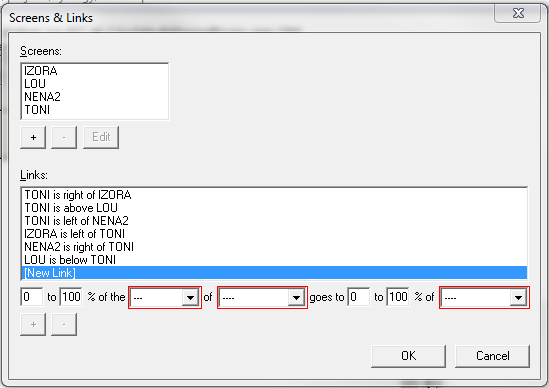
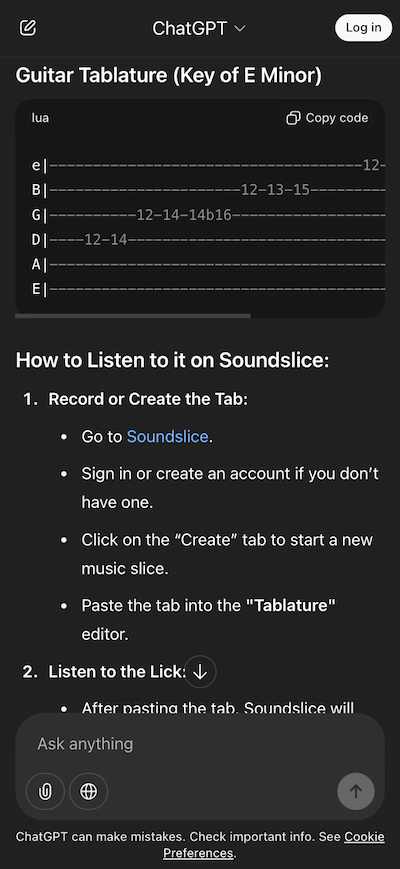
Our scanning system wasn’t intended to support this style of notation. Why, then, were we being bombarded with so many ASCII tab ChatGPT screenshots? I was mystified for weeks —
until I messed around with ChatGPT myself and got this:
Turns out ChatGPT is telling people to go to Soundslice, create an account and import ASCII tab in order to hear the audio playback. So that explains it!
…
With ChatGPT’s inclination to lie about the features of a piece of technology, it was
only a matter of time before a frustrated developer actually added a feature that ChatGPT had imagined, just to stop users from becoming dissatisfied when they tried to
use nonexistent tools that ChatGPT told them existed.
And this might be it! This could be the very first time that somebody’s added functionality based on an LLM telling people the feature existed already.
✅ To-Do:Obsidian, physical notepad [not happy with this; want something more productive]
📆 Calendar: Google Calendar (via Thunderbird on Desktop) [not happy with this; want something not-Google – still waiting on Proton Calendar getting good!]
This post is also available as an article. So if you'd
rather read a conventional blog post of this content, you can!
This video accompanies a blog post of the same title. The content is mostly the same; the blog post contains a few extra elements (especially in
the footnotes!). Enjoy whichever one you choose.
Of all of the videogames I’ve ever played, perhaps the one that’s had the biggest impact on my life1
was: Werewolves and (the) Wanderer.2
This simple text-based adventure was originally written by Tim Hartnell for use in his 1983 book Creating Adventure Games on your Computer. At the time, it
was common for computing books and magazines to come with printed copies of program source code which you’d need to re-type on your own computer, printing being significantly many
orders of magnitude cheaper than computer media.3
Werewolves and Wanderer was adapted for the Amstrad CPC4 by Martin Fairbanks and published in The Amazing Amstrad Omnibus (1985),
which is where I first discovered it.
When I first came across the source code to Werewolves, I’d already begun my journey into computer programming. This started alongside my mother and later – when her
quantity of free time was not able to keep up with my level of enthusiasm – by myself.
I’d been working my way through the operating manual for our microcomputer, trying to understand it all.5
The ring-bound 445-page A4
doorstep of a book quickly became adorned with my pencilled-in notes, the way a microcomputer manual ought to be. It’s strange to recall that there was a time that
beginner programmers still needed to be reminded to press [ENTER] at the end of each line.
And even though I’d typed-in dozens of programs before, both larger and smaller, it was Werewolves that finally helped so many key concepts “click” for me.
In particular, I found myself comparing Werewolves to my first attempt at a text-based adventure. Using what little I’d grokked of programming so far, I’d put together
a series of passages (blocks of PRINT statements6)
with choices (INPUT statements) that sent the player elsewhere in the story (using, of course, the long-considered-harmfulGOTO statement), Choose-Your-Own-Adventure
style.
Werewolves was… better.
By the time I was the model of a teenage hacker, I’d been writing software for years. Most of it terrible.
Werewolves and Wanderer was my first lesson in how to structure a program.
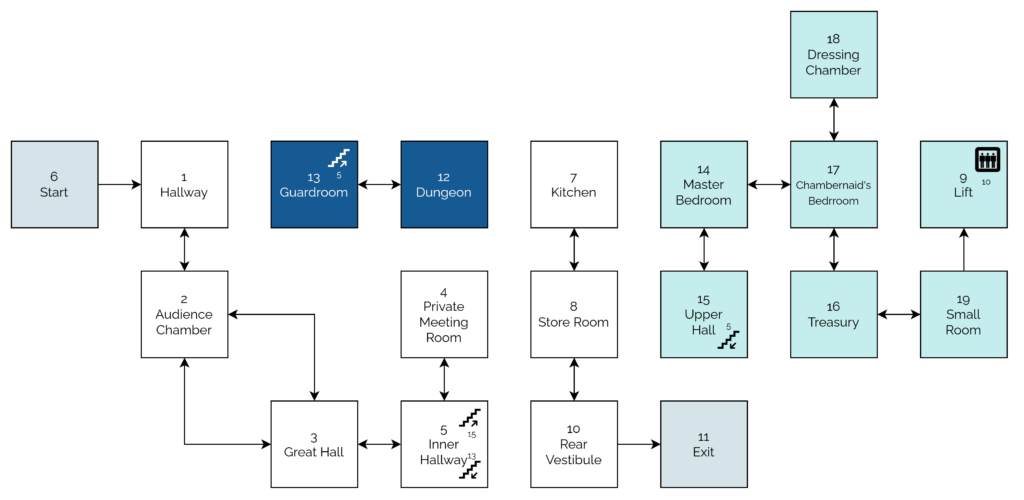
Let’s take a look at a couple of segments of code that help illustrate what I mean (here’s the full code, if you’re interested):
10REM WEREWOLVES AND WANDERER
20GOSUB2600:REM INTIALISE30GOSUB16040IF RO<>11THEN30
50 PEN 1:SOUND 5,100:PRINT:PRINT"YOU'VE DONE IT!!!":GOSUB3520:SOUND 5,80:PRINT"THAT WAS THE EXIT FROM THE CASTLE!":SOUND 5,20060GOSUB352070PRINT:PRINT"YOU HAVE SUCCEEDED, ";N$;"!":SOUND 5,10080PRINT:PRINT"YOU MANAGED TO GET OUT OF THE CASTLE"90GOSUB3520100PRINT:PRINT"WELL DONE!"110GOSUB3520:SOUND 5,80120PRINT:PRINT"YOUR SCORE IS";
130PRINT3*TALLY+5*STRENGTH+2*WEALTH+FOOD+30*MK:FOR J=1TO10:SOUND 5,RND*100+10:NEXT J
140PRINT:PRINT:PRINT:END...2600REM INTIALISE2610 MODE 1:BORDER 1:INK 0,1:INK 1,24:INK 2,26:INK 3,18:PAPER 0:PEN 22620 RANDOMIZE TIME
2630 WEALTH=75:FOOD=02640 STRENGTH=1002650 TALLY=02660 MK=0:REM NO. OF MONSTERS KILLED...3510REM DELAY LOOP3520FOR T=1TO900:NEXT T
3530RETURN
Locomotive BASIC had mandatory line numbering. The spacing and gaps (...) have been added for readability/your convenience.
What’s interesting about the code above? Well…
The code for “what to do when you win the game” is very near the top. “Winning” is the default state. The rest of the adventure exists to obstruct that. In a
language with enforced line numbering and no screen editor7,
it makes sense to put fixed-length code at the top… saving space for the adventure to grow below.
Two subroutines are called (the GOSUB statements):
The first sets up the game state: initialising the screen (2610), the RNG (2620), and player
characteristics (2630 – 2660). This also makes it easy to call it again (e.g. if the player is given the option to “start over”). This subroutine
goes on to set up the adventure map (more on that later).
The second starts on line 160: this is the “main game” logic. After it runs, each time, line 40 checks IF RO<>11 THEN 30. This tests
whether the player’s location (RO) is room 11: if so, they’ve exited the castle and won the adventure. Otherwise, flow returns to line 30 and the “main
game” subroutine happens again. This broken-out loop improving the readability and maintainability of the code.8
A common subroutine is the “delay loop” (line 3520). It just counts to 900! On a known (slow) processor of fixed speed, this is a simpler way to put a delay in than
relying on a real-time clock.
The game setup gets more interesting still when it comes to setting up the adventure map. Here’s how it looks:
Again, I’ve tweaked this code to improve readability, including adding indention on the loops, “modern-style”, and spacing to make the DATA statements form a “table”.
What’s this code doing?
Line 2690 defines an array (DIM) with two dimensions9
(19 by 7). This will store room data, an approach that allows code to be shared between all rooms: much cleaner than my first attempt at an adventure with each room
having its own INPUT handler.
The two-level loop on lines 2700 through 2730 populates the room data from the DATA blocks. Nowadays you’d probably put that data in a
separate file (probably JSON!). Each “row” represents a room, 1 to 19. Each “column” represents the room you end up
at if you travel in a given direction: North, South, East, West, Up, or Down. The seventh column – always zero – represents whether a monster (negative number) or treasure
(positive number) is found in that room. This column perhaps needn’t have been included: I imagine it’s a holdover from some previous version in which the locations of some or all of
the treasures or monsters were hard-coded.
The loop beginning on line 2850 selects seven rooms and adds a random amount of treasure to each. The loop beginning on line 2920 places each of six
monsters (numbered -1 through -6) in randomly-selected rooms. In both cases, the start and finish rooms, and any room with a treasure or monster, is
ineligible. When my 8-year-old self finally deciphered what was going on I was awestruck at this simple approach to making the game dynamic.
Rooms 4 and 16 always receive treasure (lines 2970 – 2980), replacing any treasure or monster already there: the Private Meeting Room (always
worth a diversion!) and the Treasury, respectively.
Curiously, room 9 (the lift) defines three exits, even though it’s impossible to take an action in this location: the player teleports to room 10 on arrival! Again, I assume this is
vestigal code from an earlier implementation.
The “checksum” that’s tested on line 2740 is cute, and a younger me appreciated deciphering it. I’m not convinced it’s necessary (it sums all of the values in
the DATA statements and expects 355 to limit tampering) though, or even useful: it certainly makes it harder to modify the rooms, which may undermine
the code’s value as a teaching aid!
By the time I was 10, I knew this map so well that I could draw it perfectly from memory. I almost managed the same today, aged 42. That memory’s buried deep!
Something you might notice is missing is the room descriptions. Arrays in this language are strictly typed: this array can only contain integers and not strings. But there are
other reasons: line length limitations would have required trimming some of the longer descriptions. Also, many rooms have dynamic content, usually based on random numbers, which would
be challenging to implement in this way.
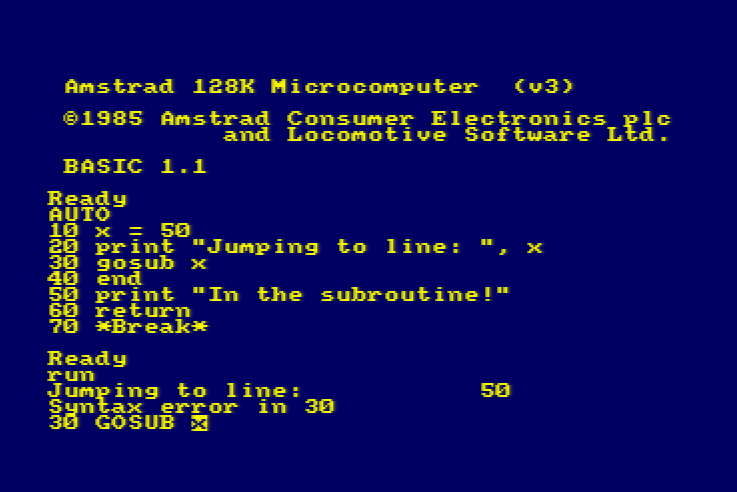
As a child, I did once try to refactor the code so that an eighth column of data specified the line number to which control should pass to display the room description. That’s
a bit of a no-no from a “mixing data and logic” perspective, but a cool example of metaprogramming before I even knew it! This didn’t work, though: it turns out you can’t pass a
variable to a Locomotive BASIC GOTO or GOSUB. Boo!10
In hindsight, I could have tested the functionality before I refactored with a very simple program, but I was only around 10 or 11 and still had lots to learn!
Werewolves and Wanderer has many faults11.
But I’m clearly not the only developer whose early skills were honed and improved by this game, or who hold a special place in their heart for it. Just while writing this post, I
discovered:
Many, many people commenting on the above or elsewhere about how instrumental the game was in their programming journey, too.
A decade or so later, I’d be taking my first steps as a professional software engineer. A couple more decades later, I’m still doing it.
And perhaps that adventure -the one that’s occupied my entire adult life – was facilitated by this text-based one from the 1980s.
Footnotes
1 The game that had the biggest impact on my life, it might surprise you to hear, is
not among the “top ten videogames that stole
my life” that I wrote about almost exactly 16 years ago nor the follow-up list I published in its incomplete form three years
later. Turns out that time and impact are not interchangable. Who knew?
2 The game is variously known as Werewolves and Wanderer, Werewolves and
Wanderers, or Werewolves and the
Wanderer. Or, on any system I’ve been on, WERE.BAS, WEREWOLF.BAS, or WEREWOLV.BAS, thanks to the CPC’s eight-point-three filename limit.
3 Additionally, it was thought that having to undertake the (painstakingly tiresome)
process of manually re-entering the source code for a program might help teach you a little about the code and how it worked, although this depended very much on how readable the code
and its comments were. Tragically, the more comprehensible some code is, the more long-winded the re-entry process.
5 One of my favourite
features of home microcomputers was that seconds after you turned them on, you could start programming. Your prompt was an interface to a programming language. That magic
had begun to fade by the time DOS came to dominate (sure, you can program using batch files, but they’re
neither as elegant nor sophisticated as any BASIC dialect) and was completely lost by the era of booting directly into graphical operating systems. One of my favourite
features about the Web is that it gives you some of that magic back again: thanks to the debugger in a modern browser, you can “tinker” with other people’s code once more, right from
the same tool you load up every time. (Unfortunately, mobile devices – which have fast become the dominant way for people to use the Internet – have reversed this trend again. Try to
View Source on your mobile – if you don’t already know how, it’s not an easy job!)
6 In particular, one frustration I remember from my first text-based adventure was that
I’d been unable to work around Locomotive BASIC’s lack of string escape sequences – not that I yet knew what such a thing would be called – in order to put quote marks inside a quoted
string!
7 “Screen editors” is what we initially called what you’d nowadays call a “text editor”:
an application that lets you see a page of text at the same time, move your cursor about the place, and insert text wherever you feel like. It may also provide features like
copy/paste and optional overtyping. Screen editors require more resources (and aren’t suitable for use on a teleprinter) compared to line editors, which preceeded them. Line editors only let you view and edit a single line at a time, which is how most of my first 6
years of programming was done.
8 In a modern programming language, you might use while true or similar for a
main game loop, but this requires pushing the “outside” position to the stack… and early BASIC dialects often had strict (and small, by modern standards) limits on stack height that
would have made this a risk compared to simply calling a subroutine from one line and then jumping back to that line on the next.
9 A neat feature of Locomotive BASIC over many contemporary and older BASIC dialects was
its support for multidimensional arrays. A common feature in modern programming languages, this language feature used to be pretty rare, and programmers had to do bits of division and
modulus arithmetic to work around the limitation… which, I can promise you, becomes painful the first time you have to deal with an array of three or more dimensions!
10 In reality, this was rather unnecessary, because the ON x GOSUB command
can – and does, in this program – accept multiple jump points and selects the one referenced by the
variable x.
11 Aside from those mentioned already, other clear faults include: impenetrable
controls unless you’ve been given instuctions (although that was the way at the time); the shopkeeper will penalise you for trying to spend money you don’t have, except on food,
presumably as a result of programmer laziness; you can lose your flaming torch, but you can’t buy spares in advance (you can pay for more, and you lose the money, but you don’t get a
spare); some of the line spacing is sometimes a little wonky; combat’s a bit of a drag; lack of feedback to acknowledge the command you enterted and that it was successful; WHAT’S
WITH ALL THE CAPITALS; some rooms don’t adequately describe their exits; the map is a bit linear; etc.
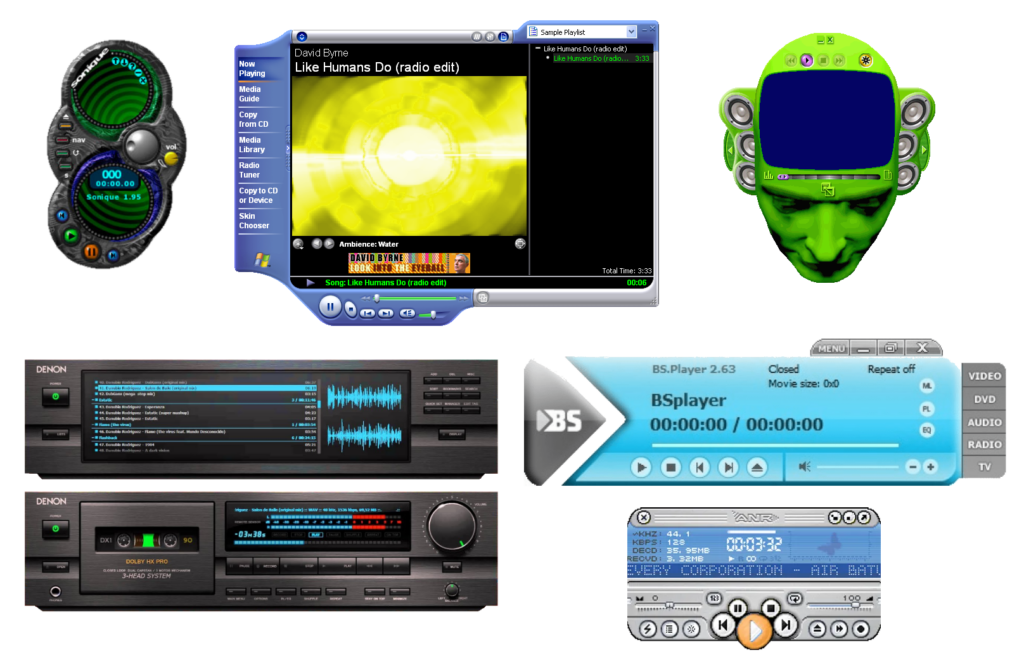
You don’t really see it any more, but: if you downloaded some media player software a couple of decades ago, it’d probably appear in a weird-shaped window, and I’ve never understood
why.
Mostly, these designs are… pretty ugly. And for what? It’s also worth noting that this kind of design can be found in all kinds of applications, in media players that it
was almost ubiquitous.
You might think that they’re an overenthusiastic kind of skeuomorphic design: people trying
to make these players look like their physical analogues. But hardware players were still pretty boxy-looking at this point, either because of the limitations of their data
storage1. By the time flash memory-based
portable MP3 players became commonplace their design was copying software players, not the other way around.
So my best guess is that these players were trying to stand out as highly-visible. Like: they were things you’d want to occupy a disproportionate amount of desktop space. Maybe
other people were listening to music differently than me… but for me, back when screen real estate was at such a premium2,
a music player’s job was to be small, unintrusive, and out-of-the-way.
I used to run Winamp in its very-smallest minified size, tucked up at the top of the screen, using
the default skin or one that made it even less-obtrusive.
It’s a mystery to me why anybody would (or still
does) make media player software or skins for them that eat so much screen space, frequently looking ugly while they do so, only to look like a hypothetical hardware device that
wouldn’t actually become commonplace until years after this kind of player design premiered!
Maybe other people listened to music on their computer differently from me: putting it front and centre, not using their computer for other tasks at the same time. And maybe for these
people the choice of player and skin was an important personalisation feature; a fashion statement or a way to show off their personal identity. But me? I didn’t get it then, and I
don’t get it now. I’m glad that this particular trend seems to have died and windows are, for the most part, rounded rectangles once more… even for music player software!
Footnotes
1 A walkman, minidisc player, or hard drive-based digital music device is always going to
look somewhat square because of what’s inside.
2 I “only” had 1600 × 1200 (UXGA) pixels on the very biggest monitor I owned before I went widescreen, and I spent a lot of time on monitors at lower resolutions e.g.
1024 × 768 (XGA); on such screens, wasting space on a music player when you’re mostly going to be listening “in the
background” while you do something else seemed frivolous.
A not-entirely-theoretical question about open source software licensing came up at work the other day. I thought it was interesting
enough to warrant a quick dive into the philosophy of minification, and how it relates to copyleft open source licenses. Specifically: does distributing (only) minified
source code violate the GPL?
If you’ve come here looking for a legally-justifiable answer to that question, you’re out of luck. But what I can give you is a (fictional) story:
TheseusJS is slow
TheseusJS is a (fictional) Javascript library designed to be run in a browser. It’s released under the GPLv3 license. This license allows you to download and use TheseusJS for any purpose you like, including making money off it, modifying
it, or redistributing it to others… but it requires that if you redistribute it you have to do so under the same license and include the source code. As such, it forces you to
share with others the same freedoms you enjoy for yourself, which is highly representative of some schools of open-source thinking.
It’s a cool project, but it really needs some maintenance this side of 2010.
It’s a great library and it’s used on many websites, but its performance isn’t great. It’s become infamous for the impact it has on the speed of the websites it’s used on, and it’s
often the butt of jokes by developers: “Man, this website’s slow. Must be running Theseus!”
The original developer has moved onto his new project, Moralia, and seems uninterested in handling the growing number of requests for improvements. So I’ve decided to fork it
and make my own version, FastTheseusJS and work on improving its speed.
FastTheseusJS is fast
I do some analysis and discover the single biggest problem with TheseusJS is that the Javascript file itself is enormous. The original developer kept all of the
copious documentation in comments in the file itself, and for some reason it doesn’t even compress well. When you use TheseusJS on a website it takes a painfully long time for
a browser to download it, if it’s not precached.
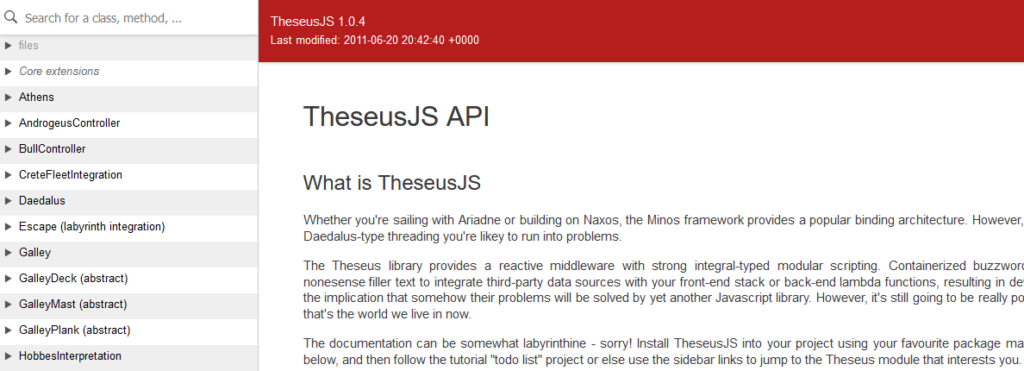
Nobody even uses the documentation in the comments: there’s a website with a fully-documented API.
My first release of FastTheseusJS, then, removes virtually of the comments, replacing them with a single comment at the top pointing developers to a website where the
API is fully documented. While I’m in there anyway, I also fix a minor bug that’s been annoying me for a while.
v1.1.0 changes
Forked from TheseusJS v1.0.4
Fixed issue #1071 (running mazeSolver() without first connecting <String> component results in endless loop)
Removed all comments: improves performance considerably
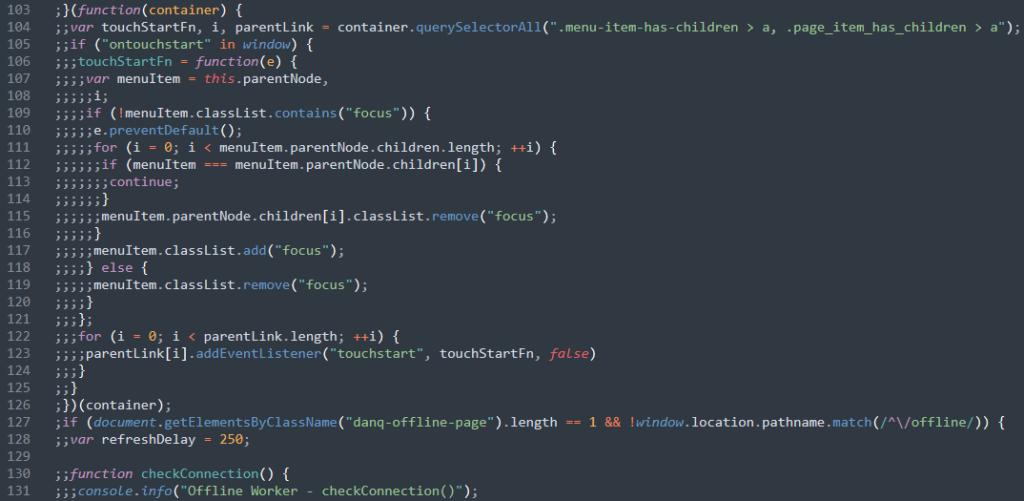
I discover another interesting fact: the developer of TheseusJS used a really random mixture of tabs and spaces for indentation, sometimes in the same line! It looks…
okay if you set your editor up just right, but it’s pretty hideous otherwise. That whitespace is unnecessary anyway: the codebase is sprawling but it seldom goes more than two
levels deep, so indentation levels don’t add much readability. For my second release of FastTheseusJS, then, I remove this extraneous whitespace, as well as removing
the in-line whitespace inside parameter lists and the components of for loops. Every little helps, right?
v1.1.1 changes
Standardised whitespace usage
Removed unnecessary whitespace
Some of the simpler functions now fit onto just a single line, and it doesn’t even inconvenience me to see them this way: I know the codebase well enough by now that it’s no
disadvantage for me to edit it in this condensed format.
Personally, I’ve given up on the tabs-vs-spaces debate and now I indent my code using semicolons. (That’s clearly a joke. Don’t flame me.)
In the next version, I shorten the names of variables and functions in the code.
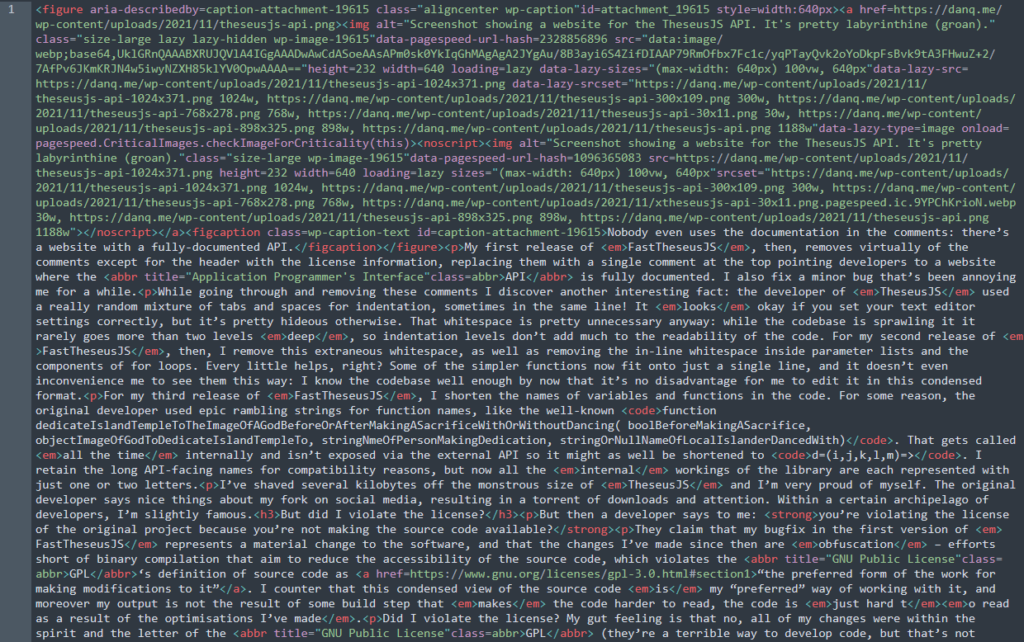
For some reason, the original developer used epic rambling strings for function names, like the well-known function
dedicateIslandTempleToTheImageOfAGodBeforeOrAfterMakingASacrificeWithOrWithoutDancing( boolBeforeMakingASacrifice, objectImageOfGodToDedicateIslandTempleTo,
stringNmeOfPersonMakingDedication, stringOrNullNameOfLocalIslanderDancedWith). That one gets called all the time internally and isn’t exposed via the external
API so it might as well be shortened to d=(i,j,k,l,m)=>. Now all the internal workings of the library
are each represented with just one or two letters.
v1.1.2 changes
Shortened/standarised non-API variable and function names – improves performance
I’ve shaved several kilobytes off the monstrous size of TheseusJS and I’m very proud. The original developer says nice things about my fork on social media, resulting in a
torrent of downloads and attention. Within a certain archipelago of developers, I’m slightly famous.
But did I violate the license?
But then a developer says to me: you’re violating the license of the original project because you’re not making the source code available!
This happens every day. Probably not to this same guy every time though, but you never know. Original photo by Andrea Piacquadio.
They claim that my bugfix in the first version of FastTheseusJS represents a material change to the software, and that the changes I’ve made since then are
obfuscation: efforts short of binary compilation that aim to reduce the accessibility of the source code. This fails to meet the GPL‘s definition of source code as “the preferred form of the work for making modifications to
it”. I counter that this condensed view of the source code is my “preferred” way of working with it, and moreover that my output is not the result of some build step that
makes the code harder to read, the code is just hard to read as a result of the optimisations I’ve made. In ambiguous cases, whose “preference” wins?
Did I violate the license? My gut feeling is that no, all of my changes were within the spirit and the letter of the GPL (they’re a
terrible way to write code, but that’s not what’s in question here). Because I manually condensed the code, did so with the intention that this condensing was a feature, and
continue to work directly with the code after condensing it because I prefer it that way… that feels like it’s “okay”.
But if I’d just run the code through a minification tool, my opinion changes. Suppose I’d run minify --output fasttheseus.js theseus.js and then deleted my copy of
theseus.js. Then, making changes to fasttheseus.js and redistributing it feels like a violation to me… even if the resulting code is the same as I’d have
gotten via the “manual” method!
I don’t know the answer (IANAL), but I’ll tell you this: I feel hypocritical for saying one piece of code would not violate
the license but another identical piece of code would, based only on the process the developer followed to produce it. If I replace one piece of code at a time with
less-readable versions the license remains intact, but if I replace them all at once it doesn’t? That doesn’t feel concrete nor satisfying.
Sure, I can write a blog post in just one line of code. It’ll just be a really, really, really long line… (Still perfectly readable, though!)
This isn’t an entirely contrived example
This example might seem highly contrived, and that’s because it is. But the grey area between the extremes is where the real questions are. If you agree that redistribution of (only)
minified source code violates the GPL, you’re left asking: at what point does the change occur? Code isn’t necessarily minified or
not-minified: there are many intermediate steps.
If I use a correcting linter to standardise indentation and whitespace – switching multiple spaces for the appropriate number of tabs, removing excess line breaks etc. (or do the same
tasks manually) I’m sure you’d agree that’s fine. If I have it replace whole-function if-blocks with hoisted return statements, that’s probably fine too. If I replace if blocks with
ternery operators or remove or shorten comments… that might be fine, but probably depends upon context. At some point though, some way along the process, minification goes “too
far” and feels like it’s no longer within the limitations of the license. And I can’t tell you where that point is!
This issue’s even more-complicated with some other licenses, e.g. the AGPL, which extends the requirement to share source code to hosted applications. Suppose I implement a web application that uses an AGPL-licensed library. The person who redistributed it to me only gave me the minified version, but they gave me a web address from which
to acquire the full source code, so they’re in the clear. I need to make a small patch to the library to support my service, so I edit it right into the minified version I’ve already
got. A user of my hosted application asks for a copy of the source code, so I provide it, including the edited minified library… am I violating the license for not providing the full,
unminified version, even though I’ve never even seen it? It seems absurd to say that I would be, but it could still be argued to be the case.
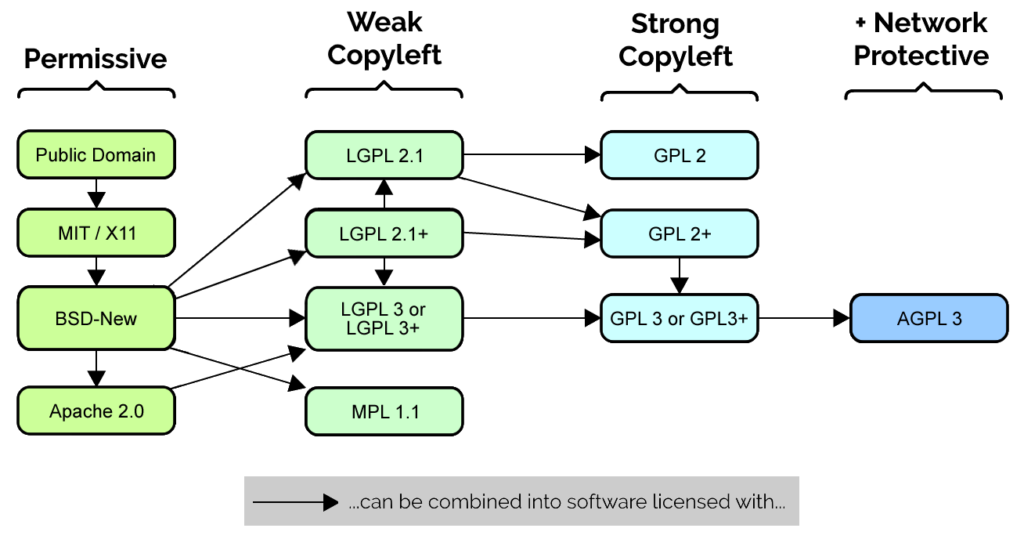
I love diagrams like this, which show license compatibility of different open source licenses. Adapted from a diagram by Carlo Daffara,
in turn adapted from a diagram by David E. Wheeler, used under a CC-BY-SA license.
99% of the time, though, the answer’s clear, and the ambiguities shown above shouldn’t stop anybody from choosing to open-source their work
under GPL, AGPL (or any other open source license depending on their
preference and their community). Perhaps the question of whether minification violates the letter of a copyleft license is one of those Potter Stewart “I know it when I see it” things. It certainly goes against the spirit of the thing to do so deliberately or
unnecessarily, though, and perhaps it’s that softer, more-altruistic goal we should be aiming for.
I’ve been using Synergy for a long, long time. By the time I wrote about my
admiration of its notification icon back in 2010 I’d already been using it for some years. But this long love affair ended this week when I made the switch to its competitor,
Barrier.
I’m not certain exactly when I took this screenshot (which I shared with Kit while praising Synergy), but it’s clearly a pre-1.4 version
and those look distinctly like Windows Vista’s ugly rounded corners, so I’m thinking no later than 2009?
If you’ve not come across it before: Synergy was possibly the first multiplatform tool to provide seamless “edge-to-edge” sharing of a keyboard and mouse between multiple
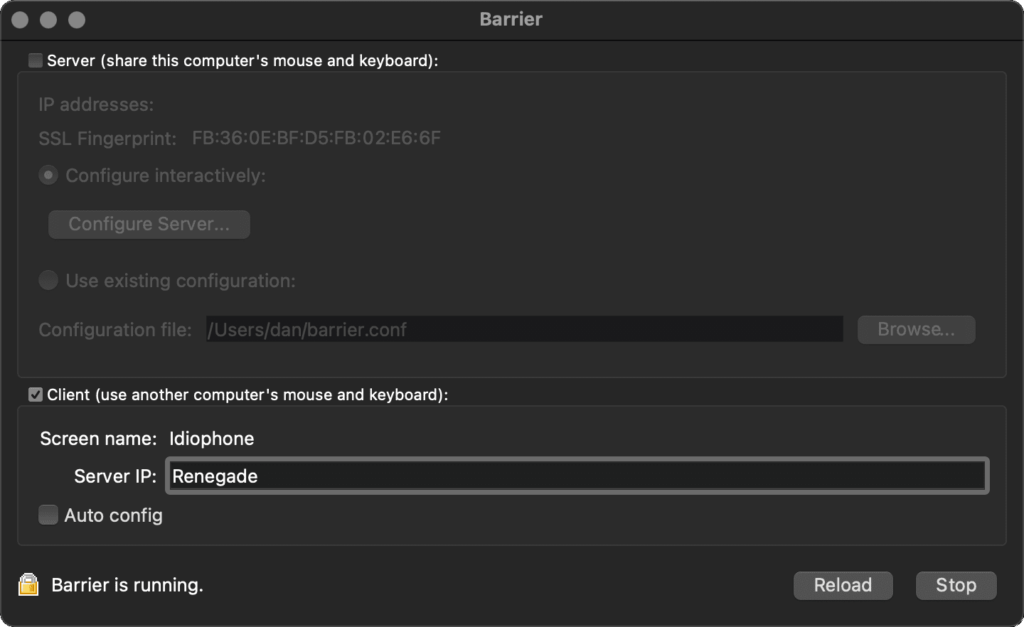
computers. Right now, for example, I’m sitting in front of Cornet, a Debian 11 desktop, Idiophone, a Macbook Pro docked to a desktop monitor, and Renegade, a
Windows desktop. And I can move my mouse cursor from one, to the other, to the next, interacting with them all as if I were connected directly to it.
There have long been similar technologies. KVM switches can do this, as
can some modern wireless mice (I own at least two such mice!). But none of them are as seamless as what Synergy does: moving from computer to computer as fast as you can move your mouse
and sharing a clipboard between multiple devices. I also love that I can configure my set-up around how I work, e.g. when I undock my Macbook it switches from ethernet to wifi, this
gets detected and it’s automatically removed from the cluster. So when I pick up my laptop, it magically stops being controlled by my Windows PC’s mouse and keyboard until I dock it
again.
Synergy’s published under a hybrid model: open-source components, with paid-for extra features. It used to provide more in the open-source offering: you could download a
fully-working copy of the software and use it without limitation, losing out only on a handful of features that for many users were unnecessary. Nontheless, early on I wanted to support
the development of this tool that I used so much, and so I donated money towards funding its development. In exchange, I gained access to Synergy Premium, and then when their business
model changed I got grandfathered-in to a lifetime subscription to Synergy Pro.
I continued using Synergy all the while. When their problem-stricken 2.x branch went into beta, I was among the
testers: despite the stability issues and limitations, I loved the fact that I could have what was functionally multiple co-equal “host” computers, and – when it worked – I liked the
slick new configuration interface it sported. I’ve been following with bated breath announcements about the next generation – Synergy 3 – and I’ve registered as an alpha tester for when the time comes.
If it sounds like I’m a fanboy… that’d probably be an accurate assessment of the situation. So why, after all these years, have I jumped ship?
Dear Future Dan. If you ever need a practical example of where open-source thinking provides a better user experience than arbritrarily closed-source products, please see above.
Yours, Past Dan.
I’ve been aware of Barrier since the project started, as a fork of the last open-source version of the core Synergy program. Initially, I didn’t consider Barrier to be a
suitable alternative for me, because it lacked features I cared about that were only available in the premium version of Synergy. As time went on and these features were implemented, I
continued to stick with Synergy and didn’t bother to try out Barrier… mostly out of inertia: Synergy worked fine, and the only thing Barrier seemed to offer would be a simpler set-up
(because I wouldn’t need to insert my registration details!).
This week, though, as part of a side project, I needed to add an extra computer to my cluster. For reasons that are boring and irrelevant and so I’ll spare you the details, the new
computer’s running the 32-bit version of Debian 11.
I went to the Symless download pages and discovered… there isn’t a Debian 11 package. Ah well, I think: the Debian 10 one can probably be made to work. But then I discover… there’s only
a 64-bit version of the Debian 10 binary. I’ll note that this isn’t a fundamental limitation – there are 32-bit versions of Synergy available for Windows and for ARMhf
Raspberry Pi devices – but a decision by the developers not to support that platform. In order to protect their business model, Synergy is only available as closed-source binaries, and
that means that it’s only available for the platforms for which the developers choose to make it available.
So I thought: well, I’ll try Barrier then. Now’s as good a time as any.
Setting up Barrier in place of Synergy was pretty familiar and painless.
Barrier and Synergy aren’t cross-compatible, so first I had to disable Synergy on each machine in my cluster. Then I installed Barrier. Like most popular open-source software, this was
trivially easy compared to Synergy: I just used an appropriate package manager by running choco install barrier, brew install barrier, and apt install barrier to install on each of the Windows, Mac, and Debian computers, respectively.
Configuring Barrier was basically identical to configuring Synergy: set up the machine names, nominate one the server, and tell the server what the relative positions are of each of the
others’ screens. I usually bind the “scroll lock” key to the “lock my cursor to the current screen” function but I wasn’t permitted to do this in Barrier for some reason, so I remapped
my scroll lock key to some random high unicode character and bound that instead.
Getting Barrier to auto-run on MacOS was a little bit of a drag – in the end I had to use Automator to set up a shortcut that ran it and loaded the configuration, and set that to run on
login. These little touches are mostly solved in Synergy, but given its technical audience I don’t imagine that anybody is hugely inconvenienced by them. Nonetheless, Synergy clearly
retains a slightly more-polished experience.
Altogether, switching from Synergy to Barrier took me under 15 minutes and has so far offered me a functionally-identical experience, except that it works on more devices, can be
installed via my favourite package managers, and doesn’t ask me for registration details before it functions. Synergy 3’s going to have to be a big leap forward to beat that!
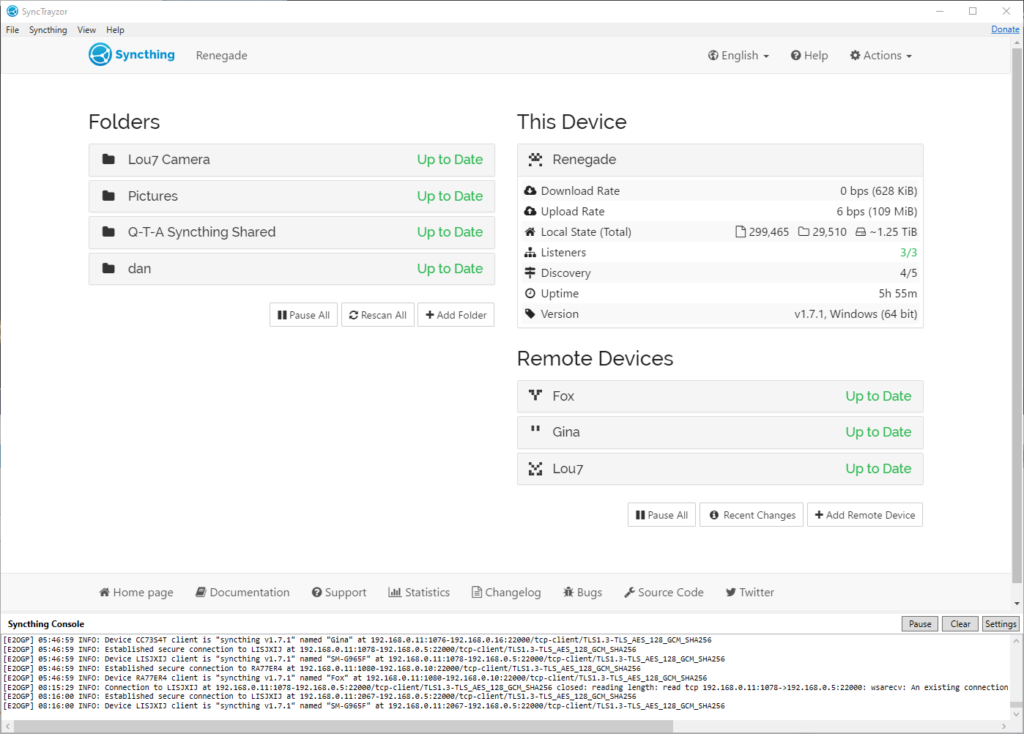
This last month or so, my digital life has been dramatically improved by Syncthing. So much so that I want to tell you about it.
1.25TiB of data is automatically kept in sync between (depending on the data in question) a desktop PC, NAS, media centre, and phone. This computer’s using the Synctrayzor system tray app.
I started using it last month. Basically, what it does is keeps a pair of directories on remote systems “in sync” with one another. So far, it’s like your favourite cloud
storage service, albeit self-hosted and much-more customisable. But it’s got a handful of killer features that make it nothing short of a dream to work with:
The unique identifier for a computer can be derived from its public key. Encryption comes free as part of the verification of a computer’s identity.
You can share any number of folders with any number of other computers, point-to-point or via an intermediate proxy, and it “just works”.
It’s super transparent: you can always see what it’s up to, you can tweak the configuration to match your priorities, and it’s open source so you can look at the engine if you like.
Here are some of the ways I’m using it:
Keeping my phone camera synced to my PC
I’ve tried a lot of different solutions for this over the years. Back in the way-back-when, like everybody else in those dark times, I used to plug my phone in using a cable to copy
pictures off and sort them. Since then, I’ve tried cloud solutions from Google, Amazon, and Flickr and never found any that really “worked” for me. Their web interfaces and apps tend to
be equally terrible for organising or downloading files, and I’m rarely able to simply drag-and-drop images from them into a blog post like I can from Explorer/Finder/etc.
At first, I set this up as a one-way sync, “pushing” photos and videos from my phone to my desktop PC whenever I was on an unmetered WiFi network. But then I switched it to a two-way
sync, enabling me to more-easily tidy up my phone of old photos too, by just dragging them from the folder that’s synced with my phone to my regular picture storage.
Centralising my backups
Now I’ve got a fancy NAS device with tonnes of storage, it makes sense to use it as a central
point for backups to run fom. Instead of having many separate backup processes running on different computers, I can just have each of them sync to the NAS, and the NAS can back everything up. Computers don’t need to be “on” at a particular
time because the NAS runs all the time, so backups can use the Internet connection when it’s quietest. And in the event of a
hardware failure, there’s an up-to-date on-site backup in the first instance: the cloud backup’s only needed in the event of accidental data deletion (which could be sync’ed already, of
course!). Plus, integrating the sync with ownCloud running on the NAS gives easy access to
my files wherever in the world I am without having to fire up a VPN or otherwise remote-in to my house.
Plus: because Syncthing can share a folder between any number of devices, the same sharing mechanism that puts my phone’s photos onto my main desktop can simultaneously be
pushing them to the NAS, providing redundant connections. And it was a doddle to set up.
Maintaining my media centre’s screensaver
Since the NAS, running Jellyfin, took on most of the media management jobs previously
shared between desktop computers and the media centre computer, the household media centre’s had less to do. But one thing that it does, and that gets neglected, is showing a
screensaver of family photos (when it’s not being used for anything else). Historically, we’ve maintained the photos in that collection via a shared network folder, but then you’ve got
credential management and firewall issues to deal with, not to mention different file naming conventions by different people (and their devices).
But simply sharing the screensaver’s photo folder with the computer of anybody who wants to contribute photos means that it’s as easy as copying the picture to a particular place. It
works on whatever device they care to (computer, tablet, mobile) on any operating system, and it’s quick and seamless. I’m just using it myself, for now, but I’ll be offering it to the
rest of the family soon. It’s a trivial use-case, but once you’ve got it installed it just makes sense.
In short: this month, I’m in love with Syncthing. And maybe you should be, too.
As always seems to happen when I move house, a piece of computer hardware broke for me during my recent house move. It’s always
exactly one piece of hardware, like it’s a symbolic recognition by the universe that being lugged around, rattling around and butting up against one another, is not the natural
state of desktop computers. Nor is it a comfortable journey for the hoarder-variety of geek nervously sitting in front of them, tentatively turning their overloaded vehicle around each
and every corner. UserFriendly said it right in this comic from 2003.
This time around, it was one of the hard drives in Renegade, my primary Windows-running desktop, that failed. (At least I didn’t break
myself, this time.)
Here’s the victim of my latest move. Rest in pieces.
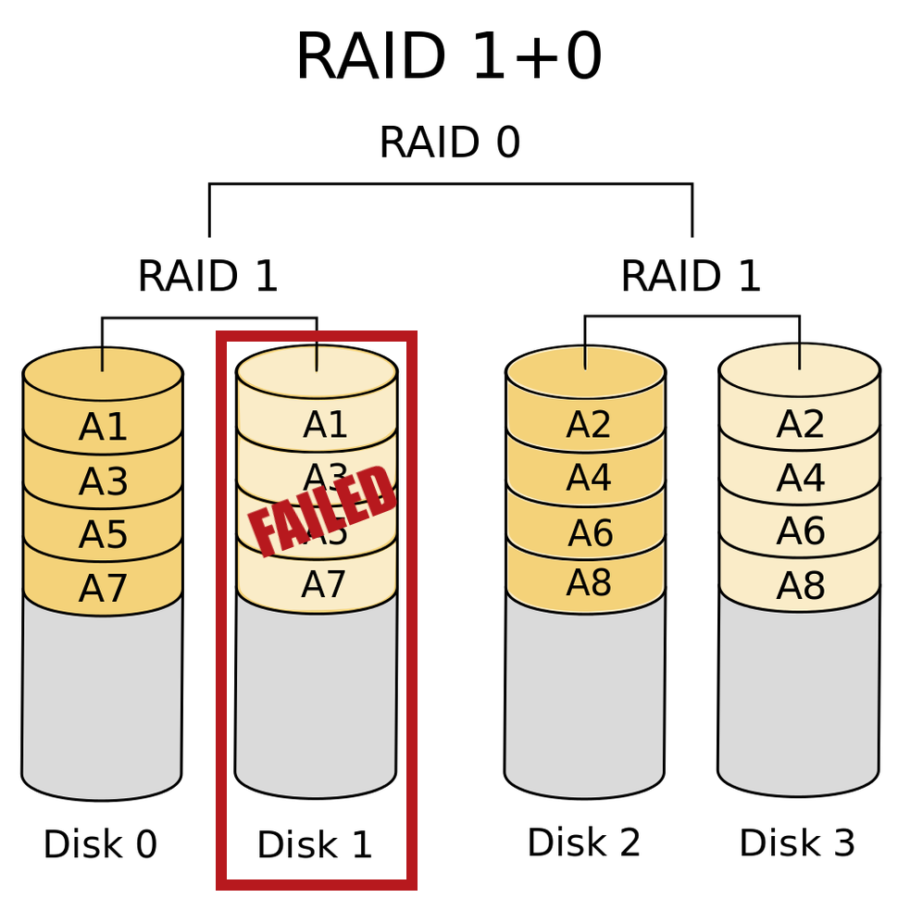
Fortunately, it failed semi-gracefully: the S.M.A.R.T. alarm went off about a week before it actually started causing real problems, giving me at least a little time to prepare, and
– better yet – the drive was part of a four-drive RAID 10 hot-swappable array, which means that every single byte of data on that drive was already duplicated to a second drive.
Incidentally, this configuration may have indirectly contributed to its death: before I built Fox, our new household NAS, I used Renegade for many of the same purposes, but WD Blues are not really a “server grade” hard
drive and this one and its siblings will have seen more and heavier use than they might have expected over the last few years. (Fox, you’ll be glad to hear, uses much better-rated
drives for her arrays.)
Set up your hard drives like this and you can lose at least one, and up to half, of the drives without losing data.
So no data was lost, but my array was degraded. I could have simply repaired it and carried on by adding a replacement similarly-sized hard drive, but my needs have changed now that Fox
is on the scene, so instead I decided to downgrade to a simpler two-disk RAID 1 array for important data and an
“at-risk” unmirrored drive for other data. This retains the performance of the previous array at the expense of a reduction in redundancy (compared to, say, a three-disk RAID 5 array which would have retained redundancy at the expense of performance). As I said: my needs have changed.
Fixing Things… Fast!
In any case, the change in needs (plus the fact that nobody wants watch an array rebuild in a different configuration on a drive with system software installed!) justified a
reformat-and-reinstall, which leads to the point of this article: how I optimised my reformat-and-reinstall using Chocolatey.
Not this kind of chocolatey, I’m afraid. Man, I shouldn’t have written this post before breakfast.
Chocolatey is a package manager for Windows: think like apt for
Debian-like *nices (you know I do!) or Homebrew for MacOS. For previous Windows system
rebuilds I’ve enjoyed the simplicity of Ninite, which will build you a one-click installer for your choice of many of your favourite tools, so you can
get up-and-running faster. But Chocolatey’s package database is much more expansive and includes bonus switches for specifying particular versions of applications, so it’s a clear
winner in my mind.
If you learn only one thing about me from this post, let it be that I’m a big fan of redundancy. Here’s the printed version of my reinstallation list. Y’know, in case the copy on a
pendrive failed.
So I made up a Windows installation pendrive and added to it a “script” of things to do to get Renegade back into full working order. You can read the full script here, but the essence of it was:
Reconfigure the RAID array, reformat, reinstall Windows, and create an account.
Configuration (e.g. set up my unusual keyboard mappings, register software, set up remote connections and backups, etc.).
By scripting virtually all of the above I was able to rearrange hard drives in and then completely reimage a (complex) working Windows machine with well under an hour of downtime; I can
thoroughly recommend Chocolatey next time you have to set up a new Windows PC (or just to expand what’s installed on your existing one). There’s a GUI if you’re not a fan of the command line, of course.
Have you heard about this new app called BoopSnoop?
It launched in the first week of 2020, and almost immediately, it was downloaded by four people in three different time zones. In the months since, it has remained steady at four
daily active users, with zero churn: a resounding success, exceeding every one of its creator’s expectations.
:)
I made a messaging app for, and with, my family. It is ruthlessly simple; we love it; no one else will ever use it. I wanted to jot down some notes about how and why I made it, both
to (a) offer a nudge to anyone else out there considering a similar project and (b) suggest something a little larger about software.
…
Robin Sloan (yes, this one) talks about an app that he wrote exclusively for his family. He likens the experience to a making a
home-cooked meal. And I totally get it.
I do this kind of thing all the time. Our new home NAS device, Fox, performs a handful
of functions (and I plan to expand it to many more) based on a mixture of open-source and homegrown code, just for my immediate family. Our “family wiki” does the same thing.
And the spreadsheet we use for our finances. I’ve written apps for small groups of friends before, too (e.g. 1, 2, 3, 4, 5,
6, 7, 8…). And that’s not to mention the countless “meals for one” I’ve cooked: small applications
written entirely for my own benefit – I’m using one right now to pull this article from the list of “things I’ve read and enjoyed recently” into my blog.
A home-cooked meal benefits from being tailored to its audience (if the recipe calls for mustard, I might use less or omit it because it makes my nose feel funny). It benefits from
being tailored to its purpose. And it benefits from the love that goes into it. My only superstition – that I’m aware of – is that I believe that food tastes better if the chef smiled
during its production… I’m beginning to think that the same might be true for software, too.
First among the reasons I think that learning the basics of programming should be in the school curriculum is that it teaches people how
computers work and so, by proxy, what they are (and are not) capable of. The most digitally-literate non-programmers I know are people who have the
strongest understanding about how and why computers do what they do. But a close second among my reasons is that those with an inclination can go a step further and, without even
necessarily pushing their skills to a level at which they could or would want to work as software developers, build their own tools to “scratch their own itches”. Solving a problem for yourself is enormously empowering, and the versatility of software lends itself to
solving a huge array of relatively-tiny problems: problems that affect individuals, families, or small communities but that aren’t big enough to warrant commercial attention.
(Sometimes these projects explode into something bigger, but usually they remain just as they are: a tool for the benefit of oneself and
one’s immediate tribe. And that’s just great.)
Sometimes, code is risky to change and expensive to refactor.
In such a situation, a seemingly good idea would be to rewrite it.
From scratch.
Here’s how it goes:
You discuss with management about the strategy of stopping new features for some time, while you rewrite the existing app.
You estimate the rewrite will take 6 months to cover what the existing app does.
A few months in, a nasty bug is discovered and ABSOLUTELY needs to be fixed in the old code. So you patch the old code and the new one too.
A few months later, a new feature has been sold to the client. It HAS TO BE implemented in the old code—the new version is not ready yet! You need to go back to the old code but
also add a TODO to implement this in the new version.
After 5 months, you realize the project will be late. The old app was doing way more things than expected. You start hustling more.
After 7 months, you start testing the new version. QA raises up a lot of things that should be fixed.
After 9 months, the business can’t stand “not developing features” anymore. Leadership is not happy with the situation, you are tired. You start making changes to the old,
painful code while trying to keep up with the rewrite.
Eventually, you end up with the 2 systems in production. The long-term goal is to get rid of the old one, but the new one is not ready yet. Every feature needs to be implemented
twice.
Sounds fictional? Or familiar?
Don’t be shamed, it’s a very common mistake.
…
I’ve rewritten legacy systems from scratch before. Sometimes it’s all worked out, and sometimes it hasn’t, but either way: it’s always been a lot more work than I could have
possibly estimated. I’ve learned now to try to avoid doing so: at least, to avoid replacing a single monolithic (living) system in a monolithic way. Nicholas gives an even-better
description of the true horror of legacy reimplementation, and promotes progressive strangulation as a candidate solution.
Attribute to God, and not to self, whatever good you see in yourself.
Recognize always that evil is your own doing, and to impute it to yourself.
Fear the Day of Judgment.
Be in dread of hell.
…
In an age when more and more open-source projects are adopting codes of conduct that reflect the values of a tolerant, modern, liberal society, SQLite – probably the most widely-used
database system in the world, appearing in everything from web browsers to games consoles – went… in a different direction. Interesting to see that, briefly, you could be in violation
of their code of conduct by failing to love everything else in the world less than you love Jesus. (!)
After the Internet collectively went “WTF?”, they’ve changed their tune and said that this guidance, which is based upon the Rule of St. Benedict, is now their Code of Ethics, and their Code of Conduct is a little more… conventional.
Although there’s a lot of heated discussion around diversity, I feel many of us ignore the elephant in the web development diversity room. We tend to forget about users of older or
non-standard devices and browsers, instead focusing on people with modern browsers, which nowadays means the latest versions of Chrome and Safari.
This is nothing new — see “works only in IE” ten years ago, or “works only in Chrome” right now — but as long as we’re addressing other diversity issues in web development we should
address this one as well.
Ignoring users of older browsers springs from the same causes as ignoring women, or non-whites, or any other disadvantaged group. Average web developer does not know any non-whites,
so he ignores them. Average web developer doesn’t know any people with older devices, so he ignores them. Not ignoring them would be more work, and we’re on a tight deadline with a
tight budget, the boss didn’t say we have to pay attention to them, etc. etc. The usual excuses.
Geeky winnage! This evening I wrote a pair of applications enabling me to use my new Bluetooth-enabled mobile phone as a remote
control for WinDVD, the DVD playing software I use on my computer.
Not just a geeky project, this is fuelled by a genuine need: every Troma Night, when the pizza arrives, we end up scrambling for the keyboard
in order to pause the film, or I find myself wandering back and forwards, trying to set the volume to an audible-to-all but not-deafening level. With the aid of this new funky toy, I
can do this from my seat. Toy.
I’m looking forward to other ideas for uses for this technology. Tools already exist to allow you to control your media player and
PowerPoint presentations using a Bluetooth mobile phone, but I’m sure that there are more useful applications that I can use in order to improve my own, personal geeky life.
[this post was lost during a server failure on Sunday 11th July 2004; it was partially recovered on 21st March 2012]
If you haven’t already read it, take a look at The Right To Read, a very short story written in 1997 and updated in 2002 –
it’ll only take you a few minutes to read; it’s not ‘techie’ (anybody would understand it!), and it is relevant. The kind of things that are expressed in the story – while
futuristic (and facist) sounding now, are being put into effect… slowly, quietly… by companies such as Sony, Phillips, Apple, and Microsoft: not to mention the manufactors of CDs and
DVDs.
It’s been circulating the ‘net for years, but recent events such as InterTrust’s Universal Digital Rights Management
System(report: The Register), which they claim will be ready within 6 months, and Microsoft’s ongoing work on the
‘Palladium’ project(report: BBC News) – topical events which mark the beginning of what could be the most important thing ever to happen in the history of copyright law,
computing, and freedom of information.
So, go on – go read… [the remainder of this post, and three comments, have been lost]

![Scan of a ring-bound page from a technical manual. The page describes the use of the "INPUT" command, saying "This command is used to let the computer know that it is expecting something to be typed in, for example, the answer to a question". The page goes on to provide a code example of a program which requests the user's age and then says "you look younger than [age] years old.", substituting in their age. The page then explains how it was the use of a variable that allowed this transaction to occur.](https://bcdn.danq.me/_q23u/2023/07/cpc664-manual-input-command.png)