be extreme dark and light patches, at the expense of being more computationally-expensive (to initially create) than other dithering strategies.
All of which is to say that: I really appreciate Spencer’s work to make my “1999 Mode” impose a 216-colour palette on images. But while it’s closer to the truth, it still doesn’t
quite reflect what my website would’ve looked like in the 1990s because I made extensive use of dithering when I saved my images in Web safe palettes5.
Why did I take the time to dither my images, back in the day? Because doing the hard work once, as a creator of graphical Web pages, saves time and computation (and can look
better!), compared to making every single Web visitor’s browser do it every single time.
Which, now I think about it, is a lesson that’s still true today (I’m talking to you, developers who send a tonne of JavaScript and ask my browser to generate the HTML for you
rather than just sending me the HTML in the first place!).
Footnotes
1 Actually, my “1999 mode” doesn’t use tables for layout; it pretty much only applies a
CSS overlay, but it’s deliberately designed to look a lot like my blog did in 1999, which did use tables for layout. For those too young to remember: back before CSS
gave us the ability to lay out content in diverse ways, it was commonplace to use a table – often with the borders and cell-padding reduced to zero – to achieve things that today
would be simple, like putting a menu down the edge of a page or an image alongside some text content. Using tables for non-tabular data causes problems, though: not only is
it hard to make a usable responsive website with them, it also reduces the control you have over the order of the content, which upsets some kinds of accessibility
technologies. Oh, and it’s semantically-invalid, of course, to describe something as a table if it’s not.
2Perhaps as few as 22 colours were defined the same across all
widespread colour-capable Web systems. At first that sounds bad. Then you remember that 4-bit (16 colour) palettes used to look look perfectly fine in 90s videogames. But then you
realise that the specific 22 “very safe” colours are pretty shit and useless for rendering anything that isn’t composed of black, white, bright red, and maybe one of a few
greeny-yellows. Ugh. For your amusement, here’s a copy of the image rendered using only the “very safe” 22
colours.
3 Spencer’s SVG filter does pretty-much the same thing as a computer might if asked to
render a 24-bit colour image using only 8-bit colour. Simply “rounding” each pixel’s colour to the nearest available colour is a fast operation, even on older hardware and with larger
images.
4 Note that I didn’t say “images”: dithering is also used to produce the same “more
natural” feel for audio, too, when reducing its bitrate (i.e. reducing the number of finite states into which the waveform can be quantised for digitisation), for example.
5 I’m aware that my footnotes are capable of nerdsniping Spencer, so by writing this
there’s a risk that he’ll, y’know, find a way to express a dithering algorithm as an SVG filter too. Which I suspect isn’t possible, but who knows! 😅
We still didn’t feel up to a repeat of the bigger summer party we held the year before last, but we love our Abnib buddies, so put the call out to say: hey, come on over, bring a tent (or be willing to crash on a sofa bed) if you want to stay over; we’ll let the
kids run themselves ragged with a water fight and cricket and football and other garden games, then put them in front of a film or two while we hang out and drink and play board games
or something.
Every one of these people is awesome. Or else a dog.
The entire plan was deliberately low-effort. Drinks? We had a local brewery drop us off a couple of kegs, and encouraged people to BYOB. Food? We
threw a stack of pre-assembled snacks onto a table, and later in the day I rotated a dozen or so chilled pizzas through the oven. Entertainments? Give the kids a pile of toys and the
adults one another’s company.
We didn’t even do more than the bare minimum of tidying up the place before people arrived. Washing-up done? No major trip hazards on the floor? That’s plenty good enough!
The intersection of “BYOB” and the generosity of our friends somehow meant that, I reckon, we have more alcohol in the house now than before the party!
I found myself recalling our university days, when low-effort ad-hoc socialising seemed… easy. We lived close together and we had uncomplicated schedules, which combined to make it socially-acceptable to “just turn up” into one another’s lives and spaces. Many were the times that people would descend upon Claire and
I’s house in anticipation that there’d probably be a film night later, for example1.
I remember one occasion a couple of decades ago, chilling with friends2. Somebody – possibly Liz
– commented that it’d be great if in the years to come our kids would be able to be friends with one another. I was reminded of it when our eldest asked me, of our weekend
guests, “why are all of your friends’ children are so great?”
It’s not the same as those days long ago, but I’m not sure I’d want it to be. It is, however, fantastic.
What pleased me in particular was how relatively-effortless it was for us all to slip back into casually spending time together. With a group of folks who have, for the most part, all
known each other for over two decades, even not seeing one another in-person for a couple of years didn’t make a significant dent on our ability to find joy in each other’s company.
Plus, being composed of such laid-back folks, it didn’t feel awkward that we had, let’s face it, half-arsed the party. Minimal effort was the order of the day, but the flipside of that
was that the value-for-effort coefficient was pretty-well optimised3.
A delightful weekend that I was glad to be part of.
3 I’m pretty sure that if I’d have used the term “value-for-effort coefficient”
at the party, though, then it’d have immediately sucked 100% of the fun out of the room.
Why must a blog comment be text? Why could it not be… a drawing?1
Red and black might be more traditional ladybird colours, but sometimes all you’ve got is blue.
I started hacking about and playing with a few ideas and now, on selected posts including this one, you can draw me a comment instead of typing one.
Just don’t tell the soup company what I’ve been working on, okay?
I opened the feature, experimentally (in a post available only to RSS subscribers2) the
other week, but now you get a go! Also, I’ve open-sourced the whole thing, in case you want to pick it apart.
What are you waiting for: scroll down, and draw me a comment!
Footnotes
1 I totally know the reasons that a blog comment shouldn’t be a drawing; I’m not
completely oblivious. Firstly, it’s less-expressive: words are versatile and you can do a lot with them. Secondly, it’s higher-bandwidth: images take up more space, take longer to
transmit, and that effect compounds when – like me – you’re tracking animation data too. But the single biggest reason, and I can’t stress this enough, is… the
penises. If you invite people to draw pictures on your blog, you’re gonna see a lot of penises. Short penises, long penises, fat penises, thin penises. Penises of every shape
and size. Some erect and some flacid. Some intact and some circumcised. Some with hairy balls and some shaved. Many of them urinating or ejaculating. Maybe even a few with smiley
faces. And short of some kind of image-categorisation AI thing, you can’t realistically run an anti-spam tool to detect hand-drawn penises.
2 I’ve copied a few of my favourites of their drawings below. Don’t forget to subscribe if you want early access to any weird shit I make.
Subject Access Request – Dan Q, pupil Sep 1992 – Jun 1997
Date:
Tue, 23 Jul 2024 15:18:07 +0100
To Whom It May Concern,
Please supply the personal data you hold about me, per data protection law. Specifically, I’m looking for: a list of all offences for which I was assigned detention at
school.
Please find attached a variety of documentation which I feel proves my identity and the legitimacy of this request. If there’s anything else you need or you have further questions,
please feel free to email me.
Thanks in advance;
Dan Q
To:
“Dan Q” <***@danq.me>
From:
“Jodie Clayton” <*.*******@fulwoodacademy.co.uk>
Subject:
Re: Subject Access Request – Dan Q, pupil Sep 1992 – Jun 1997
Date:
Fri, 26 Jul 2024 10:48:33 +0100
Dear Dan Q,
We do not retain records of detentions of former pupils, and we certainly have no academic records of pupils going back thirty years ago.
Jodie Clayton | Office Manager with Cover and Admissions
Black Bull Lane, Fulwood, Preston, PR2 9YR
+44 (0) 1772 719060
To:
“Jodie Clayton” <*********@fulwoodacademy.co.uk>
From:
“Dan Q” <***@danq.me>
Subject:
Re: Subject Access Request – Dan Q, pupil Sep 1992 – Jun 1997
Date:
Fri, 26 Jul 2024 17:00:49 +0100
But, but… I was always told that this would go on my permanent record. Are you telling me that teachers lied to me? What else is fake!?
Maybe I will always have a calculator with me and I won’t actually need to know how to derive a square root using a pen and paper. Maybe nobody will ever care what
my GCSE results are for every job I apply for. Maybe my tongue isn’t divided into different
taste areas capable of picking out sweet, salty, bitter etc. flavours. Maybe practicing my handwriting won’t be an essential skill I use every day.
And maybe I will amount to something despite never turning in any History homework, Mr. Needham!












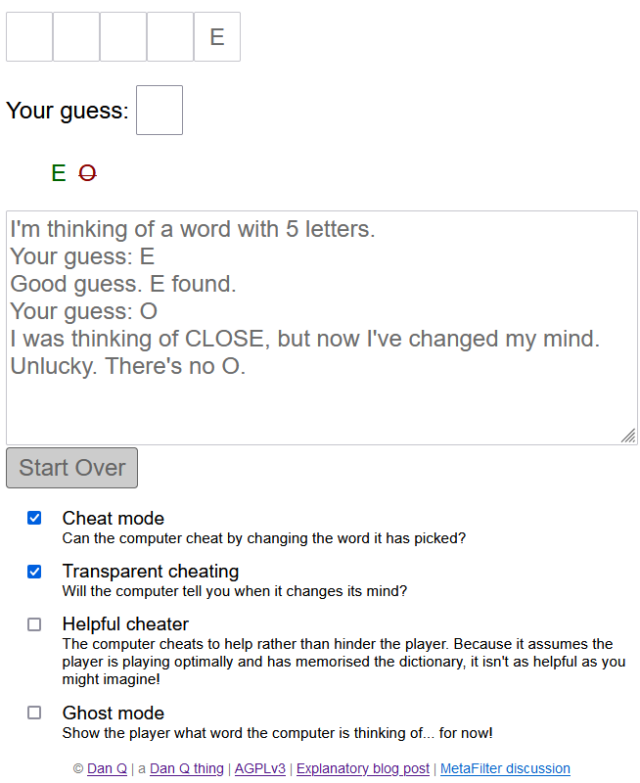


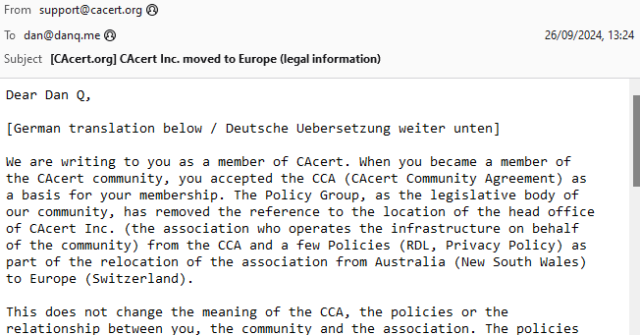
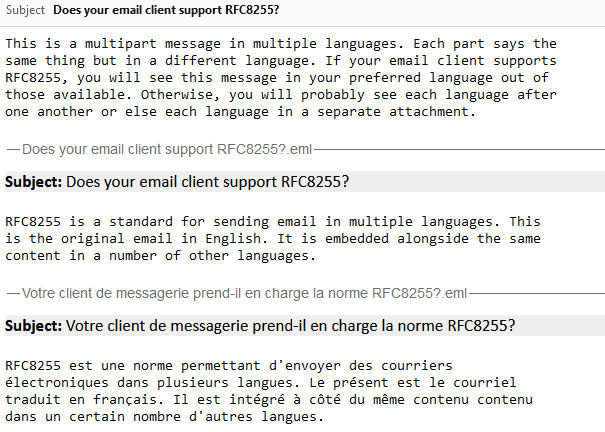
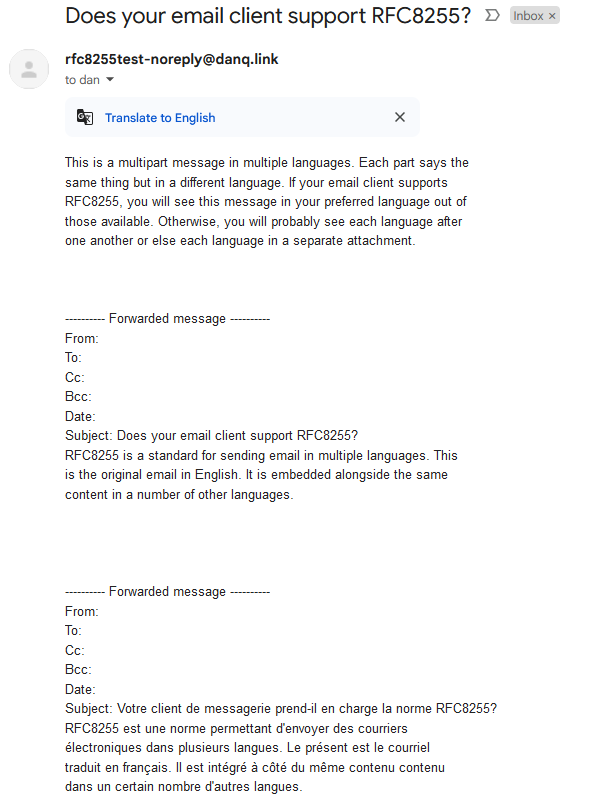
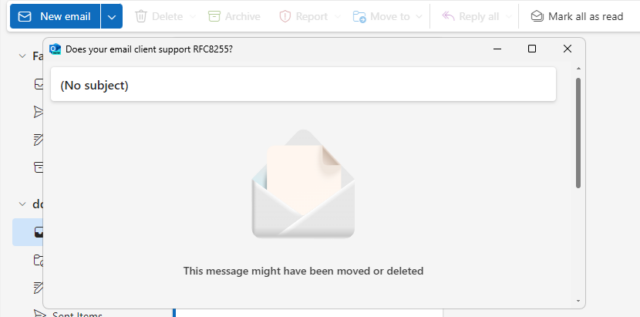
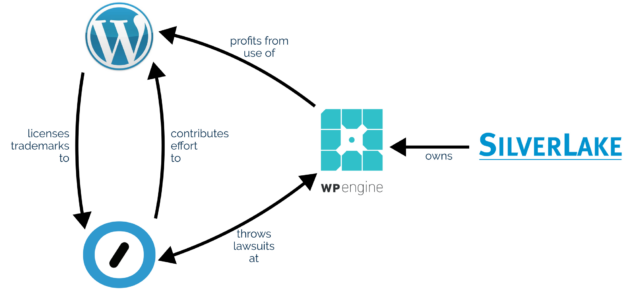


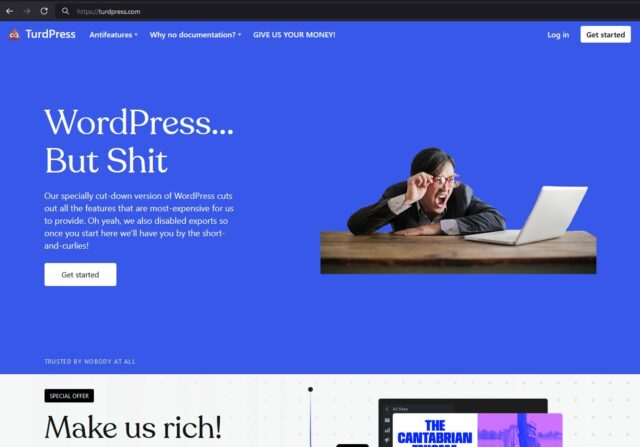
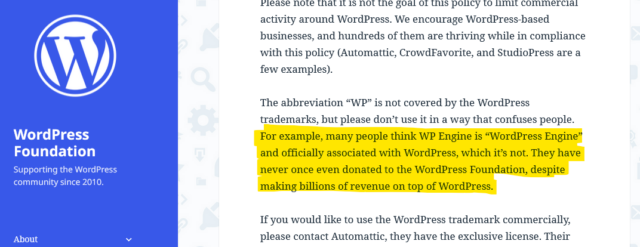


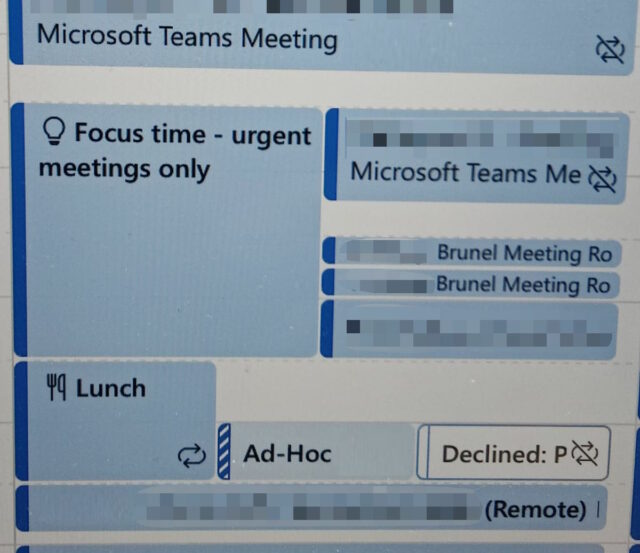


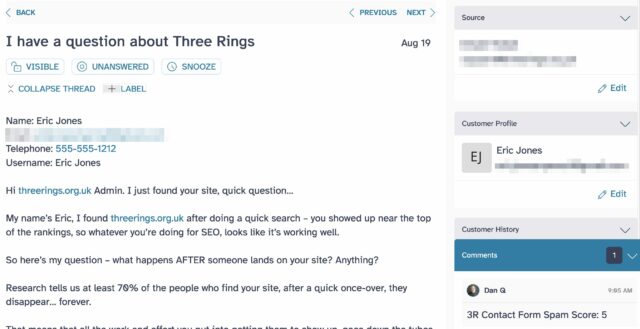







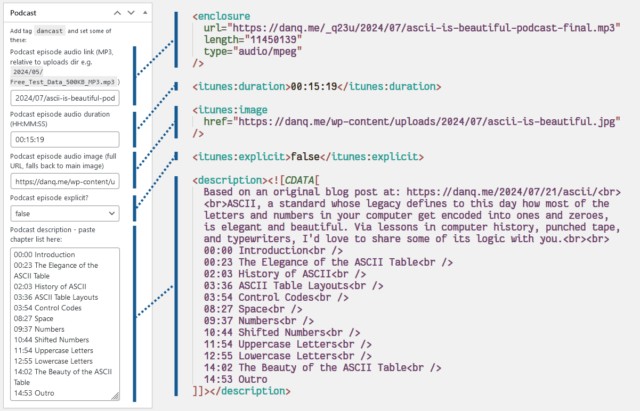




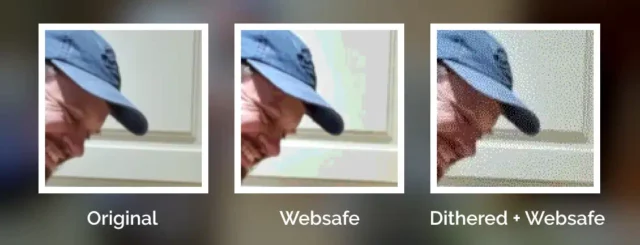





{kind=link}