It all started when I saw no-ht.ml, Terence Eden‘s hilarious response to Salma Alam-Naylor‘s excellent HTML is all you need to make a website. The latter is an argument against both the silly amount of JavaScript with which websites routinely burden their users, but also even against depending on CSS. As a fan of CSS Naked Day and a firm believer in using JS only for progressive enhancement, I’m obviously in favour.

Terence’s site works by delivering a document with a
claimed MIME type of text/html, but which contains only the (invalid) “HTML” code
<!doctype UNICODE><meta charset="UTF-8"><plaintext> (to work around browsers’ wish to treat the page as HTML). This is followed by a block of UTF-8 plain text making use of spacing
and emoji to illustrate and decorate the content. It’s frankly very silly, and I love it.1
I think it’s possible to go one step further, though, and create a web page with no code whatsoever. That is, one that you can read as if it were a regular web page, but where
using View Source or e.g. downloading the page with curl will show you… nothing.
I present: The Page With No Code! (It’ll probably only work if you’re using Firefox, for reasons that will become apparent later.)

Once you’ve had a look for yourself and had a chance to form an opinion, here’s an explanation of the black magic that makes this atrocity possible:
- The page is blank. It’s delivered with
Content-Type: text/html. Your browser interprets a completely-blank page as faulty and corrects it to a functionally-blank minimal HTML page:<html><head></head><body></body></html>. -
<body>and<html>elements can be styled with CSS; this includes the ability to add content:::beforeand::aftereach element. If only we could load a stylesheet then content injection is possible. - We use the fourth way to inject
CSS – a
Link:HTTP header – to deliver a CSS payload (this, unfortunately, only works in Firefox). To further obfuscate what’s happening and remove the need for a round-trip, this is encoded as a data: URI.
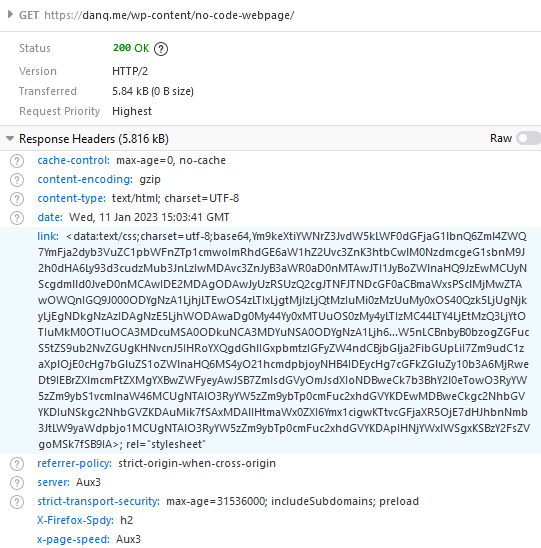
This is one of the most disgusting things I’ve ever coded, and that’s saying a lot. I’m so proud of myself. You can view the code I used to generate this awful thing on Github.
My server-side implementation of this broke in 2023 after I upgraded Nginx; my new version doesn’t support the super-long Link: header needed
to make this hack work, so I’ve updated the page to use the Link: to reference the CSS file rather than embed it via a data URI. It’s not as cool, but it at least means you can
still see the page. Thanks to Thomas Bradshaw for pointing out the problem.
Footnotes
1 My first reaction was “why not just deliver something with Content-Type:
text/plain; charset=utf-8 and dispense with the invalid code, but perhaps that’s just me overthinking the non-existent problem.
Some html for you page with no html.
This text is bold.
Sure thing, but this isn’t the page with no HTML. This is a blog post about the page with no HTML!
Lol, Firefox *barely* supports this. If you go into the inspector and try to get any information about the stylesheet that it loaded from the `link` header, it summarily crashes.
Strange! The inspector works fine for me! Tested using latest Firefox on Linux, Mac, and Windows.
This Article was mentioned on old.reddit.com
Read more →
Dear GOD/GODS and/or anyone else who can HELP ME (e.g. TIME TRAVELERS or MEMBERS OF SUPER-INTELLIGENT ALIEN CIVILIZATIONS):
The next time I wake up, please change my physical form to that of FINN MCMILLAN formerly of SOUTH NEW BRIGHTON at 8 YEARS OLD and keep it that way FOREVER.
I am so sick of this chubby Asian man body!
Thank you!
– CHAUL JHIN KIM (a.k.a. A DESPERATE SOUL)
Terence Eden wrote about his recent experience of IndieWebCamp Brighton, in which he mentioned that somebody – probably Jeremy Keith – had said, presumably to provoke discussion: A blog post doesn’t need a title. Terence disagrees, saying: In a literal sense, he was wrong. The HTML specification
Read more →