This article is probably “safe for work” (depending on your workplace).
It makes reference to a popular pornographic website and the features of that website. It contains screenshots, but the porny bits are blurred. The links are all safe.
Verify your age
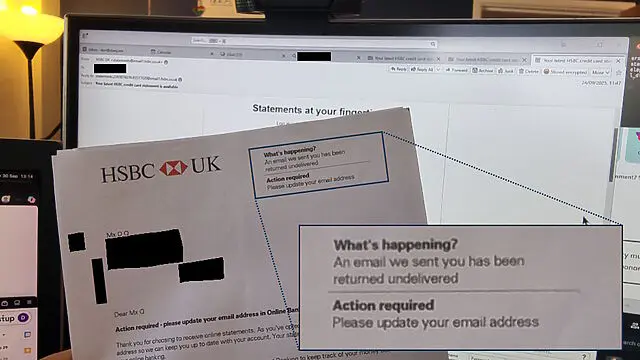
After Pornhub introduced age check to comply with the Online Safety Act1, I figured that I’d make an account to see how arduous and privacy-destroying the process of verifying that I was old enough to see naked people2. I thought it would make an amusing blog post.
I felt confident that my stupid name, if nothing else, would guarantee me a hard time with this kind of automated system.

Unfortunately3, it turned out to be super-easy for me to pass the age verification.
I just hit “verify by email” with the third-party age verification tool they use, entered an email address that’s associated with a few online accounts (not even the one I gave Pornhub!), and… everything just worked.
Sooo… this isn’t a blog post about how insurmountable age verification is. This is a blog post about something else I discovered as a result of doing this research: Pornhub has “achievements”!
Achievement unlocked
I was slightly surprised to see how many “social networking”-like features Pornhub accounts have. You can upload a profile photo… you have a “wall” that you can post to, and you can post to other people’s. Your profile (unless you tell it not to) shares which channels you’ve subscribed to, which videos you’ve favourited, and so on.
Who on Earth wants those features? I mean: really? 😅 I consider myself pretty sex-positive, but I’m not sure I’d want there to be a web page with my name, photo, and a list of all my favourite dirty vids!4
Anyway… the other thing a Pornhub profile seems to provide is… achievements:
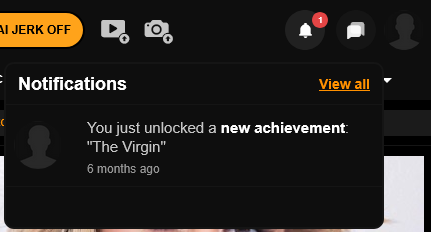
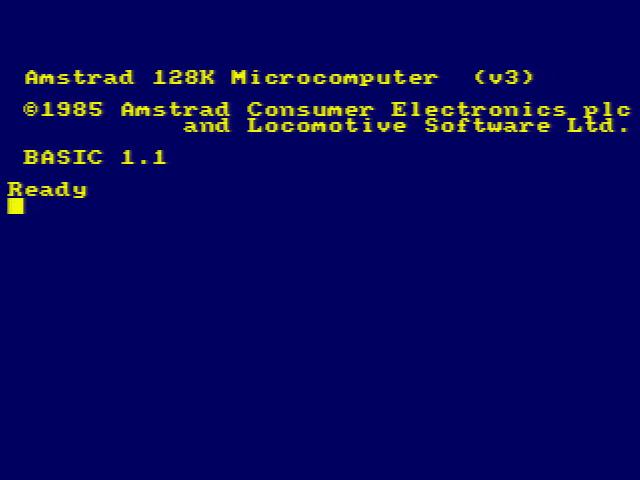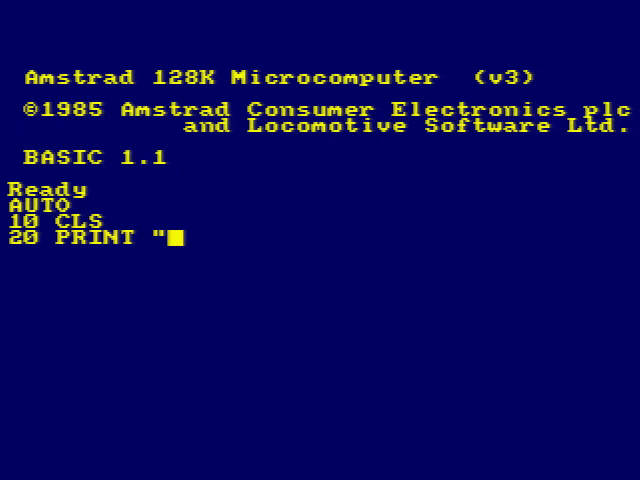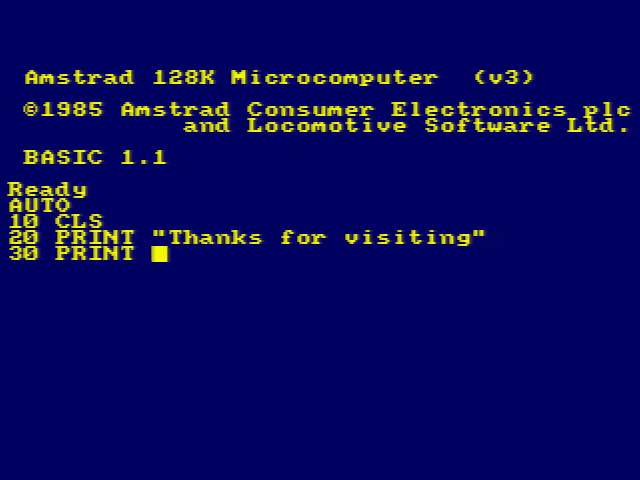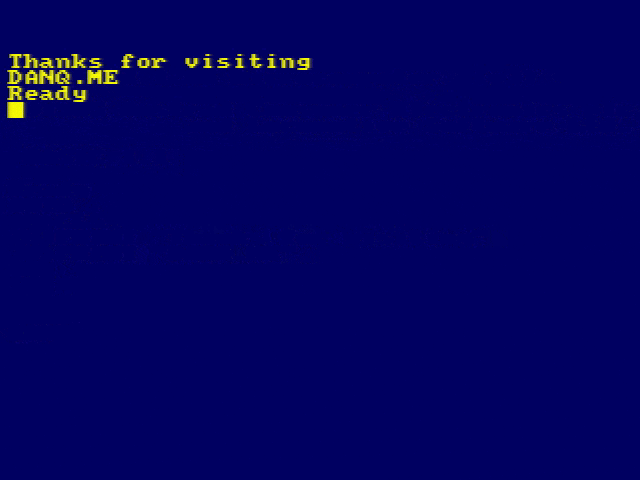
I’ve only got the one achievement right now, of course, and it’s the one that you get “for free”. So it didn’t feel like I’d earned it.
I suppose I was an actual virgin, once. And I had to prove that I’m a real human to get an account. So… maybe I earned it?
![Screenshot from Pornhub showing Dan Q's profile (0 subscribers, 69 [nice!] videos watched)'s achievements page, showing only one achievement: The Virgin.](https://bcdn.danq.me/_q23u/2026/01/pornhub-achievements-1-640x250.png)
But just stop and think about what this means for a moment. At some point, in some conference room at Pornhub HQ, there was a meeting in which somebody said something like:
“You know what we need? Public profile pages for all Pornhub accounts. And they should show, like, ‘achievements’ like you get for videogames. Except the achievements are for things like how much porn you’ve watched and how often. You can show it off to your friends!”
And then somebody else in the meeting said:
“Yes. That is a good idea.”5
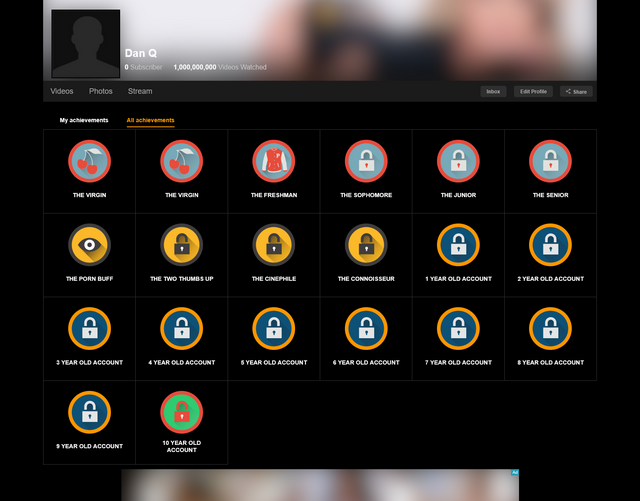
Complete list of Pornhub Achievements
I’ve reverse-engineered the complete6 collection of Pornhub Achievements for you. Y’know, in case you’re trying to finish your collection:
|
|
The Virgin | Congrats! You have accessed your account for the first time! Enjoy the ride on Many Faps Road. |
|
|
The Freshman |
You have accessed your account for the 10th time! I take it you’ve enjoyed the 9 last times?
|
|
|
The Sophomore |
You have accessed your account for the 100th time! Maximus Fappitus, you’re a true Pornhub warrior!
|
|
|
The Junior |
You have accessed your account for the 500th time! If only you could get air miles for this.
|
|
|
The Senior |
You have accessed your account for the 1000th time! If only you could get air miles for this.
|
|
|
The Porn Buff |
You’ve watched 10 videos – This is just the beginning, trust me.
|
|
|
The Two Thumbs |
You’ve watched 500 videos – Lotion or no lotion, that is the question.
|
|
|
The Cinephile |
You’ve watched 5,000 videos – Be careful, carpal tunnel is a thing.
|
|
|
The Connoisseur |
You’ve watched 50,000 videos – you are a veritable porn expert now.
|
|
|
1 Year Old Account |
Our very first anniversary, I wish us many more!
|
|
|
2 Year Old Account |
Two years of pleasure!
|
|
|
3 Year Old Account |
Three years… Ah! The memories!
|
|
|
4 Year Old Account |
Most relationships don’t even last this long #funfact
|
|
|
5 Year Old Account |
That’s half a decade of watching porn.. woah… that’s impressive.
|
|
|
6 Year Old Account |
I guess we were a match made in heaven. Who would’ve known that 6 years later, you would still be fapping on me.
|
|
|
7 Year Old Account |
No 7 year itch here! Thanks for 7 fappy years
|
|
|
8 Year Old Account |
The Outlook is good: you’ve had 8 magical years on Pornhub!
|
|
|
9 Year Old Account |
In 9 more years, your account will be old enough to view itself.
|
|
|
10 Year Old Account |
You were really ahead of the wave – here’s to a decade on Pornhub!
|
I have no idea who this feature is “for”. I’d feel the same way if YouTube had achievements, too7, but the fact that you can, and by default do, showcase your achievements on a porn site is what really blows my mind.
But maybe they ought to double-down and add more achievements. If they’re going to have them, they might as well make the most of them! How about achievements for watching a particular video a certain number of times? Or for watching videos in each of many different hour segments of the day? Or for logging in to your account and out again without consuming any pornography (hey, that’s one that I would have earned!)? If they’re going to have this bizarre feature, they might as well double-down on it!
I also have no idea who this blog post is “for”. If it turned out to be for you (maybe you wanted to know how to unlock all the achievements… or maybe you just found this as amusing as I did), leave me a comment!
Footnotes
1 Don’t get me started with everything that’s wrong with the so-called Online Safety Act. Just… don’t. The tl;dr would be that it’s about 60% good ideas, 20% good implementation.
2 Obviously if I were actually trying to use Pornhub I’d just use a VPN with an endpoint outside of the UK. Y’know, like a sensible person.
3 I mean: it’s probably pretty fortunate that – based on my experience at least – it seems to be easy for adults to verify that they’re adults in order to access services that are restricted to adults as a result of the OSA. But it’s unfortunate in that I’d hoped to make a spicy blog post about all the hoops I had to jump through and ultimately it turned out that there was only one hoop and it was pretty easy.
4 Of course, the Indieweb fan within me also says that if I did want such a page to exist, I’d want it to be on my own domain. Should there be an Indieweb post kind for “fap” for people who want to publicly track their masturbatory activities as an exercise in the quantified self?
Or should there be a “sex” kind that works a bit like “invitation” in that you can optionally tag other people who were involved? Or is sex a kind of “exercise”? Could it be considered “game play”? What about when it’s a “performance”? Of course, the irony is that anybody who puts a significant amount of effort into standardising the way that a person might publicly catalogue their sex life… is probably rendering themselves less-likely to have one.
I think I got off-topic in this footnote.
5 To be fair, I’ve worked places where committee groupthink has made worse decisions. Want a topical example? My former employer The Bodleian Libraries decided to call a podcast series “BodCast” without first performing a search… which would have revealed that Playboy were already using that name for a series of titillating vlogs. Curiously, it was Playboy who caved and renamed their service first. Presumably the strippers didn’t want to be associated with librarians?
6 It’s possible there are achievements I’ve missed – their spriteset file looks like it contains others! – that are only available to content creators on the platform. But if that’s the case, it further reinforces that these achievements are for the purpose of consumers who want to show off how many videos they’ve watched, or whatever! Weird, right?
7 “Congratulations: you watched your 500th YouTube ‘short’ – look how much of your life you’ve wasted!”