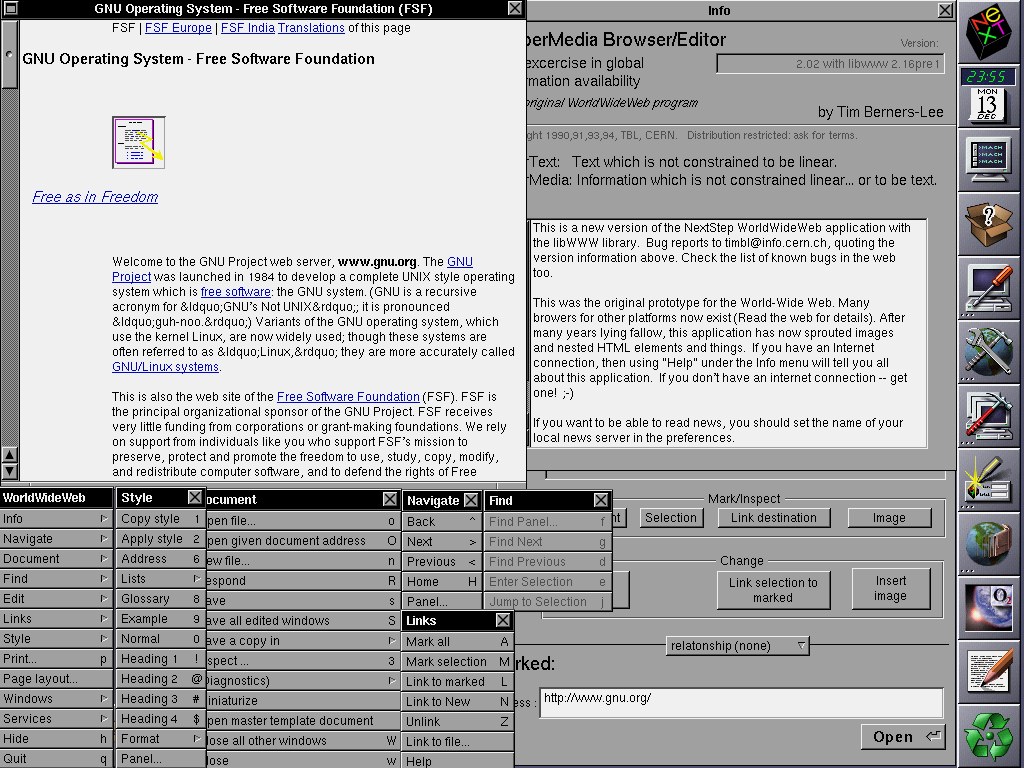
This month, a collection of some of my favourite geeks got invited to CERN in Geneva to participate in a week-long hackathon with the aim of reimplementing WorldWideWeb – the first web browser, circa 1990-1994 – as a web application. I’m super jealous, but I’m also really pleased with what they managed to produce.
This represents a huge leap forward from their last similar project, which aimed to recreate the line mode browser: the first web browser that didn’t require a NeXT computer to run it and so a leap forward in mainstream appeal. In some ways, you might expect reimplementing WorldWideWeb to be easier, because its functionality is more-similar that of a modern browser, but there were doubtless some challenges too: this early browser predated the concept of the DOM and so there are distinct processing differences that must be considered to get a truly authentic experience.

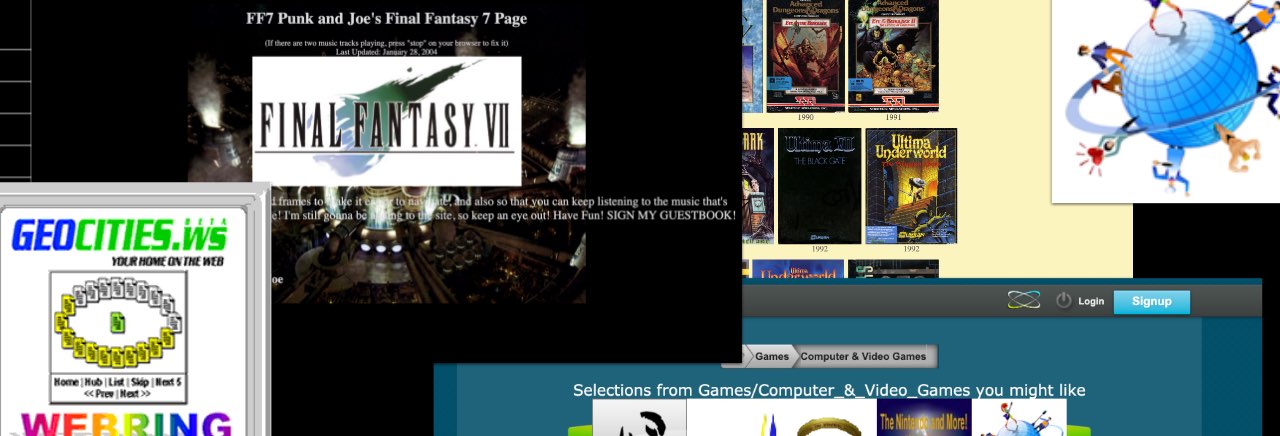
Among their outputs, the team also produced a cool timeline of the Web, which – thanks to some careful authorship – is as legible in WorldWideWeb as it is in a modern browser (if, admittedly, a little less pretty).
In an age of increasing Single Page Applications and API-driven sites and “apps”, it’s nice to be reminded that if you develop right for the Web, your content will be visible (sort-of; I’m aware that there are some liberties taken here in memory and processing limitations, protocols and negotiation) on machines 30 years old, and that gives me hope that adherence to the same solid standards gives us a chance of writing pages today that look just as good in 30 years to come. Compare that to a proprietary technology like Flash whose heyday 15 years ago is overshadowed by its imminent death (not to mention Java applets or ActiveX <shudders>), iOS apps which stopped working when the operating system went 64-bit, and websites which only work in specific browsers (traditionally Internet Explorer, though as I’ve complained before we’re getting more and more Chrome-only sites).
The Web is a success story in open standards, natural and by-design progressive enhancement, and the future-proof archivability of human-readable code. Long live the Web.
Update 24 February 2019: After I submitted news of the browser to MetaFilter, I (and others) spotted a bug. So I came up with a fix…