Email Antipatterns
There are two particular varieties of email address that I don’t often see, but I’ve been known to ridicule when I have:
-
Geographically-based personal email addresses, e.g.
OurHouseName@example.com. These always seemed to me to undermine one of the single-best things about an email address compared to postal mail – that they don’t change when you move house!1 -
Shared/couple email addresses, e.g.
MrAndMrsSmith@example.net. These make me want to scream “You know email addresses are basically free, right? You don’t have to share one!” Even back when most people got their email address directly from their dial-up provider, most ISPs offered some number of addresses (e.g. five).
If you’ve come across either of the above before, there’s… perhaps a reasonable chance that it was in the possession of somebody born before 1960 (and the older, the more-likely)2.

You’ll never catch me doing that!
I found myself thinking about this as I clicked the “No” button on a poll by Terence Eden that asked whether I used a “shared” email address when in a stable long-term relationship.
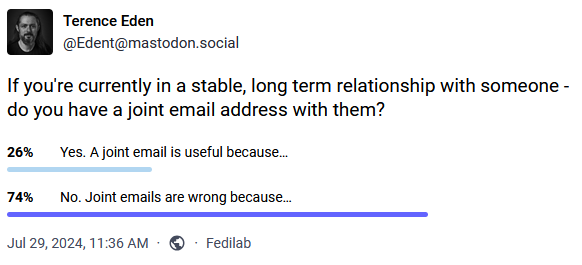
It wasn’t until after I clicked “No” that I realised that, in actual fact, I have had multiple email addresses that I’ve share with significant other(s). And more than that, sometimes they’ve been geographically-based! What’s going on?
I’ve routinely had domains or subdomains that I’ve used to represent a place that I live. They’re convenient for when you want to give somebody a short web address which’ll take them to a page with directions to you and links to your location in a variety of different services and formats.
And by that point, you might as well have an email alias, e.g. all@myhouse.example.org, that forwards on email to, well, all the adults at the house. What I’ve
described there is, after a fashion, a shared email address tied to a geographical location. But we don’t ever send anything from it. Nor do we use it for any kind of
personal communication with anybody outside the house.
We don’t give out these all@ addresses (or their aliases: every company gets their own) to people willy-nilly. But they’re useful for shared services that send
automated emails to us all. For example:
- Giving a forwarding alias to the supermarket means that receipts (listing any unavailable products) g0 to all of us, and whoever’s meal plan’s been scuppered by an awkward substitution will know what’s up.
- Using a forwarding alias with the household Netflix account means anybody can use the “send me a sign-in link” feature to connect a new device.
- When confirming that you’ve sent money to a service provider, CC’ing one of these nice, short aliases provides a quick way to let the others know that a bill’s been paid (this one’s especially useful where, like me, you live in a 3+ adult household and otherwise you’d be having to add multiple people to the CC field).
Sure, the need for most of these solutions would evaporate instantly if more services supported multi-user or delegated access3. But outside of that fantasy world, shared aliases seem to be pretty useful!
Footnotes
1 The most ill-conceived example of geographically-based email addresses I’ve ever seen
came from a a 2003 proposal by then-MP Derek Wyatt, who proposed that the domain name part of every single email address should contain not
only the country of the owner (e.g. .uk) but also their complete postcode. He was under the delusion that this would somehow prevent spam. Even ignoring the
immense technical challenges of his proposal and the impossibility of policing it across the borders of every country that uses email… it probably wouldn’t even be
effective at his stated goal. I’ll let The Register take it from here.
2 No ageism intended: I suspect that the phenomenon actually stems from the fact that as email took off in the noughties this demographic who were significantly more-likely than younger folks to have (a) a very long-term home that they didn’t anticipate moving out of any time soon, and (b) an existing anticipation that people and companies wrote to them as a couple, not individually.
3 I’d love it if the grocery delivery sites would let multiple “accounts”, by mutual consent, share a delivery slot, destination, and payment method. It’d be cool to know that we could e.g. have a houseguest and give them temporary access to a specific order that was scheduled for during their stay. But that’s probably a lot of work for very little payoff if you’re busy running a supermarket.