I keep my life pretty busy and don’t get as much “outside” as I’d like, but when I do I like to get out on an occasional geohashing expedition (like these
ones). I (somewhat badly) explained geohashing in the vlog attached to my expedition 2018-08-07 51 -1, but the short
version is this: an xkcd comic proposed an formula to use a stock market index to generate a pair of random coordinates, impossible to predict in
advance, for each date. Those coordinates are (broadly) repeated for each degree of latitude and longitude throughout the planet, and your challenge is to get to them and discover
what’s there. So it’s like geocaching, except you don’t get to find anything at the end and there’s no guarantee that the destination is even remotely accessible. I love it.
My favourite kind of random pointlessness is summarised by this algorithm.
Most geohashers used to use a MediaWiki-powered website to coordinate their efforts and share their stories, until a different application on the server where it resided got hacked and the wiki got taken down as a precaution.
That was last September, and the community became somewhat “lost” this winter as a result. It didn’t stop us ‘hashing, of course: the algorithm’s open-source and so are many of its
implementations, so I was able to sink into a disgusting hole in November, for example. But we’d lost the digital
“village square” of our community.
My dissertation “burndown” is characterised on my whiteboard by two variables: outstanding issues (blue) and wordcount (red). There are… a few problems.
So I emailed Davean, who does techy things for xkcd, and said that I’d like to take over the Geohashing wiki but that I’d first like (a) his or Randall’s blessing to do so, and ideally
(b) a backup of the pages of the site as it last-stood. Apparently I thought that my new job plus finishing my dissertation plus trying to move house plus all of the usual
things I fill my time with wasn’t enough and I needed a mini side-project, because when I finally got the go-ahead at the end of last month I (re)launched geohashing.site. Take a look, if you like. If you’ve never been Geohashing before, there’s never been a more-obscure time to start!
My implementation of the site is mobile-friendly for the benefit of people who might want to use it while out in a muddy ditch. For example. Just hypothetically.
Luckily, it’s not been a significant time-sink for me: members of the geohashing community quickly stepped up to help me modernise content, fix bots, update hyperlinks and the like. I
took the opportunity to fix a few things that had always bugged me about the old site, like the mobile-unfriendly interface and the inability to upload GPX files, and laid the groundwork to make bigger changes down the road (like changing the way that inline maps are displayed, a popular community request).
So yeah: Geohashing’s back, not that it ever went away, and I got to be part of the mission to make it so. I feel like I am, as geohashers say… out standing in my field.
Last week I built Fox, the newest addition to our home network. Fox, whose specification
called for not one, not two, not three but four 12 terabyte hard disk drives was built principally as a souped-up NAS
device – a central place for us all to safely hold and control access to important files rather than having them spread across our various devices – but she’s got a lot more going on
that that, too.
Right now, Fox lives under my desk along with most of our network cables.
Fox has:
Enough hard drive space to give us 36TB of storage capacity plus 12TB of parity, allowing any
one of the drives to fail without losing any data.
“Headroom” sufficient to double its capacity in the future without significant effort.
A mediumweight graphics card to assist with real-time transcoding, helping her to convert and stream audio and videos to our devices in whatever format they prefer.
A beefy processor and sufficient RAM to run a dozen virtual machines supporting a variety of functions like software
development, media ripping and cataloguing, photo rescaling, reverse-proxying, and document scanning (a planned future purpose for Fox is to have a network-enabled scanner near our
“in-trays” so that we can digitise and OCR all of our post and paperwork into a searchable, accessible, space-saving
collection).
“QFlix” is a lot like Netflix, except geared mostly towards saving us from having to walk over to the DVD shelf or remember which disc we were up to when watching a long-running
series. #firstworldproblems
The last time I filmed myself building a PC was when I built Cosmo, a couple of desktops ago. He
turned out to be a bit of a nightmare: he was my first fully-watercooled computer and he leaked everywhere: by the time I’d done all the fixing and re-fixing to make him behave nicely,
I wasn’t happy with the video footage and I never uploaded it. I’d been wary, almost-superstitious, about filming a build since then, but I shot a timelapse of Fox’s construction and it
turned out pretty well: you can watch it below or on YouTube or QTube.
The timelapse slows to real-time, about a minute in, to illustrate a point about the component test I did with only a CPU (and
cooler), PSU, and RAM attached. Something I routinely do when building
computers but which I only recently discovered isn’t commonly practised is shown: that the easiest way to power on a computer without attaching a power switch is just to bridge the
power switch pins using your screwdriver!
Fox is running Unraid, an operating system basically designed for exactly these kinds of purposes. I’ve been super-impressed by the
ease-of-use and versatility of Unraid and I’d recommend it if you’ve got a similar NAS project in your future! I’d also like
to sing the praises of the Fractal Design Node 804 case: it’s not got quite as many bells-and-whistles
as some cases, but its dual-chamber design is spot-on for a multipurpose NAS, giving ample room for both full-sized expansion
cards and heatsinks and lots of hard drives in a relatively compact space.
While being driven around England it struck me that humans are currently like the filling in a sandwich between one slice of machine — the satnav — and another — the car. Before the
invention of sandwiches the vehicle was simply a slice of machine with a human topping. But now it’s a sandwich, and the two machine slices are slowly squeezing out the human filling
and will eventually be stuck directly together with nothing but a thin layer of API butter. Then the human will be a superfluous thing, perhaps a little gherkin on the side of the
plate.
While we were driving I was reading the directions from a mapping app on my phone, with the sound off, checking the upcoming turns, and giving verbal directions to Mary, the driver. I
was an extra layer of human garnish — perhaps some chutney or a sliced tomato — between the satnav slice and the driver filling.
What Phil’s describing is probably familiar to you: the experience of one or more humans acting as the go-between to allow two machines to communicate. If you’ve ever re-typed a
document that was visible on another screen, read somebody a password over the phone, given directions from a digital map, used a pendrive to carry files between computers that weren’t
talking to one another properly then you’ve done it: you’ve been the soft wet meaty middleware that bridged two already semi-automated (but not quite automated enough)
systems.
Sigourney Weaver as Gwen DeMarco as Tawny Madison realised what she was doing back in 1999. Should I be alarmed that a science fiction spoof is a better indicator of the future that
the science fiction it parodies?
This generally happens because of the lack of a common API (a communications protocol) between two systems. If your
phone and your car could just talk it out then the car would know where to go all by itself! Or, until we get self-driving cars, it could at least provide the directions in a
way that was appropriately-accessible to the driver: heads-up display, context-relative directions, or whatever.
It also sometimes happens when the computer-to-human interface isn’t good enough; for example I’ve often offered to navigate for a driver (and used my phone for the purpose) because I
can add a layer of common sense. There’s no need for me to tell my buddy to take the second exit from every roundabout in Milton Keynes (did you know that the town has 930 of them?) – I can just tell them that I’ll let them know when
they have to change road and trust that they’ll just keep going straight ahead until then.
Finally, we also sometimes find ourselves acting as a go-between to filter and improve information flow when the computers don’t have enough information to do better by themselves. I’ll
use the fact that I can see the road conditions and the lane markings and the proposed route ahead to tell a driver to get into the right lane with an appropriate amount of
warning. Or if the driver says “I can see signs to our destination now, I’ll just keep following them,” I can shut up unless something goes awry. Your in-car SatNav can’t do that
because it can’t see and interpret the road ahead of you… at least not yet!
I was certainly glad that this prototype self-driving car could “see” me when it overtook my bike the other day.
But here’s my thought: claims of an upcoming AI
winter aside, it feels to me like we’re making faster progress in technologies related to human-computer interaction – voice and natural languages interfaces, popularised
by virtual assistants like Siri and Alexa and by chatbots – than we are in technologies related to universal computer interoperability. Voice-controller computers are hip and exciting
and attract a lot of investment but interoperable systems are hampered by two major things. The first thing holding back interoperability is business interests: for the longest while,
for example, you couldn’t use Amazon Prime Video on a Google Chromecast for a long while because the two companies couldn’t play nice. The second thing is a lack of interest by
manufacturers in developing open standards: every smart home appliance manufacturer wants you to use their app, and so your smart speaker manufacturer needs to implement code
to talk to each and every one of them, and when they stop supporting one… well, suddenly your thermostat switches jumps permanently from smart mode to dumb mode.
A thing that annoys me is that from a technical perspective making an open standard should be a much easier task than making an AI that can understand what a human is asking for or drive a car safely or whatever we’re using them for this week. That’s not to say that technical
standards aren’t difficult to get right – they absolutely are! – but we’ve been practising doing it for many, many decades! The very existence of the Internet over which you’ve been
delivered this article is proof that computer interoperability is a solvable problem. For anybody who thinks that the interoperability brought about by the Internet was inevitable or
didn’t take lots of hard work, I direct you to Darius Kazemi’s re-reading of the early standards discussions, which I first plugged a year ago; but the important thing is that people were working on it. That’s something we’re not really seeing in the Internet of
Things space.
Engineers: “Standards are good. Let’s have lots of them.”
Everybody else: “…?”
On our current trajectory, it’s absolutely possible that our virtual assistants will reach a point of becoming perfectly “human” communicators long before we can reach agreements about
how they should communicate with one another. If that’s the case, those virtual assistants will probably fall back on using English-language voice communication as their lingua
franca. In that case, it’s not unbelievable that ten to twenty years from now, the following series of events might occur:
You want to go to your friends’ house, so you say out loud “Alexa, drive me to Bob’s house in five minutes.” Alexa responds “I’m on it; I’ll let you know more in a few
minutes.”
Alexa doesn’t know where Bob’s house is, but it knows it can get it from your netbook. It opens a voice channel over your wireless network (so you don’t have to “hear” it) and says
“Hey Google, it’s Alexa [and here’s my credentials]; can you give me the address that [your name] means when they say ‘Bob’s house’?” And your netbook responds by reading
out the address details, which Alexa then understands.
Alexa doesn’t know where your self-driving car is right now and whether anybody’s using it, but it has a voice control system and a cellular network connection, so Alexa phones
up your car and says: “Hey SmartCar, it’s Alexa [and here’s my credentials]; where are you and when were you last used?”. The car replies “I’m on the driveway, I’m
fully-charged, and I was last used three hours ago by [your name].” So Alexa says “Okay, boot up, turn on climate control, and prepare to make a journey to [Bob’s
address].” In this future world, most voice communication over telephones is done by robots: your virtual assistant calls your doctor’s virtual assistant to make you an
appointment, and you and your doctor just get events in your calendars, for example, because nobody manages to come up with a universal API for medical appointments.
Alexa responds “Okay, your SmartCar is ready to take you to Bob’s house.” And you have no idea about the conversations that your robots have been having behind your back
I’m not saying that this is a desirable state of affairs. I’m not even convinced that it’s likely. But it’s certainly possible if IoT development keeps focussing on shiny friendly conversational interfaces at the expense of practical, powerful technical standards. Our already
topsy-turvy technologies might get weirder before they get saner.
But if English does become the “universal API” for robot-to-robot communication, despite all engineering common
sense, I suggest that we call it “sandwichware”.
Update 23 November 2022: This isn’t how I consume The Far Side in my RSS reader any more. There’s an updated guide.
Prior to his retirement in 1995 I managed to amass a collection of almost all of Gary Larson’s The Far Side books as well as a couple of calendars and other thingamabobs. After
24 years of silence I didn’t expect to hear anything more from him and so I was as surprised as most of the Internet was when he re-emerged last yearwith a brand new on his
first ever website. Woah.
Larson’s hinted that there might be new and original content there someday, but for the time being I’m just loving that I can read The Far Side comments (legitimately) via the
Web for the first time! The site’s currently publishing a “Daily Dose” of classic strips, which is awesome. But… I don’t want to have to go to a website to get comics every
day. Nor do I want to have to remember which days I’ve caught-up with, yet. That’s a job for computers, right? And it’s a solved problem: RSS (which has been around for almost as long as Larson hasn’t) and similar technologies allow a website to publicise that it’s got updates
available in a way that people can “subscribe” to, so I should just use that, right?
Except… the new The Far Side website doesn’t have an RSS feed. Boo! Luckily, I’m not above automating the creation of feeds for websites that I wish had them, even (or
perhaps especially) where that involves a little reverse-engineering of online comics. So with a
little thanks to my RSS middleware RSSey… I can now read daily The Far
Side comics in the way that’s most-convenient to me: right alongside my other subscriptions in my feed reader.
How screen scrapers are made.
I’m afraid I’m not going to publicly1-share a ready-to-go feed URL for this one, unlike my BBC News Without The Sport
feed, because a necessary side-effect of the way it works is that the ads are removed. And if I were to republish a feed containing The Far Side website cartoons but with
the ads stripped I’d be guilty of, like, all the ethical and legal faults that Larson was trying to mitigate by putting his new website up in the first place! I love The
Far Side and I certainly don’t want to violate its copyright!
But – at least until Larson’s web developer puts up a proper feed (with or without ads) – for those of us who like our comics delivered fresh to us every morning, here’s the source code (as an RSSey feed definition) you
could use to run your own personal-use-only “give me The Far Side Daily Dose as an RSS feed” middleware.
Thanks for deciding to join us on the Internet, Gary. I hear it’s going to be a big thing, someday!
Footnotes
1 Friends are welcome to contact me off-blog for an address if they like, if they promise
to be nice and ethical about it.
Since I reported last summer that I’d accepted a job offer with Automattic I’ve
been writing about my experience of joining and working with Automattic on a nice, round 128-day schedule.
My first post covered the first 128 days: starting from the day I decided (after 15 years of
watching-from-afar) that I should apply to work there through to 51 days before my start date. It described my recruitment process, which is famously comprehensive and intensive. For me
this alone was hugely broadening! My first post spanned the period up until I started getting access to Automattic’s internal systems, a month and a half before my start date. If you’re
interested in my experience of recruitment at Automattic, you should go and read that post. This post, though, focusses on my induction,
onboarding, and work during my first two months.
I could possibly do with a little more desk space, or at least a little better desk arrangement, after the house move.
With a month to go before I started, I thought it time to start setting up my new “office” for my teleworking. Automattic offered to buy me a new desk and chair, but I’m not ready to
take them up on that yet: but I’m waiting until after my (hopefully-)upcoming house move so I know how much space I’ve got to work with/what I need! There’s still plenty for a new
developer to do, though: plugging in and testing my new laptop, monitor, and accessories, and doing all of the opinionated tweaks that make one’s digital environment one’s own –
preferred text editor, browser, plugins, shell, tab width, mouse sensitivity, cursor blink rate… important stuff like that.
For me, this was the cause of the first of many learning experiences, because nowadays I’m working on a MacBook! Automattic doesn’t
require you to use a Mac, but a large proportion of the company does and I figured that learning to use a Mac effectively would be easier than learning my new codebase on a
different architecture than most of my colleagues.
Working on location, showing some Automattic pride. You can’t really make out my WordPress “Christmas jumper”, hanging on the back of the sofa, but I promise that’s what it is.
I’ve owned a couple of Intel Macs (and a couple of Hackintoshes) but I’ve never gotten on with them well enough to warrant
becoming an advanced user, until now. I’ll probably write in the future about my experience of making serious use of a Mac after a history of mostly *nix and Windows machines.
Automattic also encouraged me to kit myself up with a stack of freebies to show off my affiliation, so I’ve got a wardrobe-load of new t-shirts and stickers too. It’s hard to argue that
we’re a company and not a cult when we’re all dressed alike, and that’s not even mentioning a colleague of mine with two WordPress-related tattoos, but there we have it.
Totally not a cult. Now let me have another swig of Kool-Aid…
Role and Company
I should take a moment to say what I do. The very simple version, which I came up with to very briefly describe my new job to JTA‘s mother, is: I write software that powers an online shop that sells software that powers online shops.
It’s eCommerce all the way down. Thanks, Xzibit.
You want the long version? I’m a Code Magician (you may say it’s a silly job title,
I say it’s beautiful… but I don’t necessarily disagree that it’s silly too) with Team Alpha at Automattic. We’re the engineering team behind WooCommerce.com, which provides downloads of the Web’s most-popular eCommerce platform… plus hundreds of
free and premium extensions.
There’s a lot of stuff I’d love to tell you about my role and my new employer, but there’s enough to say here about my induction so I’ll be saving following topics for a future
post:
Chaos: how Automattic produces order out of entropy, seemingly against all odds,
Transparency and communication: what it’s like to work in an environment of radical communication and a focus on transparency,
People and culture: my co-workers, our distributed team, and what is lost by not being able to “meet around the coffee machine” (and how we work to artificially
recreate that kind of experience),
Distributed working: this is my second foray into a nearly-100% remote-working environment; how’s it different to before?
To be continued, then.
I’m not the only member of my family to benefit from a free t-shirt.
Onboarding (days 1 through 12)
I wasn’t sure how my onboarding at Automattic could compare to that which I got when I started at the Bodleian. There, my then-line manager Alison‘s obsession with preparation had me arrive to a
thoroughly-planned breakdown of everything I needed to know and everybody I needed to meet over the course of my first few weeks. That’s not necessarily a bad thing, but it
leaves little breathing room in an already intense period!
What it felt like to receive an induction from the first boss I had at the Bod.
By comparison, my induction at Automattic was far more self-guided: each day in my first fortnight saw me tackling an agenda of things to work on and – in a pleasing touch I’ve seen
nowhere else – a list of expectations resulting from that day. Defined expectations day-by-day are an especially good as a tool for gauging one’s progress and it’s a nice touch that
I’ll be adapting should I ever have to write another induction plan for a somebody else.
Both an agenda and a list of expectations for the day? That’s awesome and intimidating in equal measure.
Skipping the usual induction topics of where the fire escapes and toilets are (it’s your house; you tell us!), how to dial an outside line (yeah, we don’t really do that here),
what to do to get a key to the bike shed and so on saves time, of course! But it also removes an avenue for more-casual interpersonal contact (“So how long’ve you been working here?”)
and ad-hoc learning (“So I use that login on this system, right?”). Automattic’s aware of this and has an entire culture about making information accessible, but it
takes additional work on the part of a new hire to proactively seek out the answers they need, when they need them: searching the relevant resources, or else finding out who to ask… and
being sure to check their timezone before expecting an immediate response.
Onboarding at Automattic is necessarily at least somewhat self-driven, and it’s clear in hindsight that the recruitment process is geared towards selection of individuals who can work
in this way because it’s an essential part of how we work in general. I appreciated the freedom to carve my own path as I learned the ropes, but it took me a little while to
get over my initial intimidation about pinging a stranger to ask for a video/voice chat to talk through something!
Meetup (days 14 through 21)
How cool is South African currency? This note’s got a lion on it!
I’d tried to arrange my migration to Automattic to occur just before their 2019 Grand Meetup, when virtually the entire company gets together in one place for an infrequent but important gathering, but I couldn’t make it work and just barely missed it. Luckily, though, my team had
planned a smaller get-together in South Africa which coincided with my second/third week, so I jetted off to get some
facetime with my colleagues.
When they say that Automatticians can work from anywhere, there might nonetheless be practical limits.
My colleague and fellow newbie Berislav‘s contract started a few hours after he landed in Cape Town, and it was helpful to my
journey to see how far I’d come over the last fortnight through his eyes! He was, after all, on the same adventure as me, only a couple of weeks behind, and it was reassuring
to see that I’d already learned so much as well as to be able to join in with helping him get up-to-speed, too.
The meetup wasn’t all work. I also got to meet penguins and get attacked by one of the little buggers.
By the time I left the meetup I’d learned as much again as I had in the two weeks prior about my new role and my place in the team. I’d also
learned that I’m pretty terrible at surfing, but luckily that’s not among the skills I have to master in order to become a valuable
developer to Automattic.
Happiness Rotation (days 23 through 35)
A quirk of Automattic – and indeed something that attracted me to them, philosophically – is that everybody spends two weeks early in their first year and a week in every subsequent
year working on the Happiness Team. Happiness at Automattic is what almost any other company would call “tech support”, because Automattic’s full of job titles and team names that are,
frankly, a bit silly flipping awesome. I like this “Happiness Rotation” as a concept because it keeps the entire company focussed on customer issues and the things that
really matter at the coal face. It also fosters a broader understanding of our products and how they’re used in the real world, which is particularly valuable to us developers who can
otherwise sometimes forget that the things we produce have to be usable by real people with real needs!
Once I’d gotten the hang of answering tickets I got to try my hand at Live Chat, which was a whole new level of terrifying.
One of the things that made my Happiness Rotation the hardest was also one of the things that made it the most-rewarding: that I didn’t really know most of the products I was
supporting! This was a valuable experience because I was able to learn as-I-went-along, working alongside my (amazingly supportive and understanding) Happiness Team co-workers: the
people who do this stuff all the time. But simultaneously, it was immensely challenging! My background in WordPress in general, plenty of tech support practice at Three Rings, and even my experience of email support at Samaritans put me in a strong position in-general…
but I found that I could very-quickly find myself out of my depth when helping somebody with the nitty-gritty of a problem with a specific WooCommerce extension.
Portering and getting DRI (days 60 through 67)
I’ve also had the opportunity during my brief time so far with Automattic to take on a few extra responsibilities within my team. My team rotates weekly responsibility for what they
call the Porter role. The Porter is responsible for triaging pull requests and monitoring blocking issues and acting as a first point-of-call to stakeholders: you know, the
stuff that’s important for developer velocity but that few developers want to do all the time. Starting to find my feet in my team by now, I made it my mission during my first
shift as Porter to get my team to experiment with an approach for keeping momentum on long-running issues, with moderate success (as a proper continuous-integration shop, velocity is
important and measurable). It’s pleased me so far to feel like I’m part of a team where my opinion matters, even though I’m “the new guy”.
“Here, I found these things we need to be working on.” Pretty much how I see the Porter role.
I also took on my first project as a Directly Responsible Individual, which is our fancy term for the person who makes sure the project runs to schedule, reports on progress etc.
Because Automattic more strongly than any other place I’ve ever worked subscribes to a dogfooding strategy, the
woocommerce.com online store for which I share responsibility runs on – you guessed it – WooCommerce! And so the first project for which I’m directly responsible is the upgrade of woocommerce.com to the latest version of
WooCommerce, which went into beta last month. Fingers crossed for a smooth deployment.
There’s so much I’d love to say about Automattic’s culture, approach to development, people, products, philosophy, and creed, but that’ll
have to wait for another time. For now, suffice to say that I’m enjoying this exciting and challenging new environment and I’m looking forward to reporting on them in another 128 days
or so.
This is part of a series of posts on computer terminology whose popular meaning – determined by surveying my friends – has significantly
diverged from its original/technical one. Read more evolving words…
Anticipatory note: based on the traffic I already get to my blog and the keywords people search for, I imagine that some people will end up here looking to
learn “how to become a hacker”. If that’s your goal, you’re probably already asking the wrong question, but I direct you to Eric S. Raymond’s Guide/FAQ on the subject. Good luck.
Few words have seen such mutation of meaning over their lifetimes as the word “silly”. The earliest references, found in Old English, Proto-Germanic, and Old Norse and presumably having
an original root even earlier, meant “happy”. By the end of the 12th century it meant “pious”; by the end of the 13th, “pitiable” or “weak”; only by the late 16th coming to mean
“foolish”; its evolution continues in the present day.
The Monty Python crew were certainly the experts on the contemporary use of the word.
But there’s little so silly as the media-driven evolution of the word “hacker” into something that’s at least a little offensive those of us who probably would be
described as hackers. Let’s take a look.
Hacker
What people think it means
Computer criminal with access to either knowledge or tools which are (or should be) illegal.
What it originally meant
Expert, creative computer programmer; often politically inclined towards information transparency, egalitarianism, anti-authoritarianism, anarchy, and/or decentralisation of
power.
The Past
The earliest recorded uses of the word “hack” had a meaning that is unchanged to this day: to chop or cut, as you might describe hacking down an unruly bramble. There are clear links
between this and the contemporary definition, “to plod away at a repetitive task”. However, it’s less certain how the word came to be associated with the meaning it would come to take
on in the computer labs of 1960s university campuses (the earliest references seem to come from
around April 1955).
There, the word hacker came to describe computer experts who were developing a culture of:
sharing computer resources and code (even to the extent, in extreme
cases, breaking into systems to establish more equal opportunity of access),
learning everything possible about humankind’s new digital frontiers (hacking to learn, not learning to hack)
discovering and advancing the limits of computers: it’s been said that the difference between a non-hacker and a hacker is that a non-hacker asks of a new gadget “what does it do?”,
while a hacker asks “what can I make it do?”
What the media generally refers to as “hackers” would be more-accurately, within the hacker community, be called crackers; a subset of security hackers, in turn a subset of
hackers as a whole. Script kiddies – people who use hacking tools exclusively for mischief without fully understanding what they’re doing – are a separate subset on their own.
It is absolutely possible for hacking, then, to involve no lawbreaking whatsoever. Plenty of hacking involves writing (and sharing) code, reverse-engineering technology and systems you
own or to which you have legitimate access, and pushing the boundaries of what’s possible in terms of software, art, and human-computer interaction. Even among hackers with a specific
interest in computer security, there’s plenty of scope for the legal pursuit of their interests: penetration testing, security research, defensive security, auditing, vulnerability
assessment, developer education… (I didn’t say cyberwarfare because 90% of its
application is of questionable legality, but it is of course a big growth area.)
Hackers have a serious image problem, and the best way to see it is to search on your favourite stock photo
site for “hacker”. If you don’t use a laptop in a darkened room, wearing a hoodie and optionally mask and gloves, you’re not a real hacker. Also, 50% of all text should be
green, 40% blue, 10% red.
So what changed? Hackers got famous, and not for the best reasons. A big tipping point came in the early 1980s when hacking group The
414s broke into a number of high-profile computer systems, mostly by using the default password which had never been changed. The six teenagers responsible were arrested by the
FBI but few were charged, and those that were were charged only with minor offences. This was at least in part because
there weren’t yet solid laws under which to prosecute them but also because they were cooperative, apologetic, and for the most part hadn’t caused any real harm. Mostly they’d just been
curious about what they could get access to, and were interested in exploring the systems to which they’d logged-in, and seeing how long they could remain there undetected. These remain
common motivations for many hackers to this day.
Hoodie: check. Face-concealing mask: check. Green/blue code: check. Is I a l33t hacker yet?
News media though – after being excited by “hacker” ideas introduced by WarGames – rightly realised that a hacker with the
same elementary resources as these teens but with malicious intent could cause significant real-world damage. Bruce
Schneier argued last year that the danger of this may be higher today than ever before. The press ran news stories strongly associating the word “hacker” specifically with the focus
on the illegal activities in which some hackers engage. The release of Neuromancer the following year, coupled
with an increasing awareness of and organisation by hacker groups and a number of arrests on both sides of the Atlantic only fuelled things further. By the end of the decade it was
essentially impossible for a layperson to see the word “hacker” in anything other than a negative light. Counter-arguments like The
Conscience of a Hacker (Hacker’s Manifesto) didn’t reach remotely the same audiences: and even if they had, the points they made remain hard to sympathise with for those outside of
hacker communities.
‘Nuff said.
A lack of understanding about what hackers did and what motivated them made them seem mysterious and otherworldly. People came to make the same assumptions about hackers that
they do about magicians – that their abilities are the result of being privy to tightly-guarded knowledge rather than years of practice – and this
elevated them to a mythical level of threat. By the time that Kevin Mitnick was jailed in the mid-1990s, prosecutors were able to successfully persuade a judge that this “most dangerous
hacker in the world” must be kept in solitary confinement and with no access
to telephones to ensure that he couldn’t, for example, “start a nuclear war by whistling into a pay phone”. Yes, really.
Whistling into a phone to start a nuclear war? That makes CSI: Cyber seem realistic [watch].
The Future
Every decade’s hackers have debated whether or not the next decade’s have correctly interpreted their idea of “hacker ethics”. For me, Steven Levy’s tenets encompass them best:
Access to computers – and anything which might teach you something about the way the world works – should be unlimited and total.
All information should be free.
Mistrust authority – promote decentralization.
Hackers should be judged by their hacking, not bogus criteria such as degrees, age, race, or position.
You can create art and beauty on a computer.
Computers can change your life for the better.
Given these concepts as representative of hacker ethics, I’m convinced that hacking remains alive and well today. Hackers continue to be responsible for many of the coolest and
most-important innovations in computing, and are likely to continue to do so. Unlike many other sciences, where progress over the ages has gradually pushed innovators away from
backrooms and garages and into labs to take advantage of increasingly-precise generations of equipment, the tools of computer science are increasingly available to individuals.
More than ever before, bedroom-based hackers are able to get started on their journey with nothing more than a basic laptop or desktop computer and a stack of freely-available
open-source software and documentation. That progress may be threatened by the growth in popularity of easy-to-use (but highly locked-down) tablets and smartphones, but the barrier to
entry is still low enough that most people can pass it, and the new generation of ultra-lightweight computers like the Raspberry Pi are doing
their part to inspire the next generation of hackers, too.
That said, and as much as I personally love and identify with the term “hacker”, the hacker community has never been less in-need of this overarching label. The diverse variety
of types of technologist nowadays coupled with the infiltration of pop culture by geek culture has inevitably diluted only to be replaced with a multitude of others each describing a
narrow but understandable part of the hacker mindset. You can describe yourself today as a coder, gamer, maker, biohacker, upcycler,cracker, blogger, reverse-engineer, social engineer, unconferencer, or one of dozens of other terms that more-specifically ties you to your
community. You’ll be understood and you’ll be elegantly sidestepping the implications of criminality associated with the word “hacker”.
The original meaning of “hacker” has also been soiled from within its community: its biggest and perhaps most-famous
advocate‘s insistence upon linguistic prescriptivism came under fire just this year after he pushed for a dogmatic interpretation of the term “sexual assault” in spite of a victim’s experience.
This seems to be absolutely representative of his general attitudes towards sex, consent,
women, and appropriate professional relationships. Perhaps distancing ourselves from the old definition of the word “hacker” can go hand-in-hand with distancing ourselves from some of
the toxicity in the field of computer science?
(I’m aware that I linked at the top of this blog post to the venerable but also-problematic Eric S. Raymond; if anybody can suggest an equivalent resource by another
author I’d love to swap out the link.)
Verdict: The word “hacker” has become so broad in scope that we’ll never be able to rein it back in. It’s tainted by its associations with both criminality, on one
side, and unpleasant individuals on the other, and it’s time to accept that the popular contemporary meaning has won. Let’s find new words to define ourselves, instead.
This is part of a series of posts on computer terminology whose popular meaning – determined by surveying my friends – has significantly
diverged from its original/technical one. Read more evolving words…
The language we use is always changing, like how the word “cute” was originally a truncation of the word “acute”, which you’d use to describe somebody who was sharp-witted, as in “don’t
get cute with me”. Nowadays, we use it when describing adorable things, like the subject of this GIF:
Cute, but not acute.
But hang on a minute: that’s another word that’s changed meaning: GIF. Want to see how?
GIF
What people think it means
File format (or the files themselves) designed for animations and transparency. Or: any animation without sound.
What it originally meant
File format designed for efficient colour images. Animation was secondary; transparency was an afterthought.
The Past
Back in the 1980s cyberspace was in its infancy. Sir Tim hadn’t yet dreamed up the Web, and the Internet wasn’t something that most
people could connect to, and bulletin board systems (BBSes) –
dial-up services, often local or regional, sometimes connected to one another in one of a variety of ways – dominated the scene. Larger services like CompuServe acted a little like huge
BBSes but with dial-up nodes in multiple countries, helping to bridge the international gaps and provide a lower learning curve
than the smaller boards (albeit for a hefty monthly fee in addition to the costs of the calls). These services would later go on to double as, and eventually become
exclusively, Internet Service Providers, but for the time being they were a force unto themselves.
My favourite bit of this 1983 magazine ad for CompuServe is the fact that it claims a trademark on the word “email”. They didn’t try very hard to cling on to that claim, unlike their
controversial patent on the GIF format…
In 1987, CompuServe were about to start rolling out colour graphics as a new feature, but needed a new graphics format to support that. Their engineer Steve Wilhite had the
idea for a bitmap image format backed by LZW compression
and called it GIF, for Graphics Interchange Format. Each image could be composed of multiple frames each having up to 256
distinct colours (hence the common mistaken belief that a GIF can only have 256 colours). The nature of the palette system
and compression algorithm made GIF a particularly efficient format for (still) images with solid contiguous blocks of
colour, like logos and diagrams, but generally underperformed against cosine-transfer-based algorithms like
JPEG/JFIF for images with gradients (like most
photos).
This animated GIF (of course) shows how it’s possible to have more than 256 colours in a GIF by separating it into multiple non-temporal frames.
GIF would go on to become most famous for two things, neither of which it was capable of upon its initial release: binary
transparency (having “see through” bits, which made it an excellent choice for use on Web pages with background images or non-static background colours; these would become popular in
the mid-1990s) and animation. Animation involves adding a series of frames which overlay one another in sequence: extensions to the format in 1989 allowed the creator to specify the
duration of each frame, making the feature useful (prior to this, they would be displayed as fast as they could be downloaded and interpreted!). In 1995, Netscape added a custom extension to GIF to allow them to
loop (either a specified number of times or indefinitely) and this proved so popular that virtually all other software followed suit, but it’s worth noting that “looping” GIFs have never been part of the official standard!
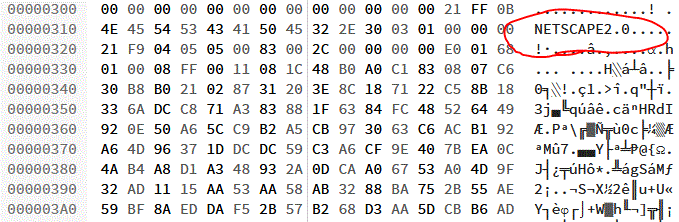
Open almost any animated GIF file in a hex editor and you’ll see the word NETSCAPE2.0; evidence of
Netscape’s role in making animated GIFs what they are today.
Compatibility was an issue. For a period during the mid-nineties it was quite possible that among the visitors to your website there would be a mixture of:
people who wouldn’t see your GIFs at all, owing to browser, bandwidth, preference, or accessibility limitations,
people who would only see the first frame of your animated GIFs, because their browser didn’t support animation,
people who would see your animation play once, because their browser didn’t support looping, and
people who would see your GIFs as you intended, fully looping
This made it hard to depend upon GIFs without carefully considering their use. But people still did, and they just stuck a
button on to warn people, as if that made up for it. All of this has happened before, etc.
In any case: as better, newer standards like PNG came to dominate the Web’s need for lossless static (optionally
transparent) image transmission, the only thing GIFs remained good for was animation. Standards like APNG/MNG failed to get off the ground, and so GIFs remained the dominant animated-image standard. As Internet connections became faster and faster in the 2000s, they experienced a
resurgence in popularity. The Web didn’t yet have the <video> element and so embedding videos on pages required a mixture of at least two of
<object>, <embed>, Flash, and black magic… but animated GIFs just worked and
soon appeared everywhere.
How animation online really works.
The Future
Nowadays, when people talk about GIFs, they often don’t actually mean GIFs! If you see a GIF on Giphy or WhatsApp, you’re probably actually seeing an MPEG-4 video file with no audio track! Now that Web video
is widely-supported, service providers know that they can save on bandwidth by delivering you actual videos even when you expect a GIF. More than ever before, GIF has become a byword for short, often-looping Internet
animations without sound… even though that’s got little to do with the underlying file format that the name implies.
What’s a web page? What’s anything?
Verdict: We still can’t agree on whether to pronounce it with a soft-G (“jif”), as Wilhite intended, or with a hard-G, as any sane person would, but it seems that GIFs are here to stay
in name even if not in form. And that’s okay. I guess.
This is part of a series of posts on computer terminology whose popular meaning – determined by surveying my friends – has significantly
diverged from its original/technical one. Read more evolving words…
Until the 17th century, to “fathom” something was to embrace it. Nowadays, it’s more likely to refer to your understanding of something in depth. The migration came via the
similarly-named imperial unit of measurement, which was originally defined as the span of a man’s outstretched arms, so you can
understand how we got from one to the other. But you know what I can’t fathom? Broadband.
I can’t fathom dalmatians. But this woman can.
Broadband Internet access has become almost ubiquitous over the last decade and a half, but ask people to define “broadband” and they have a very specific idea about what it means. It’s
not the technical definition, and this re-invention of the word can cause problems.
Broadband
What people think it means
High-speed, always-on Internet access.
What it originally meant
Communications channel capable of multiple different traffic types simultaneously.
The Past
Throughout the 19th century, optical (semaphore) telegraph networks gave way to the new-fangled electrical telegraph, which not only worked regardless of the weather but resulted in
significantly faster transmission. “Faster” here means two distinct things: latency – how long it takes a message to reach its destination, and bandwidth – how much
information can be transmitted at once. If you’re having difficulty understanding the difference, consider this: a man on a horse might be faster than a telegraph if the size of the
message is big enough because a backpack full of scrolls has greater bandwidth than a Morse code pedal, but the latency of an electrical wire beats land transport
every time. Or as Andrew S. Tanenbaum famously put it: Never underestimate the bandwidth of a station wagon full of
tapes hurtling down the highway.
There were transitional periods. This man, photographed in 1912, is relaying a telephone message into a heliograph. I’m not sure
what message he’s transmitting, but I’m guessing it ends with a hashtag.
Telegraph companies were keen to be able to increase their bandwidth – that is, to get more messages on the wire – and this was achieved by multiplexing. The simplest approach,
time-division multiplexing, involves messages (or parts of messages) “taking turns”, and doesn’t actually increase bandwidth at all: although it does improve the perception of
speed by giving recipients the start of their messages early on. A variety of other multiplexing techniques were (and continue to be) explored, but the one that’s most-interesting to us
right now was called acoustic telegraphy: today, we’d call it frequency-division multiplexing.
What if, asked folks-you’ll-have-heard-of like Thomas Edison and Alexander Graham Bell, we were to send telegraph messages down the line at different frequencies. Some beeps and bips
would be high tones, and some would be low tones, and a machine at the receiving end could separate them out again (so long as you chose your frequencies carefully, to avoid harmonic
distortion). As might be clear from the names I dropped earlier, this approach – sending sound down a telegraph wire – ultimately led to the invention of the
telephone. Hurrah, I’m sure they all immediately called one another to say, our efforts to create a higher-bandwidth medium for telegrams has accidentally resulted in a
lower-bandwidth (but more-convenient!) way for people to communicate. Job’s a good ‘un.
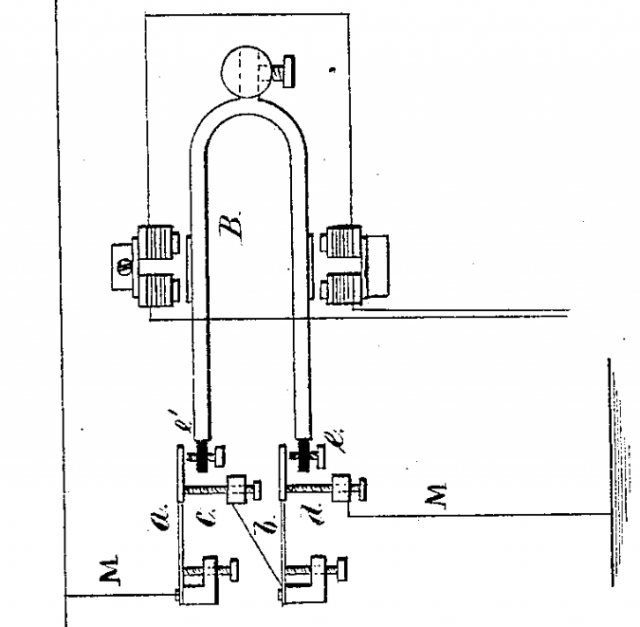
If this part of Edison’s 1878 patent looks like a tuning fork, that’s not a coincidence. These early multiplexers made distinct humming sounds as they operated, owing to the movement
of the synchronised forks within.
Most electronic communications systems that have ever existed have been narrowband: they’ve been capable of only a single kind of transmission at a time. Even if you’re
multiplexing a dozen different frequencies to carry a dozen different telegraph messages at once, you’re still only transmitting telegraph messages. For the most part, that’s
fine: we’re pretty clever and we can find workarounds when we need them. For example, when we started wanting to be able to send data to one another (because computers are cool now)
over telephone wires (which are conveniently everywhere), we did so by teaching our computers to make sounds and understand one another’s sounds. If you’re old enough to have heard
a fax machine call a landline or, better yet used a dial-up modem, you know what I’m talking about.
As the Internet became more and more critical to business and home life, and the limitations (of bandwidth and convenience) of dial-up access became increasingly questionable,
a better solution was needed. Bringing broadband to Internet access was necessary, but the technologies involved weren’t revolutionary: they were just the result of the application of a
little imagination.
I’ve felt your pain, Dawson. I’ve felt your pain.
We’d seen this kind of imagination before. Consider teletext, for example (for those of you too young to remember teletext, it was a
standard for browsing pages of text and simple graphics using an 70s-90s analogue television), which is – strictly speaking – a broadband technology. Teletext works by embedding pages
of digital data, encoded in an analogue stream, in the otherwise-“wasted” space in-between frames of broadcast video. When you told your television to show you a particular page, either
by entering its three-digit number or by following one of four colour-coded hyperlinks, your television would wait until the page you were looking for came around again in the
broadcast stream, decode it, and show it to you.
Teletext was, fundamentally, broadband. In addition to carrying television pictures and audio, the same radio wave was being used to transmit text: not pictures of text, but
encoded characters. Analogue subtitles (which used basically the same technology): also broadband. Broadband doesn’t have to mean “Internet access”, and indeed for much of its history,
it hasn’t.
My family started getting our news via broadband in about 1985. Not broadband Internet, but broadband nonetheless.
Here in the UK, ISDN (from 1988!) and later ADSL would be the first widespread technologies to provide broadband data connections over the copper wires simultaneously used to
carry telephone calls. ADSL does this in basically the same way as Edison and Bell’s acoustic telegraphy: a portion
of the available frequencies (usually the first 4MHz) is reserved for telephone calls, followed by a no-mans-land band, followed by two frequency bands of different sizes (hence the
asymmetry: the A in ADSL) for up- and downstream data. This, at last, allowed true “broadband Internet”.
But was it fast? Well, relative to dial-up, certainly… but the essential nature of broadband technologies is that they share the bandwidth with other services. A connection
that doesn’t have to share will always have more bandwidth, all other things being equal! Leased lines, despite
technically being a narrowband technology, necessarily outperform broadband connections having the same total bandwidth because they don’t have to share it with other services. And
don’t forget that not all speed is created equal: satellite Internet access is a narrowband technology with excellent bandwidth… but sometimes-problematic latency issues!
Did you have one of these tucked behind your naughties router? This box filtered out the data from the telephone frequencies, helping to ensure that you can neither hear the pops and
clicks of your ADSL connection nor interfere with it by shouting.
Equating the word “broadband” with speed is based on a consumer-centric misunderstanding about what broadband is, because it’s necessarily true that if your home “broadband” weren’t
configured to be able to support old-fashioned telephone calls, it’d be (a) (slightly) faster, and (b) not-broadband.
The Future
But does the word that people use to refer to their high-speed Internet connection matter. More than you’d think: various countries around the world have begun to make legal
definitions of the word “broadband” based not on the technical meaning but on the populist one, and it’s becoming a source of friction. In the USA, the FCC variously defines broadband as having a minimum download speed of
10Mbps or 25Mbps, among other characteristics (they seem to use the former when protecting consumer rights and the latter when reporting on penetration, and you can read into that what
you will). In the UK, Ofcom‘s regulations differentiate between “decent” (yes, that’s really the word they use) and “superfast” broadband at
10Mbps and 24Mbps download speeds, respectively, while the Scottish and Welsh governments as well as the EU say it must be 30Mbps to be
“superfast broadband”.
At full-tilt, going from 10Mbps to 24Mbps means taking only 4 seconds, rather than 11 seconds, to download the music video to Faster! Harder! Scooter!
I’m all in favour of regulation that protects consumers and makes it easier for them to compare products. It’s a little messy that definitions vary so widely on what different speeds
mean, but that’s not the biggest problem. I don’t even mind that these agencies have all given themselves very little breathing room for the future: where do you go after “superfast”?
Ultrafast (actually, that’s exactly where we go)? Megafast? Ludicrous speed?
What I mind is the redefining of a useful term to differentiate whether a connection is shared with other services or not to be tied to a completely independent characteristic of that
connection. It’d have been simple for the FCC, for example, to have defined e.g. “full-speed broadband” as
providing a particular bandwidth.
Verdict: It’s not a big deal; I should just chill out. I’m probably going to have to throw in the towel anyway on this one and join the masses in calling all high-speed
Internet connections “broadband” and not using that word for all slower and non-Internet connections, regardless of how they’re set up.
This is part of a series of posts on computer terminology whose popular meaning – determined by surveying my friends – has significantly
diverged from its original/technical one. Read more evolving words…
A few hundred years ago, the words “awesome” and “awful” were synonyms. From their roots, you can see why: they mean “tending to or causing awe” and “full or or characterised by awe”,
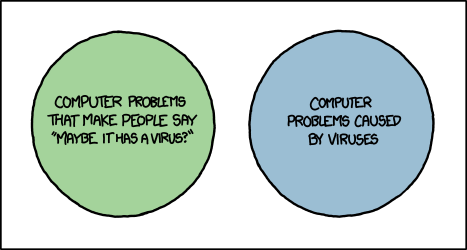
respectively. Nowadays, though, they’re opposites, and it’s pretty awesome to see how our language continues to evolve. You know what’s awful, though? Computer viruses. Right?
“Oh no! A virus has stolen all my selfies and uploaded them to a stock photos site!”
You know what I mean by a virus, right? A malicious computer program bent on causing destruction, spying on your online activity, encrypting your files and ransoming them back to you,
showing you unwanted ads, etc… but hang on: that’s not right at all…
Virus
What people think it means
Malicious or unwanted computer software designed to cause trouble/commit crimes.
What it originally meant
Computer software that hides its code inside programs and, when they’re run, copies itself into other programs.
The Past
Only a hundred and thirty years ago it was still widely believed that “bad air” was the principal cause of disease. The idea that tiny germs could be the cause of infection was only
just beginning to take hold. It was in this environment that the excellent scientist Ernest Hankin travelled around
India studying outbreaks of disease and promoting germ theory by demonstrating that boiling water prevented cholera by killing the (newly-discovered) vibrio cholerae bacterium.
But his most-important discovery was that water from a certain part of the Ganges seemed to be naturally inviable as a home for vibrio cholerae… and that boiling this
water removed this superpower, allowing the special water to begin to once again culture the bacterium.
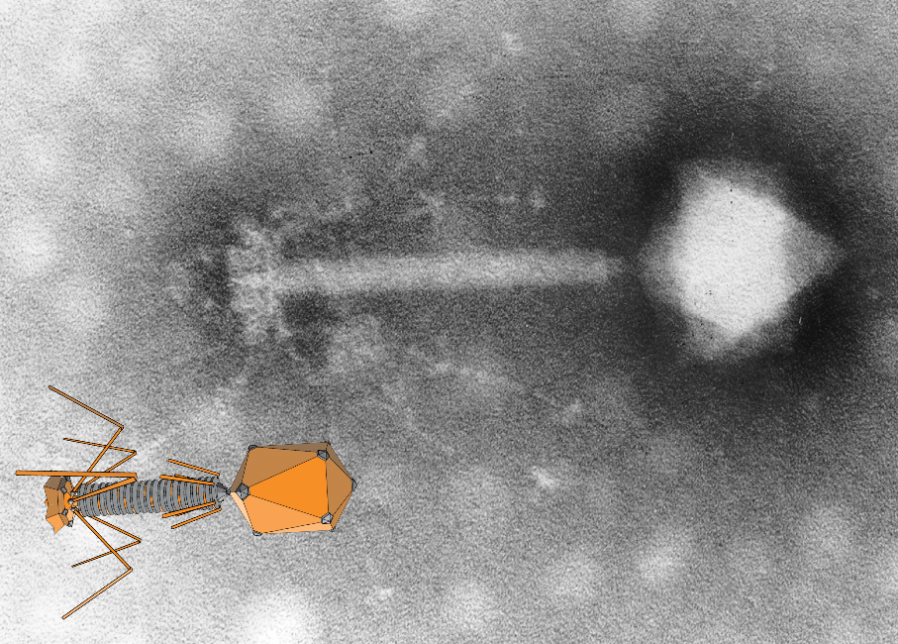
Hankin correctly theorised that there was something in that water that preyed upon vibrio cholerae; something too small to see with a microscope. In doing so, he was probably
the first person to identify what we now call a bacteriophage: the most common kind of virus. Bacteriophages were briefly seen as exciting for their medical potential. But then
in the 1940s antibiotics, which were seen as far more-convenient, began to be manufactured in bulk, and we stopped seriously looking at “phage therapy” (interestingly, phages are seeing a bit of a resurgence as antibiotic resistance becomes increasingly problematic).
It took until the development of the scanning electron microscope in the mid-20th century before we’d actually “see” a virus.
But the important discovery kicked-off by the early observations of Hankin and others was that viruses exist. Later, researchers would discover how these viruses
work1:
they inject their genetic material into cells, and this injected “code” supplants the unfortunate cell’s usual processes. The cell is “reprogrammed” – sometimes after a dormant
period – to churns out more of the virus, becoming a “virus factory”.
Let’s switch to computer science. Legendary mathematician John von Neumann, fresh from showing off his expertise in
calculating how shaped charges should be used to build the first atomic bombs, invented the new field of cellular autonoma. Cellular autonoma are computationally-logical,
independent entities that exhibit complex behaviour through their interactions, but if you’ve come across them before now it’s probably because you played Conway’s Game of Life, which made the concept popular decades after their invention. Von Neumann was very interested
in how ideas from biology could be applied to computer science, and is credited with being the first person to come up with the idea of a self-replicating computer program which would
write-out its own instructions to other parts of memory to be executed later: the concept of the first computer virus.
This is a glider factory… factory. I remember the first time I saw this pattern, in the 1980s, and it sank in for me that cellular autonoma must logically be capable of any
arbitrary level of complexity. I never built a factory-factory-factory, but I’ll bet that others have.
Retroactively-written lists of early computer viruses often identify 1971’s Creeper as the first computer virus:
it was a program which, when run, moved (later copied) itself to another computer on the network and showed the message “I’m the creeper: catch me if you can”. It was swiftly followed
by a similar program, Reaper, which replicated in a similar way but instead of displaying a message attempted to
delete any copies of Creeper that it found. However, Creeper and Reaper weren’t described as viruses at the time and would be more-accurately termed
worms nowadays: self-replicating network programs that don’t inject their code into other programs. An interesting thing to note about them, though, is that – contrary
to popular conception of a “virus” – neither intended to cause any harm: Creeper‘s entire payload was a relatively-harmless message, and Reaper actually tried to do
good by removing presumed-unwanted software.
Another early example that appears in so-called “virus timelines” came in 1975. ANIMAL presented as a twenty
questions-style guessing game. But while the user played it would try to copy itself into another user’s directory, spreading itself (we didn’t really do directory permissions back
then). Again, this wasn’t really a “virus” but would be better termed a trojan: a program which pretends to be something that it’s not.
“Malware? Me? No siree… nothing here but this big executable horse.”
It took until 1983 before Fred Cooper gave us a modern definition of a computer virus, one which – ignoring usage by laypeople –
stands to this day:
A program which can ‘infect’ other programs by modifying them to include a possibly evolved copy of itself… every program that gets infected may also act as a virus and thus the
infection grows.
This definition helps distinguish between merely self-replicating programs like those seen before and a new, theoretical class of programs that would modify host programs such
that – typically in addition to the host programs’ normal behaviour – further programs would be similarly modified. Not content with leaving this as a theoretical, Cooper wrote the
first “true” computer virus to demonstrate his work (it was never released into the wild): he also managed to prove that there can be no such thing as perfect virus detection.
(Quick side-note: I’m sure we’re all on the same page about the evolution of language here, but for the love of god don’t say viri. Certainly don’t say virii.
The correct plural is clearly viruses. The Latin root virus is a mass noun and so has no plural, unlike e.g.
fungus/fungi, and so its adoption into a count-noun in English represents the creation of a new word which should therefore, without a precedent to the
contrary, favour English pluralisation rules. A parallel would be bonus, which shares virus‘s linguistic path, word ending, and countability-in-Latin: you wouldn’t say
“there were end-of-year boni for everybody in my department”, would you? No. So don’t say viri either.)
No, no, no, no, no. The only wholly-accurate part of this definition is the word “program”.
Viruses came into their own as computers became standardised and commonplace and as communication between them (either by removable media or network/dial-up connections) and Cooper’s
theoretical concepts became very much real. In 1986, The Virdim method brought infectious viruses to the DOS platform, opening up virus writers’ access to much of the rapidly growing business and home computer markets.
The Virdim method has two parts: (a) appending the viral code to the end of the program to be infected, and (b) injecting early into the program a call to the appended code. This
exploits the typical layout of most DOS executable files and ensures that the viral code is run first, as an infected program
loads, and the virus can spread rapidly through a system. The appearance of this method at a time when hard drives were uncommon and so many programs would be run from floppy disks
(which could be easily passed around between users) enabled this kind of virus to spread rapidly.
For the most part, early viruses were not malicious. They usually only caused harm as a side-effect (as we’ve already seen, some – like Reaper – were intended to be not just
benign but benevolent). For example, programs might run slower if they’re also busy adding viral code to other programs, or a badly-implemented virus might
even cause software to crash. But it didn’t take long before viruses started to be used for malicious purposes – pranks, adware, spyware, data ransom, etc. – as well as to carry
political messages or to conduct cyberwarfare.
XKCD already explained all of this in far fewer words and a diagram.
The Future
Nowadays, though, viruses are becoming less-common. Wait, what?
Yup, you heard me right: new viruses aren’t being produced at remotely the same kind of rate as they were even in the 1990s. And it’s not that they’re easier for security software to
catch and quarantine; if anything, they’re less-detectable as more and more different types of file are nominally “executable” on a typical computer, and widespread access to
powerful cryptography has made it easier than ever for a virus to hide itself in the increasingly-sprawling binaries that litter modern computers.
Soo… I click this and all the viruses go away, right? Why didn’t we do this sooner?
The single biggest reason that virus writing is on the decline is, in my opinion, that writing something as complex as a a virus is longer a necessary step to illicitly getting your
program onto other people’s computers2!
Nowadays, it’s far easier to write a trojan (e.g. a fake Flash update, dodgy spam attachment, browser toolbar, or a viral free game) and trick people into running it… or else to write a
worm that exploits some weakness in an open network interface. Or, in a recent twist, to just add your code to a popular library and let overworked software engineers include it in
their projects for you. Modern operating systems make it easy to have your malware run every time they boot and it’ll quickly get lost amongst the noise of all the
other (hopefully-legitimate) programs running alongside it.
In short: there’s simply no need to have your code hide itself inside somebody else’s compiled program any more. Users will run your software anyway, and you often don’t even
have to work very hard to trick them into doing so.
Verdict: Let’s promote use of the word “malware” instead of “virus” for popular use. It’s more technically-accurate in the vast majority of cases, and it’s actually a
more-useful term too.
Footnotes
1 Actually, not all viruses work this way. (Biological) viruses are, it turns out, really
really complicated and we’re only just beginning to understand them. Computer viruses, though, we’ve got a solid understanding of.
2 There are other reasons, such as the increase in use of cryptographically-signed
binaries, protected memory space/”execute bits”, and so on, but the trend away from traditional viruses and towards trojans for delivery of malicious payloads began long before these
features became commonplace.
Eight years, six months, and one week after I started at the Bodleian, we’ve gone our separate ways. It’s genuinely been the nicest place I’ve
ever worked; the Communications team are a tightly-knit, supportive, caring bunch of diverse misfits and I love them all dearly, but the time had come for me to seek my next challenge.
My imminent departure began to feel real when I turned over my badge and gun card and keys.
Being awesome as they are, my team threw a going-away party for me, complete with food from Najar’s Place, about which I’d previously
raved as having Oxford’s best falafels. I wasn’t even aware that Najar’s place did corporate catering… actually, it’s possible that they don’t and this was just a (very)
special one-off.
Start from the left, work towards the right.
Following in the footsteps of recent team parties, they’d even gotten a suitably-printed cake with a picture of my face on it. Which meant that I could leave my former team with one
final magic trick, the never-before-seen feat of eating my own head (albeit in icing form).
Of course, the first thing I was asked to do was to put a knife through my own neck.
As the alcohol started to work, I announced an activity I’d planned: over the weeks prior I’d worked to complete but not cash-in reward cards at many of my favourite Oxford eateries and
cafes, and so I was now carrying a number of tokens for free burritos, coffees, ice creams, smoothies, pasta and more. Given that I now expect to spend much less of my time in the city
centre I’d decided to give these away to people who were able to answer challenge questions presented – where else? – on our digital signage
simulator.
Among the games was Play Your Shards Right, a game of “higher/lower” played across London’s skyscrapers.
I also received some wonderful going-away gifts, along with cards in which a few colleagues had replicated my long tradition of drawing cartoon animals in other people’s cards, by
providing me with a few in return.
“Wait… all of these Javascript frameworks look like they’re named after Pokémon!”
Later, across the road at the Kings’ Arms and with even more drinks inside of me, I broke out the lyrics I’d half-written to a rap song about my time at the
Bodleian. Because, as I said at the time, there’s nothing more-Oxford than a privileged white boy rapping about how much he’d loved his job at a library (video also available on QTube [with lyrics] and on Videopress).
It’s been an incredible 8½ years that I’ll always look back on with fondness. Don’t be strangers, guys!
My department’s made far too much use out of that “Sorry you’re leaving” banner, this year. Here’s hoping they get a stabler, simpler time next year.
Some years ago, a friend of mine told me about an interview they’d had for a junior programming position. Their interviewer was one of that particular breed who was attached to
programming-test questions: if you’re in the field of computer science, you already know that these questions exist. In any case: my friend was asked to write pseudocode to shuffle a
deck of cards: a classic programming problem that pretty much any first-year computer science undergraduate is likely to have considered, if not done.
Let’s play at writing software. Rather than a computer, we’ll use paper. But to make it sound techy, we’ll call it “pseudocode”.
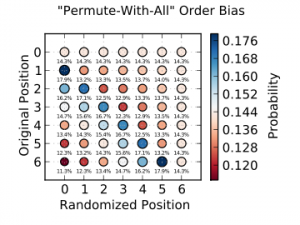
There are lots of wrong ways to programmatically shuffle a deck of cards, such as the classic “swap the card in each position with the card in a randomly-selected position”,
which results in biased
results. In fact, the more that you think in terms of how humans shuffle cards, the less-likely you are to come up with a good answer!
If we shuffled a deck of six cards with this ‘broken’ algorithm, for example, we’d be more-likely to find the card that was originally in second place at the top of the deck than in
any other position. This kind of thing REALLY matters if, for example, you’re running an online casino.
The simplest valid solution is to take a deck of cards and move each card, choosing each at random, into a fresh deck (you can do this as a human, if you like, but it takes a while)…
and that’s exactly what my friend suggested.
The interviewer was ready for this answer, though, and asked my friend if they could think of a “more-efficient” way to do the shuffle. And this is where my friend had a brain fart and
couldn’t think of one. That’s not a big problem in the real world: so long as you can conceive that there exists a more-efficient shuffle, know what to search for, and can
comprehend the explanation you get, then you can still be a perfectly awesome programmer. Demanding that people already know the answer to problems in an interview setting
doesn’t actually tell you anything about their qualities as a programmer, only how well they can memorise answers to stock interview questions (this interviewer should have stopped this
line of inquiry one question sooner).
Writing a program to shuffle a deck takes longer than just shuffling it, but that’s hardly the point, is it?
The interviewer was probably looking for an explanation of the modern form of the Fisher-Yates shuffle algorithm, which does the same thing as my friend suggested but without needing to start a
“separate” deck: here’s a video demonstrating it. When they asked for greater efficiency, the interviewer was probably looking
for a more memory-efficient solution. But that’s not what they said, and it’s certainly not the only way to measure efficiency.
When people ask ineffective interview questions, it annoys me a little. When people ask ineffective interview questions and phrase them ambiguously to boot, that’s just makes
me want to contrive a deliberately-awkward answer.
So: another way to answer the shuffling efficiency question would be to optimise for time-efficiency. If, like my friend, you get a question about improving the efficiency of a
shuffling algorithm and they don’t specify what kind of efficiency (and you’re feeling sarcastic), you’re likely to borrow either of the following algorithms. You won’t find
them any computer science textbook!
Complexity/time-efficiency optimised shuffling
Precompute and store an array of all 52! permutations of a deck of cards. I think you can store a permutation in no more than 226 bits, so I calculate that 2.3 quattuordecillion yottabytes would be plenty sufficient to store such an array. That’s
about 25 sexdecillion times more data than is believed to exist on the Web, so you’re going to need to upgrade your hard drive.
To shuffle a deck, simply select a random number x such that 0 <= x < 52! and retrieve the deck stored at that location.
This converts the O(n) problem that is Fisher-Yates to an O(1) problem, an entire complexity class of improvement.
Sure, you need storage space valued at a few hundred orders of magnitude greater than the world GDP, but if you didn’t specify cost-efficiency, then that’s not what you get.
If you’ve got a thousand galaxies worth of free space you can just fill them with
actual decks of cards – one for each permutation – and physically pick one at random. That sounds convenient, right?
You’re also going to need a really, really good PRNG to ensure that the 226-bit binary number you generate has sufficient entropy. You could always use a real
physical deck of cards to seed it, Solitaire/Pontifex-style, and go full meta, but I
worry that doing so might cause this particular simulation of the Universe to implode, sooo… do it at your own risk?
Perhaps we can do one better, if we’re willing to be a little sillier…
If you live in a universe in which quantum optimised shuffling isn’t possible, the technique below can be adapted to create a universe in which it is.
Assuming the many-worlds interpretation of quantum mechanics is applicable to reality, there’s a
yet-more-efficient way to shuffle a deck of cards, inspired by the excellent (and hilarious) quantum bogosort algorithm:
Create a superposition of all possible states of a deck of cards. This divides the universe into 52! universes; however, the division has no cost, as it happens constantly anyway.
Collapse the waveform by observing your shuffled deck of cards.
The unneeded universes can be destroyed or retained as you see fit.
Let me know if you manage to implement either of these.
For the last few months, I’ve been running an alpha test of an email-based subscription to DanQ.me with a handful of handpicked testers. Now, I’d like to open it up to a slightly larger
beta test group. If you’d like to get the latest from this site directly in your inbox, just provide your email address below:
Subscribe by email!
Who’s this for?
Some people prefer to use their email inbox to subscribe to things. If that’s you: great!
What will I receive?
You’ll get a “daily digest”, no more than once per day, summarising everything I’ve published within the last 24 hours. It usually works: occasionally
but not often it misses things. You can unsubscribe with one click at any time.
How else can I subscribe?
You can still subscribe in a variety of other ways. Personally, I recommend using a feed reader which lets you choose exactly which kinds of content
you’re interested in, but there are plenty of options including Facebook and Twitter (for those of such an inclination).
Didn’t you do this before?
Yes, I ran a “subscribe by email” system back in 2007 but didn’t maintain it. Things might be better this time around. Maybe.
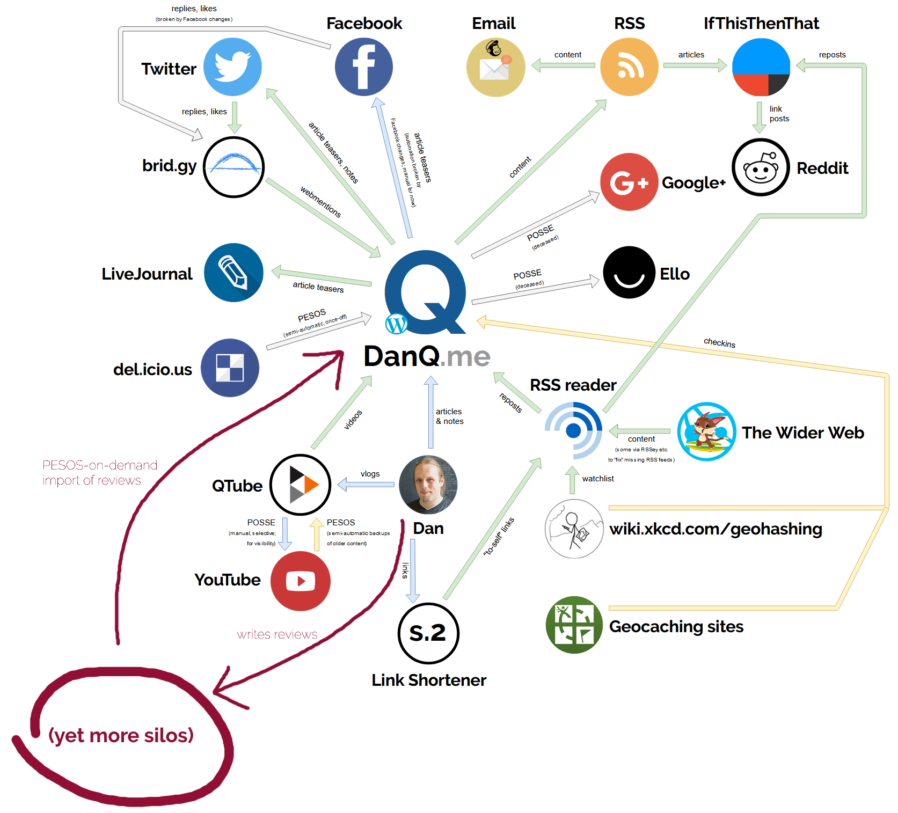
When I arrived at this weekend’s IndieWebCamp I still wasn’t sure what it was that I would be
working on. I’d worked recently to better understand the ecosystem surrounding DanQ.me and had a number of half-formed ideas about tightening
it up. But instead, I ended up expanding the reach of my “personal web” considerably by adding reviews as a post type to my site and building
tools to retroactively-reintegrate reviews I’d written on other silos.
The oldest surviving review I found was my grumbling about Windows XP Home edition being just a crippled version of Pro edition. And now it’s immortalised here.
Over the years, I’ve written reviews of products using Amazon and Steam and of places using Google Maps and TripAdvisor. These are silos and my
content there is out of my control and could, for example, be deleted at a moment’s notice. This risk was particularly fresh in my mind as my friend Jen‘s Twitter account was suspended this weekend for allegedly violating the platform’s rules
(though Twitter have so far proven unwilling to tell her which rules she’s broken or even when she did so, and she’s been left completely in the dark).
My mission for the weekend was to:
Come up with a mechanism for the (microformat-friendly) display of reviews on this site, and
Reintegrate my reviews from Amazon, Steam, Google Maps and TripAdvisor
Steam reviews use a “thumbs up/thumbs down” rating system rather than a “5-star” style, but h-review is capable of expressing both and more.
I opted not to set up an ongoing POSSE nor PESOS process at this point; I’ll do this manually in the short term (I don’t write reviews on third-party sites often). Also out of
scope were some other sites on which I’ve found that I’ve posted reviews, for example BoardGameGeek. These can both be tasks for a future date.
The lovely diagram I drew earlier this year? Here it is with the new loop drawn on.
I used Google Takeout to export my Google Maps reviews, which comprised the largest number of reviews of the sites I targetted and which is the
least screen-scraper friendly. I wrote a bookmarklet-based screen-scraper to get the contents of my reviews on each of the other sites. Meanwhile, I edited by WordPress theme’s functions.php to extended the Post Kinds plugin with an
extra type of post, Review, and designed a content template which wrapped reviews in appropriate microformat markup, using metadata attached to each review post to show e.g. a
rating, embed a h-product (for products) or h-card (for
places). I also leveraged my existing work from last summer’s effort to reintegrate my geo*ing logs to automatically
add a map when I review a “place”. Finally, I threw together a quick WordPress plugin to import the data and create a stack of draft posts for proofing and publication.
I was moderately unimpressed by Oxford pub The Rusty Bicycle. I originally said so on Google Maps, and now I can say so here, too!
So now you can read all of the reviews I’ve ever posted to any of those four sites, right here, alongside any other reviews I subsequently reintegrate and any
I write directly to my blog in the future. The battle to own all of my own content after 25 years of scattering it throughout the Internet isn’t always easy, but it remains worthwhile.
(I haven’t open-sourced my work this time because it’s probably useful only to me and my very-specific set-up, but if anybody wants a copy they can get in
touch.)
A long while ago, inspired by Nick Berry‘s analysis of optimal Hangman strategy, I worked it backwards to find the
hardest words to guess when playing Hangman. This week, I showed these to my colleague Grace – who turns out to be a fan of word puzzles – and our conversation inspired me to go a little deeper. Is it possible, I
thought, for me to make a Hangman game that cheats by changing the word it’s thinking of based on the guesses you make in order to make it as difficult as possible for you to
win?
The principle is this: every time the player picks a letter, but before declaring whether or not it’s found in the word –
Make a list of all possible words that would fit into the boxes from the current game state.
If there are lots of them, still, that’s fine: let the player’s guess go ahead.
But if the player’s managing to narrow down the possibilities, attempt to change the word that they’re trying to guess! The new word must be:
Legitimate: it must still be the same length, have correctly-guessed letters in the same places, and contain no letters that have been declared to be incorrect
guesses.
Harder: after resolving the player’s current guess, the number of possible words must be larger than the number of possible words that would have
resulted otherwise.
Yeah, you’re screwed now.
You might think that this strategy would just involve changing the target word so that you can say “nope” to the player’s current guess. That happens a lot, but it’s not always the
case: sometimes, it’ll mean changing to a different word in which the guessed letter also appears. Occasionally, it can even involve changing from a word in which the guessed
letter didn’t appear to one in which it does: that is, giving the player a “freebie”. This may seem counterintuitive as a strategy, but it sometimes makes sense: if
saying “yeah, there’s an E at the end” increases the number of possible words that it might be compared to saying “no, there are no Es” then this is the right move for a
cheating hangman.
Playing against a cheating hangman also lends itself to devising new strategies as a player, too, although I haven’t yet looked deeply into this. But logically, it seems that the
optimal strategy against a cheating hangman might involve making guesses that force the hangman to bisect the search space: knowing that they’re always going to adapt towards the
largest set of candidate words, a perfect player might be able to make guesses to narrow down the possibilities as fast as possible, early on, only making guesses that they actually
expect to be in the word later (before their guess limit runs out!).
The game is brutally-difficult, but surprisingly fun, and you can have it tell you when and how it cheats so you can begin to understand its strategy.
I also find myself wondering how easily I could adapt this into a “helpful hangman”: a game which would always change the word that you’re trying to guess in order to try to make you
win. This raises the possibility of a whole new game, “suicide hangman”, in which the player is trying to get themselves killed and so is trying to pick letters that can’t
possibly be in the word and the hangman is trying to pick words in which those letters can be found, except where doing so makes it obvious which letters the player must avoid next.
Maybe another day.
In the meantime, you’re welcome to go play the game (and let me know what you think, below!) and, if you’re of such an inclination, read the source code. I’ve used some seriously ugly techniques to make this work, including regular expression metaprogramming (using
regular expressions to write regular expressions), but the code should broadly make sense if you want to adapt it. Have fun!
Update 26 September 2019, 16:23: I’ve now added “helpful mode”, where the computer tries to cheat on your behalf
rather than against you, but it’s not as helpful as you’d think because it assumes you’re playing optimally and have already memorised the dictionary!
This afternoon, the kids and I helped with some citizen science as part of the Thames WaterBlitz, a collaborative effort
to sample water quality of the rivers, canals, and ponds of the Thames Valley to produce valuable data for the researchers of today and tomorrow.
Our sampling point was by bridge 228 on the Oxford Canal: the first job was fetching water.
My two little science assistants didn’t need any encouragement to get out of the house and into the sunshine and were eager to go. I didn’t even have to pull out my trump card of
pointing out that there were fruiting brambles along the length of the canal. As I observed in a vlog last year, it’s usually pretty easy to
motivate the tykes with a little foraging.
Some collaboration was undertaken to reach a consensus on the colour of the sample.
The EarthWatch Institute had provided all the chemicals and instructions we needed by post, as well as a mobile app with which to record our results (or paper forms, if we preferred).
Right after lunch, we watched their instructional video and set out to the sampling site. We’d scouted out a handful of sites including some on the River Cherwell as it snakes through
Kidlington but for this our first water-watch expedition we figured we’d err on the safe side and aim to target only a single site: we chose this one both because it’s close to home and
because a previous year’s citizen scientist was here, too, improving the comparability of the results year-on-year.
Lots of nitrates, as indicated by the colour of the left tube. Very few phosphates, as indicated by the lack of colour in the right (although it’s still a minute and a half from
completing its processing time at the point this photo was taken and would darken a tiny bit yet).
Which colour most-resembles the colour of our reagent?
Our results are now online, and we’re already looking forward to seeing the overall
results pattern (as well as taking part in next year’s WaterBlitz!).
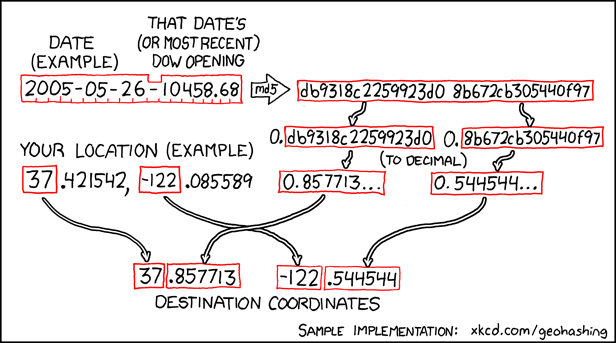
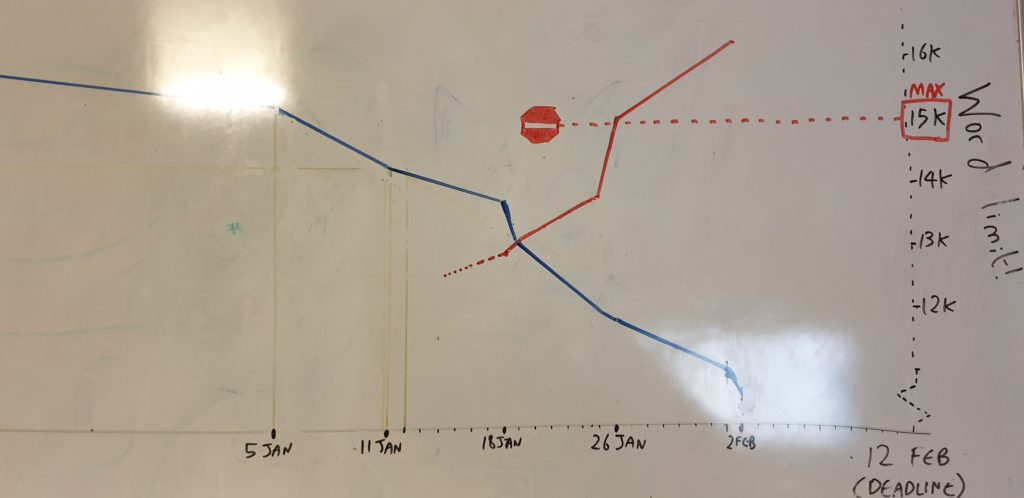
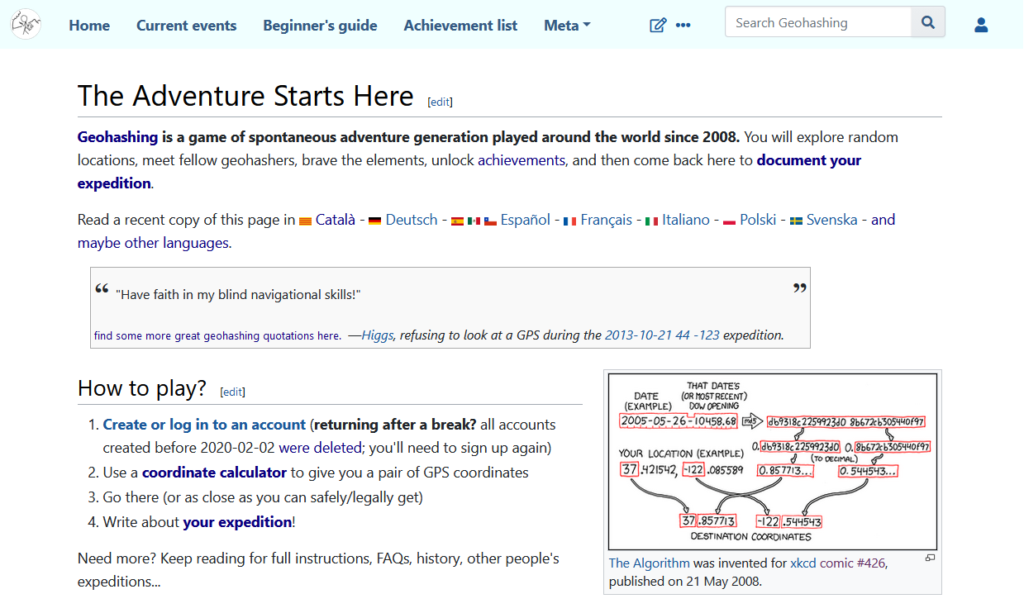

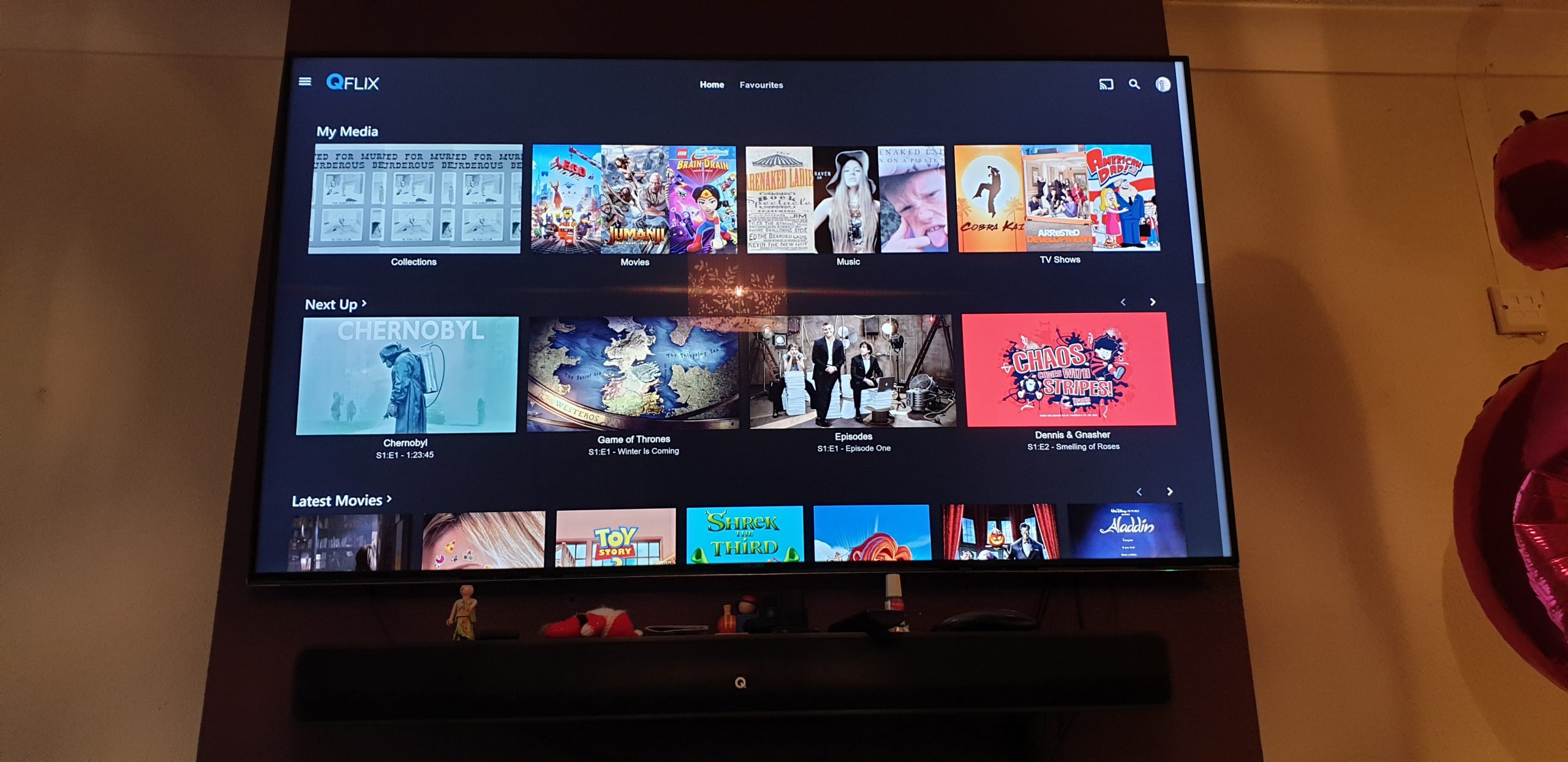















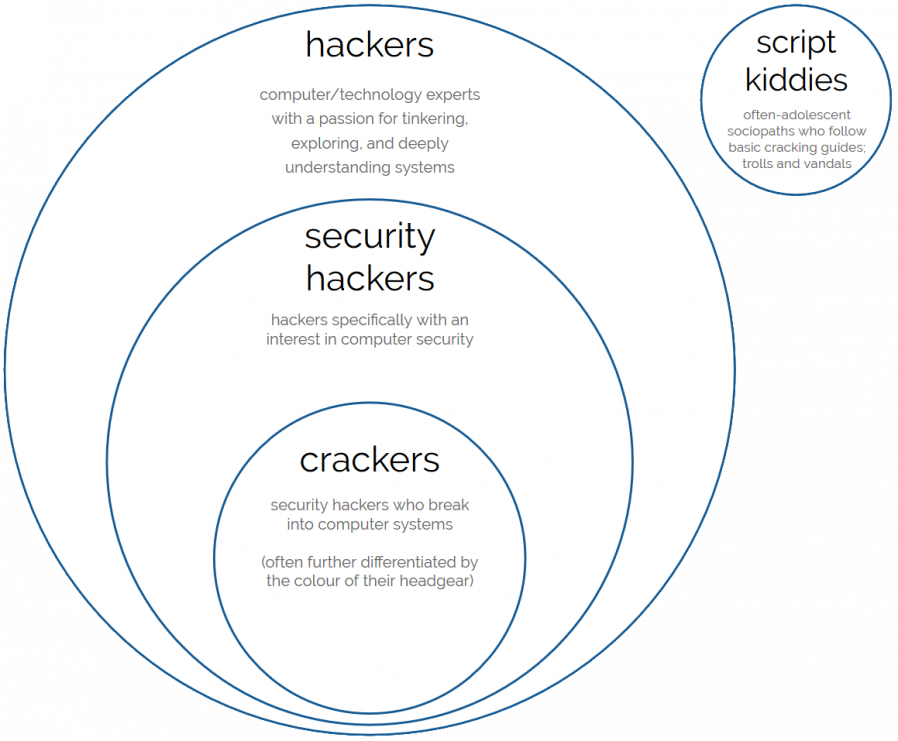
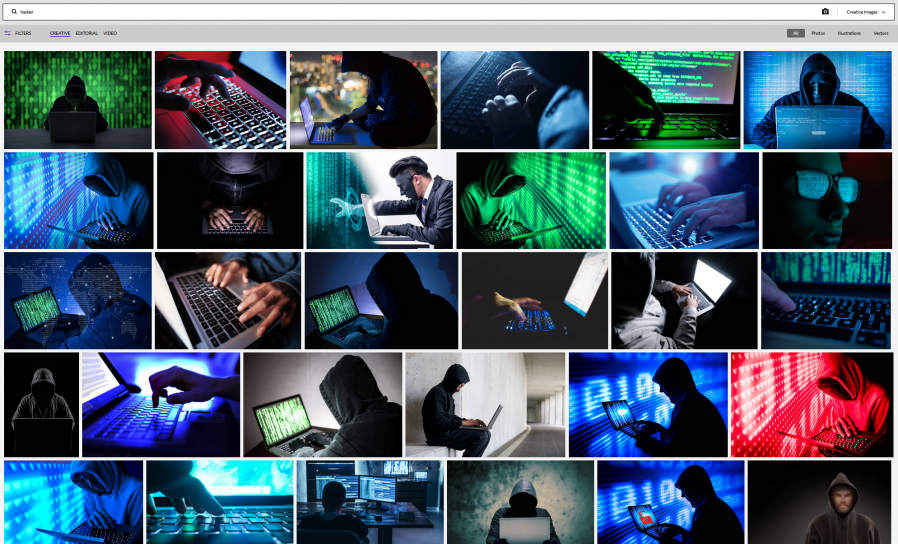



![[Animated GIF] Puppy flumps onto a human.](/_q23u/2019/09/cute-puppy.gif)