I’m testing a handful of highly-experimental new features on my personal website using multivariate (“A/B”) testing.
“Dark Mode” is just one of the new features I’m testing out.
If you visit within the next day or so you’re likely to be randomly-selected to try out one of them. (If you’re not selected, you can manually enable one of the
experiments.)
I’d love to hear your feedback on these Very Serious New Features! Let me know which one(s) you see and whether you think they should become permanent fixtures on my site.
I was contacted this week by a geocacher called Dominik who, like me, loves geocaching…. but hates it when the coordinates for a cache are hidden behind a virtual jigsaw puzzle.
A popular online jigsaw tool used by lazy geocache owners is Jigidi: I’ve come up with severaltechniques for bypassing their puzzles or at
least making them easier.
Not just any puzzle; the geocache used an ~1000 piece puzzle! Ugh!
I experimented with a few ways to work-around the jigsaw, e.g. dramatically increasing the “snap range” so dragging a piece any distance would result in it jumping to a
neighbour, and extracting original image URLs from localStorage. All were good, but none were
perfect.
For a while, making pieces “snap” at any range seemed to be the best hacky workaround.
Then I realised that – unlike Jigidi, where there can be a congratulatory “completion message” (with e.g. geocache coordinates in) – in JigsawExplorer the prize is seeing the
completed jigsaw.
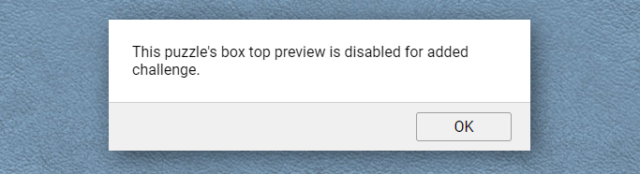
You can click a button to see the “box” of a jigsaw, but this can be disabled by the image uploader.
Let’s work on attacking that bit of functionality. After all: if we can bypass the “added challenge” we’ll be able to see the finished jigsaw and, therefore, the geocache
coordinates. Like this:
Hackaround
Here’s how it’s done. Or keep reading if you just want to follow the instructions!
Open a jigsaw and try the “box cover” button at the top. If you get the message “This puzzle’s box top preview is disabled for added challenge.”, carry on.
Open your browser’s debug tools (F12) and navigate to the Sources tab.
Find the jigex-prog.js file. Right-click and select Override Content (or Add Script Override).
In the overridden version of the file, search for the string – e&&e.customMystery?tt.msgbox("This puzzle's box top preview is disabled for added challenge."): –
this code checks if the puzzle has the “custom mystery” setting switched on and if so shows the message, otherwise (after the :) shows the box cover.
Carefully delete that entire string. It’ll probably appear twice.
Reload the page. Now the “box cover” button will work.
The moral, as always, might be: don’t put functionality into the client-side JavaScript if you don’t want the user to be able to bypass it.
Or maybe the moral is: if you’re going to make a puzzle geocache, put some work in and do something clever, original, and ideally with fieldwork rather than yet another low-effort
“upload a picture and choose the highest number of jigsaw pieces to cut it into from the dropdown”.
Ever wondered why Oxford’s area code is 01865? The story is more-complicated than you’d think.
As a child, I was told that city STD codes were usually associated to the letters that appear on some telephones… but that
wouldn’t make any sense for Oxford’s code!
I’ll share the story on my blog, of course. But before then, I’ll be telling it from the stage of the Jericho Tavern at 21:15 on Wednesday 17 April as
my third(?) appearance at Oxford Geek Nights! So if you’re interested in learning about some of the quirks of UK telephone numbering
history, I can guarantee that this party’s the only one to be at that Wednesday night!
Not your jam? That’s okay: there’s plenty of more-talented people than I who’ll be speaking, about subjects as diverse as quantum computing with QATboxen, bringing your D&D experience to stakeholder management (!), video games
without screens, learnings from the Horizon scandal, and whatever Freyja Domville means by The Unreasonable Effectiveness of the Scientific Method (but I’m seriously excited by that title).
Anyway: I hope you’ll be coming along to Oxford Geek Nights 57 next month, if not to hear me witter on about the
fossils in our telecommunications networks then to enjoy a beer and hear from the amazing speakers I’ll be sharing the stage with. The event’s always a blast, and I’m looking forward to
seeing you there!
In August, I celebrated my blog – with its homepage weighing-in at a total of just 481kb – being admitted to Kev Quirk‘s 512kb club. 512kb club celebrates websites (often personal sites) whose homepage are neither “ultra minimal”
or “link pages” but have a total size, including all assets, of under half a megabyte. It’s about making a commitment to a leaner, more-efficient Web.
My relatively-heavyweight homepage only just slipped in under the line. But, feeling inspired perhaps by some performance enhancements I’ve been planning this week at work, I
decided to try to shave a little more off:
Now, at ~234kb, danq.me just beats the excellent gomakethings.com (it’s all those heavyweight fonts, Chris!).
Here’s what I changed:
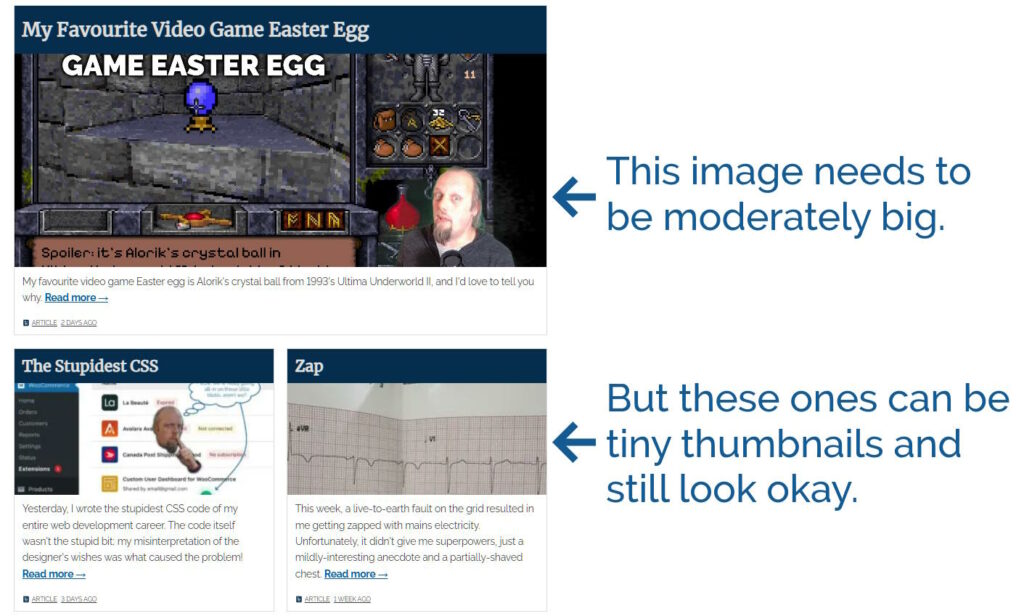
The “recent article” tiles are dynamically sized based on their number, type, and the visitor’s screen resolution. But apart from the top one they’re almost never very large. Using
thumbnail images for the non-first tile shaved off almost 160kb.
You can see the difference, but it’s still acceptable to look at, I think.
Not space-saving, but while I was in there I ensured that the first tile’s image – which almost-certainly comprises part of the Largest
Contentful Paint – is never delivered with loading="lazy".
I was providing a shortcut icon in .ico format (<link rel="shortcut icon" href="https://bcdn.danq.me/_q23t/icons/favicon-16-32-48-64-128.ico" />),
which is pretty redundant nowadays because all modern browsers (and even IE11)
support .png icons. I was already providing.png and .svg versions, but it turns out that some browsers favour the one with the
(harmful?) rel="shortcut icon" over rel="icon" if both are present, and .ico
files are – being based on Windows Bitmaps – horrendously inefficient.
By getting under the 250kb threshold, I’ve jumped up a league from Blue Team to Orange Team, so that’s nice too. I can’t see a meaningful
path from where I’m at to Green Team (under 100kb) though, so this level might have to suffice.
My favourite video game Easter egg is found in Ultima Underworld II: Labyrinth of Worlds1.
Released early in 1993 after missing a target of Christmas 19922,
it undersold despite being almost universally well-received by reviewers3.
I don’t know how print magazine video game reviews read today, but back in the early 90s they seemed to be frivolous and flippant approximately 100% of the time.
Developed by Looking Glass Technologies, it used an enhanced version of the engine they’d used for the game’s prequel a year earlier4.
The engine is particularly cool for it’s time; it’s sometimes compared to Wolfenstein5, but
that’s not entirely fair… on Wolfenstein! The original version of Underworld‘s 3D engine predated Wolfenstein… and yet supported several features that
Wolfenstein lacked, like the ability for the player to look up and down and jump over chasms, for example.
Move around and you’ll see the 3D walls shift to your new perspective, but you’ll always see the same side of the 2D objects on the floor. Turn as you might, you’ll never see the back
of that skull!
The team’s expertise and code would eventually be used to produce System Shock in 1994. The team’s producer, Warren Spector,
would eventually draw from his experience of the Ultima Underworld games when he went on to make Thief: The Dark Project and Deus Ex.
But the technology of Ultima Underworld II and its prequel aren’t as interesting as its approach to storytelling and gameplay. They’re:
Underworld II encourages lateral thinking and provides multiple solutions to many challenges, perhaps best-described by this section in the Designers’ Notes page at the back
of the manual.
What’s being described there is what we’d now call emergent gameplay, and while it wasn’t completely new in 19937 it was still uncommon enough to be
noteworthy.
The Easter Egg
The Ultima series are riddled with Easter eggs, but my favourite is one that I feel is well-hidden, beautiful… and heavily
laden with both fan service and foreshadowing!
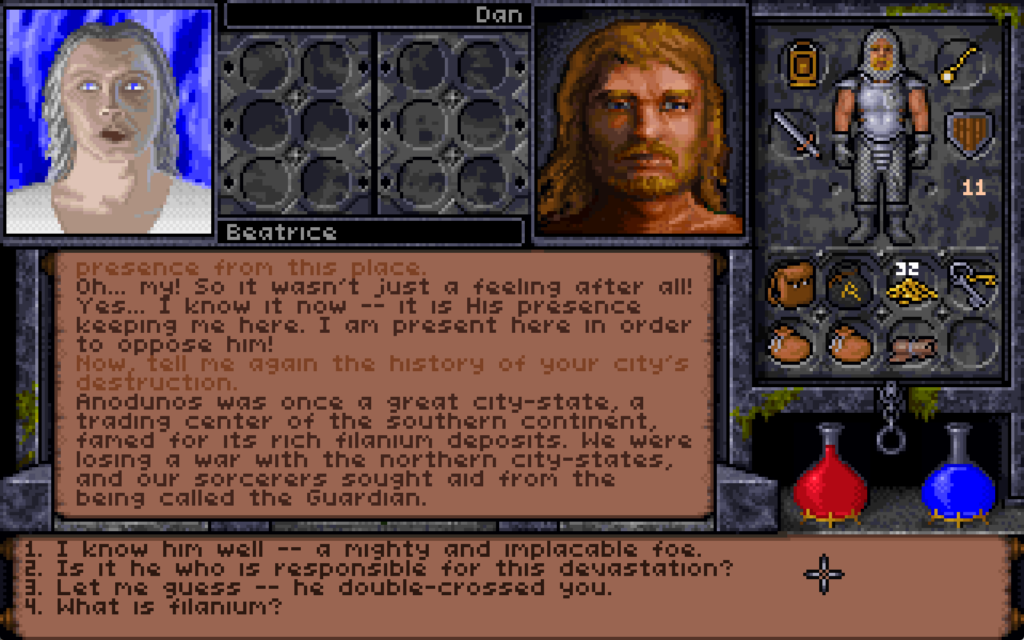
The third of the interdimensional planes the Avatar visits in the game contains a city frozen solid by the Guardian’s magic.
To find the Easter egg, you must first travel to Anodunos. This city was once the capital of a tropical city-state which had become allied to the Guardian, the the principal antagonist
of Ultima VII through IX.
After the city’s major, Beatrice, attempted to put an end to the red titan’s growing demands, the Guardian cursed the city fountain to radiate out a magical cold that eventually froze
the entire settlement under a cave of ice.
Mayor Beatrice lives on here, as a ghost. While she’s a great source of information about the ice caverns as a whole and has information highly useful to the primary quest, that’s not
the thing we’re interested in right now.
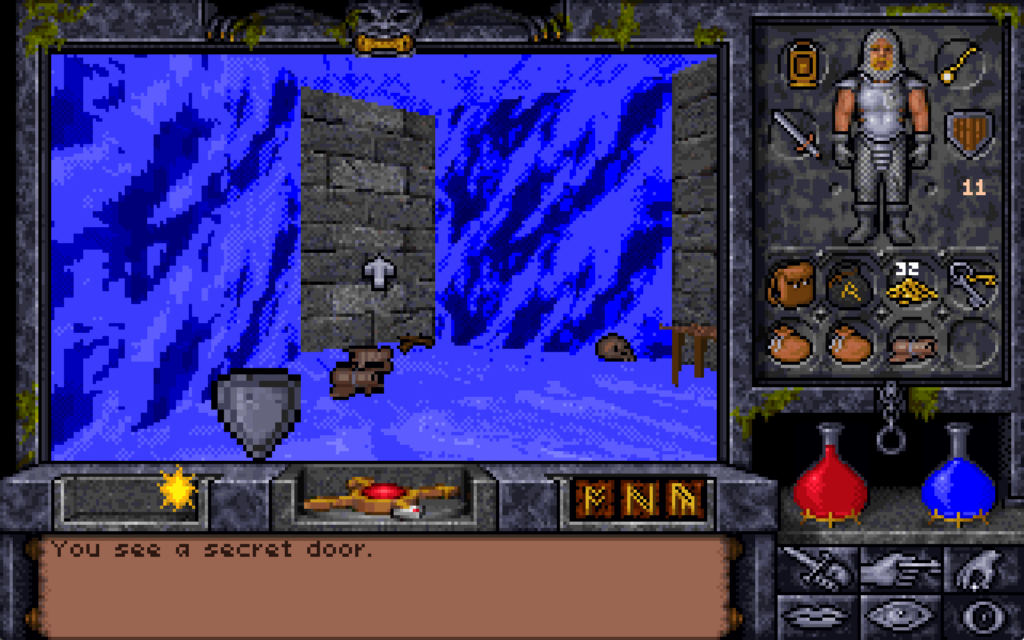
On the Eastern bank of the city’s river we find the remnants of the workshop of the magician Alorik, and in it – if we look in the right place8
– a secret door. We can’t open it though: unusually for a secret door in this game, it’s locked.
In the original, unpatched release of the game, you couldn’t even cast the “open” spell on it to unlock it: the only way through was to use a powerful late-game spell like “portal” to
teleport to the other side.
I didn’t even find this chamber on my first playthrough of the game. It was only on my second, while using the Map Area spell to help me to draw accurate maps of the entire game world,
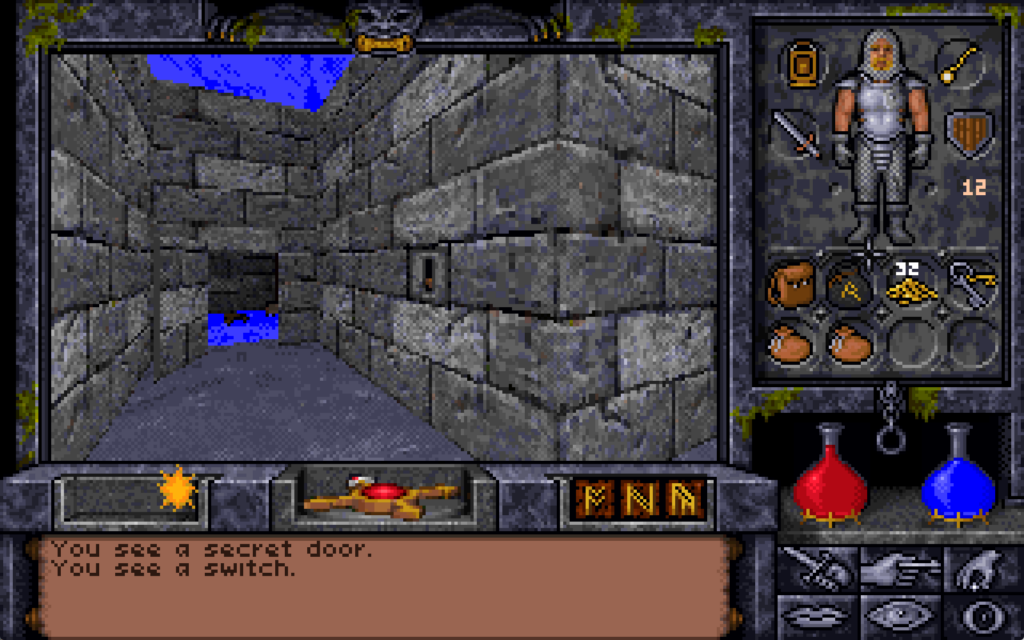
that I found the room… and even then I spent some time hunting for a switch on the “outside” before eventually giving up and teleporting into the secret room.
Once you’re on the other side, there’s a switch. I guess it’s a Alorik’s panic room?
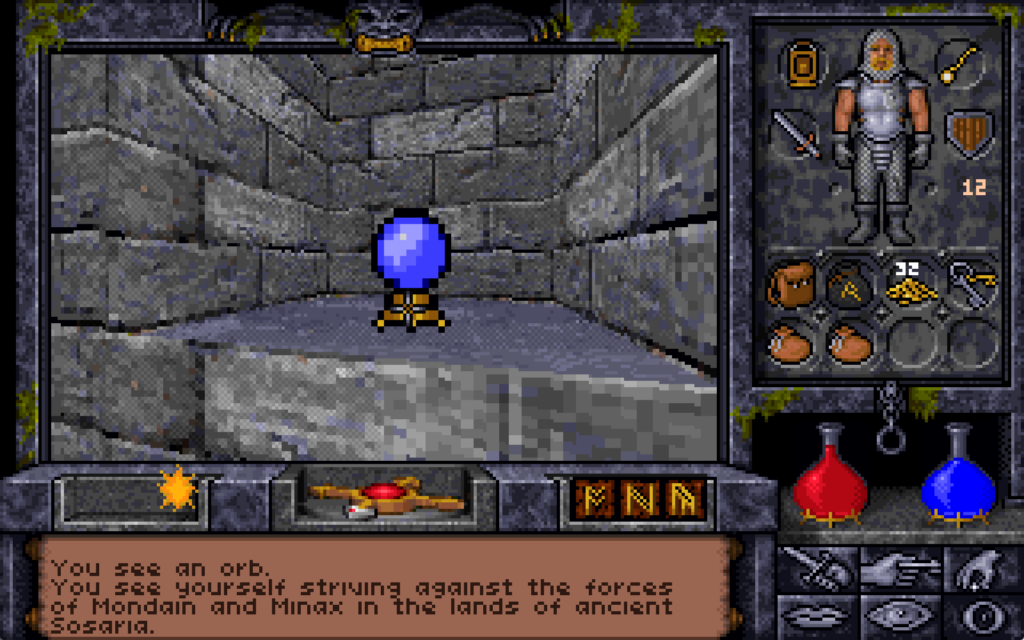
There’s valuable treasure here including a sceptre of mana restoration, a “grav” runestone (probably still easier to get than the one at the Scintillus Academy), but what’s most
interesting is the crystal ball, which the player can look into to see a vision of another place and, in the case of this orb, another time.
The first time you look into it, you’re told:
You see yourself striving against the forces of Mondain and Minax in the lands of ancient Sosaria.9
Mondain and Minax are the antagonists in Ultima I and Ultima II. We’re seeing the earliest parts of the player character’s adventures.
It’s long been argued that the “Stranger” – the protagonist of Ultima I through Ultima III – is a different person to the Avatar of Ultima IV but I feel
like this vision is canonical proof that they’re supposed to be interpreted as being the same person…
If we look into the crystal ball a second time:
You see yourself climbing to the peak of Olympus Mons on the planet Mars.
This is a reference to the plot of Ultima: Worlds of Adventure 2: Martian Dreams… which is a… weird choice of game to reference.
In my mind, a more logical leap forward in time might have been to jump to Ultima IV10, in which the protagonist
first becomes the Avatar of the Eight Virtues and the Hero of Britannia. Martian Dreams is… a sequel to a spinoff of Ultima VI. So why pick that?
Little-known and oft-forgotten, Martian Dreams is apparently nonetheless a source of pride for the real Spector.
Martian Dreams starts with a friend of the Avatar’s from Earth facilitating the Avatar and their companions to set out on an adventure to the planet Mars. That friend is called
Dr. Spector, obviously named for Warren Spector, who helped develop Ultima VI and, of
course, this game. This usual choice of vision of the past is a cryptic nod to the producer of Underworld II.
Let’s look again:
You see yourself in the Deep Forest, speaking with the peace-loving simian race of Emps.
This one’s a reference to Ultima VII, the game whose story immediately precedes this one. The Deep Forest seems an strange part of the adventure to choose, though. The Avatar
goes to the Deep Forest where, via some emps and then a wisp are eventually lead to the Time Lord11.
The Time Lord provides a whole heap of exposition and clues that the Avatar needs to eventually close the Black Gate and win the game.
Tardis noises intensify.
Do these references serve to hint that this crystal ball, too, is a source of exposition and guidance? Let’s see what it says next.
You see yourself peering into a crystal ball.
I remember the moment I first saw this happen in the game: serious chills! You’ve just found a long-lost, centuries-buried secret chamber, in which there’s a crystal ball. You peer into
it and observe a series of moments from throughout your life. You continue to watch, and eventually you see yourself, staring into the crystal ball: you’re seeing the present. So what’s
next?
Alorik’s crystal ball from Ultima Underworld II and the mural of G’mork from The NeverEnding Story totally have the same energy.
If you look again, you’re asking to see… the unwritten future:
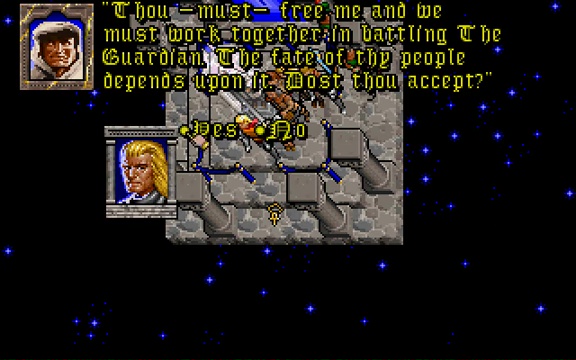
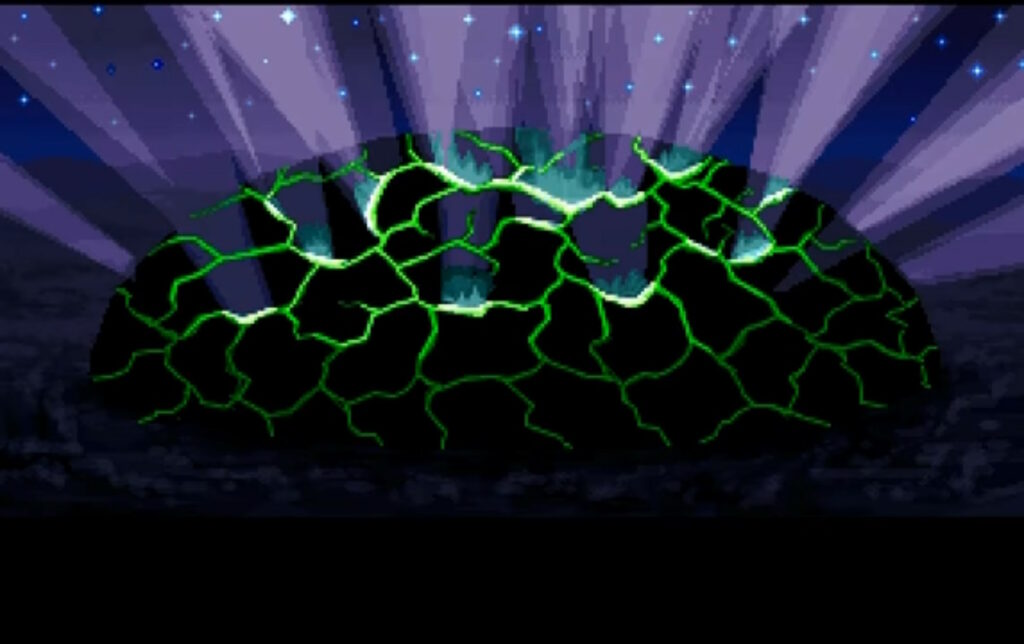
You see yourself winding a great war horn in the throne room of Castle British.
To save Britannia in Ultima Underworld II, the Avatar needs to exploit symmetries implicit in The Guardian’s spellcasting to travel to eight different parallel worlds, find a
place from which His power stems, dispel it, encase themselves in a shell of basilisk oil-infused magic mud, immerse themselves in lava to bake it on, find a magic sigil, consume a
djinn… it’s a whole thing. But ultimately it all leads to a climactic end scene in which the Avatar raises a horn retrieved from the Tomb of Praecor Loth and blows it to shatter a dome
of blackrock.
If you happen to find this clue on your first playthrough, it’s helpful exposition.
But that’s the end of this game, right? How can we possibly peer into the orb again?
You see yourself sailing through majestic pillars cropping up out of the sea, on a voyage of discovery.
What’s being described there is the opening scene from the next game in the series, the as-yet-unreleased Ultima VII Part 2: Serpent Isle!
Serpent Isle begins with the Avatar and their companions sailing out to some special pillars in pursuit of a bad guy.
This vision is a teaser of what’s to come. That’s just… magical, for both the character and the player.
The character uses fortune-telling magic to see their future, but the player is also seeing their future: if they’re playing Ultima Underworld II at or close to its
release date, or they’re playing through the games in chronological order, they’re in a literal sense being shown what comes next in their life. That’s really cool.12
Let’s look again:
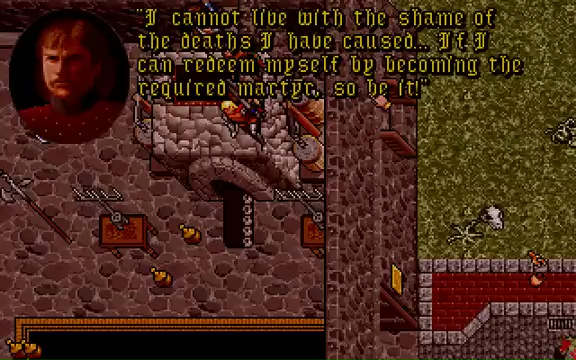
You see the obscure form of an old and dear friend, as he sacrifices his life for the good of all.
Some time after the party arrives on Serpent Isle, the Avatar’s companions are possessed by the Banes of Chaos and go on a murderous rampage. Later, there’s a ritual that will save the
world, but at the cost of the death of one of the heroes. The Avatar is willing to make the ultimate sacrifice, but in the end Sir Dupre takes his place, unwilling to live within
himself after seeing the carnage he has wrought.
The death of Sir Dupre, who first appeared way back in Ultima II, is somewhat undercut by his resurrection in Ultima IX. But perhaps you’ll let me pretend for a
paragraph longer that Ultima IX doesn’t exist, okay?
At the end of Serpent Isle, the Avatar is plucked out of space and time and deposited into Pagan, The Guardian’s home base. The plot of Ultima VIII and Ultima
IX revolve around the Avatar working to return to a radically-changed Britannia, attempting to fight The Guardian and bring to an end the Age of Armageddon, and ultimately
merging and become one with Him before vanishing completely from the world.
I don’t disagree with how Ultima IX got to where it was going, but I don’t like the route it took to get there. Or the hilariously-terrible bugs.
Which is why it’s perhaps quite fitting that if the Avatar in Underworld II looks into the orb one final time, they’re told…
You see nothing.
That’s it. That’s the end.
The end of the vision, certainly, but also: a vision of the end.
Depending on how you count the Ultima games13, this is the 13th of 17 in the series. We’re approaching the
final chapter, and this Easter egg foreshadows that finale.
I feel hugely privileged that I got to experience it “organically”, by accident, as its authors presumably intended, back in 1993. But it also makes me happy to be able to share the
story of it with you14.
If you haven’t seen it yet, you might enjoy watching the vlog version of this post, through which my enthusiasm for the topic might be more-palpable.
Footnotes
1 I’ve doubtless mentioned Ultima Underworld II before: for example both it and
Ultima VII, as well as NetHack (mentioned elsewhere in this post) made it into my 2007 list of top 10 computer games that stole my life.
3 It suffered perhaps for the time of year it was released, but perhaps also for the fact
that 1993 was a big year for video games and it was competing with The 7th Guest, Star Wars: Rebel Assault, Return to Zork , Myst, Disney’s
Aladdin and, of course – later in the year – Doom.
4 Director/designer Paul Neurath apparently sang the praises of his team for improving
texture mapping and viewport size constraints, and he’s right: they’re a huge improvement on Underworld I‘s. Neurath would later go on create the crowdfunded “spiritual
successor” Underworld Ascendant, which was critically panned, which just goes to show that sometimes it’s better to get a tight
team together and make it “until it’s done” than to put your half-baked idea on Kickstarter and hope you can work it out what you’re making before the money runs out.
5 Like Wolfenstein, the engine uses a mixture of software-rendered 3D (for walls
and furniture) overlaid with traditionally-produced sprites (for characters and items).
6 All executed over a year before the release of the very first Elder Scrolls
game. Just sayin’.
7 That king of emergent gameplay NetHack was showcasing emergent gameplay in
a fantasy roleplaying game way back in the 1980s!
8 An interesting quirk of the game was that if you turned the graphics settings down to
their lowest, secret doors would become just as visible as regular doors. If you’re sure there is one but you can’t quite find it, tweaking your graphics settings is much easier than
casting a spell!
9 Do you like the “in the style of Underworld II” scrolls I’ve used in this post?
I’ve made available the source code you need
if you want to use them yourself.
10Ultima IV is my personal favourite Ultima game, but I see the
argument of people who claim that Ultima VII is the best of the series.
11 The Time Lord turns up throughout the game series. Way back in Ultima III,
he appears in the Dungeon of Time where he provides a clue essential to defeating Exodus, and he appears or is referenced in most games from Ultima VII onwards. He doesn’t
seem to appear in Ultima IV through Ultima VI, except… in Ultima IX, which wouldn’t be released until six years after Underworld II, it’s revealed
that the Time Lord is the true identity of the seer Hawkwind… who provided the same kind of exposition and guidance in Ultima IV!
12 How did the Underworld II team know with such certainty what was being
planned for Serpent Isle? At some point in 1992 project director Jeff George left Origin Studios and was replaced by lead designer Bill Armintrout, and the role of producer was assigned to… Warren Spector again! For some time, Spector was involved with both
projects, providing an easy conduit for inter-team leaks.
13 How you count Ultima games and what specifically should be counted is a
source of controversy in fan circles.
14 I’m sure many people reading this will have heard me talk about this particular
Easter egg in-person before, over the last couple of decades. Some of you might even have heard me threaten to write a blog post about it, someday. Well: now I have. Tada! It only
took me thirty years after experiencing it to write about it here, which is still faster than some things I’ve blogged about!
Yesterday, I wrote the stupidest bit of CSS of my entire career.
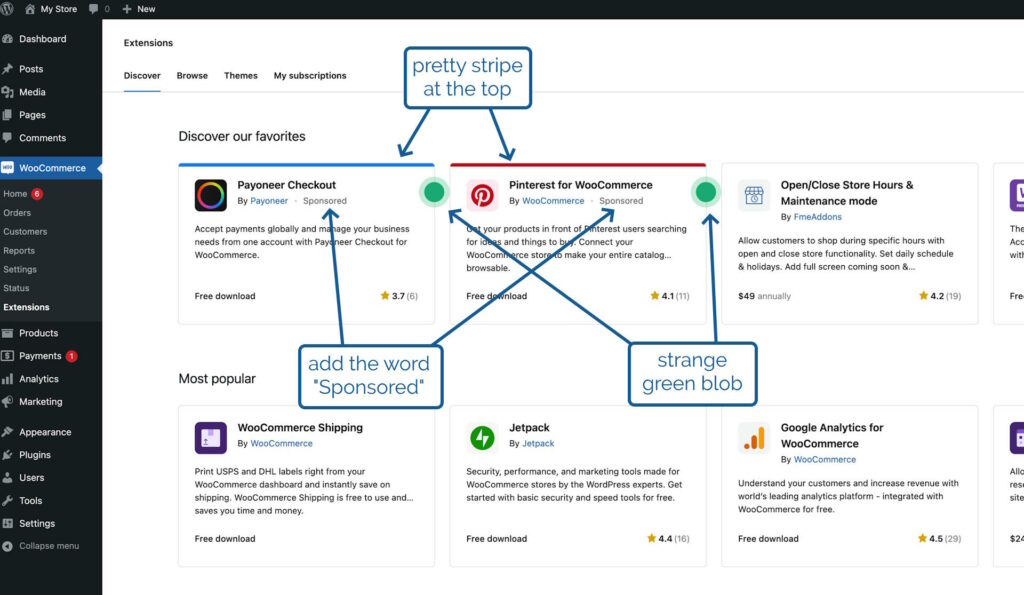
Two new visual elements and one textual one will make it clear where a product’s placement in the marketplace is sponsored.
Owners of online shops powered by WooCommerce can optionally “connect” their stores back to Woo.com. This enables them to manage their subscriptions to
any extensions they use to enhance their store1. They can also browse a
marketplace of additional extensions they might like to consider, which is somewhat-tailored to them based on e.g. their geographical location2
In the future, we’ll be adding sponsored products to the marketplace listing, but we want to be transparent about it so yesterday I was working on some code that would determine from
the appropriate API whether an extension was sponsored and then style it differently to make this clear. I took
a look at the proposal from the designer attached to the project, which called for
the word “Sponsored” to appear alongside the name of the extension’s developer,
a stripe at the top in the brand colour of the extension, and
a strange green blob alongside it
That third thing seemed like an odd choice, but I figured that probably I just didn’t have the design or marketing expertise to understand it, and I diligently wrote some appropriate code.3
I even attached to my PR a video demonstrating how my code reviewers could test it without spoofing actual sponsored
extensions.
After some minor tweaks, my change was approved. The designer even swung by and gave it a thumbs-up. All I needed to do was wait for the automated end-to-end tests to complete, and I’d
be able to add it to WooCommerce ready to be included in the next-but-one release. Nice.
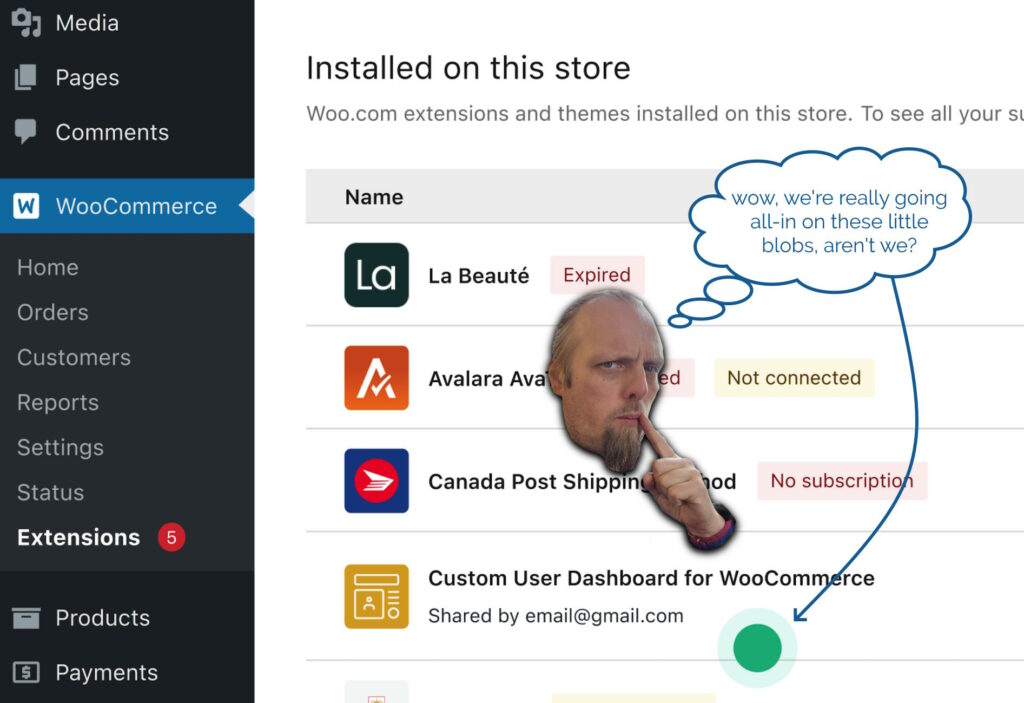
In the meantime, I got started on my next bit of work. This one also included some design work by the same designer, and wouldn’t you know it… this one also had a little green
blob on it?
I’m almost embarrassed to admit that my first thought was that this must be part of some wider design strategy to put little green blobs everywhere.
Then it hit me. The blobs weren’t part of the design at all, but the designer’s way of saying “look at this bit, it’s important!”. Whoops!
So I got to rush over to my (already-approved, somehow!) changeset and rip out
the offending CSS: the stupidest bit of CSS of my entire career.
Not bad code per se, but reasonable code resulting from a damn-stupid misinterpretation of a designer’s wishes. Brilliant.
3 A fun side-effect of working on open-source software is that my silly mistake gets
immortalised somewhere where you can go and see it any time you like!
This week, I received a ~240V AC electric shock. I can’t recommend it.
As you may have guessed based on photos in previous posts, our house is currently wrapped in a convenient climbing frame scaffolding.
We’re currently having our attic converted, so we’ve had some electricians in doing the necessary electrical wiring. Shortly after they first arrived they discovered that our existing electrics were pretty catastrophic, and needed to make a few changes including a new fusebox and disconnecting the
hilariously-unsafe distribution board in the garage.
The owner before last of our house worked for SSEN and did all of his own wiring, and left us a rats’ nest
of spaghetti wiring that our electricians described as being unlike anything they’d ever seen before. Also a literal rats’ nest under the decking, but we got rid of that already.
After connecting everything new up they began switching everything back on and testing the circuits… and we were surprised to hear arcing sounds and see all the lights flickering.
The electricians switched everything off and started switching breakers back on one at a time to try to identify the source of the fault, reasonably assuming that something was shorting
somewhere, but no matter what combination of switches were enabled there always seemed to be some kind of problem.
You know those escape room puzzles where you have to get the right permutation of switch combinations? This was a lot less fun than that.
Noticing that the oven’s clock wasn’t just blinking 00:00 (as it would after a power cut) but repeatedly resetting itself to 00:00, I pointed this out to the electricians as an
indicator that the problem was occurring on their current permutation of switches, which was strange because it was completely different to the permutation that had originally exhibited
flickering lights.
I reached over to point at the oven, and the tip of my finger touched the metal of its case…
Blam! I felt a jolt through my hand and up my arm and uncontrollably leapt backwards across the room, convulsing as I fell to the floor. I gestured to the cooker and
shouted something about it being live, and the electricians switched off its circuit and came running with those clever EM-field sensor
pens they use.
Somehow the case of the cooker was energised despite being isolated at the fusebox? How could that be?
Buy one ECG appointment. Get a free partial chest-shaving free!
I missed the next bits of the diagnosis of our electrical system because I was busy getting my own diagnosis: it turns out that if you get a mains electric shock – even if you’re
conscious and mobile – the NHS really want you to go to A&E.
At my suggestion, Ruth delivered me to the Minor Injuries unit at our nearest hospital (I figured that what I had wasn’t that
serious, and the local hospital generally has shorter wait times!)… who took one look at me and told me that I ought to be at the emergency department of the bigger hospital over the
way.
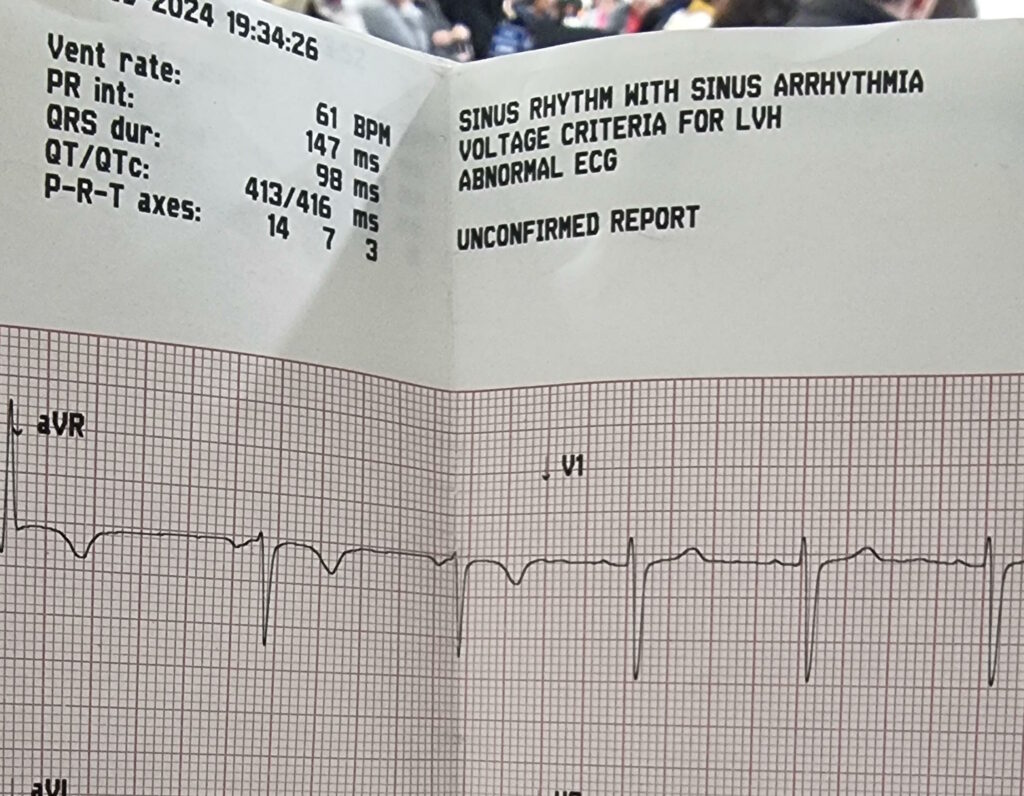
The first hospital were kind enough to hook me up to an ECG before sending me on to the A&E department. It indicated possible cardiac arrhythmia in the sinus node – basically: my heart’s natural pacemaker was firing somewhat
irregularly – which is kinda what you’d expect from an AC zap.
Off at the “right” hospital I got another round of ECG tests, some blood tests (which can apparently be used to diagnose muscular
damage: who knew?), and all the regular observations of pulse and blood pressure and whatnot that you might expect.
And then, because let’s face it I was probably in better condition than most folks being dropped off at A&E, I was left to
chill in a short stay ward while the doctors waited for test results to come through.
Apparently our electricity meter blew itself up somewhere along the way, leaving us with even less of a chance to turn the power back on again.
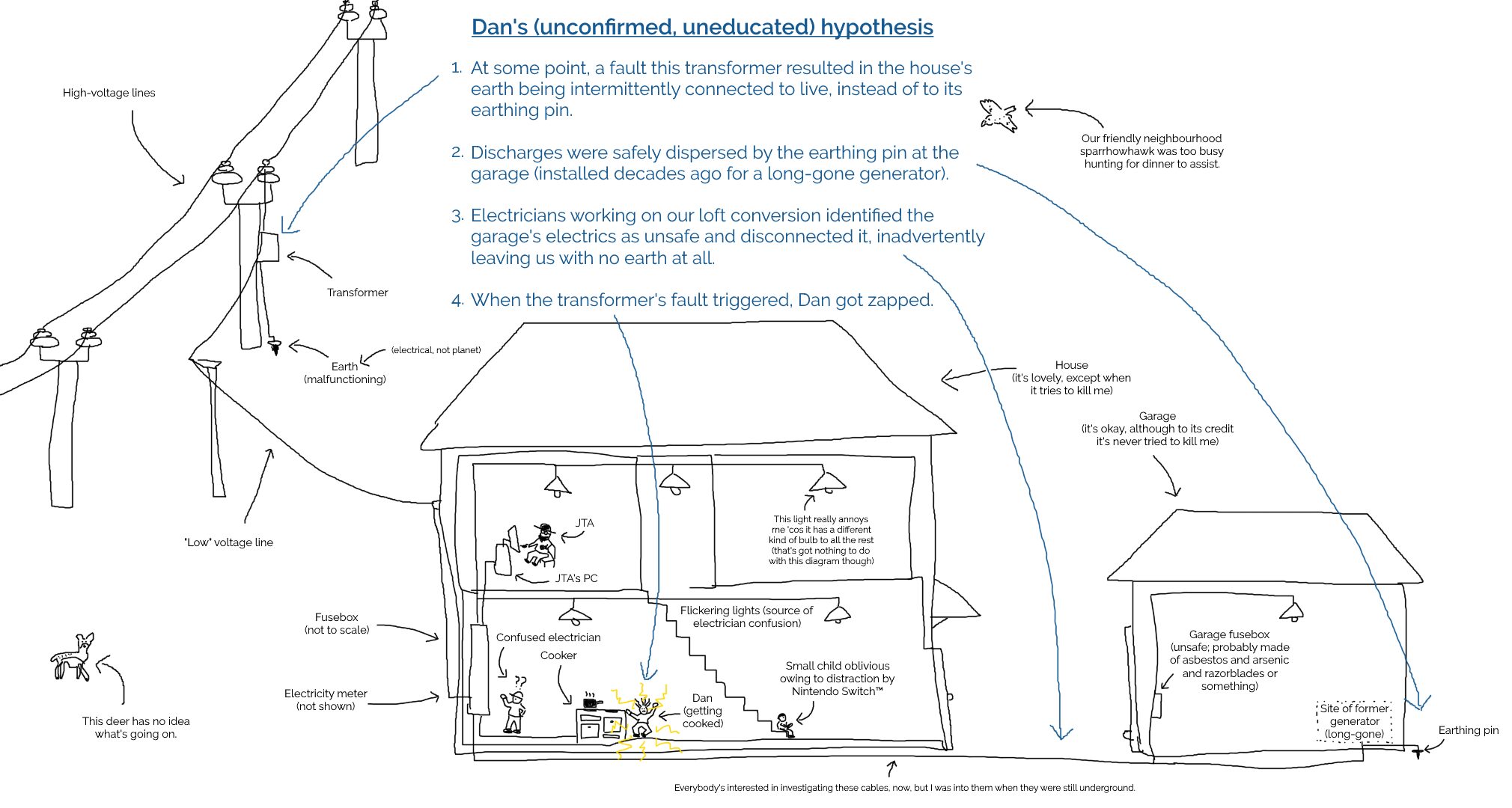
Meanwhile, back at home our electricians had called-in SSEN, who look after the grid in our area. It turns
out that the problem wasn’t directly related to our electrical work at all but had occurred one or two pylons “upstream” from our house. A fault on the network had, from the sounds of
things, resulted in “live” being sent down not only the live wire but up the earth wire too.
That’s why appliances in the house were energised even with their circuit breakers switched-off: they were connected to an earth that was doing pretty-much the opposite of what an earth
should: discharging into the house!
For the next day or so, a parade of linesmen climbed up and down all the pylons in the field behind our house, hunting for the source of the problem.
It seems an inconceivable coincidence to me that a network fault might happen to occur during the downtime during which we happened to have electricians working, so I find myself
wondering if perhaps the network fault had occurred some time ago but only become apparent/dangerous as a result of changes to our household configuration.
I’m no expert, but I sketched a diagram showing how such a thing might happen (click to
embiggen). I’ll stress that I don’t know for certain what went wrong: I’m just basing this on what I’ve been told my SSEN plus a little speculation:
By the time I was home from the hospital the following day, our driveway was overflowing with the vehicles of grid engineers to the point of partially blocking the main street outside
(which at least helped ensure that people obeyed our new 20mph limit for a change).
We weren’t even able to get our own car onto our driveway when we got back from the hospital.
Two and a half days later, I’m back at work and mostly recovered. I’ve still got some discomfort in my left hand, especially if I try to grip anything tightly, but I’m definitely moving
in the right direction.
It’s actually more-annoying how much my chest itches from having various patches of hair shaved-off to make it possible to hook up ECG electrodes!
The actual conversation at this point seemed to consist of the guy at the top of the pole confirming that yes, he really had disconnected the live wire from our house, and
one at the bottom saying he can’t have because he’s still seeing electricity flowing. Makes sense now, doesn’t it?
Anyway, the short of it is that I recommend against getting zapped by the grid. If it had given me superpowers it might have been a different story, but I guess it just gave me
sore muscles and a house with a dozen non-working sockets.
A lovely letter from the Vagina Museum – which I’ve not had the opportunity to visit yet – came through my letterbox:
“Yours quim-cerely,” doesn’t appear in any style guide but is now the best sign-off in any letter I’ve ever received.
This moment of joy was kick-started when I casually dropped in on a conversation about printer recommendations. I’ve got a big
ol’ Brother printer here, and it’s great, not least because even though it’s got a tonne of features like duplexing and (double-sided) scanning and photocopying and it’s even
got a fax machine built in for some reason… it doesn’t try to be any more “smart” than it needs to be. It doesn’t talk to Alexa or order itself more toner (it even gets-by with knockoff
toner!) or try to do anything well… except print things, which it does wonderfully.
For this and other reasons I recommended they buy a Brother.
Then, alongside some other Fediversians, I chipped in to help them buy one.
Totally worth it for the letter alone. Now I just need to find an excuse to visit an exhibition!
I used to have a single minor niggle with the BBC News RSS feed: that it included sports news, which I didn’t care
about. So I wrote a script that downloaded it, stripped
sports news, and re-exported the feed for me to subscribe to. Magic.
Lately my BBC News feed has caused me some annoyance and frustration.
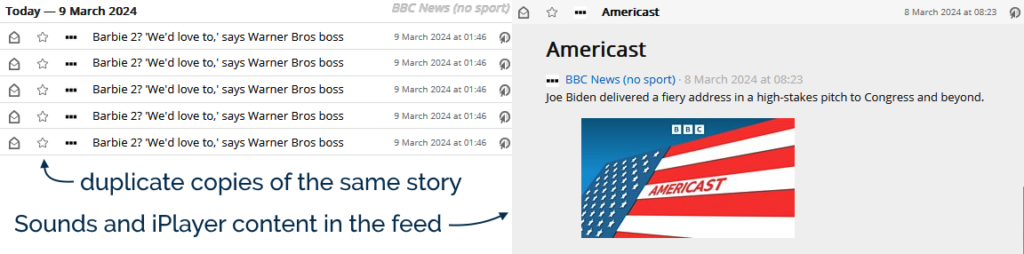
But lately – presumably as a result of technical changes at the Beeb’s side – this feed has found two fresh ways to annoy me:
The feed now re-publishes a story if it gets re-promoted to the front page… but with a different<guid> (it appears to get a #0 after it
when first published, a #1 the second time, and so on). In a typical day the feed reader might scoop up new stories about once an hour, any by the time I get to reading them the
same exact story might appear in my reader multiple times. Ugh.
They’ve started adding iPlayer and BBC Sounds content to the BBC News feed. I don’t follow BBC News in my feed reader because I want to watch or listen to things. If
you do, that’s fine, but I don’t, and I’d rather filter this content out.
Luckily, I already have a recipe for improving this feed, thanks to my prior work. Let’s look at my newly-revised script (also available on GitHub):
#!/usr/bin/env rubyrequire'bundler/inline'# # Sample crontab:# # At 41 minutes past each hour, run the script and log the results# */20 * * * * ~/bbc-news-rss-filter-sport-out.rb > ~/bbc-news-rss-filter-sport-out.log 2>>&1# Dependencies:# * open-uri - load remote URL content easily# * nokogiri - parse/filter XML
gemfile do
source 'https://rubygems.org'
gem 'nokogiri'endrequire'open-uri'# Regular expression describing the GUIDs to reject from the resulting RSS feed# We want to drop everything from the "sport" section of the website, also any iPlayer/Sounds linksREJECT_GUIDS_MATCHING=/^https:\/\/www\.bbc\.co\.uk\/(sport|iplayer|sounds)\//# Load and filter the original RSS
rss =Nokogiri::XML(open('https://feeds.bbci.co.uk/news/rss.xml?edition=uk'))
rss.css('item').select{|item| item.css('guid').text =~REJECT_GUIDS_MATCHING }.each(&:unlink)
# Strip the anchors off the <guid>s: BBC News "republishes" stories by using guids with #0, #1, #2 etc, which results in duplicates in feed readers
rss.css('guid').each{|g|g.content=g.content.gsub(/#.*$/,'')}
File.open( '/www/bbc-news-no-sport.xml', 'w' ){ |f| f.puts(rss.to_s) }
It’s amazing what you can do with Nokogiri and a half dozen lines of Ruby.
That revised script removes from the feed anything whose <guid> suggests it’s sports news or from BBC Sounds or iPlayer, and also strips any “anchor” part of the
<guid> before re-exporting the feed. Much better. (Strictly speaking, this can result in a technically-invalid feed by introducing duplicates, but your feed reader
oughta be smart enough to compensate for and ignore that: mine certainly is!)
You’re free to take and adapt the script to your own needs, or – if you don’t mind being tied to my opinions about what should be in BBC News’ RSS feed – just subscribe to my copy at:https://fox.q-t-a.uk/bbc-news-no-sport.xml
Update: nowadays, the best place to get this feed and more like it is at bbc-feeds.danq.dev.
A devastating blow by RSS against a competitor 19 years his junior! For updates on this bout as it develops, don’t forget to subscribe… using either protocol.
When I subscribe to content, I want:
Resilient failsafes. ActivityPub has many points-of-failure. A notification might fail to complete transmission as a result of downtime, faults, or network
conditions, and the receiving server might never know. A feed reader, conversely, can tell you that an address 404’d or the server was down.
Retroactive access. Once you fix the problem above… you still don’t get the message you missed: it’s probably gone forever – there’s no retroactive access. The same
is true when your ActivityPub server connects with a peer for the first time: you only ever get new content after that point. RSS, on the other hand, provides some number of “recent” items the moment you first subscribe.
Simple subscriptions. RSS can be served from a statically-hosted single file, which makes it suitable to
deploy anywhere as well as consume using anything. It can be read, after a fashion, in anything from Lynx upwards.
RSS ticks all these boxes. If I can choose between RSS and
ActivityPub to subscribe to your content, and I don’t need a real-time update, I’m probably going to choose RSS.
Obviously I appreciate that RSS and ActivityPub are different tools for different jobs, and there are doubtless
use-cases for which ActivityPub is clearly the superior solution.
I certainly don’t object to services providing both RSS and ActivityPub as syndication options, like
Mastodon does, where both might be good choices.
Has anyone informed work/colleagues about being ENM and how was it received?
I’ve informed a few colleagues but I am considering informing my team as part of my Team Champion and EDI role.
…
I’ve been “out” at every one of the employers1 since I entered into my first open/nonmonogamous
relationship a couple of decades ago.
I didn’t do so immediately: in fact, I waited almost until the point that coming out was an academic necessity! The point at which it was
only a matter of time before somebody thought they’d caught us “cheating”… or else because I didn’t want to have to lie to coworkers about e.g. from whom a romantic gift might have
come.
I guess I’ll squeeze in “come out to colleagues” in between the project planning meeting and working on rolling out the server upgrades.
Here’s how it went to be “out” at each of the three full-time jobs I’ve held over that period:
We lived and worked in and around a small town, and in our small tight-knit team we all had a reasonable handle on what was going on in one another’s personal lives. By the time I was
actively in a relationship with Ruth (while still in a relationship with Claire, whom all my coworkers had met at e.g. office parties and the
like), it just seemed prudent to mention it, as well as being honest and transparent.
This photograph – featuring some of my coworkers – was taken in 2005. At that point, they probably all thought of me as a regular, normal person. At least, as far as my relationship
structure was concerned. Not in any other way. Obviously.
It went fine. And it made Monday watercooler conversations about “who what I did at the weekend” simpler. Being a small team sharing a single open-plan office meant that I
was able to mention my relationship status to literally the entire company at once, and everybody took it with a shrug of noncommittal acceptance.
The Bodleian Libraries was a much bigger beast, and in turn a part of the massive University of Oxford. It was big enough to have a “LGBT+ Staff”
network within its Equality and Diversity unit, within which – because of cultural intersections2
– I was able to meet a handful of other poly folk at the University.
This motley crew were exactly as warm and accepting a bunch as you could ask for.
I mentioned very early on – as soon as it came up organically – the structure of the relationship I was in, and everybody was cool (or failing that, at least professional) about it.
Curious coworkers asked carefully-crafted questions, and before long (and following my lead) my curious lifestyle choices were as valid a topic for light-hearted jokes as anything else
in that fun and gossipy office.
And again: it paid-off pragmatically, especially when I took parental leave after the birth of each of our two kids3.
It also helped defuse a situation when I was spotted by a more-distant coworker on my way back from a lunchtime date with a lover who wasn’t Ruth, and my confused colleague
introduced herself to the woman that she assumed must’ve been the partner she’d heard about. When I explained that no, this is a different person I’m seeing my
colleague seemed taken aback, and I was glad to be able to call on a passing coworker who knew me better to back me up in my assertion that no, this wasn’t just me trying to lie to
cover some illicit work affair! Work allies are useful.
I’ve been with Automattic for four and a half years now, and this time around I went one step further in telling potential teammates about my relationship structure by mentioning it in
my “Howdymattic” video – a video introduction new starters are encouraged to record to say hi to the rest of the company4.
Some full-on MSPaint grade titling made it into that video, didn’t it?
A convenient side-effect of this early coming-out was that I found myself immediately inducted into the “polymatticians” group – a minor diversity group within Automattic, comprising a
massive 1.2% of the company, who openly identify as engaging in nonmonogamous relationships5!
That was eye-opening. Not only does Automattic have a stack of the regular inclusivity groups you might expect from a big tech company (queer, Black, women, trans,
neurodiverse) and a handful of the less-common ones (over-40s, cancer survivors, nondrinkers, veterans), they’ve also got a private group for those of us who happen to be both
Automatticians and in (or inclined towards) polyamorous relationships. Mind blown.
My relationship structure’s been… quietly and professionally accepted. It doesn’t really come up (why would it? in a distributed company it has even less-impact on anything than it did
in my previous non-distributed roles)… outside of the “polymatticians” private space.
In summary: I can recommend being “out” at work. So long as you’d feel professionally safe to do so: relationship structure isn’t necessarily a protected characteristic
(it’s complicated), and even if it were you might be careful about mentioning it in some environments. It’s great to have the transparency to not have to watch your words when a
coworker asks about “your partner”. Plus being free to be emotionally honest at work is just good for your mental wellbeing, in my opinion! If you trust your coworkers, be honest with
them. If you don’t… perhaps you need to start looking for a better job?
Footnotes
1 I’m not counting my freelance work during any of those periods, although I’ve been
pretty transparent with them too.
2 Let’s be clear: most queer folks, just like most straight folks, seem to be
similarly-inclined towards monogamy. But ethnical non-monogamy in various forms seems to represent a larger minority within queer communities than outside them. There’s all kinds of
possible reasons for this, and smarter people than me have written about them, but personally I’m of the opinion that, for many, it stems from the fact that by the time you’re
societally-forced to critically examine your relationships, you might as well go the extra mile and decide whether your relationship structure is right for you too. In other
words: I suspect that cis hetro folks would probably have a proportional parity of polyamory if they weren’t saturated with media and cultural role models that show them what their
relationship “should” look like.
3 Unwilling to lie, I made absolutely clear that I was neither the father of either of
them nor the husband of their mother (among other reasons, the law prohibits Ruth from marrying me on account of being married to JTA), but pointed out that my contract merely stipulated that I was the partner of a birth parent, which was something I’d made completely
clear since I first started working there. I’m not sure if I was just rubber-stamped through the University’s leave process as a matter of course or if they took a deeper look at me
and figured “yeah, we’re not going to risk picking a legal fight with that guy”, but I got my leave granted.
4 If you enjoyed my “Howdymattic”, you’ll probably also love the outtakes.
I use a tool called Sonarr to, uhh1, keep track of when new episodes of television
shows are released, regardless of what platform they’re on (Netflix, Prime, iPlayer, whatever) and notify me so I remember to watch it.
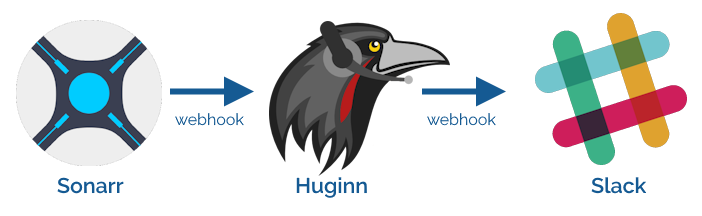
For several years, I’ve used IFTTT as the intermediary, receiving webhooks from Sonarr and
translating them for Slack:
This worked for years, but it’s time to retire it.
IFTTT‘s move to kill its Legacy Pro plan2 – which
I was on – gave me reason to re-assess this configuration. It turns that the only Pro feature I was using was an IFTTT “filter” to
convert the Sonarr webhooks to a Slack-friendly-format.
Given that I’m running an installation of Huginn on my home network anyway, I resolved to re-implement this flow in Huginn and
cancel my IFTTT subscription.
Raven-powered automation is the new hotness.
This turned out to be so easy I wonder why I never did it before.
First, I created a Webhook Agent and gave the URL to Sonarr.
Then I connected that to a Slack Agent with the following configuration:
I’ve omitted my Slack webhook URL so you don’t spam me. I tried for far too long to get the pluralize filter to
work so it’d say “episode” or “episodes” as appropriate before realising I didn’t care enough and gave up.
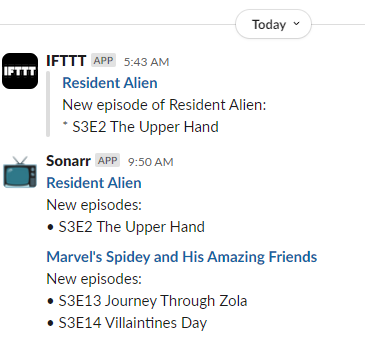
Then all I needed to do was re-emit some of the previous webhooks to test it:
As a bonus, I swapped out the IFTTT logo for Slackmoji’s :tv: icon and added the “Sonarr” username, as shown in my code sample.
Now I’ll continue to know when there’s new television to watch3!
I love the power and flexibility that Huginn provides to help automate your life. It does many of the things that I used to do with a handful of cron jobs and shell scripts, but all in
one convenient place.
Footnotes
1 I’ve heard there are other uses for the tool. Your mileage may vary. Don’t forget to pay
for your content, if possible.
3 It’s especially useful when you’re between seasons or a show is on hiatus to be reminded
that it’s back and I should go and watch it. Hey, there’s a thought: I wonder if I can extract the subtitles from shows and run them through a summarising LLM to give me a couple of paragraphs reminding me “what happened last series” if the show’s been on a long break?
During a family holiday last week to the Three Valleys region of the French Alps for some skiing1, I
came to see that I enjoy a privilege I call the freedom of the mountain.
“Mornin’. Let’s go skiing.”
The Freedom
The freedom of the mountain is a privilege that comes from having the level of experience necessary to take on virtually any run a resort has to offer. It provides a handful of
benefits denied to less-confident skiers:
I usually don’t feed to look at a map to plan my next route; whichever way I go will be fine!
When I reach one or more lifts, I can choose which to take based on the length of their queue, rather than considering their destinations.
When faced with a choice of pistes (or an off-piste route), my choice can be based on my mood, how crowded they are, etc., rather than their rated difficulty.
Let’s tear this up, yo.
The downside is that I’m less well-equipped to consider the needs of others! Out skiing with Ruth one morning I suggested a route back into town that “felt easy” based on my previous
runs, only to have her tell me that – according to the map – it probably wasn’t!
Approaching the Peak
The kids spent the week in lessons. It’s paying off: they’re both improving fast, and the eldest has got all the essentials down and it’s working on improving her parallel turns and on
“reading the mountain”. It’s absolutely possible that the eldest, and perhaps both of them, will be a better skier than me someday2.
I’m not perfect, mind. While skiing backwards and filming, I misjudged the height of an arch and hit the back of the head with it… despite the child shouting to warn me! 😅
Maybe, as part of my effort to do what I’m bad at, I should have another go at learning to
snowboard. I always found snowboarding frustrating because everything I needed to re-learn was something that I could already do much better and easier on skis. But perhaps if I can
reframe that frustration through the lens of learning itself as the destination, I might be in a better place. One to consider for next time I hit the piste.
Progressive enhancement is a great philosophy for Web application development. Deliver all the essential basic functionality using the simplest standards available; use advanced
technologies to add bonus value and convenience features for users whose platform supports them. Win.
JavaScript disabled/enabled is one of the most-fundamental ways to differentiate a basic from an enhanced experience, but it’s absolutely not the only way (especially now that feature
detection in JavaScript and in CSS has become so powerful!).
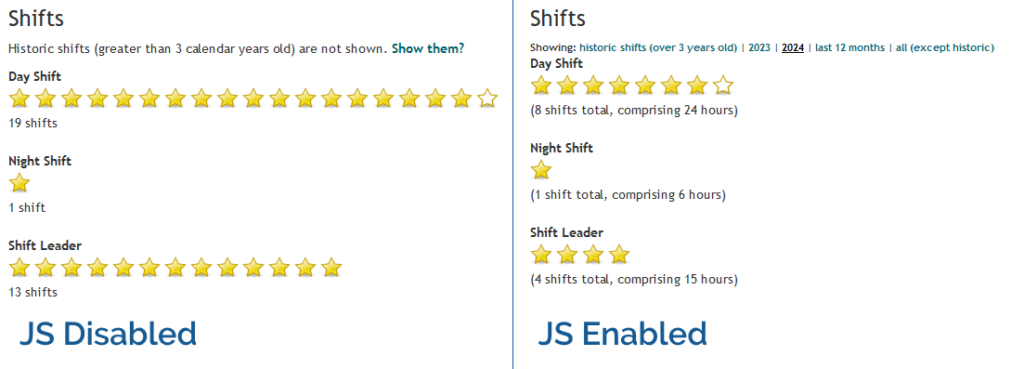
In Three Rings, for example, volunteers can see a “starchart” of the volunteering shifts they’ve done recently, at-a-glance, on
their profile page1.
In the most basic case, this is usable in its HTML-only form: even with no JavaScript, no CSS, no images even, it still functions. But if JavaScript is enabled, the volunteer can dynamically “filter” the year(s) of volunteering
they’re viewing. Basic progressive enhancement.
If a feature requires JavaScript, my usual approach is to use JavaScript to add the relevant user interface to the page in the first place. Those starchart filters in Three
Rings don’t appear at all if JavaScript is disabled. A downside to this approach is that the JavaScript necessarily modifies the DOM on page load, which introduces a delay to the page being interactive as well as potentially resulting in layout shift.
That’s not always the best approach. I was reminded of this today by the website of 7-year-old Shiro (produced with, one assumes, at least
a little help from Saneef H. Ansari). Take a look at this progressively-enhanced theme switcher:
No layout
shift, no DOM manipulation. And yet it’s still pretty clear what features are available.
The HTML that’s delivered over-the-wire provides a disabled<select> element, which gains the CSS directive cursor: not-allowed;, to make it clear to the used that this dropdown doesn’t do anything. The whole thing’s wrapped
in a custom element.
When that custom element is defined by the JavaScript, it enhances the dropdown with an event listener that implements the theme changes, then enables the disabled
<select>.
I’m not convinced by the necessity of the <form> if there’s no HTML-only fallback… and the <label>
probably should use a for="..." rather than wrapping the <select>, but otherwise this code is absolutely gorgeous.
It’s probably no inconvenience to the minority of JS-less users to see a theme switcher than, when they go to use it, turns out to be
disabled. But it saves time for virtually everybody not to have to wait for JavaScript to manipulate the DOM, or else to risk
shifting the layout by revealing a previously-hidden element.
Altogether, this is a really clever approach, and I was pleased today to be reminded – by a 7-year-old! – of the elegance of this approach. Nice one Shiro (and Saneef!).
Footnotes
1 Assuming that administrators at the organisation where they volunteer enable this
feature for them, of course: Three Rings‘ permission model is robust and highly-customisable. Okay, that’s enough sales pitch.
I guess I’ve always been more of a sprinter/hurdles blogger than a marathon runner.
Might I meet that challenge? Maybe. But it turns out it’s easier than I thought because Kev revised the rules to require only 100 posts in a calendar year (or any other 365-day
period, but I’m not going to start thinking about the maths of that).
That’s not only much more-achievable… I’ve probably already achieved it! Let’s knock out some SQL to check how many posts I
made each year:
SELECTYEAR(wp_posts.post_date_gmt) yyyy,
COUNT(wp_posts.ID) total
FROM
wp_posts
WHERE
wp_posts.post_status='publish'AND wp_posts.post_type='post'GROUPBY yyyy
ORDERBY yyyy
My code’s actually a little more-complicated than this, because of some plot, but this covers the essentials.
A big question in some years is what counts as a post. Kev’s definition is quite liberal and includes basically-everything, but I wonder if mine shouldn’t perhaps be stricter.
For example:
Should I count checkins, even though they’re not always born as blog posts but often start as logs on geocaching websites?
(My gut says yes!)
Do reposts and bookmarks contribute, a significant minority of which are presented without any further
interpretation by me? (My gut says no!)
Does a vlog version of a blog post count separately, or is it a continuation of the same content? (My gut says the volume is too
low to matter!)
Can a retroactive achievement (i.e. from before the challenge was announced) count? Kev writes “there is no specific start date”, but it seems a little counter to
the idea of it specifically being a challenge to claim it when you weren’t attempting the challenge at the time.
Some posts are lost from 1998/1999. If they were recovered I might have made 100 posts in 1999, but probably not in 1998 as I only started blogging on 27 September 1998.
A heartfelt post about saying goodbye to Aberystwyth as I moved to Oxford on 16 June was my 100th of the year. Pedants might argue that
this year shouldn't count, but so long as you're willing to count checkins (and you should) then it would... and my qualifying post would have come only a couple of days
later, with a post about the Headington Shark, which I had just moved-in near to.
I'm not convined this low-blogging year should count: a clear majority of the posts were geocaching logs, and they weren't always even that verbose (consider this candidate for 100th post of 2013, from 1 October).
Another geocache log heavy, conventional blogpost light year that I'm not convinced should count, even if the obvious candidate for 100th post would be 18 May's cool article about
geocaching like Batman!
I maintain that checkins should count, even when they're PESOS'd from geocaching sites, so long as they don't make up a majority of the qualifying posts in a year. In
which case this year should qualify, with the 100th post being my visit to this well-hidden London pub
while on my way to a conference.
My blogging ramped up again this year, and on 24 August I shared a motivational poster with a funny twist, plus a pun at the intersection
between my sexuality and my preferred mode of transport.
Total count of all the posts.
Doesn't add up? Not all posts feature in one of the years above!
* Pedants might claim this year was not a success for the reasons described above. Make your own mind up.
In any case, I’d argue that I clearly achieved the revised version of the challenge on certainly six, probably fourteen, arguably (depending on how you count posts) as
many as nineteen different years since I started blogging in 1998. My least-controversial claims would be:
Given all these unanswered questions, I’m not going to just go ahead and raise a PR against the Hall of Fame! Instead, I’ll leave it to
Kev to decide whether I’m (a) eligible to claim a 14-time award, (b) merely eligible for a 4-time award for the years following the challenge starting, or (c) ineligible to claim
success until I intentionally post 100 times in a year (in, at current rates, another two months…). Over to you, Kev…
Update: Kev’s agreed that I can claim the most-recent four of them, so I raised a PR.