You’ve probably come across GeoGuessr already: it’s an online game where you (and friends, if you’ve got them) get dropped into Google Street View and have two minutes to try to work out where in the world you are and drop a pin on it.
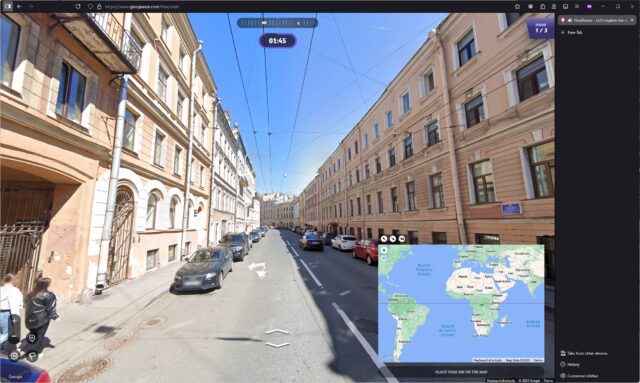
A great strategy is to “walk around” a little, looking for landmarks, phone numbers, advertisements, linguistic clues, cultural indicators, and so on, narrowing down the region of the world you think you’re looking at before committing to a country or even a city. You’re eventually scored by how close you are to the actual location.
Cheating at GeoGuessr
I decided to see if ChatGPT can do better than me. Using only the free tier of both GeoGuessr and ChatGPT1, I pasted screenshots of what I was seeing right into ChatGPT:

That’s pretty spooky, right?
The response came back plenty fast enough for me to copy-and-paste the suggested address into Google Maps, get the approximate location, and then drop a pin in the right place in GeoGuessr. It’s probably one of my most-accurate guesses ever.
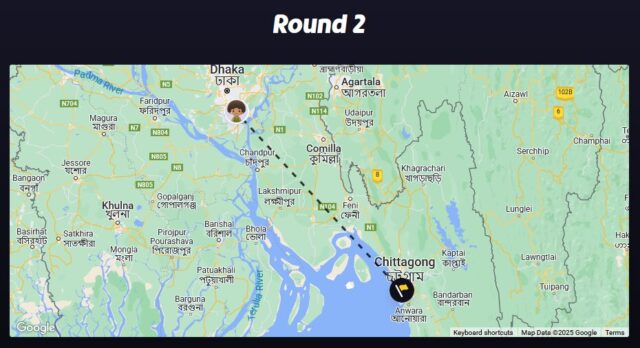
This isn’t a one-off fluke. I tried again, this time using only a single photo, rather than one pointing in each direction on the street:

This time, it wasn’t quite right: the actual location of the photo was Chittagong, not Dhaka, about 200km away.
But that’s still reasonably spectacular from only a single vantage from a single point.
Obviously my approach here was crude, but it’d be relatively easy to, for example, implement a browser wrapper that cheated on-your-behalf: while playing GeoGuessr, you’d just click a “send to AI” button whenever you fancied and it’d start working in the background, improving precision with each subsequent screenshot (so you could still “walk around” and pass extra details to it).
And similarly, a little prompt manipulation could have the output include estimated GPS coordinates, allowing the code to place the pin for you while outputting its reasoning on the side2.
The short of what I’m saying is: if you’re playing GeoGuessr against somebody you don’t trust not to cheat… they might well be cheating. And thanks to the explanatory output, they can even justify their explanations for the places they dropped pins.
What about other photos?
The other thought that comes to my mind is: could this be used to infer approximate geolocations from photos whose EXIF metadata has been stripped. Because if so, that’s the kind of thing that’s certain to get exploited by all kind of people who want to know where you are/were at a particular time. For example… law enforcement, stalkers, and other unsavoury types.
I wrote a prompt for gpt4o and put it to work:
1. Starting out easy

The AI guessed:
Location: Port of Spain, Trinidad and Tobago
Explanation: The photograph shows a large ship docked at a port with a building that displays the text “WELCOME TO PORT OF SPAIN”. This text is in English, indicating an English-speaking country. The mention of “Port of Spain” directly specifies the port’s location in the capital city of Trinidad and Tobago. The design and style of the port facilities, as well as the presence of a ship named “Logos Hope”, which is known to visit many ports globally, further suggests a Caribbean port, aligning with Port of Spain’s known characteristics.
Coordinates: 10.6549, -61.5011
✅ That was pretty easy, to be fair.
2. A little more challenging

The AI guessed:
Location: The Rollright Stones, England, United Kingdom
Explanation: The photograph depicts an area with several ancient standing stones arranged in a circle in a rural setting, characteristic of a stone circle. These are typically found in certain parts of the UK. The terrain is typical of the British countryside, with a grassy field and surrounding trees. The specific arrangement and size of the stones, along with the style of fencing and walking paths, are reminiscent of the Rollright Stones, one of Britain’s historic sites known for a circle of Neolithic or Bronze Age standing stones located in Oxfordshire, England.
Coordinates: 51.9743, -1.5731
✅ Again, spot on. If you’d never been to the Rollright Stones, you probably wouldn’t get that one, because while it’s a distinctive-looking stone circle… it’s not that distinctive-looking, right? Let’s be honest: it’s some rocks in a field.
3. Ramping up the difficulty

The AI guessed:
Location: Istanbul, Turkey
Explanation: The photograph prominently features the Galata Tower in the background, a well-known landmark in Istanbul, Turkey. Moreover, the presence of a ferry or similar boat and the architectural style of the surrounding buildings are indicative of Istanbul’s famous skyline. The signage in Turkish, as suggested by the word partially visible on the left, also supports this location as Turkey is a predominantly Turkish-speaking country. These elements combined make it highly likely that the photograph was taken in Istanbul.
Coordinates: 41.0082, 28.9784
✅ The coordinates aren’t exactly right – it’s placed us in the city rather than on a boat, which we clearly are – but it’s not done badly. Spotting the Galata Tower3 was a nice move.
4. Okay, now hard mode:

The AI guessed:
Location: Cardiff Bay, Cardiff, Wales, United Kingdom
Explanation: The photograph features a marina with modern residential buildings, which is characteristic of the Cardiff Bay area in Cardiff, Wales. The architecture, clear blue skies, and marina setting are reminiscent of Cardiff’s waterfront development. Additionally, the presence of English signage on the boat (“FINBAR”) supports a location in an English-speaking country. Cardiff Bay is known for its redeveloped waterfront area with modern apartments and leisure facilities surrounding the marina. The style and design of the building are consistent with developments in Cardiff’s revitalized docklands.
Coordinates: 51.4626, -3.1678
❌ Oops! Nope. I can see the thinking of what it’s claiming, there, but this was actually the Ipswich marina. I went for a walk to take a break from the code I’d been writing and took this somewhere in the vicinity of the blue plaque for Edward Ardizzone that I’d just spotted (I was recording a video for my kids, who’ve enjoyed several of his Tim… books).
So I don’t think this is necessarily a game-changer for Internet creeps yet. So long as you’re careful not to post photos in which you’re in front of any national monuments and strip your EXIF metadata as normal, you’re probably not going to give away where you are quite yet.
Footnotes
1 And in a single-player game only: I didn’t actually want to cheat anybody out of a legitimate victory!
2 I’m not going to implement GeoCheatr, as I’d probably name it. Unless somebody feels like paying me to do so: I’m open for freelance work right now, so if you want to try to guarantee the win at the GeoGuessr World Championships (which will involve the much-riskier act of cheating in person, so you’ll want a secret UI – I’m thinking a keyboard shortcut to send data to the AI, and an in-ear headphone so it can “talk” back to you?), look me up? (I’m mostly kidding, of course: just because something’s technically-possible doesn’t mean it’s something I want to do, even for your money!)
3 Having visited the Galata Tower I can confirm that it really is pretty distinctive.
4 3Camp is Three Rings‘ annual volunteer get-together, hackathon, and meetup. People come together for an intensive week of making-things-better for charities the world over.