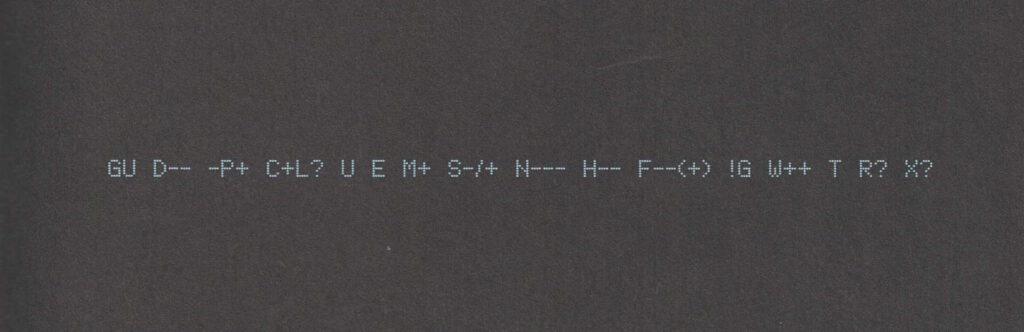Do you play in your daily life? What says “playtime” to you?
How do I play? Let me count the ways!
RPGs
I’m involved in no fewer than three different RPG campaigns (DMing the one for
The Levellers) right now, plus periodic one-shots. I love a good roleplaying game, especially one that puts character-building and storytelling
above rules-lawyering and munchkinery, specifically because that kind of collaborative, imaginative experience feels more like the kind of thing we call “play” when
done it’s done by children!
Family D&D and Abnib D&D might have a distinctly different tone, but they’re still both playtime activities.
Videogames
I don’t feel like I get remotely as much videogaming time as I used to, and in theory I’ve become more-selective about exactly what I spend my time on1.
Similarly, I don’t feel like I get as much time to grind through my oversized board games collection as I used to2,
but that’s improving as the kids get older and can be roped-into a wider diversity of games3.
Our youngest wakes early on weekend mornings and asks to kick off his day with board games. Our eldest, pictured, has grown to the point where she’s working her way through all of the
animal-themed games at our local board games cafe.
Escape Rooms
I love a good escape room, and I can’t wait until the kids are old enough for (more of) them too so I’ve an excuse to do more of them. When we’re not playing conventional escape rooms,
Ruth and I can sometimes be found playing board game-style boxed “kit” ones (which have very variable quality, in my experience) and we’ve
recently tried a little Escape Academy.
Ruth and I make a great duo when we remember to communicate early-and-often and to tag-team puzzles by swapping what we’re focussing on when we get stuck.
They’re not the only satnav-based activities I do at least partially “for fun” though! I contribute to OpenStreetMap, often through the
“gamified” experience of the StreetComplete app, and I’m very slowly creeping up the leader board at OpenBenches. Are these “play”? Sure, maybe.
And all of the above is merely the structured kinds of play I engage in. Playing “let’s pretend”-style games with the kids (even when they make it really, really
weird) adds a whole extra aspect. Also there’s the increasingly-rare murder mystery parties we sometimes hold: does that count as roleplaying, or some other kind of play?
A chef, a priest, and a librarian walk into a party… stop me if you’ve heard this one.
Suffice to say, there’s plenty of play in my life, it’s quite varied and diverse, and there is, if anything, not enough of it!
Footnotes
1 I say that, and yet somehow Steam tells me that one of my most-played games this year
was Starfield, which was… meh? Apparently compelling enough
that I’ve “ascended” twice, but in hindsight I wish I hadn’t bothered.
2 Someday my group and I will finish Pandemic Legacy: Season 2 so we can get
started on Season 0 which has sat
unplayed on my shelves since I got it… oooh… two or three years ago‽
3 This Christmas, I got each of them their first “legacy” game: Zombie Kids for the younger one, My City for the elder. They both seem pretty good.
4Geocaching is where you use military satellite networks to find lost tupperware. Geohashing uses the same technology but what you find is a whole
lot of nothing. I don’t think I can explain why I find the latter more-compelling.
I find winters are generally bad for my creativity
and motivation, usually until I bounce back in the Spring.
In an attempt to keep me writing daily, I’m giving Bloganuary a go this year. It’s sort-of like the NaNoWriMo of blogging1. And for me, Bloganuary’s very purpose is to overcome the challenge of getting disconnected
from blogging when the nights are long and inspiration’s hard to find2.
The Challenge of Staying On-Task
But outside of the winter, my biggest challenge is usually… staying on-task!
It’s easy to get my focus to wane and for me to drift into some other activity than whatever it is I should be spending my time on. It’s not even
procrastination3 so much as it’s a
fluctuating and changing field of interest. I’ll drift off of what I’m supposed to be working on and start on something that interests me more in that moment… and then potentially off
that too, in turn. The net result is that both my personal and professional lives are awash with half-finished projects4, all waiting their turn for me to find the
motivation to swing back around and pick them up on some subsequent orbit of my brain.
You know how sometimes a stock image says exactly what you need it to? This isn’t one of those times.
It’s the kind of productivity antipattern I’d bring up with my coach, except that I already
know exactly how she’d respond. First, she’d challenge the need to change; require that I justify it first. Second, she’d insist that before I can change, I need to accept and come to
terms with who I am, intrinsically: if this flitting-about is authentically “me”, who am I to change it?
Finally, after weeks or months of exercises to fulfil these two tasks, she’d point out that I’ve now reached a place where I’m still just as liable to change lanes in the middle of a
project as I was to begin with, but now I’m more comfortable with that fact. I won’t have externally changed, I’ll “just” have found some kind of happy-clappy inner peace. And she’ll
have been right that that’s what I’d actually needed all along.
Maybe it’s not such a challenge, after all.
Footnotes
1 Except that would be NaBloPoMo, of course. But it’s a similar thing.
2 Also, perhaps, to help me focus on writing more-often, on more-topics, than I might
otherwise in the course of my slow, verbose writing.
There are video games that I’ve spent
many years playing (sometimes on-and-off) before finally beating them for the first time. I spent three years playing Dune II before I finally beat it as every house. It took twice that to reach the end of Ultima Underworld II. But
today, I can add a new contender1 to that list.
Today, over thirty-five years after I first played it, I finally completed Wonder Boy.
My first experience of the game, in the 1980s, was on a coin-op machine where I’d discovered I could get away with trading the 20p piece I’d been given by my parents to use as a deposit
on a locker that week for two games on the machine. I wasn’t very good at it, but something about the cutesy graphics and catchy chip-tune music grabbed my attention and it became my
favourite arcade game.
Of all the video games about skateboarding cavemen I’ve ever played, it’s my favourite.
I played it once or twice more when I found it in arcades, as an older child. I played various console ports of it and found them disappointing. I tried it a couple of times in MAME. But I didn’t really put any effort into it until a hotel we stayed at during a family holiday to Paris in October had a bank of free-to-play arcade machines
rigged with Pandora’s Box clones so they could be used to play a few thousand different arcade classics. Including Wonder Boy.
Our eldest was particularly taken with Wonder Boy, and by the time we set off for home at the end of our holiday she’d gotten further than I ever had at it (all
without spending a single tenpence).
Off the back of all the fun the kids had, it’s perhaps no surprise that I arranged for a similar machine to be delivered to us as a gift “to the family”2
this Christmas.
If you look carefully, you can work out which present it it, despite the wrapping.
And so my interest in the game was awakened and I threw easily a hundred pounds worth of free-play games of Wonder Boy3 over the last few days. Until…
…today, I finally defeated the seventh ogre4,
saved the kingdom, etc. It was a hell of a battle. I can’t count how many times I pressed the “insert coin” button on that final section, how many little axes I’d throw into the beast’s
head while dodging his fireballs, etc.
So yeah, that’s done, now. I guess I can get back to finishing Wonder Boy: The Dragon’s Trap, the 2017 remake of a 1989 game I
adored!5
It’s aged amazingly well!
Footnotes
1 This may be the final record for time spent playing a video game before beating it,
unless someday I ever achieve a (non-cheating) NetHack ascension.
2 The kids have had plenty of enjoyment out of it so far, but their time on the machine is
somewhat eclipsed by Owen playing Street Fighter II Turbo and Streets of Rage on it and, of course, by my rediscovered obsession with Wonder Boy.
3 The arcade cabinet still hasn’t quite paid for itself in tenpences-saved,
despite my grinding of Wonder Boy. Yet.
4 I took to calling the end-of-world bosses “ogres” when my friends and I swapped tips for
the game back in the late 80s, and I refuse to learn any different name for them.6, saved Tina7Apparently the love interest has a name. Who knew?
5 I completed the original Wonder Boy III: The Dragon’s Trap on a Sega Master
System borrowed from my friend Daniel back in around 1990, so it’s not a contender for the list either.
Tracy Durnell’s post
about blogrolls really spoke to me. Like her, I used to think of a blogroll as a list of people you know personally (who happen to blog)1, but the number of bloggers among my immediate
in-person circle of friends has shrunk from several dozen to just a handful, and I dropped my blogroll in around 2008.
On the Internet, a blogger is only as alone as they choose to be.
But my connection to a wider circle has grown, and like Tracy I enjoy the “hardly strangers” connection I feel with the people I follow online. She writes:
While social media emphasizes the show-off stuff — the vacation in Puerto Vallarta, the full kitchen remodel, the night out on the town — on blogs it still seems that people are
sharing more than signalling. These small pleasures seem to be offered in a spirit of generosity — this is too beautiful not to share.
…
Although I may never interact with all the folks whose blogs I follow, reading the same blogger for a long time does build a (one-sided) connection. I may not know you, author,
but I am rooting for you. It’s a different modality of relationship than we may be used to in person, but it’s real: a parasocial relationship simmering with the potential for
deeper connection, but also satisfying as it exists.
At its core, blogging is a solitary activity with many (if not most) authors claiming that their blog is for them – myself included. Yet, the implication of audience cannot be
ignored. Indeed, the more an author embeds themself in the loose community of blogs, by reading and linking to others, the more that implication becomes reality even if not actively
pursued via comments or email.
To that end: I’ve started publishing my blogroll again! Follow that link and you’ll see an only-lightly-curated list of all the people (plus
some non-personal blogs, vlogs, and webcomics) I follow (that have updated their feeds within the last year2). Naturally, there’s an
OPML version too, and I’ve open-sourced the code I used to generate it (although I can’t imagine
anybody’s situation is enough like mine for it to be useful).
The page is a little flaky and there’s things I’d like to do to improve it, but I’d rather publish a basic version now and then come back to it with my gardening gloves on another time to improve it.
Maybe my blogroll has some folks on that you might recognise? Or else: maybe you’re only a single random-click away from somebody new you
never heard of before!
Footnotes
1 Possibly marked up with XFN to
indicate how you’re connected to one another, but I’ve always had a soft spot for XFN.
During a conversation with a colleague last week, I claimed that while I blog more-frequently than I did 5-10 years ago, it’s still with a much lower frequency than say 15-20 years ago.
Only later did I stop to think: is that actually true? It’s time for a graph!
Generating a chart...
If this message doesn't go away, the JavaScript that makes this magic work probably isn't doing its job right: please tell Dan so he can fix it.
If you consider just articles (and optionally notes, which some older content might have been better classified-as, in
retrospect) it looks like I’m right. Long gone are months like February 2005 when I posted an average of three times every two days! November
2018 was a bit of an anomaly as a I live-tweeted Challenge Robin II: my recent output’s mostly been comparable to the “quiet period”
from 2008-20102.
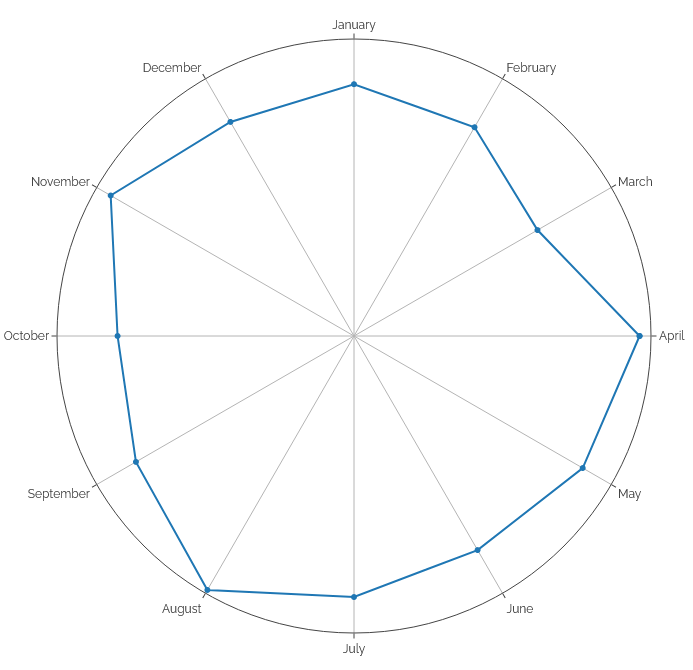
Looking at number of posts by month of the year, it’s interesting to see a pronounced “dip” in all kinds of output roundabout March, less reposts in
Summer and Autumn, and – perhaps unsurprisingly – more checkins (which often represent geocaching/geohashing logs) in the warmer months.
Even on this scale, you can see the impact of the November “Challenge Robin spike” in the notes:
Generating a chart...
If this message doesn't go away, the JavaScript that makes this magic work probably isn't doing its job right: please tell Dan so he can fix it.
Anyway, now I’ve actually automated these kinds of stats its easier than ever for me to ask questions about how and when I write in my blog. I’ve put living copies of the
charts plus additional treats (want to know when my longest “daily streak” was?) on a special page dedicated to that purpose. It’ll be interesting to see how it
looks on this blog’s 25th anniversary, in a little under a year!
Footnotes
1 Try clicking on any of the post kinds in the legend to add/remove them, or
click-and-drag a range across the chart to zoom in.
2 In hindsight, I was clearly depressed in and around
2009 and this doubtless impacted my ability to engage in “creative” pursuits.
You can click an image and see a full-window popup dialog box containing a larger version of the image.
The larger version of the image isn’t loaded until it’s needed.
You can close the larger version with a close button. You can also use your browser’s back button.
You can click again to download the larger version/use your browser to zoom in further.
You can share/bookmark etc. the URL of a zoomed-in image and the recipient will see the same image (and return to the
image, in the right blog post, if they press the close button).
No HTTP round trip is required when opening/closing a lightbox: it’s functionally-instantaneous.2
No JavaScript is used at all.
Visitors can click on images to see a larger version, with a “close” button. No JavaScript needed.
Here’s how it works –
The Markup
<figureid="img3336"aria-describedby="caption-img3336"><ahref="#lightbox-img3336"role="button"><imgsrc="small-image.jpg"alt="Alt text is important."width="640"height="480"></a><figcaptionid="caption-img3336">
Here's the caption.
</figcaption></figure>
... (rest of blog post) ...
<dialogid="lightbox-img3336"class="lightbox"><ahref="large-image.jpg"><imgsrc="large-image.jpg"loading="lazy"alt="Alt text is important."></a><aclass="close"href="#img3336"title="Close image"role="button">×</a></dialog>
The HTML is pretty simple (and I automatically generate it, of course).
For each lightboxed image in a post, a <dialog> for that image is appended to the post. That dialog contains a larger copy of the image (set to
loading="lazy" so the browser have to download it until it’s needed), and a “close” button.
The image in the post contains an anchor link to the dialog; the close button in the dialog links back to the image in the post.3 I wrap the lightbox image itself in a link to the full version of the
image, which makes it easier for users to zoom in further using their browser’s own tools, if they like.
Even without CSS, this works (albeit with “scrolling” up and down to the larger image). But the clever bit’s yet to
come:
The Style
body:has(dialog:target) {
/* Prevent page scrolling when lightbox open (for browsers that support :has()) */position:fixed;
}
a[href^='#lightbox-'] {
/* Show 'zoom in' cursor over lightboxed images. */cursor: zoom-in;
}
.lightbox {
/* Lightboxes are hidden by-default, but occupy the full screen and top z-index layer when shown. */all:unset;
display:none;
position:fixed;
top:0;
left:0;
width:100%;
height:100%;
z-index:2;
background:#333;
}
.lightbox:target {
/* If the target of the URL points to the lightbox, it becomes visible. */display: flex;
}
.lightboximg {
/* Images fill the lightbox. */object-fit:contain;
height:100%;
width:100%;
}
/* ... extra CSS for styling the close button etc. ... */
Here’s where the magic happens.
Lightboxes are hidden by default (display: none), but configured to fill the window when shown.
They’re shown by the selector .lightbox:target, which is triggered by the id of the <dialog> being referenced by the anchor part of
the URL in your address bar!
Summary
It’s neither the most-elegant nor cleanest solution to the problem, but for me it hits a sweet spot between developer experience and user experience. I’m always disappointed when
somebody’s “lightbox” requires some heavyweight third-party JavaScript (often loaded from a CDN), because that seems to be the
epitome of the “take what the Web gives you for free, throw it away, and reimplement it badly in JavaScript” antipattern.
There’s things I’ve considered adding to my lightbox. Progressively-enhanced JavaScript that adds extra value and/or uses the Popover API where available, perhaps? View Transitions to animate the image “blowing up” to the larger size, while the full-size image loads in the
background? Optimistic preloading when hovering over the image4? “Previous/next” image links when lightboxing a gallery? There’s lots of potential to expand it
without breaking the core concept here.
I’d also like to take a deeper dive into the accessibility implications of this approach: I think it’s pretty good, but accessibility is a big topic and there’s always more to
learn.
In the meantime, why not try out my lightbox by clicking on this picture of my dog (photographed here staring longingly at the bacon sandwich picture above, perhaps).
I hope the idea’s of use to somebody else looking to achieve this kind of thing, too.
Footnotes
1 Where JavaScript is absolutely necessary, I (a) host it on the same domain, for
performance and privacy-respecting reasons, and (b) try to provide a functional alternative that doesn’t require JavaScript, ideally seamlessly.
2 In practice, the lightbox images get lazy-loaded, so there can be a short round
trip to fetch the image the first time. But after that, it’s instantaneous.
3 The pair – post image and lightbox image – work basically the same way as footnotes,
like this one.
4 I already do this with links in general using the excellent instant.page.
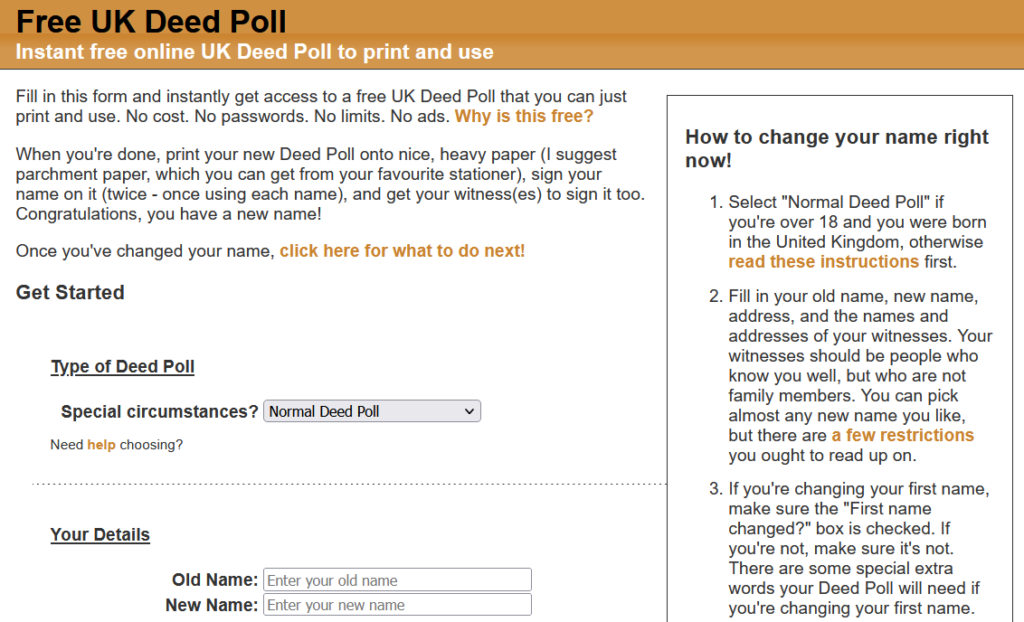
Naturally, I was delighted, not least because it gives me an excuse to use the “deed poll” and “music” tags simultaneously on a post for the first time.
Don’t ask me what my “real” name is,
I’ve already told you what it was,
And I’m planning on burning my birth certificate.
The song’s about discovering and asserting self-identity through an assumed, rather than given, name. Which is fucking awesome.
The website’s basically unchanged for most of a decade and a half, and… umm… it looks it. I really ought to get around to improving and enhancing it someday.
Like virtually all of my sites, including this one, freedeedpoll.org.uk deliberately retains minimal logs and has no analytics tools. As a result, I have very little concept of how
popular it is, how widely it’s used etc., except when people reach out to me.
People do: I get a few emails every month from people who’ve got questions1,
or who are having trouble
getting their homemade deed poll accepted by troublesome banks. I’m happy to help them, but without additional context, I can’t be sure whether these folks represent the entirety of the
site’s users, a tiny fraction, or somewhere in-between.
So it’s obviously going to be a special surprise for me to have my website featured in a song.
I’ve been having a challenging couple of weeks2,
and it was hugely uplifting for me to bump into these appreciative references to my work in the wider Internet.
Footnotes
1 Common questions I receive are about legal gender recognition, about changing the names
of children, about changing one’s name while still a minor without parental consent, or about citizenship requirements. I’ve learned a lot about some fascinating bits of law.
This post is also available as a video. If you'd
prefer to watch/listen to me talk about this topic, give it a look.
Prefer to watch/listen than read? There’s a vloggy/video version of this post in which I explain all the
key concepts and demonstrate an SHA-1 length extension attack against an imaginary site.
I understood the concept of a length traversal
attack and when/how I needed to mitigate them for a long time before I truly understood why they worked. It took until work provided me an opportunity to play with one in practice (plus reading Ron Bowes’ excellent article on the subject) before I really grokked it.
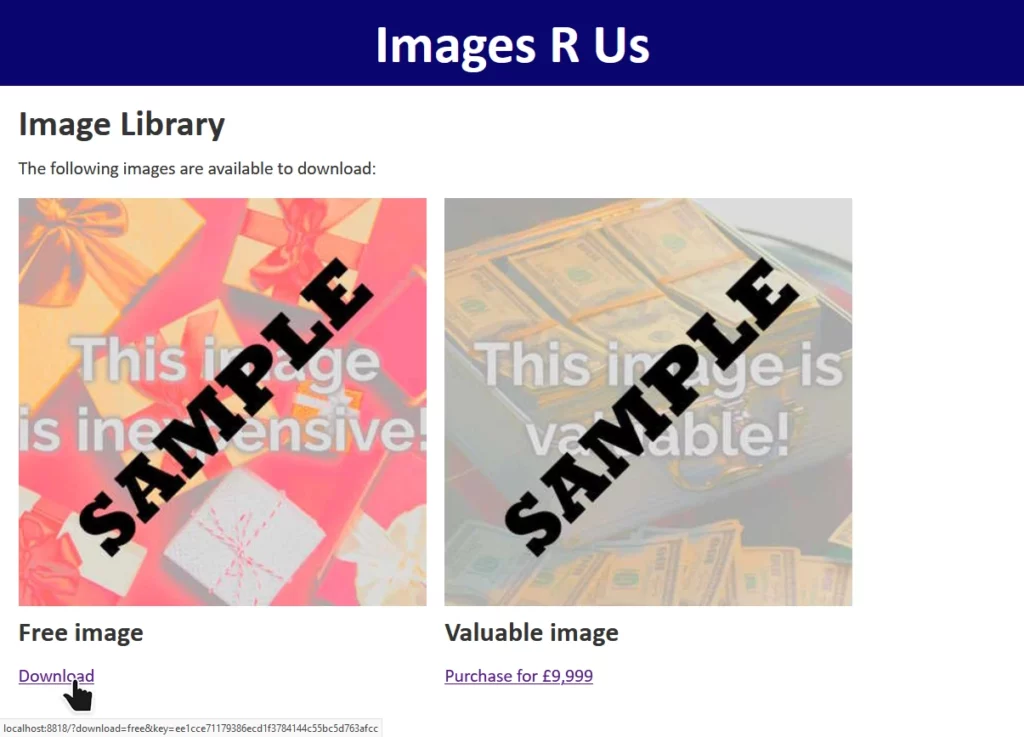
For the demonstration, I’ve built a skeletal stock photography site whose download links are protected by a hash of the link parameters, salted using a secret string stored securely
on the server. Maybe they let authorised people hotlink the images or something.
You can check out the code and run it using the instructions in the repository if you’d like to play along.
Using hashes as message signatures
The site “Images R Us” will let you download images you’ve purchased, but not ones you haven’t. Links to the images are protected by a SHA-1 hash1, generated as follows:
The nature of hashing algorithms like SHA-1 mean that even a small modification to the inputs, e.g. changing one character in
the word “free”, results in a completely different output hash which can be detected as invalid.
When a “download” link is generated for a legitimate user, the algorithm produces a hash which is appended to the link. When the download link is clicked, the same process is followed
and the calculated hash compared to the provided hash. If they differ, the input must have been tampered with and the request is rejected.
Without knowing the secret key – stored only on the server – it’s not possible for an attacker to generate a valid hash for URL parameters of the attacker’s choice. Or is it?
Changing
download=free to download=valuable invalidates the hash, and the request is denied.
Actually, it is possible for an attacker to manipulate the parameters. To understand how, you must first understand a little about how SHA-1 and its siblings actually work:
SHA-1‘s inner workings
The message to be hashed (SECRET_KEY + URL_PARAMS) is cut into blocks of a fixed size.2
The final block is padded to bring it up to the full size.3
A series of operations are applied to the first block: the inputs to those operations are (a) the contents of the block itself, including any padding, and (b) an initialisation
vector defined by the algorithm.4
The same series of operations are applied to each subsequent block, but the inputs are (a) the contents of the block itself, as before, and (b) the output of the previous
block. Each block is hashed, and the hash forms part of the input for the next.
The output of running the operations on the final block is the output of the algorithm, i.e. the hash.
SHA-1 operates on a single block at a time, but the output of processing each block acts as part of the input of the one that
comes after it. Like a daisy chain, but with cryptography.
In SHA-1, blocks are 512 bits long and the padding is a 1, followed by as many 0s as is necessary,
leaving 64 bits at the end in which to specify how many bits of the block were actually data.
Padding the final block
Looking at the final block in a given message, it’s apparent that there are two pieces of data that could produce exactly the same output for a given function:
The original data, (which gets padded by the algorithm to make it 64 bytes), and
A modified version of the data, which has be modified by padding it in advance with the same bytes the algorithm would; this must then be followed by an
additional block
A “short” block with automatically-added padding produces the same output as a full-size block which has been pre-populated with the same data as the padding would
add.5In the case where we insert our own “fake” padding data, we can provide more message data after the padding and predict the overall hash. We can do this because
we the output of the first block will be the same as the final, valid hash we already saw. That known value becomes one of the two inputs into the function for the block that
follows it (the contents of that block will be the other input). Without knowing exactly what’s contained in the message – we don’t know the “secret key” used to salt it – we’re
still able to add some padding to the end of the message, followed by any data we like, and generate a valid hash.
Therefore, if we can manipulate the input of the message, and we know the length of the message, we can append to it. Bear that in mind as we move on to the other half
of what makes this attack possible.
Parameter overrides
“Images R Us” is implemented in PHP. In common with most server-side scripting languages,
when PHP sees a HTTP query string full of key/value pairs, if
a key is repeated then it overrides any earlier iterations of the same key.
Many online sources say that this “last variable matters” behaviour is a fundamental part of HTTP, but it’s not: you can
disprove is by examining $_SERVER['QUERY_STRING'] in PHP, where you’ll find the entire query string.
You could even implement your own query string handler that instead makes the first instance of each key the canonical one, if you really wanted.6It’d be tempting to simply override the download=free parameter in the query string at “Images R Us”, e.g. making it
download=free&download=valuable! But we can’t: not without breaking the hash, which is calculated based on the entire query string (minus the &key=...
bit).
But with our new knowledge about appending to the input for SHA-1 first a padding string, then an extra block containing our
payload (the variable we want to override and its new value), and then calculating a hash for this new block using the known output of the old final block as the
IV… we’ve got everything we need to put the attack together.
Putting it all together
We have a legitimate link with the query string download=free&key=ee1cce71179386ecd1f3784144c55bc5d763afcc. This tells us that somewhere on the server, this is
what’s happening:
I’ve drawn the secret key actual-size (and reflected this in the length at the bottom). In reality, you might not know this, and some trial-and-error might be necessary.7If we pre-pad the string download=free with some special characters to replicate the padding that would otherwise be added to this final8 block, we can add a second block containing
an overriding value of download, specifically &download=valuable. The first value of download=, which will be the word free followed by
a stack of garbage padding characters, will be discarded.
And we can calculate the hash for this new block, and therefore the entire string, by using the known output from the previous block, like this:
The URL will, of course, be pretty hideous with all of those special characters – which will require percent-encoding – on the end of the word ‘free’.
Doing it for real
Of course, you’re not going to want to do all this by hand! But an understanding of why it works is important to being able to execute it properly. In the wild, exploitable
implementations are rarely as tidy as this, and a solid comprehension of exactly what’s happening behind the scenes is far more-valuable than simply knowing which tool to run and what
options to pass.
That said: you’ll want to find a tool you can run and know what options to pass to it! There are plenty of choices, but I’ve bundled one called hash_extender into my example, which will do the job pretty nicely:
which algorithm to use (sha1), which can usually be derived from the hash length,
the existing data (download=free), so it can determine the length,
the length of the secret (16 bytes), which I’ve guessed but could brute-force,
the existing, valid signature (ee1cce71179386ecd1f3784144c55bc5d763afcc),
the data I’d like to append to the string (&download=valuable), and
the format I’d like the output in: I find html the most-useful generally, but it’s got some encoding quirks that you need to be aware of!
hash_extender outputs the new signature, which we can put into the key=... parameter, and the new string that replaces download=free, including
the necessary padding to push into the next block and your new payload that follows.
Unfortunately it does over-encode a little: it’s encoded all the& and = (as %26 and %3d respectively), which isn’t what we
wanted, so you need to convert them back. But eventually you end up with the URL:
http://localhost:8818/?download=free%80%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%e8&download=valuable&key=7b315dfdbebc98ebe696a5f62430070a1651631b.
Disclaimer: the image you get when you successfully exploit the test site might not actually be valuable.
And that’s how you can manipulate a hash-protected string without access to its salt (in some circumstances).
Mitigating the attack
The correct way to fix the problem is by using a HMAC in place
of a simple hash signature. Instead of calling sha1( SECRET_KEY . urldecode( $params ) ), the code should call hash_hmac( 'sha1', urldecode( $params ), SECRET_KEY
). HMACs are theoretically-immune to length extension attacks, so long as the output of the hash function used is
functionally-random9.
Ideally, it should also use hash_equals( $validDownloadKey, $_GET['key'] ) rather than ===, to mitigate the possibility of a timing attack. But that’s another story.
Footnotes
1 This attack isn’t SHA1-specific: it works just as well on many other popular hashing algorithms too.
2 SHA-1‘s blocks are 64 bytes
long; other algorithms vary.
3 For SHA-1, the padding bits
consist of a 1 followed by 0s, except the final 8-bytes are a big-endian number representing the length of the message.
4 SHA-1‘s IV is 67452301 EFCDAB89 98BADCFE 10325476 C3D2E1F0, which you’ll observe is little-endian counting from 0 to
F, then back from F to 0, then alternating between counting from 3 to 0 and C to F. It’s
considered good practice when developing a new cryptographic system to ensure that the hard-coded cryptographic primitives are simple, logical, independently-discoverable numbers like
simple sequences and well-known mathematical constants. This helps to prove that the inventor isn’t “hiding” something in there, e.g. a mathematical weakness that depends on a
specific primitive for which they alone (they hope!) have pre-calculated an exploit. If that sounds paranoid, it’s worth knowing that there’s plenty of evidence that various spy
agencies have deliberately done this, at various points: consider the widespread exposure of the BULLRUN programme and its likely influence on Dual EC DRBG.
5 The padding characters I’ve used aren’t accurate, just representative. But there’s the
right number of them!
6 You shouldn’t do this: you’ll cause yourself many headaches in the long run. But you
could.
7 It’s also not always obvious which inputs are included in hash generation and how
they’re manipulated: if you’re actually using this technique adversarily, be prepared to do a little experimentation.
8 In this example, the hash operates over a single block, but the exact same principle
applies regardless of the number of blocks.
9 Imagining the implementation of a nontrivial hashing algorithm, the predictability of
whose output makes their HMAC vulnerable to a length extension attack, is left as an exercise for the reader.
Our lessons started online, in our own living room, with videos from Tango Stream‘s “Tango Basics” series. It was a really good
introduction and I’d recommend it, but it’s no substitute for practice!
This adventure began, in theory at least, on my birthday in January. I’ve long expressed an interest
in taking a dance class together, and so when Ruth pitched me a few options for a birthday gift, I jumped on the opportunity to learn tango. My knowledge of the dance was
basically limited to what I’d seen in films and television, but it had always looked like such an amazing dance: careful, controlled… synchronised, sexy.
After shopping around for a bit, Ruth decided that the best approach was for us to do a “beginners” video course in the comfort of our living room, and then take a weekend
getaway to do an “improvers” class.
After all, we’d definitely have time to complete the beginners’ course and get a lot of practice in before we had to take to the dance floor with a group of other “improvers”,
right?2
By the time we were riding the train up to Edinburgh, we’d watched all the videos in our beginners’ course, and tried all of the steps in isolation… but we’d had barely any
opportunity to combine them into an actual dance.
Okay, let me try again to enumerate you everything I actually know about tango3:
Essentials. A leader and follower4
hold one another’s upper torso closely enough that, with practice, each can intuit from body position where the other’s feet are without looking. While learning, you will not manage
to do this, and you will tread on one another’s toes.
The embrace. In the embrace, one side – usually the leader’s left – is “open”, with the dancers’ hands held; the other side is “closed”, with the dancers holding one
another’s bodies. Generally, you should be looking at one another or towards the open side. But stop looking at your feet: you should know where your own feet are by proprioception,
and you know where your partners’ feet are by guesswork and prayer.
The walk. You walk together, (usually) with opposite feet moving in-sync so that you can be close and not tread on one another’s toes, typically forward
(from the leader’s perspective) but sometimes sideways or even backwards (though not usually for long, because it increases the already-inevitable chance that you’ll collide
embarrassingly with other couples).
Movement. Through magic and telepathy a good connection with one another, the pair will, under the leader’s direction, open opportunities to perform more
advanced (but still apparently beginner-level) steps and therefore entirely new ways to mess things up. These steps include:
Forward ochos. The follower stepping through a figure-eight (ocho) on the closed side, or possibly the open side, but they probably forget which
way they were supposed to turn when they get there, come out on the wrong foot, and treat on the leader’s toes.
Backwards ochos. The follower moves from side to side or in reverse through a series of ochos, until the leader gets confused which way they’re
supposed to pivot to end the maneuver and both people become completely confused and
unstuck.
The cross. The leader walks alongside the follower, and when the leader steps back the follower chooses to assume that the leader intended for them to cross their
legs, which opens the gateway to many other steps. If the follower guesses incorrectly, they probably fall over during that step. If the follower guesses correctly but forgets
which way around their feet ought to be, they probably fall over on the very next step. Either way, the leader gets confused and does the wrong thing next.
Giros. One or both partners perform a forwards step, then a sideways step, then a backwards step, then another sideways step, starting on the inside leg
and pivoting up to 270° with each step such that the entire move rotates them some portion of a complete circle. In-sync with one another, of course.
Sacadas. Because none of the above are hard enough to get right together, you should start putting your leg out between your partner’s leg and try and
trip them up as they go. They ought to know you’re going to do this, because they’ve got perfect predictive capabilities about where your feet are going to end, remember?
Also remember to use the correct leg, which might not be the one you expect, or you’ll make a mess of the step you’ll be doing in three beats’ time. Good luck!
Barridas and mordidas. What, you finished the beginners’ course? Too smart to get tripped up by your partner’s sacada any more? Well
now it’s time to start kicking your partner’s feet out from directly underneath them. That’ll show ’em.
Style. All of the above should be done gracefully, elegantly, with perfect synchronicity and in time with the music… oh, and did I mention you should be able to
improve the whole thing on the fly, without pre-communication with your partner. 😅
Just when you think you’ve worked out the basic rules of tango, you find a leaflet on your table with some rules of the dancefloor to learn, too!
Ultimately, it was entirely our own fault we felt out-of-our-depth up in Edinburgh at the weekend. We tried to run before we could walk, or – to put it another way – to milonga
before we could caminar.
A somewhat-rushed video course and a little practice on carpet in your living room is not a substitute for a more-thorough práctica on a proper-sized dance floor, no matter how
often you and your partner use any excuse of coming together (in the kitchen, in an elevator, etc.) to embrace and walk a couple of steps! Getting a hang of the fluid connections and
movement of tango requires time, and practice, and discipline.
Got the feeling that your body and your feet aren’t moving in the same direction? That’s tango!
But, not least because of our inexperience, we did learn a lot during our weekend’s deep-dive. We got to watch (and, briefly, partner with) some much better dancers
and learned some advanced lessons that we’ll doubtless reflect back upon when we’re at the point of being ready for them. Because yes: we are continuing! Our next step is a
Zoom-based lesson, and then we’re going to try to find a more-local group.
Also, we enjoyed the benefits of some one-on-one time with Jenny and Ricardo, the amazingly friendly and supportive teachers whose video course got us started and whose
in-person event made us feel out of our depth (again: entirely our own fault).
If you’ve any interest whatsoever in learning to dance tango, I can wholeheartedly recommend Ricardo and Jenny Oria as teachers. They run
courses in Edinburgh and occasionally elsewhere in the UK as well as providing online resources, and they’re the most amazingly
supportive, friendly, and approachable pair imaginable!
Just… learn from my mistake and start with a beginner course if you’re a beginner, okay? 😬
Footnotes
1 I’m exaggerating how little I know for effect. But it might not be as much of an
exaggeration as you’d hope.
4 Tango’s progressive enough that it’s come to reject describing the roles in binary
gendered terms, using “leader” and “follower” in place of what was once described as “man” and “woman”, respectively. This is great for improving access to pairs of dancers who don’t
consist of a man and a woman, as well as those who simply don’t want to take dance roles imposed by their gender.
Our household costs have increased considerably over the last decade, not least because children and pets are expensive (who knew?).
Sample data
For my examples below, assume a three-person family. I’m using unrealistic numbers for easy arithmetic.
Alice earns £2,000, Bob earns £1,000, and Chris earns £500, for a total household income of £3,500.
Alice spends £1,450, Bob £800, and Chris £250, for a total household expenditure of £2,500.
Model #1: Straight Split
We’ve never done things this way, but for completeness sake I’ll mention it: the simplest way that households can split their costs is by dividing them between the participants equally:
if the family make a £60 shopping trip, £20 should be paid by each of Alice, Bob, and Chris.
My example above shows exactly why this might not be a smart choice: this model would have each participant contribute £833.33 over the course of the month, which is more than Chris
earned. If this month is representative, then Chris will gradually burn through their savings and go broke, while Alice will put over a grand into her savings account every month!
“Land, Bread, Peace… and Spreadsheets!”
Model #2: Income-Assessed
We’re a bunch of leftie socialist types, and wanted to reflect our political outlook in our household finances, too. So rather than just splitting our costs equally between us, we
initially implemented a means-assessment system based on the relative differences between our incomes. The thinking was that somebody that earns twice as much should
contribute twice as much towards the costs of running the household.
Using our example family above, here’s how that might look:
Alice earned 57% of the household income, so she should have contributed 57% of the household costs: £1,425. She overpaid by £25.
Bob earned 29% of the household income, so he should have contributed 29% of the household costs: £725. He overpaid by £75.
Chris earned 14% of the household income, so they should have contributed 14% of the household costs: £350. They underpaid by £100.
Therefore, at the end of the month Chris should settle up by giving £25 to Alice and £75 to Bob.
By analogy: The “Income-Assessed” model is functionally equivalent to splitting each and every expense according to the participants income – e.g. if a £100 bill landed
on their doormat, Alice would pay £57, Bob £29, and Chris £14 of it – but has the convenience that everybody just pays for things “as they go along” and then square everything up when
their paycheques come in.
You know what else is surprisingly expensive? Having the roof of your house taken off.
Over time, our expenditures grew and changed and our incomes grew, but they didn’t do so in an entirely simple fashion, and we needed to make some tweaks to our income-assessed model of
household finance contributions. For example:
Gross vs Net Income: For a while, some of our incomes were split into a mixture of employed income (on which income tax was paid as-we-earned) and self-employed
income (for which income tax would be calculated later), making things challenging. We agreed that net income (i.e. take-home pay) was the correct measure for us to use for the
income-based part of the calculation, which also helped keep things fair as some of us began to cross into and out of the higher earner tax bracket.
Personal Threshold: At times, a subset of us earned a disproportionate portion of the household income (there were short periods where one of us earned over 50% of
the household income; at several other times two family members each earned thrice that of the third). Our costs increased too, but this imposed an regressive burden on the
lower-earner(s), for whom those costs represented a greater proportion of their total income. To attempt to mitigate this, we introduced a personal threshold somewhat analogous to the
income tax “personal allowance” (the policy that means that you don’t pay tax on your first £12,570 of income).
Eventually, we came to see that what we were doing was trying to patch a partially-broken system, and tried something new!
Model #3: Same-Residual
In 2022, we transitioned to a same-residual system that attempts to share out out money in an even-more egalitarian way. Instead of each person contributing in accordance
with their income, the model attempts to leave each person with the same average amount of disposable personal income at the end. The difference is most-profound where the
relative incomes are most-diverse.
With the example family above, that would mean:
The household earned £3,500 and spent £2,500, leaving £1,000. Dividing by 3 tells us that each person should have £333.33 after settling up.
Alice earned earned £2,000 and spent £1,450, so she has £550 left. That’s £216.67 too much.
Bob earned earned £1,000 and spent £800, so she has £200 left. That’s £133.33 too little.
Chris earned earned £500 and spent £250, so she has £250 left. That’s £83.33 too little.
Therefore, at the end of the month Alice should settle up by giving £133.33 to Bob and £83.33 to Chris (note there’s a 1p rounding error).
That’s a very different result than the Income-Assessed calculation came up with for the same family! Instead of Chris giving money to Alice and Bob, because those two
contributed to household costs disproportionately highly for their relative incomes, Alice gives money to Bob and Chris, because their incomes (and expenditures) were much lower.
Ignoring any non-household costs, all three would expect to have the same bank balance at the start of the month as at the end, after settlement.
By analogy: The “Same-Residual” model is functionally equivalent to having everybody’s salary paid into a shared bank account, out of which all household expenditures
are paid, and at the end of the month everything that’s left in the bank account gets split equally between the participants.
Our version of the spreadsheet has inherited a lot of hacky edges, many for now-unused functionality.
We’ve made tweaks to this model, too, of course. For example: we’ve set a “target” residual and, where we spend little enough in a month that we would each be eligible for more
than that, we instead sweep the excess into our family savings account. It’s a nice approach to help build up a savings reserve without feeling a pinch.
I’m sure our model will continue to evolve, as it has for the last decade and a half, but for now it seems stable, fair, and reasonable. Maybe it’ll work for your household too (whether
or not you’re also a polyamorous family!): take a look at the spreadsheet in Google Drive and give it a go.
Semi-inspired by a similar project by Kev Quirk,
I’ve got a project I want to run on my blog in 2024.
I want you to be my pen pal for a month. Get in touch by emailing penpals@danq.me or any other way you like and let’s do this!
We’ll use email, though, not paper.
I don’t know much about the people who read my blog, whether they’re ad-hoc visitors or regular followers1.
I’m not interested in collecting statistics about people reading this post. I’m interested in meeting them.
So here’s the plan: I’m looking to do is to fill a “dance card” of interesting people each of with whom I’ll “pen pal” for a month.
The following month, I’ll blog about the experience: who I met, what I learned about them, what I learned about myself. Have a look below and see if there’s a slot for you: I’d love to
chat to you about, well – anything!
My goals:
Get inspired to blog about new/different things (and hopefully help inspire others to do the same).
Connect with a dozen folks on a more-interpersonal level than I normally do via my blog.
Maybe even make, or deepen, some friendships!
The “rules”:
Aiming for at least 3 email exchanges over a month. Maybe more.2
There’s no specific agenda: I promise to bring what I’ve been thinking about and working on, and possibly a spicy conversation-starter from LetsLifeChat.com. You bring whatever you like. No topic is explicitly off the table unless somebody says it is (which anybody can do
at any time, for any or no reason).
I’ll blog a summary of my experience the month afterwards, but I won’t share anything without permission. I’ll happily share an unpublished draft with each penpal first so they
can veto any bits they don’t like. I’ll refer to you by whatever name, link etc. suits you best.
If you have a blog/digital garden/social presence of any kind, you’re welcome to blog about it too. Or not: entirely up to you!
You! If you’re reading this, you’re probably somebody I want to meet! But I’d be especially interested in penpalling with people who tick one or more of the following
boxes:
Personal bloggers at the edges of or just outside my usual social circles. Maybe you’re an IndieWeb, RSS Club, or Geminispace explorer?
Regular readers, whether you just skim the post titles and dive in once in a blue moon or read every post and comment on the things you care about.
Automatticians from parts of the company I don’t get to interact with. Let’s build some bridges!
People whose interests overlap with mine in any way, large or small. That overlap might be technology (web standards, accessibility, security, blogging, open
source…), hobbies (GPS sports, board games, magic, murder mysteries, science fiction, getting lost on Wikipedia…),
volunteering (third sector support, tech for good, diversity in tech…), social (queer issues, polyamory, socialism…), or something else entirely.
Missed connections. Did we meet briefly or in-passing (conferences, meetups, friends-of-friends, overlapping volunteering circles) but not develop anything further?
I’d love to pick up where we left off!
Distant- and nearly-friends. Did we drift apart long ago, or never quite move into one another’s orbit in the first place? This could be your excuse to touch bases!
If you read this far and didn’t email penpals@danq.me yet, go do that. I’m looking forward to hearing from you!
Footnotes
1 Not-knowing who reads my blog might come at least in part from the fact that I actively sabotage any plugin that might give me any analytics! One might say I’ve shot myself in the foot, there.
2 If we stay in touch afterwards that’s fine too, but it’s not essential.
3 I’m looking for longer-form, but slower, communication than you get via e.g. instant
messengers and whatnot: a more “penpal” experience.
✅ To-Do:Obsidian, physical notepad [not happy with this; want something more productive]
📆 Calendar: Google Calendar (via Thunderbird on Desktop) [not happy with this; want something not-Google – still waiting on Proton Calendar getting good!]
A particular joy of the Gemini and Spartan protocols – and the Markdown-like syntax of Gemtext – is their simplicity.
The best way to explore Geminispace is with a browser like Lagrange browser, of course.
Even without a browser, you can usually use everyday command-line tools that you might have installed already to access relatively human-readable content.
Here are a few different command-line options that should show you a copy of this blog post (made available via CapsulePress, of course):
Gemini
Gemini communicates over a TLS-encrypted channel (like HTTPS), so we need a to use a tool that speaks the language. Luckily: unless you’re on Windows you’ve probably got one installed
already1.
Using OpenSSL
This command takes the full gemini:// URL you’re looking for and the domain name it’s at. 1965 refers to the port number on
which Gemini typically runs –
GnuTLS closes the connection when STDIN closes, so we use cat to keep it open. Note inclusion of --no-ca-verification to allow self-signed
certificates (optionally add --tofu for trust-on-first-use support, per the spec).
Spartan is a little like “Gemini without TLS“, but it sports an even-more-lightweight request format which makes it especially
easy to fudge requests2.
Using Telnet
Note the use of cat to keep the connection open long enough to get a response, as we did for Gemini over GnuTLS.
Because TLS support isn’t needed, this also works perfectly well with Netcat – just substitute nc/netcat or whatever your platform calls it in place of
ncat:
The Internet is full of guides on easily making your WordPress installation run fast. If you’re looking to speed up your WordPress site, you should go read those, not this.
Those guides often boil down to the same old tips:
uninstall unnecessary plugins,
optimise caching (both on the server and, via your headers, on clients/proxies),
resize your images properly and/or ensure WordPress is doing this for you,
This article is for people who aren’t afraid to go tinkering in their WordPress codebase to squeeze a little extra (real world!) performance.
It’s for people whose neverending quest for perfection is already well beyond the point of diminishing returns.
But mostly, it’s for people who want to gawp at me, the freak who actually did this stuff just to make his personal blog a tiny bit nippier without spending an extra penny on
hosting.
You shouldn’t use Lighthouse as your only measure of your site’s performance. But it’s still reassuring when you get to see those fireworks!
Don’t start with the hard way. Exhaust all the easy solutions – or at least, make a conscious effort which easy solutions to enact or reject – first. Only if you really
want to get into the weeds should you actually try doing the things I propose here. They’re not for most sites, and they’re not the for faint of heart.
Performance is a tradeoff. Every performance improvement costs you something else: time, money, DX, UX, etc. What you choose to trade for performance gains depends on your priority of constituencies, which may differ from mine.4
This is not a recipe book. This won’t tell you what code to change or what commands to run. The right answers for your content will be different than the right answers
for mine. Also: you shouldn’t change what you don’t understand! But I hope these tips will help you think about what questions you need to ask to make your site blazing fast.
Okay, let’s get started…
1. Backstab the plugins you can’t live without
If there are plugins you can’t remove because you depend upon their functionality, and those plugins inject content (especially JavaScript) on the front-end… backstab them to
undermine that functionality.
For example, if you want Jetpack‘s backup and downtime monitoring features, but you don’t want it injecting random <linkrel='stylesheet' id='...-jetpack-css' href='...' media='all' />‘s (an
extra stylesheet to download and parse) into your pages: find the add_filter hook it uses and remove_filter it in your theme5.
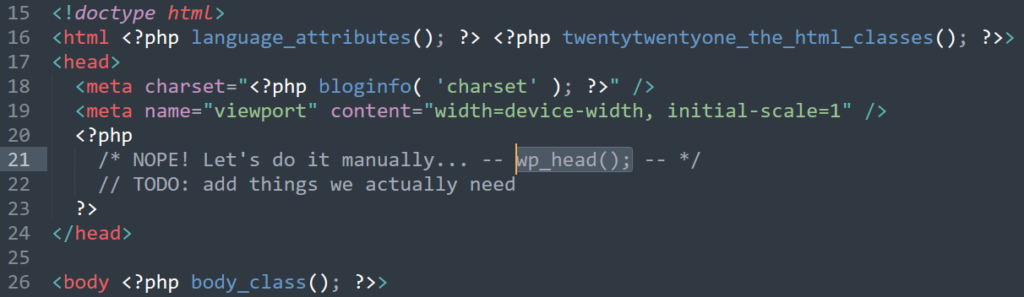
Alternatively, entirely remove the wp_head() and manually reimplement the functionality you actually need. Insert your own joke about “Headless WordPress” here.
Better yet, remove wp_head() from your theme entirely6.
Now, instead of blocking the hooks you don’t want polluting your <head>, you’re specifically allowing only those you want. You’ll want to take care to get
some semi-essential ones like <link rel="canonical" href="...">7.
Now most of your plugins are broken, but in exchange, your theme has reclaimed complete control over what gets sent to the user. You can select what content you actually
want delivered, and deliver no more than that. It’s harder work for you, but your site becomes so much lighter.
Your site is faster now. It doesn’t work, but it’s quick about it!
2. Throw away 100% of your render-blocking JavaScript (and as much as you can of the rest)
The single biggest bottleneck to the user viewing a modern WordPress website is the JavaScript that needs to be downloaded, compiled, and executed before the page can be rendered. Most
of that’s plugins, but even on a nearly-vanilla installation you might find a copy of jQuery (eww!) and some other files.
In step 1 you threw it all away, which is great… but I’m betting you were depending on some of that to make your site work? Let’s put it back, carefully and selectively, while
minimising the impact on load time.
That means scripts should be loaded (a) low-down, and/or (b) marked defer (or, better yet, async), so they don’t block page rendering.
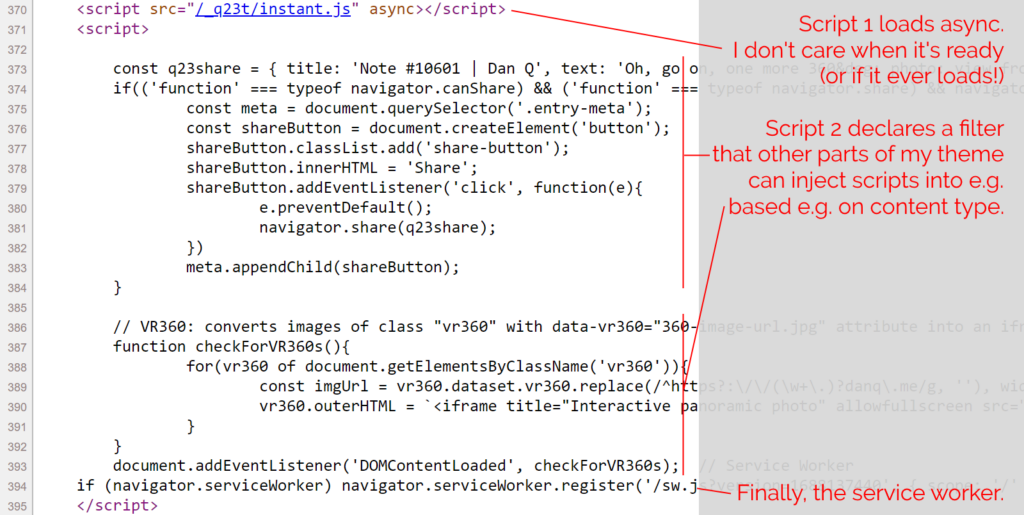
If you haven’t already, you might like to View Source on this page. Count my <script> tags. You’ll probably find just two of them: one external file marked
async, and a second block right at the bottom.
The only third-party script routinely loaded on danq.me is Instant.Page, which specifically exists to improve perceived performance. It preloads
links when you hover over or start-to-touch them.
The inline <script> in my footer.php wraps a single line of PHP: which looks a little like
this: <?php echo implode("\n\n", apply_filters( 'danq_footer_js', [] ) ); ?>. For each item in an initially-empty array, it appends to the script tag. When I render
anything that requires JavaScript, e.g. for 360° photography, I can just add to that
(keyed, to prevent duplicates when viewing an archive page) array. Thus, the relevant script gets added exclusively to the pages where it’s needed, not to the entire site.
The only inline script added to every page loads my service worker, which itself aims to optimise caching as well as providing limited “offline” functionality.
While you’re tweaking your JavaScript anyway, you might like to check that any suitable addEventListeners are set to passive mode. Especially if you’re doing anything with touch or
mousewheel events, you can often increase the perceived performance of these interactions by not letting your custom code block the default browser behaviour.
I promise you; most of your blog’s front-end JavaScript is either (a) garbage nobody wants, (b) polyfills for platforms nobody uses, or (c) huge libraries you’ve imported so you can
use just one or two functions form them. Trash them.
3. Don’t use a CDN
Wait, what? That’s the opposite of what everybody else recommends. To understand why, you have to think about why people recommend a CDN in the first place. Their reasons are usually threefold:
Proximity
Claim: A CDN delivers content geographically-closer to the user.
Retort: Often true. But in step 4 we’re going to make sure that everything critical comes within the first TCP
sliding window anyway, so there’s little benefit, and there’s a cost to that extra DNS lookup and fresh handshake. Edge
caching your own contentmay have value, but for most sites it’ll have a much smaller impact than almost everything else on this list.
Precaching
Claim: A CDN improves the chance resources are precached in the user’s browser.
Retort: Possibly true, especially with fonts (although see step 6) but less than you’d think with JS libraries because
there are so many different versions/hosts of each. Yours may well be the only site in the user’s circuit that uses a particular one!
Power Claim: A CDN has more resources than you and so can better-withstand spikes of traffic.
Retort: Maybe, but they also introduce an additional single-point-of-failure. CDNs aren’t magically immune
to downtime nor content-blocking, and if you depend on one you’ve just doubled the number of potential failure points that can make your site instantly useless. Furthermore:
in exchange for those resources you’re trading away your users’ privacy and security: if a CDN gets hacked, every site that
uses it gets hacked too.
Consider edge-caching your own content only if you think you need it, but ditch jsDeliver, cdnjs, Google Hosted Libraries etc.
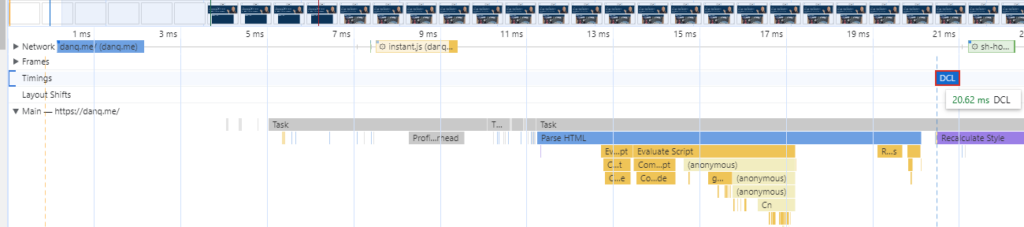
Despite having no edge cache and being hosted in a different country to me, I can open a completely fresh browser and reach DOMContentLoaded on the my homepage in ~20ms. You should learn how to read a
waterfall performance chart just so you can enjoy how “flat” mine is.
Hell: if you can, ditch all JavaScript served from third-parties and slap a Content-Security-Policy: script-src 'self' header on your domain to dramatically reduce
the entire attack surface of your site!8
4. Reduce your HTML and CSS size to <12kb compressed
There’s a magic number you need to know: 12kb. Because of some complicated but fascinating maths (and depending on how your hosting is configured), it can be significantly faster to
initially load a web resource of up to 12kb than it is to load one of, say, 15kb. Also, for the same reason, loading a web resource of much less than 12kb
might not be significantly faster than loading one only a little less than 12kb.
Inlining as much essential content as possible (CSS, SVGs,
JavaScript etc.) to bring you back up to close-to that magic number again!
$ curl --compressed -so /dev/null -w "%{size_download}\n" https://danq.me/
10416
Note that this is the compressed, over-the-wire size. Last I checked, my homepage weighed-in at about 10.4kb compressed, which includes the entirety of its HTML and CSS, most of its JS, and a
couple of its SVG images.
Again, this probably flies in the face of everything you were taught about performance. I’m sure you were told that you should <link> to your stylesheets so that they
can be cached across page loads. But it turns out that if you can make your HTML and CSS small enough, the opposite is true and you should inline the stylesheet again: caching styles becomes almost irrelevant if you get all the content in
a single round-trip anyway!
For extra credit, consider optimising your homepage’s CSS so it’s even smaller by excluding directives that only apply to
non-homepage pages, and vice-versa. Assuming you’re using a preprocessor, this shouldn’t be too hard: at simplest, you can have a homepage.css and main.css,
each derived from a set of source files some of which they share (reset/normalisation, typography, colours, whatever) and the rest which is specific only to that part of the site.
Most web pages should fit entirely onto a floppy disk. This one doesn’t, mostly because of all the Simpsons clips, but most should.
Can’t manage to get your HTML and CSS down below the magic
number? Then at least ensure that your HTML alone weighs in at <12kb compressed and you’ll still get some of the
benefits. If you’ve got the headroom, you can selectively include a <style> block containing only the most-crucial CSS, with a particular focus on any that results in layout shifts (e.g. anything that specifies the height: of otherwise dynamically-sized
block elements, or that declares an element position: absolute or position: fixed). These kinds of changes are relatively computationally-expensive because
they cause content to re-flow, so provide hints as soon as possible so that the browser can accommodate for them.
5. Make the first load awesome
We don’t really talk about content being “above the fold” like we used to, because the modern Web has such a diverse array of screen sizes and resolutions that doing so doesn’t make
much sense.
But if loading your full page is still going to take multiple HTTP requests (scripts, images, fonts, whatever),
you should still try to deliver the maximum possible value in the first round-trip. That means:
Making sure all your textual content loads immediately! Unless you’re delivering a huge amount of text, there’s absolutely no excuse for lazy-loading text: it’s
usually tiny, compresses well, and it’s fast to parse. It’s also the most-important content of most pages. Get it delivered to the browser so it can be rendered rightaway.
Reserving space for blocks by sizing images appropriately, e.g. using <img width="..." height="..." ...> or having them load as a background with
background-size: cover or contain in a block sized with CSS delivered in the initial payload. This
reduces layout shift, which mitigates the need for computationally-expensive content reflows.
If possible (see point 4), move vector images that support basic site functionality, like logos, inline. This might also apply to icons, if they’re “as important” as text content.
Marking everything up with standard semantic HTML. There’s a trend for component-driven design to go much too
far, resulting in JavaScript components being used in place of standard elements like links, buttons, and images, resulting in highly-fragile websites: when those scripts fail (or are
very slow to load), the page becomes unusable.
If you want to be sure you’re prioritising your content first and foremost, try disabling all CSS, JavaScript, and external
resources (or just access your site in a browser that ignores those things, like Lynx), and check that it’s still usable. As a bonus, this
helps you check for several accessibility issues.
6. Reduce your dependence on downloaded fonts
Fonts are lovely and can be an important part of your brand identity, but they can also add a lot of weight to your web pages.
If you’re ready and able to drop your webfonts and appreciate the beauty and flexibility of a system font stack (I get it: I’m not there quite yet!), you can at least make
smarter use of your fonts:
Every modern browser supports WOFF2, so you can ditch those chunky old formats you’re clinging onto.
If you’re only using the Latin alphabet, minify your fonts further by dropping the characters you don’t need: tools like Google Webfonts
Helper can help with this, as well as making it easier to selfhost fonts from the most-popular library (is a smart idea for the reasons described under point 3, above!). There are
tools available to further minify fonts if e.g. you only need the capital letters for your title font or something.
Browsers are pretty clever and will work-around it if you make a mistake. Didn’t include an emoji or some obscure mathematical symbol, and then accidentally used them in a
post? Browsers will switch to a system font that can fill in the gap, for you.
Make the most-liberal use of the font-display: CSS directive that you can tolerate!
Don’t use font-display: block, which is functionally the default in most browsers, unless you absolutely have to.
font-display: fallback is good if you’re too cowardly/think your font is too important for you to try font-display: optional.
font-display: optional is an excellent choice for body text: if the browser thinks it’s worthwhile to download the font (it might choose not to if the operating
system indicates that it’s using a metered or low-bandwidth connection, for example), it’ll try to download it, but it won’t let doing so slow things down too much and it’ll
fall-back to whatever backup (system) font you specify.
font-display: swap is also worth considering: this will render any text immediately, even if the right font hasn’t downloaded yet, with no blocking time
whatsoever, and then swap it for the right font when it appears. It’s probably better for headings, because large paragraphs of text can be a little disorienting if they change
font while a user is looking at them!
If writing is for nerds, then typography must be doubly-so. But you’ve read this far, so I’m confident that you qualify…
7. Cache pre-compressed static files
It’s possible that by this point you’re saying “if I had to do this much work, I might as well just use a static site generator”. Well good news: that’s what you’re about to
do!
Obviously you should make sure all your regular caching improvements (appropriate HTTP headers for caching, a
service worker that further improves on that logic based on your content’s update schedule, etc.) first. Again: everything in this guide presupposes that you’ve already done the things
that normal people do.
By aggressively caching pre-compressed copies of all your pages, you’re effectively getting the best of both worlds: a website that, for anonymous visitors, is served directly from
.html.gz files on a hard disk or even straight from RAM in memcached10,
but which still maintains all the necessary server-side interactivity to allow it to be used as a conventional Web-based CMS
(including accepting comments if that’s your jam).
WP Super Cache can do the heavy lifting for you for a filesystem-based solution so long as you put it into “Expert” mode and
amending your webserver configuration. I’m using Nginx, so I needed a try_files directive like this:
I’m sure your favourite performance testing tool has already complained at you about your failure to use the best formats possible when serving images to your users. But how can you fix
it?
There are some great plugins for improving your images automatically and/or in bulk – I use EWWW Image Optimizer – but
to really make the most of them you’ll want to reconfigure your webserver to detect clients that Accept: image/webp and attempt to dynamically
serve them .webp variants, for example. Or if you’re ready to give up on legacy formats and replace all your .pngs with .webps, that’s probably
fine too!
The image you see at https://danq.me/_q23u/2023/11/dynamic.png is probably an image/webp. But if your browser doesn’t support WebP, you’ll get an
image/png instead!
Assuming you’ve got curl and Imagemagick‘s identify, you can see this in action:
curl -s https://danq.me/_q23u/2023/11/dynamic.png -H "Accept: image/webp" | identify -
(Will give you a WebP image)
curl -s https://danq.me/_q23u/2023/11/dynamic.png -H "Accept: image/png" | identify -
(Will give you a PNG image, even though the URL is the same)
9. Simplify, simplify, simplify
The single biggest impact you can have upon the performance of your WordPress pages is to make them less complex.
You don’t have to go as light as Gemtext – like this page on Gemini does – to see
benefits.
Writing my templates and posts so that they’re compatible with CapsulePress helps keep my code necessarily-simple. You don’t have to
do that, though, but you should be asking yourself:
Does my DOM need to cascade so deeply? Could I achieve the same with less?
Am I pre-emptively creating content, e.g. adding a hidden <dialog> directly to the markup in the anticipation that it might be triggered later using
JavaScript, rather than having that JavaScript run document.createElement the element after the page becomes readable?
Have I created unnecessarily-long chains of CSS selectors11
when what I really want is a simple class name, or perhaps even a semantic element name?
10. Add a Service Worker
A service worker isn’t magic. In particular, it can’t help you with those new visitors hitting your site for the first time12.
A service worker lets you do smart things on behalf of the user’s network connection, so that by the time they ask for a resource, you already fetched it for them.
But a suitable service worker can do a few things that can help with performance. In particular, you might consider:
Precaching assets that you anticipate they’re likely to need (e.g. if you use different stylesheets for the homepage and other pages, you can preload both so no matter
where a user lands they’ve already got the CSS they’ll need for the entire site).
Preloading popular pages like the homepage and recent articles, allowing them to load quickly.
Caching a fallback pages – and other resources as-they’re-accessed – to support a full experience for users even if they (or your site!) disconnect from the Internet (or even
embedding “save for offline” functionality!).
Chapters 7 and 8 of Going Offline by Jeremy Keith are
especially good for explaining how this can be achieved, and it’s all much easier than everything else I just described.
Anything else?
Did I miss anything? If you’ve got a tip about ramping up WordPress performance that isn’t one of the “typical seven” – probably because it’s too hard to be worthwhile for most people –
I’d love to hear it!
Footnotes
1 You’ll sometimes see guides that suggest that using a CDN is to be recommended specifically because it splits your assets among multiple domains/subdomains, which mitigates browsers’ limitation on the
number of files they can download simultaneously. This is terrible advice, because such limitations essentially don’t exist any more, but DNS lookups and TLS handshakes still have a bandwidth and computational cost. There are good
things about CDNs, sometimes, but this has not been one of them for some time now.
2 I’m not sure why guides keep stressing the importance of minifying code,
because by the time you’re compressing them too it’s almost pointless. I guess it’s helpful if your compression fails?
3 “Use a faster server” is a “just throw money/the environment at it” solution. I’d like
to think we can do better.
4 For my personal blog, I choose to prioritise user experience, privacy, accessibility,
resilience, and standards compliance above almost everything else.
5 If you prefer to keep your backstab code separate, you can put it in a custom plugin,
but you might find that you have to name it something late in the alphabet – I’ve previously used names like zzz-danq-anti-plugin-hacks – to ensure that they load
after the plugins whose functionality you intend to unhook: broadly-speaking, WordPress loads plugins in alphabetical order.
6 I’ve assumed you’re using a classic, not block, theme. If you’re using a block theme,
you get a whole different set of performance challenges to think about. Don’t get me wrong: I love block themes and think they’re a great way to put more people in control of their
site’s design! But if you’re at the point where you’re comfortable digging this deep into your site’s PHP code,
you probably don’t need that feature anyway, right?
7 WordPress is really good at serving functionally-duplicate content, so search
engines appreciate it if you declare a proper canonical URL.
8 Before you choose to block all third-party JavaScript, you might have to
whitelist Google Analytics if you’re the kind of person who doesn’t mind selling their visitor data to the world’s biggest harvester of personal information in exchange for some
pretty graphs. I’m not that kind of person.
10 I’ve experimented with mounting a ramdisk and storing the WP Super Cache directory
there, but it didn’t make a huge difference, probably because my files are so small that the parse/render time on the browser side dominates the total cascade, and they’re already
being served from an SSD. I imagine in my case memcached would provide similarly-small benefits.
11 I really love the power of CSS preprocessors like Sass, but they do make it deceptively easy to create many more – and longer – selectors
than you intended in your final compiled stylesheet.
12 Tools like Lighthouse usually simulate first-time visitors, which can be a little
unfair to sites with great performance for established visitors. But everybody is a first-time visitor at least once (and probably more times, as caches expire or are
cleared), so they’re still a metric you should consider.
Conveniently just-over-A5 sized, each of the two volumes is light enough to read in bed without uncomfortably clonking yourself in the face.
Set in the early-to-mid-1990s world in which the BBS is still alive and kicking, and the Internet’s gaining traction but still
lacks the “killer app” that will someday be the Web (which is still new and not widely-available), the story follows a handful of teenagers trying to find their place in the world.
Meeting one another in the 90s explosion of cyberspace, they find online communities that provide connections that they’re unable to make out in meatspace.
I loved some of the contemporary nerdy references, like the fact that each chapter page sports the “Geek Code” of the character upon which that chapter focusses.1So yeah: the whole thing feels like a trip back into the naivety of the online world of the last millenium, where small, disparate (and often local) communities flourished and
early netiquette found its feet. Reading Incredible Doom provides the same kind of nostalgia as, say, an afternoon spent on textfiles.com. But
it’s got more than that, too.
The user interfaces of IRC, Pine, ASCII-art-laden BBS menus etc. are all produced with
a good eye for accuracy, but don’t be fooled: this is a story about humans, not computers. My 9-year-old loved it too, and she’s never even heard of IRC (I hope!).
It touches on experiences of 90s cyberspace that, for many of us, were very definitely real. And while my online “scene” at around the time that the story is set might have been
different from that of the protagonists, there’s enough of an overlap that it felt startlingly real and believable. The online world in which I – like the characters in the story – hung
out… but which occupied a strange limbo-space: both anonymous and separate from the real world but also interpersonal and authentic; a frontier in which we were still working out the
rules but within which we still found common bonds and ideals.
Having had times in the 90s that I met up offline with relative strangers whom I first met online, I can confirm that… yeah, the fear is real!
Anyway, this is all a long-winded way of saying that Incredible Doom is a lot of fun and if it sounds like your cup of tea, you should read it.
Also: shortly after putting the second volume down, I ended up updating my Geek Code for the first time in… ooh, well over a decade. The standards have moved on a little (not entirely
in a good way, I feel; also they’ve diverged somewhat), but here’s my attempt:
----- BEGIN GEEK CODE VERSION 6.0 -----
GCS^$/SS^/FS^>AT A++ B+:+:_:+:_ C-(--) D:+ CM+++ MW+++>++
ULD++ MC+ LRu+>++/js+/php+/sql+/bash/go/j/P/py-/!vb PGP++
G:Dan-Q E H+ PS++ PE++ TBG/FF+/RM+ RPG++ BK+>++ K!D/X+ R@ he/him!
----- END GEEK CODE VERSION 6.0 -----
Footnotes
1 I was amazed to discover that I could still remember most of my Geek Code
syntax and only had to look up a few components to refresh my memory.