If you’ve been a programmer or programming-adjacent nerd1 for a while, you’ll have doubtless come across an ASCII table.
An ASCII table is useful. But did you know it’s also beautiful and elegant.

History
ASCII was initially standardised in X3.4-1963 (which just rolls off the tongue, doesn’t it?) which assigned meanings to 100 of the potential 128 codepoints presented by a 7-bit4 binary representation: that is, binary values 0000000 through 1111111:
If you’ve already guessed where I’m going with this, you might be interested to look at the X3.4-1963 table and see that yes, many of the same elegant design choices I’ll be talking about later already existed back in 1963. That’s really cool!
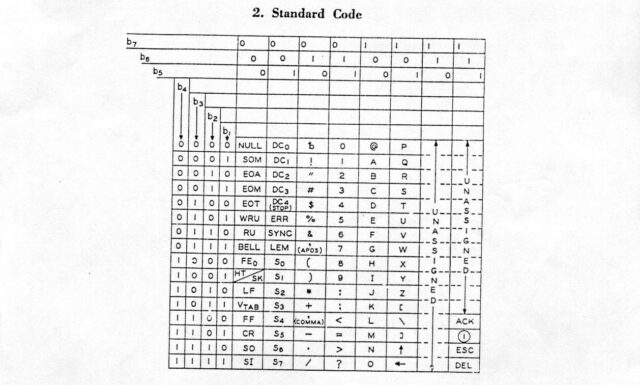
Table
In case you’re not yet intimately familiar with it, let’s take a look at an ASCII table. I’ve colour-coded some of the bits I think are most-beautiful:
 That table only shows decimal and
hexadecimal values for each character, but we’re going to need some binary too, to really appreciate some of the things that make ASCII sublime and clever.
That table only shows decimal and
hexadecimal values for each character, but we’re going to need some binary too, to really appreciate some of the things that make ASCII sublime and clever.
Control codes
The first 32 “characters” (and, arguably, the final one) aren’t things that you can see, but commands sent between machines to provide additional instructions. You might be
familiar with carriage return (0D) and line feed (0A) which mean “go back to the beginning of this line” and “advance to the next line”,
respectively5.
Many of the others don’t see widespread use any more – they were designed for very different kinds of computer systems than we routinely use today – but they’re all still there.
32 is a power of two, which means that you’d rightly expect these control codes to mathematically share a particular “pattern” in their binary representation with one another, distinct
from the rest of the table. And they do! All of the control codes follow the pattern 00_____: that is, they begin with two zeroes. So when you’re reading
7-bit ASCII6, if it starts with
00, it’s a non-printing character. Otherwise it’s a printing character.
Not only does this pattern make it easy for humans to read (and, with it, makes the code less-arbitrary and more-beautiful); it also helps if you’re an ancient slow computer system comparing one bit of information at a time. In this case, you can use a decision tree to make shortcuts.

1111111. This
is a historical throwback to paper tape, where the keyboard would punch some permutation of seven holes to represent the ones and zeros of each character. You can’t delete
holes once they’ve been punched, so the only way to mark a character as invalid was to rewind the tape and punch out all the holes in that position: i.e. all
1s.
Space
The first printing character is space; it’s an invisible character, but it’s still one that has meaning to humans, so it’s not a control character (this sounds obvious today, but it was actually the source of some semantic argument when the ASCII standard was first being discussed).
Putting it numerically before any other printing character was a very carefully-considered and deliberate choice. The reason: sorting. For a computer to sort a list (of files, strings, or whatever) it’s easiest if it can do so numerically, using the same character conversion table as it uses for all other purposes7. The space character must naturally come before other characters, or else John Smith won’t appear before Johnny Five in a computer-sorted list as you’d expect him to.
Being the first printing character, space also enjoys a beautiful and memorable binary representation that a human can easily recognise: 0100000.
Numbers
The position of the Arabic numbers 0-9 is no coincidence, either. Their position means that they start with zero at the nice round binary value 0110000
(and similarly round hex value 30) and continue sequentially, giving:
| Binary | Hex | Decimal digit (character) |
|---|---|---|
011 0000
|
30
|
0 |
011 0001
|
31
|
1 |
011 0010
|
32
|
2 |
011 0011
|
33
|
3 |
011 0100
|
34
|
4 |
011 0101
|
35
|
5 |
011 0110
|
36
|
6 |
011 0111
|
37
|
7 |
011 1000
|
38
|
8 |
011 1001
|
39
|
9 |
The last four digits of the binary are a representation of the value of the decimal digit depicted. And the last digit of the hexadecimal representation is the decimal digit. That’s just brilliant!
If you’re using this post as a way to teach yourself to “read” binary-formatted ASCII in your head,
the rule to take away here is: if it begins 011, treat the remainder as a binary representation of an actual number. You’ll probably be
right: if the number you get is above 9, it’s probably some kind of punctuation instead.
Shifted Numbers
Subtract 0010000 from each of the numbers and you get the shifted numbers. The first one’s occupied by the space character already, which is a
shame, but for the rest of them, the characters are what you get if you press the shift key and that number key at the same time.
“No it’s not!” I hear you cry. Okay, you’re probably right. I’m using a 105-key ISO/UK QWERTY keyboard and… only four of the nine digits 1-9 have their shifted variants properly represented in ASCII.
That, I’m afraid, is because ASCII was based not on modern computer keyboards but on the shifted positions of a Remington No. 2 mechanical typewriter – whose shifted layout was the closest compromise we could find as a standard at the time, I imagine. But hey, you got to learn something about typewriters today, if that’s any consolation.

Letters
Like the numbers, the letters get a pattern. After the @-symbol at 1000000, the uppercase letters all begin
10, followed by the binary representation of their position in the alphabet. 1 = A = 1000001, 2 = B = 1000010, and so on up to 26 = Z =
1011010. If you can learn the numbers of the positions of the letters in the alphabet, and you can count
in binary, you now know enough to be able to read any ASCII uppercase letter that’s been encoded as
binary8.
And once you know the uppercase letters, the lowercase ones are easy too. Their position in the table means that they’re all exactly 0100000
higher than the uppercase variants; i.e. all the lowercase letters begin 11! 1 = a = 1100001, 2 = b = 1100010, and 26 = z =
1111010.
If you’re wondering why the uppercase letters come first, the answer again is sorting: also the fact that the first implementation of ASCII, which we saw above, was put together before it was certain that computer systems would need separate character codes for upper and lowercase letters (you could conceive of an alternative implementation that instead sent control codes to instruct the recipient to switch case, for example). Given the ways in which the technology is now used, I’m glad they eventually made the decision they did.
Beauty
There’s a strange and subtle charm to ASCII. Given that we all use it (or things derived from it) literally all the time in our modern lives and our everyday devices, it’s easy to think of it as just some arbitrary encoding.
But the choices made in deciding what streams of ones and zeroes would represent which characters expose a refined logic. It’s aesthetically pleasing, and littered with historical artefacts that teach us a hidden history of computing. And it’s built atop patterns that are sufficiently sophisticated to facilitate powerful processing while being coherent enough for a human to memorise, learn, and understand.
Footnotes
1 Programming-adjacent? Yeah. For example, geocachers who’ve ever had to decode a puzzle-geocache where the coordinates were presented in binary (by which I mean: a binary representation of ASCII) are “programming-adjacent nerds” for the purposes of this discussion.
2 In both the book and the film, Mark Watney divides a circle around the recovered Pathfinder lander into segments corresponding to hexadecimal digits 0 through F to allow the rotation of its camera (by operators on Earth) to transmit pairs of 4-bit words. Two 4-bit words makes an 8-bit byte that he can decode as ASCII, thereby effecting a means to re-establish communication with Earth.
3 Y’know, so that you can type all those emoji you love so much.
4 ASCII is often thought of as an 8-bit code, but it’s not: it’s 7-bit. That’s why virtually every ASCII message you see starts every octet with a zero. 8-bits is a convenient number for transmission purposes (thanks mostly to being a power of two), but early 8-bit systems would be far more-likely to use the 8th bit as a parity check, to help detect transmission errors. Of course, there’s also nothing to say you can’t just transmit a stream of 7-bit characters back to back!
5 Back when data was sent to teletype printers these two characters had a distinct
different meaning, and sometimes they were so slow at returning their heads to the left-hand-side of the paper that you’d also need to send a few null bytes e.g. 0D 0A
00 00 00 00 to make sure that the print head had gotten settled into the right place before you sent more data: printers didn’t have memory buffers at this point! For
compatibility with teletypes, early minicomputers followed the same carriage return plus line feed convention, even when outputting text to screens. Then to maintain backwards
compatibility with those systems, the next generation of computers would also use both a carriage return and a line feed character to mean “next line”. And so,
in the modern day, many computer systems (including Windows most of the time, and many Internet protocols) still continue to use the combination of a carriage return
and a line feed character every time they want to say “next line”; a redundancy build for a chain of backwards-compatibility that ceased to be relevant decades ago but which
remains with us forever as part of our digital heritage.
6 Got 8 binary digits in front of you? The first digit is probably zero. Drop it. Now you’ve got 7-bit ASCII. Sorted.
7 I’m hugely grateful to section 13.8 of Coded Character Sets, History and Development by Charles E. Mackenzie (1980), the entire text of which is available freely online, for helping me to understand the importance of the position of the space character within the ASCII character set. While most of what I’ve written in this blog post were things I already knew, I’d never fully grasped its significance of the space character’s location until today!
8 I’m sure you know this already, but in case you’re one of today’s lucky 10,000 to discover that the reason we call the majuscule and minuscule letters “uppercase” and “lowercase”, respectively, dates to 19th century printing, when moveable type would be stored in a box (a “type case”) corresponding to its character type. The “upper” case was where the capital letters would typically be stored.
The explanation of DEL goes further back than punchtape to punchcards.
Type the cards up. Drop the cards in the reader/writer and they read the cards and punch line numbers into them.
Now to edit: DEL the errored character (punch out the entire column on the card). Grab a new card, punch in the line number, and in the correct column the new character. That means all the other columns are NUL. Insert that correction card after the incorrect card.
Now drop the lot through the reader/writer again, with line number punching off.
The editor loads the text, with the second card correcting the line created by the first card.
Many editors would store DEL as NUL, meaning that future cards for that line were simply ORed.
😲 I learned a lot just from your well written blog post about the beauty and historical background of the ASCII character encoding standard. I’m supprised how little I had already know about the most important character encoding standard.
The one thing that you mentioned that I come across and only know about it because of it is that Windows still uses the carriage return and the line feed character when I opened some plain text files the lines all ended with “^M” in vim under Linux. I have to do some research why is this happening and how to fix it.
I have learned this way Windows uses “/r/n”, where “/r” character is carriage return and “/n” character is line feed, while Linux (and all Unix like OSs) only uses “/n” the line feed character.
The fix was an easy fix I had to convert “/r/n” in the end of each line to “/n”, there’s multiple ways to do it the easiest being the dos2unix commandline utility.
A person could hardly avoid ASCII in the early days of flash gaming. Pretty much any game with an in game chat inevitably displayed & # 3 9 ; in place of an apostrophe. And every kid would inevitably learn that using the same syntax with 102 would allow them to bypass chat filters.
Interesting write up. I learned something new today. 😀
Fascinating stuff! On the other hand, I am really glad that I don’t have to program with paper tape. I don’t think I would have become a programmer if I had been born in 1951, like my father-in-law. I am reminded a bit of the book Outliers by Malcolm Gladwell, in which he notes that many of the software giants like Bill Gates, Steve Jobs, Wozniak, Bill Joy, etc. were all born within a few years of each other. They were all coming of age when computing was transitioning from punch cards to terminal-based computing, such that instead of having to wait 1-3 days to see the results of your program, you could see it immediately, which made programming much more enjoyable, and so they were lucky to get into programming at such a time. I feel lucky to have started at a time when Linux was mature enough to be stable and fun.
Amazing explanation! Thank you for the article! :)
When I started coding in my teens by code golfing in python, ASCII looked like an empirical table of rune magic. I loved it so much, the table you used (minus the highlighting) became my wallpaper for a couple years.
Finally almost ten years later it makes a bit more sense in my mind. :D Somehow binary and hex do fair better than decimal when trying to memorize the values, who would have guessed (((:
alternatively, for some typist & typewriters a lower-case L doubled as the numeral 1.
I really like your style
Never liked that the numbers are not immediately followed by letters, so that you can directly convert to hex: char hex_char = ‘0’ + value;
When describing Carriage Return and Line Feed, why do you refer to one in Hex (0D) and one in Decimal (10)? Both in the text and in the footnote. Carriage Return is 13 decimal, and Line Feed is 0A hex. (typing hex values in this font is a bit unsatisfying too). 10 hex is 16 decimal, the under utilized DLE code.
The letters also correspond to the control characters so that one can type Ctrl+M to insert a carriage return or Ctrl+J for a linefeed. Also Ctrl+L for Form Feed, Ctrl+H for backspace, &c.
@Light, this is why ^M shows up in your Windows text files on Linux. Old Macs actually used ^M alone as the line separator.
Another thing about old typewriters, they often didn’t have an Exclamation Mark character. You were expected to type a period, then backspace, then type an apostrophe on top of it: . ^H ‘ = !
Whoops! Typo. Thanks for pointing it out; fixed now.
Interesting read. I also wrote a story about ASCII : https://www.lostlanguageofthemachines.com/chapter2
Thanks for sharing. Wow; I love that it’s interactive!
ok enough
I recently discussed with a former coworker if the 32-character difference between the upper and lower case ranges in early systems was related to the shift key directly flipping the relevant bit (an xor with 0x20).
The closest indication of this we found was the following sentence by R. W. Bemer in “Standards for Keyboards”:
> The major problem is the “bit-paired” keyboard where the character pairs on each key, no matter how dissimilar to each other or contrary to a typewriter keyboard, are forced by the fact that the two characters differed by the one shift key controlled bit in the bit-coded representation
Fascinating article, I love understanding the origin of things and this one explained it well
You mix the terms code, character, digit and number as if there is no difference in this context. Obviously there is.
Yeah, it’s hard to talk about the characters that represent digits and the numbers of those characters without getting tangled somewhere along the way. I hope I’ve mostly made sense!
Another interesting backwards compatibility angle involving ASCII appears in the UTF-8 standard. At the time that standard came out, there were literally billions of ASCII documents in storage around the world. The brilliant solution here was to make the first 127 code points in UTF-8 identical to their ASCII encoding. Thus, an ASCII file or document could be read as a UTF-8 document with no changes. (The reverse is not true, of course.)
This simple convention vastly encouraged the adoption of UTF-8, and saved millions of hours of software engineer time.
It just occurred to me that the control and shift keys both work by zeroing bits.
Wow, thanks! It was staring me in the face but I did not see the pretty patterns then but I do now :) I documented the readable part of the ASCII table with HEX columns (0 to F):
0 1 2 3 4 5 6 7 8 9 A B C D E F +---+---+---+---+---+---+---+---+ +---+---+---+---+---+---+---+---+ 20 | | ! | " | # | $ | % | & | ' | | ( | ) | * | + | , | - | . | / | +---+---+---+---+---+---+---+---+ +---+---+---+---+---+---+---+---+ 30 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | | 8 | 9 | : | ; | | ? | +---+---+---+---+---+---+---+---+ +---+---+---+---+---+---+---+---+ 40 | @ | A | B | C | D | E | F | G | | H | I | J | K | L | M | N | O | +---+---+---+---+---+---+---+---+ +---+---+---+---+---+---+---+---+ 50 | P | Q | R | S | T | U | V | W | | X | Y | Z | [ | \ | ] | ^ | _ | +---+---+---+---+---+---+---+---+ +---+---+---+---+---+---+---+---+ 60 | ` | a | b | c | d | e | f | g | | h | i | j | k | l | m | n | o | +---+---+---+---+---+---+---+---+ +---+---+---+---+---+---+---+---+ 70 | p | q | r | s | t | u | v | w | | x | y | z | { | | | } | ~ | | +---+---+---+---+---+---+---+---+ +---+---+---+---+---+---+---+---+https://piconomix.com/px-fwlib/group___p_x___a_s_c_i_i.html
Best ascii chart ever: https://ctan.org/pkg/ascii-chart
Clean! Thanks for sharing.
A lot of the early microcomputers on the late 70s and early 80s did have the shifted number keys in the “right” place per the table: !”#$%&’()sp. Likewise the shifted punctuation keys.
You know what, I should’ve known that given how long it took me to re-train my muscle memory from working on an Amstrad CPC microcomputer (which had exactly that layout) when I switched to a PC-AT-compatible! Thanks for reminding me!