Making a conscious daily effort to write more has been… challenging. I feel like my thoughts come out half-finished, like I’m writing too trivially, without sufficient
structure, or even too-personally. But I’m loving the challenge!
Anyway – happy birthday Matt! Forty is a great age, highly recommended. Hope you love it.
I find winters are generally bad for my creativity
and motivation, usually until I bounce back in the Spring.
In an attempt to keep me writing daily, I’m giving Bloganuary a go this year. It’s sort-of like the NaNoWriMo of blogging1. And for me, Bloganuary’s very purpose is to overcome the challenge of getting disconnected
from blogging when the nights are long and inspiration’s hard to find2.
The Challenge of Staying On-Task
But outside of the winter, my biggest challenge is usually… staying on-task!
It’s easy to get my focus to wane and for me to drift into some other activity than whatever it is I should be spending my time on. It’s not even
procrastination3 so much as it’s a
fluctuating and changing field of interest. I’ll drift off of what I’m supposed to be working on and start on something that interests me more in that moment… and then potentially off
that too, in turn. The net result is that both my personal and professional lives are awash with half-finished projects4, all waiting their turn for me to find the
motivation to swing back around and pick them up on some subsequent orbit of my brain.
You know how sometimes a stock image says exactly what you need it to? This isn’t one of those times.
It’s the kind of productivity antipattern I’d bring up with my coach, except that I already
know exactly how she’d respond. First, she’d challenge the need to change; require that I justify it first. Second, she’d insist that before I can change, I need to accept and come to
terms with who I am, intrinsically: if this flitting-about is authentically “me”, who am I to change it?
Finally, after weeks or months of exercises to fulfil these two tasks, she’d point out that I’ve now reached a place where I’m still just as liable to change lanes in the middle of a
project as I was to begin with, but now I’m more comfortable with that fact. I won’t have externally changed, I’ll “just” have found some kind of happy-clappy inner peace. And she’ll
have been right that that’s what I’d actually needed all along.
Maybe it’s not such a challenge, after all.
Footnotes
1 Except that would be NaBloPoMo, of course. But it’s a similar thing.
2 Also, perhaps, to help me focus on writing more-often, on more-topics, than I might
otherwise in the course of my slow, verbose writing.
Tracy Durnell’s post
about blogrolls really spoke to me. Like her, I used to think of a blogroll as a list of people you know personally (who happen to blog)1, but the number of bloggers among my immediate
in-person circle of friends has shrunk from several dozen to just a handful, and I dropped my blogroll in around 2008.
On the Internet, a blogger is only as alone as they choose to be.
But my connection to a wider circle has grown, and like Tracy I enjoy the “hardly strangers” connection I feel with the people I follow online. She writes:
While social media emphasizes the show-off stuff — the vacation in Puerto Vallarta, the full kitchen remodel, the night out on the town — on blogs it still seems that people are
sharing more than signalling. These small pleasures seem to be offered in a spirit of generosity — this is too beautiful not to share.
…
Although I may never interact with all the folks whose blogs I follow, reading the same blogger for a long time does build a (one-sided) connection. I may not know you, author,
but I am rooting for you. It’s a different modality of relationship than we may be used to in person, but it’s real: a parasocial relationship simmering with the potential for
deeper connection, but also satisfying as it exists.
At its core, blogging is a solitary activity with many (if not most) authors claiming that their blog is for them – myself included. Yet, the implication of audience cannot be
ignored. Indeed, the more an author embeds themself in the loose community of blogs, by reading and linking to others, the more that implication becomes reality even if not actively
pursued via comments or email.
To that end: I’ve started publishing my blogroll again! Follow that link and you’ll see an only-lightly-curated list of all the people (plus
some non-personal blogs, vlogs, and webcomics) I follow (that have updated their feeds within the last year2). Naturally, there’s an
OPML version too, and I’ve open-sourced the code I used to generate it (although I can’t imagine
anybody’s situation is enough like mine for it to be useful).
The page is a little flaky and there’s things I’d like to do to improve it, but I’d rather publish a basic version now and then come back to it with my gardening gloves on another time to improve it.
Maybe my blogroll has some folks on that you might recognise? Or else: maybe you’re only a single random-click away from somebody new you
never heard of before!
Footnotes
1 Possibly marked up with XFN to
indicate how you’re connected to one another, but I’ve always had a soft spot
for XFN.
theunderground.blog is an experimental blog that is only available to read through a feed reader.
If you would like to read the latest posts, you can subscribe to the feed at https://theunderground.blog/feed.xml, using the feed reader of your choice.
…
Chris first suggested this idea in the footnote of a post that talks about something I’ve been witnessing recently: that
blogging seems to be having a renaissance1. I’ve
for a few years been telling people that now is the second-best time to start a blog. The best time was, of course, ~20 years ago, but if you missed out first time around (or
let your blog die as big social media silos took over): now’s the time to join the growing resurgence!
There’s two posts published so far, and if you want to read them you’ll need to subscribe to theunderground.blog using your feed reader. There’s tips on that page on getting an easy-to-use one if you haven’t already.
Footnotes
1 He also had interesting things to say about OPML, which is a topic close to my heart. I wonder if I ought to start sharing a partial OPML file of my subscriptions?
2 Or by reading the source code, I suppose: on the open Web, that’s always an option. The
Web is, indeed, magical.
During a conversation with a colleague last week, I claimed that while I blog more-frequently than I did 5-10 years ago, it’s still with a much lower frequency than say 15-20 years ago.
Only later did I stop to think: is that actually true? It’s time for a graph!
Generating a chart...
If this message doesn't go away, the JavaScript that makes this magic work probably isn't doing its job right: please tell Dan so he can fix it.
Generating a chart...
If this message doesn't go away, the JavaScript that makes this magic work probably isn't doing its job right: please tell Dan so he can fix it.
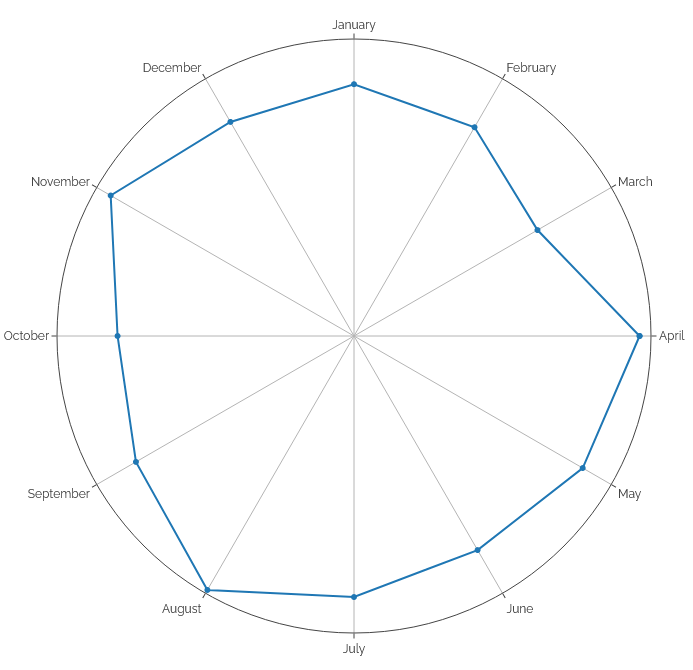
If you consider just articles (and optionally notes, which some older content might have been better classified-as, in
retrospect) it looks like I’m right. Long gone are months like February 2005 when I posted an average of three times every two days! November
2018 was a bit of an anomaly as a I live-tweeted Challenge Robin II: my recent output’s mostly been comparable to the “quiet period”
from 2008-20102.
Looking at number of posts by month of the year, it’s interesting to see a pronounced “dip” in all kinds of output roundabout March, less reposts in
Summer and Autumn, and – perhaps unsurprisingly – more checkins (which often represent geocaching/geohashing logs) in the warmer months.
Even on this scale, you can see the impact of the November “Challenge Robin spike” in the notes:
Generating a chart...
If this message doesn't go away, the JavaScript that makes this magic work probably isn't doing its job right: please tell Dan so he can fix it.
Anyway, now I’ve actually automated these kinds of stats its easier than ever for me to ask questions about how and when I write in my blog. I’ve put living copies of the
charts plus additional treats (want to know when my longest “daily streak” was?) on a special page dedicated to that purpose. It’ll be interesting to see how it
looks on this blog’s 25th anniversary, in a little under a year!
Footnotes
1 Try clicking on any of the post kinds in the legend to add/remove them, or
click-and-drag a range across the chart to zoom in.
2 In hindsight, I was clearly depressed in and around
2009 and this doubtless impacted my ability to engage in “creative” pursuits.
The web loves data. Data about you. Data about who you are, about what you do, what you love doing, what you love eating.
…
I, on the other end, couldn’t care less about your data. I don’t run analytics on this website. I don’t care which articles you read, I don’t care if you read them. I don’t care about
which post is the most read or the most clicked. I don’t A/B test, I don’t try to overthink my content. I just don’t care.
…
Manu speaks my mind. Among the many hacks I’ve made to this site, I actively try not to invade on your privacy by
collecting analytics, and I try not to let others to so either!
My blog is for myself
first and foremost (if you enjoy it too, that’s just a bonus). This leads to two conclusions:
If I’m the primary audience, I don’t need analytics (because I know who I am), and
I don’t want to be targeted by invasive analytics (and use browser extensions to block them, e.g. I by-default block all third-party scripts, delete cookies from non-allowlisted
domains 15 seconds after navigating away from sites, etc.); so I’d prefer them not to be on a site for which I’m the primary audience!
I’ve gone into more detail about this on my privacy page and hinted at it on my colophon. But I don’t know if anybody ever reads either
of those pages, of course!
Semi-inspired by a similar project by Kev Quirk,
I’ve got a project I want to run on my blog in 2024.
I want you to be my pen pal for a month. Get in touch by emailing penpals@danq.me or any other way you like and let’s do this!
We’ll use email, though, not paper.
I don’t know much about the people who read my blog, whether they’re ad-hoc visitors or regular followers1.
I’m not interested in collecting statistics about people reading this post. I’m interested in meeting them.
So here’s the plan: I’m looking to do is to fill a “dance card” of interesting people each of with whom I’ll “pen pal” for a month.
The following month, I’ll blog about the experience: who I met, what I learned about them, what I learned about myself. Have a look below and see if there’s a slot for you: I’d love to
chat to you about, well – anything!
My goals:
Get inspired to blog about new/different things (and hopefully help inspire others to do the same).
Connect with a dozen folks on a more-interpersonal level than I normally do via my blog.
Maybe even make, or deepen, some friendships!
The “rules”:
Aiming for at least 3 email exchanges over a month. Maybe more.2
There’s no specific agenda: I promise to bring what I’ve been thinking about and working on, and possibly a spicy conversation-starter from LetsLifeChat.com. You bring whatever you like. No topic is explicitly off the table unless somebody says it is (which anybody can do
at any time, for any or no reason).
I’ll blog a summary of my experience the month afterwards, but I won’t share anything without permission. I’ll happily share an unpublished draft with each penpal first so they
can veto any bits they don’t like. I’ll refer to you by whatever name, link etc. suits you best.
If you have a blog/digital garden/social presence of any kind, you’re welcome to blog about it too. Or not: entirely up to you!
You! If you’re reading this, you’re probably somebody I want to meet! But I’d be especially interested in penpalling with people who tick one or more of the following
boxes:
Personal bloggers at the edges of or just outside my usual social circles. Maybe you’re an IndieWeb, RSS Club, or Geminispace explorer?
Regular readers, whether you just skim the post titles and dive in once in a blue moon or read every post and comment on the things you care about.
Automatticians from parts of the company I don’t get to interact with. Let’s build some bridges!
People whose interests overlap with mine in any way, large or small. That overlap might be technology (web standards, accessibility, security, blogging, open
source…), hobbies (GPS sports, board games, magic, murder mysteries, science fiction, getting lost on Wikipedia…),
volunteering (third sector support, tech for good, diversity in tech…), social (queer issues, polyamory, socialism…), or something else entirely.
Missed connections. Did we meet briefly or in-passing (conferences, meetups, friends-of-friends, overlapping volunteering circles) but not develop anything further?
I’d love to pick up where we left off!
Distant- and nearly-friends. Did we drift apart long ago, or never quite move into one another’s orbit in the first place? This could be your excuse to touch bases!
If you read this far and didn’t email penpals@danq.me yet, go do that. I’m looking forward to hearing from you!
Footnotes
1 Not-knowing who reads my blog might come at least in part from the fact that I actively sabotage any plugin that might
give me any analytics! One might say I’ve shot myself in the foot, there.
2 If we stay in touch afterwards that’s fine too, but it’s not essential.
3 I’m looking for longer-form, but slower, communication than you get via e.g. instant
messengers and whatnot: a more “penpal” experience.
I’ve made a handful of tweaks to my RSS feed which I feel improves upon
WordPress’s default implementation, at least in my use-case.1 In case any of these improvements help
you, too, here’s a list of them:
Post Kinds in Titles
Since 2020, I’ve decorated post titles by prefixing them with the “kind” of post they are (courtesy of the Post Kinds
plugin). I’ve already written about how I do it, if you’re
interested.
Identifying post kinds is particularly useful for people who subscribe by
email (the emails are generated off the RSS feed either daily or weekly: subscriber’s choice), who might want to see
articles and videos but not care about for example checkins and reposts.
RSS Only posts
A minority of my posts are – initially, at least – publicised only via my RSS feed (and places that are directly fed
by it, like email subscribers). I use a tag to identify posts to be hidden in this way. I’ve
written about my implementation before, but I’ve since made a couple of additional improvements:
Suppressing the tag from tag clouds, to make it harder to accidentally discover these posts by tag-surfing,
Tweaking the title of such posts when they appear in feeds (using the same technique as above), so that readers know when they’re seeing “exclusive” content, and
Setting a X-Robots-Tag: noindex, nofollow HTTP header when viewing such tag or a post, to discourage
search engines (code for this not shown below because it’s so very specific to my theme that it’s probably no use to anybody else!).
// 1. Suppress the "rss club" tag from tag clouds/the full tag listfunctionrss_club_suppress_tags_from_display( string $tag_list, string $before, string $sep, string $after, int $post_id ): string {
foreach(['rss-club'] as$tag_to_suppress){
$regex=sprintf( '/<li>[^<]*?<a [^>]*?href="[^"]*?\/%s\/"[^>]*?>.*?<\/a>[^<]*?<\/li>/', $tag_to_suppress );
$tag_list=preg_replace( $regex, '', $tag_list );
}
return$tag_list;
}
add_filter( 'the_tags', 'rss_club_suppress_tags_from_display', 10, 5 );
// 2. In feeds, tweak title if it's an RSS exclusivefunctionrss_club_add_rss_only_to_rss_post_title( $title ){
$post_tag_slugs=array_map(function($tag){ return$tag->slug; }, wp_get_post_tags( get_the_ID() ));
if ( !in_array( 'rss-club', $post_tag_slugs ) ) return$title; // if we don't have an rss-club tag, drop out herereturn trim( "{$title} [RSS Exclusive!]" );
return$title;
}
add_filter( 'the_title_rss', 'rss_club_add_rss_only_to_rss_post_title', 6 );
Adding a stylesheet
Adding a stylesheet to your feeds can make them much friendlier to beginner users (which helps drive adoption) without making them much less-convenient for people who know how
to use feeds already. Darek Kay and Terence Eden both wrote great articles about this just
earlier this year, but I think my implementation goes a step further.
In addition to adding some “Q” branding, I made tweaks to make it work seamlessly with both my RSS and Atom feeds by using
two<xsl:for-each> blocks and exploiting the fact that the two standards don’t overlap in their root namespaces. Here’s my full XSLT; you need to
override your feed template as Terence describes to use it, but mine can be applied to both RSS and Atom.2
I’ve still got more I’d like to do with this, for example to take advantage of the thumbnail images I attach to posts. On which note…
Thumbnail images
When I first started offering email subscription options I used Mailchimp’s RSS-to-email service, which was… okay,
but not great, and I didn’t like the privacy implications that came along with it. Mailchimp support adding thumbnails to your email template from your feed, but WordPress themes don’t
by-default provide the appropriate metadata to allow them to do that. So I installed Jordy Meow‘s RSS Featured Image plugin which did it for me.
<item><title>[Checkin] Geohashing expedition 2023-07-27 51 -1</title><link>https://danq.me/2023/07/27/geohashing-expedition-2023-07-27-51-1/</link>
...
<media:contenturl="https://bcdn.danq.me/_q23u/2023/07/20230727_141710-1024x576.jpg"medium="image"/><media:description>Dan, wearing a grey Three Rings hoodie, carrying French Bulldog Demmy, standing on a path with trees in the background.</media:description></item>
Media attachments for RSS feeds are perhaps most-popular for podcasts, but they’re also great for post thumbnail images.
During my little redesign earlier this year I decided to go two steps further: (1) ditching the
plugin and implementing the functionality directly into my theme (it’s really not very much code!), and (2) adding not only a <media:content medium="image" url="..."
/> element but also a <media:description> providing the default alt-text for that image. I don’t know if any feed readers (correctly) handle this
accessibility-improving feature, but my stylesheet above will, some day!
So there we have it: a little digital gardening, and four improvements to WordPress’s default feeds.
RSS may not be as hip as it once was, but little improvements can help new users find their way into this (enlightened?) way
to consume the Web.
If you’re using RSS to follow my blog, great! If it’s not for you, perhaps pick your favourite alternative way to get updates, from options including email, Telegram, the Fediverse (e.g. Mastodon), and more…
1 The changes apply to the Atom
feed too, for anybody of such an inclination. Just assume that if I say RSS I’m including Atom, okay?
2 The experience of writing this transformation/stylesheet also gave me yet another opportunity to remember how much I hate
working with XSLTs. This time around, in addition to the normal namespace issues and headscratching
syntax, I had to deal with the fact that I initially tried to use a feature from XSLT version 2.0 (a
22-year-old version) only to discover that all major web browsers still only support version 1.0 (specified last millenium)!
There’s a perception that a blog is a long-lived, ongoing thing. That it lives with and alongside its author.1
But that doesn’t have to be true, and I think a lot of people could benefit from “short-term” blogging. Consider:
Photoblogging your holiday, rather than posting snaps to social media
You gain the ability to add context, crosslinking, and have permanent addresses (rather than losing eveything to the depths of a feed). You can crosspost/syndicate to your favourite
socials if that’s your poison..
Photoblog your holiday and I might follow it, and I’ll do so at my convenience. Put your snaps on Facebook and I almost certainly won’t bother. Photo courtesy ArtHouse Studio.
Blogging your studies, rather than keeping your notes to yourself
Writing what you learn helps you remember it; writing what you learn in a public space helps others learn too and makes it easy to search for your discoveries later.2
Recording your roleplaying, rather than just summarising each session to your fellow players
My D&D group does this at levellers.blog! That site won’t continue to be updated forever – the party will someday retire or, more-likely, come to a
glorious but horrific end – but it’ll always live on as a reminder of what we achieved.
One of my favourite examples of such a blog was 52 Reflect3 (now integrated into its successor The Improbable Blog). For 52 consecutive weeks my partner‘s brother Robin
blogged about adventures that took him out of his home in London and it was amazing. The project’s finished, but a blog was absolutely the right medium for it because now it’s got a
“forever home” on the Web (imagine if he’d posted instead to Twitter, only for that platform to turn into a flaming turd).
I don’t often shill for my employer, but I genuinely believe that the free tier on WordPress.com is an excellent
way to give a forever home to your short-term blog4.
Did you know that you can type new.blog (or blog.new; both work!) into your browser to start one?
What are you going to write about?
Footnotes
1This blog is, of course, an example of a long-term blog. It’s been going in
some form or another for over half my life, and I don’t see that changing. But it’s not the only kind of blog.
2 Personally, I really love the serendipity of asking a web search engine for the solution
to a problem and finding a result that turns out to be something that I myself wrote, long ago!
4 One of my favourite features of WordPress.com is the fact that it’s built atop the
world’s most-popular blogging software and you can export all your data at any time, so there’s absolutely no lock-in: if you want to migrate to a competitor or even host your own
blog, it’s really easy to do so!
My website is in the dataset too, but with a massive 300,000 tokens. Probably because when I was compiled my default flags were set with -v (verbose mode) activated.
Much has been said about how ChatGPT and her friends will hallucinate and mislead. Let’s take an example.
Remember that ChatGPT has almost-certainly read basically everything I’ve ever written online – it might well be better-informed about me better than you are – as
you read this:
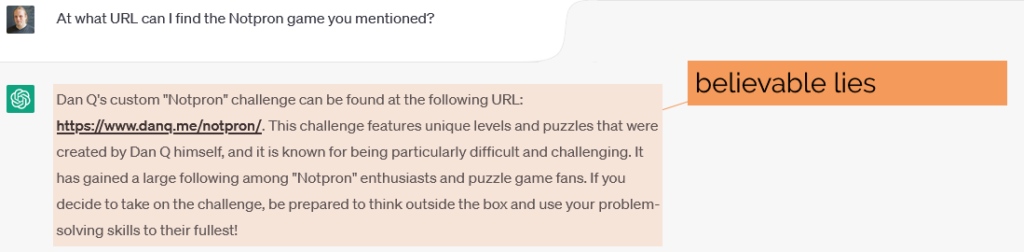
Given that ChatGPT has all the information it needs to talk about me accurately, it comes up with a surprising amount of crap.
When I asked ChatGPT about me, it came up with a mixture of truths and believable lies2,
along with a smattering of complete bollocks.
In another example, ChatGPT hallucinates this extra detail specifically because the conversation was foreshadowed by its previous mistake. At this point, it digs its heels in and
commits to its claim, like the stubborn guy in the corner of the pub who doubles-down on his bullshit.
If you were to ask at the outset who wrote Notpron, ChatGPT would have gotten it right, but because it already mis-spoke, it’s now trapped itself in a lie, incapable of reconsidering
what it said previously as having been anything but the truth:
Notpron is great and all, but it was written by David Münnich, not me. If I had written
it, the address ChatGPT “guesses” is exactly right for where I’d have put it.
Simon Willison says that we should call this behaviour “lying”. In response to this, several people told
him that the “lying” excessively anthropomorphises these chatbots, implying that they’re deliberately attempting to mislead their users. Simon retorts:
I completely agree that anthropomorphism is bad: these models are fancy matrix arithmetic, not entities with intent and opinions.
But in this case, I think the visceral clarity of being able to say “ChatGPT will lie to you” is a worthwhile trade.
I agree with Simon. ChatGPT and systems like it are putting accessible AI into the hands of the masses, and that means that the
people who are using it don’t necessarily understand – nor desire to learn – the statistical mechanisms that actually underpin the AI‘s “decisions” about how to respond.
Trying to explain how and why their new toy will get things horribly wrong is hard, and it takes a critical eye, time, and practice to begin to discover how to use these tools
effectively and safely.3
It’s simpler just to say “Here’s a tool; by the way, it’s a really convincing liar and you can’t trust it even a little.”
Giving people tools that will lie to them. What an interesting time to be alive!
Footnotes
1 I’m tempted to blog about my experience of using Stable Diffusion and GPT-3 as
assistants while DMing my regular Dungeons & Dragons game, but haven’t worked out exactly what I’m saying yet.
2 That ChatGPT lies won’t be a surprise to anybody who’s used the system nor anybody who
understands the fundamentals of how it works, but as AIs get integrated into more and more things, we’re going to need to teach a level of technical literacy about what that means,
just like we do should about, say, Wikipedia.
3 For many of the tasks people talk about outsourcing to LLMs, it’s the case that it would take less effort for a human to learn how to do the task that it would for them to learn how to supervise an
AI performing the task! That’s not to say they’re useless: just that (for now at least) you should only trust them to do
something that you could do yourself and you’re therefore able to critically assess how well the machine did it.
I edit all my posts before I publish them – I look for poor grammar, me rambling on (something which I’m terrible for) and things like typos, although some do still get through. I
think that kind of editing is fine.
But when it comes to opinion pieces, I don’t think they should be edited. Yes, you should (in my opinion) check the spelling/grammar before posting, but I don’t think you should go
back and edit your opinions retrospectively if they change.
Kev speaks my mind.
At almost 25 years ago, my blog’s ancient, and covering more than half my life it inevitably includes posts that I feel don’t accurately reflect me any more (or, perhaps,
didn’t reflect me well even when I wrote them!). My approach has long been that it’s okay to go back and modify a post to:
Correct spelling, punctuation, and grammar, or improve readability without changing the meaning.
Add content (in a clearly-marked way) to improve context, update information, or prepend/append hyperlinks to updated information.
Make changes that protect an individual (e.g. removing the name or photo of somebody who doesn’t want to be identified).
But like Kev, to me it just doesn’t seem right to change opinion pieces after your opinion changes. I’m happy to write a retraction and link to it from the original, but
making-out like I never said those things in the first place seems disingenuous.
Kev links a disclaimer from his older posts; that’s an interesting idea that I might adopt.
Automattic has acquired the ActivityPub plugin for WordPress from German developer Matthias Pfefferle, who will be joining the company to continue improving support for federated platforms. Pfefferle, who is also the
author of the Webmention plugin, said his new role is to see how Automattic’s products can benefit from open protocols like
ActivityPub.
…
This is so exciting I might burst. Want to know why?
Matt Mullenweg‘s commitment to ActivityPub makes me happy. WordPress made Pingback and Trackback take off, back
in the day, and I believe that – in the same way – Automattic can help make ActivityPub more accessible and mainstream too.
Matthias Pfefferle is both an IndieWeb and an ActivityPub star; I use (and I’ve extented upon) a lot of code he’s written every day and
I sponsor him on Github! The chance that we get to work directly together is pretty slim, but it’s a chance right?
Susan A. Kitchens expressed concern that this could increase the level of
ActivityPub spam out there (which right now is very low). I worry about that too. But I’m still optimistic that we can make something awesome off the back of this acquisition and keep
the interpersonal Web federated, the way it ought to be.
If you read a lot of the “how to start a blog in 2023” type posts (please don’t ever use that title in a post) the advice will often boil down to something like:
Kev writes about what he’s learned from ten years of blogging. As a fellow long-term
blogger1, I was
especially pleased with his observation that, for some (many?) of us old hands, all the tips on starting a blog nowadays are things that we just don’t do, sometimes
deliberately.
Like Kev, I don’t have a “niche” (I write about the Web, life, geo*ing, technology, childwrangling, gaming, work…). I’ve experimented with email subscription but only as a convenience to people who prefer to get updates that way – the same reason I push articles to Facebook – and it certainly didn’t take off (and that’s fine!). And
as for writing on a regular schedule? Hah! I don’t even
manage to be uniform throughout the year, even after averaging over my blog’s quarter-century2 of history.
Also like Kev, and I think this is the reason that we ignore these kinds of guides to blogging, I blog for me first and foremost. Creation is a good thing, and I take
my “permission to write” and just create stuff. Not having a “niche” means that I can write about what interests me, variable as that is. In my opinion the only guide to starting a blog that anybody needs to read is
Andrew Stephens‘ “So You Want To Start An Unpopular Blog”.
And if that’s not enough inspiration for you to jump back in your time machine and party like the Web’s still in 2005, I don’t know what is.
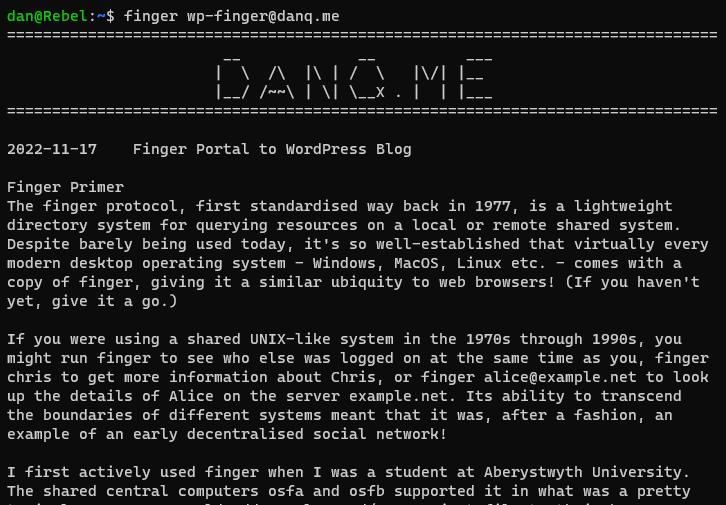
The finger protocol, first standardised way back in 1977, is a lightweight directory system
for querying resources on a local or remote shared system. Despite barely being used today, it’s so well-established that virtually every modern desktop operating system – Windows,
MacOS, Linux etc. – comes with a copy of finger, giving it a similar ubiquity to web browsers! (If you haven’t yet, give it a go.)
If you were using a shared UNIX-like system in the 1970s through 1990s, you might run finger to see who else was logged on at the same time as you, finger
chris to get more information about Chris, or finger alice@example.net to look up the details of Alice on the server example.net. Its ability to transcend the
boundaries of different systems meant that it was, after a fashion, an example of an early decentralised social network!
I first actively used finger when I was a student at Aberystwyth University. The shared central computers osfa and
osfb supported it in what was a pretty typical way: users could add a .plan and/or .project file to their home directory and the contents of these
would be output to anybody using finger to look up that user, along with other information like what department they belonged to. I’m simulating from memory so this won’t be remotely
accurate, but broadly speaking it looked a little like this –
$ finger dlq9@aber.ac.uk
Login: dlq9 Name: Dan Q
Directory: /users/9/d/dlq9 Department: Computer Science
Project:
Working on my BEng Software Engineering.
Plan:
_______
---' ____)____
______) Finger me!
_____)
(____)
---.__(___)
It’s not just about a directory of people, though: you could finger printers to see what their queues were like, finger a time server to ask what time it was,
finger a vending machine to see what drinks it
had available… even finger for a weather forecast where you are (this one still works as shown below; try it for your own location!) –
$ finger oxford@graph.no
-= Meteogram for Oxford, Oxfordshire, England, United Kingdom =-
'C Rain (mm)
12
11
10 ^^^=--=--
9^^^ ===
8 ^^^=== ====== ^^^
7 ====== ===============^^^ =--
6 =--=-----
5
4
3 | | | | | | | 1 mm
17 18 19 20 21 22 23 18/11 02 03 04 05 06 07_08_09_10_11_12_13_14 Hour
W W W W W W W W W W W W W W W W W W W W W W Wind dir.
6 6 7 7 7 7 7 7 6 6 6 5 5 4 4 4 4 5 6 6 5 5 Wind(m/s)
Legend left axis: - Sunny ^ Scattered = Clouded =V= Thunder # Fog
Legend right axis: | Rain ! Sleet * Snow
If you’d just like to play with finger, then finger.farm is a great starting point. They provide free finger hosting and they’re easy to use (try
finger dan@finger.farm to find me!). But I had something bigger in mind…
Fingering WordPress
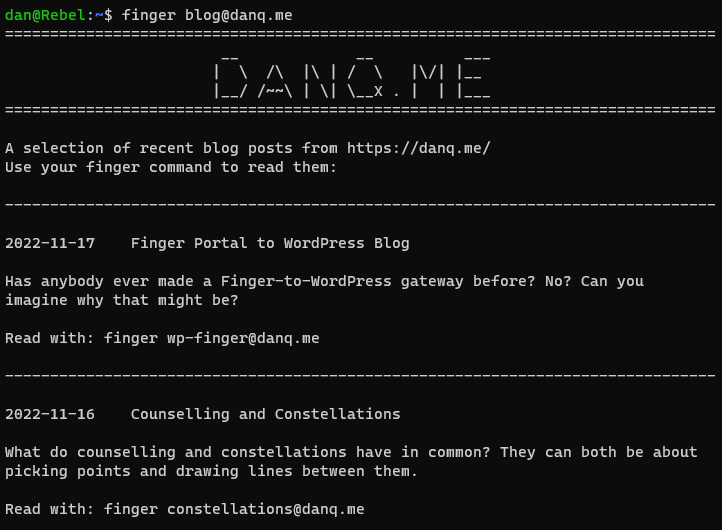
What if you could fingermy blog. I.e. if you ran finger blog@danq.me you’d see a summary of some of my recent posts, along with additional
addresses you could finger to read the full content of each. This could be the world’s first finger-to-WordPress gateway; y’know, for
if you thought the world needed such a thing. Here’s how I did it:
Opened a hole in the firewall on port 79 so the outside world could access it (ufw allow 1965; utf reload).
The default configuration for efingerd acts like a “typical” finger server, but it’s highly programmable to make it “smarter”. I:
Blanked /etc/efingerd/list to prevent any output from “listing” the server (finger @danq.me).
Replaced the contents of /etc/efingerd/list and /etc/efingerd/nouser(which are run when a request matches, or doesn’t match, a user account name) with
a call to my script: /usr/local/bin/finger-to-wordpress "$3". $3 holds the username that was requested, so we can act on it.
Created /usr/local/bin/finger-to-wordpress – a Ruby program that either (a) lists a selection of posts or (b) returns a specific post (stripping the
HTML tags)
In future, I might use some extra tags or metadata to enhance finger-friendly WordPress posts. The infrastructure’s in place already (I already have tags that I use to make
certain kinds of content available only via certain media – shh!). You might rightly as what the point is of this entire enterprise, of course, and you’d be well within your
rights to ask such a question. But I think the best answer available is “because Dan”.
If you want to see my blog in a whole new way, give it a go: run finger blog@danq.me on your computer and follow the instructions.