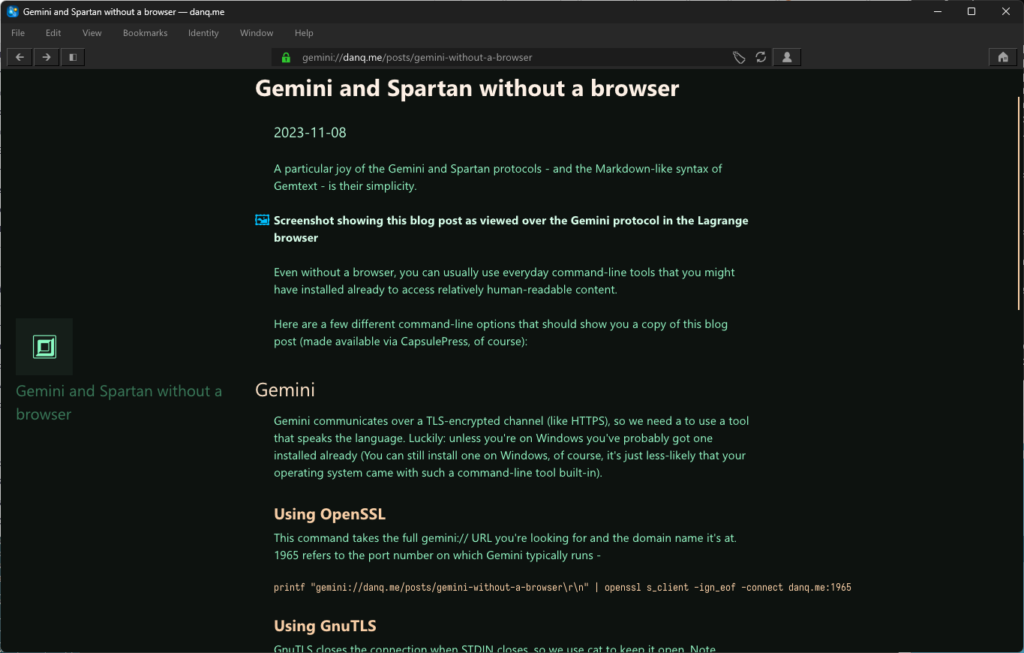
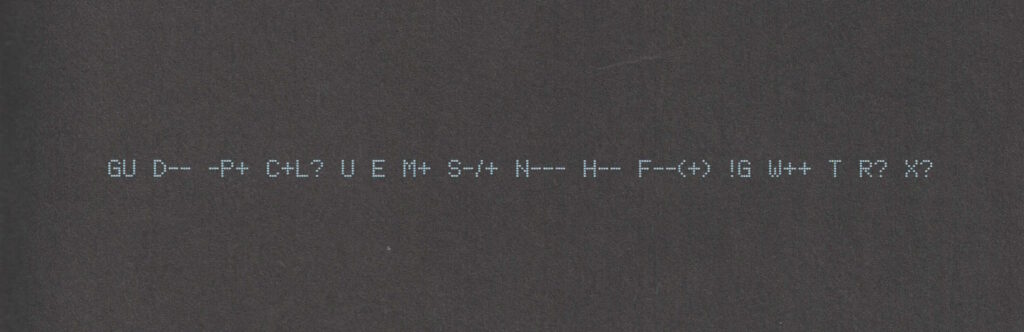A particular joy of the Gemini and Spartan protocols – and the Markdown-like syntax of Gemtext – is their simplicity.
The best way to explore Geminispace is with a browser like Lagrange browser, of course.
Even without a browser, you can usually use everyday command-line tools that you might have installed already to access relatively human-readable content.
Here are a few different command-line options that should show you a copy of this blog post (made available via CapsulePress, of course):
Gemini
Gemini communicates over a TLS-encrypted channel (like HTTPS), so we need a to use a tool that speaks the language. Luckily: unless you’re on Windows you’ve probably got one installed
already1.
Using OpenSSL
This command takes the full gemini:// URL you’re looking for and the domain name it’s at. 1965 refers to the port number on
which Gemini typically runs –
GnuTLS closes the connection when STDIN closes, so we use cat to keep it open. Note inclusion of --no-ca-verification to allow self-signed
certificates (optionally add --tofu for trust-on-first-use support, per the spec).
Spartan is a little like “Gemini without TLS“, but it sports an even-more-lightweight request format which makes it especially
easy to fudge requests2.
Using Telnet
Note the use of cat to keep the connection open long enough to get a response, as we did for Gemini over GnuTLS.
Because TLS support isn’t needed, this also works perfectly well with Netcat – just substitute nc/netcat or whatever your platform calls it in place of
ncat:
The Internet is full of guides on easily making your WordPress installation run fast. If you’re looking to speed up your WordPress site, you should go read those, not this.
Those guides often boil down to the same old tips:
uninstall unnecessary plugins,
optimise caching (both on the server and, via your headers, on clients/proxies),
resize your images properly and/or ensure WordPress is doing this for you,
This article is for people who aren’t afraid to go tinkering in their WordPress codebase to squeeze a little extra (real world!) performance.
It’s for people whose neverending quest for perfection is already well beyond the point of diminishing returns.
But mostly, it’s for people who want to gawp at me, the freak who actually did this stuff just to make his personal blog a tiny bit nippier without spending an extra penny on
hosting.
You shouldn’t use Lighthouse as your only measure of your site’s performance. But it’s still reassuring when you get to see those fireworks!
Don’t start with the hard way. Exhaust all the easy solutions – or at least, make a conscious effort which easy solutions to enact or reject – first. Only if you really
want to get into the weeds should you actually try doing the things I propose here. They’re not for most sites, and they’re not the for faint of heart.
Performance is a tradeoff. Every performance improvement costs you something else: time, money, DX, UX, etc. What you choose to trade for performance gains depends on your priority of constituencies, which may differ from mine.4
This is not a recipe book. This won’t tell you what code to change or what commands to run. The right answers for your content will be different than the right answers
for mine. Also: you shouldn’t change what you don’t understand! But I hope these tips will help you think about what questions you need to ask to make your site blazing fast.
Okay, let’s get started…
1. Backstab the plugins you can’t live without
If there are plugins you can’t remove because you depend upon their functionality, and those plugins inject content (especially JavaScript) on the front-end… backstab them to
undermine that functionality.
For example, if you want Jetpack‘s backup and downtime monitoring features, but you don’t want it injecting random <linkrel='stylesheet' id='...-jetpack-css' href='...' media='all' />‘s (an
extra stylesheet to download and parse) into your pages: find the add_filter hook it uses and remove_filter it in your theme5.
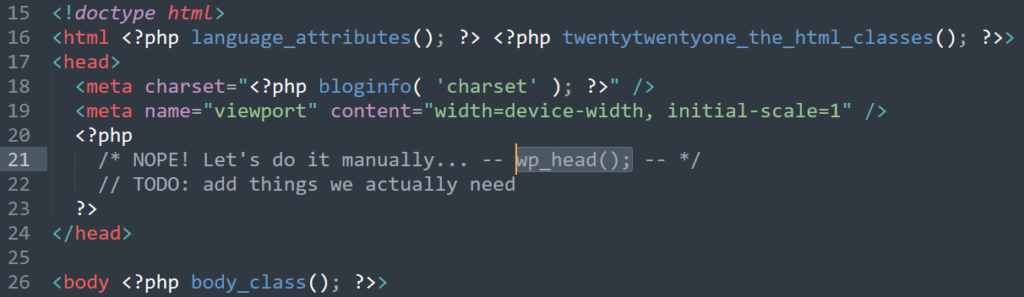
Alternatively, entirely remove the wp_head() and manually reimplement the functionality you actually need. Insert your own joke about “Headless WordPress” here.
Better yet, remove wp_head() from your theme entirely6.
Now, instead of blocking the hooks you don’t want polluting your <head>, you’re specifically allowing only those you want. You’ll want to take care to get
some semi-essential ones like <link rel="canonical" href="...">7.
Now most of your plugins are broken, but in exchange, your theme has reclaimed complete control over what gets sent to the user. You can select what content you actually
want delivered, and deliver no more than that. It’s harder work for you, but your site becomes so much lighter.
Your site is faster now. It doesn’t work, but it’s quick about it!
2. Throw away 100% of your render-blocking JavaScript (and as much as you can of the rest)
The single biggest bottleneck to the user viewing a modern WordPress website is the JavaScript that needs to be downloaded, compiled, and executed before the page can be rendered. Most
of that’s plugins, but even on a nearly-vanilla installation you might find a copy of jQuery (eww!) and some other files.
In step 1 you threw it all away, which is great… but I’m betting you were depending on some of that to make your site work? Let’s put it back, carefully and selectively, while
minimising the impact on load time.
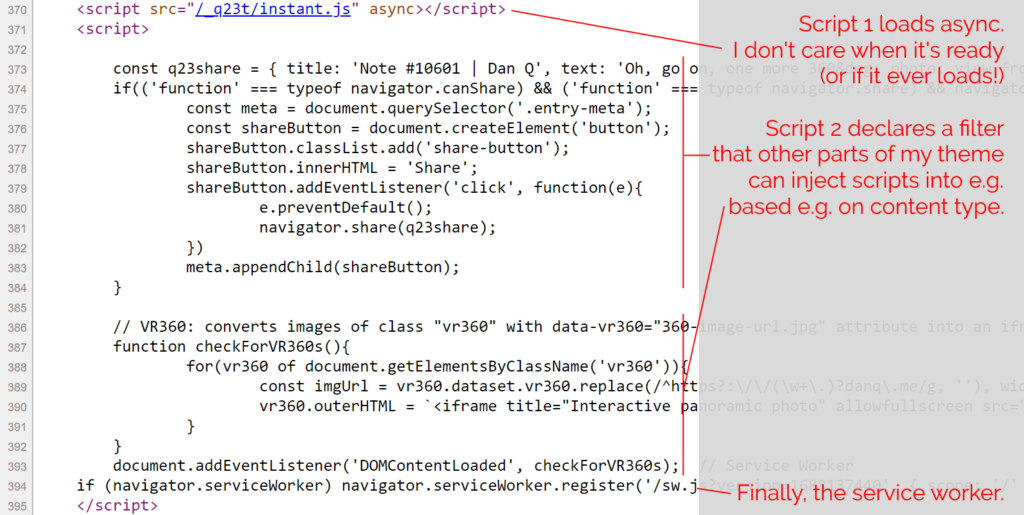
That means scripts should be loaded (a) low-down, and/or (b) marked defer (or, better yet, async), so they don’t block page rendering.
If you haven’t already, you might like to View Source on this page. Count my <script> tags. You’ll probably find just two of them: one external file marked
async, and a second block right at the bottom.
The only third-party script routinely loaded on danq.me is Instant.Page, which specifically exists to improve perceived performance. It preloads
links when you hover over or start-to-touch them.
The inline <script> in my footer.php wraps a single line of PHP: which looks a little like
this: <?php echo implode("\n\n", apply_filters( 'danq_footer_js', [] ) ); ?>. For each item in an initially-empty array, it appends to the script tag. When I render
anything that requires JavaScript, e.g. for 360° photography, I can just add to that
(keyed, to prevent duplicates when viewing an archive page) array. Thus, the relevant script gets added exclusively to the pages where it’s needed, not to the entire site.
The only inline script added to every page loads my service worker, which itself aims to optimise caching as well as providing limited “offline” functionality.
While you’re tweaking your JavaScript anyway, you might like to check that any suitable addEventListeners are set to passive mode. Especially if you’re doing anything with touch or
mousewheel events, you can often increase the perceived performance of these interactions by not letting your custom code block the default browser behaviour.
I promise you; most of your blog’s front-end JavaScript is either (a) garbage nobody wants, (b) polyfills for platforms nobody uses, or (c) huge libraries you’ve imported so you can
use just one or two functions form them. Trash them.
3. Don’t use a CDN
Wait, what? That’s the opposite of what everybody else recommends. To understand why, you have to think about why people recommend a CDN in the first place. Their reasons are usually threefold:
Proximity
Claim: A CDN delivers content geographically-closer to the user.
Retort: Often true. But in step 4 we’re going to make sure that everything critical comes within the first TCP
sliding window anyway, so there’s little benefit, and there’s a cost to that extra DNS lookup and fresh handshake. Edge
caching your own contentmay have value, but for most sites it’ll have a much smaller impact than almost everything else on this list.
Precaching
Claim: A CDN improves the chance resources are precached in the user’s browser.
Retort: Possibly true, especially with fonts (although see step 6) but less than you’d think with JS libraries because
there are so many different versions/hosts of each. Yours may well be the only site in the user’s circuit that uses a particular one!
Power Claim: A CDN has more resources than you and so can better-withstand spikes of traffic.
Retort: Maybe, but they also introduce an additional single-point-of-failure. CDNs aren’t magically immune
to downtime nor content-blocking, and if you depend on one you’ve just doubled the number of potential failure points that can make your site instantly useless. Furthermore:
in exchange for those resources you’re trading away your users’ privacy and security: if a CDN gets hacked, every site that
uses it gets hacked too.
Consider edge-caching your own content only if you think you need it, but ditch jsDeliver, cdnjs, Google Hosted Libraries etc.
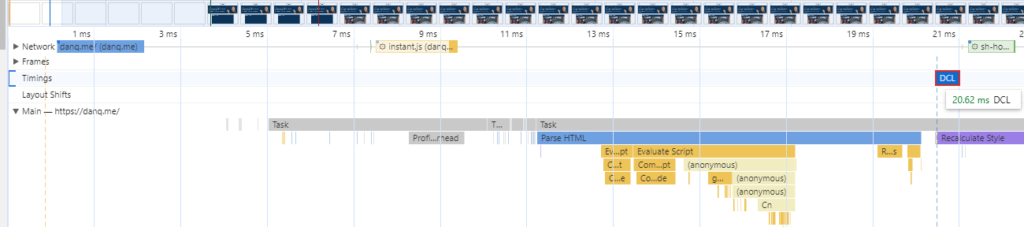
Despite having no edge cache and being hosted in a different country to me, I can open a completely fresh browser and reach DOMContentLoaded on the my homepage in ~20ms. You should learn how to read a
waterfall performance chart just so you can enjoy how “flat” mine is.
Hell: if you can, ditch all JavaScript served from third-parties and slap a Content-Security-Policy: script-src 'self' header on your domain to dramatically reduce
the entire attack surface of your site!8
4. Reduce your HTML and CSS size to <12kb compressed
There’s a magic number you need to know: 12kb. Because of some complicated but fascinating maths (and depending on how your hosting is configured), it can be significantly faster to
initially load a web resource of up to 12kb than it is to load one of, say, 15kb. Also, for the same reason, loading a web resource of much less than 12kb
might not be significantly faster than loading one only a little less than 12kb.
Inlining as much essential content as possible (CSS, SVGs,
JavaScript etc.) to bring you back up to close-to that magic number again!
$ curl --compressed -so /dev/null -w "%{size_download}\n" https://danq.me/
10416
Note that this is the compressed, over-the-wire size. Last I checked, my homepage weighed-in at about 10.4kb compressed, which includes the entirety of its HTML and CSS, most of its JS, and a
couple of its SVG images.
Again, this probably flies in the face of everything you were taught about performance. I’m sure you were told that you should <link> to your stylesheets so that they
can be cached across page loads. But it turns out that if you can make your HTML and CSS small enough, the opposite is true and you should inline the stylesheet again: caching styles becomes almost irrelevant if you get all the content in
a single round-trip anyway!
For extra credit, consider optimising your homepage’s CSS so it’s even smaller by excluding directives that only apply to
non-homepage pages, and vice-versa. Assuming you’re using a preprocessor, this shouldn’t be too hard: at simplest, you can have a homepage.css and main.css,
each derived from a set of source files some of which they share (reset/normalisation, typography, colours, whatever) and the rest which is specific only to that part of the site.
Most web pages should fit entirely onto a floppy disk. This one doesn’t, mostly because of all the Simpsons clips, but most should.
Can’t manage to get your HTML and CSS down below the magic
number? Then at least ensure that your HTML alone weighs in at <12kb compressed and you’ll still get some of the
benefits. If you’ve got the headroom, you can selectively include a <style> block containing only the most-crucial CSS, with a particular focus on any that results in layout shifts (e.g. anything that specifies the height: of otherwise dynamically-sized
block elements, or that declares an element position: absolute or position: fixed). These kinds of changes are relatively computationally-expensive because
they cause content to re-flow, so provide hints as soon as possible so that the browser can accommodate for them.
5. Make the first load awesome
We don’t really talk about content being “above the fold” like we used to, because the modern Web has such a diverse array of screen sizes and resolutions that doing so doesn’t make
much sense.
But if loading your full page is still going to take multiple HTTP requests (scripts, images, fonts, whatever),
you should still try to deliver the maximum possible value in the first round-trip. That means:
Making sure all your textual content loads immediately! Unless you’re delivering a huge amount of text, there’s absolutely no excuse for lazy-loading text: it’s
usually tiny, compresses well, and it’s fast to parse. It’s also the most-important content of most pages. Get it delivered to the browser so it can be rendered rightaway.
Reserving space for blocks by sizing images appropriately, e.g. using <img width="..." height="..." ...> or having them load as a background with
background-size: cover or contain in a block sized with CSS delivered in the initial payload. This
reduces layout shift, which mitigates the need for computationally-expensive content reflows.
If possible (see point 4), move vector images that support basic site functionality, like logos, inline. This might also apply to icons, if they’re “as important” as text content.
Marking everything up with standard semantic HTML. There’s a trend for component-driven design to go much too
far, resulting in JavaScript components being used in place of standard elements like links, buttons, and images, resulting in highly-fragile websites: when those scripts fail (or are
very slow to load), the page becomes unusable.
If you want to be sure you’re prioritising your content first and foremost, try disabling all CSS, JavaScript, and external
resources (or just access your site in a browser that ignores those things, like Lynx), and check that it’s still usable. As a bonus, this
helps you check for several accessibility issues.
6. Reduce your dependence on downloaded fonts
Fonts are lovely and can be an important part of your brand identity, but they can also add a lot of weight to your web pages.
If you’re ready and able to drop your webfonts and appreciate the beauty and flexibility of a system font stack (I get it: I’m not there quite yet!), you can at least make
smarter use of your fonts:
Every modern browser supports WOFF2, so you can ditch those chunky old formats you’re clinging onto.
If you’re only using the Latin alphabet, minify your fonts further by dropping the characters you don’t need: tools like Google Webfonts
Helper can help with this, as well as making it easier to selfhost fonts from the most-popular library (is a smart idea for the reasons described under point 3, above!). There are
tools available to further minify fonts if e.g. you only need the capital letters for your title font or something.
Browsers are pretty clever and will work-around it if you make a mistake. Didn’t include an emoji or some obscure mathematical symbol, and then accidentally used them in a
post? Browsers will switch to a system font that can fill in the gap, for you.
Make the most-liberal use of the font-display: CSS directive that you can tolerate!
Don’t use font-display: block, which is functionally the default in most browsers, unless you absolutely have to.
font-display: fallback is good if you’re too cowardly/think your font is too important for you to try font-display: optional.
font-display: optional is an excellent choice for body text: if the browser thinks it’s worthwhile to download the font (it might choose not to if the operating
system indicates that it’s using a metered or low-bandwidth connection, for example), it’ll try to download it, but it won’t let doing so slow things down too much and it’ll
fall-back to whatever backup (system) font you specify.
font-display: swap is also worth considering: this will render any text immediately, even if the right font hasn’t downloaded yet, with no blocking time
whatsoever, and then swap it for the right font when it appears. It’s probably better for headings, because large paragraphs of text can be a little disorienting if they change
font while a user is looking at them!
If writing is for nerds, then typography must be doubly-so. But you’ve read this far, so I’m confident that you qualify…
7. Cache pre-compressed static files
It’s possible that by this point you’re saying “if I had to do this much work, I might as well just use a static site generator”. Well good news: that’s what you’re about to
do!
Obviously you should make sure all your regular caching improvements (appropriate HTTP headers for caching, a
service worker that further improves on that logic based on your content’s update schedule, etc.) first. Again: everything in this guide presupposes that you’ve already done the things
that normal people do.
By aggressively caching pre-compressed copies of all your pages, you’re effectively getting the best of both worlds: a website that, for anonymous visitors, is served directly from
.html.gz files on a hard disk or even straight from RAM in memcached10,
but which still maintains all the necessary server-side interactivity to allow it to be used as a conventional Web-based CMS
(including accepting comments if that’s your jam).
WP Super Cache can do the heavy lifting for you for a filesystem-based solution so long as you put it into “Expert” mode and
amending your webserver configuration. I’m using Nginx, so I needed a try_files directive like this:
I’m sure your favourite performance testing tool has already complained at you about your failure to use the best formats possible when serving images to your users. But how can you fix
it?
There are some great plugins for improving your images automatically and/or in bulk – I use EWWW Image Optimizer – but
to really make the most of them you’ll want to reconfigure your webserver to detect clients that Accept: image/webp and attempt to dynamically
serve them .webp variants, for example. Or if you’re ready to give up on legacy formats and replace all your .pngs with .webps, that’s probably
fine too!
The image you see at https://danq.me/_q23u/2023/11/dynamic.png is probably an image/webp. But if your browser doesn’t support WebP, you’ll get an
image/png instead!
Assuming you’ve got curl and Imagemagick‘s identify, you can see this in action:
curl -s https://danq.me/_q23u/2023/11/dynamic.png -H "Accept: image/webp" | identify -
(Will give you a WebP image)
curl -s https://danq.me/_q23u/2023/11/dynamic.png -H "Accept: image/png" | identify -
(Will give you a PNG image, even though the URL is the same)
9. Simplify, simplify, simplify
The single biggest impact you can have upon the performance of your WordPress pages is to make them less complex.
You don’t have to go as light as Gemtext – like this page on Gemini does – to see
benefits.
Writing my templates and posts so that they’re compatible with CapsulePress helps keep my code necessarily-simple. You don’t have to
do that, though, but you should be asking yourself:
Does my DOM need to cascade so deeply? Could I achieve the same with less?
Am I pre-emptively creating content, e.g. adding a hidden <dialog> directly to the markup in the anticipation that it might be triggered later using
JavaScript, rather than having that JavaScript run document.createElement the element after the page becomes readable?
Have I created unnecessarily-long chains of CSS selectors11
when what I really want is a simple class name, or perhaps even a semantic element name?
10. Add a Service Worker
A service worker isn’t magic. In particular, it can’t help you with those new visitors hitting your site for the first time12.
A service worker lets you do smart things on behalf of the user’s network connection, so that by the time they ask for a resource, you already fetched it for them.
But a suitable service worker can do a few things that can help with performance. In particular, you might consider:
Precaching assets that you anticipate they’re likely to need (e.g. if you use different stylesheets for the homepage and other pages, you can preload both so no matter
where a user lands they’ve already got the CSS they’ll need for the entire site).
Preloading popular pages like the homepage and recent articles, allowing them to load quickly.
Caching a fallback pages – and other resources as-they’re-accessed – to support a full experience for users even if they (or your site!) disconnect from the Internet (or even
embedding “save for offline” functionality!).
Chapters 7 and 8 of Going Offline by Jeremy Keith are
especially good for explaining how this can be achieved, and it’s all much easier than everything else I just described.
Anything else?
Did I miss anything? If you’ve got a tip about ramping up WordPress performance that isn’t one of the “typical seven” – probably because it’s too hard to be worthwhile for most people –
I’d love to hear it!
Footnotes
1 You’ll sometimes see guides that suggest that using a CDN is to be recommended specifically because it splits your assets among multiple domains/subdomains, which mitigates browsers’ limitation on the
number of files they can download simultaneously. This is terrible advice, because such limitations essentially don’t exist any more, but DNS lookups and TLS handshakes still have a bandwidth and computational cost. There are good
things about CDNs, sometimes, but this has not been one of them for some time now.
2 I’m not sure why guides keep stressing the importance of minifying code,
because by the time you’re compressing them too it’s almost pointless. I guess it’s helpful if your compression fails?
3 “Use a faster server” is a “just throw money/the environment at it” solution. I’d like
to think we can do better.
4 For my personal blog, I choose to prioritise user experience, privacy, accessibility,
resilience, and standards compliance above almost everything else.
5 If you prefer to keep your backstab code separate, you can put it in a custom plugin,
but you might find that you have to name it something late in the alphabet – I’ve previously used names like zzz-danq-anti-plugin-hacks – to ensure that they load
after the plugins whose functionality you intend to unhook: broadly-speaking, WordPress loads plugins in alphabetical order.
6 I’ve assumed you’re using a classic, not block, theme. If you’re using a block theme,
you get a whole different set of performance challenges to think about. Don’t get me wrong: I love block themes and think they’re a great way to put more people in control of their
site’s design! But if you’re at the point where you’re comfortable digging this deep into your site’s PHP code,
you probably don’t need that feature anyway, right?
7 WordPress is really good at serving functionally-duplicate content, so search
engines appreciate it if you declare a proper canonical URL.
8 Before you choose to block all third-party JavaScript, you might have to
whitelist Google Analytics if you’re the kind of person who doesn’t mind selling their visitor data to the world’s biggest harvester of personal information in exchange for some
pretty graphs. I’m not that kind of person.
10 I’ve experimented with mounting a ramdisk and storing the WP Super Cache directory
there, but it didn’t make a huge difference, probably because my files are so small that the parse/render time on the browser side dominates the total cascade, and they’re already
being served from an SSD. I imagine in my case memcached would provide similarly-small benefits.
11 I really love the power of CSS preprocessors like Sass, but they do make it deceptively easy to create many more – and longer – selectors
than you intended in your final compiled stylesheet.
12 Tools like Lighthouse usually simulate first-time visitors, which can be a little
unfair to sites with great performance for established visitors. But everybody is a first-time visitor at least once (and probably more times, as caches expire or are
cleared), so they’re still a metric you should consider.
Conveniently just-over-A5 sized, each of the two volumes is light enough to read in bed without uncomfortably clonking yourself in the face.
Set in the early-to-mid-1990s world in which the BBS is still alive and kicking, and the Internet’s gaining traction but still
lacks the “killer app” that will someday be the Web (which is still new and not widely-available), the story follows a handful of teenagers trying to find their place in the world.
Meeting one another in the 90s explosion of cyberspace, they find online communities that provide connections that they’re unable to make out in meatspace.
I loved some of the contemporary nerdy references, like the fact that each chapter page sports the “Geek Code” of the character upon which that chapter focusses.1So yeah: the whole thing feels like a trip back into the naivety of the online world of the last millenium, where small, disparate (and often local) communities flourished and
early netiquette found its feet. Reading Incredible Doom provides the same kind of nostalgia as, say, an afternoon spent on textfiles.com. But
it’s got more than that, too.
The user interfaces of IRC, Pine, ASCII-art-laden BBS menus etc. are all produced with
a good eye for accuracy, but don’t be fooled: this is a story about humans, not computers. My 9-year-old loved it too, and she’s never even heard of IRC (I hope!).
It touches on experiences of 90s cyberspace that, for many of us, were very definitely real. And while my online “scene” at around the time that the story is set might have been
different from that of the protagonists, there’s enough of an overlap that it felt startlingly real and believable. The online world in which I – like the characters in the story – hung
out… but which occupied a strange limbo-space: both anonymous and separate from the real world but also interpersonal and authentic; a frontier in which we were still working out the
rules but within which we still found common bonds and ideals.
Having had times in the 90s that I met up offline with relative strangers whom I first met online, I can confirm that… yeah, the fear is real!
Anyway, this is all a long-winded way of saying that Incredible Doom is a lot of fun and if it sounds like your cup of tea, you should read it.
Also: shortly after putting the second volume down, I ended up updating my Geek Code for the first time in… ooh, well over a decade. The standards have moved on a little (not entirely
in a good way, I feel; also they’ve diverged somewhat), but here’s my attempt:
----- BEGIN GEEK CODE VERSION 6.0 -----
GCS^$/SS^/FS^>AT A++ B+:+:_:+:_ C-(--) D:+ CM+++ MW+++>++
ULD++ MC+ LRu+>++/js+/php+/sql+/bash/go/j/P/py-/!vb PGP++
G:Dan-Q E H+ PS++ PE++ TBG/FF+/RM+ RPG++ BK+>++ K!D/X+ R@ he/him!
----- END GEEK CODE VERSION 6.0 -----
Footnotes
1 I was amazed to discover that I could still remember most of my Geek Code
syntax and only had to look up a few components to refresh my memory.
One of my favourite parts of my former role at
the Bodleian Libraries was getting to work on exhibitions. Not just because it was varied and interesting work, but because it let me get
up-close to remarkable artifacts that
most people never even get the chance to see.
We also got to play dollhouse, laying out exhibitions in miniature.
A personal favourite of mine are the Herculaneum Papyri. These charred scrolls were part of a private library near Pompeii that was buried by the eruption
of Mount Vesuvius in 79 CE. Rediscovered from 1752, these ~1,800 scrolls were distributed to academic institutions around the world, with
the majority residing in Naples’ Biblioteca Nazionale Vittorio Emanuele III.
The second time I was in an exhibition room with the Bodleian’s rolled-up Herculaneum Papyri was for an exhibition specifically about humanity’s relationship with volcanoes.
As you might expect of ancient scrolls that got buried, baked, and then left to rot, they’re pretty fragile. That didn’t stop Victorian era researchers trying a variety of techniques to
gently unroll them and read what was inside.
Unrolling the scrolls tends to go about as well as you’d anticipate. A few have been deciphered this way. Many others have been damaged or destroyed by unrolling efforts.
Like many others, what I love about the Herculaneum Papyri is the air of mystery. Each could be anything from a lost religious text to, I don’t know, somebody’s to-do list (“buy milk, arrange for annual service of chariot, don’t forget to renew
volcano insurance…”).1
In recent years, we’ve tried “virtually unrolling” the scrolls using a variety of related technologies. And – slowly – we’re getting there.
X-ray tomography is amazing, but it’s hampered by the fact that the ink and paper have near-equivalent transparency to x-rays. Plus, all the other problems. But new techniques are helping to overcome them.
So imagine my delight when this week, for the first time ever, a
complete word was extracted from one of the carbonised, still-rolled-up scrolls from Herculaneum. Something that would have seemed inconceivable to the historians who first
discovered and catalogued the scrolls is now possible, thanks to their careful conservation over the years along with the steady advance of technology.
The word appears to be “purple”: either πορφύ̣ρ̣ας̣ (a noun, similar to how we might say “pass the purple [pen]” or πορφυ̣ρ̣ᾶς̣: if we can decode more words around it then it which
might become clear from the context.
Anyway, I thought that was exciting news so I wanted to share.
I’m probably not going to get you a Christmas present. You probably shouldn’t get me one either.
All I need for Christmas is… a woolly jumper and a dog, apparently. (And I only need the latter if the goose doesn’t get delivered.)
If you’re one of my kids and you’ve decided that maybe my blog isn’t just “boring grown-up stuff” and have come by, then you’re one of the exceptions. Lucky you.
Children get Christmas gifts from me. But if you’re an adult, all you’re likely to get from me is a hug, a glass of wine, and more food than you can possibly eat in a single
sitting.
Turns out the real meaning of Christmas was eating yourself into indigestion all along.
I’ve come to the conclusion – much later than my mother and my sisters, who were clearly ahead of the curve – that Christmas presents are for kids.
Maybe, once, Christmas presents were for adults too, but by now the Internet has broken gift-giving to the extent it’s almost certainly preferable for me and the adults in my life
if they just, y’know, order the thing they want than hoping that I’ll pick it out for them. Especially as so many of us are at a point where we already have a plethora of
“stuff”, and don’t want to add to it unnecessarily at a time of year when, frankly, we’ve got better things to spend our time and money on.
I’ll still be participating fully in my household‘s “book exchange” Christmas Eve tradition, though, because
it’s awesome.
Birthdays are still open season, because they aren’t hampered by the immediate expectation of reciprocity that Christmas carries. And I reserve the right to buy groups of (or
containing) adults gifts at Christmas. But individual adults aren’t getting one this year, and they certainly shouldn’t feel like they need to get me anything either.1
I don’t know to what extent, if at all, Ruth and JTA will be following me in this idea, so
if you’re somebody who might have expected a gift from or wanted to give a gift to one of them… you’re on your own; you work it out!
Here’s to a Merry Christmas full of presents for children, only!
Footnotes
1 If you’ve already bought me a gift for Christmas this year… firstly, that’s way
too organised: you know it’s only October, right? And secondly: my birthday’s only a couple of weeks later…
Foundry is a wonderful virtual tabletop tool well-suited to playing tabletop roleplaying games with your friends, no
matter how far away they are. It compares very favourably to the market leader Roll20, once you
get past some of the initial set-up challenges and a moderate learning curve.
The party of adventurers I’ve been DMing
for since last summer use Foundry to simulate a tabletop (alongside a conventional video chat tool to let us see and hear
one another).
You can run it on your own computer and let your friends “connect in” to it, so long as you’re able to reconfigure your router a little, but you’ll be limited by the speed of your home
Internet connection and people won’t be able to drop in and e.g. tweak their character sheet except when you’ve specifically got the application running.
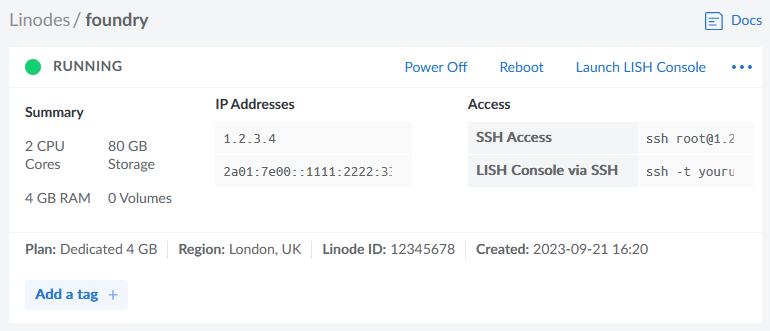
A generally better option is to host your Foundry server in the cloud. For most of its history, I’ve run mine on Fox, my NAS, but I’ve recently set one up on a more-conventional cloud virtual machine too. A couple of
friends have asked me about how to set up their own, so here’s a quick guide:
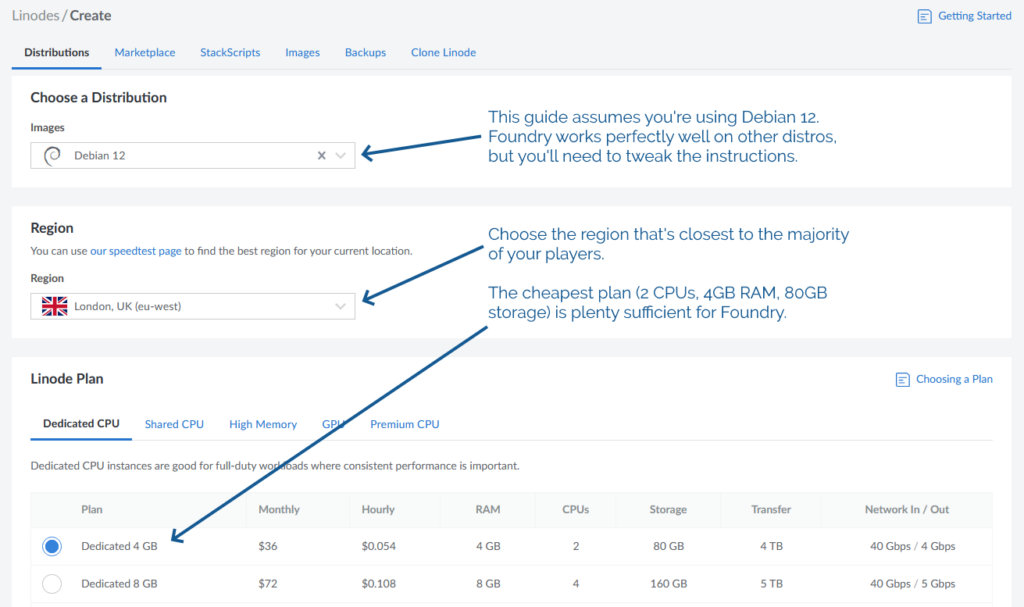
I used Linode to spin up a server because I still had a stack of free credits following a recent
project. The instructions will work on any cloud host where you can spin up a Debian 12 virtual machine, and can be adapted for other distributions of Linux.
You will need…
A Foundry license ($50 USD / £48 GBP, one-off payment1)
A domain name for which you control the DNS records; you’ll need to point a domain, like “danq.me” (or a subdomain of it, e.g.
“vtt.danq.me”), at an IP address you’ll get later by creating an “A” record: your domain name registrar can probably help with this –
I mostly use Gandi and, ignoring my frustration with
recent changes to their email services, I think they’re great
An account with a cloud hosting provider: this example uses Linode but you can adapt for any of them
A basic level of comfort with the command-line
1. Spin up a server
Getting a virtual server is really easy nowadays.
Click, click, click, and you’ve got yourself a server.
You’ll need:
The operating system to be Debian 12 (or else you’ll need to adapt the instructions below)
The location to be somewhere convenient for your players: pick a server location that’s relatively-local to the majority of them to optimise for connection speeds
An absolute minimum of 1GB of storage space, I’d recommend plenty more: The Levellers’ campaign currently uses about 10GB for all of its various maps, art, videos,
and game data, so give yourself some breathing room (space is pretty cheap) – I’ve gone with 80GB for this example, because that’s what comes as standard with the 2
CPU/4GB RAM server that Linode offer
Choose a root password when you set up your server. If you’re a confident SSH user, add your public key so you can log in easily (and then
disable password authentication
entirely!).
For laziness, this guide has you run Foundry as root on your new server. Ensure you understand the implications of this.2
2. Point your (sub)domain at it
DNS propogation can be pretty fast, but… sometimes it isn’t. So get this step underway before you need it.
Your newly-created server will have an IP address, and you’ll be told what it is. Put that IP address into an A-record for your domain.
The interface for adding a new DNS record in Gandi is pretty simple – record type, time to live, name, address – but it’s rarely
more complicated that this with any registrar that provides DNS services.
3. Configure your server
In my examples, my domain name is vtt.danq.me and my server is at 1.2.3.4. Yours will be different!
Connect to your new server using SSH. Your host might even provide a web interface if you don’t have an SSH client installed: e.g. Linode’s “Launch LISH Console” button will do pretty-much exactly that for you. Log in as root using the password you chose
when you set up the server (or your SSH private key, if that’s your preference). Then, run each of the commands below in order (the full script is available as a single file if you
prefer).
3.1. Install prerequisites
You’ll need unzip (to decompress Foundry), nodejs (to run Foundry), ufw (a firewall, to prevent unexpected surprises), nginx (a
webserver, to act as a reverse proxy to Foundry), certbot (to provide a free SSL certificate for Nginx),
nvm (to install pm2) and pm2 (to keep Foundry running in the background). You can install them all like this:
By default, Foundry runs on port 30000. If we don’t configure it carefully, it can be accessed directly, which isn’t what we intend: we want connections to go through the webserver
(over https, with http redirecting to https). So we configure our firewall to allow only these ports to be accessed. You’ll also want ssh enabled so we can remotely connect into the
server, unless you’re exclusively using an emergency console like LISH for this purpose:
Putting the domain name we’re using into a variable for the remainder of the instructions saves us from typing it out again and again. Make sure you type your domain name (that
you pointed to your server in step 2), not mine (vtt.danq.me):
DOMAIN=vtt.danq.me
3.4. Get an SSL certificate with automatic renewal
So long as the DNS change you made has propogated, this should Just Work. If it doesn’t, you might need to wait for a bit then try
again.
3.5. Configure Nginx to act as a reverse proxy for Foundry
You can, of course, manually write the Nginx configuration file: just remove the > /etc/nginx/sites-available/foundry from the end of the printf line to see
the configuration it would write and then use/adapt to your satisfaction.
set +H
printf "server {\n listen 80;\n listen [::]:80;\n server_name $DOMAIN;\n\n # Redirect everything except /.well-known/* (used for ACME) to HTTPS\n root /var/www/html/;\n if (\$request_uri !~ \"^/.well-known/\") {\n return 301 https://\$host\$request_uri;\n }\n}\n\nserver {\n listen 443 ssl http2;\n listen [::]:443 ssl http2;\n server_name $DOMAIN;\n\n ssl_certificate /etc/letsencrypt/live/$DOMAIN/fullchain.pem;\n ssl_certificate_key /etc/letsencrypt/live/$DOMAIN/privkey.pem;\n\n client_max_body_size 300M;\n\n location / {\n # Set proxy headers\n proxy_set_header Host \$host;\n proxy_set_header X-Forwarded-For \$proxy_add_x_forwarded_for;\n proxy_set_header X-Forwarded-Proto \$scheme;\n\n # These are important to support WebSockets\n proxy_set_header Upgrade \$http_upgrade;\n proxy_set_header Connection \"Upgrade\";\n\n proxy_pass http://127.0.0.1:30000/;\n }\n}\n" > /etc/nginx/sites-available/foundry
ln -sf /etc/nginx/sites-available/foundry /etc/nginx/sites-enabled/foundry
service nginx restart
3.6. Install Foundry
3.6.1. Create a place for Foundry to live
mkdir {vtt,data}
cd vtt
3.6.2. Download and decompress it
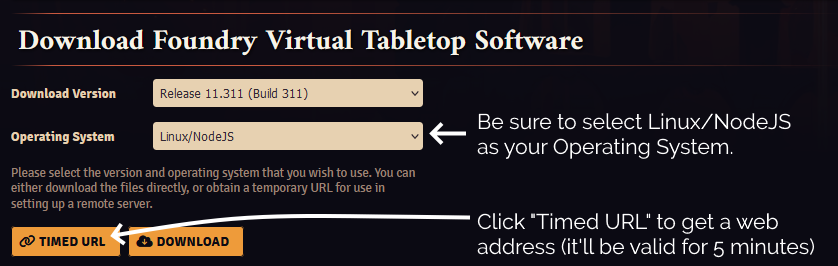
For this step, you’ll need to get a Timed URL from the Purchased Licenses page on your FoundryVTT account.
Substitute in your Timed URL in place of <url from website> (keep the quotation marks – " –
though!):
wget -O foundryvtt.zip "<url from website>"
unzip foundryvtt.zip
rm foundryvtt.zip
3.6.3. Configure PM2 to run Foundry and keep it running
Now you’re finally ready to launch Foundry! We’ll use PM2 to get it to run automatically in the background and keep running:
You can watch the logs for Foundry with PM2, too. It’s a good idea to take a quick peep at them to check it launched okay (press CTRL-C to exit):
pm2 logs 0
4. Start adventuring!
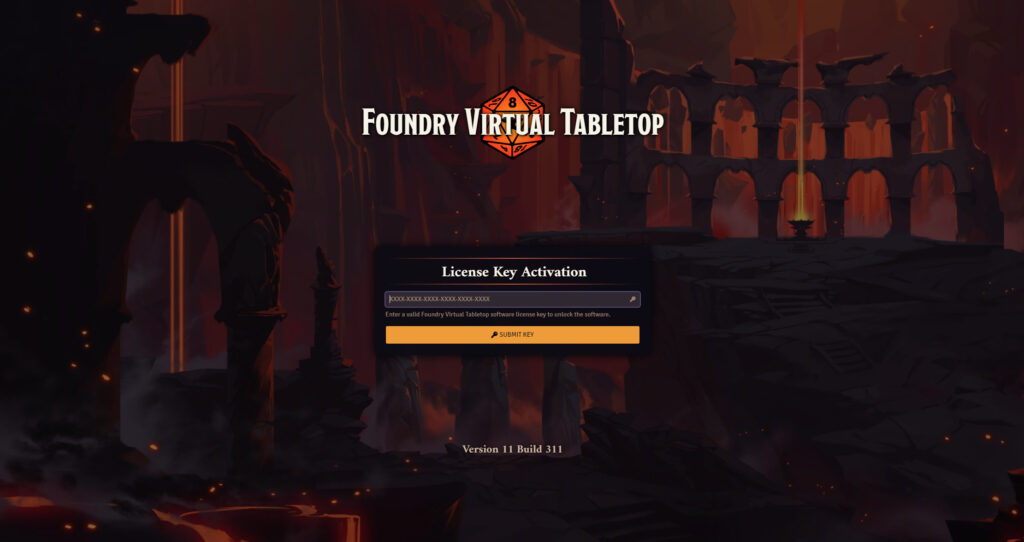
Point your web browser at your domain name (e.g. I might go to https://vtt.danq.me) and you should see Foundry’s first-load page, asking for your license key.
Provide your license key to get started, and then immediately change the default password: a new instance of Foundry has a blank default password, which means that
anybody on Earth can administer your server: get that changed to something secure!
Now you’re running on Foundry!
Footnotes
1Which currency you pay in, and therefore how much you pay, for a Foundry license depends on where in the world you are
where your VPN endpoint says you are. You might like to plan accordingly.
2 Running Foundry as root is dangerous, and you should consider the risks for yourself.
Adding a new user is relatively simple, but for a throwaway server used for a single game session and then destroyed, I wouldn’t bother. Specifically, the risk is that a vulnerability
in Foundry, if exploited, could allow an attacker to reconfigure any part of your new server, e.g. to host content of their choice or to relay spam emails. Running as a non-root user
means that an attacker who finds such a vulnerability can only trash your Foundry instance.
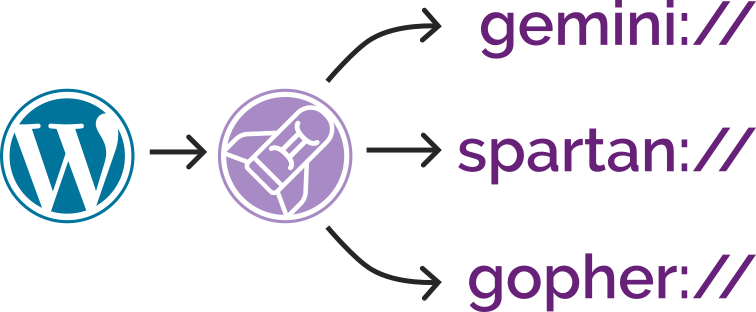
Now I’ve added support for Spartan3 too and, seeing as the implementations shared functionality, I’ve
combined all three – Gemini, Spartan, and Gopher – into a single package: CapsulePress.
CapsulePress is a Gemini/Spartan/Gopher to WordPress bridge. It lets you use WordPress as a CMS for any or all of
those three non-Web protocols in addition to the Web.
For example, that means that this post is available on all of:
It’s also possible to write posts that selectively appear via different media: if I want to put something exclusively on my gemlog, I can, by assigning metadata that
tells WordPress to suppress a post but still expose it to CapsulePress. Neat!
Using Gemini and friends in the 2020s make me feel like the dream of the Internet of the nineties and early-naughties is still alive. But with fewer banner ads.
I’ve open-sourced the whole thing under a super-permissive license, so if you want your own WordPress blog to “feed” your Gemlog… now you can. With a few caveats:
It’s hard to use. While not as hacky as the disparate piles of code it replaced, it’s still not the cleanest. To modify it you’ll need a basic comprehension of all
three protocols, plus Ruby, SQL, and sysadmin skills.
It’s super opinionated. It’s very much geared towards my use case. It’s improved by the use of templates. but it’s still probably only suitable for this
site for the time being, until you make changes.
It’s very-much unfinished. I’ve got a growing to-do list, which should
be a good clue that it’s Not Finished. Maybe it never will but. But there’ll be changes yet to come.
Whether or not your WordPress blog makes the jump to Geminispace4, I hope you’ll came take a look at mine at one of the URLs linked above,
and then continue to explore.
If you’re nostalgic for the interpersonal Internet – or just the idea of it, if you’re too young to remember it… you’ll find it there. (That Internet never actually went away,
but it’s harder to find on today’s big Web than it is on lighter protocols.)
It turns out that by default, WordPress replaces emoji in its feeds (and when sending email) with images of those emoji, using the Tweemoji set, and with the alt-text set to the original emoji. These images are hosted at https://s.w.org/images/core/emoji/…-based
URLs.
I can see why this functionality was added: what if the feed reader didn’t support Unicode or didn’t have a font capable of showing the appropriate emoji?
But I can also see reasons why it might not be desirable to everybody. For example:
Downloading an image will always be slower than rendering an emoji.
The code to include an image is always more-verbose than simply including an emoji.
As seen above: a feed reader which imposes a minimum size on embedded images might well render one “wrong”.
It’s marginally more-verbose for screen reader users to say “Image: heart emoji” than just “heart emoji”, I imagine.
Serving an third-party image when a feed item is viewed has potential privacy implications that I try hard to avoid.
Replacing emoji with images is probably unnecessary for modern feed readers anyway.
That’s all there is to it. Now, my feed reader shows my system’s emoji instead of a huge image:
I’m always grateful to discover that a piece of WordPress functionality, whether core or in an extension, makes proper use of hooks so that its functionality can be changed, extended,
or disabled. One of the single best things about the WordPress open-source ecosystem is that you almost never have to edit somebody else’s code (and remember to re-edit it
every time you install an update).
Earlier this year, for reasons of privacy/love of selfhosting, I moved the DanQ.me mailing list from Mailchimp to Listmonk (there’s a blog post about how I set it up), relaying
outbound messages via an SMTP server provided by my domain registrar, Gandi.
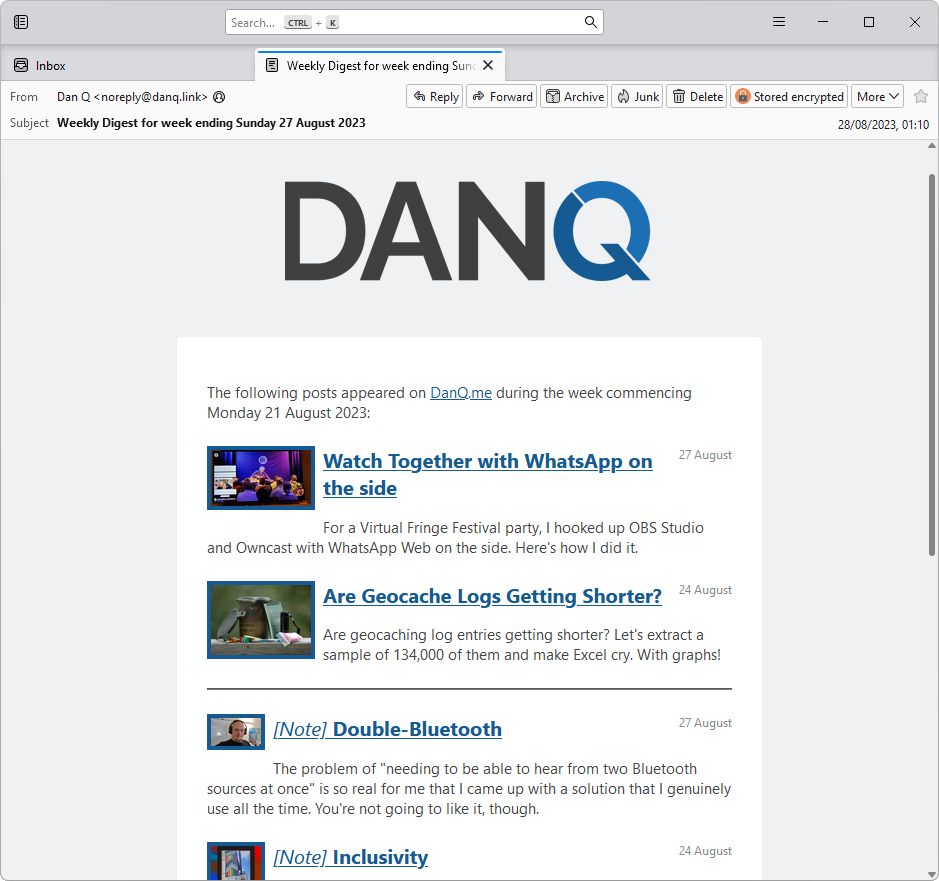
I assume that you knew that you can get an email, no more than once per day or once per week (your choice!) of what I get up to online, right? Email not your jam: there are plenty of other options too!
And because I learned a few things while doing so, I wrote this blog post so that next time I have to configure Postfix + DKIM, I’ll know where to find a guide. If it helps you in the meantime, that’s just a bonus.
If the first rule of computing is “never roll your own crypto” (based on Schneier’s Law), the second
rule might be “don’t run your own mailserver”. I don’t have a good picture to illustrate that, so here’s a photo of my dog playing tug-of-war.
Postfix
Running your own mailserver is a pain. I used to do it for all of my email, but – like many other nerds – when spam reached its peak and deliverability became an issue, I gave
up and oursourced it1.
Fun fact: when I’m at my desktop, I use a classic desktop email application for my personal email, like it’s the 90s or something2.
Luckily, I don’t need it to do much. I just need a mail transfer agent with an (unauthenticated, but local-only) SMTP endpoint: something that Listmonk can dump emails into, which will then reach out to the mailservers representing each of the recipients and
relay them on. A default install of Postfix does all that out-of-the-box, so I ran sudo apt install postfix, accepted all the default
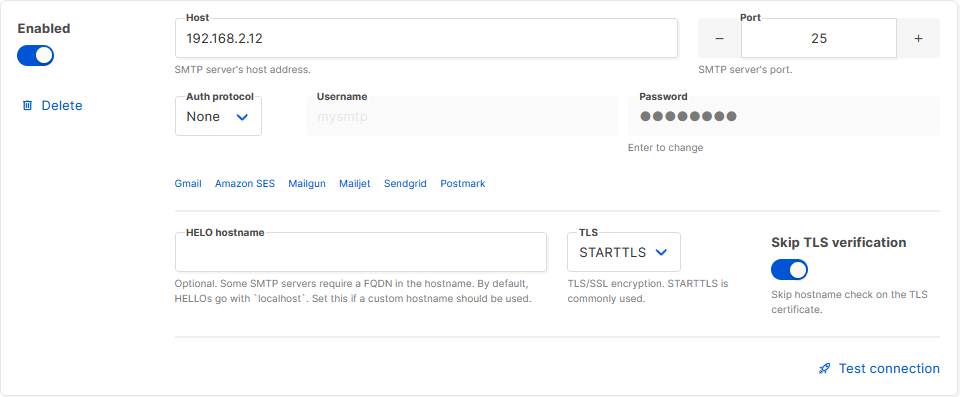
options, and put the details into Listmonk.
Listmonk makes adding an SMTP server very easy, and even includes a quick “test connection” link with which you can try
out your settings.
Next, I tweaked my DNS configuration to add an SPF record, and tested it.
This ought to have been enough to achieve approximate parity with what Gandi had been providing me with. Not bad.
You really can’t be doing without an SPF record as a minimum these days.
I sent a test email to a Gmail account, where I noticed two problems:
It turns out that since the last time I ran a mailserver “for real”, the use of TLS for inter-server communication has
become… basically mandatory. You don’t strictly have to do it, but if you don’t, some big email providers will put scary security warnings on your messages. This is a good thing.
The first problem was that Postfix on Debian isn’t configured by-default to use opportunistic TLS when talking to other
mailservers. That’s a bit weird, but I’m sure there’s a good reason for it. The solution was to add smtp_tls_security_level = may to my
/etc/postfix/main.cf.
The second problem was that without a valid DKIM signature on them, about half of my test emails were going straight to the
spam folder. Again, it seems that since the last time I seriously ran a mailserver 20 years ago, this has become something that isn’t strictly required… but your emails aren’t
going to get through if you don’t.
I’ve put it off this long, but I think it’s finally time for me to learn some practical DKIM.
Understanding DKIM
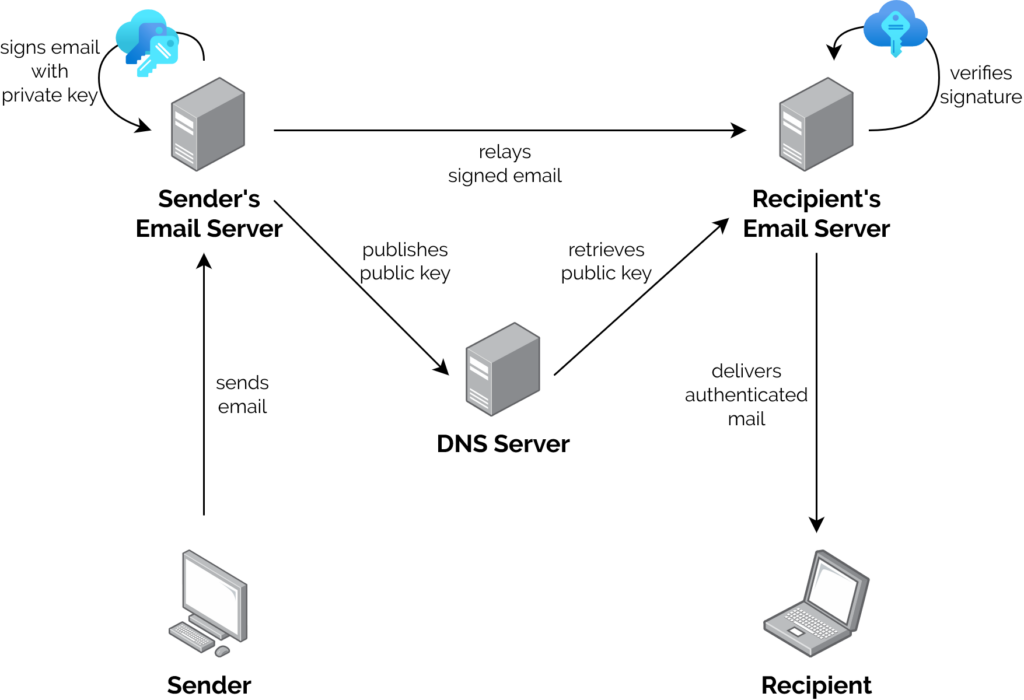
What’s DKIM, then?
I’ve already got an elementary understanding of how DKIM works, which I’ll summarise below.
A server that wants to send email from a domain generates a cryptographic keypair.
The public part of the key is published using DNS. The private part is kept securely on the server.
When the server relays mail on behalf of a user, it uses the private key to sign the message body and a stated subset of the headers3,
and attaches the signature as an email header.
When a receiving server (or, I suppose, a client) receives mail, it can check the signature by acquiring the public key via DNS and validating the signature.
In this way, a recipient can be sure that an email received from a domain was sent with the authorisation of the owner of that domain. Properly-implemented, this is a strong mitigation
against email spoofing.
OpenDKIM
To set up my new server to sign outgoing mail, I installed OpenDKIM and its keypair generator using sudo apt install opendkim
opendkim-tools. It’s configuration file at /etc/opendkim.conf needed the following lines added to it:
# set up a socket for Postfix to connect to:
Socket inet:12301@localhost
# set up a file to specify which IPs/hosts can send through us without authentication and get their messages signed:
ExternalIgnoreList refile:/etc/opendkim/TrustedHosts
InternalHosts refile:/etc/opendkim/TrustedHosts
# set up a file to specify which selector/domain are used to each incoming email address:
SigningTable refile:/etc/opendkim/SigningTable
# set up a file to specify which signing key to use for each selector/domain:
KeyTable refile:/etc/opendkim/KeyTable
Into /etc/opendkim/TrustedHosts I put a list of local IPs/domains that would have their emails signed by this server. Mine looks like this (in this example I’m using
example.com as my domain name, and default as the selector for it: the selector can be anything you like, it only matters if you’ve got multiple
mailservers signing mail for the same domain). Note that 192.168.0.0/16 is the internal subnet on which my sending VM will
run.
/etc/opendkim/SigningTable maps email addresses (I’m using a wildcard) to the subdomain whose TXT record will hold the public key for the signature. This also goes on to
inform the KeyTable which private key to use:
*@example.com default._domainkey.example.com
And then /etc/opendkim/KeyTable says where to find the private key for that:
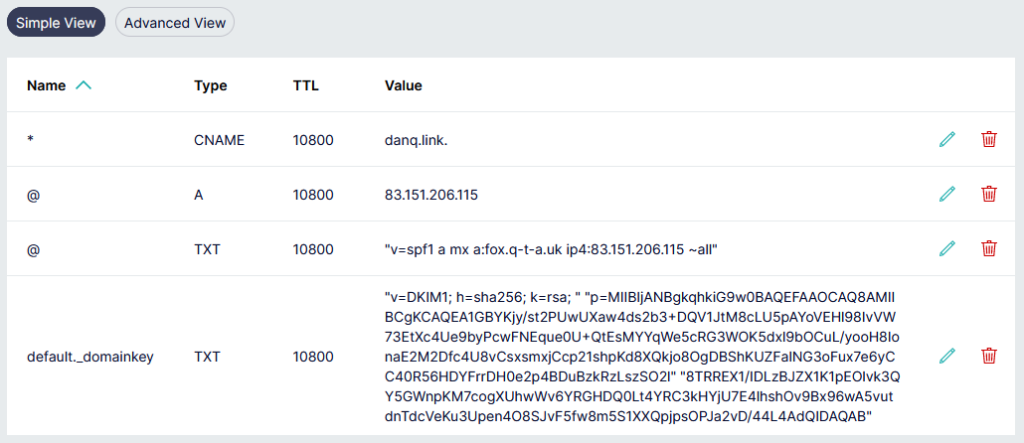
The public key needs publishing via DNS. Conveniently, when you create a keypair using its tools, OpenDKIM provides a sample (in
BIND-style) for you to copy-paste from or adapt: look in /etc/opendkim/keys/example.com/default.txt!
Gandi’s DNS “Simple View” is great for one-off and quick operations, but I really appreciate that they have a BIND-style syntax “Advanced View” for when I’m making bigger and
more-complex DNS configuration changes.
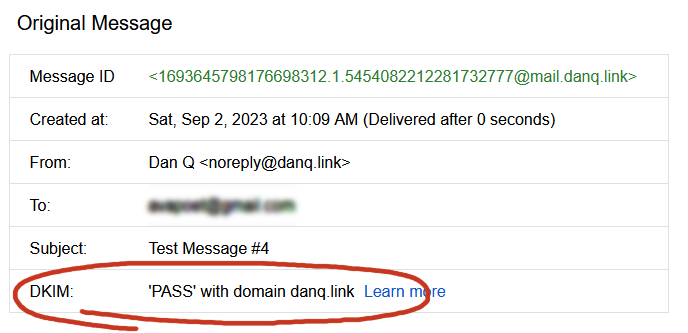
Once we’ve restarted both services (sudo service postfix restart; sudo service opendkim restart), we can test it!
Once the major email providers – who have the worst spam problem to deal with – say that your email signature looks good, you’re good.
So I learned something new today.
If you, too, love to spend your Saturday mornings learning something new, have a look at those subscription
options to decide how you’d like to hear about whatever I get up to next.
Footnotes
1 I still outsource my personal email, and I sing the praises of the excellent folks
behind ProtonMail.
2 My desktop email client also doubles as my newsreader, because, yes, of course
you can still find me on USENET. Which, by the way, is undergoing a mini-revival…
3 Why doesn’t DKIM sign
all the headers in an email? Because intermediary servers and email clients will probably add their own headers, thereby invalidating the signature! DKIM gets used to sign the From: header, for obvious reasons, and ought to be used for other headers whose tampering could be
significant such as the Date: and Subject:, but it’s really up to the signing server to choose a subset.
This weekend, I threw a Virtual Free Fringe
party for some friends. The party was under-attended, but it’s fine because I got to experiment
with some tech that I’d been meaning to try.
The Abnibbers and I have experimented with watching things together, but apart, before, but this is the first time we’ve watched stand-up comedy this way.
If you ever want to run something like this yourself1, here’s how I did it.
My goals were:
A web page at which any attendee could “watch together” a streaming video2,
A “chat” overlay, powered by a WhatsApp group3 (the friend group I
was inviting were all using WhatsApp anyway, so this was an obvious choice), and
To do all the above cheaply or for free.
I’m a big fan of experiments. Contrary to this picture, though, they’re usually software experiments.
There were two parts to this project:
Setting up a streaming server that everybody can connect to, and
Decorating the stream with a WhatsApp channel
Setting up a streaming server
Linode offers a free trial of $100 of hosting credit over 60 days and has a ready-to-go recipe for installing Owncast, an open-source streaming server I’ve
used before, so I used their recipe, opting for a 4GB dedicated server in their London datacentre: at $36/mo, there’d be no risk of running out of my free trial credit even if I failed
to shut down and delete the virtual machine in good time. If you prefer the command-line, here’s the API call for
that:
The IP address got assigned before the machine finished booting, so I had time to copy that into my DNS configuration so the domain was already pointing to the machine before it was fully running. This enabled it to get its SSL certificate set up rightaway (if not, I’d have had to finish waiting for the DNS change to propogate and then reboot it).
Out of the box, Owncast is insecure-by-default, so I wanted to jump in and change some passwords. For some reason you’re initially only able to correct this over unencrypted
HTTP! I opted to take the risk on this server (which would only be alive for a few hours) and just configure it with this
limitation, logging in at http://mydomain:8080/admin with the default username and password (admin / abc123), changing the credentials to
something more-secure. I also tweaked the configuration in general: setting the service name, URL, disabling chat features,
and so on, and generating a new stream key to replace the default one.
Now I was ready to configure OBS Studio to stream video to my new Owncast server, which would distribute it to anybody who tuned-in.
Next up, we need to make WhatsApp appear on the stream with a little bit of CSS hackery.
Decorating the stream
I configured OBS Studio with a “Custom…” stream service with server rtmp://mydomain:1935/live and the stream key I chose when configuring Owncast and kicked off a test
stream to ensure that I could access it via https://mydomain. I added a VLC source4
to OBS and fed it a playlist of videos, and added some branding.
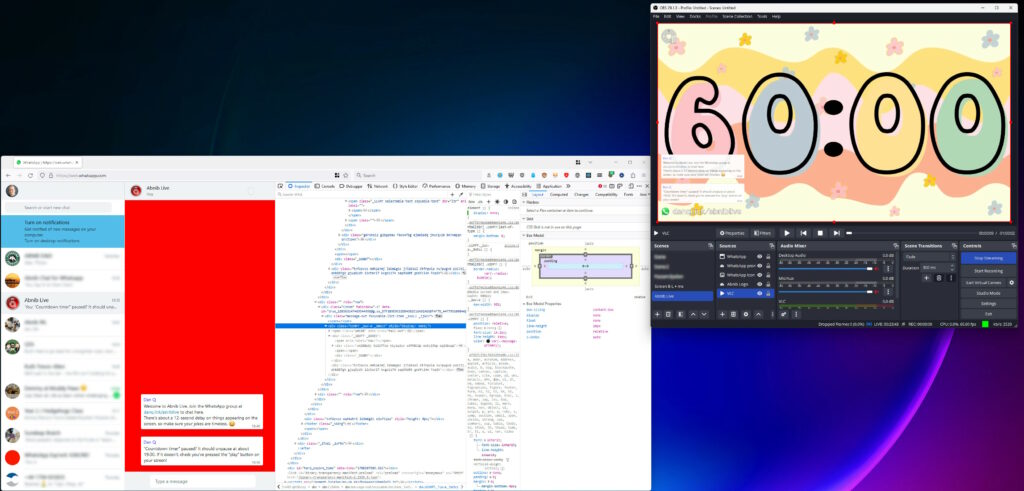
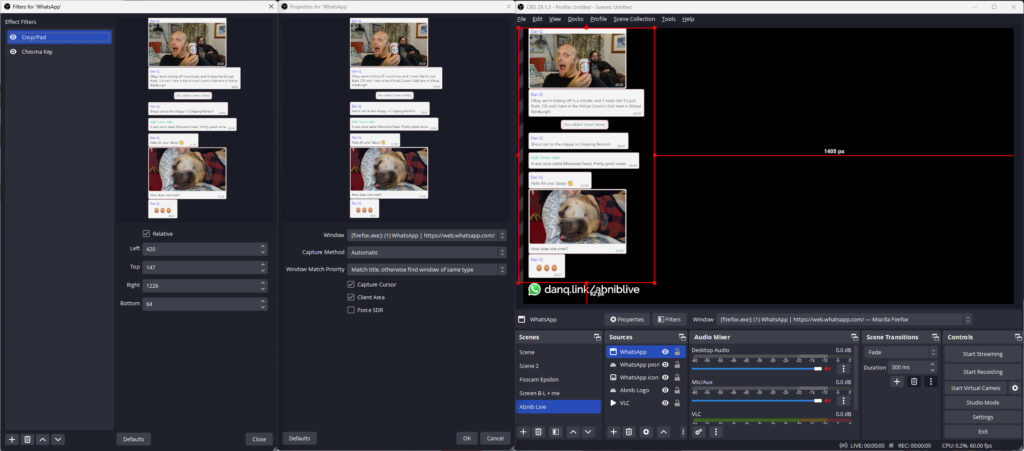
With that all working, I now needed a way to display the WhatsApp chat superimposed over the video.For this, I added a Window Capture source and pointed it at a Firefox window that was
showing a WhatsApp Web view of the relevant channel. I added a Crop/Pad filter to trim off the unnecessary chrome.
The same technique, of course, could be used to superimpose any web page or whatever other content you like onto a stream.
Next, I used the Firefox debugger “Style Editor” to inject some extra CSS into WhatsApp Web. The class names vary frequently, so
there’s no point we re-documenting all of them here, but the essence of the changes were:
Changing the chat background to a solid bright color (I used red) that can then be removed/made transparent using OBS’s Chroma Key filter. Because you have a good
solid color you can turn the Similarity and Smoothness way down.
Making all messages appear the same (rather than making my messages appear different from everybody else’s). To do this, I added:
.message-in, .message-out { align-items: flex-start !important; } to align them all to the left
[aria-label="You:"]::after { content: "Dan Q"; height: 15px !important; display: block; color: #00f !important; padding: 8px 0 0 8px; } to force my name to appear
even on my own messages
[aria-label^="Open chat details for "] { display: none; } to remove people’s avatars
[data-testid="msg-meta"] { display: none !important; } to remove message metadata
A hacky bit of CSS to make the backgrounds all white and to remove the speech bubble “tails”
Removing all the sending/received/read etc. icons with [data-icon] { display: none; }
I aimed where possible to exploit selectors that probably won’t change frequently, like [aria-label]s; this improves the chance that I can use the same code next time. I
also manually removed “old” messages from the channel that didn’t need to be displayed on the big screen. I wasn’t able to consistently remove “X new messages” notifications, but I’ll
probably try again another time, perhaps with the help of an injected userscript.
A little bit of a shame that more people didn’t get to see the results of this experiment, but I’m sure I’ll use the techniques I’ve learned on another ocassion.
Footnotes
1 Or, let’s be honest, if you’re Future Dan and you’re trying to remember how you did it
in last time.
3 This could probably be adapted for any other chat system that has a web interface, so if
you prefer Telegram or Slack or whatever ever, that’s fine.
4 OBS’s VLC source is just amazing: not only can you give it files, but you can give it
URLs, meaning that you can set up a playlist of YouTube videos, or RTSP security camera feeds, or pretty much anything else you feel like (and have the codecs for).
When geocachers find a geocache, they typically “log” their find both in the cache’s paper logbook and on one of the online listing sites on which the cache’s coordinates can be
found.1
A typical geocacher can find their cache container, logbook, swag, toothbrush, face flannel, soap, tin of biscuits, flask, compass, and most-importantly towel. Hang on, I’ve got my
geekeries crossed again. Photo courtesy cachemania, used under a CC BY-SA license.
I’ve been finding and hiding geocaches for… a long while, so I’ve
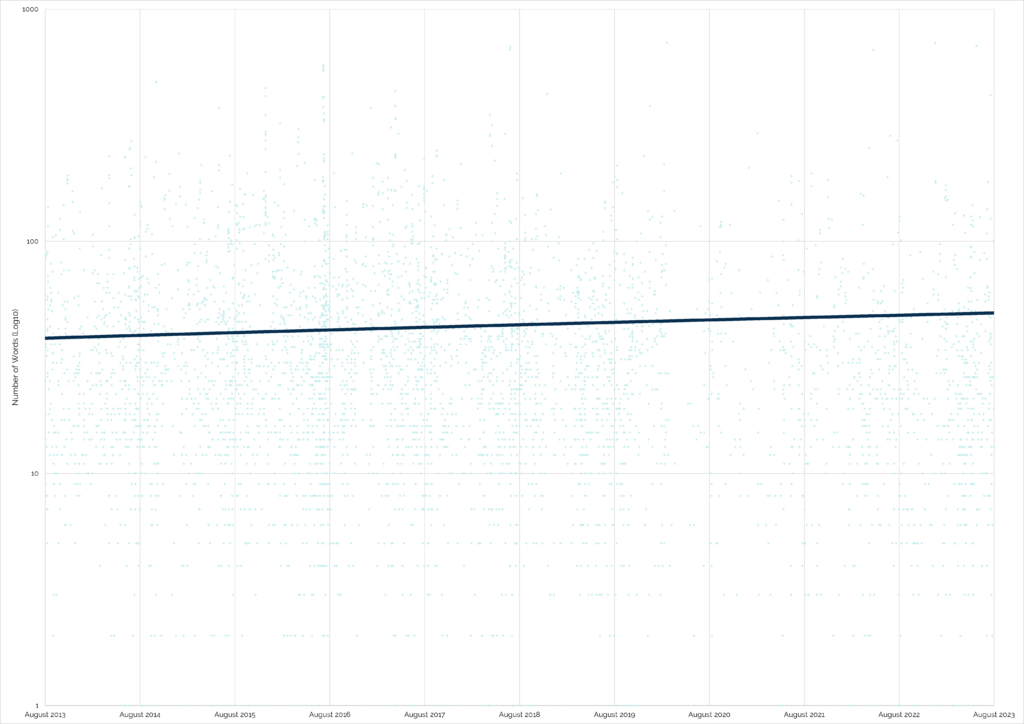
seen lots of log entries from people who’ve found my caches (and those of others). And it feels to me like the average length of a
geocaching log entry is getting shorter.
A single emoji is probably the shortest log entry I’ve ever seen. I’m
not claiming that its
cachedeserves a longer log (it’s far from my best work!): just using it as an example of a wider trend towards shorter logs.
“It feels to me like…” isn’t very scientific, though. Let’s see if we can do better.
Getting the data
To test my hypothesis, I needed a decade or so of logs. I didn’t want to compare old caches to new caches (in case people are biased by the logs before them) so I used Geocaching.com’s
own search to open the pages for the 500 caches closest to me that are each at least 10 years old.
My browser hates me right now.
I hacked together a quick
userscript to save all of the logs in a way that was easier than copy-pasting each of them but still didn’t involve hitting Geocaching.com’s API or automating bulk-scraping (which would violate their terms of service). Clicking each of several hundred tabs once every few minutes in
the background while I got on with other things wasn’t as much of an ordeal as you might think… but it did take a while.
Needless to say I only had to go through the cycle a couple of times before I set up a keyboard shortcut.
I mashed that together into a CSV file and for the first time looked at the size of my sample data: ~134,000 log entries,
spanning 20 years. I filtered out everything over 10 years old (because some of the caches might have no logs that old) and stripped out everything that wasn’t a “found it” or “didn’t
find it” log.
That gave me a far more-reasonable ~80,000 records with which I could make Excel cry.2
Results
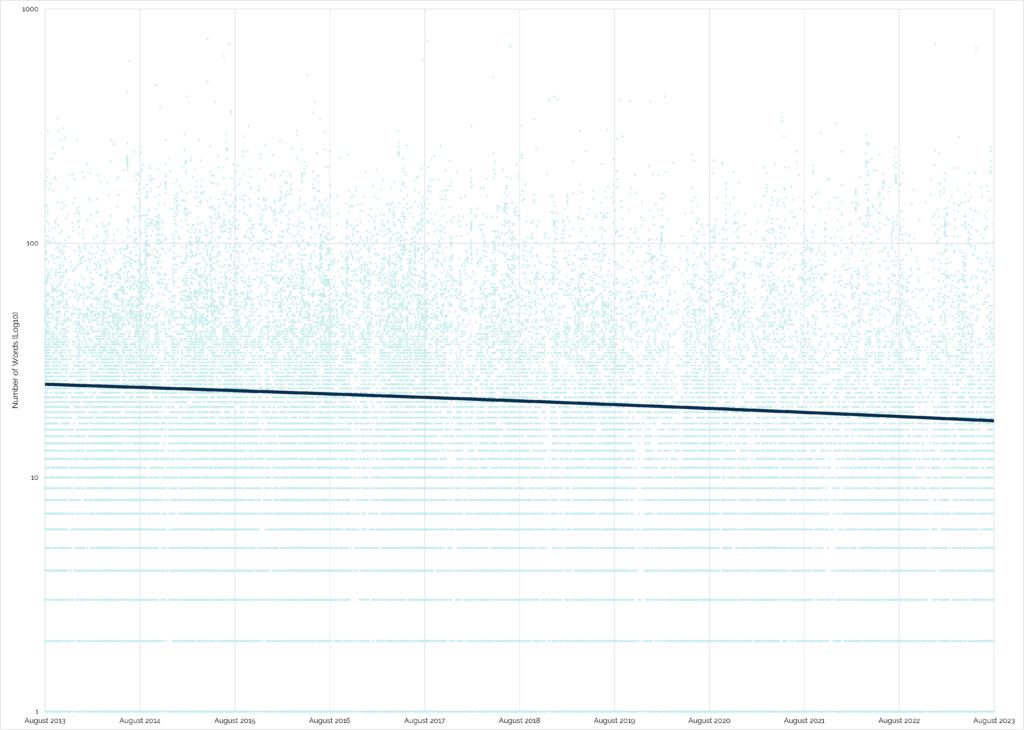
It looks like my hunch is right. The wordcount of “found” logs on traditional and multi-stage caches has generally decreased over time:
“Found” logs are great for cache owner morale: a simple “TFTC” is a lot less-inspiring that hearing about your adventure to get
to that point.
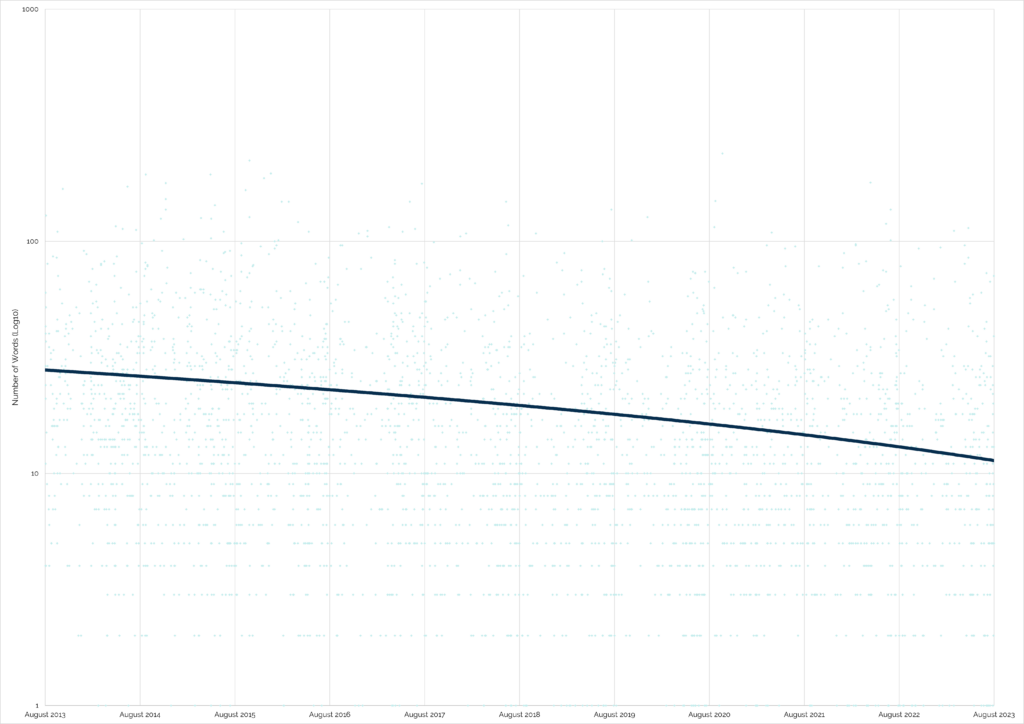
“Did not find” logs, which can be really helpful for cache owners to diagnose problems with their caches, have an even more-pronounced dip:
Geocachers are just typing “Didn’t find it” and moving on. Without an indication of the conditions at the GZ, how long they spent
looking, or an indication of whether the hint was followed, that doesn’t give a cache owner much to work with.
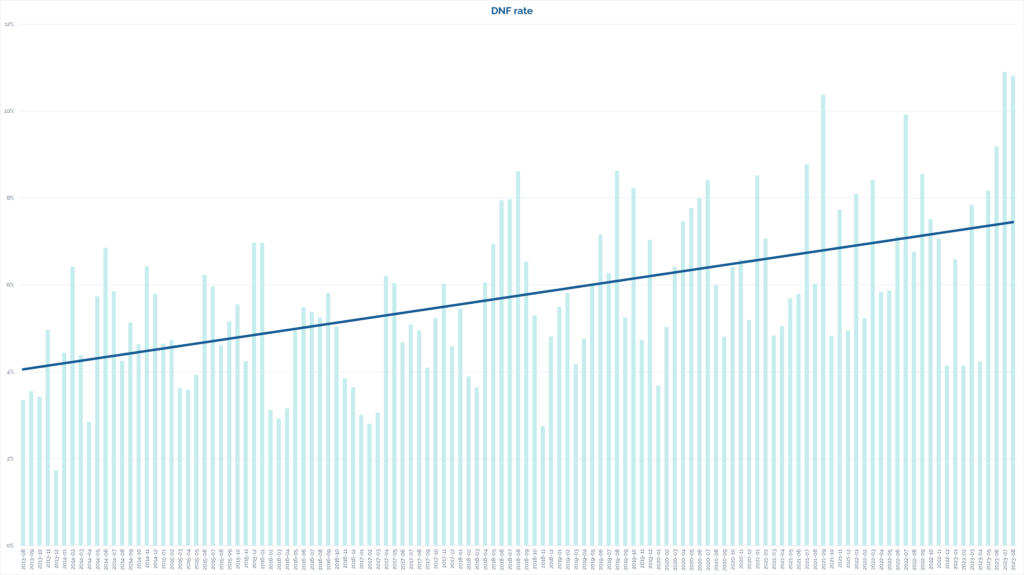
When I first saw that deep dip on the average length of “did not find” logs, my first thought was to wonder whether the sample might not be representative because the did-not-find rate
itself might have fallen over time. But no: the opposite is true:
A higher proportion than ever of geocachers are logging that they couldn’t find the cache, but they’re simultaneously saying less than ever about it.
Strangely, the only place that the trend is reversed is in “found” logs of virtual caches, which have seen a slight increase in verbosity.
I initially assumed that this resulted from “virtual
rewards” from 2017 onwards3
but this doesn’t make any sense because all of the caches in my study are 10+ years old: none of them can be “virtual rewards”.
Conclusion
Within the limitations of my research (80,000 logs from 500 caches each 10+ years old, near me), there are a handful of clear trends over the last decade:
Geocachers are leaving increasingly concise logs when they find geocaches.
That phenomenon is even more-pronounced when they don’t find them.
And they’re failing-to-find caches and giving up with significantly greater frequency.
Are these trends a sign of shortening attention spans? Increased use of mobile phones for logging? Use of emoji and acronyms to pack more detail into shorter messages? I don’t know.
I’d love to see some wider research, perhaps by somebody at Geocaching.com HQ (who has database access and is thus able to easily extract
enough data for a wider analysis!). I’m also very interested in whether the identity of the cache finder has an impact on log length: is it impacted by how long ago they
started ‘caching? Whether or not they have hidden caches of their own? How many caches they’ve found?
But personally, I’m just pleased to have been able to have a question in the back of my mind and – through a little bit of code and a little bit of data-mashing – have a pretty good go
at answering it.
Footnotes
1 I have a dream that someday cache logging could be powered by Webmentions or ActivityPub or some similar decentralised-Web technology, so that cachers can log their finds on any site on which a cache is listed or even
on their own site and have all the dots joined-up… but that’s pretty far-fetched I’m afraid. It’s not stopping some of us from experimenting
with possible future standards, though…
2 Just for fun, try asking Excel to extrapolate a second-order polynomial trendline across
80,000 pairs of datapoints. Just don’t do it if you’re hoping to use your computer for anything in the next quarter hour.
3 With stricter guidelines on how a “virtual rewards” virtual caches should work than
existed for original pre-2005 virtuals, these new virtuals are more-likely than their predecessor to encourage or require longer logs.
The week before last, Katie shared with me that article from last month, Who killed Google Reader? I’d read it before so I
didn’t bother clicking through again, but we did end up chatting about RSS a bit1.
I ditched Google Reader several years before its untimely demise, but I can confirm “461 unread items” was a believable message.
Katie “abandoned feeds a few years ago” because they were “regularly ending up with 200+ unread items that felt overwhelming”.
Conversely: I think that dropping your feed reader because there’s too much to read is… solving the wrong problem.
About half way through editing this image I completely forgot what message I was trying to convey, but I figured I’d keep it anyway and let you come up with your own
interpretation.
I think that he, like Katie, might be looking at his reader in a different way than I do mine.
At time of writing, I’ve got 567 unread items. And that’s fine.
RSS is not email!
I’ve been in the position that Katie and David describe: of feeling overwhelmed by the sheer volume of unread items. And I know others have, too. So let me share something I’ve learned
sooner:
There’s nothing special about reaching Inbox Zero in your feed reader.
It’s not noble nor enlightened to get to the bottom of your “unread” list.
Your 👏 feed 👏 reader 👏 is 👏 not 👏 an 👏 email 👏 client. 👏
The idea of Inbox Zero as applied to your email inbox is about productivity. Any message in your email might be something that requires urgent action, and you
won’t know until you filter through and categorise .
But your RSS reader doesn’t (shouldn’t?) be there to add to your to-do list. Your RSS reader is a list of things you might like to read. In an ideal world, reaching “RSS Zero” would mean that you’ve seen everything on the Internet that you might
enjoy. That’s not enlightened; that’s sad!
Google Reader understood this, although the word “congratulations” was misplaced.
Use RSS for joy
My RSS reader is a place of joy, never of stress. I’ve tried to boil down the principles that makes it so, and here they are:
Zero is not the target.
The numbers are to inspire about how much there is “out there” for you, not to enumerate how much work need have to do.
Group your feeds by importance.
Your feed reader probably lets you group (folder, tag…) your feeds, so you can easily check-in on what you care about and leave other feeds for a rainy day.2 This is good.
Don’t read every article.
Your feed reader gives you the convenience of keeping content in one place, but you’re not obligated to read every single one. If something doesn’t interest you, mark it
as read and move on. No judgement.
Keep things for later.
Something you want to read, but not now? Find a way to “save for later” to get it out of your main feed so you. Don’t have to scroll past it every day! Star it or tag
it3 or push it to your link-saving or note-taking app. I use a
link shortener which then feeds back into my feed reader into a “for later” group!
Let topical content expire.
Have topical/time-dependent feeds (general news media, some social media etc.)? Have reader “purge” unread articles after a time. I have my subscription to BBC News headlines expire after 5 days: if I’ve taken that long to
read a headline, it might as well disappear.4
Use your feed reader deliberately.
You don’t need popup notifications (a new article’s probably already up to an hour stale by the time it hits your reader). We’re all already slaves to
notifications! Visit your reader when it suits you. I start and end every day in mine; most days I hit it again a couple of other times. I don’t need a notification: there’s always new
content. The reader keeps track of what I’ve not looked at.
It’s not just about text.
Don’t limit your feed reader to just text. Podcasts are nothing more than RSS feeds with attached
audio files; you can keep track in your reader if you like. Most video platforms let you subscribe to a feed of new videos on a channel or playlist basis, so you can e.g. get notified about YouTube channel updates without having to fight with The
Algorithm. Features like XPath Scraping in FreshRSS let you subscribe to services that
don’t even have feeds: to watch the listings of dogs on local shelter websites when you’re looking to adopt, for example.
Do your reading in your reader.
Your reader respects your preferences: colour scheme, font size, article ordering, etc. It doesn’t nag you with newsletter signup popups, cookie notices, or ads. Make the
most of that. Some RSS feeds try to disincentivise this by providing only summary content, but a good feed reader can work
around this for you, fetching actual content in the background.5
Use offline time to catch up on your reading.
Some of the best readers support offline mode. I find this fantastic when I’m on an aeroplane, because I can catch up on all of the interesting articles I’d not
had time to yet while grounded, and my reading will get synchronised when I touch down and disable flight mode.
Make your reader work foryou.
A feed reader is a tool that works for you. If it’s causing you pain, switch to a different tool6,
or reconfigure the one you’ve got. And if the way you find joy from RSS is different from me, that’s fine: this is
a personal tool, and we don’t have to have the same answer.
2 If your feed reader doesn’t support any kind of grouping, get a better reader.
3 If your feed reader doesn’t support any kind of marking/favouriting/tagging of articles,
get a better reader.
4 If your feed reader doesn’t support customisable expiry times… well that’s not too
unusual, but you might want to consider getting a better reader.
5 FreshRSS calls the feature that fetches actual post content from the resulting page
“Article CSS selector on original website”, which is a bit of a mouthful, but you can see what it’s doing. If your feed reader doesn’t support fetching full content… well, it’s
probably not that big a deal, but it’s a good nice-to-have if you’re shopping around for a reader, in my opinion.
6 There’s so much choice in feed readers, and migrating between them is (usually)
very easy, so everybody can find the best choice for them. Feedly, Inoreader, and The Old Reader are popular, free, and easy-to-use if you’re looking to get started. I prefer a selfhosted tool so I use the amazing FreshRSS (having migrated from Tiny Tiny RSS). Here’s some more tips on getting started. You might prefer a desktop or
mobile tool, or even something exotic: part of the beauty of RSS feeds is they’re open and interoperable, so if for example
you love using Slack, you can use Slack to push feed updates to you and get almost all the features you need to do everything in my list, including grouping (using
channels) and saving for later (using Slackbot/”remind me about this”). Slack’s a perfectly acceptable feed reader for some people!
I’ve made a handful of tweaks to my RSS feed which I feel improves upon
WordPress’s default implementation, at least in my use-case.1 In case any of these improvements help
you, too, here’s a list of them:
Post Kinds in Titles
Since 2020, I’ve decorated post titles by prefixing them with the “kind” of post they are (courtesy of the Post Kinds
plugin). I’ve already written about how I do it, if you’re
interested.
Identifying post kinds is particularly useful for people who subscribe by
email (the emails are generated off the RSS feed either daily or weekly: subscriber’s choice), who might want to see
articles and videos but not care about for example checkins and reposts.
RSS Only posts
A minority of my posts are – initially, at least – publicised only via my RSS feed (and places that are directly fed
by it, like email subscribers). I use a tag to identify posts to be hidden in this way. I’ve
written about my implementation before, but I’ve since made a couple of additional improvements:
Suppressing the tag from tag clouds, to make it harder to accidentally discover these posts by tag-surfing,
Tweaking the title of such posts when they appear in feeds (using the same technique as above), so that readers know when they’re seeing “exclusive” content, and
Setting a X-Robots-Tag: noindex, nofollow HTTP header when viewing such tag or a post, to discourage
search engines (code for this not shown below because it’s so very specific to my theme that it’s probably no use to anybody else!).
// 1. Suppress the "rss club" tag from tag clouds/the full tag listfunctionrss_club_suppress_tags_from_display( string $tag_list, string $before, string $sep, string $after, int $post_id ): string {
foreach(['rss-club'] as$tag_to_suppress){
$regex=sprintf( '/<li>[^<]*?<a [^>]*?href="[^"]*?\/%s\/"[^>]*?>.*?<\/a>[^<]*?<\/li>/', $tag_to_suppress );
$tag_list=preg_replace( $regex, '', $tag_list );
}
return$tag_list;
}
add_filter( 'the_tags', 'rss_club_suppress_tags_from_display', 10, 5 );
// 2. In feeds, tweak title if it's an RSS exclusivefunctionrss_club_add_rss_only_to_rss_post_title( $title ){
$post_tag_slugs=array_map(function($tag){ return$tag->slug; }, wp_get_post_tags( get_the_ID() ));
if ( !in_array( 'rss-club', $post_tag_slugs ) ) return$title; // if we don't have an rss-club tag, drop out herereturn trim( "{$title} [RSS Exclusive!]" );
return$title;
}
add_filter( 'the_title_rss', 'rss_club_add_rss_only_to_rss_post_title', 6 );
Adding a stylesheet
Adding a stylesheet to your feeds can make them much friendlier to beginner users (which helps drive adoption) without making them much less-convenient for people who know how
to use feeds already. Darek Kay and Terence Eden both wrote great articles about this just
earlier this year, but I think my implementation goes a step further.
In addition to adding some “Q” branding, I made tweaks to make it work seamlessly with both my RSS and Atom feeds by using
two<xsl:for-each> blocks and exploiting the fact that the two standards don’t overlap in their root namespaces. Here’s my full XSLT; you need to
override your feed template as Terence describes to use it, but mine can be applied to both RSS and Atom.2
I’ve still got more I’d like to do with this, for example to take advantage of the thumbnail images I attach to posts. On which note…
Thumbnail images
When I first started offering email subscription options I used Mailchimp’s RSS-to-email service, which was… okay,
but not great, and I didn’t like the privacy implications that came along with it. Mailchimp support adding thumbnails to your email template from your feed, but WordPress themes don’t
by-default provide the appropriate metadata to allow them to do that. So I installed Jordy Meow‘s RSS Featured Image plugin which did it for me.
<item><title>[Checkin] Geohashing expedition 2023-07-27 51 -1</title><link>https://danq.me/2023/07/27/geohashing-expedition-2023-07-27-51-1/</link>
...
<media:contenturl="https://bcdn.danq.me/_q23u/2023/07/20230727_141710-1024x576.jpg"medium="image"/><media:description>Dan, wearing a grey Three Rings hoodie, carrying French Bulldog Demmy, standing on a path with trees in the background.</media:description></item>
Media attachments for RSS feeds are perhaps most-popular for podcasts, but they’re also great for post thumbnail images.
During my little redesign earlier this year I decided to go two steps further: (1) ditching the
plugin and implementing the functionality directly into my theme (it’s really not very much code!), and (2) adding not only a <media:content medium="image" url="..."
/> element but also a <media:description> providing the default alt-text for that image. I don’t know if any feed readers (correctly) handle this
accessibility-improving feature, but my stylesheet above will, some day!
So there we have it: a little digital gardening, and four improvements to WordPress’s default feeds.
RSS may not be as hip as it once was, but little improvements can help new users find their way into this (enlightened?) way
to consume the Web.
If you’re using RSS to follow my blog, great! If it’s not for you, perhaps pick your favourite alternative way to get updates, from options including email, Telegram, the Fediverse (e.g. Mastodon), and more…
1 The changes apply to the Atom
feed too, for anybody of such an inclination. Just assume that if I say RSS I’m including Atom, okay?
2 The experience of writing this transformation/stylesheet also gave me yet another opportunity to remember how much I hate working
with XSLTs. This time around, in addition to the normal namespace issues and headscratching syntax, I
had to deal with the fact that I initially tried to use a feature from XSLT version 2.0 (a 22-year-old
version) only to discover that all major web browsers still only support version 1.0 (specified last millenium)!
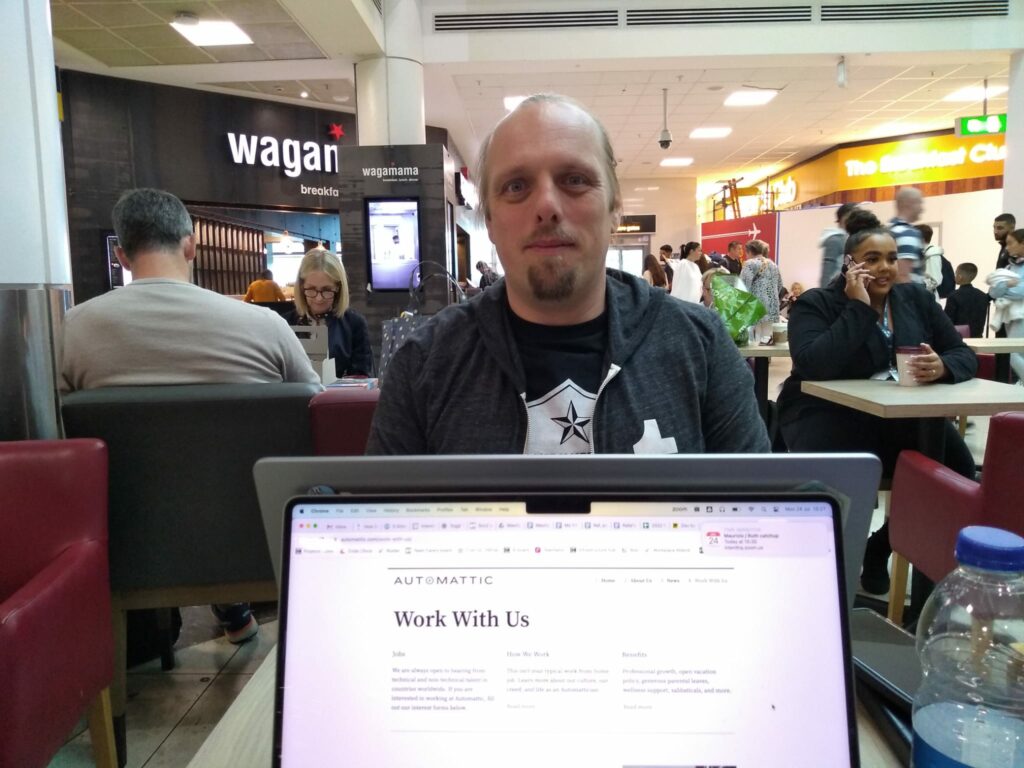
We’d intended to actually go to the Isle of Man, even turning up at Gatwick Airport six hours before our flight and working at Pret in order to optimally fit around our
workdays.
It’s (approximately) our 0x10th anniversary1,
and, struggling to find a mutually-convenient window in our complex work schedules, we’d opted to spend a few days exploring the Isle of Man. Everything was fine, until we were aboard
the ‘plane.
As the last few passengers were boarding, putting their bags into overhead lockers, and finding their seats, Ruth observed that out on the tarmac, bags were being removed
from the aircraft.
Once everybody was seated and ready to take off, the captain stood up at the front of the ‘plane and announced that it had been cancelled2.
The Isle of Man closes, he told us (we assume he just meant the airport) and while they’d be able to get us there before it did, there wouldn’t be sufficient air traffic
control crew to allow them to get back (to, presumably, the cabin crews’ homes in London).
To add insult to injury: even though the crew clearly knew that the ‘plane would be cancelled before everybody boarded, they waited until we were all aboard to tell us then
made us wait for the airport buses to come back to take us back to the terminal.
Back at the terminal we made our way through border control (showing my passport despite having not left the airport, never mind the country) and tried to arrange a rebooking,
only to be told that they could only manage to get us onto a flight that’d be leaving 48 hours later, most of the way through our mini-break, so instead we opted for a refund and gave
up.3
After dinner at the reliably-good Ye Old Six
Bells in Horley, down the road from Gatwick Airport, we grumpily made our way back home.
We resolved to try to do the same kinds of things that we’d hoped to do on the Isle of Man, but closer to home: some sightseeing, some walks, some spending-time-together. You know the
drill.
There’s evidence on the Isle of Man of Roman occupation from about the 1st century BCE through the 5th century CE, so we found a
local Roman villa and went for a look around.
A particular highlight of our trip to the North Leigh Roman Villa – one of those “on your doorstep so you never go” places – was when the audio tour advised us to beware of the snails
when crossing what was once the villa’s central courtyard.
At first we thought this was an attempt at humour, but it turns out that the Romans brought with them to parts of Britain a variety of large edible snail – helix pomatia –
which can still be found in concentration in parts of the country where they were widely farmed.4
Once you know you’re looking for them, these absolute unit gastropods are easy to spot.
There’s a nice little geocache near the ruin, too, which we were able to find on our way back.
Before you think that I didn’t get anything out of my pointless hours at the airport, though, it turns out I’d brought home a souvenier… a stinking cold! How about that for efficiency:
I got all the airport-germs, but none of the actual air travel. By mid-afternoon on Tuesday I was feeling pretty rotten, and it only got worse from then on.
I felt so awful on Wednesday that the most I was able to achieve was to lie on the sofa feeling sorry for myself, between sessions of The Legend of Zelda: Tears of the
Kingdom.
I’m confident that Ruth didn’t mind too much that I spent Wednesday mostly curled up in a sad little ball, because it let her get on with applying to a couple of jobs she’s interested
in. Because it turns out there was a third level of disaster to this week: in addition to our ‘plane being cancelled and me getting sick, this week saw Ruth made redundant as her
employer sought to dig itself out of a financial hole. A hat trick of bad luck!
Sniffle. Ugh.
As Ruth began to show symptoms (less-awful than mine, thankfully) of whatever plague had befallen me, we bundled up in bed and made not one but two abortive attempts at watching a film
together:
Spin Me Round, which looked likely to be a simple comedy that wouldn’t require much effort
by my mucus-filled brain, but turned out to be… I’ve no idea what it was supposed to be. It’s not funny. It’s not dramatic. The characters are, for the most part, profoundly
uncompelling. There’s the beginnings of what looks like it was supposed to be a romantic angle but it mostly comes across as a creepy abuse of power. We watched about half and gave
up.
Ant-Man and the Wasp:
Quantumania, because we figured “how bad can a trashy MCU sequel be anyway; we know what to expect!” But we
couldn’t connect to it at all. Characters behave in completely unrealistic ways and the whole thing feels like it was produced by somebody who wanted to be making one of the
new Star Wars films, but with more CGI. We watched about half and gave up.
As Thursday drew on and the pain in my head and throat was replaced with an unrelenting cough, I decided I needed some fresh air.
The dog needed a walk, too, which is always a viable excuse to get out and about.
I find myself wondering if (despite three jabs and a previous infection) I’ve managed to contract covid again, but I haven’t found the inclination to take a test. What would I do differently if I do have it, now, anyway? I feel like we
might be past that point in our lives.
All in all, probably the worst anniversary celebration we’ve ever had, and hopefully the worst we’ll ever have. But a fringe benefit of a willingness to change bases is that we can
celebrate our 10th5 anniversary next year, too.
Here’s to that.
Footnotes
1 Because we’re that kind of nerds, we count our anniversaries in base 16
(0x10 is 16), or – sometimes – in whatever base is mathematically-pleasing and gives us a nice round number. It could be our 20th anniversary, if you prefer octal.
2 I’ve been on some disastrous aeroplane journeys before, including one just earlier this
year which was supposed to take me from Athens to Heathrow, got re-arranged to go to Gatwick, got
delayed, ran low on fuel, then instead had to fly to Stansted, wait on the tarmac for a couple of hours, then return to Gatwick (from which I travelled – via Heathrow –
home). But this attempt to get to the Isle of Man was somehow, perhaps, even worse.
3 Those who’ve noticed that we were flying EasyJet might rightly give a knowing nod at
this point.
4 The warning to take care not to tread on them is sound legal advice: this particular
variety of snail is protected under the Wildlife and Countryside Act 1981!
5 Next year will be our 10th anniversary… in base 17. Eww, what the hell is base 17 for
and why does it both offend and intrigue me so?
There’s a perception that a blog is a long-lived, ongoing thing. That it lives with and alongside its author.1
But that doesn’t have to be true, and I think a lot of people could benefit from “short-term” blogging. Consider:
Photoblogging your holiday, rather than posting snaps to social media
You gain the ability to add context, crosslinking, and have permanent addresses (rather than losing eveything to the depths of a feed). You can crosspost/syndicate to your favourite
socials if that’s your poison..
Photoblog your holiday and I might follow it, and I’ll do so at my convenience. Put your snaps on Facebook and I almost certainly won’t bother. Photo courtesy ArtHouse Studio.
Blogging your studies, rather than keeping your notes to yourself
Writing what you learn helps you remember it; writing what you learn in a public space helps others learn too and makes it easy to search for your discoveries later.2
Recording your roleplaying, rather than just summarising each session to your fellow players
My D&D group does this at levellers.blog! That site won’t continue to be updated forever – the party will someday retire or, more-likely, come to a glorious but horrific end – but
it’ll always live on as a reminder of what we achieved.
One of my favourite examples of such a blog was 52 Reflect3 (now integrated into its successor The Improbable Blog). For 52 consecutive weeks my partner‘s brother Robin
blogged about adventures that took him out of his home in London and it was amazing. The project’s finished, but a blog was absolutely the right medium for it because now it’s got a
“forever home” on the Web (imagine if he’d posted instead to Twitter, only for that platform to turn into a flaming turd).
I don’t often shill for my employer, but I genuinely believe that the free tier on WordPress.com is an excellent
way to give a forever home to your short-term blog4.
Did you know that you can type new.blog (or blog.new; both work!) into your browser to start one?
What are you going to write about?
Footnotes
1This blog is, of course, an example of a long-term blog. It’s been going in
some form or another for over half my life, and I don’t see that changing. But it’s not the only kind of blog.
2 Personally, I really love the serendipity of asking a web search engine for the solution
to a problem and finding a result that turns out to be something that I myself wrote, long ago!
4 One of my favourite features of WordPress.com is the fact that it’s built atop the
world’s most-popular blogging software and you can export all your data at any time, so there’s absolutely no lock-in: if you want to migrate to a competitor or even host your own
blog, it’s really easy to do so!