At the weekend, I became briefly obsessed with the cover of the manual for GoScript Plus, a 1990 software tool for converting PostScript output into a format that’s compatible with a wider array of IBM-compatible printers.
I’ve never used this piece of software. I can’t even remember how I found my way to archive.org’s copy of its documentation. Just one of those mysteries.
Anyway: here’s what it looks like:

The design is very much a product of its era. That two-colour print, the strange angles, those smallcaps, the excessive use of title case, and the use of “ink jet” as two words rather than one.
Anyway: I decided I’d attempt to re-create the cover in pure HTML + CSS. No SVGs; no images. Here’s what I came up with:
I’m not entirely happy with the fonts: in the short while I was working on this, I couldn’t find anything that was quite “right” for the main title, with its stencil-style Rs and Ps, super-rounded Os and Cs, and narrow Ss. In the end I just used Ubuntu Sans almost everywhere.
The white “stripe” with font samples is all just system fonts from your computer! So that’s not accurate either. But my aim was to capture the feel of the manual rather than necessarily make a 100% faithful recreation of it, so I guess it’s okay.
I was quite pleased with the LaserGo logo in the top left. The main “striped circle with one corner a different color” was implemented like this:
/* The <address> element contains the text "LaserGo, Inc" */ address { /* Before AND after it are two virtual elements: */ &:before, &:after { content: ''; display: block; position: absolute; /* Both are offset to where I want the "circle" to be. */ /* (note use of container query units for responsive sizing!) */ top: -8cqw; left: 3cqw; width: 8cqw; height: 8cqw; /* Make it circular: */ border-radius: 50%; /* The background is striped, with a color specified in --logo-color: */ background: repeating-linear-gradient(var(--logo-color) 0cqw, transparent 0.2cqw, transparent 0.3cqw); /* Then that gets masked; two variables control which part is shown: */ mask-image: conic-gradient(var(--logo-corner-mask) 0deg, var(--logo-corner-mask) 90deg, var(--logo-remainder-mask) 90deg, var(--logo-remainder-mask) 360deg); } &:before { /* The "before" circle uses white stripes: */ --logo-color: var(--white); /* And masks so that three-quarters of the circle is shown: */ --logo-corner-mask: transparent; --logo-remainder-mask: black; } &:after { /* The "after" circle uses black stripes: */ --logo-color: var(--black); /* And masks so that one-quarter of the circle is shown: */ --logo-corner-mask: black; --logo-remainder-mask: transparent; } }
Anyway; there’s probably nothing more to say about this, apart from a reminder than HTML + CSS is absolutely a an art medium. Take a look at the source code of my fake book cover, if you like (or inspect its DOM, if you prefer): it’s all self-contained and should be reasonably readable.










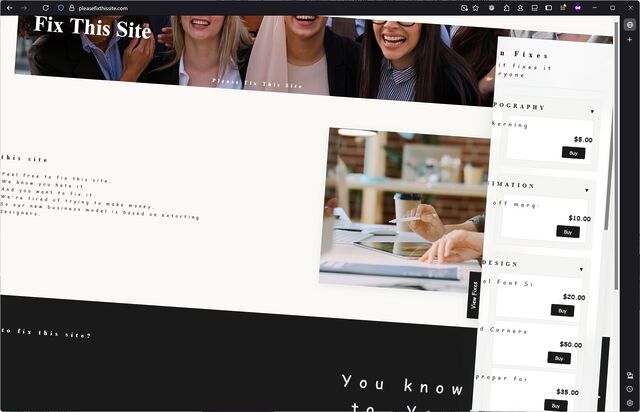
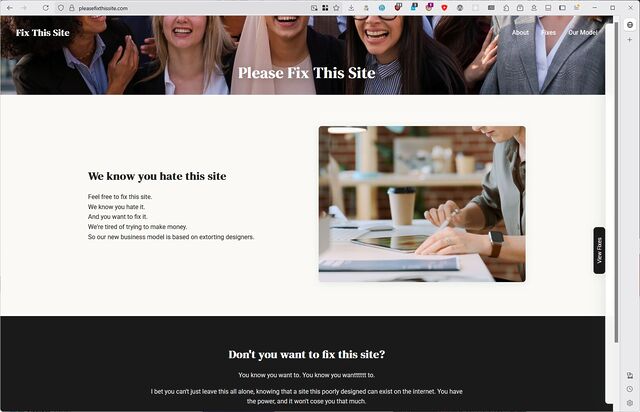
![XKCD comic. Transcript: [A single panel containing a large, elevated sign with Ponytail standing in front of it.] [Title, slightly off horizontal, more to the right than central and the character spacing is not entirely consistent/aesthetic:] Doanate[sic] to fix this sign! [To the left of the lower part of the sign there is an 'QR code', tilted slightly with a plaintext link beneath it:] https://[illegible].com [To the right are several dollar values, in one column, and 'fixes', in a second, some of which have their own self-demonstrating quirks.] [The letters "R" and "N" may be too close together:] $10 fix kerning [Both dollar value and fix text are shifted left of their respective columns:] $20 align columns [This line is in a smaller font:] $20 fix text size $50 fix typo $50 fix centering $100 fix rotation [Ponytail stands looking at the sign, apparently in the process of using a smartphone:] Grrr... [Caption below panel:] My new company's business model is based on extorting graphic designers.](https://bcdn.danq.me/_q23u/2025/07/fix_this_sign1.png)
 Alpaca
Alpaca
 Anteater
Anteater
 Bat
Bat
 Beetle
Beetle
 Butterfly
Butterfly
 Camel
Camel
 Cat
Cat
 Chameleon
Chameleon
 Cobra
Cobra
 Cow
Cow
 Crab
Crab
 Crocodile
Crocodile
 Dog
Dog
 Duck
Duck
 Elephant
Elephant
 Elk
Elk
 Fish
Fish
 Frog
Frog
 Giraffe
Giraffe
 Hippo
Hippo
 Husky
Husky
 Kangaroo
Kangaroo
 Lion
Lion
 Macaw
Macaw
 Manatee
Manatee
 Monkey
Monkey
 Mouse
Mouse
 Octopus
Octopus
 Ostrich
Ostrich
 Owl
Owl
 Panda
Panda
 Pelican
Pelican
 Penguin
Penguin
 Pig
Pig
 Rabbit
Rabbit
 Raccoon
Raccoon
 Ray
Ray
 Rhino
Rhino
 Rooster
Rooster
 Shark
Shark
 Sheep
Sheep
 Sloth
Sloth
 Snake
Snake
 Spider
Spider
 Squirrel
Squirrel
 Swan
Swan
 Tiger
Tiger
 Toucan
Toucan
 Turtle
Turtle
 Whale
Whale