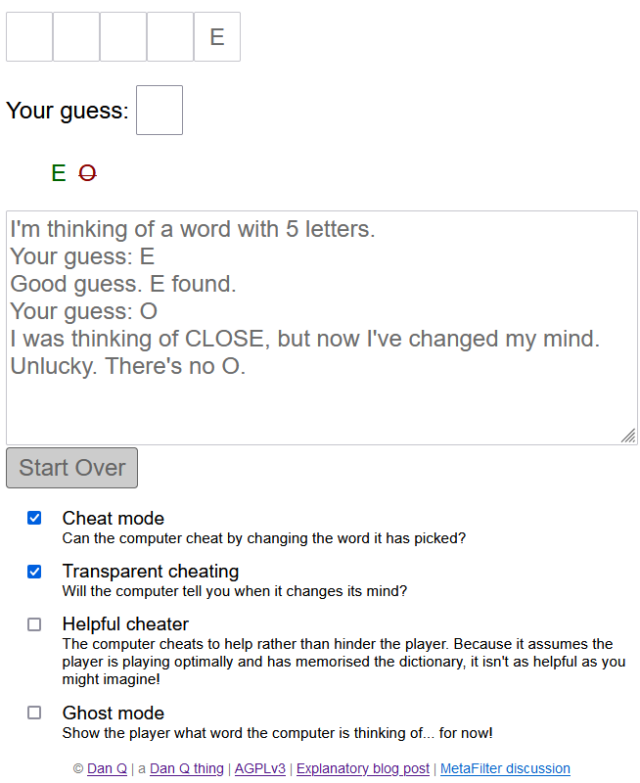
Look at the following list of words and try to find the intruder:
wp-activate.php
wp-admin
wp-blog-header.php
wp_commentmeta
wp_comments
wp-comments-post.php
wp-config-sample.php
wp-content
wp-cron.php
wp engine
wp-includes
wp_jetpack_sync_queue
wp_links
wp-links-opml.php
wp-load.php
wp-login.php
wp-mail.php
wp_options
wp_postmeta
wp_posts
wp-settings.php
wp-signup.php
wp_term_relationships
wp_term_taxonomy
wp_termmeta
wp_terms
wp-trackback.php
wp_usermeta
wp_users
What are these words?
Well, all the ones that contain an underscore _ are names of the WordPress core database tables. All the ones that contain a dash - are WordPress core file
or folder names. The one with a space is a company name…
…
A smart (if slightly tongue-in-cheek) observation by my colleague Paolo, there. The rest of his article’s cleverer and worth-reading if you’re following the WordPress Drama (but it’s
pretty long!).
tl;dr: I’m tidying up and consolidating my personal hosting; I’ve made a little progress, but I’ve got a way to go – fortunately I’ve got a sabbatical coming up at
work!
At the weekend, I kicked-off what will doubtless be a multi-week process of gradually tidying and consolidating some of the disparate digital things I run, around the Internet.
I’ve a long-standing habit of having an idea (e.g. gamebook-making tool Twinebook, lockpicking puzzle game Break Into Us, my Cheating Hangman game, and even FreeDeedPoll.org.uk!),
deploying it to one of several servers I run, and then finding it a huge headache when I inevitably need to upgrade or move said server because there’s such an insane diversity of
different things that need testing!
DNDle, my Wordle-clone where you have to guess the Dungeons & Dragons 5e monster’s stat block, is now hosted by GitHub Pages. Also, I
fixed an issue reported a month ago that meant that I was reporting Giant Scorpions as having a WIS of 19 instead of 9.
Abnib, which mostly reminds people of upcoming birthdays and serves as a dumping ground for any Abnib-related shit I produce, is now hosted by
GitHub Pages.
RockMonkey.org.uk, which doesn’t really do much any more, is now hosted by GitHub Pages.
Sour Grapes, the single-page promo for a (remote) murder mystery party I hosted during a COVID lockdown, is now hosted by GitHub
Pages.
A convenience-page for giving lost people directions to my house is now hosted by GitHub Pages.
Dan Q’s Things is now automatically built on a schedule and hosted by GitHub Pages.
Robin’s Improbable Blog, which spun out from 52 Reflect, wasn’t getting enough traffic to justify
“proper” hosting so now it sits in a Docker container on my NAS.
My μlogger server, which records my location based on pings from my phone, has also moved to my NAS. This has broken
Find Dan Q, but I’m not sure if I’ll continue with that in its current form anyway.
All of my various domain/subdomain redirects have been consolidated on, or are in the process of moving to, to a tinyLinode/Akamai
instance. It’s a super simple plain Nginx server that does virtually nothing except redirect people – this is where I’ll park the domains I register but haven’t found a use for yet, in
future.
I was pretty proud of EGXchange.org, but I’ll be first to admit that it’s among the stupider of my throwaway domains.
It turns out GitHub pages is a fine place to host simple, static websites that were open-source already. I’ve been working on improving my understanding of GitHub Actions
anyway as part of what I’ve been doing while wearing my work, volunteering, and personal hats, so switching some static build processes like DNDle’s to GitHub
Actions was a useful exercise.
Stuff I’m still to tidy…
There’s still a few things I need to tidy up to bring my personal hosting situation under control:
DanQ.me
You’re looking at it. But later this year, you might be looking at it… elsewhere?
This is the big one, because it’s not just a WordPress blog: it’s also a Gemini, Spartan, and Gopher server (thanks CapsulePress!), a Finger server, a general-purpose host to a stack of complex stuff only some of which is powered by Bloq (my WordPress/PHP integrations): e.g.
code to generate the maps that appear on my geopositioned posts, code to integrate with the Fediverse, a whole stack of configuration to make my caching work the way I want, etc.
FreeDeedPoll.org.uk
Right now this is a Ruby/Sinatra application, but I’ve got a (long-running) development branch that will make it run completely in the browser, which will further improve privacy, allow
it to run entirely-offline (with a service worker), and provide a basis for new features I’d like to provide down the line. I’m hoping to get to finishing this during my Automattic
sabbatical this winter.
The website’s basically unchanged for most of a decade and a half, and… umm… it looks it!
A secondary benefit of it becoming browser-based, of course, is that it can be hosted as a static site, which will allow me to move it to GitHub Pages too.
When I took over running the world’s geohashing hub from xkcd‘s Randall Munroe (and davean), I flung the site together on whatever hosting I had sitting
around at the time, but that’s given me some headaches. The outbound email transfer agent is a pain, for example, and it’s a hard host on which to apply upgrades. So I want to get that
moved somewhere better this winter too. It’s actually the last site left running on its current host, so it’ll save me a little money to get it moved, too!
Geohashing’s one of the strangest communities I’m honoured to be a part of. So it’d be nice to treat their primary website to a little more respect and attention.
Right now I run this on my NAS, but that turns out to be a pain sometimes because it means that if my home Internet goes down (e.g. thanks to a power cut, which we have from time to time), I lose access to the first and last place I
go on the Internet! So I’d quite like to move that to somewhere on the open Internet. Haven’t worked out where yet.
Next steps
It’s felt good so far to consolidate and tidy-up my personal web hosting (and to rediscover some old projects I’d forgotten about). There’s work still to do, but I’m expecting to spend
a few months not-doing-my-day-job very soon, so I’m hoping to find the opportunity to finish it then!
Maintaining a blog can be a lot of work. A single article can take weeks of research, drafting and editing, collecting and producing included materials, etc. It’s not unusual to
seek some form of compensation for it, and those rewards require initiative. With a good monetization strategy, it can become a fairly
lucrative venture.
So let’s talk about monetizing a blog, starting with the most obvious and perhaps easiest avenue: display advertising.
A content creator with an established audience can leverage that audience and sell ad space on their blog. Here’s an example:
…
I’m not sure I have words for how awesome this blog post is. If you’ve ever wanted to monetise your blog and are considering an ad-driven model, this should absolutely be the first (and
perhaps last) thing you read on the subject.
If you’re not convinced that Tyler is an appropriate authority to speak on this subject, I highly suggest you visit their other site that’s got a wealth of useful tips, PutAToothpickInTheChargingPortDoctorsHateThatShit.christmas. Yes, really.
If the most useful thing I achieve this Bank Holiday Monday will have been to make it easier to post short geotagged notes from my mobile to my blog (and Mastodon), it will have been a
success.
This has been a test post. Feel free to ignore it.
I used to pay for VaultPress. Nowadays I get it for free as one of the many awesome perks of my job. But I’d probably still pay for it
because it’s a lifesaver.
Like my occasional video content, this isn’t designed to replace any of my blogging: it’s just a different medium for those that might prefer it.
For some stories, I guess that audio might be a better way to find out what I’ve been thinking about. Just like how the vlog version of my post about
my favourite video game Easter Egg might be preferable because video as a medium is better suited to demonstrating a computer game, perhaps
audio’s the right medium for some of the things I write about, too?
But as much as not, it’s just a continuation of my efforts to explore different media over which a WordPress blog can be delivered2.
Also, y’know, my ongoing effort to do what I’m bad at in the hope that I might get better at a wider diversity of skills.
How?
Let’s start by understanding what a “podcast” actually is. It is, in essence, just an RSS feed (something you might have heard me talk about before…) with audio enclosures – basically, “attachments” – on each item. The idea was spearheaded by Dave Winer back in 2001 as a
way of subscribing to rich media like audio or videos in such a way that slow Internet connections could pre-download content so you didn’t have to wait for it to buffer.3
Podcasts are pretty simple, even after you’ve bent over backwards to add all of the metadata that Apple Podcasts (formerly iTunes) expects to see. I looked at a couple of
WordPress plugins that claimed to be able to do the work for me, but eventually decided it was simple enough to just add some custom metadata fields that could then be included in my
feeds and tweak my theme code a little.
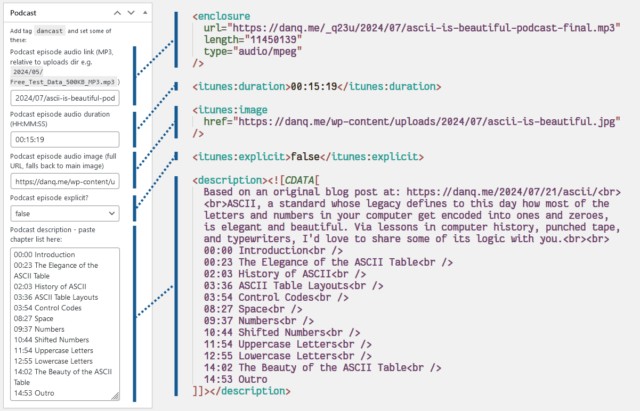
Here’s what I had to do to add podcasting capability to my theme:
The tag
I use a post tag, dancast, to represent posts with accompanying podcast content4.
This way, I can add all the podcast-specific metadata only if the user requests the feed of that tag, and leave my regular feeds untampered . This means that you don’t
get the podcast enclosures in the regular subscription; that might not be what everybody would want, but it suits me to serve podcasts only to people who explicitly ask for
them.
Okay, onto the code (which I’ve open-sourced over here). I’ve use a series of standard WordPress hooks to
add the functionality I need. The important bits are:
rss2_item – to add the <enclosure>, <itunes:duration>, <itunes:image>, and
<itunes:explicit> elements to the feed, when requesting a feed with my nominated tag. Only <enclosure> is strictly required, but appeasing Apple
Podcasts is worthwhile too. These are lifted directly from the post metadata.
the_excerpt_rss – I have another piece of post metadata in which I can add a description of the podcast (in practice, a list of chapter times); this hook
swaps out the existing excerpt for my custom one in podcast feeds.
rss_enclosure – some podcast syndication platforms and players can’t cope with RSS feeds in which an item has multiple enclosures, so as a
safety precaution I strip out any enclosures that WordPress has already added (e.g. the featured image).
the_content_feed – my RSS feed usually contains the full text of every post, because I don’t like feeds that try to force you to go to the
original web page5
and I don’t want to impose that on others. But for the podcast feed, the text content of the post is somewhat redundant so I drop it.
rss2_ns – of critical importance of course is adding the relevant namespaces to your XML declaration. I use the itunes namespace, which provides the widest compatibility for specifying metadata, but I also use the
newer podcast namespace, which has growing compatibility and provides some modern features, most of which I don’t
use except specifying a license. There’s no harm in supporting both.
rss2_head – here’s where I put in the metadata for the podcast as a whole: license, category, type, and so on. Some of these fields are
effectively essential for best support.
You’re welcome, of course, to lift any of all of the code for your own purposes. WordPress makes a perfectly reasonable platform for podcasting-alongside-blogging, in my experience.
What?
Finally, there’s the question of what to podcast about.
My intention is to use podcasting as an alternative medium to my traditional blog posts. But not every blog post is suitable for conversion into a podcast! Ones that rely on images
(like my post about dithering) aren’t a great choice. Ones that have lots of code that you might like to copy-and-paste are especially unsuitable.
You’re listening to Radio Dan. 100% Dan, 100% of the time.(Also I suppose you might be able to hear my dog snoring in the background…)
Also: sometimes I just can’t be bothered. It’s already some level of effort to write a blog post; it’s like an extra 25% effort on top of that to record, edit, and upload a podcast
version of it.
That’s not nothing, so I’ve tended to reserve podcasts for blog posts that I think have a sort-of eccentric “general interest” vibe to them. When I learn something new and feel the need
to write a thousand words about it… that’s the kind of content that makes it into a podcast episode.
Which is why I’ve been calling the endeavour “a podcast nobody asked for, about things only Dan Q cares about”. I’m capable of getting nerdsniped
easily and can quickly find my way down a rabbit hole of learning. My podcast is, I guess, just a way of sharing my passion for trivial deep dives with the rest of the world.
My episodes are probably shorter than most podcasts: my longest so far is around fifteen minutes, but my shortest is only two and a half minutes and most are about seven. They’re meant
to be a bite-size alternative to reading a post for people who prefer to put things in their ears than into their eyes.
Anyway: if you’re not listening already, you can subscribe from here or in your favourite podcasting app. Or you can just follow my blog as normal
and look for a streamable copy of podcasts at the top of selected posts (like this one!).
2 As well as Web-based non-textual content like audio (podcasts) and video (vlogs), my blog is wholly or partially available over a variety of more-exotic protocols: did you find me yet on Gemini (gemini://danq.me/), Spartan (spartan://danq.me/), Gopher (gopher://danq.me/), and even Finger
(finger://danq.me/, or run e.g. finger blog@danq.me from your command line)? Most of these are powered by my very own tool CapsulePress, and I’m itching to try a few more… how about a WordPress blog that’s accessible over FTP, NNTP, or DNS? I’m not even kidding when I say
I’ve got ideas for these…
3 Nowadays, we have specialised media decoder co-processors which reduce the size of media
files. But more-importantly, today’s high-speed always-on Internet connections mean that you probably rarely need to make a conscious choice between streaming or downloading.
4 I actually intended to change the tag to podcast when I went-live,
but then I forgot, and now I can’t be bothered to change it. It’s only for my convenience, after all!
Runners will talk about how much they enjoy the feeling of wind in their hair. Boxers won’t shut up about the grace and art of their profession. Even soccer players can be moved to
wax poetical about how enjoyable it is to be part of a truly great game.
But all golfers ever talk about is how little golf they hope to play. A typical pre-match interview will go something like this:
Some guy in a blazer: Great to have you here with us, what are your goals for the first round this morning.
Golfer: Well today I hope to play as little golf as possible. Mathematically speaking the course could be done in 18 shots but that is probably physically
impossible. But ideally as close to 18 as I can get. Any additional golf is bad.
Blazer: What is your strategy for avoiding the golf.
Golfer: I have a guy who follows me around to help share the burden of all this damn golf. He is going to help me out by suggesting ways to avoid playing any more
golf than we have to. Of course, I pay him but his real motivation is to bring this sorry excuse for a pastime to the speediest conclusion.
Blazer: Better you than me, but good luck out there.
Why must a blog comment be text? Why could it not be… a drawing?1
Red and black might be more traditional ladybird colours, but sometimes all you’ve got is blue.
I started hacking about and playing with a few ideas and now, on selected posts including this one, you can draw me a comment instead of typing one.
Just don’t tell the soup company what I’ve been working on, okay?
I opened the feature, experimentally (in a post available only to RSS subscribers2) the
other week, but now you get a go! Also, I’ve open-sourced the whole thing, in case you want to pick it apart.
What are you waiting for: scroll down, and draw me a comment!
Footnotes
1 I totally know the reasons that a blog comment shouldn’t be a drawing; I’m not
completely oblivious. Firstly, it’s less-expressive: words are versatile and you can do a lot with them. Secondly, it’s higher-bandwidth: images take up more space, take longer to
transmit, and that effect compounds when – like me – you’re tracking animation data too. But the single biggest reason, and I can’t stress this enough, is… the
penises. If you invite people to draw pictures on your blog, you’re gonna see a lot of penises. Short penises, long penises, fat penises, thin penises. Penises of every shape
and size. Some erect and some flacid. Some intact and some circumcised. Some with hairy balls and some shaved. Many of them urinating or ejaculating. Maybe even a few with smiley
faces. And short of some kind of image-categorisation AI thing, you can’t realistically run an anti-spam tool to detect hand-drawn penises.
2 I’ve copied a few of my favourites of their drawings below. Don’t forget to subscribe if you want early access to any weird shit I make.
In anticipation of WWW Day on 1 August, some work colleagues and I were
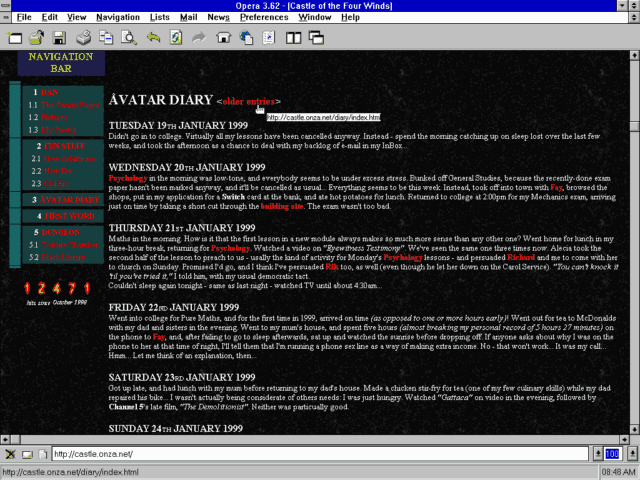
sharing pictures of the first (or early) websites we worked on. I was pleased to be able to pull out a screenshot of how my blog looked back in 1999!
Tables for layout, hit counter, web-safe colour scheme, and the need to explain what a “navigation bar” is in case they’ve not come across one before. Yup, this is 90s web design at
its peak and no mistake.
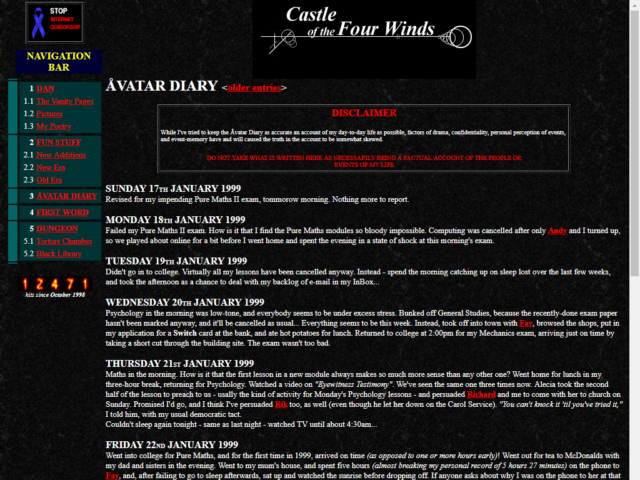
Because I’m such a digital preservationist, many of those ancient posts are still available on my blog, so I also shared a photo of me browsing the same content on my
blog as it is today, side-by-side with that 25+-year-old screenshot.1
The posts are in reverse-chronological order now, rather than chronological order, but the content’s all the same (even though the design is now very different and, of course,
responsive!).
I’ve even applied img { image-rendering: crisp-edges; } to try to compensate for modern browsers’ capability for subpixel rendering when rescaling images: let them
eat pixels!5
Or if you can’t be bothered to switch to 1999 Mode, you can just look at this screenshot to get an idea of how it looks.
I’ve added 1999 Mode to my April Fools gags so, like this year, if you happen to visit my site on or around 1 April,
there’s a change you’ll see it in 1999 mode anyway. What fun!
I think there’s a possible future blog post about Web design challenges of the 1990s. Things like: what it the user agent doesn’t support images? What if it supports GIFs, but not
animated ones (some browsers would just show the first frame, so you’d want to choose your first frame appropriately)? How do I ensure that people see the right content if they skip my
frameset? Which browser-specific features can I safely use, and where do I need a fallback6? Will this
work well on all resolutions down to 640×480 (minus browser chrome)? And so on.
Any interest in that particular rabbit hole of digital history?
Footnotes
1 Some of the addresses have changed, but from Summer 2003 onwards I’ve had a solid chain
of redirects in place to try to keep content available via whatever address it was at. Because Cool URIs Don’t Change. This occasionally turns out to be useful!
2 Actually, the entire theme is just a CSS change, so no tables are added. But I’ve tried to make it look like I’m using tables for layout, because that (and spacer GIFs) were all
we had back in the day.
3 Obviously the title saying “Dan Q” is modern, because that
wasn’t even my name back then, but this is more a reimagining of how my site would have looked if I were transported back to 1999 and made to do it all again.
4 I was slightly obsessed for a couple of years in the late 90s with flaming text on black
marble backgrounds. The hit counter in my screenshot above – with numbers on fire – was one I made, not a third-party one; and because mine was the only one of my friends’
hosts that would let me run CGIs, my Perl script powered the hit counters for most of my friends’ sites too.
5 I considered, but couldn’t be bothered, implementing an SVG CSS filter: to posterize my images down to 8-bit colour, for that real
“I’m on an old graphics card” feel! If anybody’s already implemented such a thing under a license that I can use, let me know and I’ll integrate it!
Okay, we’re gonna need a whole lot of caveats on the “this is 5,000” claim:
Engage pedantry mode
First, there’s a Ship of Theseus consideration. By “this blog”, I’m referring to what I feel is a continuation (with short
breaks) of my personal diary-style writing online from the original “Avatar Diary” on castle.onza.net in the 1990s via “Dan’s Pages” on avangel.com in the 2000s through the relaunch on scatmania.org in 2003 through migrating to danq.me in 2012. If you feel that a change of domain precludes continuation, you might
disagree with me. Although you’d be a fool to do so: clearly a blog can change its domain and still be the same blog, right? Back in 2018 I celebrated the 20th anniversary of my first blog post by revisiting how my blog had looked, felt, and changed over the decades, if
you’re looking for further reading.
These posts were from the 1990s (in case the design didn’t give that away), and despite a change in domain name, I’m counting them. They’re still accessible, via this domain,
today!1Similarly, one might ask if retroactively republishing something that originally went out via a different medium “counts”2.
In late 1999 I ran “Cool Thing of the Day (to do at the University of Wales, Aberystwyth)” as a way of staying connected to my friends back in
Preston as we all went our separate ways to study. Initially sent out by email, I later maintained a web page with a log of the entries I’d sent out, but the address wasn’t
publicly-circulated. I consider this to be a continuation of the Avatar Diary before it and the predecessor to Dan’s Pages on avangel.com after it, but a pedant might argue that because
the content wasn’t born as a blog post, perhaps it’s invalid.
Pedants might also bring up the issue of contemporaneity. In 2004 a server fault resulted in the loss of a significant number of
149 blog posts, of which only 85 have been fully-recovered. Some were resurrected from
backups as late as 2012, and some didn’t recover their lost images until later still – this one had some content recovered as late as 2017! If you consider the absence of a pre-2004 post until
2012 a sequence-breaker, that’s an issue. It’s theoretically possible, of course, that other old posts might be recovered and injected, and this post might before the 5,001st, 5,002nd,
or later post, in terms of chronological post-date. Who knows!
Then there’s the posts injected retroactively. I’ve written software that, since 2018, has ensured that
my geocaching logs get syndicated via my blog when I publish them to one of the other logging sites I use, and I retroactively imported all of my
previous logs. These never appeared on my blog when they were written: should they count? What about more egregious examples of necroposting, like this post dated long before I ever touched a keyboard? I’m counting them all.
I’m also counting other kinds of less-public content too. Did you know that I sometimes make posts that don’t appear on my front page,
and you have to subscribe e.g. by RSS to get them? They have web addresses – although search
engines are discouraged from indexing them – and people find them with or without subscribing. Maybe you should subscribe if you haven’t already?
Generating a chart...
If this message doesn't go away, the JavaScript that makes this magic work probably isn't doing its job right: please tell Dan so he can fix it.
Generating a chart...
If this message doesn't go away, the JavaScript that makes this magic work probably isn't doing its job right: please tell Dan so he can fix it.
I’ve only recently started actively keeping stats on my blogging activity, without which I probably wouldn’t even have
noticed that my “5K” milestone was coming up!
Let’s take a look at some of those previous milestone posts:
In post 1,000 I announced that I was ready for 2005’s NaNoWriMo. I had a big ol’ argument in the comments with
Statto about the value of the exercise. It’s possible that I ultimately wrote more words arguing with him than I did on my writing project that
month.
It takes a pretty special geocache for me to make a video about it (unlike my geohashing expeditions, for which videos aren’t uncommon). The only other
one I can think of was one of my own…
I absolutely count this as the 5,000th post on this blog.
Here’s to the next 5,000!
Footnotes
1 Don’t go look at them. Just don’t. I was a teenager.
Dave Winer kindly let me know about a proposed
standard for linking to OPML blogrolls. Given that I added a page
containing my blogroll last year, it was easy enough for me to add a tiny bit of code to the header to add support for automatic detection of my blogroll.
Now all we need is some tools that can do such detection!
(You’ll note I’ve added a title attribute: as I discovered the other day, some browsers including ELinks will show all
<link>s of unknown rel="..." at the top of the page and I wanted this one to make sense!)
theunderground.blog‘s content, with the exception of its homepage, is delivered entirely through an XML Atom feed. Atom feed entries do require <title>s, of course, so that’s not the strongest counterexample!
This blog is available over several media other than the Web. For example, you can read this blog post:
We’ve looked at plain text, which as a format clearly does not have to have a title. Let’s go one step further and implement it. What we’d need is:
A webserver configured to deliver plain text files by preference, e.g. by adding directives like index index.txt; (for Nginx).5
An index page listing posts by date and URL. Most browser won’t render these as “links” so users will have to copy-paste
or re-type them, so let’s keep them short,
Pages for each post at those URLs, presumably without any kind of “title” (just to prove a point), and
An RSS feed: usually I use RSS as shorthand for all feed
types, but this time I really do mean RSS and not e.g. Atom because RSS, strangely, doesn’t require that an <item> has a <title>!
Unlike other sites, I didn’t need to test textplain.blog in Lynx to
know it’d work well. But I did anyway.
In the end I decided it’d benefit from being automated as sort-of a basic flat-file CMS, so I wrote it in PHP. All requests are routed by the webserver to the program, which determines whether they’re a request for the homepage, the RSS feed, or a valid individual post, and responds accordingly.
It annoys me that feed
discovery doesn’t work nicely when using a Link: header, at least not in any reader I tried. But apart from that, it seems pretty solid, despite its limitations. Is this,
perhaps, an argument for my.well-known/feedsproposal?
Molly White writes, more-eloquently than I would’ve, almost-exactly my experience of LLMs and similar modern generative
AIs:
…
I, like many others who have experimented with or adopted these products, have found that these tools actually can be pretty useful for some tasks. Though AI
companies are prone to making overblown promises that the tools will shortly be able to replace your content writing team or generate feature-length films or develop a video game from
scratch, the reality is far more mundane: they are handy in the same way that it might occasionally be useful to delegate some tasks to an inexperienced and sometimes sloppy intern.
…
Very much this.
I’ve experimented with a handful of generative AIs, such as:
GPT-3.5 / ChatGPT, for proofreading, summarisation, experimental rephrasing when writing, and idea generation. I’ve found it to be moderately good at summarisation
and proofreading and pretty terrible at producing anything novel without sounding completely artificial and/or getting lost in a hallucination.
Bing for coalescing information. I like that it cites its sources. I dislike that it somehow still hallucinates. I might use it, I suppose, to help me
re-phase a search query where I can’t remember the word I’m looking for.
Stable Diffusion for image generation. I’ve found it most-useful in image-to-image mode, for making low-effort concept art in bulk. For example, when running online
roleplaying games for friends I’ve fed it an image of, say, a skeleton warrior and asked it to make me a few dozen more in a similar style, so as to provide a diverse selection of
distinct tokens1.
Its completely-original2 work lands squarely in
the uncanny valley, though.
Github Copilot for code assistance. I’ve not tried its “chat”-powered functionality but I quite enjoy its “autocomplete” tool. When I’m coding and I forget the syntax
of the command I’m typing, or need to stop and think for a moment about “what comes next”, it’s often there with the answer. I’ve even made us of the “write the comment describing
what the code will do, let Copilot suggest the code for you” paradigm (though I’ve been pretty disappointed with the opposite approach: it doesn’t write great comments!). I find
Copilot to be a lot like having an enthusiastic, eager-to-please, very well-read but somewhat naive junior programmer sitting beside me. If I ask them for some pairing assistance,
they’re great, but I can’t trust them to do anything that I couldn’t do for myself!
Surely others besides that I’ve since forgotten.
Most-recently, I’ve played with music-making AI Suno and… it’s not
great.. but like all these others it’s really interesting to experiment with and think about. Here: let me just ask it to write some “vocal trance europop about a woman called
Molly; Molly has a robot friend who is pretty good at doing many tasks, but the one thing she’ll never trust the robot to do is write in her blog” –
AI-generated content:
[Verse]
Molly’s got a robot that she keeps by her side
It’s pretty handy
It can do many things right
But there’s one task she won’t let it touch
It’s true
The robot can’t write in her blog
No
That won’t do
[Verse 2]
This robot can clean the house
Sweep it up real nice
It can even cook a meal
Add some spice
But when it comes to sharing her thoughts on the screen
Molly won’t trust the robot
That’s her routine
[Chorus]
Molly’s robot friend
By her side all day and night
There’s one thing it can’t do
Can’t write her blog right
She’ll keep typing away
Sharing her heart and soul
That’s something the robot can’t do
It has no control
So yes, like Molly:
I’m absolutely a believer than these kinds of AIs have some value,
I’ve been reluctant and slow to say so because they seem to be such a polarising issue that it’s hard to say that you belong to neither “camp”,
I’m not entirely convinced that for the value they provide they’ve yet proven to be worth their cost, and I’m not certain that for general-purpose generation they will be any time
soon, and
I’ve never used AI to write content for my blog, and I can’t see that ever changing.
It’s still an interesting field to follow-along with. Stuff like Sora from OpenAI and VASA-1 from Microsoft are just scary (the latter seems to have little purpose other than for
misinformation-generation3!),
but the genie’s out of the bottle now.
Footnotes
1 Visually-distinct tokens adds depth to the world and helps players communicate with one
another: “You distract the skinny cultist, and I’ll try to creep up on the ugly one!”
2 I’m going to gloss right over the question of whether or not these tools are capable of
creating anything truly original. You know what I mean.
In August, I celebrated my blog – with its homepage weighing-in at a total of just 481kb – being admitted to Kev Quirk‘s 512kb club. 512kb club celebrates websites (often personal sites) whose homepage are neither “ultra minimal”
or “link pages” but have a total size, including all assets, of under half a megabyte. It’s about making a commitment to a leaner, more-efficient Web.
My relatively-heavyweight homepage only just slipped in under the line. But, feeling inspired perhaps by some performance enhancements I’ve been planning this week at work, I
decided to try to shave a little more off:
Now, at ~234kb, danq.me just beats the excellent gomakethings.com (it’s all those heavyweight fonts, Chris!).
Here’s what I changed:
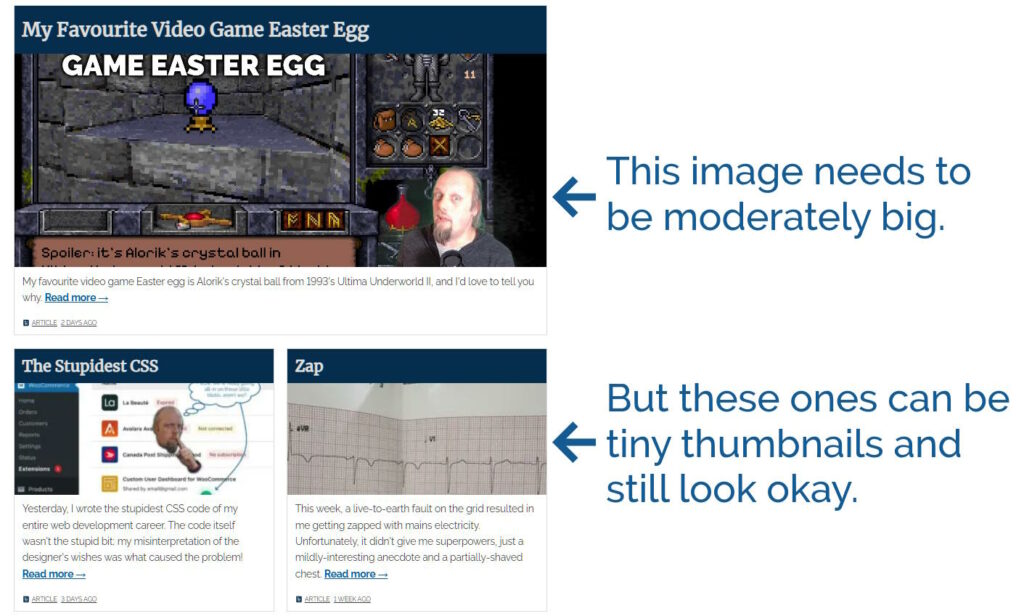
The “recent article” tiles are dynamically sized based on their number, type, and the visitor’s screen resolution. But apart from the top one they’re almost never very large. Using
thumbnail images for the non-first tile shaved off almost 160kb.
You can see the difference, but it’s still acceptable to look at, I think.
Not space-saving, but while I was in there I ensured that the first tile’s image – which almost-certainly comprises part of the Largest
Contentful Paint – is never delivered with loading="lazy".
I was providing a shortcut icon in .ico format (<link rel="shortcut icon" href="https://bcdn.danq.me/_q23t/icons/favicon-16-32-48-64-128.ico" />),
which is pretty redundant nowadays because all modern browsers (and even IE11)
support .png icons. I was already providing.png and .svg versions, but it turns out that some browsers favour the one with the
(harmful?) rel="shortcut icon" over rel="icon" if both are present, and .ico
files are – being based on Windows Bitmaps – horrendously inefficient.
By getting under the 250kb threshold, I’ve jumped up a league from Blue Team to Orange Team, so that’s nice too. I can’t see a meaningful
path from where I’m at to Green Team (under 100kb) though, so this level might have to suffice.
After a first attempt at mobile blogging, I found a process that works better for my work flow.
Throughout the day, I have ideas and need to write them down. This could be a coding process, a thought to remember, the start of a blog post, and more. I love a good notes app. I’ve
gone through quite a few and use a few for different things. Lately it’s been Simplenote.
…
As I took part in Bloganuary and began what’ll hopefully become a fifth
consecutive year of 100 Days To Offload, I started to hate my approach to mobile blogging and seek something better, too. My blog’s on WordPress, but it’s so highly-customised that
I can’t meaningfully use any of the standard apps, and I find the mobile interface too slow and clunky to use over anything less than a great Internet connection… which – living out in
the sticks – I don’t routinely have when I’m out and about. So my blogging almost-exclusively takes place at my desktop or laptop.
But your experience of using a notetaking app is reasonably inspiring. I’m almost never away from a “real” computer for more than a day, so there’s no reason I can’t simply write into
such an app, let it sync, and copy-paste into a blog post (and make any tweaks) when I’m sitting at a proper keyboard! I’m using Obsidian for
notetaking, and it Syncthing‘s to my other computers, so I should absolutely be leveraging that. I already have an Obsidian folder full of
“blog post ideas”… why shouldn’t I just write blog posts there.