This is a reply to a post published elsewhere. Its content might be duplicated as a traditional comment at the original source.
…
Those .ini files seemed unimportant to a child, but they are configuration files used by several applications, including the operating system. While the Windows
Registry did exist in Windows 95, .ini files were still commonly used. When I deleted them, any application or process that relied on them failed to load and simply
crashed.
Anyone who had anything of importance on that computer lost it. Everyone except my father, who carefully kept copies of his documents on floppy disks. He knew I was up to no good.
Throughout my career, I’ve seen many people make this same mistake. When something doesn’t look important to them, they delete it. Whether it’s a programmer deleting a function that “looks stupid,” or a DBA dropping a table or a single field they assume no one will miss. It’s
all the result of the same mindset: “I don’t think this is important.”
…
Not the same thing at all, but once, early in my career, I needed to use a colleague’s computer because mine was tied-up doing something-or-other. He was off for his lunch, so I asked
if I could borrow his and carry on testing the system I’d been developing from there.
My tests involved making a ton of CSV files, uploading them into a tool, getting the mutated results back, and comparing them. Dull stuff, and it made a load of temporary files. So I
dutifully dumped all the mess I made into the Recycle Bin and, when I was finished and returned to my own desk, I emptied the Recycle Bin.
My colleague returned and he was furious. “Did you empty my Recycle Bin?” he fumed.
“Yes,” I said, “Sorry; was that a problem?”
“I was keeping all kinds of important documents in there!” he replied.
Turns out that the software he was using to measure how much disk space he had left didn’t include the Recycle Bin in its count; after all, that could be freed-up in a moment! And so,
to “save space”, he’d taken to storing large (but important) files… in the Recycle Bin so that they didn’t take up space (at least, according to the tool he was using: obviously they
were taking up space in reality).
This guy wasn’t 10 years old. He was over twice that, a recent university graduate with a software engineering degree.
I made the flaming digits using a stock effect in Corel Photo-Paint; this is an attempt to replicate the “feel” of them.
Hit counters are pretty dumb for a variety of reasons. Counting “hits” was never a terribly-representative reflection of the popularity of your pages. But also: because they’re
a public representation of your popularity, there was every incentive to “game” them… even just by hitting refresh a couple of times. Making them untrustworthy and pointless.
1998 —
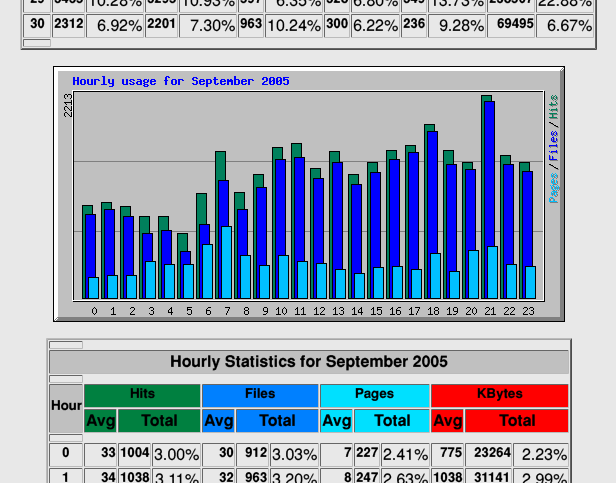
2006: Webalizer
Who can forget The Webalizer? Those Microsoft Excel ’97-grade barcharts!
Back in the day, “proper” web stats was something you did on your log files. Take log files, pump them through a program, get amalgamated output. And the king of these tools was
The Webalizer.3
On a few of my websites – and some that I helped host for my friends – I’d have The Webalizer run daily, collating an archive of monthly stats plus “month-so-far” for the
current month.
The Webalizer attempted to differentiate “hits” from “visitors”. And it tried to distinguish between browsers, and isolated bots, and tracked pulled referrer-data, and could
even try to geolocate IP addresses. It was pretty magical for its time.
2006 —
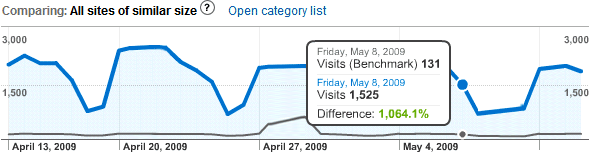
2016 Google Analytics
I was an early adopter of Google Analytics: my site ID (“UA code”) was only five digits long!
Those graphs were slick for the Web technology of the day. A product of that period in the mid-naughties when Google made products that actually impressed users
and didn’t just make them roll their eyes?
Google Analytics works via a JavaScript snippet which collects a variety of information about the visitor and sends it to Google’s mothership.
A third-party cookie that connected all Google Analytics-powered sites, plus everybody’s activity on other Google products, provided a wealth of data that you
couldn’t get any other way. Want a gender breakdown of your visitors or their interests? Google can “help” you with that… and all the while, “helping” themselves to copies of all the
data too.
If your website runs Google Analytics, it’s part of Google’s massive data-harvesting machine, monitoring people as they move around the Web. Webmasters trading away their visitors’
identities for some pretty charts seems pretty disgusting to me; it saddens me that I was ever “part of the problem”.
2015 —
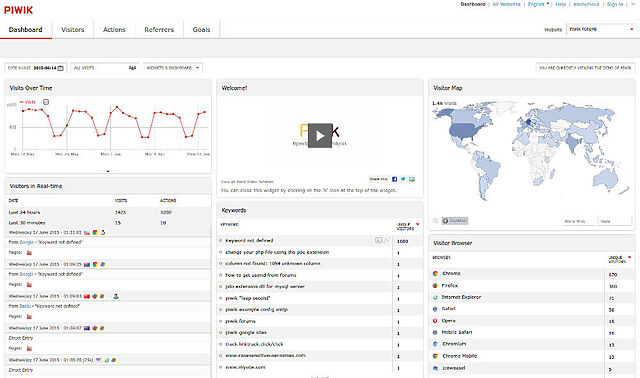
2023 Piwik
Since around 2010, I’d been actively blocking Google Analytics, which made me feel a bit like a hypocrite to be inflicting it upon others. I looked for an alternative and found it in
Piwik (now Matomo), an open-source and self-hosted analytics tool.
A self-hosted Piwik/Matomo installation provides almost the same level of useful depth as Google Analytics, but you get to keep your soul.
I ran Google Analytics and Piwik side-by-side to validate the latter, and found it to be excellent. Not only was it collecting data
in a much more-ethical and respectful way, but it was also producing more-accurate results for my readership who, leaning somewhat “techie”, would sometimes block Google
Analytics outright for all of the same reasons I did.
It was pretty good, but…
2023 — …
(Almost) nothing?
…I don’t like the kind of blogger I am when I’m collecting stats!
It’s like… being a teenager again and having that hit counter, and getting excited when it goes up. So what if a number went up? What does
“popularity” mean? Isn’t the impact more important than the number of eyeballs?4
So in 2023, after winding my analytics down by instalments for many years, I just… stopped.5
I realised that so long as I was able to easily “watch the stats”, I’d be temped to write for the stats. To treat it as a score. To make the hit counter go up.6
That, in essence, is why I don’t really “do” any webstats any more. Analytics don’t serve me and the blogger I want to be, and they didn’t represent anything that I would
consider a useful metric of success.
If somebody’s moved by what I do, that’s great: but a hit counter going up by one doesn’t tell me that; and it never did. Now if they leave a comment or drop me an email or even
send me a postcard, that’s how I know that I made a difference!
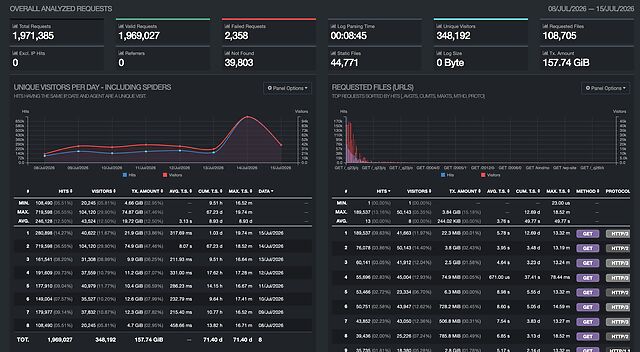
Exception to the rule: GoAccess!
While I don’t actively watch the stats any more, I suppose I can still generate them, from my webserver logs, Webalizer-style. Except nowadays I’d probably
use GoAccess:
There’s a bit of a “hump” where last week’s blog post about apps started trending on Bubbles, HackerNews, Lobste.rs and the like. But I knew that already because people sent
me lots of comments!
There’s a script that I’m able to run, if I feel like it, to parse the most-recent of my Caddy logfiles. It takes about one minute to run per day
of logs to process, and outputs a perfectly attractive self-contained HTML file.
It’s not clever. It’s not sophisticated. It doesn’t use cookies or JavaScript or, indeed, anything other than what my webserver gives me for free.
I barely use it: maybe once every 18 months or so (today was the first time in well over a year). It’s there if I need it. And it’s inconvenient-enough to use that I’m not tempted to.
2 By “blog stats”, here, I mean statistics about visitors to my blog, not
stats about my blogging (which I track and share in excruciating detail).
3 Did you know that the last point release of The Webalizer was in 2013 and
the last feature release was in 2010: much later than I thought was the case!
4 Also, how do we even count “eyeballs”. Right now, about a fifth to a quarter of my
visitors are bots. Amazonbotalone accounts for over 2% of my traffic. (I should probably tighten my
robots.txt.)
5 Nowadays, there’s no tracking scripts whatsoever on my site. I
don’t set a cookie unless you ask me to (and then it’s “transparent”: you can see exactly what it contains and what it’s for), I don’t try to fingerprint you in any way, I don’t even
keep server logs longer than 60 days! Back when I used Jetpack I actively nerfed its stats-collection “features”. I don’t want your personal data!
Hi, HackerNews! Please be kind/friendly! I’d love to hear your
experiences of these (IMHO horrible) keyboard features, whether good or bad. Drop me a comment or join in on the thread over there.
In my living room1 is an ageing Windows
media centre PC, which is connected to the TV and principally used for Jellyfin, Netflix, Nebula, Steam, and the like. For convenient sofa use, I’ve equipped it with a wireless
keyboard/trackpad combo.
The keyboard is, for the most part, fine. You wouldn’t want to type an essay on it, but if you’re searching for a YouTube video it does the job.
Unfortunately, the manufacturers of this keyboard decided that it needed a dozen extra functions, and repurposed the F-keys F1 through F12 for these
purposes.
It was nice that they gave dedicated keys to volume control/toggling muting – we use those all the time. And there are three other dedicated keys in the top right which we never use… so
there was clearly capacity for a little extra. And they still they felt the need to do… this:
That F4 key has been repurposed as a “sleep” button. This poses a problem.
I don’t want any of these “special function keys. Occasionally, I suppose, I might need one2,
but mostly I’d just like F1 through F12 to remain the multi-purpose, context-dependent keys that they have been since they first appeared in 1965.
And so, because I don’t want to hold Fn every time I want to press an F-key for its intended purpose, I used the arcane shortcut Fn+Caps
to “lock” the keyboard into “standard” mode, where multipurpose F-keys remain multipurpose F-keys unless I hold down the special magic button that transforms them into
rarely-used single-purpose special function keys.
But here’s where the problem occurs. If the batteries get changed, or if the keyboard gets turned-off for an extended period, or sometimes – seemingly – just randomly… that
function-lock gets switched off.
And I’ll grab the keyboard and, to quickly quit Steam Big Picture or a Jellyfin Client or something, I’ll press Alt+F4. Which will send the “sleep”
command. And because this computer’s a bit older, it’ll hibernate.
Instead of closing one application, which is what I intended, I now have to wait upwards of a minute for the old box to finish copying all of its RAM into a file, and shutting down, and
then booting up again (in response to my repeated and frustrated hammering of the space bar), and then loading everything back into RAM… just to put me back where I started3.
What’s most-frustrating is at F4 is the only key with such a time-consuming and annoying function. If I accidentally paused some music or opened the system
settings or did whatever-the-hell the icon on the F6 key is supposed to mean, that wouldn’t be so bad. But man; the three or four times a year that this catches me out
are just aggravating enough to piss me off without being quite bad enough for me to do something about it4.
This is the WASD Code keyboard on another of my computers5, showing how a Fn key can be done right.
It doesn’t have to be this way.
My WASD Code gets it right by resigning the effects of all double-duty keys to minor conveniences only, and making them the secondary functions of the keys to which they’re
attached. I use these volume control buttons and they’re fine6.
My Keychron K10 gets it right by having the double-duty keys mirror those of the Mac it attaches to7:
again, all minor, low-impact functions that are easily and quickly un-done. Also, when you lock it to traditional F-key mode it stays that way, even if it’s disconnected
and left unpowered for an extended period.
I had one of those Macbooks with the stupid LCD screen in place of keys, once, and I hated that “feature” and was glad to see it disappear (although occasionally I still see it on
other hardware): who the hell wants a hardware keyboard that they can only use by looking at it? This is a much saner design, and I appreciate how easy it is to switch it to
“normal” mode8.
These keyboards – which are my daily drivers – show that an Fn key can be done right.
Here’s what “doing Fn right” looks like, to me –
Where keys do double-duty, it’s a low-impact and quickly reversible operation, so there’s little cognitive load or delay in correcting any mistakes.
The default state is the traditional key function, or if that’s not the case, switching mode is easy (doesn’t involve looking up an underdocumented shortcut or
installing a proprietary driver).
When you switch the default state, it stays switched and doesn’t swap back to factory defaults just because of a loss of power or other arbitrary and unrelated
trigger.
Sadly, a great number of keyboards get their Fn key implementations wrong. And I hate them for it.
2 In particular, this keyboard lacks dedicated page up/page down keys, and I don’t mind
pressing Fn+F11 or Fn+F12 for that. And maybe once or twice I’ve used Fn+F2 for
pause/play. But other than that, they’re completely pointless.
3 Yes, I’m fully aware that I could just disable all sleep/hibernation functions at an OS
or even BIOS level. But at the time I remember that, all I want to do is get back to watching the latest episode of Star City or something.
4 I mean, except for write this blog post, I suppose. But for that I blame Terence Eden, who put the idea in my head with a recent poll.
5 And why yes, I do have Pride keycaps in place of my function keys, why do you
ask?
6 The volume control knob of the mechanical it replaced, a Das Keyboard 3, was better, but
you can’t have everything.
7 The Keychron itself is super versatile and OS-independent: it’s easily toggled between
layouts and even comes with spare keycaps to make it “look like” your preferred operating system, assuming that unlike me you don’t routinely use around three different ones in a
typical session.
8 Don’t get me started on Apple’s other UX decisions like “natural scrolling”
which makes no sense whatsoever on a mouse… but – unlike every other operating system I’ve checked – won’t let you configure a different scrolling orientation on a mouse than
for a trackpad: both have to be kept aligned in MacOS. Argh!.
Well this is a fun (and frustrating!) game. You’ll be presented with 20 (alleged) CSS properties, but some of them… are convincing-looking fakes! You’ve got 10 seconds to identify
whether each is real or not. Every few you get right increases the difficulty level, but also the score potential. How high can you score?
Me? Oh, I kept getting up into the “forbidden” level and then my brain would melt and I’d crash out. Quite proud of my last run, though:
Many years ago, someone tried to get me into cryptocurrencies. “They’re the future of money!” they said. I replied saying that I’d rather wait until they were more useful, less
volatile, easier to use, and utterly reliable.
“You don’t want to get left behind, do you?” They countered.
That struck me as a bizarre sentiment. What is there to be left behind from? If BitCoin (or whatever) is going to liberate us all from economic drudgery, what’s the point
of “getting in early”? It’ll still be there tomorrow and I can join the journey whenever it is sensible for me.
…
100%. If I “get in early” on something, it’s because that thing interests me, not because I’m betting on its future. With a hundred new ideas a day and only one of them “making it”,
it’s a fools’ game to try to jump on board every bandwagon that comes along.
With cryptocurrencies, though, I’m fortunate enough to have an even better comeback at the cryptobros that try to shill me whatever made-up currency they’re “investing” in
today: I’ve already done better than they ever will, at them.
When Bitcoin first appeared, I took a technical interest in it. I genuinely never anticipated it’d take off (I made the same incorrect
guess with MP3s, too!), but I thought it was a fun concept to play about with. The only Bitcoins I ever paid for must’ve been worth an average of 50p each, or so.
I sold my entire wallet of Bitcoins when they hit around £750 each. I know a tulip economy when I see one, I thought. Plus: I was
no longer interested in blockchains now I was seeing how they were actually being used: my interest had been entirely in the technology and its applications, not in the actual idea of a
currency!
Sure, I kick myself ocassionally, given that I later saw the value rise to tens of thousands of pounds each. But hey, I was never in it for the money anyway.
So yeah, I tell cryptobros; I already made a 1500% ROI on cryptocurrency. And no, I’m not buying any cryptocurrencies any more. Whatever they think “getting in early” was, they’re
wrong, because I was there years ahead of them and I wasn’t even doing it to “get in early”; I did it because it was interesting. And honestly, isn’t that a better story to be able to
tell?
…
I feel the same way about the current crop of AI tools. I’ve tried a bunch of them. Some are good. Most are a bit shit. Few are useful to me as they are now.
…
If this tech is as amazing as you say it is, I’ll be able to pick it up and become productive on a timescale of my choosing not yours.
…
Yup, that’s the attitude I’m taking.
I play with new AI technologies, sometimes. I don’t do it because I’m afraid of being left behind because – as you say – if a technology is transformative, we’ll all get to catch up
eventually.
Do you think that people who had smartphones first are benefitting today because they “got in early” on something that later became mainstream?
Of course they’re not. Their experience is eventually exactly the same as everybody else’s, just like it was for everybody who “got in early” on hype trains whose final station came
early, like Compuserve GO-words, WAP, Beenz.com, WebTV, the CueCat, m-Commerce, HD-DVD, the JooJoo, or Google+.
People being unwilling to discuss their wild claims later using the lack of discussion as evidence of widespread acceptance.
When people balance the new toilet roll one atop the old one’s tube.3
Come on! It would have been so easy!
Shellfish. Why would you eat that!?
People assuming my interest in computers and technology means I want to talk to them about cryptocurrencies.4
Websites that nag you to install their shitty app. (I know you have an app. I’m choosing to use your website. Stop with the banners!)
People who seem to only be able to drive at one speed.5
The assumption that the fact I’m “sharing” my partner is some kind of compromise on my part; a concession; something that I’d “wish away” if I could.
(It’s very much not.)
Brexit.
Wow, that was strangely cathartic.
Footnotes
1 I have a special pet hate for websites that require JavaScript to render their images.
Like… we’d had the<img>tag since 1993! Why are you throwing it away and replacing it with something objectively slower, more-brittle, and
less-accessible?
2 Or, worse yet, claiming
that my long, random password is insecure because it contains my surname. I get that composition-based password rules, while terrible (even when they’re correctly
implemented, which they’re often not), are a moderately useful model for people to whom you’d otherwise struggle to
explain password complexity. I get that a password composed entirely of personal information about the owner is a bad idea too. But there’s a correct way to do this, and it’s not “ban
passwords with forbidden words in them”. Here’s what you should do: first, strip any forbidden words from the password: you might need to make multiple passes. Second, validate the
resulting password against your composition rules. If it fails, then yes: the password isn’t good enough. If it passes, then it doesn’t matter that forbidden words
were in it: a properly-stored and used password is never made less-secure by the addition of extra information into it!
A lot of attention was gained by Derek Sivers‘ post Offline 23 hours a day, the other week. I was particularly
impressed by the rebuttal by Rishi Dass:
…
Anyway, the reasoning behind this idea of disconnecting seems to be that they equate
being productive with having no internet or phone service. This implies that the tool (internet or the phone) is the problem. But is that entirely true?
They further argue that disconnection helps them create a vacuum through media silence, allowing their thoughts to expand and fill the space. While it’s understandable that you can
concentrate better when your attention is focused on one thing, there’s no reason you can’t stay online and do the work. If you’re able to work comfortably in a
library, you can do this.
…
Obviously, Derek’s approach is valid. It sounds like he’s found what works for him in terms of managing his time, life, mental energy, and the like, and that’s great! I’d be lying if I
said that I didn’t envy him at least a little: don’t we all enjoy “unplugging” sometimes?
I think Derek’s post is so appealing because it touches our nostalgia of a simpler, less-always-online time.
For a while I thought that this would be a sensation unique to folks who, like me, had their first experiences of the Internet in a very intermittent and deliberate way. In the 1990s, I
used to go on the Internet: a premeditated act that required being somewhere with a landline and the appropriate hardware, requiring that nobody was using or
intending to use the phone, booting up a computer, dialling-up to the local Internet Service Provider, and then going about what I wanted to do. At that time, it was uncommon to use the
‘net for trivial things like checking the weather or what’s on at the cinema, because picking up the local newspaper would probably be a faster way to achieve that!
Similarly, it wasn’t so-useful as a procrastination activity, because picking up a book or going for a walk was more accessible and reliable.
But this isn’t a generational thing, or at least not entirely. Gen Zs are seeing the joy in retro tech from before they were
born, which is something I’ve witnessed myself: I’m part of a couple of online communities that do quite a bit of retro-Web and other retro-tech stuff, and I’ve
been amazed at how young the demographics can skew in some of these groups! Like: there are people who were born after Facebook was founded who yearn to
recreate the kind of dial-up experience that I had, before their parents met.
(Obviously, I think this is great; I think there are great lessons to be learned from the more open, decentralised, distributed, transparent, and exploratory Internet of times gone by.
It just… initially surprised me to find so many younger folks showing such an interest in it, too.)
I still think this is nostalgia, though. Here’s why: none of us are born with unfettered and unfiltered access to the Internet. Unless they have the most hands-off parents
possible, even a child born today won’t be “always online” for the first decade or more of their life. And being a child, for most folks, is a time of safety and
wonderment: where there are other people to attend to our needs and filter our information intake and answer our questions in a protected environment. Growing up, we all have to learn
to do those things for ourselves. And in the information-saturated attention economy of the modern world, that shit is exhausting.
You don’t need to be reminiscing about dial-up to fantasise about a slower time, when pub quizzes couldn’t be cheated by a shithead in the corner unless you catch them in the act and
when your pocket computer wouldn’t beep for attention every 30 seconds because a half-remembered friend posted a holiday snap. Not having the extra cognitive load all the time is
liberating!
No wonder “going offline” seems like a luxury to people, and why Derek’s extreme approach is so intriguing! But it’s just the same as that curated holiday snap that your
friend-of-a-friend just posted to Instagram: it’s a snapshot into the best bits of somebody else’s life. It’s not reality. It’s your imagination, your
fantasy, projected onto somebody else’s solution. “This works for them,” you say to yourself, “It must work for me, too!”
Maybe it would! And I hope that a few people feel empowered by Derek’s post to fulfil their dream and go live in the woods. Good for them!
But Rishi’s rebuttal brings us a sense of balance. For most people, it’s not necessary to go live in the woods to “go offline”. If you really want to,
just… go offline. The power’s in your hands.
if you don’t want to be distracted by social media and games, close those accounts and take those apps off your device
if you don’t want to be interrupted by notifications, switch them off and check your inputs on your own schedule
if you don’t want to be online at all, set airplane mode or disconnect from the WiFi, and narrow your focus onto that book, board game, film, conversation, or daydream
if you don’t trust yourself not to be tempted to backslide… well, that’s a bigger problem of self-control that you need to work on, but in the meantime, try and experiment: leave
your device behind and take a walk!
I get wanting to disconnect. I have my own controls in place, too, and they’re great for my mental health. But my approach, Derek’s approach, anybody’s
approach… don’t have to be your approach.
Start the journey by working out what parts of the always-online world aren’t serving you. What things are more of a psychological drain than a boost? What’s bad for your mental
wellbeing on the whole (not just in the moment)? What habits would you like to kick? What excuses are you using to keep them?
Then, work out what you can do about them. Seek assistance if you need it; you might not have all the solutions. But beware the seductive approach of taking what works
for somebody else and trying to fit yourself to their mould.
Sure: maybe you need to go live in the woods with Derek. But make that choice because it solves your problems, not because it solves his!
My recent post How an RM Nimbus Taught Me a Hacker Mentality kickstarted several conversations, and I’ve enjoyed talking to people about the “hacker
mindset” (and about old school computers!) ever since.1
Thinking “like a hacker” involves a certain level of curiosity and creativity with technology. And there’s a huge overlap between that outlook and the attitude required to
be a security engineer.
By way of example: I wrote a post for a Web forum2
recently. A feature of this particular forum is that (a) it has a chat room, and (b) new posts are “announced” to the chat room.
It’s a cute and useful feature that the chat room provides instant links to new topics.
The title of my latest post contained a HTML tag (because that’s what the post was talking about). But when the post got “announced” to the chat room… the HTML tag seemed to have
disappeared!
And this is where “hacker curiosity” causes a person to diverge from the norm. A normal person would probably just say to themselves “huh, I guess the chat room doesn’t show HTML
elements in the subjects of posts it announces” and get on with their lives. But somebody with a curiosity for the technical, like me, finds themselves wondering exactly
what went wrong.
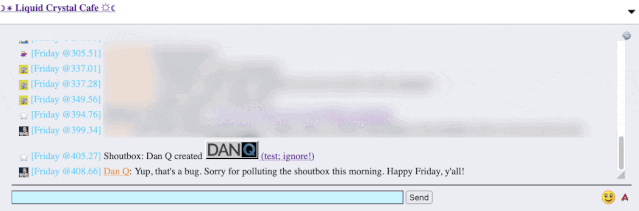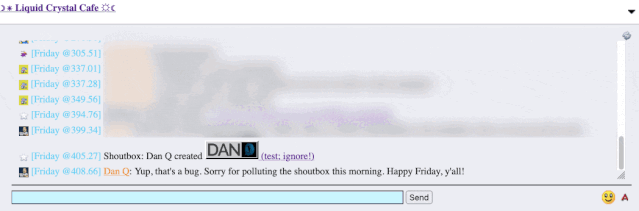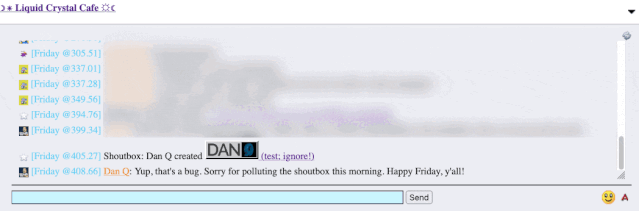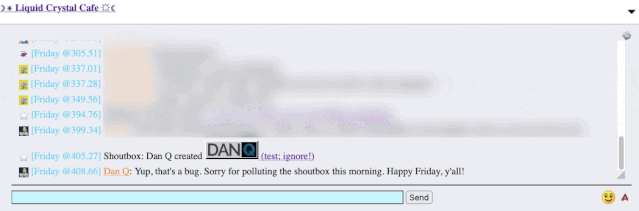
It took only a couple of seconds with my browser’s debug tools to discover that my HTML tag… had actually been rendered to the page! That’s not good: it means that, potentially, the
combination of the post title and the shoutbox announcer might be a vector for an XSS attack. If I wrote a post with a title of, say, <script
src="//example.com/some-file.js"></script>Benign title, then the chat room would appear to announce that I’d written a post called “Benign title”, but anybody viewing it
in the chat room would execute my JavaScript payload3.
I reached out to an administrator to let them know. Later, I delivered a proof-of-concept: to keep it simple, I just injected an <img> tag into a post title and, sure
enough, the image appeared right there in the chat room.
Injecting an 88×31 seemed like a less-disruptive proof-of-concept than, y’know, alert('xss'); or something!
This didn’t start out with me doing penetration testing on the site. I wasn’t looking to find a security vulnerability. But I spotted something strange, asked
“what can I make it do?”, and exercised my curiosity.
Even when I’m doing something more-formally, and poking every edge of a system to try to find where its weak points are… the same curiosity still sometimes pays dividends.
And that’s why you need that mindset in your security engineers. Curiosity, imagination, and the willingness to ask “what can I make it do?”. Because if you don’t find the loopholes,
the bad guys will.
Footnotes
1 It even got as far as the school run, where I ended up chatting to another parent about
the post while our kids waited to be let into the classroom!
2 Remember forums? They’re still around, and – if you find one with the right group of
people – they’re still delightful. They represent the slower, smaller communities of a simpler Web: they’re not like Reddit or Facebook where the algorithm will always find something
more to “feed” you; instead they can be a place where you can make real human connections online, so long as you can deprogram yourself of your need to have an endless-scroll of
content and you’re willing to create as well as consume!
3 This, in turn, could “act as” them on the forum, e.g. attempting to steal their
credentials or to make them post messages they didn’t intend to, for example: or, if they were an administrator, taking more-significant actions!
Samsung have been showing off pre-release versions of their new Galaxy S26 range. It’s all pretty same-old predictable
changes (and I’m still not really looking for anything to replace my now-five-year-old mobile anyway!), but one feature in particular – one that they’re not even mentioning in their
marketing copy – seemed interesting and innovative.
You know those polarising filters you can use to try to stop people shoulder-surfing? Samsung have come up with a software-controlled one.
Demos show the feature being used to black-out the screen at a 15°+ angle when entering a PIN or password, but also show how it can configured on an app-by-app basis to e.g. black out
notifications so that only the person right in front of the screen can see them.
I assume that this black magic is facilitated by an additional layer between the screen and the glass, performing per-pixel selective polarisation in the same way as a monochrome LCD
display might. But the fact that each pixel can now show two images – one to a user directly ahead, superimposed with another (monochrome) one to users with an offset
viewing angle, is what interests me: my long-cultivated “hacker mentality” wants to ask “what I can make that do?”
Does the API of this (of this or of any similar or future screens?) provide enough control to manipulate the new layer? And is its resolution identical to that of the underlying screen?
Could “spoilers”, instead of being folded-away behind a <details>/<summary> or ROT13-encoded, say “tilt to reveal” and provide
a physicality to the mechanism of exposure?
Could diagrams embed their own metadata annotations: look at a blueprint from the side to see descriptions, or tilt your phone to see the alt-text on an image?
Can the polarisation layer be expanded to provide a more-sophisticated privacy overlay, such as a fake notification in place of a real one, to act as a honeypot?
Is there sufficient control over the angle of differentiation that a future screen could use eye tracking to produce a virtual lenticular barrier, facilitating a novel kind of
autostereoscopic 3D display that works – like a hologram – from any viewing angle?
I doubt I’m buying one of these devices. But I’m very curious about all of these questions!
An RM Nimbus was not the first computer on which I played Game of Life1. But this glider is here symbolically, anyway.
I can trace my hacker roots back further than my first experience of using an RM
Nimbus M-Series in circa 19922.
But there was something particular about my experience of this popular piece of British edutech kit which provided me with a seminal experience that shaped my “hacker identity”. And
it’s that experience about which I’d like to tell you:
Shortly after I started secondary school, they managed to upgrade their computer lab from a handful of Nimbus PC-186s to a fancy new network of M-Series PC-386s. The school were clearly very proud of this cutting-edge new acquisition, and we watched the
teachers lay out the manuals and worksheets which smelled fresh and new and didn’t yet have their corners frayed nor their covers daubed in graffiti.
I only got to use the schools’ older computers – this kind! – once or twice before the new ones were delivered.
Program Manager
The new ones ran Windows 3 (how fancy!). Well… kind-of. They’d been patched with a carefully-modified copy of Program Manager that imposed a variety of limitations. For example, they had removed the File > Run… menu item, along
with an icon for File Manager, in order to restrict access to only the applications approved by the network administrator.
A special program was made available to copy files between floppy disks and the user’s network home directory. This allowed a student to take their work home with them if they wanted.
The copying application – whose interface was vastly inferior to File Manager‘s – was limited to only copying files with extensions in its allowlist. This meant that (given
that no tool was available that could rename files) the network was protected from anybody introducing any illicit file types.
Bring a .doc on a floppy? You can copy it to your home directory. Bring a .exe? You can’t even see it.
To young-teen-Dan, this felt like a challenge. What I had in front of me was a general-purpose computer with a limited selection of software but a floppy drive through which media could
be introduced. What could I make it do?
This isn’t my school’s computer lab circa mid-1990s (it’s this school) but it has absolutely the same
energy. Except that I think Solitaire was one of the applications that had been carefully removed from Program Manager.
Spoiler: eventually I ended up being able to execute pretty much anything I wanted, but we’ll get to that. The journey is the important part of the story. I didn’t start by asking “can
I trick this locked-down computer lab into letting my friends and I play Doom deathmatches on it?” I started by asking “what can I make it do?”; everything else built up over
time.
Recorder + Paintbrush made for an interesting way to use these basic and limited tools to produce animations. Like this one, except at school I’d have put more effort in4.
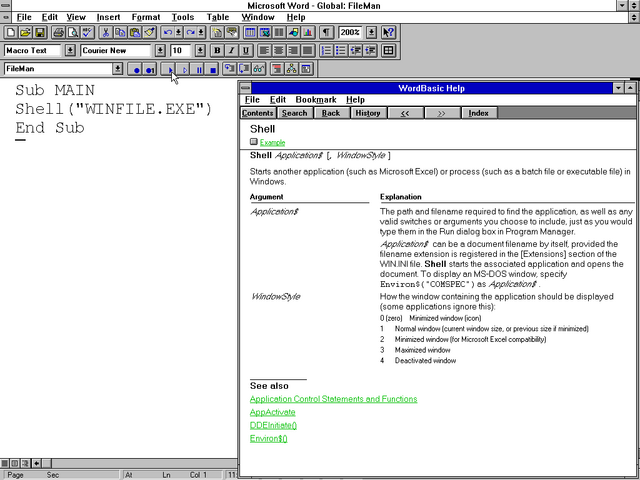
Microsoft Word
Then I noticed that Microsoft Word also had a macro recorder, but this one was scriptable using a programming language called WordBasic (a predecessor to Visual Basic for
Applications). So I pulled up the help and started exploring what it could do.
And as soon as I discovered the Shell function, I realised that
the limitations that were being enforced on the network could be completely sidestepped.
A Windows 3 computer that runs Word… can run any other executable it has access to. Thanks, macro editor.
Now that I could run any program I liked, I started poking the edges of what was possible.
Could I get a MS-DOS prompt/command shell? Yes, absolutely5.
Could I write to the hard disk drive? Yes, but any changes got wiped when the computer performed its network boot.
Could I store arbitrary files in my personal network storage? Yes, anything I could bring in on floppy disks6
could be persisted on the network server.
I didn’t have a proper LAN at home7
So I really enjoyed the opportunity to explore, unfettered, what I could get up to with Windows’ network stack.
The “WinNuke” NetBIOS remote-crash vulnerability was a briefly-entertaining way to troll classmates, but unlocking WinPopup/Windows Chat capability was ultimately more-rewarding.
File Manager
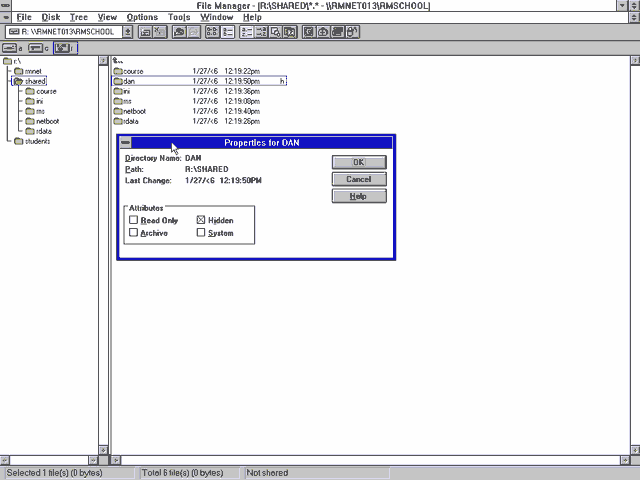
I started to explore the resources on the network. Each pupil had their own networked storage space, but couldn’t access one another’s. But among the directories shared between
all students, I found a directory to which I had read-write access.
I created myself a subdirectory and set the hidden bit on it, and started dumping into it things that I wanted to keep on the network8.
By now my classmates were interested in what I was achieving, and I wanted in the benefits of my success. So I went back to Word and made a document template that looked
superficially like a piece of coursework, but which contained macro code that would connect to the shared network drive and allow the user to select from a series of programs that
they’d like to run.
Gradually, compressed over a series of floppy disks, I brought in a handful of games: Commander Keen, Prince of Persia, Wing Commander, Civilization,
Wolfenstein 3D, even Dune II. I got increasingly proficient at modding games to strip out unnecessary content, e.g. the sound and music files9,
minimising the number of floppy disks I needed to ZIP (or ARJ!) content to before smuggling it in via my shirt pocket, always sure not to
be carrying so many floppies that it’d look suspicious.
The goldmine moment – for my friends, at least – was the point at which I found a way to persistently store files in a secret shared location, allowing me to help them run whatever
they liked without passing floppy disks around the classroom (which had been my previous approach).
In a particularly bold move, I implemented a simulated login screen which wrote the entered credentials into the shared space before crashing the computer. I left it running,
unattended, on computers that I thought most-likely to be used by school staff, and eventually bagged myself the network administrator’s password. I only used it twice: the first time,
to validate my hypothesis about the access levels it granted; the second, right before I finished school, to confirm my suspicion that it wouldn’t have been changed during my entire
time there10.
Are you sure you want to quit?
My single biggest mistake was sharing my new-found power with my classmates. When I made that Word template that let others run the software I’d introduced to the
network, the game changed.
When it was just me, asking the question what can I make it do?, everything was fun and exciting.
But now half a dozen other teens were nagging me and asking “can you make it do X?”
This wasn’t exploration. This wasn’t innovation. This wasn’t using my curiosity to push at the edges of a system and its restrictions! I didn’t want to find the exploitable boundaries
of computer systems so I could help make it easier for other people to do so… no: I wanted the challenge of finding more (and weirder) exploits!
I wanted out. But I didn’t want to say to my friends that I didn’t want to do something “for” them any more11.
I figured: I needed to get “caught”.
I considered just using graphics software to make these screenshots… but it turned out to be faster to spin up a network of virtual machines running Windows 3.11 and some basic tools.
I actually made the stupid imaginary dialog box you’re seeing.12
I chose… to get sloppy.
I took a copy of some of the software that I’d put onto the shared network drive and put it in my own home directory, this time un-hidden. Clearly our teacher was already suspicious and
investigating, because within a few days, this was all that was needed for me to get caught and disciplined13.
I was disappointed not to be asked how I did it, because I was sufficiently proud of my approach that I’d hoped to be able to brag about it to somebody who’d
understand… but I guess our teacher just wanted to brush it under the carpet and move on.
Aftermath
The school’s IT admin certainly never worked-out the true scope of my work. My “hidden” files remained undiscovered, and my friends were able to continue to use my special Word template
to play games that I’d introduced to the network14.
I checked, and the hidden files were still there when I graduated.
The warning worked: I kept my nose clean in computing classes for the remainder of secondary school. But I would’ve been happy to, anyway: I already felt like I’d “solved” the challenge
of turning the school computer network to my interests and by now I’d moved on to other things… learning how to reverse-engineer phone networks… and credit card processors… and
copy-protection systems. Oh, the stories I could tell15.
I “get” it that some of my classmates – including some of those pictured – were mostly interested in the results of my hacking efforts. But for me it always was – and still
is – about the journey of discovery.
But I’ll tell you what: 13-ish year-old me ought to be grateful to the RM Nimbus network at my school for providing an interesting system about which my developing “hacker brain” could
ask: what can I make it do?
Which remains one of the most useful questions with which to foster a hacker mentality.
Footnotes
1 I first played Game of Life on an Amstrad CPC464, or possibly a PC1512.
2 What is the earliest experience to which I can credit my “hacker mindset”?
Tron and WarGames might have played a part, as might have the
“hacking” sequence in Ferris Bueller’s Day Off. And there was the videogame Hacker and its sequel (it’s funny to
see their influence in modern games). Teaching myself to program so that I could make
text-based adventures was another. Dissecting countless obfuscated systems to see how they worked… that’s yet another one: something I did perhaps initially to cheat at games by
poking their memory addresses or hexediting their save games… before I moved onto reverse-engineering copy protection systems and working out how they could be circumvented… and then
later still when I began building hardware that made it possible for me to run interesting experiments on telephone networks.
Any of all of these datapoints, which took place over a decade, could be interpreted as “the moment” that I became a hacker! But they’re not the ones I’m talking about today.
Today… is the story of the RM Nimbus.
3 Whatever happened to Recorder? After it disappeared in Windows 95 I occasionally had
occasion to think to myself “hey, this would be easier if I could just have the computer watch me and copy what I do a few times.” But it was not to be: Microsoft decided that this
level of easy automation wasn’t for everyday folks. Strangely, it wasn’t long after Microsoft dropped macro recording as a standard OS feature that Apple decided that MacOS
did need a feature like this. Clearly it’s still got value as a concept!
4 Just to clarify: I put more effort in to making animations, which were not part of
my schoolwork back when I was a kid. I certainly didn’t put more effort into my education.
5 The computers had been configured to make DOS access challenging: a boot menu let you
select between DOS and Windows, but both were effectively nerfed. Booting into DOS loaded an RM-provided menu that couldn’t be killed; the MS-DOS prompt icon was absent from Program
Manager and quitting Windows triggered an immediate shutdown.
6 My secondary school didn’t get Internet access during the time I was enrolled there. I
was recently trying to explain to one of my kids the difference between “being on a network” and “having Internet access”, and how often I found myself on a network that wasn’t
internetworked, back in the day. I fear they didn’t get it.
7 I was in the habit of occasionally hooking up PCs together with null modem cables, but only much later on would I end up acquiring sufficient “thinnet”
10BASE2 kit that I could throw together a network for a LAN party.
8 Initially I was looking to sidestep the space limitation enforcement on my “home”
directory, and also to put the illicit software I was bringing in somewhere that could not be trivially-easily traced back to me! But later on this “shared” directory became the
repository from which I’d distribute software to my friends, too.
9 The school computer didn’t have soundcards and nobody would have wanted PC speakers
beeping away in the classroom while they were trying to play a clandestine videogame anyway.
10 The admin password was concepts. For at least four years.
11 Please remember that at this point I was a young teenager and so was pretty well
over-fixated on what my peers thought of me! A big part of the persona I presented was of somebody who didn’t care what others thought of him, I’m sure, but a mask that
doesn’t look like a mask… is still a mask. But yeah: I had a shortage of self-confidence and didn’t feel able to say no.
13 I was briefly alarmed when there was talk of banning me from the computer lab for
the remainder of my time at secondary school, which scared me because I was by now half-way through my
boring childhood “life plan” to become a computer programmer by what seemed to be the appropriate route, and I feared that not being able to do a GCSE in a CS-adjacent subject
could jeopardise that (it wouldn’t have).
14 That is, at least, my friends who were brave enough to carry on doing so after the
teacher publicly (but inaccurately) described my alleged offences, seemingly as a warning to others.
15 Oh, the stories I probably shouldn’t tell! But here’s a teaser: when I
built my first “beige box” (analogue phone tap hardware) I experimented with tapping into the phone line at my dad’s house from the outside. I carefully shaved off some of
the outer insulation of the phone line that snaked down the wall from the telegraph pole and into the house through the wall to expose the wires inside, identified each, and then
croc-clipped my box onto it and was delighted to discovered that I could make and receive calls “for” the house. And then, just out of curiosity to see what kinds of protections were
in place to prevent short-circuiting, I experimented with introducing one to the ringer line… and took out all the phones on the street. Presumably I threw a circuit breaker in the
roadside utility cabinet. Anyway, I patched-up my damage and – fearing that my dad would be furious on his return at the non-functioning telecomms – walked to the nearest functioning
payphone to call the operator and claim that the phone had stopped working and I had no idea why. It was fixed within three hours. Phew!
I just needed to spin up a new PHP webserver and I was amazed how fast and easy it was, nowadays. I mean: Caddyalready makes it
pretty easy, but I was delighted to see that, since the last time I did this, the default package repositories had 100% of what I needed!
Apart from setting the hostname, creating myself a user and adding them to the sudo group, and reconfiguring sshd to my preference, I’d
done nothing on this new server. And then to set up a fully-functioning PHP-powered webserver, all I needed to run (for a domain “example.com”) was:
After that, I was able to put an index.php file into /var/www/example.com and it just worked.
And when I say “just worked”, I mean with all the bells and whistles you ought to expect from Caddy. HTTPS came as standard (with a solid QualSys grade). HTTP/3 was supported with a
0-RTT handshake.
As part of my efforts to reclaim the living room from the children, I’m building a new gaming PC for the playroom. She’s called Bee, and – thanks to the absolute insanity that is
The Tower 300 case from Thermaltake – she’s one of the most bonkers PC cases I’ve ever worked in.
I’m not saying the plain-text is the best web experience. But it is an experience. Perfect if you like your browsing fast, simple, and readable. There are no
cookie banners, pop-ups, permission prompts, autoplaying videos, or garish colour schemes.
I’m certainly not the first person to do this, so I thought it might be fun to gather a list of websites which you browse in text-only mode.
…
Terence Eden’s maintaining a list of websites that are presented as, or are wholly or partially available via, plain text. Obviously my own text/plain
blog is among them, and is as far as I’m aware the only one to be entirely presented as text/plain.
Anyway, this inspired me to write a post of my own (on text/plain blog, of course!), in which I ask the question: what do we
consider plain text? Based on the sites in the list, Markdown is permissible as plain text, (for the purposes of Terence’s list), but this implies that “plain text” is a
spectrum of human-readability.
If Markdown’s fine, then presumably Gemtext would be too? How about BBCode? HTML and RTF are explicitly excluded by Terence’s rules,
but I’d argue that HTML 1.0 could be more human-readable than some of the more-sophisticated dialects of BBCode (or any Markdown that contains tables, unless those tables are laid-out
in a way that specifically facilitates human-readability)?
As I say in my post:
<-- More human-readable Less human-readable -->
|-----------|-----------|-----------|------------|-----------|-----------|-----------|-----------|
Plain text Gemtext Markdown BBCode HTML 1.0 Modern HTML RTF
This provocation is only intended to get you to think about “what does it mean for a markup language to be ‘human readable’?” Where do you draw the line?
Over the Christmas break I dug out my old HTC Vive VR gear, which I got way back in the Spring of 2016. Graphics card technology having come a long
way1,
it was now relatively simple to set up a fully-working “holodeck” in our living room with only a slight risk to the baubles on the Christmas tree.
For our younger child, this was his first experience of “roomscale VR”, which I maintain is the most magical thing about this specific kind of augmented
reality. Six degrees of freedom for your head and each of your hands provides the critical level of immersion, for me.
And you know what: this ten-year-old hardware of mine still holds up and is still awesome!2
The kids and I have spent a few days dipping in and out of classics like theBlu, Beat Saber, Job Simulator, Vacation Simulator, Raw Data,
and (in my case3)
Half-Life: Alyx.
It doesn’t feel too heavy, but this first edition Vive sure is a big beast, isn’t it?
I’m moderately excited by the upcoming Steam Frame with its skinny headset, balanced weight, high-bandwidth
wireless connectivity, foveated streaming, and built-in PC for basic gaming… but what’s with those controllers? Using AA batteries instead of a built-in rechargeable one feels like a
step backwards, and the lack of a thumb “trackpad” seems a little limiting too. I’ll be waiting to see the reviews, thanks.
When I looked back at my blog to double-check that my Vive really is a decade old, I was reminded that I got it in the same month at Three
Rings‘ 2016 hackathon, then called “DevCamp”, near Tintern4.
This amused me, because I’m returning to Tintern this year, too, although on family holiday rather than Three Rings business. Maybe I’ll visit on a third occasion in
another decade’s time, following another round of VR gaming?
Footnotes
1 The then-high-end graphics card I used to use to drive this rig got replaced
many years ago… and then that replacement card in turn got replaced recently, at which point it became a hand-me-down for our media centre PC in the living room.
2 I’ve had the Vive hooked-up in the office since our house move in 2020, but there’s rarely been space for roomscale play there: just an occasional bit of Elite: Dangerous at my desk…
which is still a good application of VR, but not remotely the same thing as being able to stand up and move around!
3 I figure Alyx be a little scary/intense for the kids, but I could be
wrong. I think the biggest demonstration of how immersive the game can be in VR is the moment when you see how somebody can watch it played on the big screen and be fine but as soon
as they’re in the headset and a combine zombie has you pinned-down in a railway carriage and it’s suddenly way too much!
4 Where, while doing a little geocaching, I messed-up a bonus cache’s coordinate
calculation, realised my mistake, brute-forced the possible answers, narrowed it down to two… and then picked the wrong one and fell off a cliff.