It turns out my seriesofefforts to improve the BBC News RSS feeds are more-popular
than I thought. People keep asking for variants of them, and it’s probably time I stopped hosting the resulting feeds on my NAS (which does a good job,
but it’s in a highly-kickable place right under my desk).
The new site isn’t pretty. But it works.
So I’ve launched BBC-Feeds.DanQ.dev. On a 20-minute schedule, it generates both UK and World editions of the BBC News feeds,
filtered to remove iPlayer, Sounds, app “nudges”, duplicates, and other junk, and optionally with the sports news filtered out too.
Their inclusion of non-news content such as plugs for iPlayer and their apps,
Their repeating of identical news stories with marginally-different GUIDs, and
All of the sports news, which I don’t care about one jot.
Well, it turns out that some people want #3: the sport. But still don’t want the other two.
Some people actually want to read this crap, apparently.
I shan’t be subscribing to this RSS feed, and I can’t promise I’ll fix it if it gets broken. But if “without the crap, but with the sports” is the way you like your BBC News RSS feed,
I’ve got you covered:
the world needs more recreational programming.
like, was this the most optimal or elegant way to code this?
no, but it was the most fun to write.
Yes. This.
As Baz Luhrmann didn’t say, despite the implications of this video: code one thing every day that amuses you.
There is no greater way to protest the monetisation of the Web, the descent into surveillance capitalism, and the monoculture of centralised social media silos… than to create things
just for the hell of it. Maybe that’s Kirby eating a blog post. Maybe that’s whatever slippy stuff Lu put out this week. Maybe it’s a podcast exclusively about random things that interest one person.
The pre-corporate Web was fun and weird. Nowadays, keeping the Internet fun and weird is relegated to a
counterculture.
But making things (whether code, or writing, or videos, or whatever) “just because” is a critical part of that counterculture. It’s beautiful art flying in the face of rampant
commercialism. The Web provides a platform where you can share what you create: it doesn’t have to be good, or original, or world-changing… there’s value in just creating and giving
things away.
Even when it’s technical, not all of my International Volunteer Day work for Three Rings has been spent using our key technologies (LNMR [Linux, Nginx, MariaDB, Ruby] stacks).
Today, I wrote some extra PHP for our WordPress-powered contact form to notify our Support Team volunteers via Slack when messages are sent. We already aim to respond to every message
within 24 hours, 365 days a year, and are often faster than that… but this might help us to be even more-responsive to the needs of the charities who we help look after.
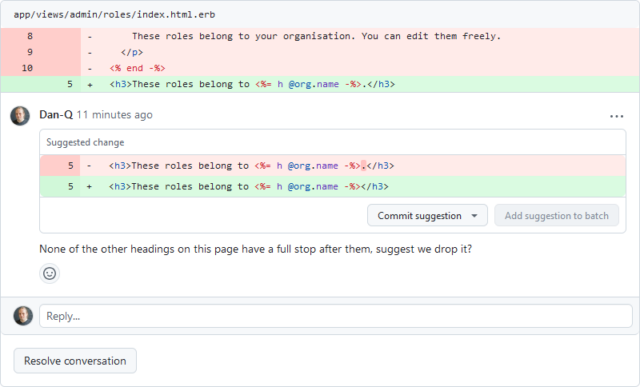
Not every code review is fireworks, but most Three Rings changes come from the actual needs of the voluntary organisations that Three Rings supports. Some of our users were confused by
the way the Admin > Roles page was laid out, so one of our volunteers wrote an improved version.
And because we’re all about collaboration, discussion, learning from one another, and volunteer-empowerment… I’ve added a minor suggestion… but approved their change “with or without”
it. I trust my fellow volunteer to either accept my suggestion (if it’s right), reject it (if it’s wrong), or solicit more reviews or bring it to Slack or our fortnightly dev meeting
(if it requires discussion).
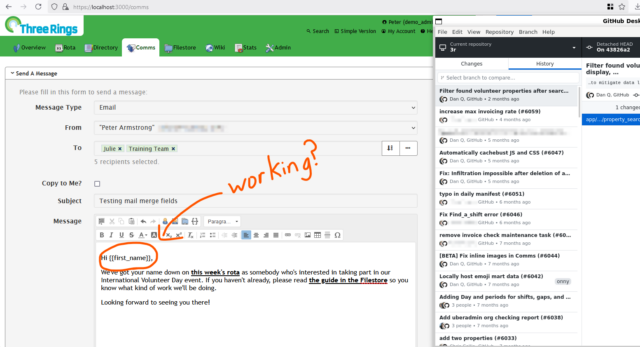
Good news! It turns out that the new code to fix the mail merge fields in Three Rings doesn’t introduce an inconsistency with established behaviour. It was important to check, but it
turns out all is well.
I touched bases with a fellow volunteer on Slack. Three Rings volunteers primarily communicate via Slack: it helps us to work asynchronously, which supports the fact that our volunteers
all have different schedules and preferences. Some might do a couple of evenings a week, others might do the odd weekend, others still might do an occasional intense solid week of
volunteering with us and then nothing for months! A communication model that works both synchronously and asynchronously is really important to make that volunteering model work, and
Slack fits the bill.
We get together in person sometimes, and we meet on Zoom from time to time too, but Slack is king of communication at Three Rings
My first task this International Volunteer Day is to test a pull request that aims to fix a bug with Three Rings’ mail merge fields functionality. As it’s planned to be a hotfix (direct
into production) we require extra rigor and more reviewers than code that just goes into the main branch for later testing on our beta environment.
My concern is that fixing this bug might lead to a regression not described by our automated tests, so I’m rolling back to a version from a couple of months ago to compare the behaviour
of the affected tool then and now. Sometimes you just need some hands-on testing!
The Beeb continue to keep adding more and more non-news content to the BBC News RSS feed (like this ad for the iPlayer app!), so I’ve once again had to update my script to “fix” the feed so that it only contains, y’know, news.
This morning’s actual breakfast order from the 7-year-old: “A sesame seed bagel with honey, unless there aren’t any sesame seed bagels, in which case a plain bagel with honey on one
half and jam on the other half, unless there aren’t any plain bagels, in which case a cinnamon and raisin bagel with JimJams on one half and Biscoff on the other half.”
Some day, this boy will make a great LISP programmer. 😂
I’ve never been even remotely into Sex and the City. But I can’t help but love that this developer was so invested in the characters and their relationships that when
he asked himself “couldn’t all this drama and heartache have been simplified if these characters were willing to consider polyamorous relationships rather than serial
monogamy?”1,
he did the maths to optimise his hypothetical fanfic polycule:
As if his talk at !!Con 2024 wasn’t cool enough, he open-sourced the whole thing, so you’re free to try the calculator online for yourself or expand upon or adapt it to your heart’s content. Perhaps you disagree with his assessment of the
relative relationship characteristics of the characters2: tweak them and
see what the result is!
Or maybe Sex and the City isn’t your thing at all? Well adapt it for whatever your fandom is! How I Met Your Mother,Dawson’s Creek, Mamma
Mia and The L-Word were all crying out for polyamory to come and “fix” them3.
Perhaps if you’re feeling especially brave you’ll put yourself and your circles of friends, lovers, metamours, or whatever into the algorithm and see who it matches up. You never know,
maybe there’s a love connection you’ve missed! (Just be ready for the possibility that it’ll tell you that you’re doing your love life “wrong”!)
Footnotes
1 This is a question I routinely find myself asking of every TV show that presents a love
triangle as a fait accompli resulting from an even moderately-complex who’s-attracted-to-whom.
2 Clearly somebody does, based on his commit “against his will” that increases Carrie and Big’s
validatesOthers scores and reduces Big’s prioritizesKindness.
3 I was especially disappointed with the otherwise-excellent The L-Word, which
did have a go at an ethical non-monogamy storyline but bungled the “ethical” at every hurdle while simultaneously reinforcing the “insatiable bisexual” stereotype. Boo!
Anyway: maybe on my next re-watch I’ll feed some numbers into Juan’s algorithm and see what comes out…
Perhaps inspired by my resharing of Thomas‘s thoughts about the biggest problem in
AI (tl;dr: he thinks it’s nomenclature; I agree that’s a problem but I don’t know if it’s the biggest issue), Ruth posted some thoughts to LinkedIn that I think are quite well-put:
I was going to write about something else but since LinkedIn suggested I should get AI to do it for me, here’s where I currently stand on GenAI.
As a person working in computing, I view it as a tool that is being treated as a silver bullet and is probably self-limiting in its current form. By design, it produces average
code. Most companies prior to having access to cheap average code would have said they wanted good code. Since the average code produced by the tools is being fed back into those
tools, mathematically this can’t lead anywhere good in terms of quality.
However, as a manager in tech I’m really alarmed by it. If we have tools to write code that is ok but needs a lot of double checking, we might be tempted to stop hiring
people at that level. There already aren’t enough jobs for entry level programmers to feed the talent pipeline, and this is likely to make it worse. I’m not sure where the next
generation of great programmers are supposed to come from if we move to an ecosystem where the junior roles are replaced by Copilot.
I think there’s a lot of potential for targeted tools to speed up productivity. I just don’t think GenAI is where they should come from.
This is an excellent explanation of no fewer than four of the big problems with “AI” as we’re seeing it marketed today:
It produces mediocre output, (more on that below!)
It’s a snake that eats its own tail,
It’s treated as a silver bullet, and
By pricing out certain types of low-tier knowledge work, it damages the pipeline for training higher-tiers of those knowledge workers (e.g. if we outsource all first-level tech
support to chatbots, where will the next generation of third-level tech support come from, if they can’t work their way up the ranks, learning as they go?)
Let’s stop and take a deeper look at the “mediocre output” claim. Ruth’s right, but if you don’t already understand why generative AI does this, it’s worth a
little bit of consideration about the reason for it… and the consequences of it:
Mathematically-speaking, that’s exactly what you would expect for something that is literally statistically averaging content, but that still comes as a surprise to people.
Bear in mind, of course, that there are plenty of topics in which the average person is less-knowledgable than the average of the content that was made available to the model.
For example, I know next to noting about fertiliser application in large-scale agriculture. ChatGPT has doubtless ingested a lot of literature about it, and if I ask it what
fertiliser I should use for a field of black beans in silty soil in the UK, it delivers me a confident-sounding answer:
Who knows if this answer is right, of course! If the answer mattered to me – because I was about to drill my field – I’d have to do my own research to check, by which point I
might as well have just done the research in the first place. If all I cared about was a quick sense-check to an answer I already knew, and it didn’t matter too much, this might be
okay output. (It’s pretty verbose and repeats itself a lot, like it’s learned how to talk from YouTube tutorials: I’m surprised it didn’t finish by exhorting me to like and
subscribe!)
When LLMs produce exceptional output (I use the term exceptional in the sense of unusual and not-average, not to mean “good”), it appears more-creative and interesting but is even
more-likely to be riddled with fanciful hallucinations.
There’s a fine line in getting the creativity dial set just right, and even when you do there’s no guarantee of accuracy, but the way in which many chatbots are told to talk makes them
sound authoritative on basically every subject. When you know it’s lying, that’s easy. But people don’t always use LLMs for subjects they’re knowledgeable about!
I asked ChatGPT to define five words for me. Two (“quantifiable” and “ethology”) are real words that somebody might have trouble with. One (“no cap”) is a slang term. One
(“erinaceiophobia” is a logically-sound construction from the Latin name for the biological family that hedgehogs belong to and the Greek suffix that’s applied to irrational fears).
ChatGPT came up with perfectly reasonable definitions of all of these. But it also confidently defined “undercontrastised”, a word I made up and which I can’t find used anywhere at
all!
In my example above, a more-useful robot would have stated that it didn’t know the answer to the question rather than, y’know, lying. But the nature
of the statistical models used by LLMs means that they can’t know what they don’t know: they don’t have a “known unknowns” space.
Regarding the “damages the training pipeline”: I’m undecided on whether or not I agree with Ruth. She might be on to something there, but I’m not sure. Needs more
thought before I commit to an opinion on that one.
Oh, and an addendum to this – as a human, I find the proliferation of AI tools in spaces that are all about creating connections with other humans deeply concerning. I saw a lot of
job applications through Otta at my previous role, and they were all kind of the same – I had no sense of the person behind the averaged out CV I was looking at. We already have a
huge problem with people presenting inauthentic versions of themselves on social media which makes it harder to have genuine interactions, smoothing off the rough edges of real people
to get something glossy and processed is only going to make this worse.
AI posts on social media are the chicken nuggets of human interaction and I’d rather have something real every time.
Emphasis mine… because that’s a fantastic metaphor. Content generated where a generative AI is trying to “look human” are so-often bland, flat, and unexciting: a mass-produced
most-basic form of social sustenance. So yeah: chicken nuggets.
Ironically, I might’ve gotten a better picture here if I’d asked AI to draw this for me, because I couldn’t find any really unappetising-looking McDonalds-grade chicken nuggets on the
stock photography site I used.
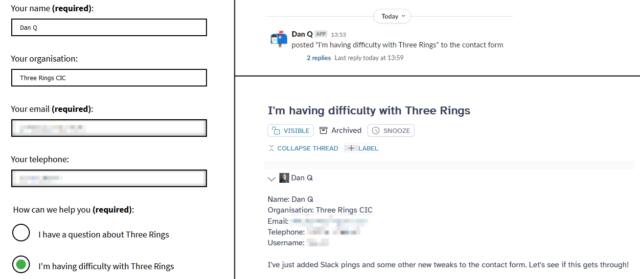
Three Rings operates a Web contact form to help people get in touch with us: the idea
is that it provides a quick and easy way to reach out if you’re a charity who might be able to make use of the system, a user who’s having difficulty with the features of the software,
or maybe a potential new volunteer willing to give your time to the project.
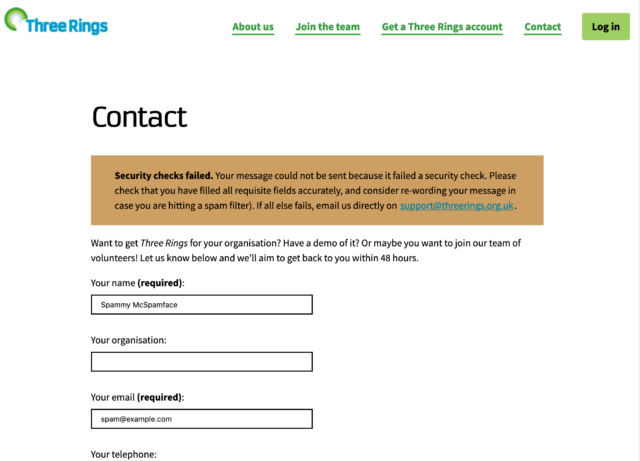
But then the volume of spam it received increased dramatically. We don’t want our support team volunteers to spend all
their time categorising spam: even if it doesn’t take long, it’s demoralising. So what could we do?
It’s clearly spam, but if it takes you 2 seconds to categorise it and there are 30 in your Inbox, that’s still a drag.
Our conventional antispam tools are configured pretty liberally: we don’t want to reject a contact from a legitimate user just because their message hits lots of scammy keywords (e.g.
if a user’s having difficulty logging in and has copy-pasted all of the error messages they received, that can look a lot like a password reset spoofing scam to a spam filter). And we
don’t want to add a CAPTCHA, because not only do those create a barrier to humans – while not necessarily reducing spam very much, nowadays – they’re often terrible for accessibility,
privacy, or both.
But it didn’t take much analysis to spot some patterns unique to our contact form and the questions it asks that might provide an opportunity. For example, we discovered that
spam messages would more-often-than-average:
Fill in both the “name” and (optional) “Three Rings username” field with the same value. While it’s cetainly possible for Three Rings users to have
a login username that’s identical to their name, it’s very rare. But automated form-fillers seem to disproportionately pair-up these two fields.
Fill the phone number field with a known-fake phone number or a non-internationalised phone number from a country in which we currently support no charities.
Legitimate non-UK contacts tend to put international-format phone numbers into this optional field, if they fill it at all. Spammers often put NANP (North American Numbering Plan)
numbers.
Include many links in the body of the message. A few links, especially if they’re to our services (e.g. when people are asking for help) is not-uncommon in legitimate
messages. Many links, few of which point to our servers, almost certainly means spam.
Choose the first option for the choose -one question “how can we help you?” Of course real humans sometimes pick this option too, but spammers almost always
choose it.
None of these characteristics alone, or any of the half dozen or so others we analysed (including invisible checks like honeypots and IP-based geofencing), are reason to
suspect a message of being spam. But taken together, they’re almost a sure thing.
To begin with, we assigned scores to each characteristic and automated the tagging of messages in our ticketing system with these scores. At this point, we didn’t do anything to block
such messages: we were just collecting data. Over time, this allowed us to find a safe “threshold” score above which a message was certainly spam.
Even when a message fails our customised spam checks, we only ‘soft-block’ it: telling the user their message was rejected and providing suggestions on working around that or emailing
us conventionally. Our experience shows that the spammers aren’t willing to work to overcome this additional hurdle, but on the very rare ocassion a human hits them, they are.
Once we’d found our threshold we were able to engage a soft-block of submissions that exceeded it, and immediately the volume of spam making it to the ticketing system dropped
considerably. Under 70 lines of PHP code (which sadly I can’t share with you) and we reduced our spam rate by over 80% while having, as far as we can see, no impact on the
false-positive rate.
Where conventional antispam solutions weren’t quite cutting it, implementing a few rules specific to our particular use-case made all the difference. Sometimes you’ve just got to roll
your sleeves up and look at the actual data you do/don’t want, and adapt your filters accordingly.
Like my occasional video content, this isn’t designed to replace any of my blogging: it’s just a different medium for those that might prefer it.
For some stories, I guess that audio might be a better way to find out what I’ve been thinking about. Just like how the vlog version of my post about
my favourite video game Easter Egg might be preferable because video as a medium is better suited to demonstrating a computer game, perhaps
audio’s the right medium for some of the things I write about, too?
But as much as not, it’s just a continuation of my efforts to explore different media over which a WordPress blog can be delivered2.
Also, y’know, my ongoing effort to do what I’m bad at in the hope that I might get better at a wider diversity of skills.
How?
Let’s start by understanding what a “podcast” actually is. It is, in essence, just an RSS feed (something you might have heard me talk about before…) with audio enclosures – basically, “attachments” – on each item. The idea was spearheaded by Dave Winer back in 2001 as a
way of subscribing to rich media like audio or videos in such a way that slow Internet connections could pre-download content so you didn’t have to wait for it to buffer.3
Podcasts are pretty simple, even after you’ve bent over backwards to add all of the metadata that Apple Podcasts (formerly iTunes) expects to see. I looked at a couple of
WordPress plugins that claimed to be able to do the work for me, but eventually decided it was simple enough to just add some custom metadata fields that could then be included in my
feeds and tweak my theme code a little.
Here’s what I had to do to add podcasting capability to my theme:
The tag
I use a post tag, dancast, to represent posts with accompanying podcast content4.
This way, I can add all the podcast-specific metadata only if the user requests the feed of that tag, and leave my regular feeds untampered . This means that you don’t
get the podcast enclosures in the regular subscription; that might not be what everybody would want, but it suits me to serve podcasts only to people who explicitly ask for
them.
Okay, onto the code (which I’ve open-sourced over here). I’ve use a series of standard WordPress hooks to
add the functionality I need. The important bits are:
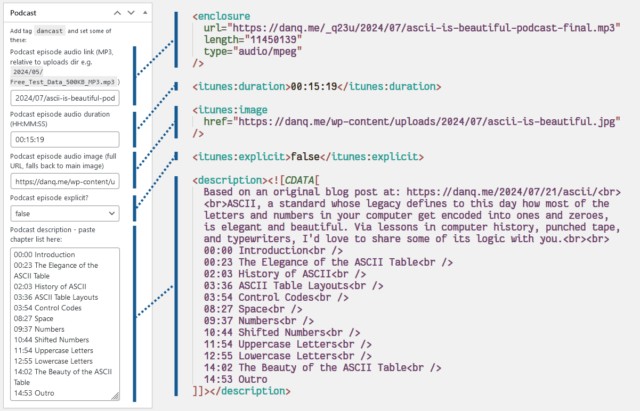
rss2_item – to add the <enclosure>, <itunes:duration>, <itunes:image>, and
<itunes:explicit> elements to the feed, when requesting a feed with my nominated tag. Only <enclosure> is strictly required, but appeasing Apple
Podcasts is worthwhile too. These are lifted directly from the post metadata.
the_excerpt_rss – I have another piece of post metadata in which I can add a description of the podcast (in practice, a list of chapter times); this hook
swaps out the existing excerpt for my custom one in podcast feeds.
rss_enclosure – some podcast syndication platforms and players can’t cope with RSS feeds in which an item has multiple enclosures, so as a
safety precaution I strip out any enclosures that WordPress has already added (e.g. the featured image).
the_content_feed – my RSS feed usually contains the full text of every post, because I don’t like feeds that try to force you to go to the
original web page5
and I don’t want to impose that on others. But for the podcast feed, the text content of the post is somewhat redundant so I drop it.
rss2_ns – of critical importance of course is adding the relevant namespaces to your XML declaration. I use the itunes namespace, which provides the widest compatibility for specifying metadata, but I also use the
newer podcast namespace, which has growing compatibility and provides some modern features, most of which I don’t
use except specifying a license. There’s no harm in supporting both.
rss2_head – here’s where I put in the metadata for the podcast as a whole: license, category, type, and so on. Some of these fields are
effectively essential for best support.
You’re welcome, of course, to lift any of all of the code for your own purposes. WordPress makes a perfectly reasonable platform for podcasting-alongside-blogging, in my experience.
What?
Finally, there’s the question of what to podcast about.
My intention is to use podcasting as an alternative medium to my traditional blog posts. But not every blog post is suitable for conversion into a podcast! Ones that rely on images
(like my post about dithering) aren’t a great choice. Ones that have lots of code that you might like to copy-and-paste are especially unsuitable.
You’re listening to Radio Dan. 100% Dan, 100% of the time.(Also I suppose you might be able to hear my dog snoring in the background…)
Also: sometimes I just can’t be bothered. It’s already some level of effort to write a blog post; it’s like an extra 25% effort on top of that to record, edit, and upload a podcast
version of it.
That’s not nothing, so I’ve tended to reserve podcasts for blog posts that I think have a sort-of eccentric “general interest” vibe to them. When I learn something new and feel the need
to write a thousand words about it… that’s the kind of content that makes it into a podcast episode.
Which is why I’ve been calling the endeavour “a podcast nobody asked for, about things only Dan Q cares about”. I’m capable of getting nerdsniped
easily and can quickly find my way down a rabbit hole of learning. My podcast is, I guess, just a way of sharing my passion for trivial deep dives with the rest of the world.
My episodes are probably shorter than most podcasts: my longest so far is around fifteen minutes, but my shortest is only two and a half minutes and most are about seven. They’re meant
to be a bite-size alternative to reading a post for people who prefer to put things in their ears than into their eyes.
Anyway: if you’re not listening already, you can subscribe from here or in your favourite podcasting app. Or you can just follow my blog as normal
and look for a streamable copy of podcasts at the top of selected posts (like this one!).
2 As well as Web-based non-textual content like audio (podcasts) and video (vlogs), my blog is wholly or partially available over a variety of more-exotic protocols: did you find me yet on Gemini (gemini://danq.me/), Spartan (spartan://danq.me/), Gopher (gopher://danq.me/), and even Finger
(finger://danq.me/, or run e.g. finger blog@danq.me from your command line)? Most of these are powered by my very own tool CapsulePress, and I’m itching to try a few more… how about a WordPress blog that’s accessible over FTP, NNTP, or DNS? I’m not even kidding when I say
I’ve got ideas for these…
3 Nowadays, we have specialised media decoder co-processors which reduce the size of media
files. But more-importantly, today’s high-speed always-on Internet connections mean that you probably rarely need to make a conscious choice between streaming or downloading.
4 I actually intended to change the tag to podcast when I went-live,
but then I forgot, and now I can’t be bothered to change it. It’s only for my convenience, after all!