Web standards sometimes disappear
Sometimes a web standard disappears quickly at the whim of some company, perhaps to a great deal of complaint (and at least one joke).
But sometimes, they disappear slowly, like this kind of web address:
http://username:password@example.com/somewhere
If you’ve not seen a URL like that before, that’s fine, because the answer to the question “Can I still use HTTP Basic Auth in URLs?” is, I’m afraid: no, you probably can’t.
But by way of a history lesson, let’s go back and look at what these URLs were, why they died out, and how web browsers handle them today. Thanks to Ruth who asked the original question that inspired this post.
Basic authentication
The early Web wasn’t built for authentication. A resource on the Web was theoretically accessible to all of humankind: if you didn’t want it in the public eye, you didn’t put it on the Web! A reliable method wouldn’t become available until the concept of state was provided by Netscape’s invention of HTTP cookies in 1994, and even that wouldn’t see widespread for several years, not least because implementing a CGI (or similar) program to perform authentication was a complex and computationally-expensive option for all but the biggest websites.
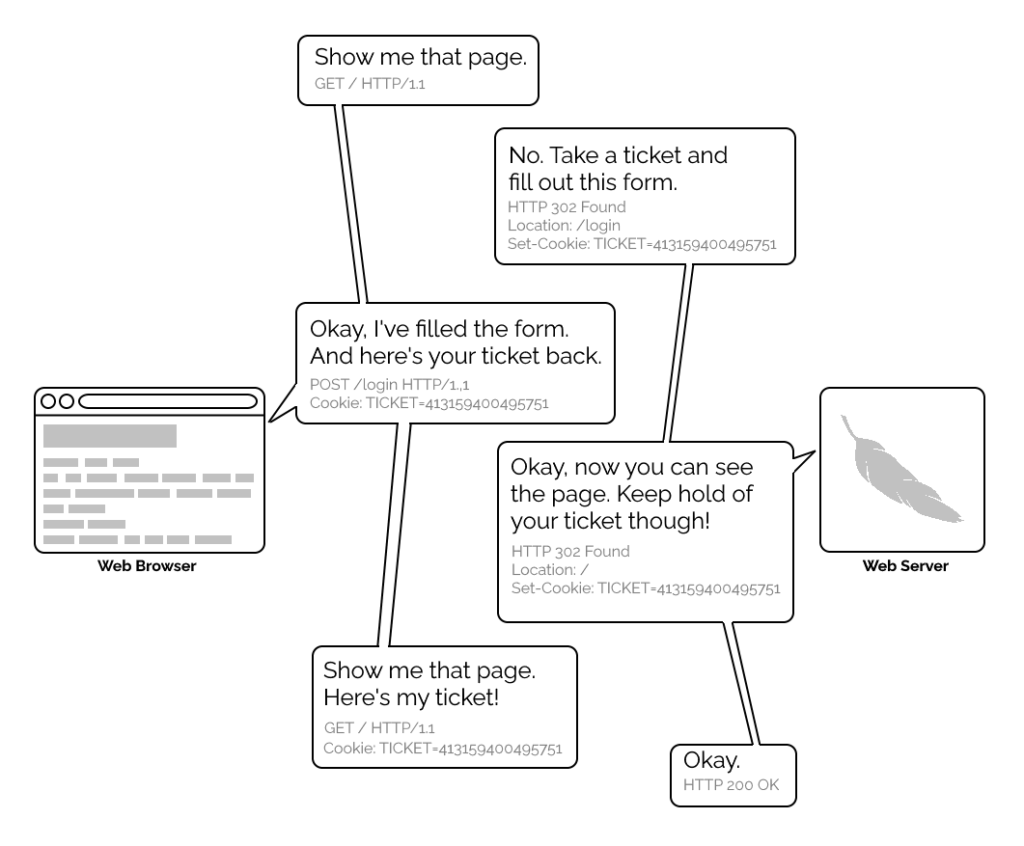
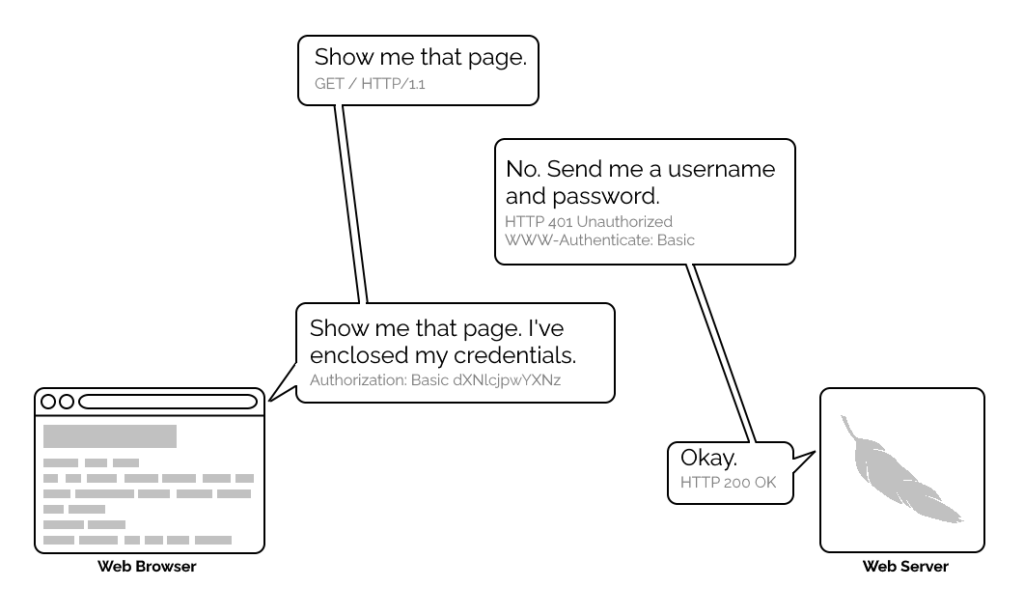
1996’s HTTP/1.0 specification tried to simplify things, though, with the introduction of the WWW-Authenticate header. The idea was that when a browser tried to access something that required
authentication, the server would send a 401 Unauthorized response along with a WWW-Authenticate header explaining how the browser could authenticate
itself. Then, the browser would send a fresh request, this time with an Authorization: header attached providing the required credentials. Initially, only “basic
authentication” was available, which basically involved sending a username and password in-the-clear unless SSL (HTTPS) was in use, but later, digest authentication and a host of others would appear.
Webserver software quickly added support for this new feature and as a result web authors who lacked the technical know-how (or permission from the server administrator) to implement
more-sophisticated authentication systems could quickly implement HTTP Basic Authentication, often simply by adding a .htaccess file to the relevant directory.
.htaccess files would later go on to serve many other purposes, but their original and perhaps best-known purpose – and the one that gives them their name – was access
control.
Credentials in the URL
A separate specification, not specific to the Web (but one of Tim Berners-Lee’s most important contributions to it), described the general structure of URLs as follows:
<scheme>://<username>:<password>@<host>:<port>/<url-path>#<fragment>
At the time that specification was written, the Web didn’t have a mechanism for passing usernames and passwords: this general case was intended only to apply to protocols that did have these credentials. An example is given in the specification, and clarified with “An optional user name. Some schemes (e.g., ftp) allow the specification of a user name.”
But once web browsers had WWW-Authenticate, virtually all of them added support for including the username and password in the web address too. This allowed for
e.g. hyperlinks with credentials embedded in them, which made for very convenient bookmarks, or partial credentials (e.g. just the username) to be included in a link, with the
user being prompted for the password on arrival at the destination. So far, so good.

This is why we can’t have nice things
The technique fell out of favour as soon as it started being used for nefarious purposes. It didn’t take long for scammers to realise that they could create links like this:
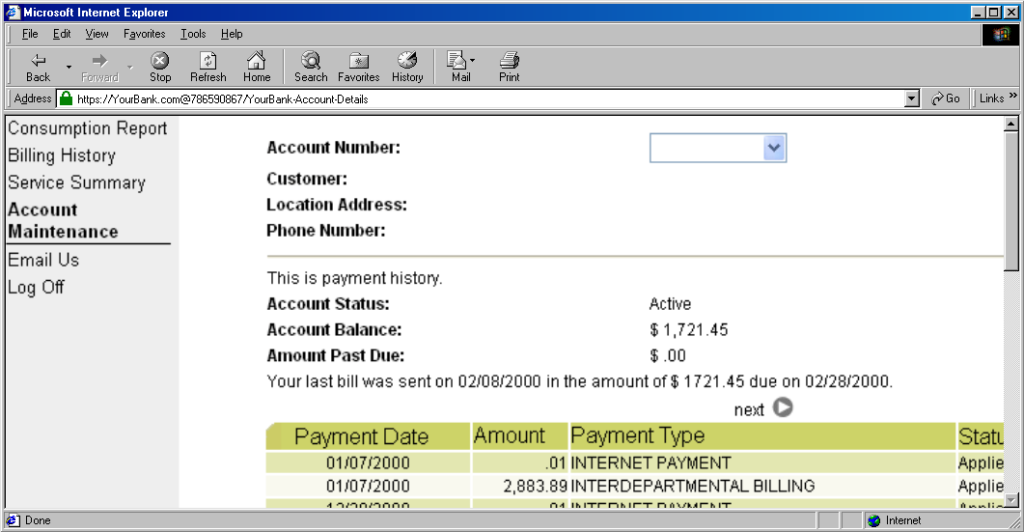
https://YourBank.com@HackersSite.com/
Everything we were teaching users about checking for “https://” followed by the domain name of their bank… was undermined by this user interface choice. The poor victim would actually be connecting to e.g. HackersSite.com, but a quick glance at their address bar would leave them convinced that they were talking to YourBank.com!
Theoretically: widespread adoption of EV certificates coupled with sensible user interface choices (that were never made) could have solved this problem, but a far simpler solution was just to not show usernames in the address bar. Web developers were by now far more excited about forms and cookies for authentication anyway, so browsers started curtailing the “credentials in addresses” feature.
(There are other reasons this particular implementation of HTTP Basic Authentication was less-than-ideal, but this reason is the big one that explains why things had to change.)
One by one, browsers made the change. But here’s the interesting bit: the browsers didn’t always make the change in the same way.
How different browsers handle basic authentication in URLs
Let’s examine some popular browsers. To run these tests I threw together a tiny web application that outputs
the Authorization: header passed to it, if present, and can optionally send a 401 Unauthorized response along with a WWW-Authenticate: Basic realm="Test Site" header in order to trigger basic authentication. Why both? So that I can test not only how browsers handle URLs containing credentials when an authentication request is received, but how they handle them when one is not. This is relevant because
some addresses – often API endpoints – have optional HTTP authentication, and it’s sometimes important for a user agent (albeit typically a library or command-line one) to pass credentials without
first being prompted.
In each case, I tried each of the following tests in a fresh browser instance:
- Go to
http://<username>:<password>@<domain>/optional(authentication is optional). - Go to
http://<username>:<password>@<domain>/mandatory(authentication is mandatory). - Experiment 1, then f0llow relative hyperlinks (which should correctly retain the credentials) to
/mandatory. - Experiment 2, then follow relative hyperlinks to the
/optional.
I’m only testing over the http scheme, because I’ve no reason to believe that any of the browsers under test treat the https scheme differently.
Chromium desktop family
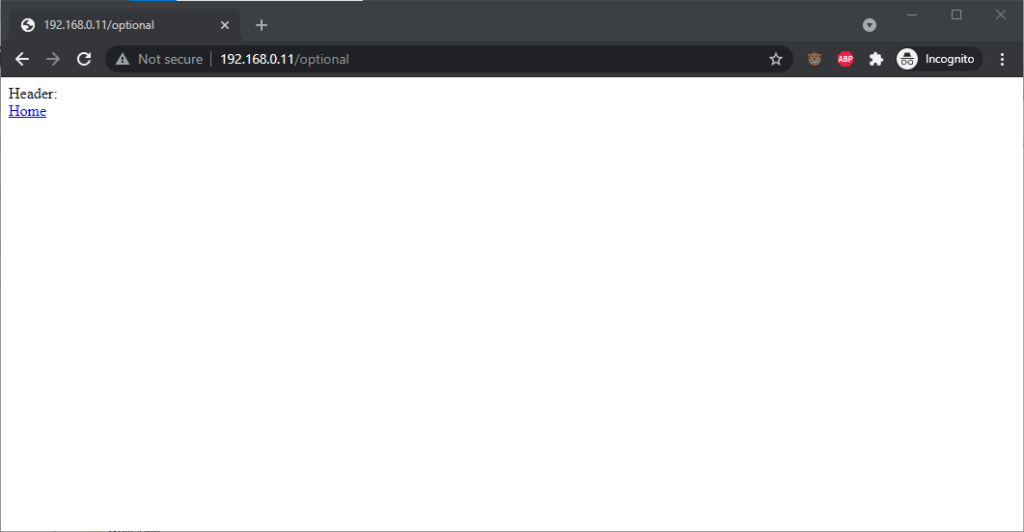 Chrome 93 and Edge 93 both immediately suppressed the username and password from the address bar, along with the “http://” as we’ve come to expect of them. Like the “http://”, though,
the plaintext username and password are still there. You can retrieve them by copy-pasting the entire address.
Chrome 93 and Edge 93 both immediately suppressed the username and password from the address bar, along with the “http://” as we’ve come to expect of them. Like the “http://”, though,
the plaintext username and password are still there. You can retrieve them by copy-pasting the entire address.
Opera 78 similarly suppressed the username, password, and scheme, but didn’t retain the username and password in a way that could be copy-pasted out.
Authentication was passed only when landing on a “mandatory” page; never when landing on an “optional” page. Refreshing the page or re-entering the address with its credentials did not change this.
Navigating from the “optional” page to the “mandatory” page using only relative links retained the username and password and submitted it to the server when it became mandatory, even Opera which didn’t initially appear to retain the credentials at all.
Navigating from the “mandatory” to the “optional” page using only relative links, or even entering the “optional” page address with credentials after visiting the “mandatory” page, does not result in authentication being passed to the “optional” page. However, it’s interesting to note that once authentication has occurred on a mandatory page, pressing enter at the end of the address bar on the optional page, with credentials in the address bar (whether visible or hidden from the user) does result in the credentials being passed to the optional page! They continue to be passed on each subsequent load of the “optional” page until the browsing session is ended.
Firefox desktop
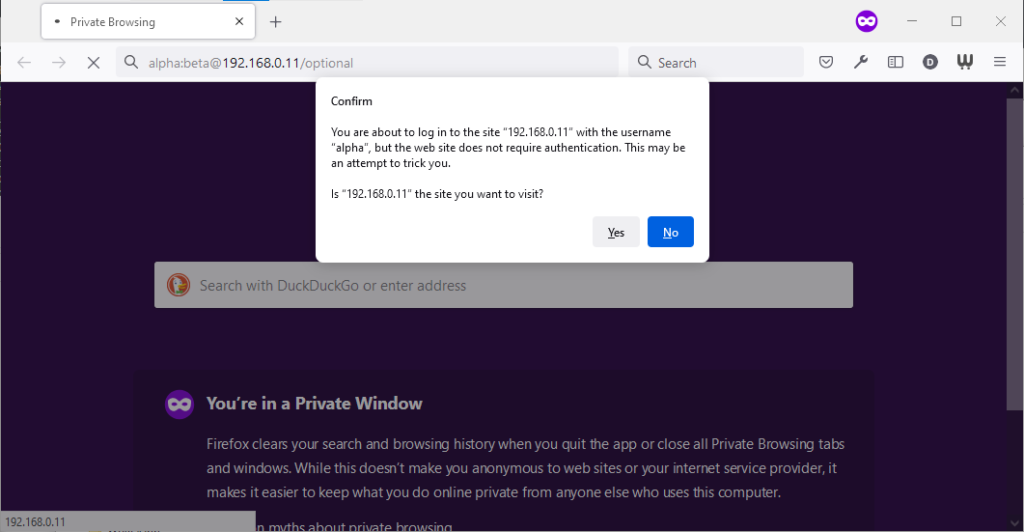 Firefox 91 does a clever thing very much in-line with
its image as a browser that puts decision-making authority into the hands of its user. When going to the “optional” page first it presents a dialog, warning the user that they’re going
to a site that does not specifically request a username, but they’re providing one anyway. If the user says that no, navigation ceases (the GET request for the page takes place the same
either way; this happens before the dialog appears). Strangely: regardless of whether the user selects yes or no, the credentials are not passed on the “optional” page. The credentials
(although not the “http://”) appear in the address bar while the user makes their decision.
Firefox 91 does a clever thing very much in-line with
its image as a browser that puts decision-making authority into the hands of its user. When going to the “optional” page first it presents a dialog, warning the user that they’re going
to a site that does not specifically request a username, but they’re providing one anyway. If the user says that no, navigation ceases (the GET request for the page takes place the same
either way; this happens before the dialog appears). Strangely: regardless of whether the user selects yes or no, the credentials are not passed on the “optional” page. The credentials
(although not the “http://”) appear in the address bar while the user makes their decision.
Similar to Opera, the credentials do not appear in the address bar thereafter, but they’re clearly still being stored: if the refresh button is pressed the dialog appears again. It does not appear if the user selects the address bar and presses enter.
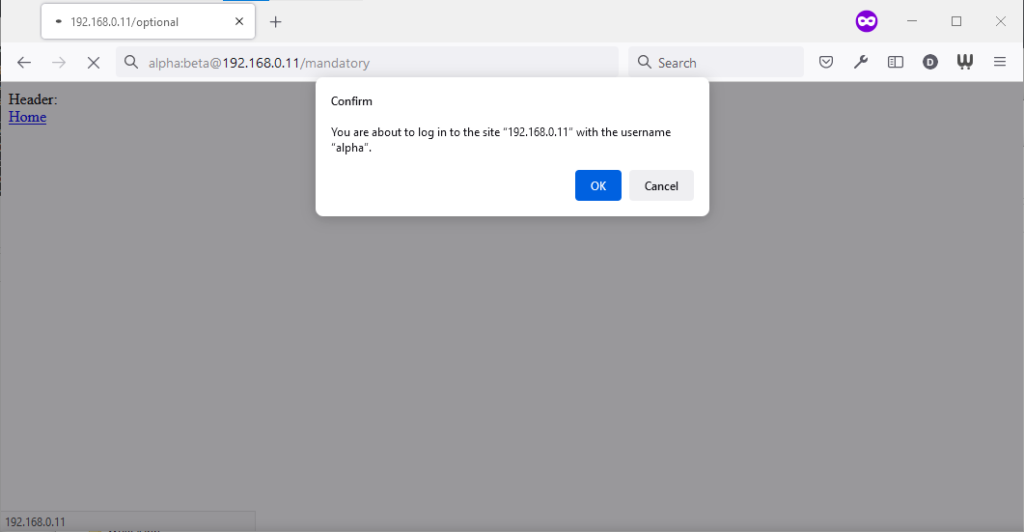 Similarly, going to the “mandatory” page in Firefox results in an informative dialog warning the user
that credentials are being passed. I like this approach: not only does it help protect the user from the use of authentication as a tracking technique (an old technique that I’ve not
seen used in well over a decade, mind), it also helps the user be sure that they’re logging in using the account they mean to, when following a link for that purpose. Again, clicking
cancel stops navigation, although the initial request (with no credentials) and the 401 response has already occurred.
Similarly, going to the “mandatory” page in Firefox results in an informative dialog warning the user
that credentials are being passed. I like this approach: not only does it help protect the user from the use of authentication as a tracking technique (an old technique that I’ve not
seen used in well over a decade, mind), it also helps the user be sure that they’re logging in using the account they mean to, when following a link for that purpose. Again, clicking
cancel stops navigation, although the initial request (with no credentials) and the 401 response has already occurred.
Visiting any page within the scope of the realm of the authentication after visiting the “mandatory” page results in credentials being sent, whether or not they’re included in the address. This is probably the most-true implementation to the expectations of the standard that I’ve found in a modern graphical browser.
Safari desktop
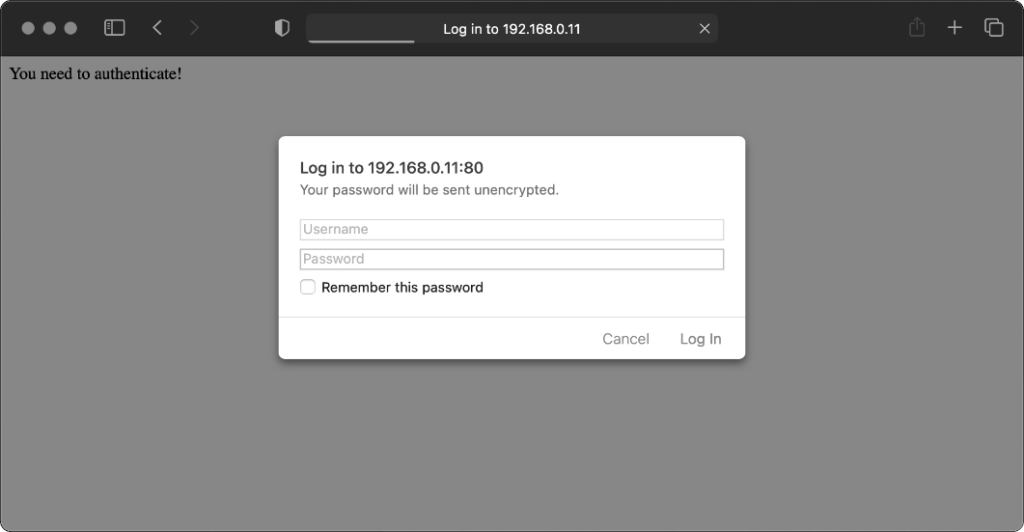 Safari 14 never displays or uses credentials provided via the web address, whether or not
authentication is mandatory. Mandatory authentication is always met by a pop-up dialog, even if credentials were provided in the address bar. Boo!
Safari 14 never displays or uses credentials provided via the web address, whether or not
authentication is mandatory. Mandatory authentication is always met by a pop-up dialog, even if credentials were provided in the address bar. Boo!
Once passed, credentials are later provided automatically to other addresses within the same realm (i.e. optional pages).
Older browsers
Let’s try some older browsers.
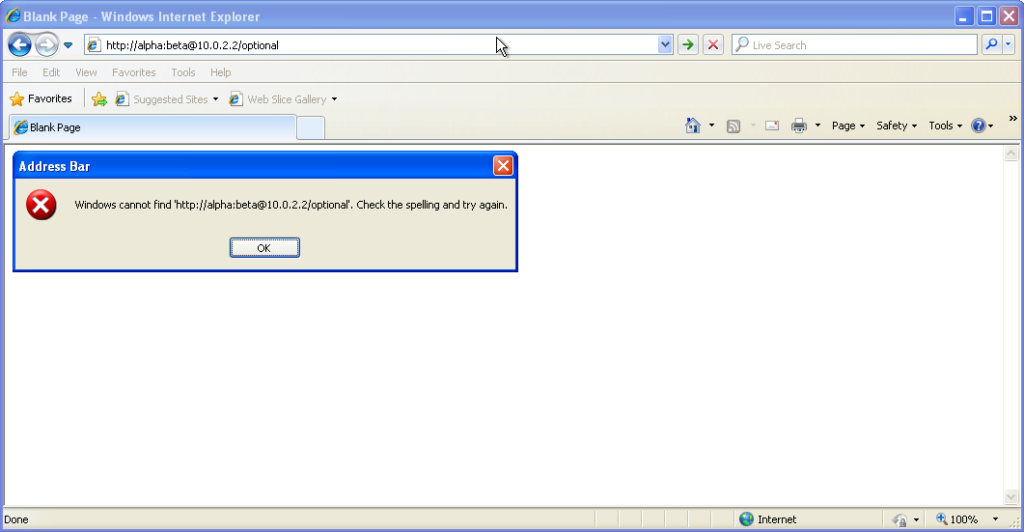 From version 7 onwards – right up to the final version 11 – Internet Explorer fails to even recognise
addresses with authentication credentials in as legitimate web addresses, regardless of whether or not authentication is requested by the server. It’s easy to assume that this is yet
another missing feature in the browser we all love to hate, but it’s interesting to note that credentials-in-addresses is permitted for
From version 7 onwards – right up to the final version 11 – Internet Explorer fails to even recognise
addresses with authentication credentials in as legitimate web addresses, regardless of whether or not authentication is requested by the server. It’s easy to assume that this is yet
another missing feature in the browser we all love to hate, but it’s interesting to note that credentials-in-addresses is permitted for ftp:// URLs…
 …and if you go back a little way, Internet Explorer 6 and below supported credentials in the address bar pretty
much as you’d expect based on the standard. The error message seen in IE7 and above is a deliberate design
decision, albeit a somewhat knee-jerk reaction to the security issues posed by the feature (compare to the more-careful approach of other browsers).
…and if you go back a little way, Internet Explorer 6 and below supported credentials in the address bar pretty
much as you’d expect based on the standard. The error message seen in IE7 and above is a deliberate design
decision, albeit a somewhat knee-jerk reaction to the security issues posed by the feature (compare to the more-careful approach of other browsers).
These older versions of IE even (correctly) retain the credentials through relative hyperlinks, allowing them to be passed when they become mandatory. They’re not passed on optional pages unless a mandatory page within the same realm has already been encountered.
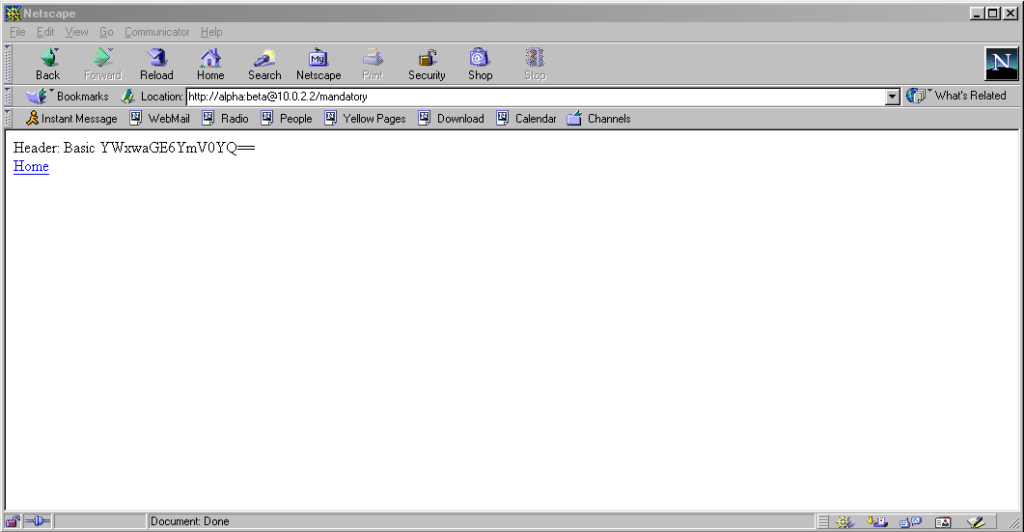 Pre-Mozilla Netscape behaved the same way. Truly this was the de facto standard for a long period on the Web, and the varied approaches we see today are the
anomaly. That’s a strange observation to make, considering how much the Web of the 1990s was dominated by incompatible implementations of different Web features (I’ve written about the
Pre-Mozilla Netscape behaved the same way. Truly this was the de facto standard for a long period on the Web, and the varied approaches we see today are the
anomaly. That’s a strange observation to make, considering how much the Web of the 1990s was dominated by incompatible implementations of different Web features (I’ve written about the <blink> and <marquee> tags before, which was perhaps the most-visible division between
the Microsoft and Netscape camps, but there were many, many more).
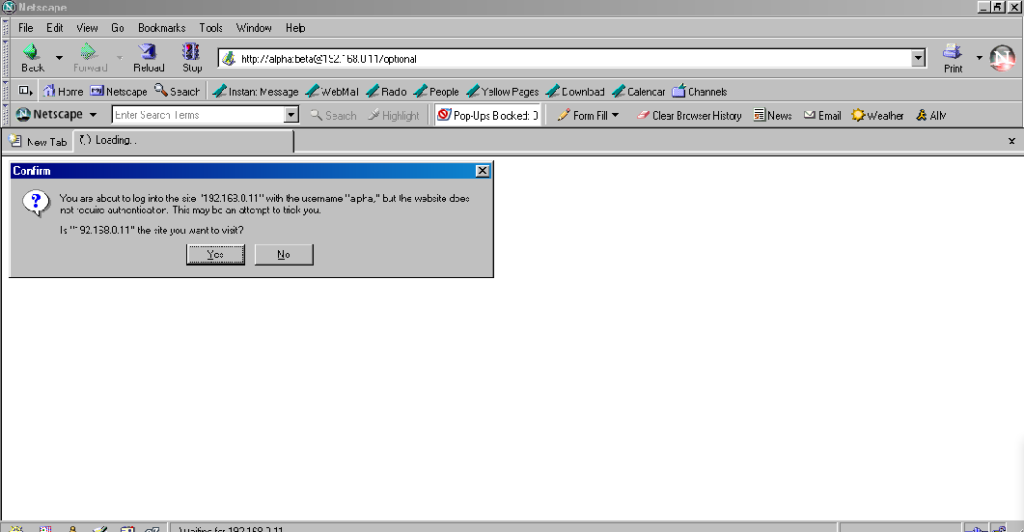 Interestingly: by Netscape 7.2 the browser’s behaviour had evolved
to be the same as modern Firefox’s, except that it still displayed the credentials in the address bar for all to see.
Interestingly: by Netscape 7.2 the browser’s behaviour had evolved
to be the same as modern Firefox’s, except that it still displayed the credentials in the address bar for all to see.
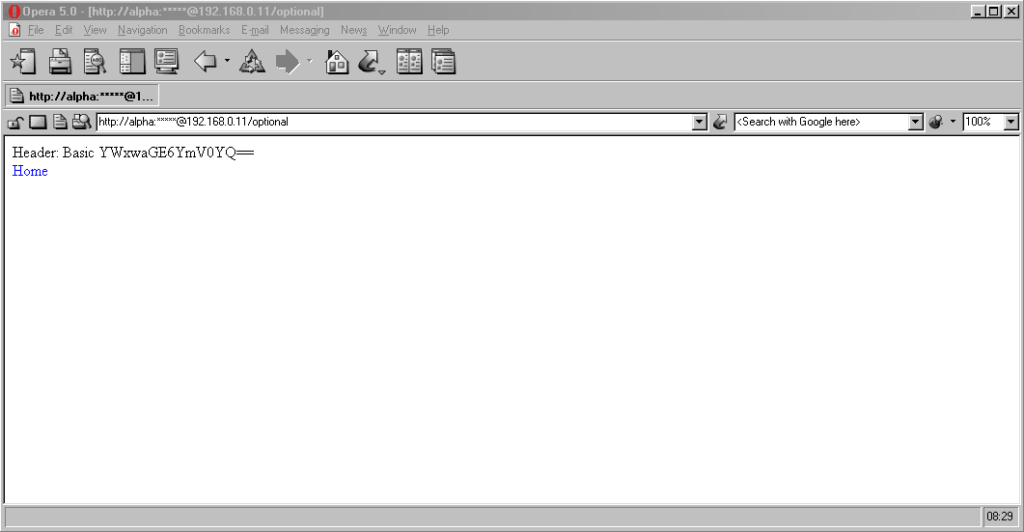 Now here’s a real gem: pre-Chromium Opera. It would send credentials to “mandatory” pages and remember them for the
duration of the browsing session, which is great. But it would also send credentials when passed in a web address to “optional” pages. However, it wouldn’t remember
them on optional pages unless they remained in the address bar: this feels to me like an optimum balance of features for power users. Plus, it’s one of very few browsers that
permitted you to change credentials mid-session: just by changing them in the address bar! Most other browsers, even to this day, ignore changes to HTTP Authentication credentials, which was sometimes be a source of frustration back in the day.
Now here’s a real gem: pre-Chromium Opera. It would send credentials to “mandatory” pages and remember them for the
duration of the browsing session, which is great. But it would also send credentials when passed in a web address to “optional” pages. However, it wouldn’t remember
them on optional pages unless they remained in the address bar: this feels to me like an optimum balance of features for power users. Plus, it’s one of very few browsers that
permitted you to change credentials mid-session: just by changing them in the address bar! Most other browsers, even to this day, ignore changes to HTTP Authentication credentials, which was sometimes be a source of frustration back in the day.
Finally, classic Opera was the only browser I’ve seen to mask the password in the address bar, turning it into a series of asterisks. This ensures the user knows that a password was used, but does not leak any sensitive information to shoulder-surfers (the length of the “masked” password was always the same length, too, so it didn’t even leak the length of the password). Altogether a spectacular design and a great example of why classic Opera was way ahead of its time.
The Command-Line
Most people using web addresses with credentials embedded within them nowadays are probably working with code, APIs, or the command line, so it’s unsurprising to see that this is where the most “traditional” standards-compliance is found.
I was unsurprised to discover that giving curl a username and password in the URL meant that username and password was sent to the server (using Basic authentication, of course, if no authentication was requested):
$ curl http://alpha:beta@localhost/optional
Header: Basic YWxwaGE6YmV0YQ==
$ curl http://alpha:beta@localhost/mandatory
Header: Basic YWxwaGE6YmV0YQ==
However, wget did catch me out. Hitting the same addresses with wget didn’t result in the credentials being sent
except where it was mandatory (i.e. where a HTTP 401 response and a WWW-Authenticate: header was received on the initial attempt). To force wget to
send credentials when they haven’t been asked-for requires the use of the --http-user and --http-password switches:
$ wget http://alpha:beta@localhost/optional -qO-
Header:
$ wget http://alpha:beta@localhost/mandatory -qO-
Header: Basic YWxwaGE6YmV0YQ==
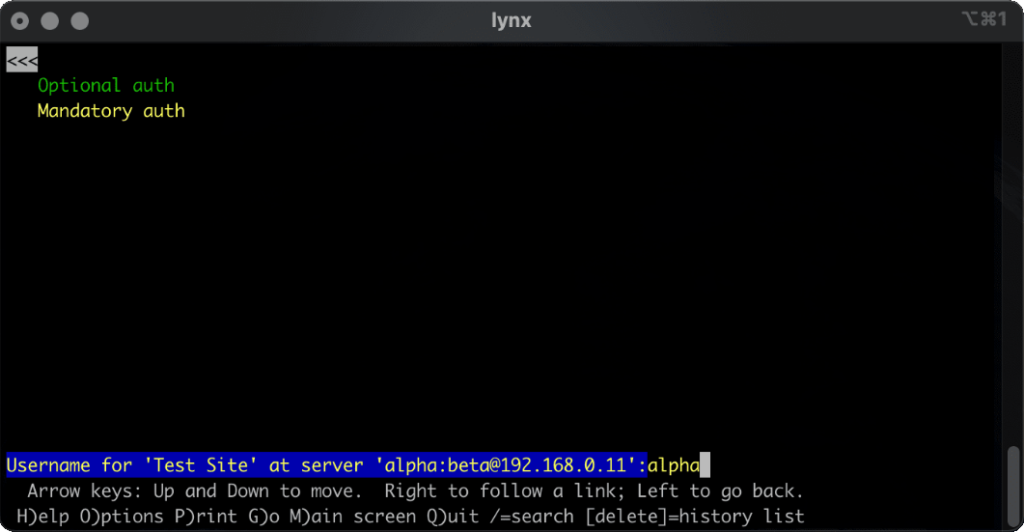
lynx does a cute and clever thing. Like most modern browsers, it does not submit credentials unless specifically requested, but if they’re in the address bar when they become mandatory (e.g. because of following relative hyperlinks or hyperlinks containing credentials) it prompts for the username and password, but pre-fills the form with the details from the URL. Nice.
What’s the status of HTTP (Basic) Authentication?
HTTP Basic Authentication and its close cousin Digest Authentication (which overcomes some of the security limitations of running Basic Authentication over an
unencrypted connection) is very much alive, but its use in hyperlinks can’t be relied upon: some browsers (e.g. IE, Safari)
completely munge such links while others don’t behave as you might expect. Other mechanisms like Bearer see widespread use in APIs, but nowhere else.
The WWW-Authenticate: and Authorization: headers are, in some ways, an example of the best possible way to implement authentication on the Web: as an
underlying standard independent of support for forms (and, increasingly, Javascript), cookies, and complex multi-part conversations. It’s easy to imagine an alternative
timeline where these standards continued to be collaboratively developed and maintained and their shortfalls – e.g. not being able to easily log out when using most graphical browsers!
– were overcome. A timeline in which one might write a login form like this, knowing that your e.g. “authenticate” attributes would instruct the browser to send credentials using an
Authorization: header:
<form method="get" action="/" authenticate="Basic">
<label for="username">Username:</label> <input type="text" id="username" authenticate="username">
<label for="password">Password:</label> <input type="text" id="password" authenticate="password">
<input type="submit" value="Log In">
</form>
In such a world, more-complex authentication strategies (e.g. multi-factor authentication) could involve encoding forms as JSON. And single-sign-on systems would simply involve the browser collecting a token from the authentication provider and passing it on to the
third-party service, directly through browser headers, with no need for backwards-and-forwards redirects with stacks of information in GET parameters as is the case today.
Client-side certificates – long a powerful but neglected authentication mechanism in their own right – could act as first class citizens directly alongside such a system, providing
transparent second-factor authentication wherever it was required. You wouldn’t have to accept a tracking cookie from a site in order to log in (or stay logged in), and if your
browser-integrated password safe supported it you could log on and off from any site simply by toggling that account’s “switch”, without even visiting the site: all you’d be changing is
whether or not your credentials would be sent when the time came.
The Web has long been on a constant push for the next new shiny thing, and that’s sometimes meant that established standards have been neglected prematurely or have failed to evolve for
longer than we’d have liked. Consider how long it took us to get the <video> and <audio> elements because the “new shiny” Flash came to dominate,
how the Web Payments API is only just beginning to mature despite over 25 years of ecommerce on the Web, or how we still can’t
use Link: headers for all the things we can use <link> elements for despite them being semantically-equivalent!
The new model for Web features seems to be that new features first come from a popular JavaScript implementation, and then eventually it evolves into a native browser feature: for example HTML form validations, which for the longest time could only be done client-side using scripting languages. I’d love to see somebody re-think HTTP Authentication in this way, but sadly we’ll never get a 100% solution in JavaScript alone: (distributed SSO is almost certainly off the table, for example, owing to cross-domain limitations).
Or maybe it’s just a problem that’s waiting for somebody cleverer than I to come and solve it. Want to give it a go?
Thanks for sharing this, It is really helpful.
Very nice! informative post you have posted here.