A freaking excellent longread by Eevee (Evelyn Woods), lamenting the direction of popular technological progress and general enshittification of creator culture. It’s ultimately
uplifting, I feel, but it’s full of bitterness until it gets there. I’ve pulled out a couple of highlights to try to get you interested, but you should just go and read the entire thing:
…
And so the entire Web sort of congealed around a tiny handful of gigantic platforms that everyone on the fucking planet is on at once. Sometimes there is some sort of
partitioning, like Reddit. Sometimes there is not, like Twitter.
That’s… fine, I guess. Things centralize. It happens. You don’t get tubgirl spam raids so much any more, at least.
But the centralization poses a problem. See, the Web is free to look at (by default), but costs money to host. There are free hosts, yes, but those are for static
things getting like a thousand visitors a day, not interactive platforms serving a hundred million. That starts to cost a bit. Picture logs being shoveled into a steam
engine’s firebox, except it’s bundles of cash being shoveled into… the… uh… website hole.
…
I don’t want to help someone who opens with “I don’t know how to do this so I asked ChatGPT and it gave me these 200 lines but it doesn’t work”. I don’t want to know how much code
wasn’t actually written by anyone. I don’t want to hear how many of my colleagues think Whatever is equivalent to their own output.
…
I glimpsed someone on Twitter a few days ago, also scoffing at the idea that anyone would decide not to use the Whatever machine. I can’t remember exactly what they said,
but it was something like: “I created a whole album, complete with album art, in 3.5 hours. Why wouldn’t I use the make it easier machine?”
This is kind of darkly fascinating to me, because it gives rise to such an obvious question: if anyone can do that, then why listen to your music? It takes a
significant chunk of 3.5 hours just to listen to an album, so how much manual work was even done here? Apparently I can just go generate an endless stream of stuff of the
same quality! Why would I want your particular brand of Whatever?
Nobody seems to appreciate that if you can make a computer do something entirely on its own, then that becomes the baseline.
…
Do things. Make things. And then put them on your website so I can see them.
Clearly this all ties in to stuff that I’ve been thinking, lately. Expect more
posts and reposts in this vein, I guess?
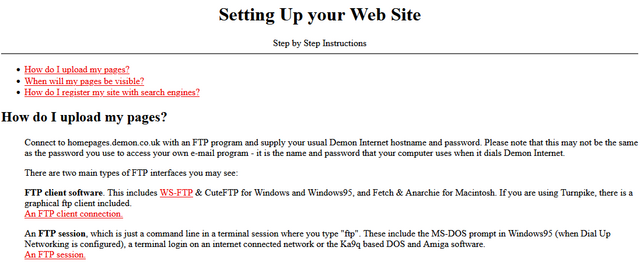
Do you remember when your domestic ISP – Internet Service Provider – used to be an Internet Services Provider? They
were only sometimes actually called that, but what I mean is: when ISPs provided more than one Internet service? Not just connectivity, but… more.
One of the first ISPs I subscribed to had a “standard services” list longer than most modern ISPs complete services list!
ISPs twenty years ago
It used to just be expected that your ISP would provide you with not only an Internet connection, but also some or all of:
I don’t remember which of my early ISPs gave me a free license for HoTMetaL Pro, but I was very appreciative of it at the time.
ISPs today
The ISP I hinted at above doesn’t exist any more, after being bought out and bought out and bought out by a series of owners. But I checked the Website of the current owner to see what
their “standard services” are, and discovered that they are:
Optional 4G backup connectivity (for an extra fee)
A voucher for 3 months access to a streaming service3
The connection is faster, which is something, but we’re still talking about the “baseline” for home Internet access then-versus-now. Which feels a bit galling, considering that (a)
you’re clearly, objectively, getting fewer services, and (b) you’re paying more for them – a cheap basic home Internet subscription today, after accounting
for inflation, seems to cost about 25% more than it did in 2000.4
Are we getting a bum deal?
Not every BBS nor ISP would ever come to support the blazing speeds of a 33.6kbps modem… but when you heard the distinctive scream of its negotiation at close to the Shannon Limit of
the piece of copper dangling outside your house… it felt like you were living in the future.
Would you even want those services?
Some of them were great conveniences at the time, but perhaps not-so-much now: a caching server, FTP site, or IRC node in the building right at the end of my
dial-up connection? That’s a speed boost that was welcome over a slow connection to an unencrypted service, but is redundant and ineffectual today. And if you’re still using a
fax-to-email service for any purpose, then I think you have bigger problems than your ISP’s feature list!
Some of them were things I wouldn’t have recommend that you depend on, even then: tying your email and Web hosting to your connectivity provider traded
one set of problems for another. A particular joy of an email address, as opposed to a postal address (or, back in the day, a phone number), is that it isn’t tied to where
you live. You can move to a different town or even to a different country and still have the same email address, and that’s a great thing! But it’s not something you can
guarantee if your email address is tied to the company you dial-up to from the family computer at home. A similar issue applies to Web hosting, although for a true traditional “personal
home page”: a little information about yourself, and your bookmarks, it would be fine.
But some of them were things that were actually useful and I miss: honestly, it’s a pain to have to use a third-party service for newsgroup
access, which used to be so-commonplace that you’d turn your nose up at an ISP that didn’t offer it as standard. A static IP being non-standard on fixed connections is a sad reminder
that the ‘net continues to become less-participatory, more-centralised, and just generally more watered-down and shit: instead of your connection making you “part of” the Internet,
nowadays it lets you “connect to” the Internet, which is a very different experience.5
A page like this used to be absolutely standard on the Website6
of any ISP worth its salt.
Yeah, sure, you can set up a static site (unencumbered by any opinionated stack) for free on Github Pages, Neocities, or wherever, but the barrier to entry has been raised
by just enough that, doubtless, there are literally millions of people who would have taken that first step… but didn’t.
And that makes me sad.
Footnotes
1 ISP-provided shared FTP servers would also frequently provide locally-available copies
of Internet software essentials for a variety of platforms. This wasn’t just a time-saver – downloading Netscape Navigator from your ISP rather than from half-way across the world was
much faster! – it was also a way to discover new software, curated by people like you: a smidgen of the feel of a well-managed BBS, from the comfort of your local ISP!
2 ISP-provided routers are, in my experience, pretty crap 50% of the time… although
they’ve been improving over the last decade as consumers have started demanding that their WiFi works well, rather than just works.
3 These streaming services vouchers are probably just a loss-leader for the streaming
service, who know that you’ll likely renew at full price afterwards.
4 Okay, in 2000 you’d have also have had to pay per-minute for the price of the
dial-up call… but that money went to BT (or perhaps Mercury or KCOM), not to your ISP. But my point still stands: in a world where technology has in general gotten cheaper
and backhaul capacity has become underutilised, why has the basic domestic Internet connection gotten less feature-rich and more-expensive? And often with worse
customer service, to boot.
5 The problem of your connection not making you “part of” the Internet is multiplied if
you suffer behind carrier-grade NAT, of course. But it feels like if we actually cared enough to commit to rolling out IPv6 everywhere we could obviate the need for that particular
turd entirely. And yet… I’ll bet that the ISPs who currently use it will continue to do so, even as the offer IPv6 addresses as-standard, because they buy into their own idea that
it’s what their customers want.
6 I think we can all be glad that we no longer write “Web Site” as two separate words, but
you’ll note that I still usually correctly capitalise Web (it’s a proper noun: it’s the Web, innit!).
Some time in the last 25 years, ISPs stopped saying they made you “part of” the Internet, just that they’d help you “connect to” the Internet.
Most people don’t need a static IP, sure. But when ISPs stopped offering FTP and WWW hosting as a standard feature (shit though it often was), they became part of the tragic process by
which the Internet became centralised, and commoditised, and corporate, and just generally watered-down.
The amount of effort to “put something online” didn’t increase by a lot, but it increased by enough that millions probably missed-out on the opportunity to create
their first homepage.
I wanted a way to simultaneously lock all of the computers – a mixture of Linux, MacOS and Windows boxen – on my desk, when I’m
going to step away. Here’s what I came up with:
There’s optional audio in this video, if you want it.
One button. And everything locks. Nice!
Here’s how it works:
The mini keyboard is just 10 cheap mechanical keys wired up to a CH552 chip. It’s configured to send CTRL+ALT+F13 through
CTRL+ALT+F221
when one of its keys are pressed.
The “lock” key is captured by my KVM tool Deskflow (which I migrated to when Barrier became neglected, which in turn I migrated to when I fell out of love with Synergy). It then relays
this hotkey across to all currently-connected machines2.
That shortcut is captured by each recipient machine in different ways:
The Linux computers run LXDE, so I added a line to /etc/xdg/openbox/rc.xml to set a <keybind> that executes xscreensaver-command
-lock.
For the Macs, I created a Quick Action in Automator that runs pmset displaysleepnow as a shell script3, and then connected that via
Keyboard Shortcuts > Services.
On the Windows box, I’ve got AutoHotKey running anyway, so I just have it run { DllCall("LockWorkStation") } when it hears
the keypress.
That’s all there is to is! A magic “lock all my computers, I’m stepping away” button, that’s much faster and more-convenient than locking two to five computers individually.
Footnotes
1F13 through F24 are absolutely valid “standard” key assignments,
of course: it’s just that the vast majority of keyboards don’t have keys for them! This makes them excellent candidates for non-clashing personal-use function keys, but I like to
append one or more modifier keys to the as well to be absolutely certain that I don’t interact with things I didn’t intend to!
2 Some of the other buttons on my mini keyboard are mapped to “jumping” my cursor to
particular computers (if I lose it, which happens more often than I’d like to admit), and “locking” my cursor to the system it’s on.
3 These boxes are configured to lock as soon as the screen blanks; if yours don’t then you
might need a more-sophisticated script.
This was an enjoyable video. Nothing cutting-edge, but a description of an imaginative use of an everyday algorithm – DEFLATE, which
is what powers most of the things you consider “ZIP files” – to do pattern-matching and comparison between two files. The tl;dr is pretty simple:
Lossless compression works by looking for repetition, and replacing the longest/most-repeated content with references to a lookup table.
Therefore, the reduction-in-size from compressing a file is an indicator of the amount of repetition within it.
Therefore, the difference in reduction-in-size of compressing a single file to the reduction-in-size of compressing a pair of files is indicative of
their similarity, because the greatest compression gains come from repetition of data that is shared across both files.
This can be used, for example, to compare the same document written in two languages as an indication of the similarity of the languages to one another, or to compare the genomes of
two organisms as an indication of their genetic similarity (and therefore how closely-related they are).
I love it when somebody finds a clever and novel use for an everyday tool.
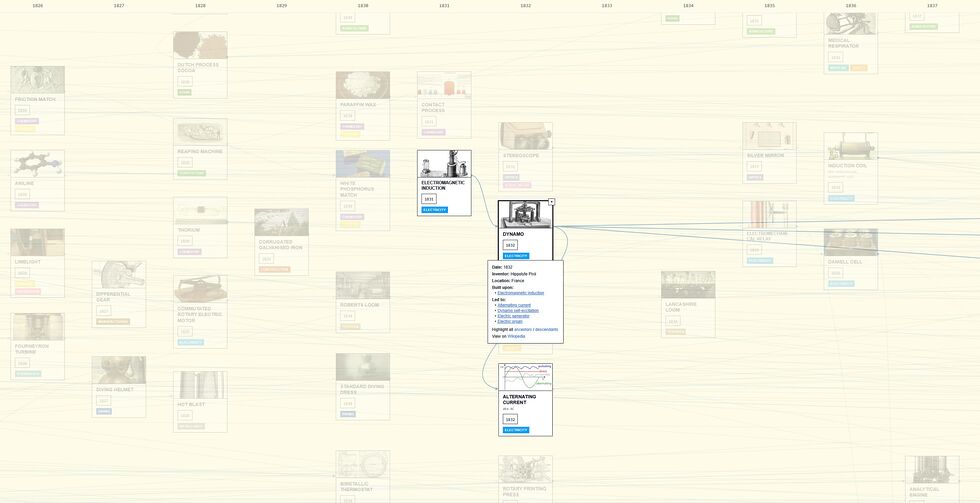
This wonderful project, released six weeks ago, attempts the impossible challenge of building a Civilization-style tech tree but chronicling the development and interplay
of all of the actual technological innovations humanity has ever made. Even in its inevitably-incomplete state, it’s inspiring and informative. Or, as Open Culture put it:
Our civilization has made its way from stone tools to robotaxis, mRNA vaccines, and LLM chatbots; we’d all be better able to inhabit it with even a slightly clearer idea of how it
did so.
I was updating my CV earlier this week in anticipation of applying for a handful of interesting-looking roles1
and I was considering quite how many different tech stacks I claim significant experience in, nowadays.
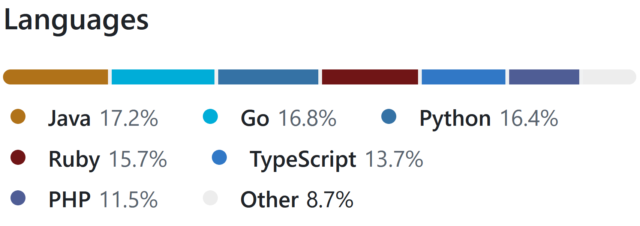
There are languages I’ve been writing in every single week for the last 15+ years, of course, like PHP, Ruby, and JavaScript. And my underlying fundamentals are solid.
But is it really fair for me to be able to claim that I can code in Java, Go, or Python: languages that I’ve not used commercially within the last 5-10 years?
What kind of developer writes the same program six times… for a tech test they haven’t even been asked to do? If you guessed “Dan”, you’d be correct!
Obviously, I couldn’t just let that question lie2.
Let’s find out!
I fished around on Glassdoor for a bit to find a medium-sized single-sitting tech test, and found a couple of different briefs that I mashed together to create this:
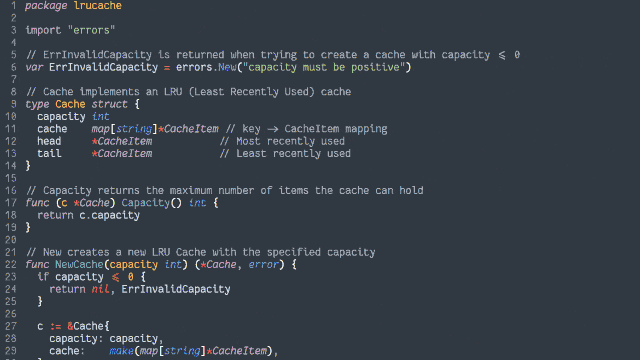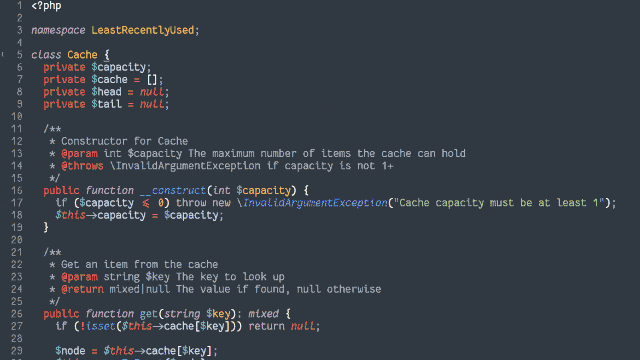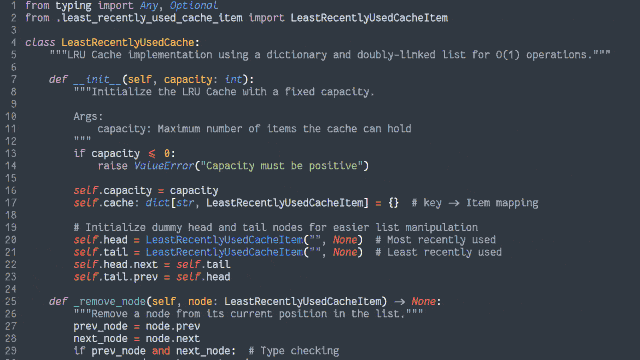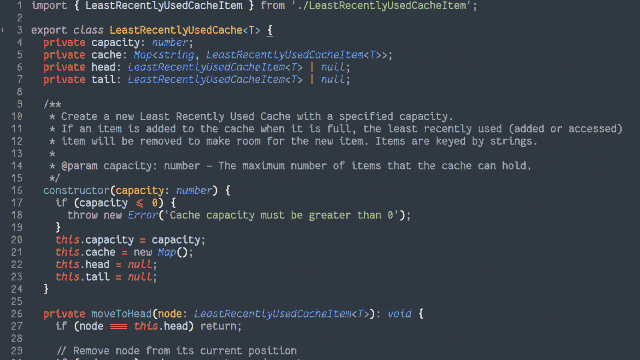
In an object-oriented manner, implement an LRU (Least-Recently Used) cache:
The size of the cache is specified at instantiation.
Arbitrary objects can be put into the cache, along with a retrieval key in the form of a string. Using the same string, you can get the objects back.
If a put operation would increase the number of objects in the cache beyond the size limit, the cached object that was least-recently accessed (by either a
put or get operation) is removed to make room for it.
putting a duplicate key into the cache should update the associated object (and make this item most-recently accessed).
Both the get and put operations should resolve within constant (O(1)) time.
Add automated tests to support the functionality.
My plan was to implement a solution to this challenge, in as many of the languages mentioned on my CV as possible in a single sitting.
But first, a little Data Structures & Algorithms theory:
The Theory
Simple case with O(n) complexity
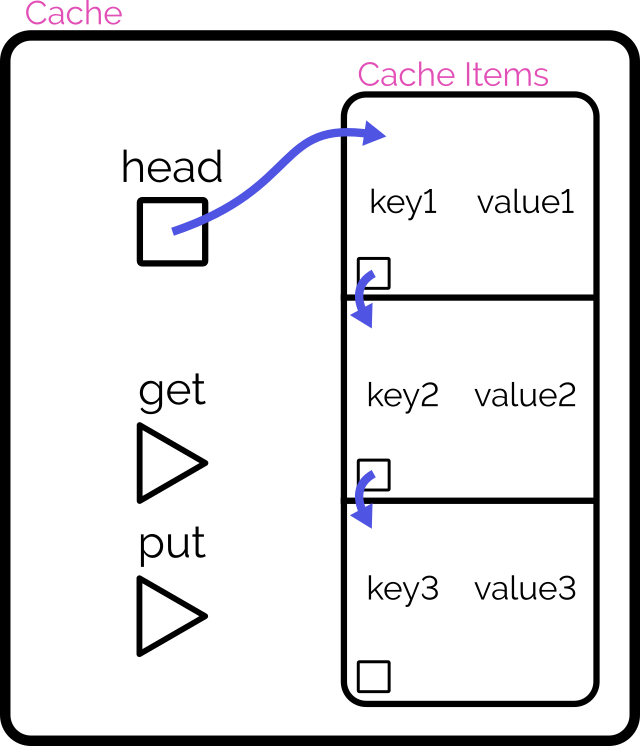
The simplest way to implement such a cache might be as follows:
Use a linear data structure like an array or linked list to store cached items.
On get, iterate through the list to try to find the matching item.
If found: move it to the head of the list, then return it.
On put, first check if it already exists in the list as with get:
If it already exists, update it and move it to the head of the list.
Otherwise, insert it as a new item at the head of the list.
If this would increase the size of the list beyond the permitted limit, pop and discard the item at the tail of the list.
It’s simple, elegant and totally the kind of thing I’d accept if I were recruiting for a junior or graduate developer. But we can do better.
The problem with this approach is that it fails the requirement that the methods “should resolve within constant (O(1)) time”3.
Of particular concern is the fact that any operation which might need to re-sort the list to put the just-accessed item at the top
4. Let’s try another design:
Achieving O(1) time complexity
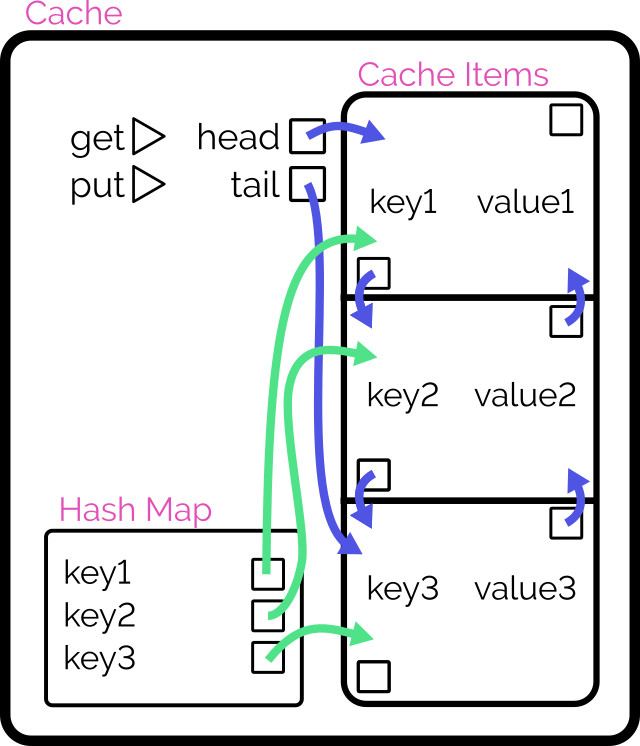
Here’s another way to implement the cache:
Retain cache items in a doubly-linked list, with a pointer to both the head and tail
Add a hash map (or similar language-specific structure) for fast lookups by cache key
On get, check the hash map to see if the item exists.
If so, return it and promote it to the head (as described below).
On put, check the hash map to see if the item exists.
If so, promote it to the head (as described below).
If not, insert it at the head by:
Updating the prev of the current head item and then pointing the head to the new item (which will have the old head item as its
next), and
Adding it to the hash map.
If the number of items in the hash map would exceed the limit, remove the tail item from the hash map, point the tail at the tail item’s prev, and
unlink the expired tail item from the new tail item’s next.
To promote an item to the head of the list:
Follow the item’s prev and next to find its siblings and link them to one another (removes the item from the list).
Point the promoted item’s next to the current head, and the current head‘s prev to the promoted item.
Point the head of the list at the promoted item.
Looking at a plate of pointer-spaghetti makes me strangely hungry.
It’s important to realise that this alternative implementation isn’t better. It’s just different: the “right” solution depends on the use-case5.
The Implementation
That’s enough analysis and design. Time to write some code.
Turns out that if you use enough different languages in your project, GitHub begins to look like itwants to draw a rainbow.
Picking a handful of the more-useful languages on my CV6,
I opted to implement in:
Ruby (with RSpec for testing and Rubocop for linting)
PHP (with PHPUnit for testing)
TypeScript (running on Node, with Jest for testing)
Java (with JUnit for testing)
Go (which isn’t really an object-oriented language but acts a bit like one, amirite?)
Python (probably my weakest language in this set, but which actually ended up with quite a tidy solution)
Naturally, I open-sourced everything if you’d like to see for yourself. It all works, although if you’re actually in need of such a
cache for your project you’ll probably find an alternative that’s at least as good (and more-likely to be maintained!) in a third-party library somewhere!
What did I learn?
This was actually pretty fun! I might continue to expand my repo by doing the same challenge with a few of the other languages I’ve used professionally at some point or
another7.
And there’s a few takeaways I got from this experience –
Lesson #1: programming more languages can make you better at all of them
As I went along, one language at a time, I ended up realising improvements that I could make to earlier iterations.
For example, when I came to the TypeScript implementation, I decided to use generics so that the developer can specify what kind of objects they want to store in the cache,
rather than just a generic Object, and better benefit type-safety. That’s when I remembered that Java supports generics, too, so I went back and used them there as well.
In the same way as speaking multiple (human) languages or studying linguistics can help unlock new ways of thinking about your communication, being able to think in terms of multiple
different programming languages helps you spot new opportunities. When in 2020 PHP 8 added nullsafe operators, union types, and
named arguments, I remember feeling confident using them from day one because those features were already familiar to me from Ruby8, TypeScript9, and Python10,
respectively.
Lesson #2: even when I’m rusty, I can rely on my fundamentals
I’ve applied for a handful of jobs now, but if one of them had invited me to a pairing session on a language I’m rusty on (like Java!) I might’ve felt intimidated.
But it turns out I shouldn’t need to be! With my solid fundamentals and a handful of other languages under my belt, I understand when I need to step away from the code editor and hit
the API documentation. Turns out, I’m in a good position to demo any of my language skills.
I remember when I was first learning Go, I wanted to make use of a particular language feature that I didn’t know whether it had. But because I’d used that feature in Ruby, I knew what
to search for in Go’s documentation to see if it was supported (it wasn’t) and if so, what the syntax was11.
Lesson #3: structural rules are harder to gearshift than syntactic ones
Switching between six different languages while writing the same application was occasionally challenging, but not in the ways I expected.
I’ve had plenty of experience switching programming languages mid-train-of-thought before. Sometimes you just have to flit between the frontend and backend of your application!
But this time around I discovered: changes in structure are apparently harder for my brain than changes in syntax. E.g.:
Switching in and out of Python’s indentation caught me out at least once (might’ve been better if I took the time to install the language’s tools into my text editor first!).
Switching from a language without enforced semicolon line ends (e.g. Ruby, Go) to one with them (e.g. Java, PHP) had me make the compiler sad several times.
This gets even tougher when not writing the language but writing about the language: my first pass at the documentation for the Go version somehow ended up with
Ruby/Python-style #-comments instead of Go/Java/TypeScript-style //-comments; whoops!
I’m guessing that the part of my memory that looks after a language’s keywords, how a method header is structured, and which equals sign to use for assignment versus comparison… are
stored in a different part of my brain than the bit that keeps track of how a language is laid-out?12
Okay, time for a new job
I reckon it’s time I got back into work, so I’m going to have a look around and see if there’s any roles out there that look exciting to me.
If you know anybody who’s looking for a UK-based, remote-first, senior+, full-stack web developer with 25+ years experience and more languages than you can shake a stick at… point them at my CV, would you?
Footnotes
1 I suspect that when most software engineers look for a new job, they filter to the
languages, frameworks, they feel they’re strongest at. I do a little of that, I suppose, but I’m far more-motivated by culture, sector, product and environment than I am by the shape
of your stack, and I’m versatile enough that technology specifics can almost come second. So long as you’re not asking me to write VB.NET.
2 It’s sort-of a parallel to how I decided to check
the other week that my Gutenberg experience was sufficiently strong that I could write standard ReactJS, too.
3 I was pleased to find a tech test that actually called for an understanding of algorithm
growth/scaling rates, so I could steal this requirement for my own experiment! I fear that sometimes, in their drive to be pragmatic and representative of “real work”, the value of a
comprehension of computer science fundamentals is overlooked by recruiters.
4 Even if an algorithm takes the approach of creating a new list with the
inserted/modified item at the top, that’s still just a very-specific case of insertion sort when you think about it, right?
5 The second design will be slower at writing but faster at
reading, and will scale better as the cache gets larger. That sounds great for a read-often/write-rarely cache, but your situation may differ.
6 Okay, my language selection was pretty arbitrary. But if I’d have also come up with
implementations in Perl, and C#, and Elixir, and whatever else… I’d have been writing code all day!
7 So long as I’m willing to be flexible about the “object-oriented” requirement, there are
even more options available to me. Probably the language that I last wrote longest ago would be Pascal: I wonder how much of that I remember?
8 Ruby’s safe navigation/”lonely” operator did the same thing as PHP’s nullsafe operator
since 2015.
9 TypeScript got union types back in 2015, and apart from them being more-strictly-enforced they’re basically identical to
PHP’s.
10 Did you know that Python had keyword arguments since its very first public release
way back in 1994! How did it take so many other interpreted languages so long to catch up?
11 The feature was the three-way comparison or “spaceship operator”, in case you were wondering.
12 I wonder if anybody’s ever laid a programmer in an MRI machine while they code? I’d
be really interested to see if different bits of the brain light up when coding in functional programming languages than in procedural ones, for example!
I’d like to nominate DB13W3 for Most Cursed Connector. I mean, just look at that thing!
Bonus: there were at least two different, incompatible, pinout “standards” for this thing, so there was no guarantee that a random monitor with this cable would connect to your
workstation, even if it had the right port.
The fundamental difference between streaming and downloading is what your device does with those frames of video:
Does it show them to you once and then throw them away? Or does it re-assemble them all back into a video file and save it into storage?
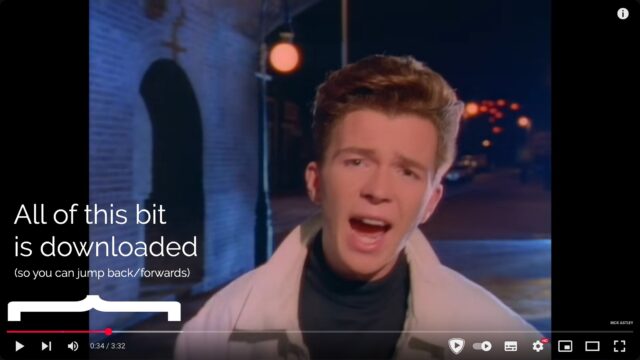
When you’re streaming on YouTube, the video player running on your computer retains a buffer of frames ahead and behind of your current position, so you can skip around easily: the
darker grey part of the timeline shows which parts of the video are stored on – that is, downloaded to – your computer.
Buffering is when your streaming player gets some number of frames “ahead” of where you’re watching, to give you some protection against connection issues. If your WiFi wobbles
for a moment, the buffer protects you from the video stopping completely for a few seconds.
But for buffering to work, your computer has to retain bits of the video. So in a very real sense, all streaming is downloading! The buffer is the part
of the stream that’s downloaded onto your computer right now. The question is: what happens to it next?
All streaming is downloading
So that’s the bottom line: if your computer deletes the frames of video it was storing in the buffer, we call that streaming. If it retains them in a file, we
call that downloading.
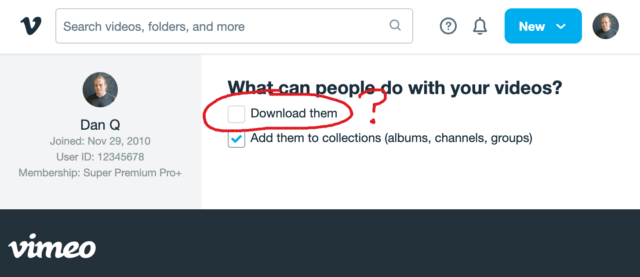
That definition introduces a philosophical problem. Remember that Vimeo checkbox that lets a creator decide whether people can (i.e. are allowed to) download their videos? Isn’t
that somewhat meaningless if all streaming is downloading.
Because if the difference between streaming and downloading is whether their device belonging to the person watching the video deletes the media when they’re done. And in
virtually all cases, that’s done on the honour system.
This kind of conversation happens, over the HTTP protocol, all the time. Probably most of the time the browser is telling the truth, but there’s no way to know for certain.
When your favourite streaming platform says that it’s only possible to stream, and not download, their media… or when they restrict “downloading” as an option to higher-cost paid plans…
they’re relying on the assumption that the user’s device can be trusted to delete the media when the user’s done watching it.
But a user who owns their own device, their own network, their own screen or speakers has many, many opportunities to not fulfil the promise of deleting media it after they’ve consumed
it: to retain a “downloaded” copy for their own enjoyment, including:
Intercepting the media as it passes through their network on the way to its destination device
Using client software that’s been configured to stream-and-save, rather than steam-and-delete, the content
Modifying “secure” software (e.g. an official app) so that it retains a saved copy rather than deleting it
Capturing the stream buffer as it’s cached in device memory or on the device’s hard disk
Outputting the resulting media to a different device, e.g. using a HDMI capture device, and saving it there
Exploiting the “analogue4
hole”5:
using a camera, microphone, etc. to make a copy of what comes out of the screen/speakers6
Okay, so I oversimplified (before you say “well, actually…”)
It’s not entirely true to say that streaming and downloading are identical, even with the caveat of “…from the server’s perspective”. There are three big exceptions worth
thinking about:
Exception #1: downloads can come in any order
When you stream some linear media, you expect the server to send the media in strict chronological order. Being able to start watching before the whole file has
downloaded is a big part of what makes steaming appealing, to the end-user. This means that media intended for streaming tends to be stored in a way that facilitates that
kind of delivery. For example:
Media designed for streaming will often be stored in linear chronological order in the file, which impacts what kinds of compression are available.
Media designed for streaming will generally use formats that put file metadata at the start of the file, so that it gets delivered first.
Video designed for streaming will often have frequent keyframes so that a client that starts “in the middle” can decode the buffer without downloading too much data.
No such limitation exists for files intended for downloading. If you’re not planning on watching a video until it’s completely downloaded, the order in which the chunks arrives is
arbitrary!
But these limitations make the set of “files suitable for streaming” a subset of the set of “files suitable for downloading”. It only makes it challenging or impossible to
stream some media intended for downloading… it doesn’t do anything to prevent downloading of media intended for streaming.
Exception #2: streamed media is more-likely to be transcoded
A server that’s streaming media to a client exists in a sort-of dance: the client keeps the server updated on which “part” of the media it cares about, so the server can jump ahead,
throttle back, pause sending, etc. and the client’s buffer can be kept filled to the optimal level.
This dance also allows for a dynamic change in quality levels. You’ve probably seen this happen: you’re watching a video on YouTube and suddenly the quality “jumps” to something more
(or less) like a pile of LEGO bricks7. That’s the result of your device realising that the rate
at which it’s receiving data isn’t well-matched to the connection speed, and asking the server to send a different quality level8.
The server can – and some do! – pre-generate and store all of the different formats, but some servers will convert files (and particularly livestreams) on-the-fly, introducing
a few seconds’ delay in order to deliver the format that’s best-suited to the recipient9. That’s not necessary for downloads, where the
user will often want the highest-quality version of the media (and if they don’t, they’ll select the quality they want at the outset, before the download begins).
Exception #3: streamed media is more-likely to be encumbered with DRM
And then, of course, there’s DRM.
As streaming digital media has become the default way for many people to consume video and audio content, rights holders have engaged in a fundamentally-doomed10
arms race of implementing copy-protection strategies to attempt to prevent end-users from retaining usable downloaded copies of streamed media.
Take HDCP, for example, which e.g. Netflix use for their 4K streams. To download these streams, your device has to be running some decryption code that only works if it can trace a path
to the screen that it’ll be outputting to that also supports HDCP, and both your device and that screen promise that they’re definitely only going to show it and not make it
possible to save the video. And then that promise is enforced by Digital Content Protection LLC only granting a decryption key and a license to use it to manufacturers.11
The real hackers do stuff with software, but people who just want their screens to work properly in spite of HDCP can just buy boxes like this (which I bought for a couple of quid on
eBay). Obviously you could use something like this and a capture card to allow you to download content that was “protected” to ensure that you could only stream it, I suppose, too.
Anyway, the bottom line is that all streaming is, by definition, downloading, and the only significant difference between what people call “streaming” and
“downloading” is that when “streaming” there’s an expectation that the recipient will delete, and not retain, a copy of the video. And that’s it.
Footnotes
1 This isn’t the question I expected to be answering. I made the animation in this post
for use in a different article, but that one hasn’t come together yet, so I thought I’d write about the technical difference between streaming and downloading as an excuse to
use it already, while it still feels fresh.
2 I’m using the example of a video, but this same principle applies to any linear media
that you might stream: that could be a video on Netflix, a livestream on Twitch, a meeting in Zoom, a song in Spotify, or a radio show in iPlayer, for example: these are all examples
of media streaming… and – as I argue – they’re therefore also all examples of media downloading because streaming and downloading are fundamentally the same thing.
3 There are a few simplifications in the first half of this post: I’ll tackle them later
on. For the time being, when I say sweeping words like “every”, just imagine there’s a little footnote that says, “well, actually…”, which will save you from feeling like you have to
say so in the comments.
4 Per my style guide, I’m using the British English
spelling of “analogue”, rather than the American English “analog” which you’ll often find elsewhere on the Web when talking about the analog hole.
5 The rich history of exploiting the analogue hole spans everything from bootlegging a
1970s Led Zeppelin concert by smuggling recording equipment
in inside a wheelchair (definitely, y’know, to help topple the USSR and not just to listen to at home while you get high)
to “camming” by bribing your friendly local projectionist to let you set up a video camera at the back of the cinema for their test screening of the new blockbuster. Until some
corporation tricks us into installing memory-erasing DRM chips into our brains (hey, there’s a dystopic sci-fi story idea in there somewhere!) the analogue hole will always be
exploitable.
6 One might argue that recreating a piece of art from memory, after the fact, is a
very-specific and unusual exploitation of the analogue hole: the one that allows us to remember (or “download”) information to our brains rather than letting it “stream” right
through. There’s evidence to suggest that people pirated Shakespeare’s plays this way!
7 Of course, if you’re watching The LEGO Movie, what you’re seeing might already
look like a pile of LEGO bricks.
8 There are other ways in which the client and server may negotiate, too: for example,
what encoding formats are supported by your device.
9My NAS does live transcoding when Jellyfin streams to devices on my network, and it’s magical!
10 There’s always the analogue hole, remember! Although in practice this isn’t even
remotely necessary and most video media gets ripped some-other-way by clever pirate types even where it uses highly-sophisticated DRM strategies, and then ultimately it’s only
legitimate users who end up suffering as a result of DRM’s burden. It’s almost as if it’s just, y’know, simply a bad idea in the first place, or something. Who knew?
11 Like all these technologies, HDCP was cracked almost immediately and every
subsequent version that’s seen widespread rollout has similarly been broken by clever hacker types. Legitimate, paying users find themselves disadvantaged when their laptop won’t let
them use their external monitor to watch a movie, while the bad guys make pirated copies that work fine on anything. I don’t think anybody wins, here.
There’s a small house ( ⌂ ) in the middle of IBM’s infamous character set Code Page 437. “Small house”—that’s the official IBM
name given to the glyph at code position 0x7F, where a control character for “Delete” (DEL) should logically exist. It’s cute, but a little strange. I wonder, how did it get there?
Why did IBM represent DEL as a house, of all things?
It’s highly accessible, so even if you’ve only got a passing interest in, I don’t know, text encoding or typography or the history of computing, it’s a great read.
As I mentioned in my recent Blog Questions Challenge, I recently switched my blog from WordPress, which it had been running on for over 20 years of its 26 year history, to ClassicPress.1
I’m aware that I’m not the only person for whom ClassicPress might be a better fit
than WordPress2,
so I figured I should share the process by which I undertook the change.
Switching from WordPress to ClassicPress
Switching from WordPress to ClassicPress should be a non-destructive, 100% reversible process, but (even though I’ve got solid backups) I wasn’t ready to
trust that, so I decided to operate on a copy of my site. I’m glad I did, because there were a couple of teething issues I needed to tackle before I could launch.
1. Duplicating the site
I took a simple approach to duplicating the site: (1) I copied the site directory, and (2) I copied the database, and (3) I set up a new subdomain to use for testing. Here’s how I did
each step:
1.1. Copying the site directory
This should’ve been simple, but a du -sh revealed that my /wp-content/uploads directory is massive (I should look into that) and I didn’t want to
clone it. And I didn’t want r need to clone my /wp-content/cache directory either. So I ran:
rsync -av --exclude=wp-content ./old-site-directory/ ./new-site-directory/ to copy everything exceptwp-content, and then
rsync -av --exclude=uploads --exclude=cache ./old-site-directory/wp-content/ ./new-site-directory/wp-content/ to copy wp-contentexcept the
uploads and cache subdirectories, and then finally
ln -s ./old-site-directory/wp-content/uploads ./new-site-directory/wp-content/uploads to symlink the uploads directory, sharing it between the two sites
1.2. Copying the database
I just piped mysqldump into mysql to clone from one database to the other:
mysqldump -uUSERNAME -p --lock-tables=false old-site-database | mysql -uUSERNAME -p new-site-database
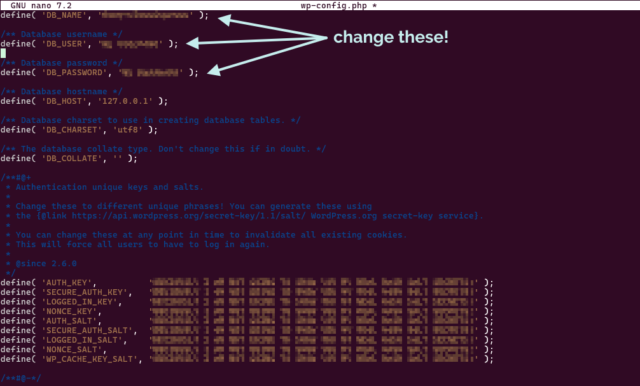
I edited DB_NAME in wp-config.php in the new site’s directory to point it at the new database.
If you’re going to clone your WordPress site before converting to ClassicPress, you’ll want to be comfortable editing your wp-config.php.
1.3. Setting up a new subdomain
My DNS is already configured with a wildcard to point (almost) all *.danq.me subdomains to this server already. I decided to use the name classicpress-testing.danq.me as my
temporary/test domain name. To keep any “changes” to my cloned site to a minimum, I overrode the domain name in my wp-config.php rather than in my database, by adding the
following lines:
Because I use Caddy/FrankenPHP as my webserver3,
configuration was really easy: I just copied the relevant part of my Caddyfile (actually an include), changed the domain name and the root, and it just worked,
even provisioning me out a LetsEncrypt SSL certificate. Magical4.
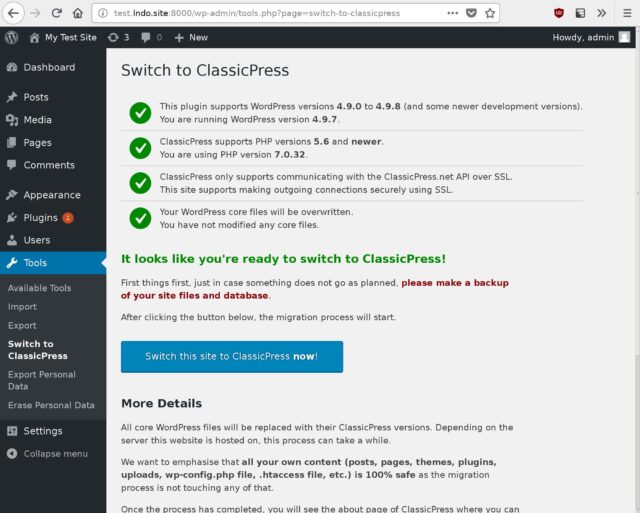
2. Switching the duplicate to ClassicPress
Now that I had a duplicate copy of my blog running at https://classicpress-testing.danq.me/, it was time to switch it to ClassicPress. I started by switching my wp-admin
colour scheme to a different one in my cloned site, so it’d be immediately visually-obvious to me if I’d accidentally switched and was editing the “wrong” site (I also made sure I was
logged-out of my primary, live site, so I was confident I wouldn’t break anything while I was experimenting!).
ClassicPress provides a migration plugin which checks for common problems and then switches your site
from WordPress to ClassicPress, so I installed it and ran it. It said that everything was okay except for my (custom) theme and a my self-built plugins, which it understandably couldn’t
check compatibility of. It recommended that I install Twenty Seventeen – the last WordPress default theme to not
require the block editor – but I didn’t do so: I was confident that my theme would work anyway… and if it didn’t, I’d want to fix it rather than switch theme!
I failed to take a screenshot of the actual process, but it looked broadly like this.
And then… it all broke.
3. Fixing what broke
After swiftly doing a safety-check that my live site was still intact, I started trying to work out why my site wasn’t broken. Debugging a ClassicPress PHP issue is functionally
identical to debugging a similar WordPress issue, for obvious reasons: check the logs, work out what’s broken, realise it’s a plugin, disable that plugin while you investigate further,
etc.
EWWW Image Optimizer: I use this plugin to pregenerate WebP variants of my images, which I then serve using webserver rules. It’s not a
complex job, and I should probably integrate the feature into my theme at some point, but for now I use this plugin. Version 8.0.0 of the plugin doesn’t work on ClassicPress 2.3.1, so
I used WP-CLI to downgrade to the last version that does (7.7.0), and then it worked fine.
Dan’s Geocaching Log Reposter: a self-made plugin that copies my logs from geocaching websites stopped working properly, which I think is because
ClassicPress is doing a more-aggressive job than WordPress at nonce validation on admin REST endpoints? I put a quick hack into my plugin to work around it, but I’ll need to look into
this properly at some point.
Some other bits of my stack, e.g. CapsulePress (my Gemini/Spartan/Nex server), have their own copies of my
database credentials, because I’ve been too lazy to centralise them into environment variables, and needed updating (but not until live switchover time).
I ran the two sites in-parallel for a couple of weeks, with the ClassicPress one as a “read only” version (so I didn’t pollute my uploads directory!), but it was pretty unnecessary
because it all worked pretty seamlessly, despite my complex stack of custom code. When I wanted to switch for-real, all I needed to do was swap the domain names over in my Caddyfile and
edit the wp-config.php of my ClassicPress installation: step 1.3, but in reverse!
If you hadn’t been told5, you probably wouldn’t have even known I’d made a change: I suppress basically all infrastructure-identifying
headers from my server output as a matter of course, and ClassicPress and WordPress are functionally-interchangeable from a front-end perspective6.
So what’s difference?
From my experience, here are the differences I’ve discovered since switching from WordPress to ClassicPress:
The good stuff
😅 ClassicPress has no Gutenberg/block editor. This would absolutely be a showstopper for many people, and that’s fine: I have nothing against the block editor (I
use it basically every day elsewhere!), but I’ve never really used it on danq.me and don’t feel the need to change that! My theme, my workflow, and my custom plugins are all
geared around the perfectly-good “classic” editor, and so getting a more-lightweight CMS by removing a feature I wasn’t using anyway falls somewhere between neutral and a blessing.
⚡The backend is fast again! One of the changes the ClassicPress team have been working on applying to WordPress is to strip out jQuery and other redundancies from
the backend, and I love how much faster and lighter my editor interface is as a result. (With caveat; see below!)
🔌Virtually everything “just works”. With the few exceptions described above, everything works exactly as it does under WordPress. Which is what you’d hope for a fork
that’s mostly “WordPress, but without the block editor”, right, but it’s still reassuring (and, for me, an essential feature). There are a few “new” features to do with paging through
posts and the media library and they’re fine, I suppose, but not by themselves worth switching for (though it might be nice to backport them into WordPress!).
The bad stuff
🏷️ Adding tags to posts takes a step backwards. A side-effect of dropping jQuery is the partial loss of the autocomplete feature when selecting tags to add to a post.
You still get a partial autocomplete, but not after typing a comma: you need to press enter to submit the tag you were writing and then start typing them next, which
frankly sucks. This is because they’re relying on a <datalist>, which isn’t as full-featured as the Javascript solution WordPress employs. This bugs
me almost enough to be a showstopper, but I gather it’s getting fixed in a near-future version.
🗺️ You’re in uncharted territory when things go wrong. One great benefit of WordPress is the side-effects of its ubiquity. If you have a query or a problem
you can throw a stone at your favourite search engine and get a million answers… and some of them will even be right! If you have a problem in ClassicPress and it’s not shared with (or
you’re not sure if it’s shared with) WordPress… you’re mostly on your own. The forums are good and friendly,
but if you want a quick answer to something, you’re likely to have to roll your sleeves up and open some source code. I don’t mind this at all – when I first started using WordPress,
this was the case, too! – but it might be a showstopper for some folks.
In summary: I’m enjoying using ClassicPress, even where there are rough edges. For me, 99% of my experience with it is identical to how I used WordPress anyway, it’s relatively
lightweight and fast, and it’s easy enough to switch back if I change my mind.
Footnotes
1 It saddens me that I have to keep clarifying this, but I feel like I do: my switch from
WordPress to ClassicPress is absolutely nothing to do with any drama in the WordPress space that’s going on right now: in fact, I’d been planning to try it out since before
any of the drama appeared. I appreciate that some people making a similar switch, including folks who use this blog post as a guide, might have different motivations to me, and that’s
fine too. Personally, I think that ditching an installation of open-source WordPress based on your interpretation of what’s going on in the ecosystem is… short-sighted? But
hey: the joy of open source is you can – and should! – do what you want. Anyway: the short of it is – the desire to change from WordPress to ClassicPress was, for me, 100% a
technical decision and 0% a political one. And I’ll thank you for leaving any of your drama at the door if you slide into my comments, ta!
2Matt recently described ClassicPress as “the last decent fork
attempt for WordPress”, and I absolutely agree. There’s been a spate of forks and reimplementations recently. I’ve looked into many of them and been… very much underwhelmed. Want my
hot take? Sure, here you go: AspirePress is all lofty ideas and no deliverables. FreeWP seems to be the same, but somehow without the lofty ideas. ForkPress is a ghost. Speaking of
ghosts, Ghost isn’t a WordPress fork; they have got some cool ideas though. b2evolution is even less a WordPress fork but it’s pretty cool in its own right. I’m not sure what
clamPress is trying to achieve but I’ve not given it a serious look. So yeah: ClassicPress is, in my mind, the only WordPress fork even worth consideration at this point, and as I
describe in this blog post: it’s not for everybody.
3 I switched from Nginx over the winter and it’s been just magical: I really love
Caddy’s minimal approach to production configuration. The only thing I’ve been able to fault it on is that it’s not capable of setting up client-side SSL certificate authentication on
a path, only on an entire domain, which meant I needed to reimplement the authentication mechanism I use on a small part of my (non-blog) internal
infrastructure.
4 To be fair, it wouldn’t have been hard if I’d still be using Nginx, because I’d
set up Certbot to use DNS-based vertification to issue me wildcard SSL certificates. But doing this in Caddy still felt magical.
6 Indeed, I wouldn’t have considered a switch to ClassicPress in the first place if it
wasn’t a closely-aligned-enough fork that I retained the ability to flip-flop between the two to my heart’s content! I’ve loved WordPress for over two decades; that’s not going to
change any time soon… and if e.g. ClassicPress ceased tracking WordPress releases and the fork diverged too far for my comfort, I’d probably switch back to regular old WordPress!
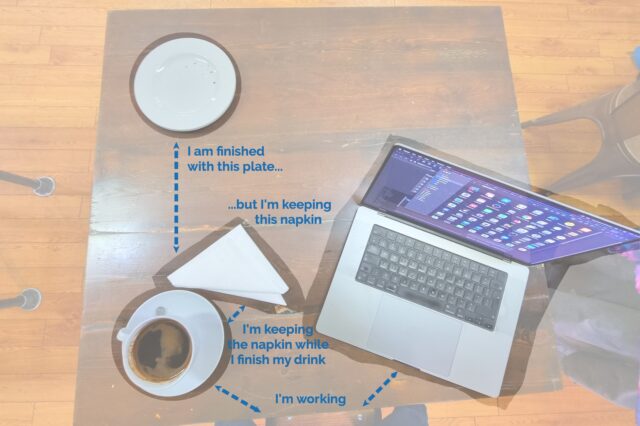
Possible future presentation concept: using a cafe/dining metaphor to help explain the proximity principle in user interface design (possibly with a “live waitstaffing” demo?).
On Wednesday, Vodafone
announced that they’d made the first ever satellite video call from a stock mobile phone in an area with no terrestrial signal. They used a mountain in Wales for their experiment.
It reminded me of an experiment of my own, way back in around 1999, which I probably should have made a bigger deal of. I believe that I was the first person to ever send an email from
the top of Yr Wyddfa/Snowdon.
Nowadays, that’s an easy thing to do. You pull your phone out and send it. But back then, I needed to use a Psion 5mx palmtop, communicating over an infared link using a custom driver
(if you ever wondered why I know my AT-commands by heart… well, this isn’t exactly why, but it’s a better story than the truth) to a Nokia 7110 (fortunately it was cloudy enough to not
interfere with the 9,600 baud IrDA connection while I positioned the devices atop the trig point), which engaged a GSM 2G connection, over which I was able to send an email to myself,
cc:’d to a few friends.
It’s not an exciting story. It’s not even much of a claim to fame. But there you have it: I was (probably) the first person to send an email from the summit of Yr Wyddfa. (If you beat
me to it, let me know!)

![Stylish (for circa 2000) webpage for HoTMetaL Pro 6.0, advertising its 'unrivaled [sic] editing, site management and publishing tools'.](https://bcdn.danq.me/_q23u/2025/08/hotmetal-pro-6-640x396.jpg)