Finishing my morning walk where, perhaps, I should have started it with the first cache in this enjoyable series. Took a while for a good GPSr fix and I walked up and down the path a few times before spotting the container. But then – disaster – this replaced cache has a brand new log book… and I’ve
dropped my caching pencil somewhere between the last cache and this one. Unable to sign log, but hopefully attached picture showing CO’s replacement message will suffice.
TFTC, and the series in general. So glad to be able to take this lovely walk from Fairlawns this year. FP
awarded here for the series in general.
Distracted by the cattle eating their breakfast and the increasingly beautiful sunrise, almost forgot to look for this cache. Read the hint but still didn’t have a clue until I spotted
something out-of-place in a field. Sure enough, it was the cache. Nice hide! TFTC.
Sunrise taking off in earnest now with reds and pinks on the horizon, and my spine – unhappy for sleeping in an unfamiliar bed last night – is enjoying getting a stretch from the walk,
too. Stared right at this cache for a moment thinking “well that’s where I would hide it, but would the CO” before reaching to check and,
yup, putting my hand right on it. Now on through the cattle field!
I can see why the previous log moved this cache; pleased to see you be a good hiding place on the other side. Also pleased this wasn’t another nano! Light’s grown enough now to add a
smiley selfie from the path. Greetings from Oxfordshire, and TFTC!
Got carried away with my walk and briefly overshot this one: realised as I reached the quarry road. Turned back and found the cache in the third place I looked. Said hi to a rabbit and
the horses, up and foraging for their breakfast in the early light, before moving on.
This morning’s caching expedition just has it in for my back, I fear, with this one no exception. Nonetheless, a QEF in the first place I looked. TFTC!
A nonprofit I volunteer with has, years ago, held our Christmas bash at the nearby Fairlawns Hotel. We haven’t been in several years and –
even though we missed Christmas itself by a full month! – decided to return here this year.
I’m often an early riser, especially when away from home, and enjoy making the most of the first light with a walk. Last time I was here there wasn’t a geocache in sight, so imagine my
delight to find that now there’s one right on the doorstep! Armed with a torch to fight off the renaming pre-dawn darkness, I braved the cold and came out to explore.
Found the obvious hiding spot quickly, but my sore back (Fairlawns’ mattress was somewhat softer than I enjoy!) made retrieval challenging! Still, a success once I was on my hands and
knees! TFTC, and Merry Christmas I guess!
The two most important things you can do to protect your online accounts remain to (a) use a different password, ideally a randomly-generated one, for every service, and (b) enable
two-factor authentication (2FA) where it’s available.
If you’re not already doing that, go do that. A password manager like 1Password, Bitwarden, or LastPass will help (although be aware that the latter’s had some security issues lately, as I’ve mentioned).
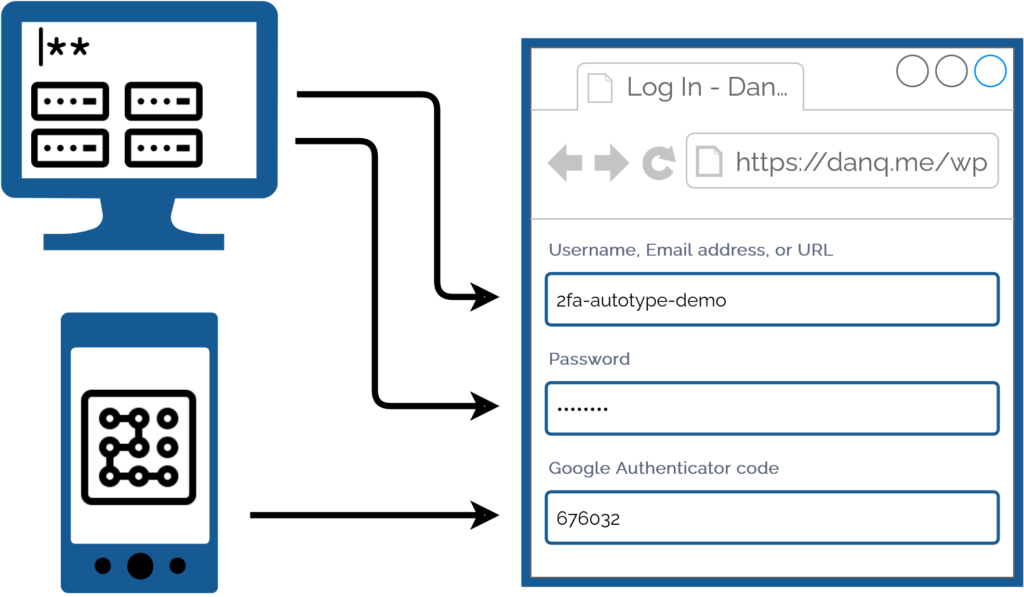
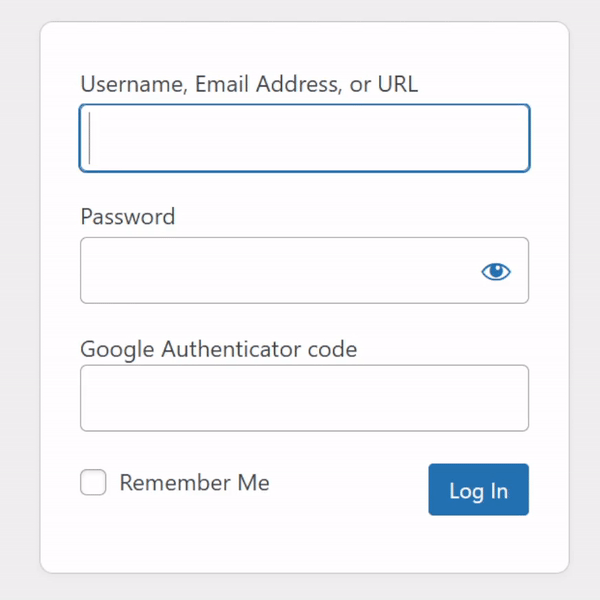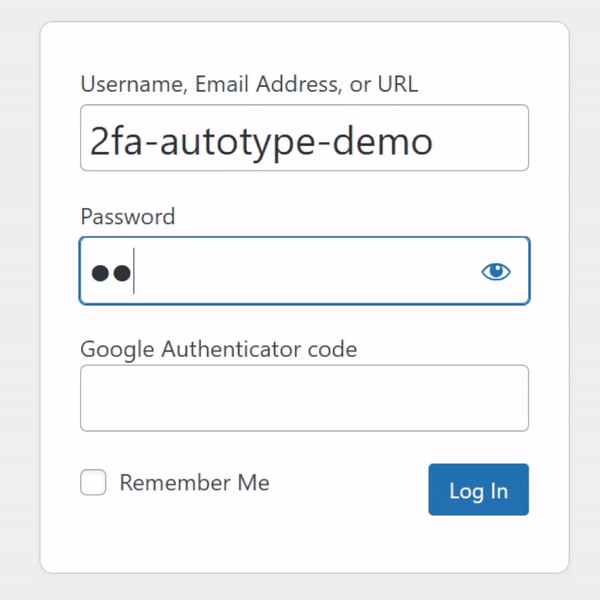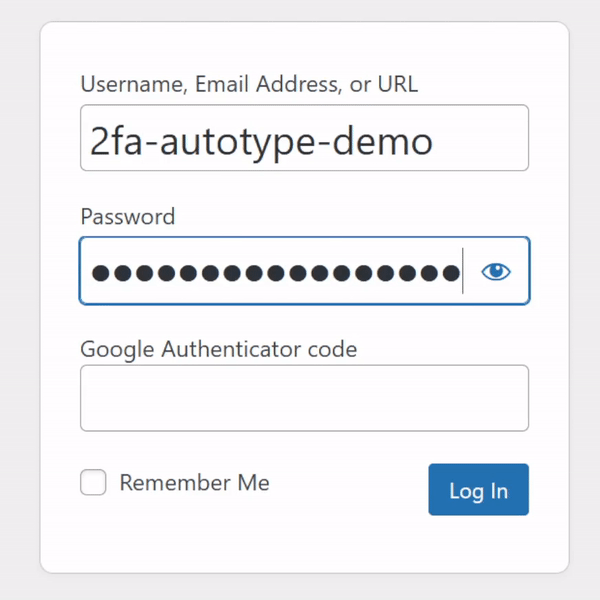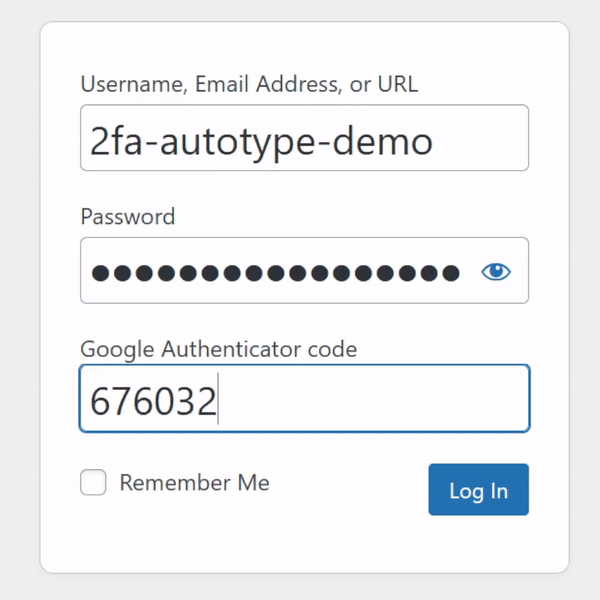
For many people, authentication looks like this: put in a username and password from a password safe (or their brain), and a second factor from their phone.
I promised back in 2018 to talk about what
this kind of authentication usually1
looks like for me, because my approach is a little different:
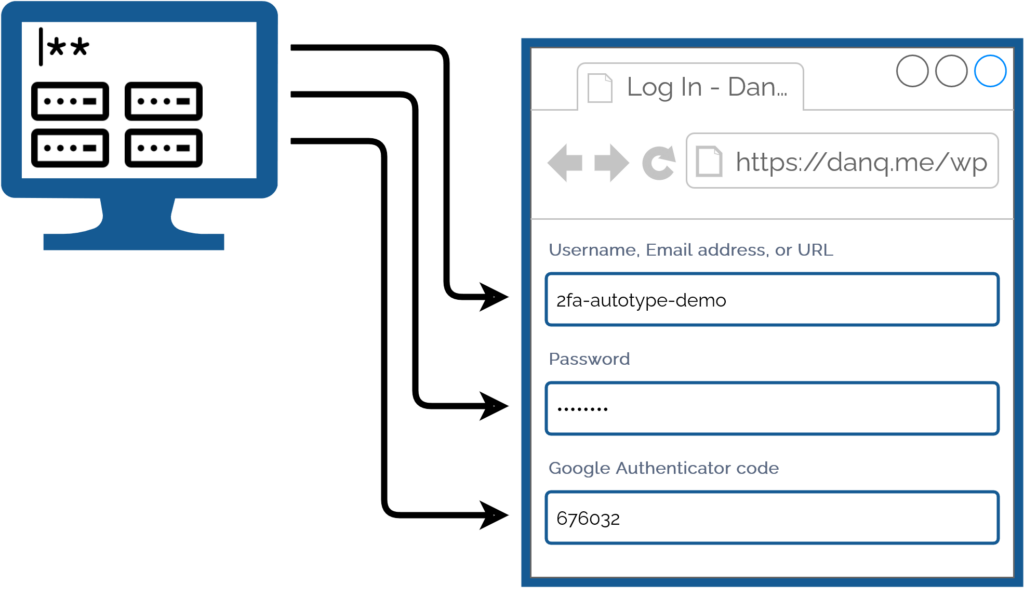
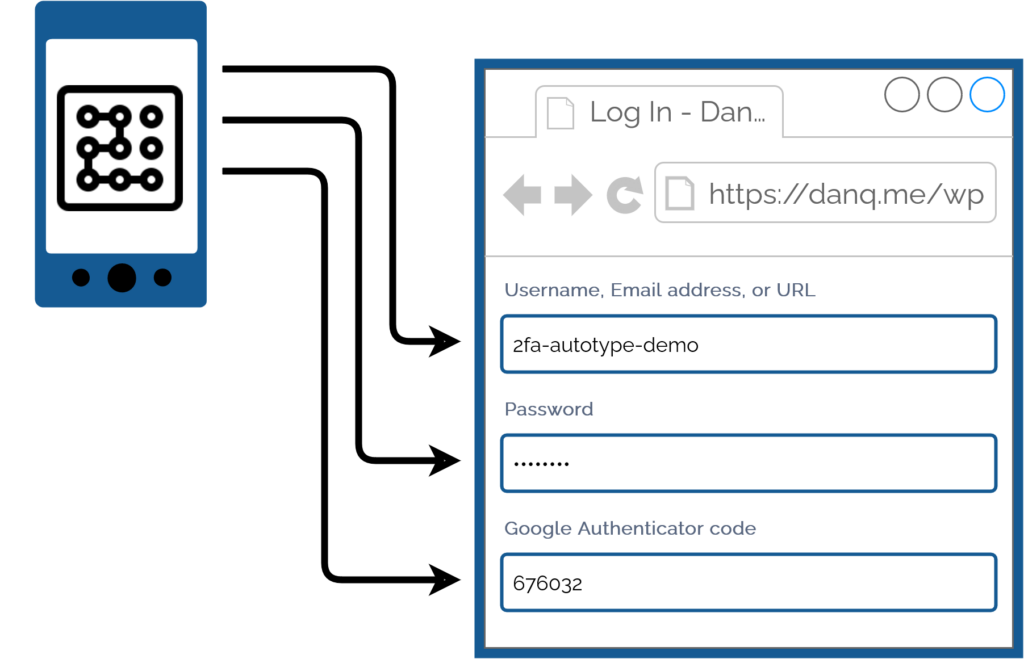
My password manager fills the username, password, and second factor parts of most login forms for me. It feels pretty magical.
I simply press my magic key combination, (re-)authenticate with my password safe if necessary, and then it does the rest. Including, thanks to some light scripting/hackery, many
authentication flows that span multiple pages and even ones that ask for randomly-selected characters from a secret word or similar2.
I love having long passwords and 2FA enabled. But I also love being able to log in with the convenience of a master
password and my fingerprint.
My approach isn’t without its controversies. The argument against it broadly comes down to this:
Storing the username, password, and the means to provide an authentication code in the same place means that you’re no-longer providing a second factor. It’s no longer e.g.
“something you have” and “something you know”, but just “something you have”. Therefore, this is equivalent to using only a username and password and not enabling 2FA at all.
I disagree with this argument. I provide two counter-arguments:
1. For most people, they’re already simplifying down to “something you have” by running the authenticator software on the same device, protected in the same way, as their
password safe: it’s their mobile phone! If your phone can be snatched while-unlocked, or if your password safe and authenticator are protected by the same biometrics3,
an attacker with access to your mobile phone already has everything.
If your argument about whether it counts as multifactor is based on how many devices are involved, this common pattern also isn’t multifactor.
2. Even if we do accept that this is fewer factors, it doesn’t completely undermine the value of time-based second factor codes4.
Time-based codes have an important role in protecting you from authentication replay!
For instance: if you use a device for which the Internet connection is insecure, or where there’s a keylogger installed, or where somebody’s shoulder-surfing and can see what you type…
the most they can get is your username, password, and a code that will stop working in 30 seconds5. That’s
still a huge improvement on basic username/password-based system.6
Note that I wouldn’t use this approach if I were using a cloud-based password safe like those I linked in the first paragraph! For me personally: storing usernames, passwords, and
2FA authentication keys together on somebody else’s hardware feels like too much of a risk.
But my password manager of choice is KeePassXC/KeePassDX, to which I migrated after I realised that the
plugins I was using in vanilla KeePass were provided as standard functionality in those forks. I keep the master copy of my password database
encrypted on a pendrive that attaches to my wallet, and I use Syncthing to push
secondary copies to a couple of other bits of hardware I control, such as my phone. Cloud-based password safes have their place and they’re extremely accessible to people new to
password managers or who need organisational “sharing” features, but they’re not the right tool for me.
As always: do your own risk assessment and decide what’s right for you. But from my experience I can say this: seamless, secure logins feel magical, and don’t have to require an
unacceptable security trade-off.
Footnotes
1 Not all authentication looks like this, for me, because some kinds of 2FA can’t be provided by my password safe. Some service providers “push” verification checks to an app, for example. Others use proprietary
TOTP-based second factor systems (I’m looking at you, banks!). And some, of course, insist on proven-to-be-terrible
solutions like email and SMS-based 2FA.
2 Note: asking for a username, password, and something that’s basically another-password
is not true multifactor authentication (I’m looking at you again, banks!), but it’s still potentially useful for organisations that need to authenticate you by multiple media
(e.g. online and by telephone), because it can be used to help restrict access to secrets by staff members. Important, but not the same thing: you should still demand 2FA.
3 Biometric security uses your body, not your mind, and so is still usable even if you’re
asleep, dead, uncooperative, or if an attacker simply removes and retains the body part that is to be scanned. Eww.
4 TOTP is a very popular
mechanism: you’ve probably used it. You get a QR code to scan into the authenticator app on your device (or multiple devices,
for redundancy), and it comes up with a different 6-digit code every 30 seconds or so.
5 Strictly, a TOTP code is
likely to work for a few minutes, on account of servers allowing for drift between your clock and theirs. But it’s still a short window.
6 It doesn’t protect you if an attacker manages to aquire a dump of the usernames,
inadequately-hashed passwords, and 2FA configuration from the server itself, of course, where other forms of 2FA (e.g. certificate-based) might, but protecting servers from bad actors is a whole separate essay.
If you read a lot of the “how to start a blog in 2023” type posts (please don’t ever use that title in a post) the advice will often boil down to something like:
Kev writes about what he’s learned from ten years of blogging. As a fellow long-term
blogger1, I was
especially pleased with his observation that, for some (many?) of us old hands, all the tips on starting a blog nowadays are things that we just don’t do, sometimes
deliberately.
Like Kev, I don’t have a “niche” (I write about the Web, life, geo*ing, technology, childwrangling, gaming, work…). I’ve experimented with email subscription but only as a convenience to people who prefer to get updates that way – the same reason I push articles to Facebook – and it certainly didn’t take off (and that’s fine!). And
as for writing on a regular schedule? Hah! I don’t even
manage to be uniform throughout the year, even after averaging over my blog’s quarter-century2 of history.
Also like Kev, and I think this is the reason that we ignore these kinds of guides to blogging, I blog for me first and foremost. Creation is a good thing, and I take
my “permission to write” and just create stuff. Not having a “niche” means that I can write about what interests me, variable as that is. In my opinion the only guide to starting a blog that anybody needs to read is
Andrew Stephens‘ “So You Want To Start An Unpopular Blog”.
And if that’s not enough inspiration for you to jump back in your time machine and party like the Web’s still in 2005, I don’t know what is.
Two years after our last murder mystery party, almost
three years since the one before, and much, much longer since our last in-person one, we finally managed to have another
get-the-guests-in-one-place murder mystery party, just like old times. And it was great!
Full credit goes to Ruth who did basically all the legwork this time around. Cheers!
D’Avekki’s murder mystery sets use an unusual mechanic that I’ve discussed before online with other murder mystery party authorship enthusiasts1 but never tried in practice: a way of determining at
random who the murderer is when play begins. This approach has a huge benefit in that it means that you can assign characters to players using a subset of those available (rather
than the usual challenges that often come up when, for example, somebody need to play somebody of a different gender than their own) and, more-importantly, it protects you from the
eventuality that a player drops-out at short notice. This latter feature proved incredibly useful as we had a total of three of our guests pull out unexpectedly!
Most of our guests were old hands at murder mystery games, but for Owen’s date Kirsty this was a completely novel experience.
The challenge of writing a murder mystery with such a mechanic is to ensure that the script and evidence adapt to the various possible murderers. When I first examined the set
that was delivered to us, I was highly skeptical: the approach is broadly as follows2:
At the start of the party, the players secretly draw lots to determine who is the murderer: the player who receives the slip marked with an X is the murderer.
Each character “script” consists of (a) an initial introduction, (b) for each of three acts, a futher introduction which sets up two follow-up questions, (c) the answers to those
two follow-up questions, (d) a final statement of innocence, and (e) a final statement of guilt, for use by the murderer.
In addition, each script has a handful of underlined sections, which are to be used only if you are the murderer. This
means that the only perceivable difference between one person and another being the murderer is that the only who is the murderer will present a small amount of additional information.
The writing is designed such that this additional piece of evidence will be enough to make the case against them be compelling (e.g. because their story becomes
internally-inconsistent).
The writing was good overall: I especially appreciated the use of a true crime podcast as a framing device (expertly delivered thanks to Rory‘s
radio voice). It was also pleasing to see, in hindsight, how the story had been assembled such that any character could be the murderer, but only one would give away a
crucial clue. The downside of the format is pretty obvious, though: knowing what the mechanic is, a detective only needs to look at each piece of evidence that appears and look for a
connection with each statement given by every other player, ruling out any “red herring” pairings that connect to every other player (as is common with just about the entire
genre, all of the suspects had viable motives: only means and opportunity may vary).
It worked very well, but I wonder if – now the formula’s understood by us – a second set in a similar style wouldn’t be as successful.
Our classic end-of-murder-mystery-party photo post makes a comeback. Extra-special hat tip to Kirsty, who ended up by coincidence being the murderer at her first ever such event and
did astoundingly well. From left to right: Rory (Major Clanger), Simon (Chef Flambé), JTA (Noah Sinner), Kirsty (Phyllis
Ora), Ruth (Dusty Tomes), Liz (Ruby Daggers), Owen (Max
Cruise), and me (Professor Pi).
That said, nobody correctly fingered the murderer this time around. Maybe we’re out of practice? Or maybe the quality of the hints in such a wide-open and dynamic murderer-selection
mechanic is less-solid than we’re used to? It’s hard to say: I’d certainly give another D’Avekki a go to find out.
Out on a walk with the dog along the footpath nearby I elected to drop in on this cache for routine maintenance. But
as I approached the GZ I learned that the footbridge that provided this cache with its home clearly wasn’t as “forgotten” as I’d thought!
The council have been up here again and rather than just signing the log as they did last time they
were on a mission to replace the entire bridge!
When they did this with the bridge that hosted GC90RH3 they gave me
enough notice to remove the cache, but not this time: by the time the geopup and I discovered the “new” bridge the cache container was long gone. (It was a modified ammo can, so I
might reach out and see if they happened to retrieve it during the demolition and can give it back!)
Beginning to prepare/test my costume for an upcoming murder mystery party, I glanced into the mirror and briefly didn’t recognise myself. Glasses can do so much to change your face
shape!
It all started when I saw no-ht.ml, Terence Eden‘s hilarious response to Salma
Alam-Naylor‘s excellent HTML is all you need to make a website. The latter is an
argument against both the silly amount of JavaScript with which websites routinely burden their users, but also even against depending on CSS. As a fan of CSS Naked Day and a firm
believer in using JS only for progressive enhancement, I’m obviously in favour.
Obviously no-ht.ml is to be taken as tongue-in-cheek, but as you’re about to see: it caught my interest and got me thinking: how could I go even further.
Terence’s site works by delivering a document with a
claimed MIME type of text/html, but which contains only the (invalid) “HTML” code
<!doctype UNICODE><meta charset="UTF-8"><plaintext> (to work around browsers’ wish to treat the page as HTML). This is followed by a block of UTF-8 plain text making use of spacing
and emoji to illustrate and decorate the content. It’s frankly very silly, and I love it.1
I think it’s possible to go one step further, though, and create a web page with no code whatsoever. That is, one that you can read as if it were a regular web page, but where
using View Source or e.g. downloading the page with curl will show you… nothing.
I present: The Page With No Code! (It’ll probably only work if you’re using Firefox, for reasons that will become apparent later.)
I’d encourage you to visit The Page With No Code, use View Source to confirm for yourself that it truly has no code, and see if you can work out for yourself how it manages
this feat… before coming back here for an explanation. Again: probably Firefox-only.
Once you’ve had a look for yourself and had a chance to form an opinion, here’s an explanation of the black magic that makes this atrocity possible:
The page is blank. It’s delivered with Content-Type: text/html. Your browser interprets a completely-blank page as faulty and corrects it to a functionally-blank
minimal HTML page: <html><head></head><body></body></html>.
<body> and <html> elements can be styled with CSS; this includes the ability to add
content:::before and ::after each
element. If only we could load a stylesheet then content injection is possible.
We use the fourth way to inject
CSS – a Link: HTTP header – to deliver a CSS payload (this, unfortunately, only works in Firefox). To further obfuscate what’s happening and remove the need for a round-trip, this is encoded
as a data: URI.
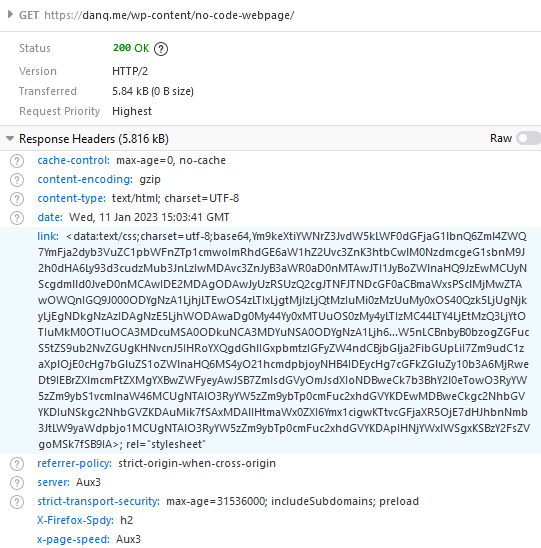
The stylesheet – and all the page content – is right there in the Link: header if you just care to decode it! Observe that while 5.84kB of
data are transferred, the browser rightly states that the page is zero bytes in size.
My server-side implementation of this broke in 2023 after I upgraded Nginx; my new version doesn’t support the super-long Link: header needed
to make this hack work, so I’ve updated the page to use the Link: to reference the CSS file rather than embed it via a data URI. It’s not as cool, but it at least means you can
still see the page. Thanks to Thomas Bradshaw for pointing out the problem.
Footnotes
1 My first reaction was “why not just deliver something with Content-Type:
text/plain; charset=utf-8 and dispense with the invalid code, but perhaps that’s just me overthinking the non-existent problem.