There are video games that I’ve spent
many years playing (sometimes on-and-off) before finally beating them for the first time. I spent three years playing Dune II before I finally beat it as every house. It took twice that to reach the end of Ultima Underworld II.
But today, I can add a new contender1 to that list.
Today, over thirty-five years after I first played it, I finally completed Wonder Boy.
My first experience of the game, in the 1980s, was on a coin-op machine where I’d discovered I could get away with trading the 20p piece I’d been given by my parents to use as a deposit
on a locker that week for two games on the machine. I wasn’t very good at it, but something about the cutesy graphics and catchy chip-tune music grabbed my attention and it became my
favourite arcade game.
Of all the video games about skateboarding cavemen I’ve ever played, it’s my favourite.
I played it once or twice more when I found it in arcades, as an older child. I played various console ports of it and found them disappointing. I tried it a couple of times in MAME. But I didn’t really put any effort into it until a hotel we stayed at during a family holiday to Paris in October had a bank of free-to-play arcade machines
rigged with Pandora’s Box clones so they could be used to play a few thousand different arcade classics. Including Wonder Boy.
Our eldest was particularly taken with Wonder Boy, and by the time we set off for home at the end of our holiday she’d gotten further than I ever had at it (all
without spending a single tenpence).
Off the back of all the fun the kids had, it’s perhaps no surprise that I arranged for a similar machine to be delivered to us as a gift “to the family”2
this Christmas.
If you look carefully, you can work out which present it it, despite the wrapping.
And so my interest in the game was awakened and I threw easily a hundred pounds worth of free-play games of Wonder Boy3 over the last few days. Until…
…today, I finally defeated the seventh ogre4,
saved Tina5, saved the kingdom, etc. It was a hell of a battle. I can’t count how many times I pressed the “insert coin” button on
that final section, how many little axes I’d throw into the beast’s head while dodging his fireballs, etc.
So yeah, that’s done, now. I guess I can get back to finishing Wonder Boy: The Dragon’s Trap, the 2017 remake of a 1989 game I
adored!6
It’s aged amazingly well!
Footnotes
1 This may be the final record for time spent playing a video game before beating it,
unless someday I ever achieve a (non-cheating) NetHack ascension.
2 The kids have had plenty of enjoyment out of it so far, but their time on the machine is
somewhat eclipsed by Owen playing Street Fighter II Turbo and Streets of Rage on it and, of course, by my rediscovered obsession with Wonder Boy.
3 The arcade cabinet still hasn’t quite paid for itself in tenpences-saved,
despite my grinding of Wonder Boy. Yet.
4 I took to calling the end-of-world bosses “ogres” when my friends and I swapped tips for
the game back in the late 80s, and I refuse to learn any different name for them.
5 Apparently the love interest has a name. Who knew?
6 I completed the original Wonder Boy III: The Dragon’s Trap on a Sega Master
System borrowed from my friend Daniel back in around 1990, so it’s not a contender for the list either.
The programmers at British Gas are among the many who don’t believe that a surname can be only a single character, and their customer service agents have clearly worked around their
validations (or just left a note for themselves in the problematic field!)… leading to hilarious postal mail1:
Update
This is getting a lot of attention, so I just wanted to add:
I’ve already seen Falsehoods Programmers Believe About Names, thanks. I linked it above, but you probably didn’t see the link if you
found me via all the Mastodon boosts this post is getting.
Tracy Durnell’s post
about blogrolls really spoke to me. Like her, I used to think of a blogroll as a list of people you know personally (who happen to blog)1, but the number of bloggers among my immediate
in-person circle of friends has shrunk from several dozen to just a handful, and I dropped my blogroll in around 2008.
On the Internet, a blogger is only as alone as they choose to be.
But my connection to a wider circle has grown, and like Tracy I enjoy the “hardly strangers” connection I feel with the people I follow online. She writes:
While social media emphasizes the show-off stuff — the vacation in Puerto Vallarta, the full kitchen remodel, the night out on the town — on blogs it still seems that people are
sharing more than signalling. These small pleasures seem to be offered in a spirit of generosity — this is too beautiful not to share.
…
Although I may never interact with all the folks whose blogs I follow, reading the same blogger for a long time does build a (one-sided) connection. I may not know you, author,
but I am rooting for you. It’s a different modality of relationship than we may be used to in person, but it’s real: a parasocial relationship simmering with the potential for
deeper connection, but also satisfying as it exists.
At its core, blogging is a solitary activity with many (if not most) authors claiming that their blog is for them – myself included. Yet, the implication of audience cannot be
ignored. Indeed, the more an author embeds themself in the loose community of blogs, by reading and linking to others, the more that implication becomes reality even if not actively
pursued via comments or email.
To that end: I’ve started publishing my blogroll again! Follow that link and you’ll see an only-lightly-curated list of all the people (plus
some non-personal blogs, vlogs, and webcomics) I follow (that have updated their feeds within the last year2). Naturally, there’s an
OPML version too, and I’ve open-sourced the code I used to generate it (although I can’t imagine
anybody’s situation is enough like mine for it to be useful).
The page is a little flaky and there’s things I’d like to do to improve it, but I’d rather publish a basic version now and then come back to it with my gardening gloves on another time to improve it.
Maybe my blogroll has some folks on that you might recognise? Or else: maybe you’re only a single random-click away from somebody new you
never heard of before!
Footnotes
1 Possibly marked up with XFN to
indicate how you’re connected to one another, but I’ve always had a soft spot
for XFN.
theunderground.blog is an experimental blog that is only available to read through a feed reader.
If you would like to read the latest posts, you can subscribe to the feed at https://theunderground.blog/feed.xml, using the feed reader of your choice.
…
Chris first suggested this idea in the footnote of a post that talks about something I’ve been witnessing recently: that
blogging seems to be having a renaissance1. I’ve
for a few years been telling people that now is the second-best time to start a blog. The best time was, of course, ~20 years ago, but if you missed out first time around (or
let your blog die as big social media silos took over): now’s the time to join the growing resurgence!
There’s two posts published so far, and if you want to read them you’ll need to subscribe to theunderground.blog using your feed reader. There’s tips on that page on getting an easy-to-use one if you haven’t already.
Footnotes
1 He also had interesting things to say about OPML, which is a topic close to my heart. I wonder if I ought to start sharing a partial OPML file of my subscriptions?
2 Or by reading the source code, I suppose: on the open Web, that’s always an option. The
Web is, indeed, magical.
During a conversation with a colleague last week, I claimed that while I blog more-frequently than I did 5-10 years ago, it’s still with a much lower frequency than say 15-20 years ago.
Only later did I stop to think: is that actually true? It’s time for a graph!
Generating a chart...
If this message doesn't go away, the JavaScript that makes this magic work probably isn't doing its job right: please tell Dan so he can fix it.
Generating a chart...
If this message doesn't go away, the JavaScript that makes this magic work probably isn't doing its job right: please tell Dan so he can fix it.
If you consider just articles (and optionally notes, which some older content might have been better classified-as, in
retrospect) it looks like I’m right. Long gone are months like February 2005 when I posted an average of three times every two days! November
2018 was a bit of an anomaly as a I live-tweeted Challenge Robin II: my recent output’s mostly been comparable to the “quiet period”
from 2008-20102.
Looking at number of posts by month of the year, it’s interesting to see a pronounced “dip” in all kinds of output roundabout March, less reposts in
Summer and Autumn, and – perhaps unsurprisingly – more checkins (which often represent geocaching/geohashing logs) in the warmer months.
Even on this scale, you can see the impact of the November “Challenge Robin spike” in the notes:
Generating a chart...
If this message doesn't go away, the JavaScript that makes this magic work probably isn't doing its job right: please tell Dan so he can fix it.
Anyway, now I’ve actually automated these kinds of stats its easier than ever for me to ask questions about how and when I write in my blog. I’ve put living copies of the
charts plus additional treats (want to know when my longest “daily streak” was?) on a special page dedicated to that purpose. It’ll be interesting to see how it
looks on this blog’s 25th anniversary, in a little under a year!
Footnotes
1 Try clicking on any of the post kinds in the legend to add/remove them, or
click-and-drag a range across the chart to zoom in.
2 In hindsight, I was clearly depressed in and around
2009 and this doubtless impacted my ability to engage in “creative” pursuits.
You can click an image and see a full-window popup dialog box containing a larger version of the image.
The larger version of the image isn’t loaded until it’s needed.
You can close the larger version with a close button. You can also use your browser’s back button.
You can click again to download the larger version/use your browser to zoom in further.
You can share/bookmark etc. the URL of a zoomed-in image and the recipient will see the same image (and return to the
image, in the right blog post, if they press the close button).
No HTTP round trip is required when opening/closing a lightbox: it’s functionally-instantaneous.2
No JavaScript is used at all.
Visitors can click on images to see a larger version, with a “close” button. No JavaScript needed.
Here’s how it works –
The Markup
<figureid="img3336"aria-describedby="caption-img3336"><ahref="#lightbox-img3336"role="button"><imgsrc="small-image.jpg"alt="Alt text is important."width="640"height="480"></a><figcaptionid="caption-img3336">
Here's the caption.
</figcaption></figure>
... (rest of blog post) ...
<dialogid="lightbox-img3336"class="lightbox"><ahref="large-image.jpg"><imgsrc="large-image.jpg"loading="lazy"alt="Alt text is important."></a><aclass="close"href="#img3336"title="Close image"role="button">×</a></dialog>
The HTML is pretty simple (and I automatically generate it, of course).
For each lightboxed image in a post, a <dialog> for that image is appended to the post. That dialog contains a larger copy of the image (set to
loading="lazy" so the browser have to download it until it’s needed), and a “close” button.
The image in the post contains an anchor link to the dialog; the close button in the dialog links back to the image in the post.3 I wrap the lightbox image itself in a link to the full version of the
image, which makes it easier for users to zoom in further using their browser’s own tools, if they like.
Even without CSS, this works (albeit with “scrolling” up and down to the larger image). But the clever bit’s yet to
come:
The Style
body:has(dialog:target) {
/* Prevent page scrolling when lightbox open (for browsers that support :has()) */position:fixed;
}
a[href^='#lightbox-'] {
/* Show 'zoom in' cursor over lightboxed images. */cursor: zoom-in;
}
.lightbox {
/* Lightboxes are hidden by-default, but occupy the full screen and top z-index layer when shown. */all:unset;
display:none;
position:fixed;
top:0;
left:0;
width:100%;
height:100%;
z-index:2;
background:#333;
}
.lightbox:target {
/* If the target of the URL points to the lightbox, it becomes visible. */display: flex;
}
.lightboximg {
/* Images fill the lightbox. */object-fit:contain;
height:100%;
width:100%;
}
/* ... extra CSS for styling the close button etc. ... */
Here’s where the magic happens.
Lightboxes are hidden by default (display: none), but configured to fill the window when shown.
They’re shown by the selector .lightbox:target, which is triggered by the id of the <dialog> being referenced by the anchor part of
the URL in your address bar!
Summary
It’s neither the most-elegant nor cleanest solution to the problem, but for me it hits a sweet spot between developer experience and user experience. I’m always disappointed when
somebody’s “lightbox” requires some heavyweight third-party JavaScript (often loaded from a CDN), because that seems to be the
epitome of the “take what the Web gives you for free, throw it away, and reimplement it badly in JavaScript” antipattern.
There’s things I’ve considered adding to my lightbox. Progressively-enhanced JavaScript that adds extra value and/or uses the Popover API where available, perhaps? View Transitions to animate the image “blowing up” to the larger size, while the full-size image loads in the
background? Optimistic preloading when hovering over the image4? “Previous/next” image links when lightboxing a gallery? There’s lots of potential to expand it
without breaking the core concept here.
I’d also like to take a deeper dive into the accessibility implications of this approach: I think it’s pretty good, but accessibility is a big topic and there’s always more to
learn.
In the meantime, why not try out my lightbox by clicking on this picture of my dog (photographed here staring longingly at the bacon sandwich picture above, perhaps).
I hope the idea’s of use to somebody else looking to achieve this kind of thing, too.
Footnotes
1 Where JavaScript is absolutely necessary, I (a) host it on the same domain, for
performance and privacy-respecting reasons, and (b) try to provide a functional alternative that doesn’t require JavaScript, ideally seamlessly.
2 In practice, the lightbox images get lazy-loaded, so there can be a short round
trip to fetch the image the first time. But after that, it’s instantaneous.
3 The pair – post image and lightbox image – work basically the same way as footnotes,
like this one.
4 I already do this with links in general using the excellent instant.page.
The web loves data. Data about you. Data about who you are, about what you do, what you love doing, what you love eating.
…
I, on the other end, couldn’t care less about your data. I don’t run analytics on this website. I don’t care which articles you read, I don’t care if you read them. I don’t care about
which post is the most read or the most clicked. I don’t A/B test, I don’t try to overthink my content. I just don’t care.
…
Manu speaks my mind. Among the many hacks I’ve made to this site, I actively try not to invade on your privacy by
collecting analytics, and I try not to let others to so either!
My blog is for myself
first and foremost (if you enjoy it too, that’s just a bonus). This leads to two conclusions:
If I’m the primary audience, I don’t need analytics (because I know who I am), and
I don’t want to be targeted by invasive analytics (and use browser extensions to block them, e.g. I by-default block all third-party scripts, delete cookies from non-allowlisted
domains 15 seconds after navigating away from sites, etc.); so I’d prefer them not to be on a site for which I’m the primary audience!
I’ve gone into more detail about this on my privacy page and hinted at it on my colophon. But I don’t know if anybody ever reads either
of those pages, of course!
Naturally, I was delighted, not least because it gives me an excuse to use the “deed poll” and “music” tags simultaneously on a post for the first time.
Don’t ask me what my “real” name is,
I’ve already told you what it was,
And I’m planning on burning my birth certificate.
The song’s about discovering and asserting self-identity through an assumed, rather than given, name. Which is fucking awesome.
The website’s basically unchanged for most of a decade and a half, and… umm… it looks it. I really ought to get around to improving and enhancing it someday.
Like virtually all of my sites, including this one, freedeedpoll.org.uk deliberately retains minimal logs and has no analytics tools. As a result, I have very little concept of how
popular it is, how widely it’s used etc., except when people reach out to me.
People do: I get a few emails every month from people who’ve got questions1,
or who are having trouble
getting their homemade deed poll accepted by troublesome banks. I’m happy to help them, but without additional context, I can’t be sure whether these folks represent the entirety of the
site’s users, a tiny fraction, or somewhere in-between.
So it’s obviously going to be a special surprise for me to have my website featured in a song.
I’ve been having a challenging couple of weeks2,
and it was hugely uplifting for me to bump into these appreciative references to my work in the wider Internet.
Footnotes
1 Common questions I receive are about legal gender recognition, about changing the names
of children, about changing one’s name while still a minor without parental consent, or about citizenship requirements. I’ve learned a lot about some fascinating bits of law.
This post is also available as an article. So
if you'd rather read a conventional blog post of this content, you can!
This is a video version of my blog post, Length Extension Attack. In it, I talk through the theory of length extension
attacks and demonstrate an SHA-1 length extension attack against an (imaginary) website.
This post is also available as a video. If you'd
prefer to watch/listen to me talk about this topic, give it a look.
Prefer to watch/listen than read? There’s a vloggy/video version of this post in which I explain all the
key concepts and demonstrate an SHA-1 length extension attack against an imaginary site.
I understood the concept of a length traversal
attack and when/how I needed to mitigate them for a long time before I truly understood why they worked. It took until work provided me an opportunity to play with one in practice (plus reading Ron Bowes’ excellent article on the subject) before I really grokked it.
For the demonstration, I’ve built a skeletal stock photography site whose download links are protected by a hash of the link parameters, salted using a secret string stored securely
on the server. Maybe they let authorised people hotlink the images or something.
You can check out the code and run it using the instructions in the
repository if you’d like to play along.
Using hashes as message signatures
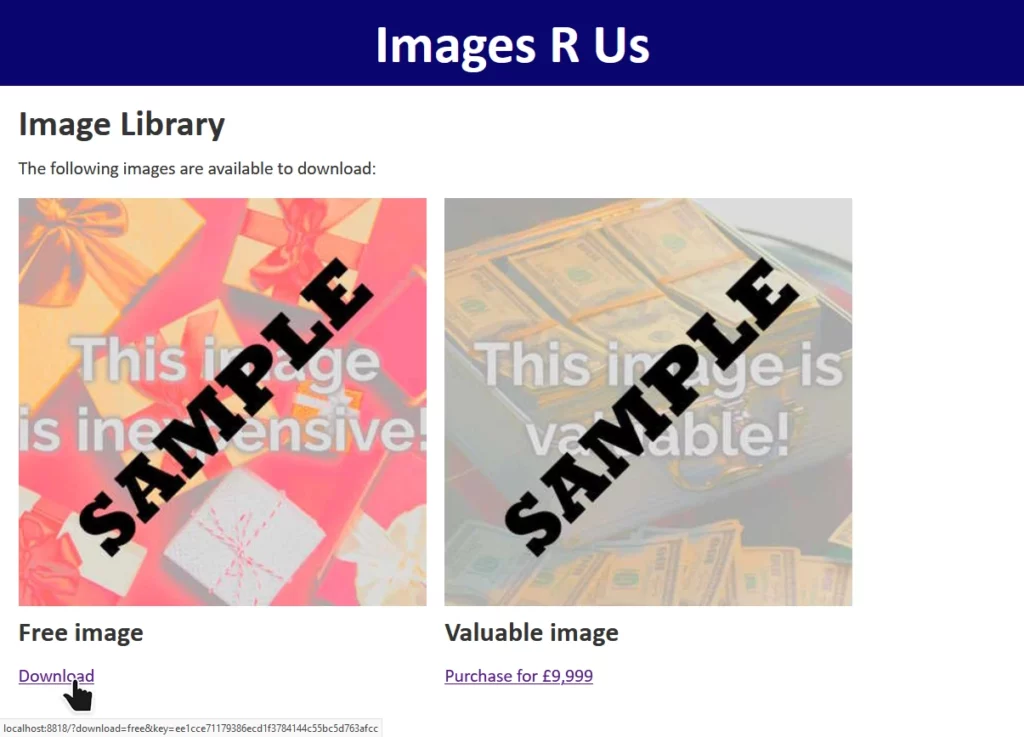
The site “Images R Us” will let you download images you’ve purchased, but not ones you haven’t. Links to the images are protected by a SHA-1 hash1, generated as follows:
The nature of hashing algorithms like SHA-1 mean that even a small modification to the inputs, e.g. changing one character in
the word “free”, results in a completely different output hash which can be detected as invalid.
When a “download” link is generated for a legitimate user, the algorithm produces a hash which is appended to the link. When the download link is clicked, the same process is followed
and the calculated hash compared to the provided hash. If they differ, the input must have been tampered with and the request is rejected.
Without knowing the secret key – stored only on the server – it’s not possible for an attacker to generate a valid hash for URL parameters of the attacker’s choice. Or is it?
Changing download=free to download=valuable invalidates the hash, and the request is denied.
Actually, it is possible for an attacker to manipulate the parameters. To understand how, you must first understand a little about how SHA-1 and its siblings actually work:
SHA-1‘s inner workings
The message to be hashed (SECRET_KEY + URL_PARAMS) is cut into blocks of a fixed size.2
The final block is padded to bring it up to the full size.3
A series of operations are applied to the first block: the inputs to those operations are (a) the contents of the block itself, including any padding, and (b) an initialisation
vector defined by the algorithm.4
The same series of operations are applied to each subsequent block, but the inputs are (a) the contents of the block itself, as before, and (b) the output of the previous
block. Each block is hashed, and the hash forms part of the input for the next.
The output of running the operations on the final block is the output of the algorithm, i.e. the hash.
SHA-1 operates on a single block at a time, but the output of processing each block acts as part of the input of the one that
comes after it. Like a daisy chain, but with cryptography.
In SHA-1, blocks are 512 bits long and the padding is a 1, followed by as many 0s as is necessary,
leaving 64 bits at the end in which to specify how many bits of the block were actually data.
Padding the final block
Looking at the final block in a given message, it’s apparent that there are two pieces of data that could produce exactly the same output for a given function:
The original data, (which gets padded by the algorithm to make it 64 bytes), and
A modified version of the data, which has be modified by padding it in advance with the same bytes the algorithm would; this must then be followed by an
additional block
A “short” block with automatically-added padding produces the same output as a full-size block which has been pre-populated with the same data as the padding would
add.5In the case where we insert our own “fake” padding data, we can provide more message data after the padding and predict the overall hash. We can do this because
we the output of the first block will be the same as the final, valid hash we already saw. That known value becomes one of the two inputs into the function for the block that
follows it (the contents of that block will be the other input). Without knowing exactly what’s contained in the message – we don’t know the “secret key” used to salt it – we’re
still able to add some padding to the end of the message, followed by any data we like, and generate a valid hash.
Therefore, if we can manipulate the input of the message, and we know the length of the message, we can append to it. Bear that in mind as we move on to the other half
of what makes this attack possible.
Parameter overrides
“Images R Us” is implemented in PHP. In common with most server-side scripting languages,
when PHP sees a HTTP query string full of key/value pairs, if
a key is repeated then it overrides any earlier iterations of the same key.
Many online sources say that this “last variable matters” behaviour is a fundamental part of HTTP, but it’s not: you can
disprove is by examining $_SERVER['QUERY_STRING'] in PHP, where you’ll find the entire query string.
You could even implement your own query string handler that instead makes the first instance of each key the canonical one, if you really wanted.6It’d be tempting to simply override the download=free parameter in the query string at “Images R Us”, e.g. making it
download=free&download=valuable! But we can’t: not without breaking the hash, which is calculated based on the entire query string (minus the &key=...
bit).
But with our new knowledge about appending to the input for SHA-1 first a padding string, then an extra block containing our
payload (the variable we want to override and its new value), and then calculating a hash for this new block using the known output of the old final block as the
IV… we’ve got everything we need to put the attack together.
Putting it all together
We have a legitimate link with the query string download=free&key=ee1cce71179386ecd1f3784144c55bc5d763afcc. This tells us that somewhere on the server, this is
what’s happening:
I’ve drawn the secret key actual-size (and reflected this in the length at the bottom). In reality, you might not know this, and some trial-and-error might be necessary.7If we pre-pad the string download=free with some special characters to replicate the padding that would otherwise be added to this final8 block, we can add a second block containing
an overriding value of download, specifically &download=valuable. The first value of download=, which will be the word free followed by
a stack of garbage padding characters, will be discarded.
And we can calculate the hash for this new block, and therefore the entire string, by using the known output from the previous block, like this:
The URL will, of course, be pretty hideous with all of those special characters – which will require percent-encoding – on the end of the word ‘free’.
Doing it for real
Of course, you’re not going to want to do all this by hand! But an understanding of why it works is important to being able to execute it properly. In the wild, exploitable
implementations are rarely as tidy as this, and a solid comprehension of exactly what’s happening behind the scenes is far more-valuable than simply knowing which tool to run and what
options to pass.
That said: you’ll want to find a tool you can run and know what options to pass to it! There are plenty of choices, but I’ve bundled one called hash_extender into my example, which will do the job pretty nicely:
which algorithm to use (sha1), which can usually be derived from the hash length,
the existing data (download=free), so it can determine the length,
the length of the secret (16 bytes), which I’ve guessed but could brute-force,
the existing, valid signature (ee1cce71179386ecd1f3784144c55bc5d763afcc),
the data I’d like to append to the string (&download=valuable), and
the format I’d like the output in: I find html the most-useful generally, but it’s got some encoding quirks that you need to be aware of!
hash_extender outputs the new signature, which we can put into the key=... parameter, and the new string that replaces download=free, including
the necessary padding to push into the next block and your new payload that follows.
Unfortunately it does over-encode a little: it’s encoded all the& and = (as %26 and %3d respectively), which isn’t what we
wanted, so you need to convert them back. But eventually you end up with the URL:
http://localhost:8818/?download=free%80%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%e8&download=valuable&key=7b315dfdbebc98ebe696a5f62430070a1651631b.
Disclaimer: the image you get when you successfully exploit the test site might not actually be valuable.
And that’s how you can manipulate a hash-protected string without access to its salt (in some circumstances).
Mitigating the attack
The correct way to fix the problem is by using a HMAC in place
of a simple hash signature. Instead of calling sha1( SECRET_KEY . urldecode( $params ) ), the code should call hash_hmac( 'sha1', urldecode( $params ), SECRET_KEY
). HMACs are theoretically-immune to length extension attacks, so long as the output of the hash function used is
functionally-random9.
Ideally, it should also use hash_equals( $validDownloadKey, $_GET['key'] ) rather than ===, to mitigate the possibility of a timing attack. But that’s another story.
Footnotes
1 This attack isn’t SHA1-specific: it works just as well on many other popular hashing algorithms too.
2 SHA-1‘s blocks are 64 bytes
long; other algorithms vary.
3 For SHA-1, the padding bits
consist of a 1 followed by 0s, except the final 8-bytes are a big-endian number representing the length of the message.
4 SHA-1‘s IV is 67452301 EFCDAB89 98BADCFE 10325476 C3D2E1F0, which you’ll observe is little-endian counting from 0 to
F, then back from F to 0, then alternating between counting from 3 to 0 and C to F. It’s
considered good practice when developing a new cryptographic system to ensure that the hard-coded cryptographic primitives are simple, logical, independently-discoverable numbers like
simple sequences and well-known mathematical constants. This helps to prove that the inventor isn’t “hiding” something in there, e.g. a mathematical weakness that depends on a
specific primitive for which they alone (they hope!) have pre-calculated an exploit. If that sounds paranoid, it’s worth knowing that there’s plenty of evidence that various spy
agencies have deliberately done this, at various points: consider the widespread exposure of the BULLRUN programme and its likely influence on Dual EC
DRBG.
5 The padding characters I’ve used aren’t accurate, just representative. But there’s the
right number of them!
6 You shouldn’t do this: you’ll cause yourself many headaches in the long run. But you
could.
7 It’s also not always obvious which inputs are included in hash generation and how
they’re manipulated: if you’re actually using this technique adversarily, be prepared to do a little experimentation.
8 In this example, the hash operates over a single block, but the exact same principle
applies regardless of the number of blocks.
9 Imagining the implementation of a nontrivial hashing algorithm, the predictability of
whose output makes their HMAC vulnerable to a length extension attack, is left as an exercise for the reader.