With IndieWebCamp Oxford 2019 scheduled to take place during the
Summer of Hacks, I drew a diagram (click to embiggen) of the current ecosystem that powers
and propogates the content on DanQ.me. It’s mostly for my own benefit – to be able to get a big-picture view of the ways my website talks to the world and plan for what
improvements I might be able to make in the future… but it also works as a vehicle to explain what my personal corner of the IndieWeb does and how it
does it. Here’s a summary:
DanQ.me
Since fifteen years ago today, DanQ.me has been powered by a self-hosted WordPress installation. I
know that WordPress isn’t “hip” on the IndieWeb this week and that if you’re not on the JAMstack you’re yesterday’s news, but at 15 years and counting my
love affair with WordPress has lasted longer than any romantic relationship I’ve ever had with another human being, so I’m sticking with it. What’s cool in Web technologies comes and
goes, but what’s important is solid, dependable tools that do what you need them to, and between WordPress, half a dozen off-the-shelf plugins and about a dozen homemade ones I’ve got
everything I need right here.
I’d been “blogging” – not that we called it that, yet – since late 1998, but my original collection of content-mangling Perl scripts wasn’t all that. More history…
I write articles (long posts like this) and notes (short, “tweet-like” updates) directly into the site, and just occasionally
other kinds of content. But for the most part, different kinds of content come from different parts of the ecosystem, as described below.
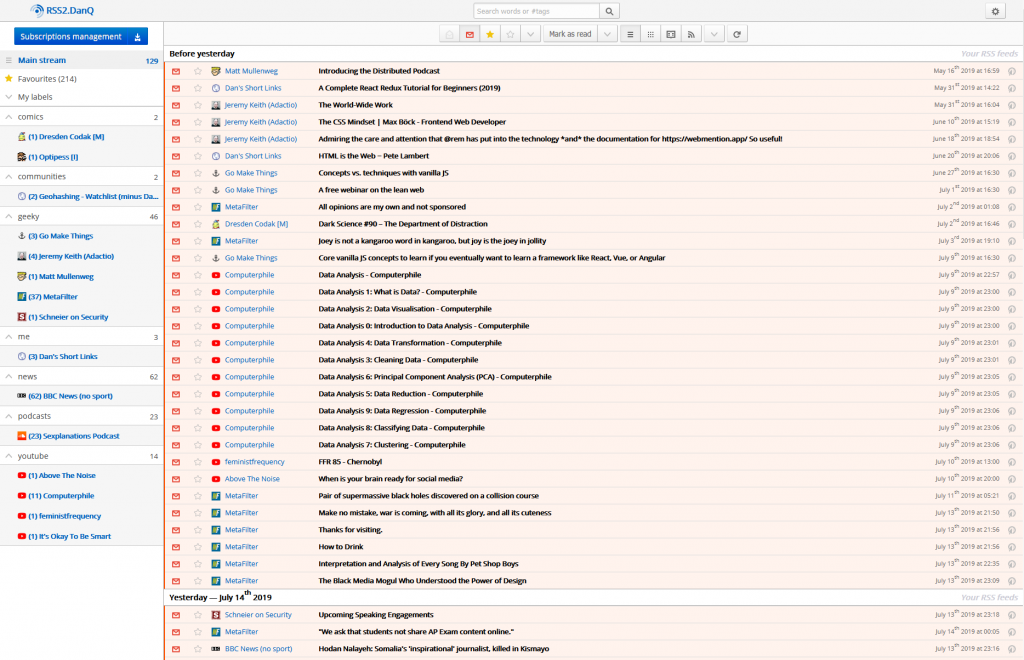
RSS reader
DanQ.me sits at the centre of the diagram, but it’s worth remembering that the diagram is deliberately incomplete: it only contains information flows directly relevant to my blog (and
it doesn’t even contain all of those!). The last time I tried to draw a diagram like this that described my online life in general, then my RSS reader found its way to the centre. Which figures: my RSS reader is usually the first
and often the last place I visit on the Internet, and I’ve worked hard to funnel everything through it.
129 unread items is a reasonable-sized queue: I try to process to “RSS zero”, but there are invariably things I want to return to on a second-pass and I’ve not yet reimplemented the
“snooze button” I added to my previous RSS reader.
Right now I’m using FreshRSS – plus a handful of plugins, including some homemade ones – as my RSS reader: I switched from Tiny Tiny RSS about a year ago to take advantage of FreshRSS’s excellent responsive
themes, among other features. Because some websites don’t have RSS feeds, even where they ought to, I use my own tool
RSSey to retroactively “fix” people’s websites for them, dynamically adding feeds for my
consumption. It’s also a nice reminder that open source and remixability were cornerstones of the original Web. My RSS reader
collates information from a variety of sources and additionally gives me a one-click mechanism to push content I enjoy to my blog as a repost.
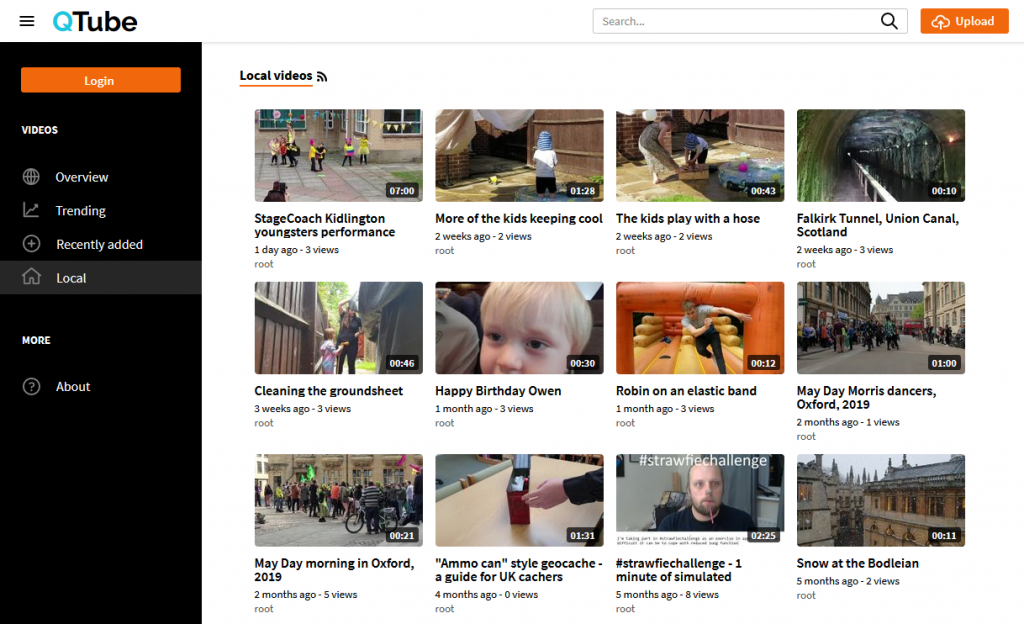
QTube
QTube is my video hosting platform; it’s a PeerTube node. If you haven’t seen it, that’s fine: most content
on it is consumed indirectly either through my YouTube channel or directly on my blog as posts of the “video” kind. Also, I don’t actually vlog very often. When I do publish videos onto QTube, their republication onto YouTube or DanQ.me is optional: sometimes I plan to
use a video inside an article post, for example, and so don’t need to republish it by itself.
I’m gradually exporting or re-uploading my backlog of YouTube videos from my current and previous channels to QTube in an effort to
recentralise and regain control over their hosting, but I’m in no real hurry. PeerTube certainly makes it easy, though!
Link Shortener
I operate a private link shortener which I mostly use for the expected purpose: to make links shorter and so easier to read out and memorise or else to make them take up less space in a
chat window. But soon after I set it up, many years ago, I realised that it could also act as a mechanism to push content to my RSS reader to “read later”. And by the time I’m using it for that, I figured, I might as well also be using it to repost content to my blog
from sources that aren’t things my RSS reader subscribes to. This leads to a process that’s perhaps unnecessarily
complex: if I want to share a link with you as a repost, I’ll push it into my link shortener and mark it as going “to me”, then I’ll tell my RSS reader to push it to my blog and there it’ll be published to the world! But it works and it’s fast enough: I’m not in the habit
of reposting things that are time-critical anyway.
Checkins
You know your sport is fringe when you need to reference another fringe sport to describe it. “Geohashing? It’s… a little like geocaching, but…”
I’ve been involved in brainstorming ways in which the act of finding (or failing to find, etc.) a geocache or reaching (or failing to
reach) a geohashpoint could best be represented as a “checkin“, and last year I open-sourced my plugin for pulling logs (with as much automation as is permitted by the terms of service of some of the
silos involved) from geocaching websites and posting them to WordPress blogs: effectively PESOS-for-geocaching. I’d prefer to be publishing on my own blog in the first instance, but syndicating my adventures from various
silos into my blog is “good enough”.
Syndication
New notes get pushed out to my Twitter account, for the benefit of my Twitter-using friends. Articles get advertised on Facebook, Twitter and LiveJournal (yes, really) in teaser form, for the benefit of friends
who prefer to get notifications via those platforms. Facebook have been fucking around with their APIs and terms of
service lately and this is now less-automatic than it used to be, which is a bit of an annoyance. My RSS feeds carry copies
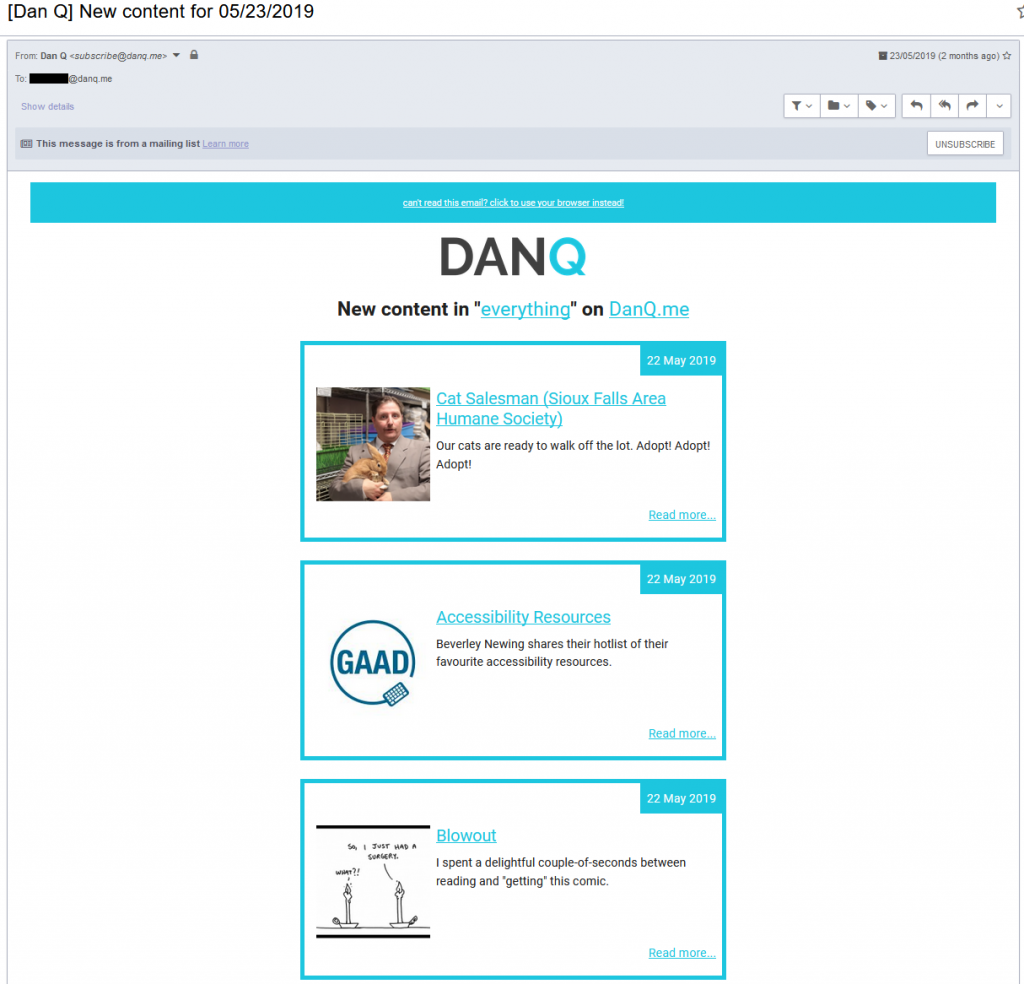
of content out to people who prefer to subscribe via that medium, and I’ve also been using this to power an experimental MailChimp “daily digest” mailing list of “what Dan’s been up to”
to a small number of friends, right in their email inboxes: I’ve not made it available to everybody yet, but if you’re happy to help test it then give me a shout
and I’ll hook you up.
Most days don’t see an email sent or see an email with only one item, but some days – like this one – are busier. I still need to update the brand colours here, too!
Finally, a couple of IFTTT recipes push my articles and my reposts to Reddit communities: I don’t
really use Reddit myself, any more, but I’ve got friends in a few places there who prefer to keep up-to-date with what I’m up to via that medium. For historical reasons, my reposts to
Reddit don’t go directly via my blog’s RSS feeds but “shortcut” directly from my RSS reader: this is suboptimal because I don’t get to tweak post titles for Reddit but it’s not a big deal.
What IFTTT does isn’t magic, but it’s often indistinguishable from it.
I used to syndicate content to Google+ (before it joined the long list of Things Google Have Killed) and to Ello
(but it never got much traction there). I’ve probably historically syndicated to other places too: I’ve certainly manually-republished content to other blogs, from time to time, too.
I use Ryan Barrett‘s excellent Brid.gy to convert Twitter replies and likes back into Webmentions for publication as comments on my blog. This used to work for Facebook, too, but again: Facebook
fucked it over. I’ve occasionally manually backfed significant Facebook comments, but it’s not ideal: I might like to look at using similar technologies to RSSey to subvert
Facebook’s limitations.
I’ve never had a need for Brid.gy’s “publishing” (i.e. POSSE) features, but its backfeed features “just work”, and it’s awesome.
Reintegration
I’ve routinely retroactively reintegrated content that I’ve produced elsewhere on the Web. This includes my previous blogs (which is why you can browse my archives, right here on this
site, all the way back to some of the cringeworthy angsty-teenager posts I made in the 1990s) but also some Reddit posts,
some replies originally posted directly to other people’s blogs, all my old del.icio.us bookmarks, long-form forum
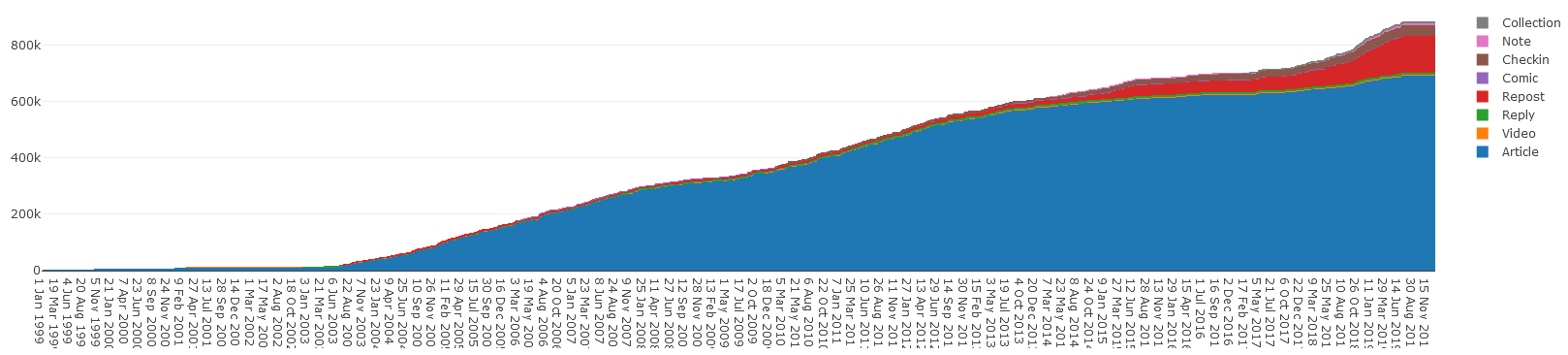
posts, posts I made to mailing lists and newsgroups, and more. As a result, there’s a lot of backdated content on this site, nowadays: almost a million words, and significantly
more than the 600,000 or so I counted a few years ago, before my biggest push for reintegration!
Cumulative wordcount per day, by content type. The lion’s share has always been articles, but reposts are creeping up as I’ve been writing more about the things I reshare, lately.
It’d be interesting to graph the differentiation of this chart to see the periods of my life that I was writing the most: I have a hypothesis, and centralising my own content under my
control makes it easier
Why do I do this? Because I really, really like owning my identity online! I’ve tried the “big” silo alternatives like Facebook, Twitter, Medium, Instagram etc., and they’ve eventually
always lead to disappointment, either because they get shut down or otherwise made-unusable, because
of inappropriately-applied “real names” policies, because they give too much power to
untrustworthy companies, because they impose arbitrary limitations on my content, because they manipulate output
promotion (and exacerbate filter bubbles), or because they make the walls of their walled gardens taller and stop you integrating with them how you used to.
A handful of silos have shown themselves to be more-trustworthy than the average – in particular, eschewing techniques that promote “lock-in” – and I’d love to tell you more about them
and what I think you should look for in a silo, another time. But for now: suffice to say that just like I don’t use YouTube like most people do, I
elect not to use Facebook or Twitter in the conventional ways either. And it’s awesome, thanks.
There are plenty of reasons that people choose to take control of their own Web presence – and everybody who puts content online ought to consider
it – but I imagine that few individuals have such a complicated publishing ecosystem as I do! Now you’ve got a picture of how my digital content production workflow works, and
perhaps start owning your online identity, too.
Google can’t be trusted to maintain the services of theirs that you depend upon (relevant XKCD?). That’s not a phenomenon that’s unique to Google,
of course: it’s perhaps just that they produce so many new and often-experimental services that they inevitably cease supporting more of them than some of the many other providers who’ve killed the silos that people depended upon.
How could things be better? For a start, Google could make a better commitment to open-source and developing standards rather than platforms. But if you don’t think you can trust them
to do that – and you can’t – then the only solution for individuals is to use fewer Google products to break the Google-monoculture. Encourage the competition to weaken their
position, and break free from silos in general where it’s possible to do so.
148+ projects and services dead. But hey, we’re getting Stadia so everything’s okay, right? <sigh>
In the days before the web was mainstream, it was a place of creation. First for education, then for every random idea that any creator had!
As the web transitioned from a network of educational institutions to the consumer force it is today, the early adopters were technologists… AKA geeks!
A hallmark of geek culture is fandom – a deep knowledge of whatever topic interests them. This could be about a book, TV show, movie or band. With this passion comes a desire to share
it with the world. Before the internet, there was no clear path. After the web started gaining traction, it was the biggest and easiest megaphone you could want.
It wasn’t always easy to be found, though. There was no search algorithm. Google was not ubiquitous with search. To be found, you needed to be listed on a site that aggregated other
sites about your topic.
…
There was always a certain joy to a well-kept webring, back in the day. I’d love to see a return to this kind of “Indieweb dream”, but I don’t think that just wishing for it nor even
telling people to go out and do it goes far enough, alone. Hopefully Bryan’s post will help nudge a few people in the right direction, though.
MySpace inspired a generation of teenagers to learn how to code. We have Dark Mode now, but where did all the glitter go?
During the internet of 2006, consumer products let anyone edit CSS. It was a beautiful mess. As the internet grew up, consumer products stopped trusting their users, and the internet
lost its soul.
…
I agree entirely with Jarred: in discouraging people from having their own web presences and in locking-down our shared social spaces online, we’re making the Web feel increasingly
flat, soulless, and – dare I say is – joyless. MDX seems really cool, but I’m not yet convinced that it alone solves the underlying problem of
content creators feeling that they should (or must) use dry, boring silos for the things they produce rather than their own space (in which they’d be able to express their personalities
and the personality of the things they were sharing). It may well lower the barrier to producing interactive personal sites a little (as well as having other applications, I’m sure!),
but we’re going to need more than that to drag people away from Facebook, Medium, Twitter and the like.
Warp and Weft by Paul Robert Lloyd(paulrobertlloyd.com)
Earlier this month I had the good fortune to attend Material, a conference that explores the concept of the web as a material and all the intrinsic characteristics that entails. The
variety of talks provided new perspectives on what it means to build for – and with – the web, and prompted me to …
…
What it means for something to be of the web has been discussed many times before. While the technical test can be reasonably objective – is it addressable, accessible and available – culturally it remains harder to judge. But I don’t know about you, I’ve found that
certain websites feel more ‘webby’ than others.
…
Despite being nonspecific on the nature of the feeling he describes, Paul hits the nail on the head. Your favourite (non-Medium) blog or guru site almost certainly has that feel of
being “of the web”. Your favourite API-less single-page app (with the growing “please use in Chrome” banner) almost
certainly does not.
Notes from #musetech18 presentations (with a strong “collaboration” theme). Note that these are “live notes” first-and-foremost for my own use and so are probably full of typos. Sorry.
Matt Locke (StoryThings, @matlocke):
Over the last 100 years, proportional total advertising revenue has been stolen from newspapers by radio, then television: scheduled media that is experienced
simultaneously. But we see a recent drift in “patterns of attention” towards the Internet. (Schedulers, not producers, hold the power in radio/television.)
The new attention “spectrum” includes things that aren’t “20-60 minutes” (which has historically been dominated by TV) nor “1-3 hours” (which has been film), but now there are
shorter and longer forms of popular medium, from tweets and blog posts (very short) to livestreams and binging (very long). To gather the full spectrum of attention, we need to span
these spectra.
Rhythm is the traditions and patterns of how work is done in your industry, sector, platforms and supply chains. You need to understand this to be most-effective (but this is
hard to see from the inside: newcomers are helpful). In broadcast television as a medium, the schedules dictate the rhythms… in traditional print publishing, the major
book festivals and “blockbuster release” cycles dominate the rhythm.
Then how do we collaborate with organisations not in our sector (i.e. with different rhythms)? There are several approaches, but think about the rhythmic impact.
Partnered with Google Arts & Heritage; Google’s first single-partner project and also their first project with a multi-site organisation.
This kind of tech can be used to increase access (e.g. street view of closed sites) and also support curatorial/research aims (e.g. ultra-high-resolution photography).
Aside from the tech access, working with a big company like Google provides basically “free” PR. In combination, these benefits boost reach.
Learnings: prepare to work hard and fast, multi-site projects are a logistical nightmare, you will need help, stay organised and get recordkeeping/planning in place early, be aware
that there’ll be things you can’t control (e.g. off-brand PR produced by the partner), don’t be afraid to stand your ground where you know your content better.
Decide what successw looks like at the outset and with all relevant stakeholders involved, so that you can stay on course. Make sure the project is integrated into contributors’
work streams.
Daria Cybulska (Wikimedia UK, @DCybulska):
Collaborative work via Wikimedians-in-residence not only provides a boost to open content but involves engagement with staff and opens further partnership opportunities.
Your audience is already using Wikipedia: reaching out via Wikipedia provides new ways to engage with them – see it as a medium as well as a platform.
Wikimedians-in-residence, being “external”, are great motivators to agitate processes and promote healthy change in your organisation.
Creative Collaborations ([1] Kate Noble @kateinoble, Ina Pruegel @3today, [2] Joanna Salter, [3] Michal Cudrnak, Johnathan Prior):
Digital making (learning about technology through making with it) can link museums with “maker culture”. Cambridge museums (Zoology, Fitzwilliam) used a “Maker in Residence”
programme and promoted “family workshops” and worked with primary schools. Staff learned-as-they-went and delivered training that they’d just done themselves (which fits maker culture
thinking). Unexpected outcomes included interest from staff and discovery of “hidden” resources around the museums, and the provision of valuable role models to participants. Tips: find
allies, be ambitious and playful, and take risks.
National Maritime Museum Greenwich/National Maritime Museum – “re.think” aimed to engage public with emotive topics and physically-interactive exhibits. Digital wing allowed leaving
of connections/memories, voting on hot issues, etc. This leads to a model in which visitors are actively engaged in shaping the future display (and interpretation) of exhibitions.
Stefanie Posavec appointed as a data artist in residence.
SoundWalk Strazky at Slovak National Gallery: audio-geography soundwalks as an immersive experiential exhibition; can be done relatively cheaply, at the basic end. Telling fictional
stories (based on reality) can help engage visitors with content (in this case, recreating scenes from artists’ lives). Interlingual challenges. Delivery via Phonegap app which provides
map and audio at “spots”; with a simple design that discourages staring-at-the-screen (only use digital to improve access to content!).
Lightning talks:
Maritime Museum Greenwich: wanted to find out how people engage with objects – we added both a museum interpretation and a community message to each object. Highly-observational
testing helped see how hundreds of people engage with content. Lesson: curators are not good judges of how their stuff will be received; audience ownership is amazing. Be reactive.
Visitors don’t mind being testers of super-rough paper-based designs.
Nordic Museum / Swedish National Heritage Board explored Generous Interfaces: show first, don’t ask, rich overviews, interobject relationships, encourage exploration etc. (Whitelaw,
2012). Open data + open source + design sprints (with coding in between) + lots of testing = a collaborative process. Use testing to decide between sorting OR filtering;
not both! As a bonus, generous interfaces encourage finding of data errors. bit.ly/2CNsNna
IWM on the centenary of WWI: thinking about continuing the crowdsourcing begun by the IWM’s original mission. Millions of assets have been created by users. Highly-collaborative
mechanism to explore, contribute to, and share a data space.
Lauren Bassam (@lswbassam) on LGBT History and co-opting of Instagram as an archival space: Instagram is an unconventional archival source, but provides a few benefits in
collaboration and engagement management, and serves as a viable platform for stories that are hard to tell using the collections in conventional archives. A suitably-engaged community
can take pride in their accuracy and their research cred, whether or not you strictly approve of their use of the term “archivist”. With closed stacks, we sometimes forget how important
engagement, touch, exploration and play can be.
Owen Gower (@owentg) from Dr. Jenner’s House Museum and Garden: they received EU REVEAL funding to look at VR as an engagement tool. Their game is for PSVR and has a commercial
release. The objects that interested the game designers the most weren’t necessarily those which the curators might have chosen. Don’t let your designers get carried away and fill the
game with e.g. zombies. But work with them, and your designers can help you find not only new ways to tell stories, but new stories you didn’t know you could
tell. Don’t be afraid to use cheap/student developers!
Rebecca Kahm @rebamex from Pelagios Commons (@Pelagiosproject): the problem with linked data is that it’s hard to show its value to end users (or even show museums “what you can do”
with it). Coins have great linked data, in collections. Peripleo was used to implement a sort-of “reverse Indiana Jones”: players try to recover information to find where an
artefact belongs.
Jon Pratty: There are lots of useful services (Flickr, Storify etc.) and many are free (which is great)… but this produces problems for us in terms of the long-term
life of our online content, not to mention the ethical issues with using services whose business model is built on trading personal data of our users. [Editor’s note: everything being
talked about here is the stuff that the Indieweb movement have been working on for some time!] We need to de-siloise and de-centralise our content
and services. redecentralize.org? responsibledata.io?
In-House Collaboration and the State of the Sector:
Rosie Cardiff @RosieCardiff, Serpentine Galleries on Mobile Tours. Delivered as web application via captive WiFi hotspot. Technical challenges were significant for a relatively
small digital team, and there was some apprehension among frontline staff. As a result of these and other problems, the mobile tours were underused. Ideas to overcome barriers: report
successes and feedback, reuse content cross-channel, fix bugs ASAP, invite dialogue. Interesting that they’ve gained a print guides off the back of the the digital. Learn lessons and
relaunch.
Sarah Younaf @sarahyounas, Tyne & Wear Museums. Digital’s job is to ask the questions the museum wouldn’t normally ask, i.e. experimentation (with a human-centric bias). Digital is
quietly, by its nature, “given permission” to take risks. Consider establishing relationships with (and inviting-in) people who will/want to do “mashups” or find alternative uses for
your content; get those conversations going about collections access. Experimental Try-New-Things afternoons had value but this didn’t directly translate into ideas-from-the-bottom,
perhaps as a result of a lack of confidence, a requirement for fully-formed ideas, or a heavy form in the application process for investment in new initiatives. Remember you can’t
change everyone, but find champions and encourage participation!
Kati Price @katiprice on Structuring for Digital Success in GLAM. Study showed that technical leadership and digital management/analysis is rated as vital, yet they’re also
underrepresented. Ambitions routinely outstrip budgets. Assumptions about what digital teams “look” like from an org-chart perspective don’t cover the full diversity: digital teams look
very different from one another! Forrester Research model of Digital Maturity seems to be the closest measure of digital maturity in GLAM institutions, but has flaws (mostly relating to
its focus in the commercial sector): what’s interesting is that digital maturity seems to correlate to structure – decentralised less mature than centralised less mature than
hub-and-spoke less mature than holistic.
Jennifer Wexler, Daniel Pett, Chiara Bonacchi on Diversifying Museum Audiences through Participation and stuff. Crowdsourcing boring data entry tasks is sometimes easier than asking
staff to do it, amazingly. For success, make sure you get institutional buy-in and get press on board. Also: make sure that the resulting data is open so everybody can
explore it. Crowdsourcing is not implicitly democratisating, but it leads to the production of data that can be. 3D prints (made from 3D cutouts generated by crowdsourcing) are a useful
accessibility feature for bringing a collection to blind or partially-sighted visitors, for example. Think about your audiences: kids might love your hip VR, but if their parents hate
it then you still need a way to engage with them!
As of next week, I’ll have been blogging for 20 years, or about 54% of my life. How did that happen?
I’d been “blogging” – not that we called it that, yet – since late 1998, but my original collection of content-mangling Perl scripts wasn’t all that. More history…
The mid-1990s were a very different time for the World Wide Web (yes, we still called it that, and sometimes we even described its use as “surfing”). Going “on the Internet” was a
calculated and deliberate action requiring tying up your phone line, minutes of “connecting” along with all of the associated screeching sounds if you hadn’t
turned off your modem’s loudspeaker, and you’d typically be paying twice for the experience: both a monthly fee to your ISP for the service and a per-minute charge to your phone company for the call.
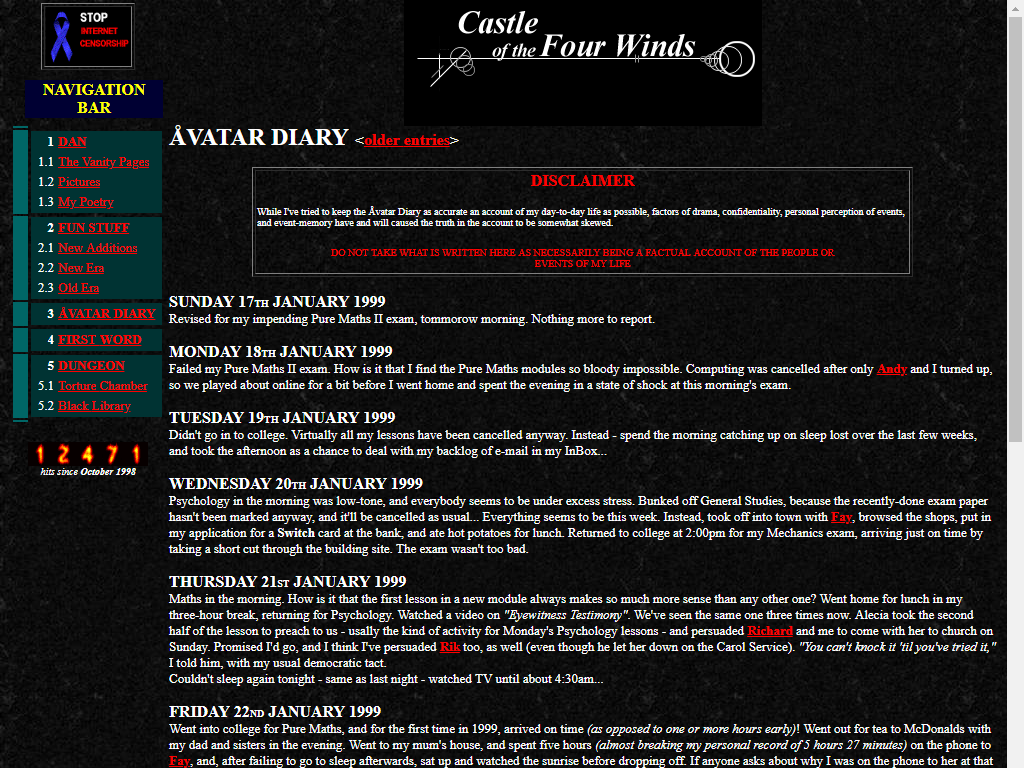
It was into this environment that in 1994 I published my first web pages: as far as I know, nothing remains of them now. It wasn’t until 1998 that I signed up an account with UserActive (whose website looks almost the same today as it did then) who offered economical subdomain hosting with shell and CGI support and launched “Castle of the Four Winds”, a set of vanity pages that
included my first blog.
Except I didn’t call it a “blog”, of course, because it wasn’t until the following year that Peter Merholz invented the word (he also commemorated 20 years of blogging, this year). I didn’t even call it a “weblog”, because
that word was still relatively new and I wasn’t hip enough to be around people who said it, yet. It was self-described as an “online diary”, a name which only served to
reinforce the notion that I was writing principally for myself. In fact, it wasn’t until mid-1999 that I discovered that it was being more-widely read than just by me and my
circle of friends when I attracted a stalker who travelled across the UK to try to “surprise” me by turning up at places she expected to
find me, based on what I’d written online… which was exactly as creepy as it sounds.
AvAngel.com
While the world began to panic that the coming millennium was going to break all of the computers, I migrated Castle of the Four Winds’ content into AvAngel.com, a joint vanity site
venture with my friend Andy. Aside from its additional content (purity tests, funny stuff, risqué e-cards), what we hosted was mostly the same old stuff, and I continued to write
snippets about my life in what was now quite-clearly a “blog-like” format, with the most-recent posts at the top and separate pages for content too old for the front page. Looking back,
there’s still a certain naivety to these posts which exemplify the youth of the Web. For example, posts routinely referenced my friends by their email
addresses, because spam was yet to become a big enough problem that people didn’t much mind if you put their email address on a public webpage somewhere, and because email
addresses still carried with them a feeling of anonymity that ceased to be the case when we started using them for important things.
Technologically-speaking, too, this was a simpler time. Neither Javascript nor CSS support was widespread (nor
consistently-standardised) enough to rely upon for anything other than the simplest progressive enhancement unless you were willing to “pick a side” in what we’d subsequently call the
first browser war and put one of those apalling “best viewed in Internet Explorer” or “best viewed in Netscape Navigator” banners on your site. I’ve always been a believer in a
universal web (and my primary browser at the time was Opera, anyway, as it mostly-remained until Opera went wrong in 2013), and I didn’t have the energy to write everything twice, so our cool/dynamic
functionality came mostly from back-end (e.g. Perl, PHP) technologies.
Meanwhile, during my initial months as a student in Aberystwyth, I wrote a series of emails to friends back home entitled “Cool And Interesting Thing Of The Day To Do At The University
Of Wales, Aberystwyth”, and put copies of each onto my student webspace; I’ve since recovered these and integrated them into my unified blog.
Scatmania.org
In 2002 I’d bought the domain name scatmania.org – a reference to my university halls of residence nickname “Scatman Dan”; I genuinely didn’t consider the possibility that the name
might be considered scatalogical until later on. As I wanted to continue my blogging at an address that felt like it was solely mine (AvAngel.com having been originally shared with a
friend, although in practice over time it became associated only with me), this seemed like a good domain upon which to relaunch. And so, in
mid-2003 and powered by a short-lived and ill-fated blogging engine called Flip I did exactly that. WordPress, to which I’d subsequently migrate, hadn’t been invented yet and it wasn’t clear whether its predecessor,
b2/cafelog, would survive the troubles its author was experiencing.
From this point on, any web address for any post made to my blog still works to this day, despite multiple technological and infrastructural changes to my blog (and
some domain name shenanigans!) in the meantime. I’d come to be a big believer in the mantra that cool URIs don’t change: something that as far as possible I’ve committed to trying to upload in my blogging, my archiving, and my paid work since
then. I’m moderately confident that all extant links on the web that point to earlier posts are all under my control so they can (and in most cases have) been fixed
already, so I’m pretty close to having all my permalink URIs be “cool”, for now. You might hit a short chain of redirects,
but you’ll get to where you’re going.
And everything was fine, until one day in 2004 when it wasn’t. The server hosting scatmania.org died in a very bad way, and because
my backup strategy was woefully inadequate, I lost a lot of content. I’ve recovered quite a lot of it and put it back in-place, but some is probably gone forever.
One of the longest-lived web designs for scatmania.org paid homage to the original, but with more “blue” and a WordPress backing.
The resurrected site was powered by WordPress, and this was the first time that live database queries had been used to power my blog. Occasionally,
these days, when talking to younger, cooler developers, I’m tempted to follow the hip trend of reimplementing my blog as a static site, compiling a stack of host-anywhere HTML files based upon whatever-structure-I-like at the “backend”… but then I remember that I basically did that already for six
years and I’m far happier with my web presence today. I’ve nothing against static site systems (I’m quite partial to Middleman, myself,
although I’m also fond of Hugo) but they’re not right for this site, right now.
IndieAuth hadn’t been invented yet, but I was quite keen on the ideals of OpenID (I still am, really), and
so I implemented what was probably the first viable “install-anywhere” implementation of OpenID for WordPress – you can see part of it
functioning in the top-right of the screenshot above, where my (copious, at that time) LiveJournal-using friends were encouraged to sign in to my blog using their LiveJournal identity.
Nowadays, the majority of the WordPress plugins I use are ones I’ve written myself: my blog is powered by a CMS that’s more
“mine” than not!
I no longer have the images that made my 2006 redesign look even remotely attractive, so here it is mocked-up with block colours instead.
Over the course of the first decade of my blogging, a few trends had become apparent in my technical choices. For example:
I’ve always self-hosted my blog, rather than relying on a “blog as a service” or siloed social media platform like WordPress.com, Blogger, or LiveJournal.
I’ve preferred an approach of storing the “master” copy of my content on my own site and then (sometimes) syndicating it elsewhere: for
example, for the benefit of my friends who during their University years maintained a LiveJournal, for many years I had my blog cross-post to a LiveJournal account (and backfeed copies of comments back to my site).
I’ve favoured web standards that provided maximum interoperability (e.g. RSS with full content)
and longevity (serving HTML pages from permanent URLs, adding
“extra” functionality via progressive enhancement so as to ensure that content functioned e.g. without Javascript, with CSS
disabled or the specification evolved, etc.).
These were deliberate choices, but they didn’t require much consideration: growing up with a Web far less-sophisticated than today’s (e.g. truly stateless prior to the advent of
HTTP cookies) and seeing the chaos caused during the first browser war and the period of stagnation that followed, these choices seemed intuitive.
That body font is plain old Verdana, you know: I’ve always felt that it (plus full justification) was the right choice for this particular design, even though I regret other parts of
it (like the brightness!).
As you’d expect from a blog covering a period from somebody’s teen years through to their late thirties, there’ve been significant changes in the kinds of content I’ve posted (and the
tone with which I’ve done so) over the years, too. If you dip into 2003, for example, you’ll see the results of quiz memes and
unqualified daily minutiae alongside actual considered content. Go back
further, to early 1999, and it is (at best) meaningless wittering about the day-to-day life of a teenage student. It took until around
2009/2010 before I actually started focussing on writing content that specifically might be enjoyable for others to read (even where
that content was frankly silly) and only far more-recently-still that I’ve committed to the “mostly technical stuff, ocassional bits of ‘life’ stuff” focus that I have today.
I say “committed”, but of course I’m fully aware that whatever this blog is now, it’ll doubtless be something somewhat different if I’m still writing it in another two decades…
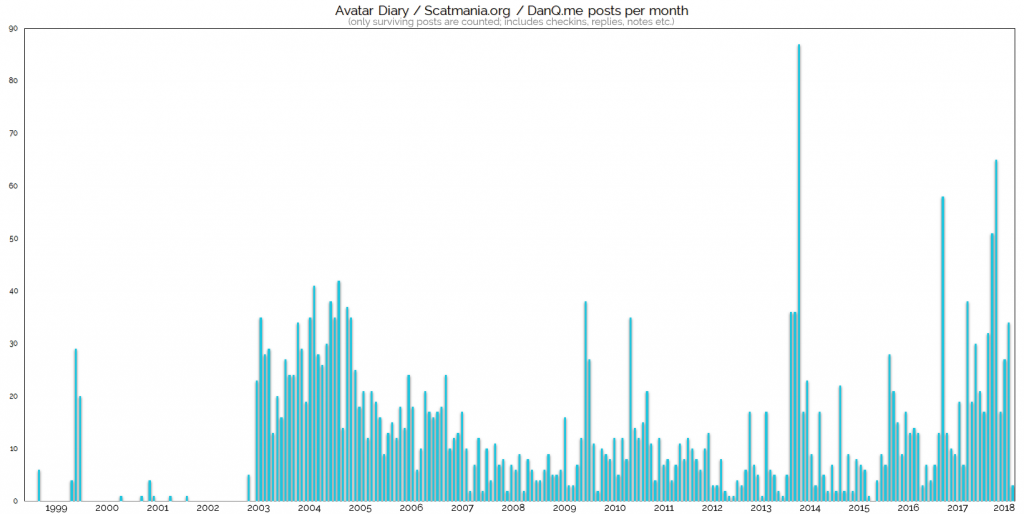
2014 may have included my most-prolific month of blogging, but 2003-2005 saw the most-consistent high-volume of content.
Once I reached the 2010s I started actually taking the time to think about the design of my blog and its meaning. Conceptually, all of my content is data-driven: database tables full of
different “kinds” of content and associated metadata, and that’s pretty-much ideal – it provides a strong separation between content and presentation and makes it possible to make
significant design changes with less work than might otherwise be expected. I’ve also always generally favoured a separation of concerns in web development and so I’m not a fan
of CSS design methodologies that encourage class names describing how things should appear, like Atomic CSS. Even where it results
in a performance hit, I’d far rather use CSS classes to describe what things are or represent. The single biggest
problem with this approach, to my mind, is that it violates the DRY principle… but that’s something that your CSS preprocessor’s there to fix for you, isn’t it?
But despite this philosophical outlook on the appropriate gap between content and presentation, it took until about 2010 before I actually attached any real significance to the
presentation at all! Until this point, I’d considered myself to have been more of a back-end than a front-end engineer, and felt that the most-important thing was to get the
content out there via an appropriate medium. After all, a site without content isn’t a site at all, but a site without design is (or at least should be) still intelligible
thanks to browser defaults! Remember, again, that I started web development at a time when stylesheets didn’t exist at all.
My previous implementations of my blog design had used simple designs, often adapted from open-source templates, in an effort to get them deployed as quickly as possible and move on to
the next task, but now, I felt, it was time to do a little more.
My 2010 relaunch put far more focus on the graphical design elements of my blog as well as providing a fully responsive design based on (then-new) CSS media queries. Alongside my
focus on separation of concerns in web development, I’m also quite opinionated on the idea that a responsive design has almost always been a superior solution to having a separate
“mobile site”.
For a few years, I was producing a new theme once per year. I experimented with different colours, fonts, and layouts, and decided (after some ad-hoc A/B testing) that my audience was
better-served by a “front” page than by being dropped directly into my blog archives as had previously been the case. Highlighting the latest few – and especially the very-latest – post
and other recent content increased the number of posts that a visitor would be likely to engage with in a single visit. I’ve always presumed that the reason for this is that regular
(but non-subscribing) readers are more-likely to be able to work out what they have and haven’t read already from summary text than from trying to decipher an entire post: possibly
because my blogging had (has!) become rather verbose.
My 2011 design, in hindsight, said more about my mood and state-of-mind at the time than it did about artistic choices: what’s with all the black backgrounds and seriffed fonts? Is
this a funeral parlour?
I went through a bit of a lull in blogging: I’ve joked that I spent more time on my 2010 and 2011 designs than I did on the sum total of the content that was published in between the
pair of them (which isn’t true… at least, not quite!). In the month I left Aberystwyth for Oxford, for example, I was doing all kinds of exciting and new things…
and yet I only wrote a total of two blog posts.
With RSS waning in popularity – which I can’t understand: RSS is amazing! – I began to crosspost to
social networks like Twitter and Google+ (although no longer to Google+, following the news of its imminent demise) to help those readers who prefer to get their content via these
media, but because I wasn’t producing much content, it probably didn’t make a significant difference anyway: the chance of a regular reader “missing” something must have been remarkably
slim.
The 2012 design featured “CSS peekaboo”: a transformation that caused my head to “hide” from you behind the search bar if your cursor got too close. Ruth, I hear, spent far too long playing with just this feature.
Nobody calls me “Scatman Dan” any more, and hadn’t for a long, long time. Given that my name is already awesome and unique
all by itself (having changed to be so during the era in which scatmania.org was my primary personal domain name), it felt like I had the opportunity to rebrand.
I moved my blog to a new domain, DanQ.me (which is nice and short, too) and came up with a new collection of colours, fonts, and layout choices that I felt better-reflected my identity…
and the fact that my blog was becoming less a place to record the mundane details of my daily life and more a place where I talk about (principally-web)
technology, security, and GPS games… and just occasionally about other topics like breadmaking and books. Also, it gave me a chance to get on top of the current trend in web design for big, clean, empty spaces, square corners, and using pictures
as the hook to a story.
The second design of my blog after moving to DanQ.me showed-off posts with big pictures, framed by lots of white-space.
I’ve been working harder this last year or two to re-integrate (in a PESOS-like way) into my blog content that I’ve published elsewhere, mostly geocaching logs and
geohashing expedition records, and I’ve also done so retroactively, so in addition to my first blog article on the subject
of geocaching, you can read my first ever cache log without switching to a different site nor relying upon the
continued existence and accessibility of that site. I’ve been working at being increasingly mindful of where my content is siloed outside of my control and reclaiming it by hosting it
here, on my blog.
Particular areas in which I produce content elsewhere but would like to at-least maintain a copy here, and would ideally publish here first and syndicate elsewhere, although I
appreciate that this is difficult, are:
Reddit, where I’ve written tens of thousands of words under a variety of accounts, but I don’t really pay attention to the site any more
I left Facebook in 2011 but I still have a backup of what was on my “Wall” at that point, which I could look into reintegrating into my
blog
I share a lot of the source code I write via my GitHub account, but I’m painfully aware that this is yet-another-silo that I ought to learn
not to depend upon (and it ought to be simple enough to mirror my repos on my own site!)
I’ve got a reasonable number of videos on two YouTube channels which are online by Google’s good graces (and potential for advertising
revenue); for a handful of technical reasons they’re a bit of a pain to self-host, but perhaps my blog could act as a secondary source to my own video content
I write business reviews on Google Maps which I should probably look into recovering from the hivemind and hosting here… in fact, I’ve
probably written plenty of reviews on other sites, too, like Amazon for example…
On two previous occasions I’ve maintained an online photo gallery; I might someday resurrect the concept, at least for the photos that used to be published on them
I’ve dabbled on a handful of other, often weirder, social networks before like Scuttlebutt (which has a genius concept, by the way) and
Ello, and ought to check if there’s anything “original” on there I should reintegrate
Going way, way back, there are a good number of usenet postings I’ve made over the last twenty-something years that I could reclaim, if I can find them…
(if you’re asking why I’m inclined to do all of these things: here’s why)
This looks familiar.
20 years and around 717,000 words worth of blogging down, it’s interesting to look back and see how things have changed: in my life, on the Web, and in the world in general. I’ve seen
many friends’ blogs come and go: they move into a new phase of their life and don’t feel like what they wrote before reflects them today, most often, and so they delete them… which is
fine, of course: it’s their content! But for me it’s always felt wrong to do so, for two reasons: firstly, it feels false to do so given that once something’s been put on the Web, it
might well be online forever – you can’t put the genie back in the bottle! And secondly: for me, it’s valuable to own everything I wrote before. Even the cringeworthy things I
wrote as a teenager who thought they knew everything and the antagonistic stuff I wrote in my early 20s but that I clearly wouldn’t stand by today is part of my history, and
hiding that would be a disservice to myself.
The 17-year-old who wrote my first blog posts two decades ago this month fully expected that the things he wrote would be online forever, and I don’t intend to take that away from him.
I’m sure that when I write a post in October 2038 looking back on the next two decades, I’ll roll my eyes at myself today, too, but for me: that’s part of the joy of a
long-running personal blog. It’s like a diary, but with a sense of accountability. It’s a space on the web that’s “mine” into which I can dump pretty-much whatever I like.
I love it: I’ve been blogging for over half of my life, and if I can get back to you in 2031 and tell you that I’ve by-then been doing so for two-thirds of my life, that would be a win.
This weekend, I attended part of Oxford’s first ever IndieWebCamp! As a long (long, long) time
proponent of IndieWeb philosophy (since long before anybody said “IndieWeb”, at least) I’ve got my personal web presence pretty-well sorted out.
Still, I loved the idea of attending and pushing some of my own tools even further: after all, a personal website isn’t “finished” until its owner says it is! One of the things I ended
up hacking on was pretty-predictable: enhancements to my recently-open-sourced geocaching PESOS tools… but the
other’s worth sharing too, I think.
Some of IndieWebCamp Oxford’s attendees share knowledge and hack code together.
I’ve recently been playing with WebVR – for my day job at the Bodleian, I swear! – and I was looking for
an excuse to try to expand some of what I’d learned into my personal blog, too. Given that I’ve recently acquired a Ricoh Theta
V I thought that this’d be the perfect opportunity to add WebVR-powered panoramas to this site. My goals were:
Entirely self-hosted; no external third-party dependencies
Must degrade gracefully (i.e. even if you’re using an older browser, don’t have Javascript enabled, etc.) it should at least show the original image
In plain-old browsers should support mouse (or touch) control to pan the scene
Where accelerators are available (e.g. mobiles), “magic window” support to allow twist-to-explore
And where “true” VR hardware (Cardboard, Vive, Rift etc.) with WebVR support is available, allow one-click use of that
It wouldn’t be a geeky hacky camp thingy if it didn’t finish at a bar.
Hopefully the images above are working for you and are “interactive”. Try click-and-dragging on them (or tilt your device), try fullscreen mode, and/or try WebVR mode if you’ve got
hardware that supports it. The mechanism of operation is slightly hacky but pretty simple: here’s how it works:
The image is inserted into the page as normal but with an extra CSS class of “vr360” and a data attribute pointing to the full-resolution image, e.g.:
<img class="vr360" src="/uploads/2018/09/R0010005_20180922182210-1024x512.jpg" alt="IndieWebCamp Oxford attendees at the pub" width="640" height="320"
data-vr360="/uploads/2018/09/R0010005_20180922182210.jpg" />
Some Javascript swaps-out images with this class for an iframe of the same size, showing a special page and passing the image filename after the hash, e.g.:
for(vr360 of document.querySelectorAll('.vr360')){
const width = parseInt(vr360.width);
const height = parseInt(vr360.height);
if(width == 0) width = '100%'; // Fallback for where width/height not specified,
if(height == 0) height = '100%'; // needed because of some quirks with Dan's lazy-loader
vr360.outerHTML = `<iframe src="/q23-content/themes/q18/vr360/#${vr360.dataset.vr360}" width="${width}" height="${height}" class="aligncenter" class="vr360-frame" style="min-width:
340px; min-height: 340px;"></iframe>`;
}
The iframe page loads this Javascript file. This loads three.js (to make 3D things easy)
and WebVR-polyfill (to fix browser quirks). Finally (scroll to the bottom of the code), it creates a camera in the centre
of a sphere, loads the image specified in the hash, flips it, and paints it onto the inside surface of the sphere, sets up controls, and turns the user loose on it. That’s all there is
to it!
You’re welcome to any of my code if you’d like a drop-in approach to hosting panoramic photographs on your own personal site. My solution’s pretty extensible if you want e.g.
interactive hotspots or contextual overlays – in fact, that – plus an easy route to editing the content for less-technical users – is pretty-much exactly what I’m working on for my day
job at the moment.
I’m here at the first IndieWebCamp Oxford. I can’t quite believe it all came together!
Listening to @garrettc kick us off at @indiewebcamp #oxford! #indieweb pic.twitter.com/4Pn1yetifA— Dan Q (@scatmandan) 22 September 2018
After some introductory rambling from me, the group got down to planni…
I’m here at the first IndieWebCamp Oxford. I can’t quite believe it all came together!
Just discovered @openbenches (openbenches.org), which tags the locations of benches with memorial plaques. If I could #indieweb webmention my checkins to them, I’d totally
promote a new GPS game based upon them. #indieweb #indiewebcamp
As an ocassional geocacher and geohasher, I’m encouraged to post logs describing my adventures, and each major provider wants me to post my logs into theirsilo (see e.g. my logs on geocaching.com, on opencache.uk, and on the geohashing wiki). But as a believer in
the ideals behind the IndieWeb (since long before anybody said “IndieWeb”), I’m opposed to keeping the only copy of content that I produce in an
environment controlled by somebody else (why?).
How do I reconcile this?
Just another hundred metres to the cache, then it’s time to freeze my ass back to base.
What I’d prefer would be to be able to write my logs here, on my own blog, and for my content to by syndicated via some process into the logging systems of the various silo sites I
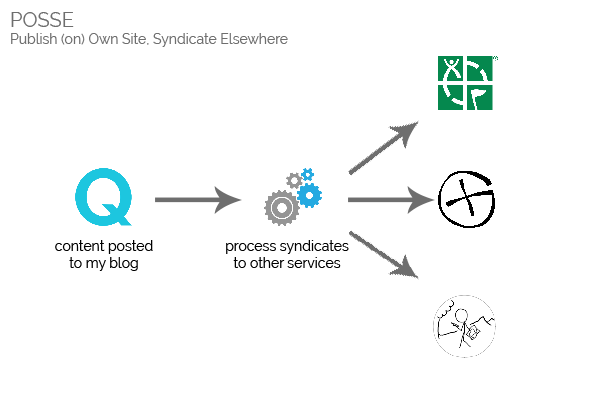
prefer. This approach is called POSSE – Publish on Own Site, Syndicate
Elsewhere. In addition to the widely-described benefits of this syndication strategy, such a system would also make it possible for me to:
write single posts that represent the same location published on multiple silos (e.g. a visit to a geocache published on two different listing sites [e.g. 1, 2])
Applying such an tool would require some work as different silos have different acceptable content rules (geocaching.com, for example, effectively forbids mention of the existence of
other geocache listing sites), but that’d theoretically be workable.
The ideal solution would be POSSE-based.
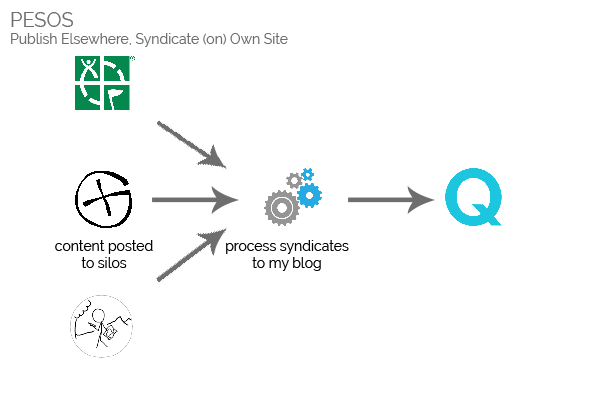
Unfortunately, content rules aren’t the only factor making PESOS – writing content into each silo and then copying it
to my blog – preferable to POSSE. There’s also:
Not all of the silos offer suitable (published) APIs, and where they do, the APIs are all distinctly different.
Geocaching.com specifically forbids the use of unapproved automated robots to access the site (and almost
certainly wouldn’t approve the kind of tool that would be ideal).
The siloed services are well-supported by official and third-party apps with medium-specific logic which make them the best existing way to produce logs.
A PESOS-based solution is far easier to implement, in this case.
Needless to say: as much as I’d have loved to POSSE my geo* logs, PESOS will do.
Implementation
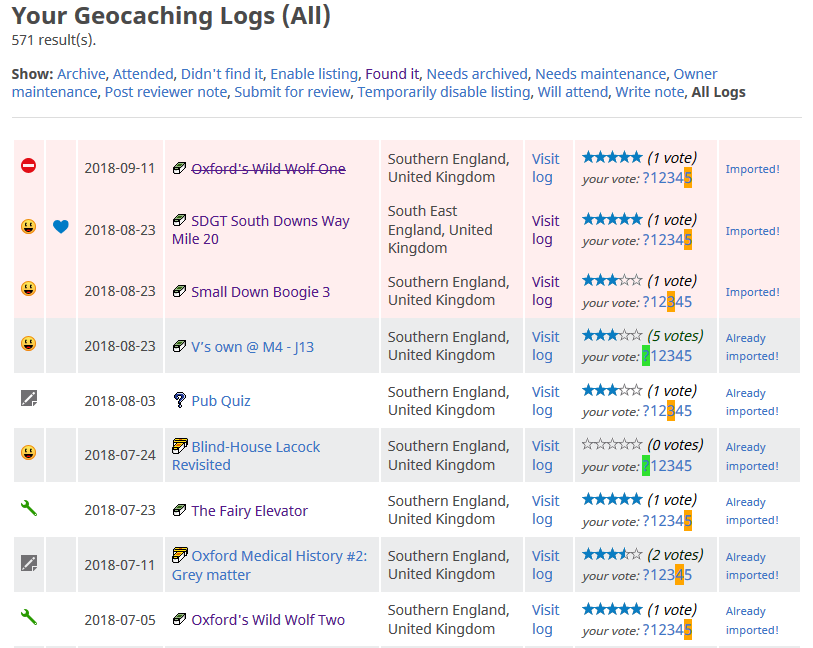
My implementation is a WordPress plugin which does two things. The first is that it provides a Javascript bookmarklet and an
accompanying dynamically-generated Javascript file (the former loads the latter) served from my blog’s domain. That Javascript file contains reference to every log already published to
my blog, so that the Javascript code can deliberately omit these logs from any import. When executed on a log listing page like those linked above, it copies all of the details of that
log into a form which submits them back to my blog, where it’s received by the second part of the plugin.
The import controls appear in a new, right-most column (GCVote is also visible running in my browser).
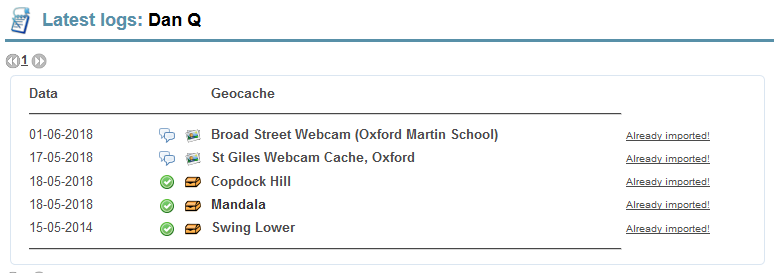
The second part of the plugin takes this data and creates a new draft post. My plugin is pretty opinionated on this part because it’s geared strongly towards my use-case, so if you want
to use it yourself you’ll probably want to tweak the code a little (e.g. it applies specific tags and names metadata fields a particular way).
When run on OpenCache.uk effectively the same interface is presented, even though the underlying mechanisms and data locations are different.
It’s not fully-automated and it’s not POSSE,but it’s “good enough” and it’s enabled me to synchronise all of my cache logs to my blog. I’ve plans to extend it to support other GPS game services to streamline my de-siloisation even further.
On Saturday 22nd September and Sunday 23rd September we will be having the first ever Oxford IndieWebCamp!
It is a free event, but I would ask that you register on Eventbrite, so I can get an
idea of numbers.
IndieWebCamp is a weekend gathering of web creators building & sharing their own websites to advance the independent web and empower ourselves and others to take control of our
online identities and data.
It is open to all skill levels, from people who want to get started with a web site, through to experienced developers wanting to tackle a specific personal project.
I gave a little presentation about the Indieweb at JS Oxford earlier this year if you want to
know more.
Last night I attended the always excellent JS Oxford, and as well as having my mind expanded by both Jo and Ruth’s talks (Lemmings make an excellent analogy for multi-threading, who
knew!), I gave a brief talk on the Indieweb movement.
If you’ve not heard of Indieweb movement before, it’s a pu…
Last night I attended the always excellent JS Oxford, and as well as having my mind expanded by
both Jo and Ruth’s talks (Lemmings make an excellent analogy for
multi-threading, who knew!), I gave a brief talk on the Indieweb movement.
If you’ve not heard of Indieweb movement before, it’s a push to encourage people to claim their own bit of the web, for their identity and content, free from corporate platforms. It’s
not about abandoning those platforms, but ensuring that you have control of your content if something goes wrong.
When you post something on the web, it should belong to you, not a corporation. Too many companies have gone out of business and lost all of their users’ data. By joining the
IndieWeb, your content stays yours and in your control.
You are better connected
Your articles and status messages can go to all services, not just one, allowing you to engage with everyone. Even replies and likes on other services can come back to your site so
they’re all in one place.
I’ve been interested in the Indieweb for a while, after attending IndieWebCamp Brighton in 2016, and I’ve been slowly
implementing Indieweb features on here ever since.
The great thing about the Indieweb is that you can implement as much or as little as you want, and it always gives you something to work on. It doesn’t matter where you start. The act
of getting your own domain is the first step on a longer journey.
To that end I’m interested in organising an IndieWebCamp Oxford this year. If this sounds like something that interests you, then come find me in the Digital Oxford Slack, or on Twitter.
I’m so excited to see that there are others in Oxford who care about IndieWeb things! I’ve honestly fantasised myself about running an IndieWebCamp or Homebrew Website Club here, but let’s face it: that fantasy is more one of a world in which I had the free time for such a venture. So
imagine my delight when somebody else offers to do the hard work!