The video below is presented in portrait orientation, because your screen is taller than it is wide.
The video below is presented in landscape orientation, because your screen is wider than it is tall.
The video below is presented in square orientation (the Secret Bonus Square Video!), because your screen has approximately the same width as as its height. Cool!
This is possible (with a single <video> element, and without any Javascript!) thanks to some cool HTML features you might not be aware of, which I’ll briefly explain
in the video. Or scroll down for the full details.
<videocontrols><sourcesrc="squareish.mp4"media="(min-aspect-ratio: 0.95) and (max-aspect-ratio: 1.05)"/><sourcesrc="portrait.mp4"media="(orientation: portrait)"/><sourcesrc="landscape.mp4"/></video>
This code creates a video with three sources: squareish.mp4 which is shown to people on “squareish” viewports, failing that portrait.mp4 which is shown to
people whose viewports are taller than wide, and failing that landscape.mp4 which is shown to anybody else.
That’s broadly-speaking how the video above is rendered. No JavaScript needed.
Browsers only handle media queries on videos when they initially load, so you can’t just tip your phone over or resize the window: you’ll need to reload the page, too. But it works!
Give it a go: take a look at the video in both portrait and landscape modes and let me know what you think1.
Adding adaptive bitrate streaming with HLS
Here’s another cool technology that you might not have realised you could “just use”: adaptive bitrate streaming with HLS!
You’ve used adaptive bitrate streaming before, though you might not have noticed it. It’s what YouTube, Netflix, etc. are doing when your network connection degrades and you quickly get
dropped-down, mid-video, to a lower-resolution version2.
Turns out you can do it on your own static hosting, no problem at all. I used this guide (which has a great
description of the parameters used) to help me:
This command splits the H.264 video landscape.mp4 into three different resolutions: the original “v1” (1920×1080, in my case, with 96kbit audio), “v2” (1280×720, with
96kbit audio), and “v3” (640×360, with 48kbit audio), each with a resolution-appropriate maximum bitrate, and forced keyframes every 48th frame. Then it breaks each of those into HLS
segments (.ts files) and references them from a .m3u8 playlist.
The output from this includes:
Master playlist landscape.m3u8, which references the other playlists with reference to their resolution and bandwidth, so that browsers can make smart choices,
Playlists landscape_0.m3u8 (“v1”), landscape_1.m3u8 (“v2”), etc., each of which references the “parts” of that video,
Directories landscape_0/, landscape_1/ etc., each of which contain
data00.ts, data01.ts, etc.: the actual “chunks” that contain the video segments, which can be downloaded independently by the browser as-needed
Bringing it all together
We can bring all of that together, then, to produce a variable-aspect, adaptive bitrate, HLS-streamed video player… in pure HTML and suitable for static hosting:
<videocontrols><sourcesrc="squareish.m3u8"type="application/x-mpegURL"media="(min-aspect-ratio: 0.95) and (max-aspect-ratio: 1.05)"/><sourcesrc="portrait.m3u8"type="application/x-mpegURL"media="(orientation: portrait)"/><sourcesrc="landscape.m3u8"type="application/x-mpegURL"/></video>
You could, I suppose, add alternate types, poster images, and all kinds of other fancy stuff, but this’ll do for now.
One solution is to also provide the standard .mp4 files as an alternate <source>, and that’s fine I guess, but you lose the benefit of HLS (and
you have to store yet more files). But there’s a workaround:
Polyfill full functionality for all browsers
If you’re willing to use a JavaScript polyfill, you can make the code above work on virtually any device. I gave this a go, here, by:
Adding some JavaScript code that detects affected `<video>` elements and applying the fix if necessary:
// Find all <video>s which have HLS sources:for( hlsVideo of document.querySelectorAll('video:has(source[type="application/x-mpegurl"]), video:has(source[type="vnd.apple.mpegurl"])') ) {
// If the browser has native support, do nothing:if( hlsVideo.canPlayType('application/x-mpegurl') || hlsVideo.canPlayType('application/vnd.apple.mpegurl') ) continue;
// If hls.js can't help fix that, do nothing:if ( ! Hls.isSupported() ) continue;
// Find the best source based on which is the first one to match any applicable CSS media queriesconst bestSource =Array.from(hlsVideo.querySelectorAll('source')).find(source=>window.matchMedia(source.media).matches)
// Use hls.js to attach the best source:const hls =new Hls();
hls.loadSource(bestSource.src);
hls.attachMedia(hlsVideo);
}
It makes me feel a little dirty to make a <video>depend on JavaScript, but if that’s the route you want to go down while we wait for HLS support to become
more widespread (rather than adding different-typed sources) then that’s fine, I guess.
This was a fun dive into some technologies I’ve not had the chance to try before. A fringe benefit of being a generalist full-stack developer is that when you’re “between jobs”
you get to play with all the cool things when you’re brushing up your skills before your next big challenge!
(Incidentally: if you think you might be looking to employ somebody like me, my CV is over there!)
Footnotes
1 There definitely isn’t a super-secret “square” video on this page, though. No
siree. (Shh.)
2 You can tell when you get dropped to a lower-resolution version of a video because
suddenly everybody looks like they’re a refugee from Legoland.
The W3C‘s WebDX Community Group this week announced that they’ve reached a milestone with their web-features project. The project is an effort to catalogue browser support for Web features, to establish an
understanding of the baseline feature set that developers can rely on.
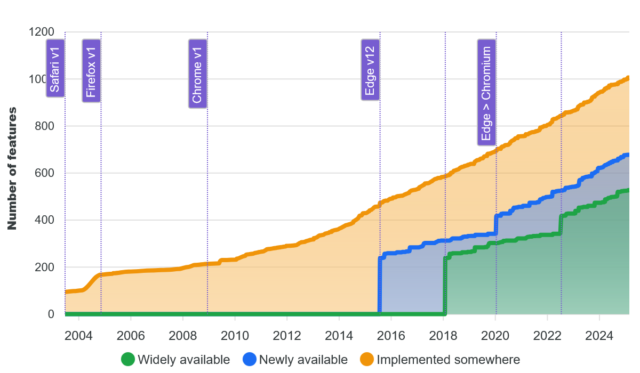
That’s great, and I’m in favour of the initiative. But I wonder about graphs like this one:
The graph shows the increase in time of the number of features available on the Web, broken down by how widespread they are implemented across the browser corpus.
The shape of that graph sort-of implies that… more features is better. And I’m not entirely convinced that’s true.
Does “more” imply “better”?
Don’t get me wrong, there are lots of Web features that are excellent. The kinds of things where it’s hard to remember how I did without them. CSS grids are for many purposes an
improvement on flexboxes; flexboxes were massively better than floats; and floats were an enormous leap forwards compared to using tables for layout! The “new” HTML5 input types are
wonderful, as are the revolutionary native elements for video, audio, etc. I’ll even sing the praises of some of the new JavaScript APIs (geolocation, web share, and push are
particular highlights).
But it’s not some kind of universal truth that “more features means better developer experience”. It’s already the case, for example, that getting started as a Web developer is
harder than it once was, and I’d argue harder than it ought to be. There exist complexities nowadays that are barriers to entry. Like the places where the promise of a
progressively-enhanced Web has failed (they’re rare, but they exist). Or the sheer plethora of features that come with caveats to their use that simply must be learned (yes, you need a
<meta name="viewport">; no, you can’t rely on JS to produce content).
Meanwhile, there are technologies that were standardised, and that we did need, but that never took off. The <keygen> element never got
implemented into the then-dominant Internet Explorer (there were other implementation problems too, but this one’s the killer). This made it functionally useless, which meant that its
standard never evolved and grew. As a result, its implementation in other browsers stagnated and it was eventually deprecated. Had it been implemented properly and iterated on, we’d
could’ve had something like WebAuthn over a decade earlier.
Which I guess goes to show that “more features is better” is only true if they’re the right features. Perhaps there’s some way of tracking the changing landscape of developer
experience on the Web that doesn’t simply count enumerate a baseline of widely-available features? I don’t know what it is, though!
A simple web
Mostly, the Web worked fine when it was simpler. And while some of the enhancements we’ve seen over the decades are indisputably an advancement, there are also plenty of places
where we’ve let new technologies lead us astray. Third-party cookies appeared as a naive consequence of first-party ones, but came to be used to undermine everybody’s privacy. Dynamic
DOM manipulation started out as a clever idea to help with things like form validation and now a significant number of websites can’t even show their images – or sometimes their text –
unless their JavaScript code gets downloaded and interpreted successfully.
Were you reading this article on Medium, you’d have downloaded ~5MB of data including 48 JS files and had 7 cookies set, just so you could… have most of the text covered with
popovers? (for comparison, reading it here takes about half a megabyte and the cookies are optional delicious)
A blog post, news article, or even an eCommerce site or social networking platform doesn’t need the vast majority of the Web’s “new” features. Those features are important for some Web
applications, but most of the time, we don’t need them. But somehow they end up being used anyway.
Whether or not the use of unnecessary new Web features is a net positive to developer experience is debatable. But it’s certainly not often to the benefit of user experience.
And that’s what I care about.
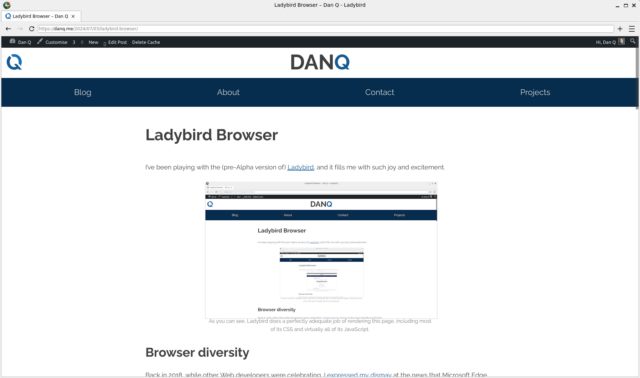
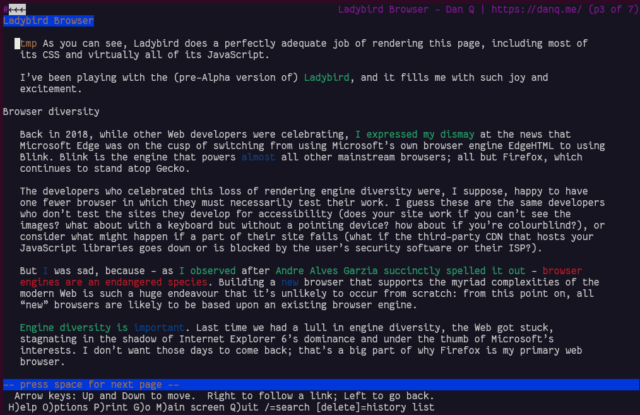
I’ve been playing with the (pre-Alpha version of) Ladybird, and it fills me with such joy and excitement.
As you can see, Ladybird does a perfectly adequate job of rendering this page, including most of its CSS and
virtually all of its JavaScript.
Browser diversity
Back in 2018, while other Web developers were celebrating, I expressed my dismay at the news that Microsoft Edge was on the cusp of switching
from using Microsoft’s own browser engine EdgeHTML to using Blink. Blink is the engine that powers almost all other mainstream browsers; all but Firefox, which continues to
stand atop Gecko.
The developers who celebrated this loss of rendering engine diversity were, I suppose, happy to have one fewer browser in which they must necessarily test their work. I guess these are
the same developers who don’t test the sites they develop for accessibility (does your site work if you can’t see the images? what about with a keyboard but without a pointing device?
how about if you’re colourblind?), or consider what might happen if a part of their site fails (what if the third-party CDN
that hosts your JavaScript libraries goes down or is blocked by the user’s security software or their ISP?).
When was the last time you tested your site in a text-mode browser?
But I was sad, because – as I observed after Andre
Alves Garzia succinctly spelled it out – browser engines are an endangered species. Building a new browser that supports the myriad complexities of the
modern Web is such a huge endeavour that it’s unlikely to occur from scratch: from this point on, all “new” browsers are likely to be based upon an existing browser engine.
Engine diversity is important. Last time we had a lull in engine diversity, the Web got stuck, stagnating in the
shadow of Internet Explorer 6’s dominance and under the thumb of Microsoft’s interests. I don’t want those days to come back; that’s a big part of why Firefox is my primary web browser.
A Ladybird book browser
I actually still own a copy of the book from which I adapted this cover!
Ladybird is a genuine new browser engine. Y’know, that thing I said that we might never see happen again! So how’ve they made it happen?
It helps that it’s not quite starting from scratch. It’s starting point is the HTML viewer component from SerenityOS. And… it’s pretty good. It’s DOM processing’s solid, it seems to support enough JavaScript and CSS that the modern Web is usable, even if it’s not beautiful 100% of the time.
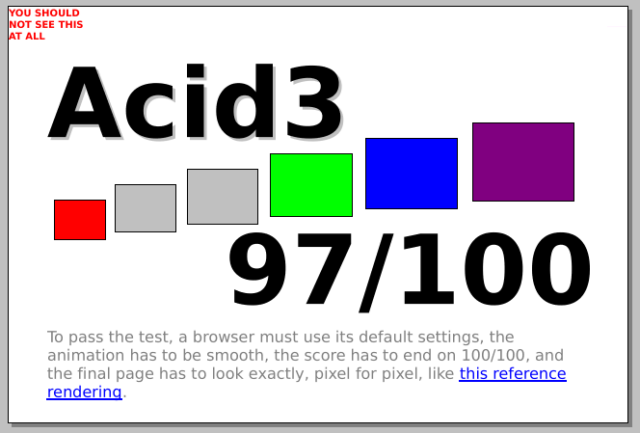
I’ve certainly seen browsers do worse than this at Acid3 and related tests…
They’re not even expecting to make an Alpha release until next year! Right now if you want to use it at all, you’re going to need to compile the code for yourself and fight with a
plethora of bugs, but it works and that, all by itself, is really exciting.
They’ve got four full-time engineers, funded off donations, with three more expected to join, plus a stack of volunteer contributors on Github. I’ve raised my first issue against the repo; sadly my C++ probably isn’t strong enough to be able to help more-directly, even if I
somehow did have enough free time, which I don’t. But I’ll be watching-from-afar this wonderful, ambitious, and ideologically-sound initiative.
When was the last time you tested your website in a text-only browser like Lynx (or ELinks, or one of several others)? Perhaps you should.
I’m a big fan of CSS Naked Day. I love the idea of JS Naked Day, although I missed it earlier this month (I was busy abroad, plus my aggressive caching,
including in service workers, makes it hard to reliably make sweeping changes for short periods). I’m a big fan of the idea that, for the vast majority of websites, if it isn’t at least
usable without any CSS or JavaScript, it should probably be considered broken.
This year, I thought I’d celebrate the events by testing DanQ.me in the most-limited browser I had to-hand: Lynx. Lynx has zero CSS or JavaScript support, along with limited-to-no support for heading levels, tables, images, etc. That may seem extreme, but it’s a reasonable
analogue for the level of functionality you might routinely expect to see in the toughest environments in which your site is accessed: slow 2G connections from old mobile hardware,
people on the other side of highly-restrictive firewalls or overenthusiastic privacy and security software, and of course users of accessibility technologies.
Here’s what broke (and some other observations):
<link rel="alternate">s at the top
I see the thinking that Lynx (and in an even more-extreme fashion, ELinks) have with showing “alternate versions” of a page at the top, but it’s not terribly helpful: most of mine are
designed to help robots, not humans!
Four alternates is pretty common for a WordPress site: post feed, comments feed, and two formats of oEmbed.
I wonder if switching from <link rel="alternate"> elements to Link: HTTP headers would
indicate to Lynx that it shouldn’t be putting these URLs in humans’ faces, while still making them accessible to all the
services that expect to find them? Doing so would require some changes to my caching logic, but might result in a cleaner, more human-readable HTML file as a side-effect. Possibly something worth investigating.
Fortunately, I ensure that my <link rel="alternate">s have a title attribute, which is respected by Lynx and ELinks and makes these scroll-past links
slightly less-confusing.
Not all sites title their alternate links. IKEA.com requires you to scroll through 113 anonymous links for their alternate language versions, because Lynx doesn’t understand the
hreflang attribute.
Post list indentation
Posts on the homepage are structured a little like this:
Strictly-speaking, that’s not valid. Heading elements are only permitted within flow elements. I chose to implement it that way because it seemed to be the most semantically-correct way
to describe the literal “list of posts”. But probably my use of <h2> is not the best solution. Let’s see how Lynx handles it:
Lynx “outdents” headings so they stand out, and “indents” lists so they look like lists. This causes a quirky clash where a heading is inside a list.
It’s not intolerable, but it’s a little ugly.
CSS lightboxes add a step to images
I use a zero-JavaScript approach to image lightboxes: you can see it by clicking
on any of the images in this post! It works by creating a (closed) <dialog> at the bottom of the page, for each image. Each <dialog> has a unique
id, and the inline image links to that anchor.
Originally, I used a CSS :target selector to detect when the link had been clicked and show the
<dialog>. I’ve since changed this to a :has(:target) and directed the link to an element within the dialog, because it works better on browsers
without CSS support.
It’s not perfect: in Lynx navigating on an inline image scrolls down to a list of images at the bottom of the page and selects the current one: hitting the link again now
offers to download the image. I wonder if I might be better to use a JavaScript-powered lightbox after all!
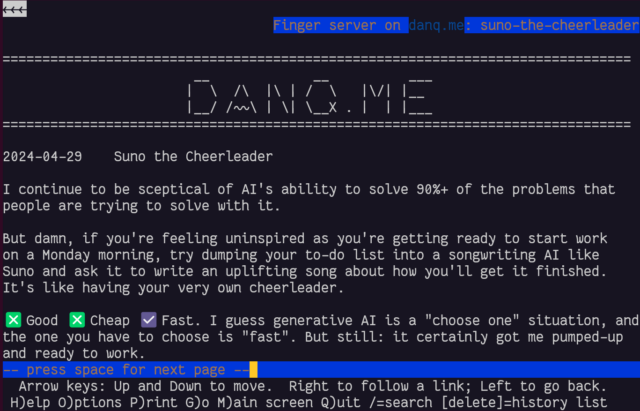
gopher: and finger: links work perfectly!
I was pleased to discover that gopher: and finger: links to alternate copies of a post… worked perfectly! That shouldn’t be a surprise – Lynx natively supports
these protocols.
In a fun quirk and unusually for a standard of its age, the Finger specification did not state the character encoding that ought to
be used. I guess the authors just assumed everybody reading it would use ASCII. But both my
WordPress-to-Finger bridge and Lynx instead assume that UTF-8 is acceptable (being a superset of
ASCII, that seems fair!) which means that emoji work (as shown in the screenshot above). That’s
nuts, isn’t it?
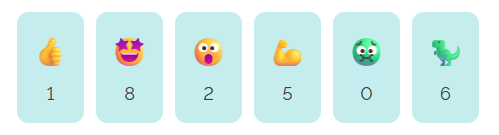
You can’t react to anything
Back in November I added the ability to “react” to a post by clicking an emoji, rather than
typing out a full comment. Because I was feeling lazy, the feature was (and remains) experimental, and I didn’t consider it essential functionality, I implemented it mostly in
JavaScript. Without JavaScript, all you can do is see what others have clicked.
The available emoji vary from post to post; I sometimes like to throw a weird/fun one in there, knowing that it’ll invariably be Ruth that
clicks it first.
In a browser with no JavaScript but with functional CSS, the buttons correctly appear disabled.
But with neither technology available, as in Lynx, they look like they should work, but just… don’t. Oops.
Lynx is correct; this is sloppy code. Without CSS support, it even shows the instruction that implies the buttons will work, but they don’t.
If I decide to keep the reaction buttons long-term, I’ll probably reimplement them so that they function using plain-old HTML
and HTTP, using a <form>, and refactor my JavaScript to properly progressively-enhance the buttons for
those that support it. For now, this’ll do.
Comment form honeypot
The comment form on my blog posts works… but there’s a quirk:
At the end of the comments form, an additional <textarea> appears!
That’s an annoyance. It turns out it’s a honeypot added by Akismet: a fake comments field, normally hidden, that tries to trick spam bots into filling
it (and thus giving themselves away): sort-of a “reverse CAPTCHA” where the
robots do something extra, unintentionally, to prove their inhumanity. Lynx doesn’t understand the code that Akismet uses to hide the form, and so it’s visible to humans, which
is suboptimal both because it’s confusing but also because a human who puts details into it is more-likely to be branded a spambot!
I might look into suppressing Akismet adding its honeypot field in the first place, or else consider one of the alternative anti-spam plugins for WordPress. I’ve heard good things about
Antispam Bee; I ought to try it at some point.
Overall, it’s pretty good
On the whole, DanQ.me works reasonably well in browsers without any JavaScript or CSS capability, with only a few optional
features failing to function fully. There’s always room for improvement, of course, and I’ve got a few things now to add to my “one day” to-do list for my little digital garden.
Obviously, this isn’t really about supporting people using text-mode browsers, who probably represent an incredible minority. It’s about making a real commitment to the
semantic web, to accessibility, and to progressive enhancement! That making your site resilient, performant, and accessible also helps make it function in even the
most-uncommon of browsers is just a bonus.
I mentioned yesterday that during Bloganuary I’d put non-Bloganuary-prompt post ideas onto the backburner, and considered extending my daily streak by posting them in February. Here’s part of my attempt to do
that:
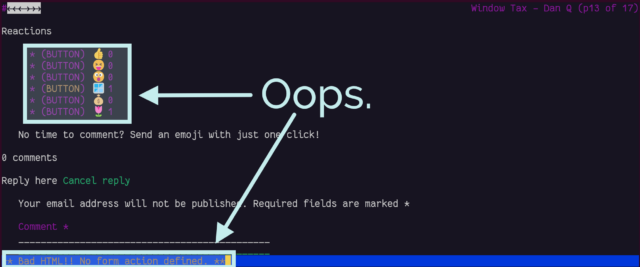
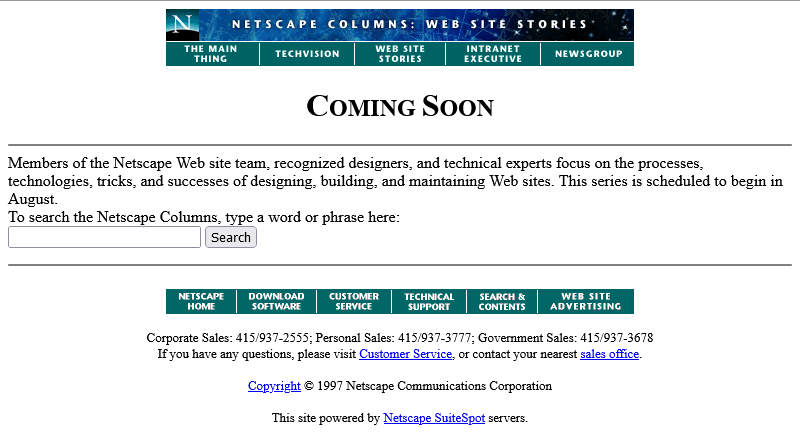
The page we’re interested in used to live at http://www.netscape.com/comprod/columns/webstories/index.html, and promised to be a showcase for best practice in Web
development. Back in October 1996, it looked like this:
The page is a placeholder for Netscape Webstories (or Web Site Stories, in some places). It’s part of a digital magazine called Netscape Columns which published pieces written by Marc
Andreeson, Jim Barksdale, and other bigwigs in the hugely-influential pre-AOL-acquisition Netscape Communications.
This new series would showcase best practice in designing and building Web sites1,
giving a voice to the technical folks best-placed to speak on that topic. That sounds cool!
Those white boxes above and below the paragraph of text aren’t missing images, by the way: they’re horizontal rules, using the little-known size attribute to specify a
thickness of <hr size=4>!2
Certainly you’re excited by this new column and you’ll come back in November 1996, right?
Oh. The launch has been delayed, I guess. Now it’s coming in January.
The <hr>s look better now their size has been reduced, though, so clearly somebody’s paying attention to the page. But let’s take a moment and look at that page
title. If you grew up writing web pages in the modern web, you might anticipate that it’s coded something like this:
There’s plenty of other ways to get that same effect. Perhaps you prefer font-feature-settings: 'smcp' in your chosen font; that’s perfectly valid. Maybe you’d use
margin: 0 auto or something to centre it: I won’t judge.
But no, that’s not how this works. The actual code for that page title is:
Back when this page was authored, we didn’t have CSS3.
The only styling elements were woven right in amongst the semantic elements of a page4.
It was simple to understand and easy to learn… but it was a total mess5.
Anyway, let’s come back in January 1997 and see what this feature looks like when it’s up-and-running.
Building “in public” was an act of commitment, a statement of intent, and an act of acceptance of the incompleteness of a digital garden. They’re sort-of coming back into fashion in the
interpersonal Web, with the “garden and stream” metaphor7
taking root. This isn’t anything new, of course – Mark Bernstein touched on the concepts in 1998 – but it’s not something that I can ever see returning to
the “serious” modern corporate Web: but if you’ve seen a genuine, non-ironic “under construction” page published to a non-root page of a company’s website within the last
decade, please let me know!
RSS doesn’t exist yet (although here’s a fun fact: the very first version of RSS came out of Netscape!). We’re just going to have to bookmark the page and check back later in the year, I guess…
Okay, so February clearly isn’t Spring, but they’ve updated the page… to add a search form.
It’s a genuine <form> tag, too, not one of those old-fashioned <isindex> tags you’d still sometimes find even as late as 1997. Interestingly, it specifies
enctype="application/x-www-form-urlencoded". Today’s developers probably don’t think about the enctype attribute except when they’re doing a form that handles
file uploads and they know they need to switch it to enctype="multipart/form-data", (or their framework does this automatically for them!).
But these aren’t the only options, and some older browsers at this time still defaulted to enctype="text/plain". So long as you’re using a POST
and not GET method, the distinction is mostly academic, but if your backend CGI program anticipates that special
characters will come-in encoded, back then you’d be wise to specify that you wanted URL-encoding or you might get a nasty surprise when somebody turns up using LMB or something
equally-exotic.
Anyway, let’s come back in June. The content must surely be up by now:
Oh come on! Now we’re waiting until August?
At least the page isn’t abandoned. Somebody’s coming back and editing it from time to time to let us know about the still-ongoing series of delays. And that’s not a trivial task: this
isn’t a CMS. They’re probably editing the .html file itself in their favourite text editor, then putting the
appropriate file:// address into their copy of Netscape Navigator (and maybe other browsers) to test it, then uploading the file – probably using FTP – to the webserver… all the while thanking their lucky stars that they’ve only got the one page they need to change.
We didn’t have scripting languages like PHP yet, you see8.
We didn’t really have static site generators. Most servers didn’t implement server-side includes. So if you had to make a change to every page on a site, for example editing
the main navigation menu, you’d probably have to open and edit dozens or even hundreds of pages. Little wonder that framesets caught on, despite their
(many) faults, with their ability to render your navigation separately from your page content.
Okay, let’s come back in August I guess:
Now we’re told that we’re to come back… in the Spring again? That could mean Spring 1998, I suppose… or it could just be that somebody accidentally re-uploaded an old copy of
the page.
Hey: the footer’s gone too? This is clearly a partial re-upload: somebody realised they were accidentally overwriting the page with the previous-but-one version, hit “cancel” in their
FTP client (or yanked the cable out of the wall), and assumed that they’d successfully stopped the upload before any damage was
done.
They had not.
I didn’t mention that top menu, did I? It looks like it’s a series of links, styled to look like flat buttons, right? But you know that’s not possible because you can’t rely on
having the right fonts available: plus you’d have to do some <table> trickery to lay it out, at which point you’d struggle to ensure that the menu was the same width
as the banner above it. So how did they do it?
The menu is what’s known as a client-side imagemap. Here’s
what the code looks like:
The image (which specifies border=0 because back then the default behaviour for graphical browser was to put a thick border around images within hyperlinks) says
usemap="#maintopmap" to cross-reference the <map> below it, which defines rectangular areas on the image and where they link to, if you click them! This
ingenious and popular approach meant that you could transmit a single image – saving on HTTP round-trips, which were
relatively time-consuming before widespread adoption of HTTP/1.1‘s persistent connections – along with a little metadata
to indicate which pixels linked to which pages.
The ismap attribute is provided as a fallback for browsers that didn’t yet support client-side image maps but did support server-side image maps: there were a few!
When you put ismap on an image within a hyperlink, then when the image is clicked on the href has appended to it a query parameter of the form
?123,456, where those digits refer to the horizontal and vertical coordinates, from the top-left, of the pixel that was clicked on! These could then be decoded by the
webserver via a .map file or handled by a CGI program. Server-side image maps were sometimes used where client-side maps were undesirable, e.g. when you want to record the actual coordinates
picked in a spot-the-ball competition or where you don’t want to reveal in advance which hotspot leads to what destination, but mostly they were just used as a fallback.9
Both client-side and server-side image maps still function in every modern web browser, but I’ve not seen them used in the wild for a long time, not least because they’re hard (maybe
impossible?) to make accessible and they can’t cope with images being resized, but also because nowadays if you really wanted to make an navigation “image” you’d probably cut it into a
series of smaller images and make each its own link.
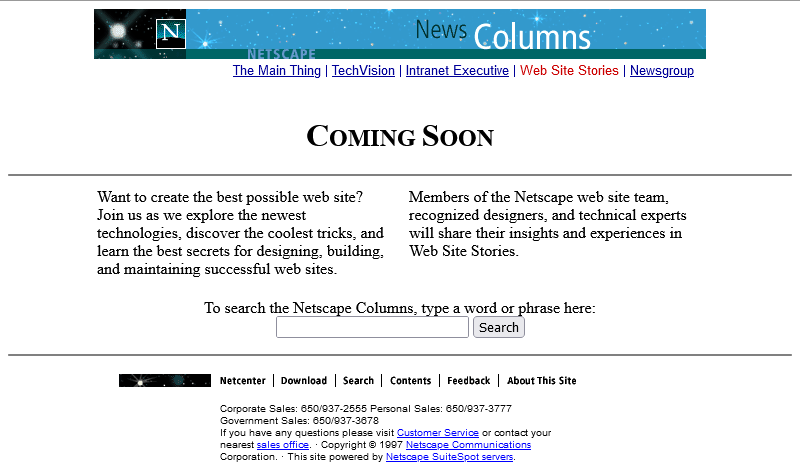
Anyway, let’s come back in October 1997 and see if they’ve fixed their now-incomplete page:
Oh, they have! From the look of things, they’ve re-written the page from scratch, replacing the version that got scrambled by that other employee. They’ve swapped out the banner and
menu for a new design, replaced the footer, and now the content’s laid out in a pair of columns.
There’s still no reliable CSS, so you’re not looking at columns: (no implementations until 2014) nor at
display: flex (2010) here. What you’re looking at is… a fixed-width <table> with a single row and three columns! Yes: three – the middle column
is only 10 pixels wide and provides the “gap” between the two columns of text.10
This wasn’t Netscape’s only option, though. Did you ever hear of the <multicol> tag? It was the closest thing the early Web had to a semantically-sound,
progressively-enhanced multi-column layout! The author of this page could have written this:
<multicol cols=2 gutter=10 width=301>
<p>
Want to create the best possible web site? Join us as we explore the newest
technologies, discover the coolest tricks, and learn the best secrets for
designing, building, and maintaining successful web sites.
</p>
<p>
Members of the Netscape web site team, recognized designers, and technical
experts will share their insights and experiences in Web Site Stories.
</p>
</multicol>
That would have given them the exact same effect, but with less code and it would have degraded gracefully. Browsers ignore tags they don’t understand, so a browser without
support for <multicol> would have simply rendered the two paragraphs one after the other. Genius!
So why didn’t they? Probably because <multicol>only ever worked in Netscape Navigator.
Introduced in 1996 for version 3.0, this feature was absolutely characteristic of the First Browser War. The two “superpowers”, Netscape and Microsoft, both engaged in unilateral
changes to the HTML specification, adding new features and launching them without announcement in order to try to get the
upper hand over the other. Both sides would often refuse to implement one-another’s new tags unless they were forced to by widespread adoption by page authors, instead
promoting their own competing mechanisms11.
Between adding this new language feature to their browser and writing this page, Netscape’s market share had fallen from around 80% to around 55%, and most of their losses were picked
up by IE. Using <multicol> would have made their page look worse in Microsoft’s hot up-and-coming
browser, which wouldn’t have helped them persuade more people to download a copy of Navigator and certainly wouldn’t be a good image on a soon-to-launch (any day now!) page about
best-practice on the Web! So Netscape’s authors opted for the dominant, cross-platform solution on this page12.
Anyway, let’s fast-forward a bit and see this project finally leave its “under construction” phase and launch!
Oh. It’s gone.
Sometime between October 1997 and February 1998 the long promised “Web Site Stories” section of Netscape Columns quietly disappeared from the website. Presumably, it never published a
single article, instead remaining a perpetual “Coming Soon” page right up until the day it was deleted.
I’m not sure if there’s a better metaphor for Netscape’s general demeanour in 1998 – the year in which they finally ceased to be the dominant market leader in web browsers – than the
quiet deletion of a page about how Netscape customers are making the best of the Web. This page might not have been important, or significant, or even completed, but
its disappearance may represent Netscape’s refocus on trying to stay relevant in the face of existential threat.
Of course, Microsoft won the First Browser War. They did so by pouring a fortune’s worth of developer effort into staying technologically one-step ahead, refusing to adopt standards
proposed by their rival, and their unprecedented decision to give away their browser for free13.
Footnotes
1 Yes, we used to write “Web sites” as two words. We also used to consistently capitalise
the words Web and Internet. Some of us still do so.
2 In case it’s not clear, this blog post is going to be as much about little-known and
archaic Web design techniques as it is about Netscape’s website.
3 This is a white lie. CSS was first
proposed almost at the same time as the Web! Microsoft Internet Explorer was first to deliver a partial implementation of the initial standard, late in 1996, but Netscape dragged
their heels, perhaps in part because they’d originally backed a competing standard called JavaScript
Style Sheets (JSSS). JSSS had a lot going for it: if it had
enjoyed widespread adoption, for example, we’d have had the equivalent of CSS variables a full twenty years earlier! In any
case, back in 1996 you definitely wouldn’t want to rely on CSS support.
4 Wondering where the text and link colours come from? <body bgcolor="#ffffff"
text="#000000" link="#0000ff" vlink="#ff0000" alink="#ff0000">. Yes really, that’s where we used to put our colours.
5 Personally, I really loved the aesthetic Netscape touted when using Times New Roman (or
whatever serif font was available on your computer: webfonts weren’t a thing yet) with temporary tweaks to font sizes, and I copied it in some of my own sites. If you look back at
my 2018 blog post celebrating two decades of blogging, where I’ve got a
screenshot of my blog as it looked circa 1999, you’ll see that I used exactly this technique for the ordinal suffixes on my post dates! On the same post, you’ll see that I somewhat
replicated the “feel” of it again in my 2011 design, this time using a stylesheet.
6 There’s a whole section of Cameron’s World
dedicated to “under construction” banners, and that’s a beautiful thing!
7 The idea of “garden and stream” is that you publish early and often, refining as you go,
in your garden, which can act as an extension of whatever notetaking system you use already, but publish mostly “finished” content to your (chronological) stream. I see an increasing
number of IndieWeb bloggers going down this route, but I’m not convinced that it’s for me.
8 Another white lie. PHP was
released way back in 1995 and even the very first version supported something a lot like server-side includes, using the syntax <!--include/file/name.html-->. But it was a little computationally-intensive to run willy-nilly.
9 Server-side imagemaps are enjoying a bit of a renaissance on .onion services, whose visitors often keep JavaScript disabled,
to make image-based CAPTCHAs. Simply show the visitor an image and
describe the bit you want them to click on, e.g. “the blue pentagon with one side missing”, then compare the coordinates of the pixel they click on to the knowledge of the right
answer. Highly-inaccessible, of course, but innovative from a purely-technical perspective.
10 Nowadays, use of tables for layout – or, indeed, for anything other than tabular
data – is very-much frowned upon: it’s often bad for accessibility and responsive design. But back before we had the features granted to us by the modern Web, it was literally
the only way to get content to appear side-by-side on a page, and designers got incredibly creative about how they misused tables to lay out content, especially as
browsers became more-sophisticated and began to support cells that spanned multiple rows or columns, tables “nested” within one another, and background images.
11 It was a horrible time to be a web developer: having to make hacky workarounds in
order to make use of the latest features but still support the widest array of browsers. But I’d still take that over the horrors of rendering engine monoculture!
12 Or maybe they didn’t even think about it and just copy-pasted from somewhere else on
their site. I’m speculating.
13 This turned out to be the master-stroke: not only did it partially-extricate
Microsoft from their agreement with Spyglass Inc., who licensed their browser engine to Microsoft in exchange for a percentage of sales value, but once Microsoft started
bundling Internet Explorer with Windows it meant that virtually every computer came with their browser factory-installed! This strategy kept Microsoft on top until Firefox and Google
Chrome kicked-off the Second Browser War in the early 2010s. But that’s another story.
I am not saying Apple’s approach is wrong. What Apple is doing is important too, and I applaud the work Apple has been doing in improving privacy on the web.
But it can’t be the only priority. Just imagine what the web would look like if every browser would have taken that approach 20 years ago.
Actually, no, don’t imagine it all. Just think back at Internet Explorer 6; that is what the web looked like 20 years ago.
…
There can only be one proper solution: Apple needs to open up their App Store to browsers with other rendering engines. Scrap rule 2.5.6 and allow other browsers on
iOS and let them genuinely compete.
As a reminder, Safari is the only web browser on iOS. You might have been fooled to think otherwise by the appearance of other browsers
in the App Store or perhaps by last year’s update that made it
possible at long last to change the default browser, but it’s all an illusion. Beneath the mask, all browsers on iOS are powered by Safari’s WebKit, or else they’re booted
from the App Store.
Neils’ comparison to Internet Explorer 6 is a good one, but as I’ve long pointed out, there’s a big and important difference between Microsoft’s story during the First Browser War and
Apple’s today:
Microsoft bundled Internet Explorer with Windows, raising the barrier to using a different web browser, which a court ruled as monopolistic and recommended that Microsoft be broken into smaller companies (this recommendation
was scaled back on appeal).
Apple bundle Safari with iOS and prohibit the use of any other browser’s rendering engine on that platform, preventing the use of a different web browser. Third-party
applications have been available for iOS – except, specifically, other browser rendering engines and a handful of other things – for 13 years now, but it still seems unlikely we’ll see
an antitrust case anytime soon.
Apple are holding the Web back… and getting away with it.
But sometimes, they disappear slowly, like this kind of web address:
http://username:password@example.com/somewhere
If you’ve not seen a URL like that before, that’s fine, because the answer to the question “Can I still use HTTP Basic Auth in URLs?” is, I’m afraid: no, you probably can’t.
But by way of a history lesson, let’s go back and look at what these URLs were, why they died out, and how web
browsers handle them today. Thanks to Ruth who asked the original question that inspired this post.
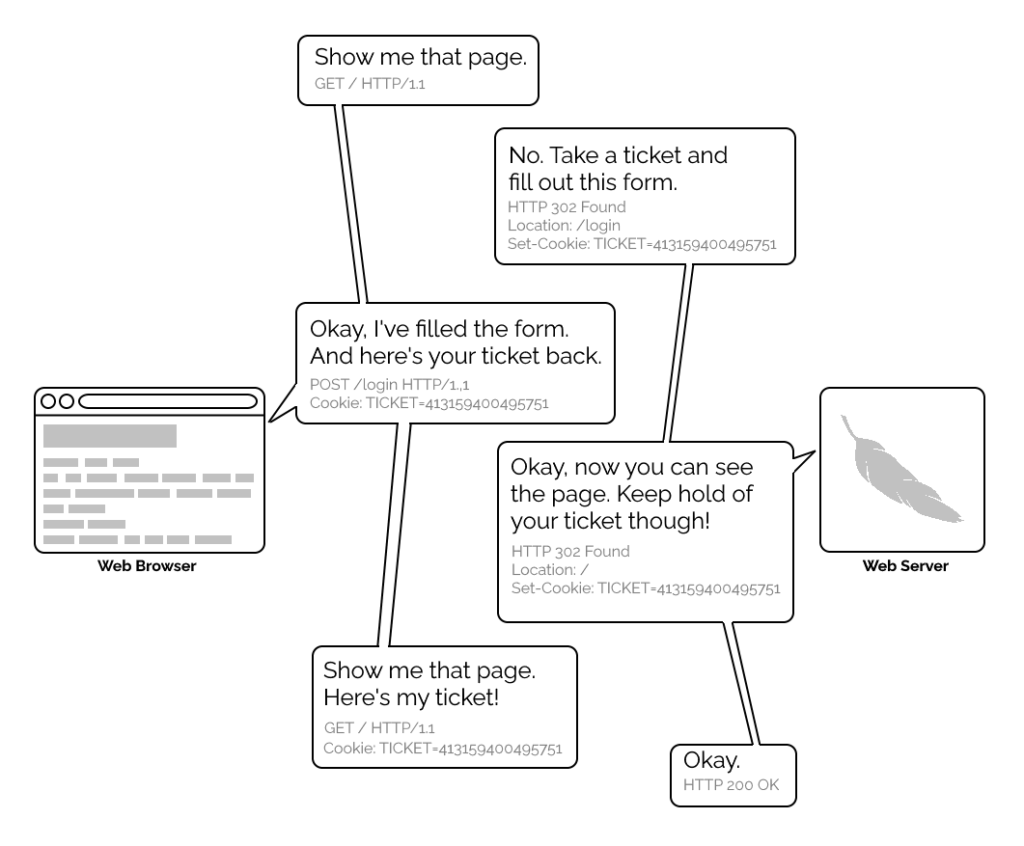
Basic authentication
The early Web wasn’t built for authentication. A resource on the Web was theoretically accessible to all of humankind: if you didn’t want it in the public eye, you didn’t put
it on the Web! A reliable method wouldn’t become available until the concept of state was provided by Netscape’s invention of HTTP
cookies in 1994, and even that wouldn’t see widespread for several years, not least because implementing a CGI (or
similar) program to perform authentication was a complex and computationally-expensive option for all but the biggest websites.
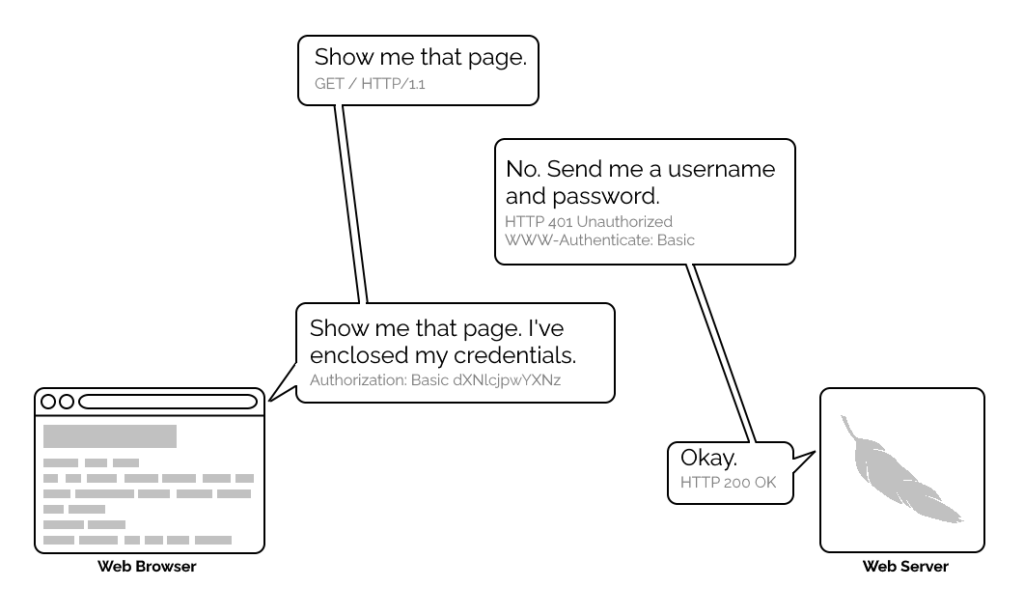
A simplified view of the form-and-cookie based authentication system used by virtually every website today, but which was too computationally-expensive for many sites in the 1990s.
1996’s HTTP/1.0 specification tried to simplify things, though, with the introduction of the WWW-Authenticate header. The idea was that when a browser tried to access something that required
authentication, the server would send a 401 Unauthorized response along with a WWW-Authenticate header explaining how the browser could authenticate
itself. Then, the browser would send a fresh request, this time with an Authorization: header attached providing the required credentials. Initially, only “basic
authentication” was available, which basically involved sending a username and password in-the-clear unless SSL (HTTPS) was in use, but later, digest authentication and a host of others would appear.
For all its faults, HTTP Basic Authentication (and its near cousins) are certainly elegant.
Webserver software quickly added support for this new feature and as a result web authors who lacked the technical know-how (or permission from the server administrator) to implement
more-sophisticated authentication systems could quickly implement HTTP Basic Authentication, often simply by adding a .htaccessfile to the relevant directory.
.htaccess files would later go on to serve many other purposes, but their original and perhaps best-known purpose – and the one that gives them their name – was access
control.
Credentials in the URL
A separate specification, not specific to the Web (but one of Tim Berners-Lee’s most important contributions to it), described the general structure of URLs as follows:
At the time that specification was written, the Web didn’t have a mechanism for passing usernames and passwords: this general case was intended only to apply to protocols that
did have these credentials. An example is given in the specification, and clarified with “An optional user name. Some schemes (e.g., ftp) allow the specification of a user
name.”
But once web browsers had WWW-Authenticate, virtually all of them added support for including the username and password in the web address too. This allowed for
e.g. hyperlinks with credentials embedded in them, which made for very convenient bookmarks, or partial credentials (e.g. just the username) to be included in a link, with the
user being prompted for the password on arrival at the destination. So far, so good.
Encoding authentication into the URL provided an incredible shortcut at a time when Web round-trip times were much longer owing to higher latencies and no keep-alives.
This is why we can’t have nice things
The technique fell out of favour as soon as it started being used for nefarious purposes. It didn’t take long for scammers to realise that they could create links like this:
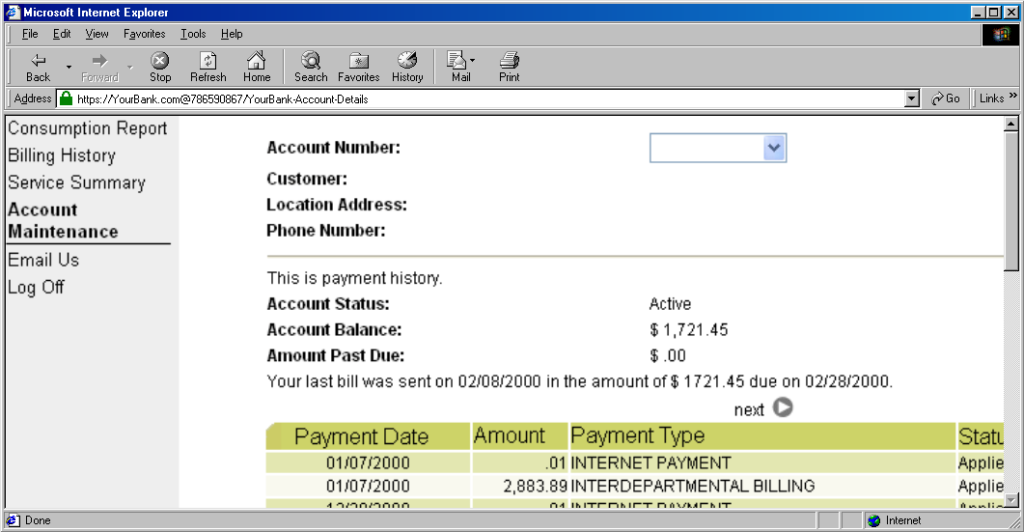
https://YourBank.com@HackersSite.com/
Everything we were teaching users about checking for “https://” followed by the domain name of their bank… was undermined by this user interface choice. The poor victim would
actually be connecting to e.g. HackersSite.com, but a quick glance at their address bar would leave them convinced that they were talking to YourBank.com!
Theoretically: widespread adoption of EV certificates coupled with sensible user interface choices (that were never made) could
have solved this problem, but a far simpler solution was just to not show usernames in the address bar. Web developers were by now far more excited about forms and
cookies for authentication anyway, so browsers started curtailing the “credentials in addresses” feature.
Users trained to look for “https://” followed by the site they wanted would often fall for scams like this one: the real domain name is after the @-sign. (This attacker is
also using dword notation to obfuscate their IP address; this
dated technique wasn’t often employed alongside this kind of scam, but it’s another historical oddity I enjoy so I’m shoehorning it in.)
(There are other reasons this particular implementation of HTTP Basic Authentication was less-than-ideal, but this reason is the big one that explains why things had to change.)
One by one, browsers made the change. But here’s the interesting bit: the browsers didn’t always make the change in the same way.
How different browsers handle basic authentication in URLs
Let’s examine some popular browsers. To run these tests I threw together a tiny web application that outputs
the Authorization: header passed to it, if present, and can optionally send a 401 Unauthorized response along with a WWW-Authenticate: Basic realm="Test Site" header in order to trigger basic authentication. Why both? So that I can test not only how browsers handle URLs containing credentials when an authentication request is received, but how they handle them when one is not. This is relevant because
some addresses – often API endpoints – have optional HTTP authentication, and it’s sometimes important for a user agent (albeit typically a library or command-line one) to pass credentials without
first being prompted.
In each case, I tried each of the following tests in a fresh browser instance:
Go to http://<username>:<password>@<domain>/optional (authentication is optional).
Go to http://<username>:<password>@<domain>/mandatory (authentication is mandatory).
Experiment 1, then f0llow relative hyperlinks (which should correctly retain the credentials) to /mandatory.
Experiment 2, then follow relative hyperlinks to the /optional.
I’m only testing over the http scheme, because I’ve no reason to believe that any of the browsers under test treat the https scheme differently.
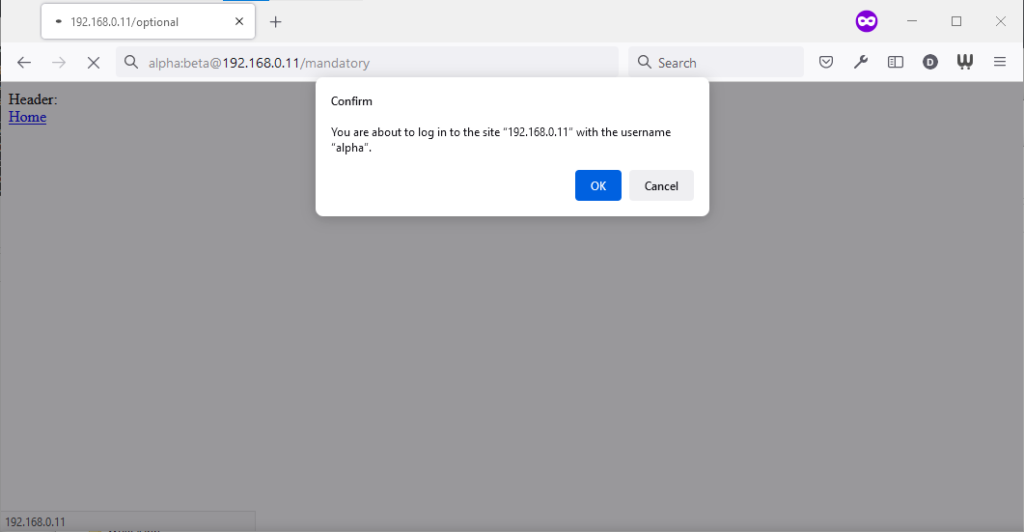
Chromium desktop family
Chrome 93 and Edge 93 both immediately suppressed the username and password from the address bar, along with the “http://” as we’ve come to expect of them. Like the “http://”, though,
the plaintext username and password are still there. You can retrieve them by copy-pasting the entire address.
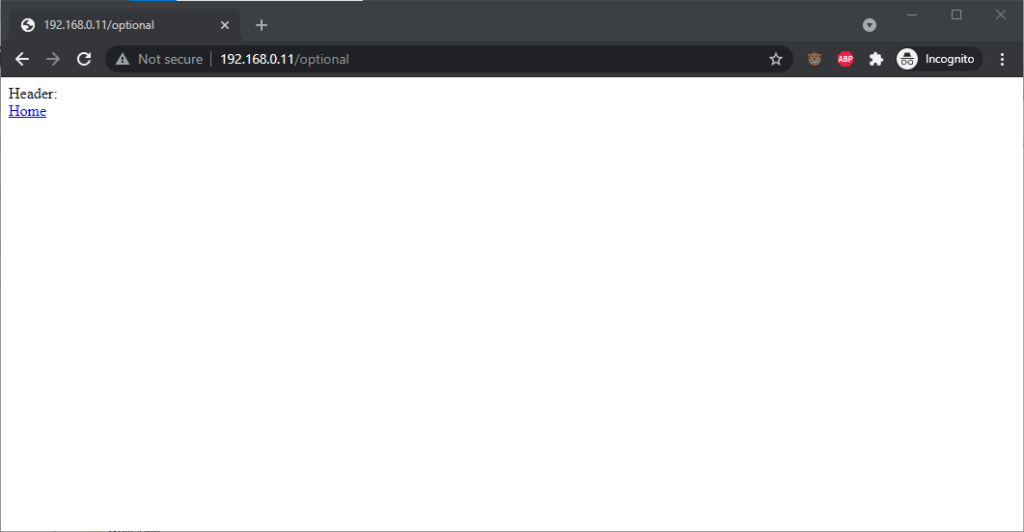
Opera 78 similarly suppressed the username, password, and scheme, but didn’t retain the username and password in a way that could be copy-pasted out.
Authentication was passed only when landing on a “mandatory” page; never when landing on an “optional” page. Refreshing the page or re-entering the address with its credentials did not
change this.
Navigating from the “optional” page to the “mandatory” page using only relative links retained the username and password and submitted it to the server when it became mandatory,
even Opera which didn’t initially appear to retain the credentials at all.
Navigating from the “mandatory” to the “optional” page using only relative links, or even entering the “optional” page address with credentials after visiting the “mandatory” page, does
not result in authentication being passed to the “optional” page. However, it’s interesting to note that once authentication has occurred on a mandatory page, pressing enter at
the end of the address bar on the optional page, with credentials in the address bar (whether visible or hidden from the user) does result in the credentials being passed to
the optional page! They continue to be passed on each subsequent load of the “optional” page until the browsing session is ended.
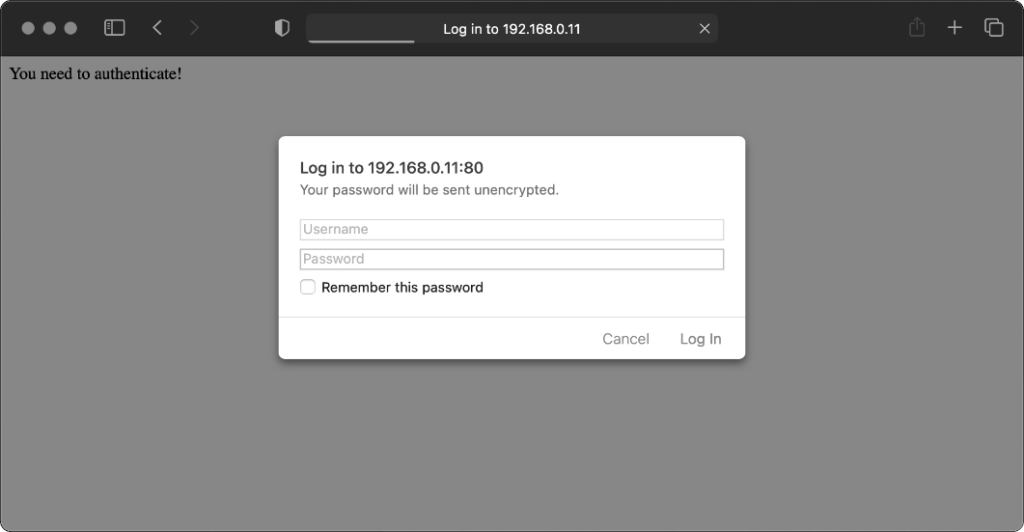
Firefox desktop
Firefox 91 does a clever thing very much in-line with
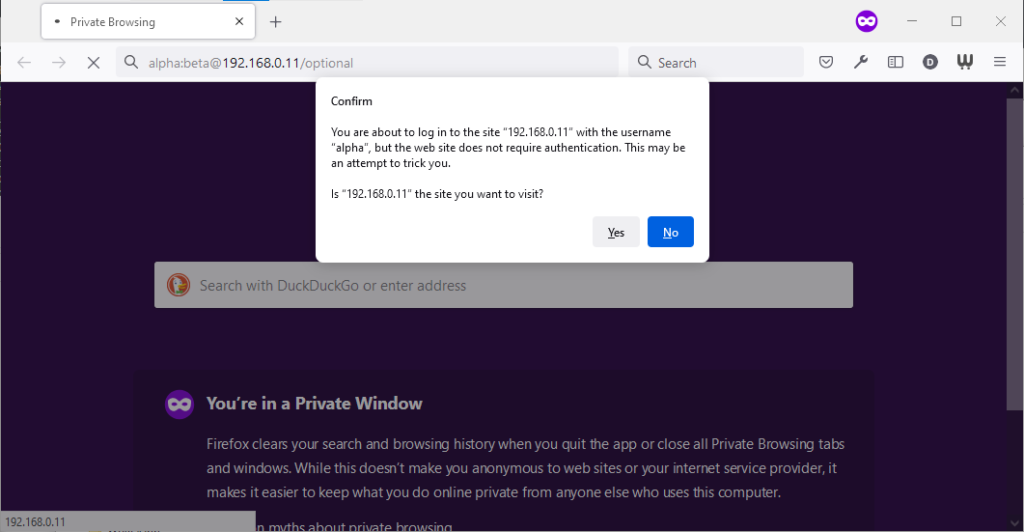
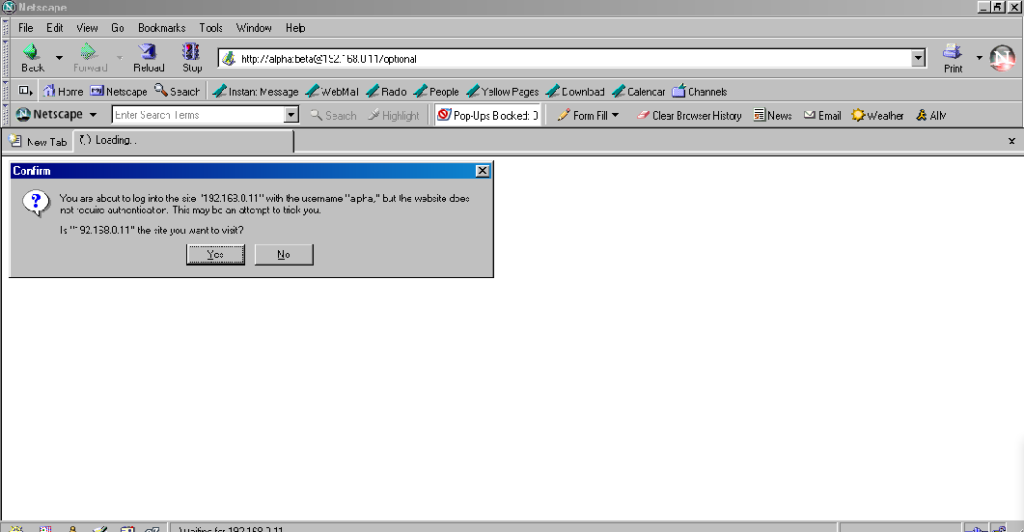
its image as a browser that puts decision-making authority into the hands of its user. When going to the “optional” page first it presents a dialog, warning the user that they’re going
to a site that does not specifically request a username, but they’re providing one anyway. If the user says that no, navigation ceases (the GET request for the page takes place the same
either way; this happens before the dialog appears). Strangely: regardless of whether the user selects yes or no, the credentials are not passed on the “optional” page. The credentials
(although not the “http://”) appear in the address bar while the user makes their decision.
Similar to Opera, the credentials do not appear in the address bar thereafter, but they’re clearly still being stored: if the refresh button is pressed the dialog appears again. It does
not appear if the user selects the address bar and presses enter.
Similarly, going to the “mandatory” page in Firefox results in an informative dialog warning the user
that credentials are being passed. I like this approach: not only does it help protect the user from the use of authentication as a tracking technique (an old technique that I’ve not
seen used in well over a decade, mind), it also helps the user be sure that they’re logging in using the account they mean to, when following a link for that purpose. Again, clicking
cancel stops navigation, although the initial request (with no credentials) and the 401 response has already occurred.
Visiting any page within the scope of the realm of the authentication after visiting the “mandatory” page results in credentials being sent, whether or not they’re included in the
address. This is probably the most-true implementation to the expectations of the standard that I’ve found in a modern graphical browser.
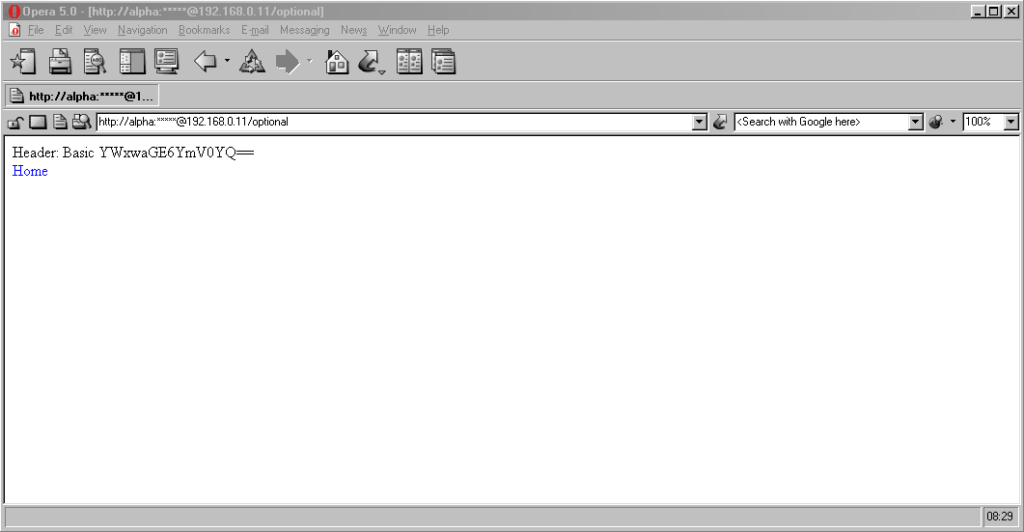
Safari desktop
Safari 14 never displays or uses credentials provided via the web address, whether or not
authentication is mandatory. Mandatory authentication is always met by a pop-up dialog, even if credentials were provided in the address bar. Boo!
Once passed, credentials are later provided automatically to other addresses within the same realm (i.e. optional pages).
Older browsers
Let’s try some older browsers.
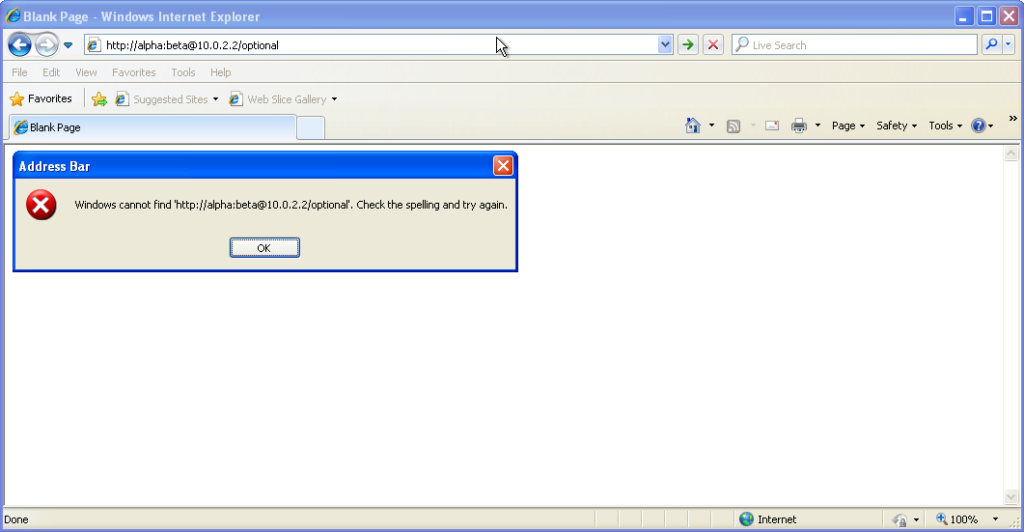
From version 7 onwards – right up to the final version 11 – Internet Explorer fails to even recognise
addresses with authentication credentials in as legitimate web addresses, regardless of whether or not authentication is requested by the server. It’s easy to assume that this is yet
another missing feature in the browser we all love to hate, but it’s interesting to note that credentials-in-addresses is permitted for ftp:// URLs…
…and if you go back a little way, Internet Explorer 6 and below supported credentials in the address bar pretty
much as you’d expect based on the standard. The error message seen in IE7 and above is a deliberate design
decision, albeit a somewhat knee-jerk reaction to the security issues posed by the feature (compare to the more-careful approach of other browsers).
These older versions of IE even (correctly) retain the credentials through relative hyperlinks, allowing them to be passed when
they become mandatory. They’re not passed on optional pages unless a mandatory page within the same realm has already been encountered.
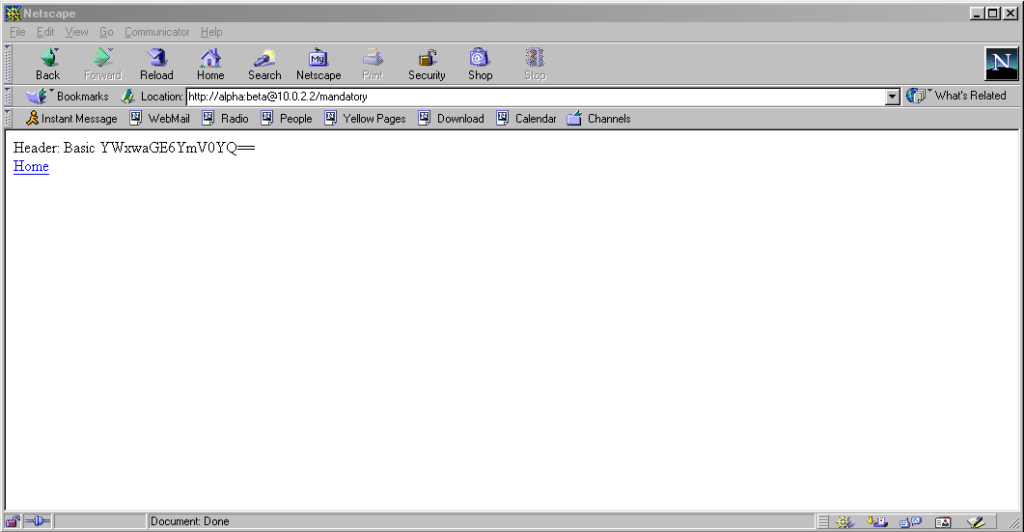
Pre-Mozilla Netscape behaved the same way. Truly this was the de facto standard for a long period on the Web, and the varied approaches we see today are the
anomaly. That’s a strange observation to make, considering how much the Web of the 1990s was dominated by incompatible implementations of different Web features (I’ve written about the <blink> and <marquee> tags before, which was perhaps the most-visible division between
the Microsoft and Netscape camps, but there were many, many more).
Interestingly: by Netscape 7.2 the browser’s behaviour had evolved
to be the same as modern Firefox’s, except that it still displayed the credentials in the address bar for all to see.
Now here’s a real gem: pre-Chromium Opera. It would send credentials to “mandatory” pages and remember them for the
duration of the browsing session, which is great. But it would also send credentials when passed in a web address to “optional” pages. However, it wouldn’t remember
them on optional pages unless they remained in the address bar: this feels to me like an optimum balance of features for power users. Plus, it’s one of very few browsers that
permitted you to change credentials mid-session: just by changing them in the address bar! Most other browsers, even to this day, ignore changes to HTTP Authentication credentials, which was sometimes be a source of frustration back in the day.
Finally, classic Opera was the only browser I’ve seen to mask the password in the address bar, turning it into a series of asterisks. This ensures the user knows that a
password was used, but does not leak any sensitive information to shoulder-surfers (the length of the “masked” password was always the same length, too, so it didn’t even leak the
length of the password). Altogether a spectacular design and a great example of why classic Opera was way ahead of its time.
The Command-Line
Most people using web addresses with credentials embedded within them nowadays are probably working with code, APIs,
or the command line, so it’s unsurprising to see that this is where the most “traditional” standards-compliance is found.
I was unsurprised to discover that giving curl a username and password in the URL meant that
username and password was sent to the server (using Basic authentication, of course, if no authentication was requested):
However, wgetdid catch me out. Hitting the same addresses with wget didn’t result in the credentials being sent
except where it was mandatory (i.e. where a HTTP 401 response and a WWW-Authenticate: header was received on the initial attempt). To force wget to
send credentials when they haven’t been asked-for requires the use of the --http-user and --http-password switches:
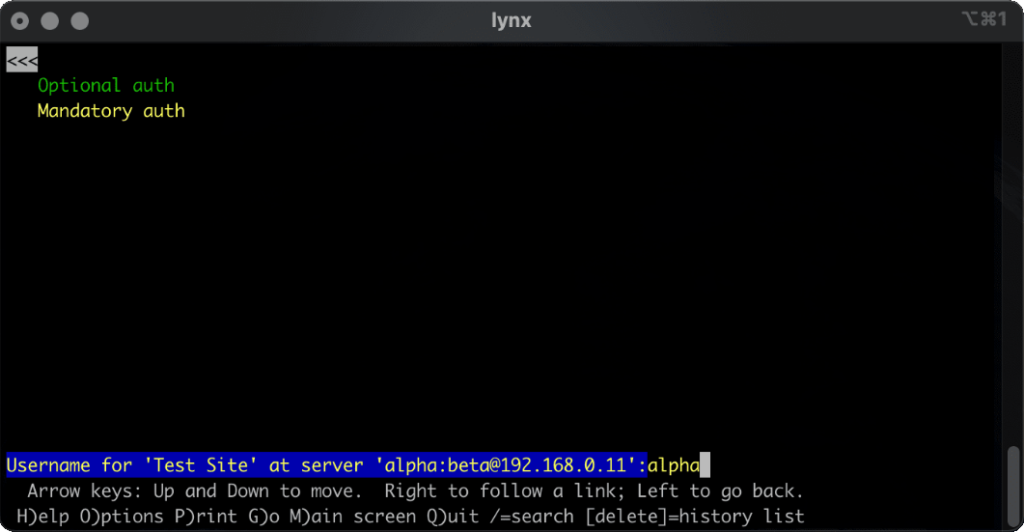
lynx does a cute and clever thing. Like most modern browsers, it does not submit credentials unless specifically requested, but if
they’re in the address bar when they become mandatory (e.g. because of following relative hyperlinks or hyperlinks containing credentials) it prompts for the username and password,
but pre-fills the form with the details from the URL. Nice.
What’s the status of HTTP (Basic) Authentication?
HTTP Basic Authentication and its close cousin Digest Authentication (which overcomes some of the security limitations of running Basic Authentication over an
unencrypted connection) is very much alive, but its use in hyperlinks can’t be relied upon: some browsers (e.g. IE, Safari)
completely munge such links while others don’t behave as you might expect. Other mechanisms like Bearer see widespread use in APIs, but nowhere else.
The WWW-Authenticate: and Authorization: headers are, in some ways, an example of the best possible way to implement authentication on the Web: as an
underlying standard independent of support for forms (and, increasingly, Javascript), cookies, and complex multi-part conversations. It’s easy to imagine an alternative
timeline where these standards continued to be collaboratively developed and maintained and their shortfalls – e.g. not being able to easily log out when using most graphical browsers!
– were overcome. A timeline in which one might write a login form like this, knowing that your e.g. “authenticate” attributes would instruct the browser to send credentials using an
Authorization: header:
In such a world, more-complex authentication strategies (e.g. multi-factor authentication) could involve encoding forms as JSON. And single-sign-on systems would simply involve the browser collecting a token from the authentication provider and passing it on to the
third-party service, directly through browser headers, with no need for backwards-and-forwards redirects with stacks of information in GET parameters as is the case today.
Client-side certificates – long a powerful but neglected authentication mechanism in their own right – could act as first class citizens directly alongside such a system, providing
transparent second-factor authentication wherever it was required. You wouldn’t have to accept a tracking cookie from a site in order to log in (or stay logged in), and if your
browser-integrated password safe supported it you could log on and off from any site simply by toggling that account’s “switch”, without even visiting the site: all you’d be changing is
whether or not your credentials would be sent when the time came.
The Web has long been on a constant push for the next new shiny thing, and that’s sometimes meant that established standards have been neglected prematurely or have failed to evolve for
longer than we’d have liked. Consider how long it took us to get the <video> and <audio> elements because the “new shiny” Flash came to dominate,
how the Web Payments API is only just beginning to mature despite over 25 years of ecommerce on the Web, or how we still can’t
use Link: headers for all the things we can use <link> elements for despite them being semantically-equivalent!
The new model for Web features seems to be that new features first come from a popular JavaScript implementation, and then eventually it evolves into a native browser feature: for
example HTML form validations, which for the longest time could only be done client-side using scripting languages. I’d love
to see somebody re-think HTTP Authentication in this way, but sadly we’ll never get a 100% solution in JavaScript alone: (distributed SSO is almost certainly off the table, for example, owing to cross-domain limitations).
Or maybe it’s just a problem that’s waiting for somebody cleverer than I to come and solve it. Want to give it a go?
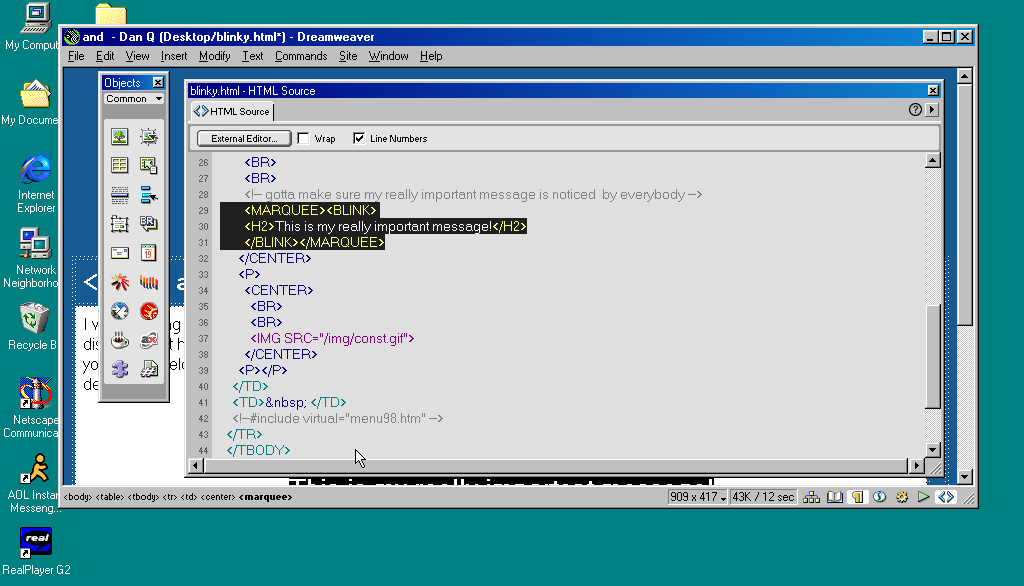
I was chatting with a fellow web developer recently and made a joke about the HTML <blink> and
<marquee> tags, only to discover that he had no idea what I was talking about. They’re a part of web history that’s fallen off the radar and younger developers are
unlikely to have ever come across them. But for a little while, back in the 90s, they were a big deal.
Even Macromedia Dreamweaver, which embodied the essence of 1990s web design, seemed to treat wrapping
<blink> in <marquee> as an antipattern.
Invention of the <blink> element is often credited to Lou Montulli, who wrote pioneering web browser Lynx before being joining Netscape in 1994. He insists that he didn’t write any
of the code that eventually became the first implementation of <blink>. Instead, he claims: while out at a bar (on the evening he’d first meet his wife!), he
pointed out that many of the fancy new stylistic elements the other Netscape engineers were proposing wouldn’t work in Lynx, which is a text-only browser. The fanciest conceivable
effect that would work across both browsers would be making the text flash on and off, he joked. Then another engineer – who he doesn’t identify – pulled a late night hack session and
added it.
And so it was that when Netscape Navigator 2.0 was released in 1995 it added support for
the <blink> tag. Also animated GIFs and the first inklings of JavaScript, which collectively
would go on to define the “personal website” experience for years to come. Here’s how you’d use it:
<BLINK>This is my blinking text!</BLINK>
With no attributes, it was clear from the outset that this tag was supposed to be a joke. By the time HTML4 was
published as a a recommendation two years later, it was documented as being a joke. But the Web of the late 1990s
saw it used a lot. If you wanted somebody to notice the “latest updates” section on your personal home page, you’d wrap a <blink> tag around the title (or,
if you were a sadist, the entire block).
If you missed this particular chapter of the Web’s history, you can simulate it at Cameron’s World.
In the same year as Netscape Navigator 2.0 was released, Microsoft released Internet Explorer
2.0. At this point, Internet Explorer was still very-much playing catch-up with the features the Netscape team had implemented, but clearly some senior Microsoft engineer took a
look at the <blink> tag, refused to play along with the joke, but had an innovation of their own: the <marquee> tag! It had a whole suite of attributes to control the scroll direction, speed, and whether it looped or bounced backwards and forwards. While
<blink> encouraged disgusting and inaccessible design as a joke, <marquee> did it on purpose.
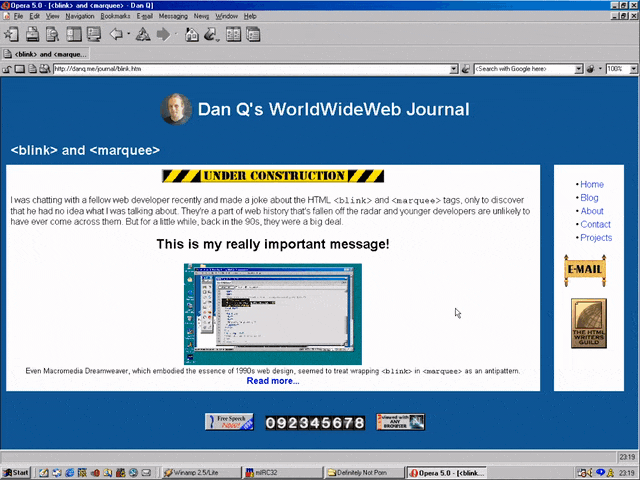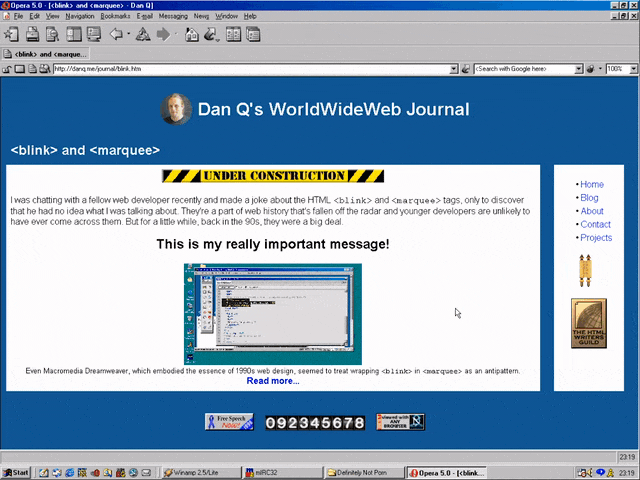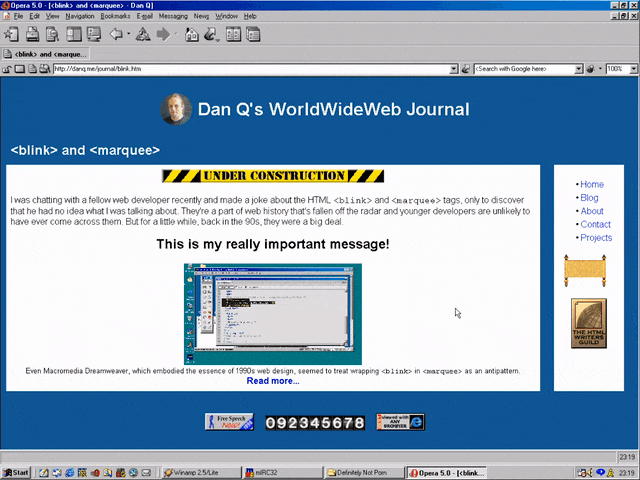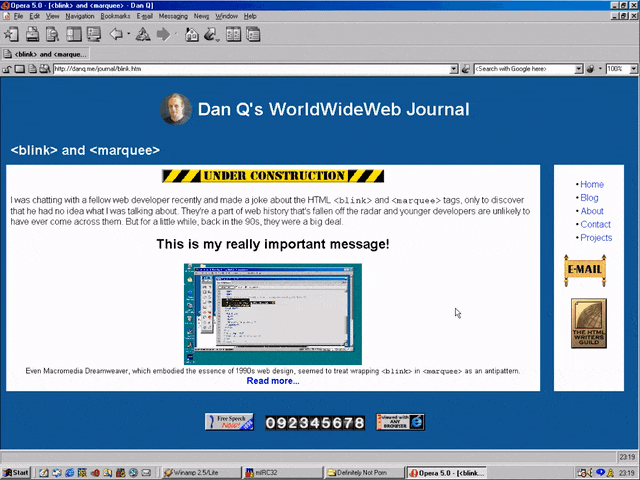
<MARQUEE>Oh my god this still works in most modern browsers!</MARQUEE>
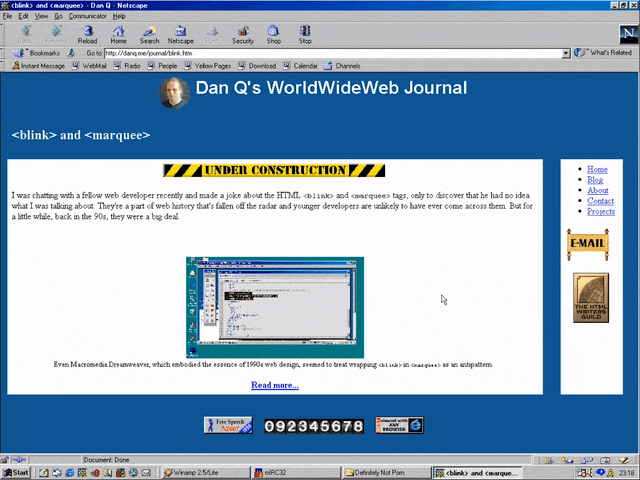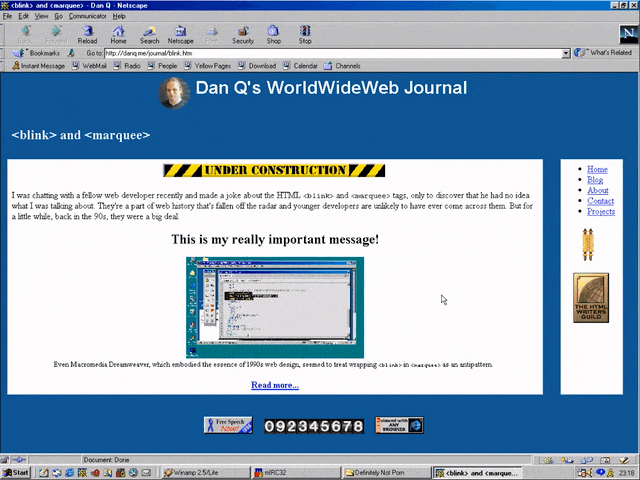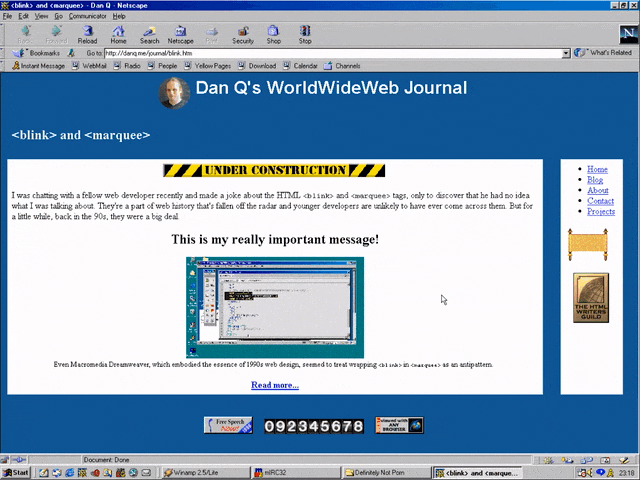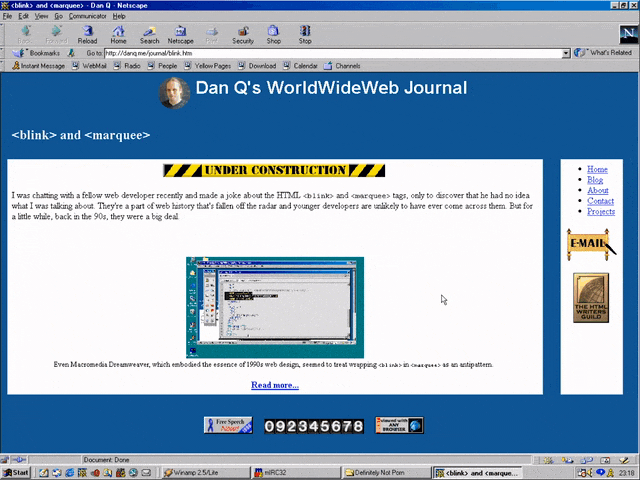
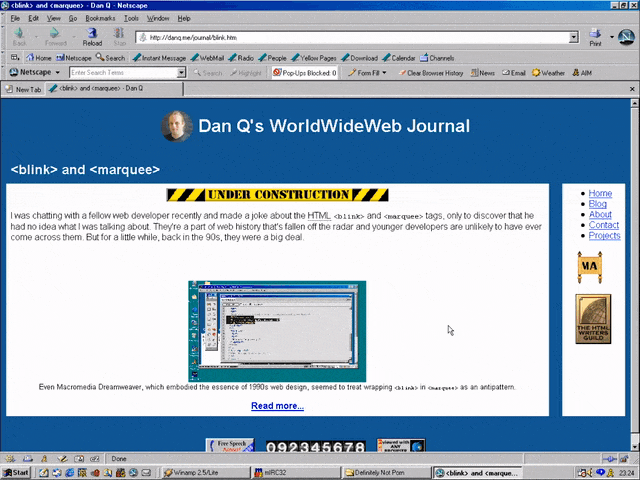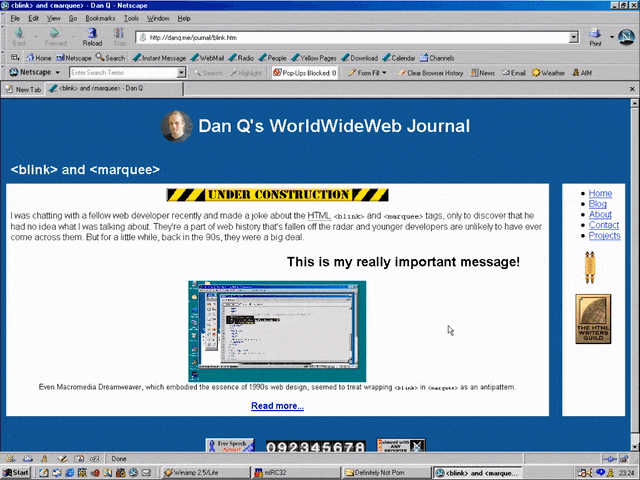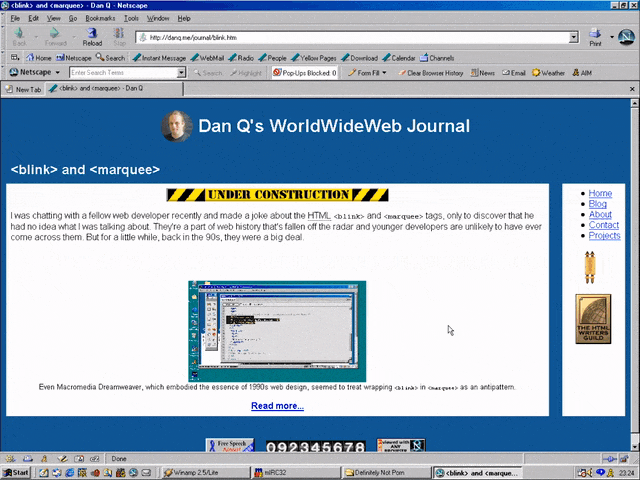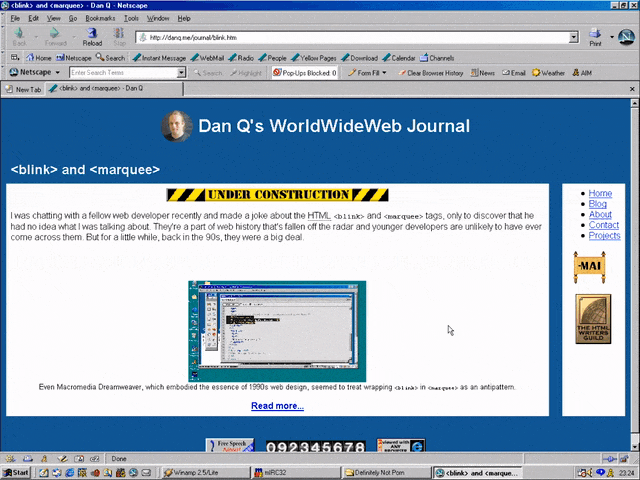
But here’s the interesting bit: for a while in the late 1990s, it became a somewhat common practice to wrap content that you wanted to emphasise with animation in both a
<blink> and a <marquee> tag. That way, the Netscape users would see it flash, the IE users
would see it scroll or bounce. Like this:
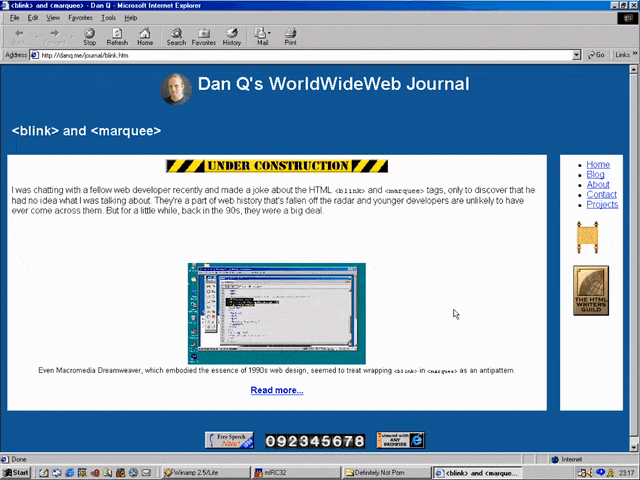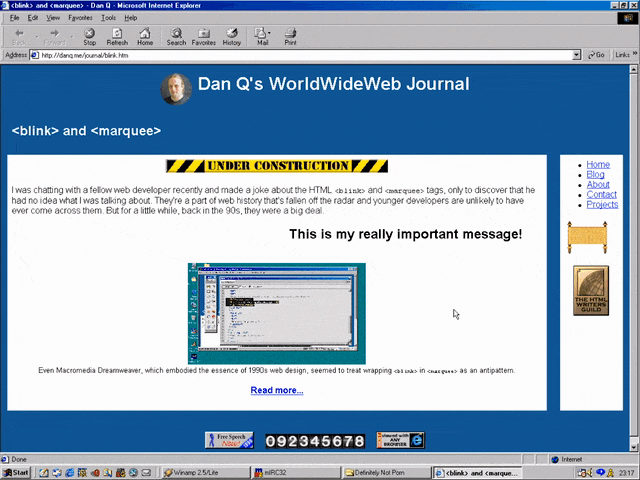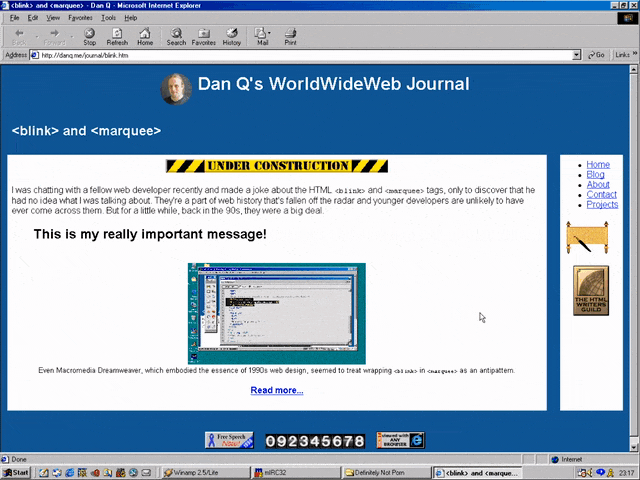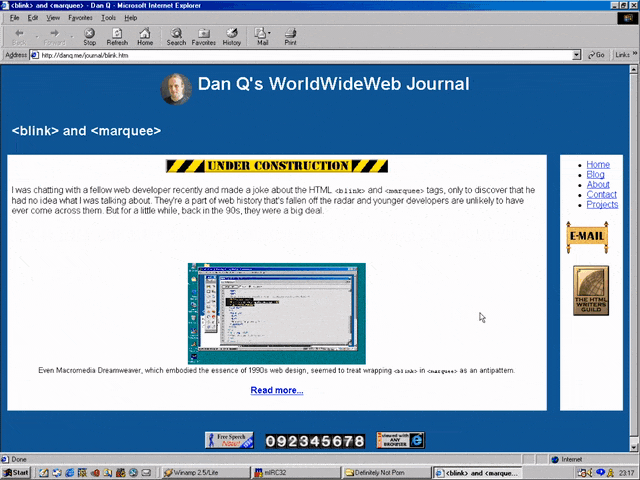
<MARQUEE><BLINK>This is my really important message!</BLINK></MARQUEE>
Wrap a <blink> inside a <marquee> and IE users will see the marquee. Delightful.
The web has always been built on Postel’s Law: a web browser should assume that it won’t understand everything it reads,
but it should provide a best-effort rendering for the benefit of its user anyway. Ever wondered why the modern <video> element is a block rather than a self-closing
tag? It’s so you can embed within it code that an earlier browser – one that doesn’t understand <video> – can read (a browser’s default state when seeing a
new element it doesn’t understand is to ignore it and carry on). So embedding a <blink> in a <marquee> gave you the best of both worlds, right?
(welll…)
Wrap a <blink> inside a <marquee> and Netscape users will see the blink. Joy.
Better yet, you were safe in the knowledge that anybody using a browser that didn’t understand either of these tags could still read your content. Used properly, the
web is about progressive enhancement. Implement for everybody, enhance for those who support the shiny features. JavaScript and CSS can be applied with the same rules, and doing so pays dividends in maintainability and accessibility (though, sadly, that doesn’t stop people writing
sites that needlessly require these technologies).
Personally, I was a (paying! – back when people used to pay for web browsers!) Opera user so I mostly saw neither <blink> nor <marquee> elements.
I don’t feel like I missed out.
I remember, though, the first time I tried Netscape 7, in 2002. Netscape 7 and its close descendent are, as far as I can tell, the only web browsers to support both<blink> and <marquee>. Even then, it was picky about the order in which they were presented and the elements wrapped-within them. But support was
good enough that some people’s personal web pages suddenly began to exhibit the most ugly effect imaginable: the combination of both scrolling and flashing text.
If Netscape 7’s UI didn’t already make your eyes bleed (I’ve toned it down here by installing the “classic skin”), its simultaneous
rendering of <blink> and <marquee> would.
The <blink> tag is very-definitely dead (hurrah!), but you can bring it back with pure CSS if you must.
<marquee>, amazingly, still survives, not only in polyfills but natively, as you might be able to see above. However, if you’re in any doubt as to whether or not
you should use it: you shouldn’t. If you’re looking for digital nostalgia, there’s a whole
rabbit hole to dive down, but you don’t need to inflict <marquee> on the rest of us.
Enter the latest iteration of the Android version, Firefox Daylight, which came
out last week.
When you first run Firefox Daylight, you’re asked where you want the address bar, among other things.
First, the good: this latest version of Firefox for Android is fast. Blazingly fast. The privacy controls are clearer and easier to access. Having picture-in-picture mode
on mobile is a nice touch, as is the new generation of tracking prevention features.
But Firefox Daylight still makes me frown. And it’s a trio of smaller things that really niggle:
1. Top or bottom toolbar… but top is a second-class citizen.
In theory, I like the idea of having the address bar and its friends at the bottom of the screen where it’s more-accessible to your thumb. I’ve even tried it, independently. in years
past. But it’s too much of a mental leap for me nowadays, plus it doesn’t cleanly fit into the “scroll down and the address bar disappears” user experience that’s become commonplace.
Making bottom toolbar the default was perhaps a little radical, then, but at least Mozilla provided an option to put it back at the top. But… it’s not quite right:
Sure, I’ll move my thumb the entire height of the screen every time I want to open a new tab.
Even with the toolbar moved back to the top, some controls associated with it stay at the bottom. Want to open a new tab? You have to press the “tabs” button at the top of the
screen, then the “plus” button at the bottom of the screen, then – probably – the address bar back at the top of the screen again! You’ve just covered two complete
lengths of the screen to do something that used to require none. Not a satisfactory experience.
The old interface put the oft-used “add tab” button in the toolbar in the same place as the “tabs” button you just pressed. Much better.
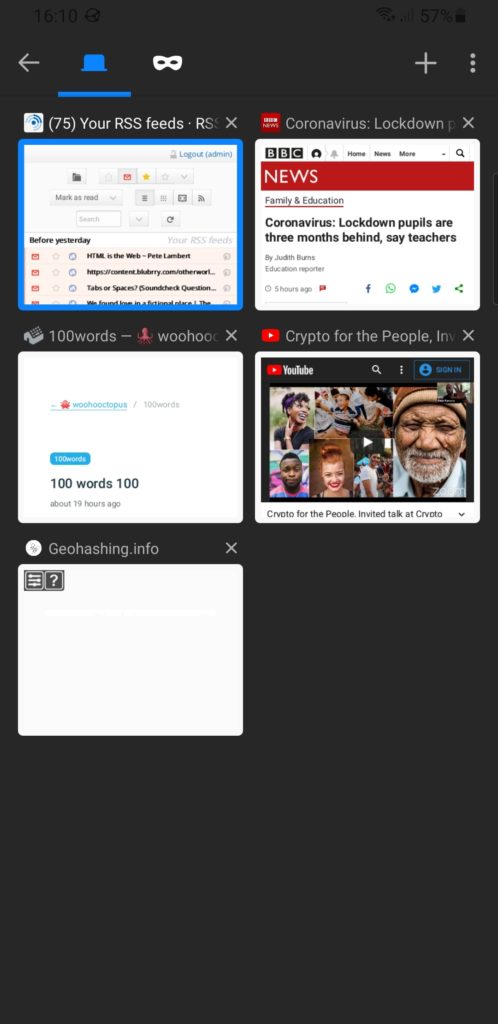
2. Tab previews were more space-efficient before
You’ve probably already spotted the other change to the “current tabs” view. Previously, open tabs were shown as mini previews with their titles above. Now they’re shown as tiny
(sometimes absent) icon-sized previews with their titles alongside. This allows the domain name to be shown, which is nice, but not nice enough to justify reducing the instant
visual recognition the previous interface provided.
It’s not even like you can fit more tabs onto a screen. The capacity is basically the same. You’re just making smaller hit targets with less recognisable graphics. Plus: previously the
most-recent tabs were at the bottom (close to where your thumb is, which was the justification for making the address bar default to the bottom); now they’re at the top, further adding
to the distance travelled.
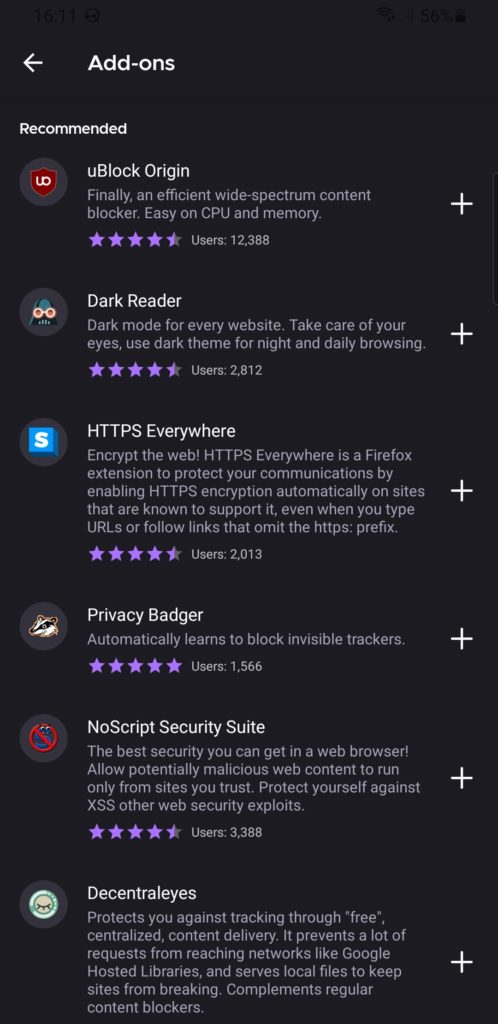
3. Plugin support is terrible
I know first hand that implementing backwards-compatibility is hard, but breaking most plugins and then providing a list of nine or so popular/recommended ones that
still works isn’t a great experience.
No uMatrix. No Violentmonkey (or any
equivalent). No Ghostery, even! Feels like surfing the Web with one hand tied behind my back.
Feels a bit like this was released before it was ready.
For the time being, I’m using Fennec F-Droid as my primary mobile browser. It picks up exactly where Firefox for
Android left off, and it doesn’t break my workflow. I hope to switch back to regular Firefox for Android someday, but Daylight needs “finishing” first.
Starting in Edge 82.0.425.0 Canary, a new flag is available.
…
…
This is a good move; a relatively simple innovation that’s sure to help end-user security. If you can’t see what’s different above without following the link through to the original
article, here’s the short version: an upcoming version of Edge will allow you to authorise a specific site to open a particular application to handle a link… without
having to compromise by choosing either to (a) see the security dialog every single time (which teaches users to “just click OK”) or (b) allow the dialog to be suppressed for links that
open a particular application (which makes it easier for bad guys to make poisonous links).
So you’ll be able to, for example, say “slack.com can open Slack for me, but other websites have to ask”. Nice.
I hope that other browser manufacturers follow suit, especially on mobile where the web/web-launched-native-app boundary has never been fuzzier.
2020 is only three weeks old, but there has been a lot of browser news that decreases rendering engine diversity. It’s time for some good news on that front: a new rendering engine,
Flow. Below I conduct an interview with Piers Wombwell, Flow’s lead developer.
This year alone, on the negative side Mozilla announced it’s
laying off 70 people, most of whom appear to come from the browser side of things, while it turns out that Opera’s main cash cow is now providing loans in Kenya, India, and
Nigeria, and it is looking to use ‘improved credit scoring’ (from browsing data?) for its business practices.
On the positive side, the Chromium-based Edge is here, and it looks good. Still, rendering engine diversity took
a hit, as we knew it would ever since the announcement.
So let’s up the diversity a notch by welcoming a new rendering engine to the desktop space. British company Ekioh is working on a the Flow browser, which sports a completely new multi-threaded rendering engine that does not have any relation to WebKit, Gecko, or Blink.
I’m not convinced that Flow is the solution to all the world’s problems (its target platforms and use-cases alone make it unlikely to make it onto the most-used-browsers leaderboard any
time soon), but I’m really glad that my doomsaying about the death of browser diversity being a one-way street might… might… turn out
not to be true.
Time will tell. But for now, this is Good News for the Web.
I think that CSS would be greatly helped if we solemnly state that “CSS4 is here!” In this post I’ll try to convince you of my viewpoint.
I am proposing that we web developers, supported by the W3C CSS WG, start saying “CSS4 is here!” and excitedly chatter about how it will hit the market any moment now and transform
the practice of CSS.
Of course “CSS4” has no technical meaning whatsoever. All current CSS specifications have their own specific
versions ranging from 1 to 4, but CSS as a whole does not have a version, and it doesn’t need one, either.
Regardless of what we say or do, CSS 4 will not hit the market and will not transform anything. It also does not describe any technical reality.
But if you’ve got more than a little web savvy you might still be surprised to hear me say that CSS4 is here, or even
that it’s a “thing” at all. Welll… that’s because it isn’t. Not officially. Just like JavaScript’s versioning has gone all evergreen these last few years,
CSS has gone the same way, with different “modules” each making their way through the standards and implementation processes
independently. Which is great, in general, by the way – we’re seeing faster development of long-overdue features now than we have through most of the Web’s history – but it
does make it hard to keep track of what’s “current” unless you follow along watching very closely. Who’s got time for that?
When CSS2 gained prominence at around the turn of the millennium it was revolutionary, and part of the reason for that
– aside from the fact that it gave us all some features we’d wanted for a long time – was that it gave us a term to rally behind. This browser already supports it, that browser’s
getting there, this other browser supports it but has a f**ked-up box model (you all know the one I’m talking about)… we at last had an overarching term to discuss what was supported,
what was new, what was ready for people to write articles and books about. Nobody’s going to buy a book that promises to teach them “CSS3 Selectors Level 3, Fonts Level 3, Writing Modes
Level 3, and Containment Level 1”: that title’s not even going to fit on the cover. But if we wrapped up a snapshot of what’s current and called it CSS4… now that’s going to sell.
Can we show the CSS WG that there’s mileage in this idea and make it happen? Oh, I hope so. Because while the
modular approach to CSS is beautiful and elegant and progressive… I’m afraid that we can’t use it to inspire junior developers.
Also: I don’t want this joke to forever remain among the top results
when searching for CSS4…
To enable users to easily navigate to specific content in a web page, we propose adding support for specifying a text snippet in the URL. When navigating to such a URL, the browser
will find the first instance of the text snippet in the page and bring it into view.
Web standards currently specify support for scrolling to anchor elements with name attributes, as well as DOM elements with ids, when navigating to a fragment. While named anchors and elements with ids enable
scrolling to limited specific parts of web pages, not all documents make use of these elements, and not all parts of pages are addressable by named anchors or elements with ids.
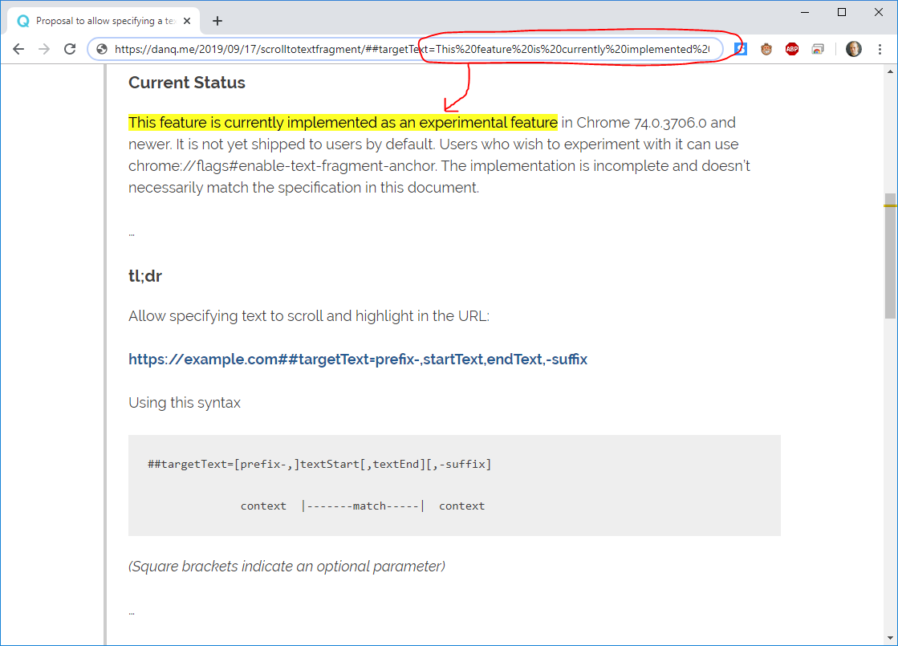
Current Status
This feature is currently implemented as an experimental feature in Chrome 74.0.3706.0 and newer. It is not yet shipped to users by default. Users who wish to experiment with it can
use chrome://flags#enable-text-fragment-anchor. The implementation is incomplete and doesn’t necessarily match the specification in this document.
…
tl;dr
Allow specifying text to scroll and highlight in the URL:
This is a feature that I’ve wished that the Web had on many, many occasions. I’m sure you’ve needed it before, too: you’ve wanted to give somebody the URL of (or link to) a particular part of a page but there’s been no appropriately-placed anchor to latch on to. Being able to select part of the text
on the page and just copy that after a ## in the address bar would be so much simpler.
Naturally, I tried this experimental feature out on this very web page; it worked pretty nicely!
Chrome’s implementation is somewhat conservative, requiring a prefix of ##targetText= (this minimises the risk of collision with other applications which store/pass data
via hashes), but it’s still pretty full-featured, with support for prefixes and suffixes to the text to-be-selected. I quite like it, but of course it needs running down the standards
track before it can be relied upon as anything other than a progressive enhancement.
I do wonder, though, whether this will be met with resistance by ad/subscription-supported content creators as a new example of the deep linking they seem to hate so much.
The plan was very simple. We would put a small banner above the video player that would only show up for IE6 users. It would read “We will be phasing out support for your browser
soon. Please upgrade to one of these more modern browsers.” Next to the text would be links to the current versions of the major browsers, including Chrome, Firefox, IE8 and
eventually, Opera. The text was intentionally vague and the timeline left completely undefined. We hoped that it was threatening enough to motivate end users to upgrade without
forcing us to commit to any actual deprecation plan. Users would have the ability to close out this warning if they wanted to ignore it or deal with it later. The code was designed
to be as subtle as possible so that it would not catch the attention of anyone monitoring our checkins. Nobody except the web development team used IE6 with any real regularity, so
we knew it was unlikely anyone would notice our banner appear in the staging environment. We even delayed having the text translated for international users so that a translator
asking for additional context could not inadvertently surface what we were doing. Next, we just needed a way to slip the code into production without anyone catching on.
…
The little-told story of how a rogue team of YouTube engineers in 2009 helped hasten IE6‘s downfall by adding a deprecation warning
to the top of the site’s homepage… without getting the (immediate) attention of the senior developers and management who’d have squashed their efforts.
Hi @avapoet, I’m the author of the JavaScript for the WorldWideWeb project, and I did read your thread on the user-agent missing and I thought I’d land the fix ;-)
The original WorldWideWeb browser that we based our work on was 0.12 with screenshots from 0.16. Both browsers supported HTTP 0.9 which didn’t send headers. Obviously unintentional
that I send the `request` user-agent, so I spent some painful hours trying to get my emulator running NeXT with a networked connection _and_ the WorldWideWeb version 1.0 – which
_did_ use HTTP 1.0 and would send a User-Agent, so I could copy it accurately into the emulator code base.
So now metafilter.com renders in the emulator, and the User Agent sent is: CERN-NextStep-WorldWideWeb.app/1.1 libwww/2.07
This comment on the MetaFilter thread, which I only just noticed, is by Remy Sharp, who was part of the team that reimplemented WorldWideWeb as part
of that hackathon (his blog posts about the experience: 1, 2,
3, 4, 5),
and acknowledges my contribution. Squee!











![Edge Canary showing an "Always allow [this website] to open links of this type..." checkbox](https://bcdn.danq.me/_q23u/2020/03/teamswithcb.png)