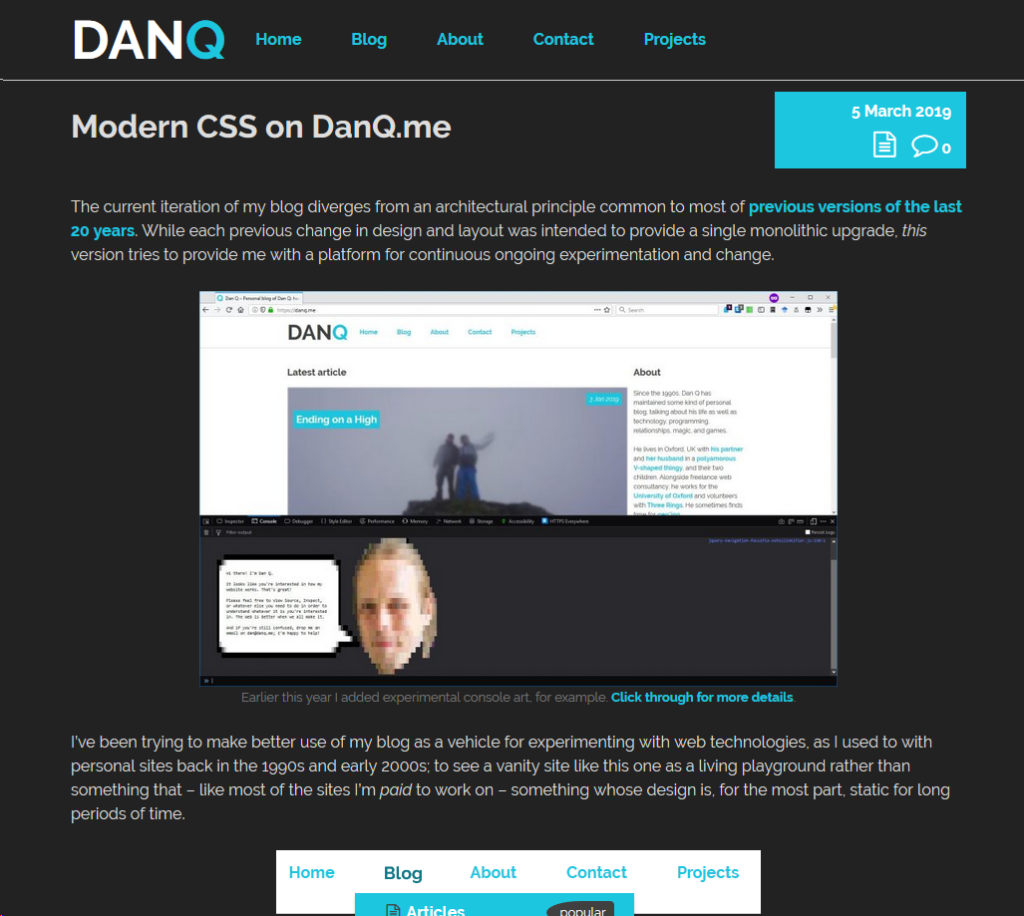
I’m a big believer in the idea that the hardware I lay my hands on all day, every day, needs to be the best for its purpose. On my primary desktop, I type on a Das Keyboard 4 Professional (with Cherry MX brown switches) because it looks, feels, and sounds spectacular. I use the Mac edition of the keyboard because it, coupled with a few tweaks, gives me the best combination of features and compatibility across all of the Windows, MacOS, and Linux (and occasionally other operating systems) I control with it. These things matter.

I also care about the mouse I use. Mice are, for the most part, for the Web and for gaming and not for use in most other applications (that’s what keyboard shortcuts are for!) but nonetheless I spend plenty of time holding one and so I want the tool that feels right to me. That’s why I was delighted when, in replacing my four year-old Logitech MX1000 in 2010 with my first Logitech Performance MX, I felt able to declare it the best mouse in the world. My Performance MX lived for about four years, too – that seems to be how long a mouse can stand the kind of use that I give it – before it started to fail and I opted to replace it with an identical make and model. I’d found “my” mouse, and I was sticking with it. It’s a great shape (if you’ve got larger hands), is full of features including highly-configurable buttons, vertical and horizontal scrolling (or whatever you want to map them to), and a cool “flywheel” mouse wheel that can be locked to regular operation or unlocked for controlled high-speed scrolling at the touch of a button: with practice, you can even use it as a speed control by gently depressing the switch like it was a brake pedal. Couple all of that with incredible accuracy on virtually any surface, long battery life, and charging “while you use” and you’ve a recipe for success, in my mind.
My second Performance MX stopped properly charging its battery this week, and it turns out that they don’t make them any more, so I bought its successor, the Logitech MX Master 2S.

The MX Master 2S is… different… from its predecessor. Mostly in good ways, sometimes less-good. Here’s the important differences:
- Matte coating: only the buttons are made of smooth plastic; the body of the mouse is now a slightly coarser plastic: you’ll see in the photo above how much less light it reflects. It feels like it would dissipate heat less-well.
- Horizontal wheel replaces rocker wheel: instead of the Performance MX’s “rocker” scroll wheel that can be pushed sideways for horizontal scroll, the MX Master 2S adds a dedicated horizontal scroll (or whatever you reconfigure it to) wheel in the thumb well. This is a welcome change: the rocker wheel in both my Performance MXes became less-effective over time and in older mice could even “jam on”, blocking the middle-click function. This seems like a far more-logical design.
- New back/forward button shape: to accommodate the horizontal wheel, the “back” and “forward” buttons in the thumb well have been made smaller and pushed closer together. This is the single biggest failing of the MX Master 2S: it’s clearly a mouse designed for larger hands, and yet these new buttons are slightly, but noticeably, harder to accurately trigger with a large thumb! It’s tolerable, but slightly annoying.
- Bluetooth support: one of my biggest gripes about the Performance MX was its dependence on Unifying, Logitech’s proprietary wireless protocol. The MX Master 2S supports Unifying but also supports Bluetooth, giving you the best of both worlds.
- Digital flywheel: the most-noticable change when using the mouse is the new flywheel and braking mechanism, which is comparable to the change in contemporary cars from a mechanical to a digital handbrake. The flywheel “lock” switch is now digital, turning on or off the brake in a single stroke and so depriving you of the satisfaction of using it to gradually “slow down” a long spin-scroll through an enormous log or source code file. But in exchange comes an awesome feature called SmartShift, which dynamically turns on or off the brake (y’know, like an automatic handbrake!) depending on the speed with which you throw the wheel. That’s clever and intuitive and “just works” far better than I’d have imagined: I can choose to scroll slowly or quickly, with or without the traditional ratchet “clicks” of a wheel mouse, with nothing more than the way I flick my finger (and all fully-configurable, of course). And I’ve still got the button to manually “toggle” the brake if I need it. It took some getting used to, but this change is actually really cool! (I’m yet to get used to the sound of the digital brake kicking in automatically, but that’s true of my car too).
- Basic KVM/multi-computing capability: with a button on the underside to toggle between different paired Unifying/Bluetooth transceivers and software support for seamless edge-of-desktop multi-computer operation, Logitech are clearly trying to target folks who, like me, routinely run multiple computers simultaneously from a single keyboard and mouse. But it’s a pointless addition in my case because I’ve been quite happy using Synergy to do this for the last 7+ years, which does it better. Still, it’s a harmless “bonus” feature and it might be of value to others, I suppose.
All in all, the MX Master 2S isn’t such an innovative leap forward over the Performance MX as the Performance MX was over the MX1000, but it’s still great that this spectacular series of heavyweight workhouse feature-rich mice continues to innovate and, for the most part, improve upon the formula. This mouse isn’t cheap, and it isn’t for everybody, but if you’re a big-handed power user with a need to fine-tune all your hands-on hardware to get it just right, it’s definitely worth a look.