Around 1995 or so, a high schooler named Matt Wright decided to launch a website that shared some basic website tools that he
programmed. Many of these were dead-simple, things like contact forms, guestbooks, and web counters.
…
OMG I remember Matt’s Script Archive. I taught myself Perl with (among other things) his scripts.
I took his Counter/ImageCounter script and adapted it into my own FireCounter, which stitched together (non-animated) GIFs of digits (which I made using a filter in Corel Photo-Paint, I
think) into the kinds of edgy hit counter I was into, back in the day.
This is a recreation. It probably looks better than the original!
Later, I even added parameter handling to allow the webmaster to specify a different set of digit images, and referrer detection so that it could track different sites:
each got its own text file with its count in it! For a while, a dozen or so of my friends had my counter visible on their Geocities and Angelfire pages!
I’m sure that my script had many, if not more, of the kinds of security vulnerabilities discussed in the linked article. But man, it felt like magic at the time!
This morning I had a lovely meeting with Andreas Marakis, who’s researching the sociological impact of the Web of the 1990s on
people who experienced it first-hand.
Anyway: chatting to Andreas was great and it reminded me of quite how grateful I am to have gotten to experience a lot of these seminal technologies when they were at their newest and
most-experimental.
To celebrate the site’s 25th birthday this year, Wikipedia is encouraging/challenging
people to read one Wikipedia article a day for 25 consecutive days. I felt that I could do one better than that: not only reading an article but – where I found one that was
particularly interesting – to write a blog post or record a podcast episode for each of those days, sharing what I learned. For each entry, I’ll hit
“random article” a few times until something catches my interest, start reading, and then start writing! Everything I’ve written below came from Wikipedia… so you should check other
sources before you use it to do your homework. Happy birthday, Wikipedia!
The planet Mercury is covered with impact craters, which isn’t surprising because it has no atmosphere to slow down incoming
meteors nor significant active tectonic or erosion processes to conceal them once they’re created. In 2015 the IAU ran a competition to name four such craters: the winning entries resulted in the naming of the craters Carolan, Enheduanna, Kulthum, Rivera, and
Karsh.
The Karsh crater is about 180km wide, which is approximately comparable to… your mum.
This crater is named after Yousuf Karsh, who’s sufficiently famous that I’d actually heard of him, which was an unusual result
from hitting “random article” on Wikipedia.
But in case you don’t know who Yousaf Karsh is – or if, like me, you just wanted to learn more about him – then you’re in luck!
Selfies used to be a lot harder in 1958.
Yousuf Karsh was an Canadian-Armenian photographer who took principally portrait photographs, some of which you’ve almost-certainly seen already. He photographed a huge number of famous
and significant individuals of the 20th century. Like this one:
“Oh yes!” No wait, that’s the other Churchill’s catchphrase.
That photo, taken in 1941, is titled The Roaring Lion, and it’s got a story to it.
Winston Churchill posed for his photograph on his way out from delivering the “some chicken! some neck!” speech to the Canadian parliament (you can see his
notes from the speech tucked into his jacket pocket). He had his trademark cigar in his mouth, but Karsh wanted it gone. He asked Churchill to remove it, but Churchill refused, and
Karsh went ahead to take the photograph anyway. But then at the last second, Karsh said “Forgive me, sir” and snatched the cigar directly out of the Prime Minister’s mouth.
“By the time I got back to the camera, he looked so belligerent, he could have devoured me,” said Karsh later, of the expression on Churchill’s face. But it’s that expression that he
captured with the camera, and that would go on to be described by the USC as a “defiant and scowling portrait
[which] became an instant icon of Britain’s stand against fascism.” Absolutely iconic.
Churchill himself said, after the picture was taken, that “you can even make a roaring lion stand still to be photographed.” Hence the portrait’s name.
Or how about this picture of the Marx Brothers in 1948:
Karsh became known for his use of harsh lighting to pick out the fine details of his subjects’ faces, which I think is especially clear in this picture.
Or how about this fantastic photo of the then Princess Elizabeth, aged 21 or 22, before her accession as Queen Elizabeth II:
“So long as Daddy manages to die before he has any sons, I’mma get me so much Empire Commonwealth.”
Here’s some things I didn’t know about Yousuf Karsh, though:
Being born to ethnic Armenians in the Ottoman Empire could have been a death sentence in itself for young Yousuf. Ottoman
and later Turkish Nationalist authorities and paramilitaries deported, confined, or murdered hundreds of thousands and quite possibly over a million Armenians, who they saw as a threat
to their national identity (among other candidate causes).
Karsh and his family travelled with a Kurdish caravan to Aleppo in Syria in 1922, and a year later his parents took advantage of a
humanitarian scheme to transport displaced Armenians to live with relatives in Canada: the then 15-year-old who “spoke little French, and less English” and “had no money and little
schooling” moved half way around the world to live with his uncle.
Yousuf’s uncle was a photographer and taught him the essentials of early-20th-century photography technology and techniques, before sending him to apprentice in Boston under John H.
Garo, a fellow Armenian whose studio hosted the still-running Boston Camera Club. He worked in the USA for a time then
returned to Canada, opening his own studio in 1932. When his brother Malak was able to join him in Canada in 1937, Yousuf helped
Malak break into a career in photography too: a career that would probably have been better-known were it not for being in the shadow of his older brother!
I don’t know whether he’d care about having a crater named after him or not. But he’d probably have been more proud of the legacy that lives on in the Karsh Award, given every alternate
year by the City of Ottawa for outstanding artistic work in a photo-based medium.
To celebrate the site’s 25th birthday this year, Wikipedia is encouraging/challenging
people to read one Wikipedia article a day for 25 consecutive days. I felt that I could do one better than that: not only reading an article but – where I found one that was
particularly interesting – to write a blog post or record a podcast episode for each of those days, sharing what I learned. For each entry, I’ll hit
“random article” a few times until something catches my interest, start reading, and then start writing! Everything I’ve written below came from Wikipedia… so you should check other
sources before you use it to do your homework. Happy birthday, Wikipedia!
One of the things I’ve discovered over my past few days of hitting “Random Article” on Wikipedia is that sometimes you get something that’s worth writing about. But more often you get
something worth reading but not writing about. But more often still you get something that doesn’t interest you at all, and you just need to click “Random Article” again.
And that latter category is the one I thought I was in when I discovered Marcus Koh, who’s a Singaporean yo-yo enthusiast who came first in the 1A division at the World Yo-Yo Contest in
2011. The page almost felt like a stub… but then I started clicking and found myself learning much more about yo-yos than I ever thought possible.
Like… I knew that the yo-yo was an old toy, but I had no idea how old.
This 1791 image allegedly from a French fashion journal. The French usually called the toy a
emigrette at the time, but the 1888 republication of this image in Le Costume Historique called it Joujou de Normandie, so who knows.
Obviously there’s a lot of pictures from around the end of the eighteenth century, which is when they became popular in Europe. In the English-speaking world at that point they were
known as “bandalores”, which I think is a nicer name than “yo-yo”, frankly.
But their influence was clearly felt much further away and much longer ago than this.
I mean, here’s a 1770 watercolor from Northern India that clearly depicts something that, despite being held in two hands, is definitely something-like-a-yo-yo:
But we can go further.
If you lived in Greece in around the 5th century BCE and were serving wine to your guests, the popular drinking vessel to use was a kylix. Kylikes were pottery cups basically the shape of modern wine glasses but much more squat, having a wide bowl atop a pedestal that
tapered outwards. Unlike modern wine glasses, though, they had handles, and these handles were used to play a game called kottabos: once you’d finished your wine, you’d use a handle to “flick” the sediment from your wine (I guess fining/clarification agents weren’t a thing yet?) at a target in order to win a cake or something.
Sounds pretty gross for whoever had to clean up afterwards, if you ask me.
Anyway: oftentimes the inner bowl of a kylix would be decorated. Depending on the kind of party you were throwing you might have a nautical theme where everybody finds a different kind
of boat at the bottom of their cup when they drain it… or for a more raucous party perhaps you’d get out the cups where the faces at the bottom all had genitals hidden in them. That
way, somebody gets surprised to find that at the end of a drinking session they have a penis in their face (I’ve certainly had parties like that before, if you know what I mean):
I guess that these were the Ancient Greek equivalent of shot glasses with swear words etched into them?
What I’m saying is… the Ancient Greeks liked to play drinking games, and they liked drinking vessels with pictures on. Which makes you look at the “Greek culture” of fraternity houses
in a whole new light.
But the pictures weren’t always either (a) boats or (b) crude, of course. They could be anything. Here’s an example of the bottom of a kylix that was probably used as a drinking vessel
in or near Athens around 2,500 years ago:
What the actual fuck? That boy’s clearly playing with a yo-yo in a picture painted before the Parthenon was built!
It’s not just novelty earthenware that tells us that the Ancient Greeks had the yo-yo, by the way. We’ve found actual examples of them made from bronze or terracotta,
although archaeologists suspect that there were many more wooden variants that have been lost to time.
I guess it’s true that it’s a toy that just keeps making a comeback. Every few centuries it gets reinvented and improved, I guess! “Modern” yo-yos got their relaunch in
the 1920s, when Pedro Flores (a Filipino businessman whose time in his birth country spanned a
previous story) brought to the USA a toy that had been popular in his homeland but seemed to be mostly-unknown in the States. The name apparently derives from a Tagalog word that means “come-come” or “come-go” or something similar. He produced both traditional “tied-on” yo-yos and
“slip-string” varieties that allowed the toy to “sleep” – to spin-freely at the end of its string – which unlocked a diversity of new tricks.
From here on, the yo-yo saw surges in popularity every 20 to 40 years. The full article’s worth a read because unless you’re a complete yo-yo nut I can guarantee there are things in
there that you didn’t know.
I was also very interested in the article about the “Eskimo yo-yo”, which I’d love to see somebody operate! It’s basically a
bola of two weights attached to a stick using strings of two different lengths, and the trick is to get them spinning in opposite directions but using only one hand. That
sounds amazing!
To celebrate the site’s 25th birthday this year, Wikipedia is encouraging/challenging
people to read one Wikipedia article a day for 25 consecutive days. I felt that I could do one better than that: not only reading an article but – where I found one that was
particularly interesting – to write a blog post or record a podcast episode for each of those days, sharing what I learned. For each entry, I’ll hit
“random article” a few times until something catches my interest, start reading, and then start writing! Everything I’ve written below came from Wikipedia… so you should check other
sources before you use it to do your homework. Happy birthday, Wikipedia!
Then back to Spain at the signing of the 1763 Treaty of Paris, where, when Britain was arguing which captured
territories it should be allowed to keep, everybody forgot about it and so it fell into the default bucket of “back to its previous controller”: it seems that Spain hadn’t even
noticed that Manilla had been captured!
Then, after the Mexican War of Independence… still under Spain, but now directly under the
Spanish crown and managed from Madrid.
The Flag of the United States of America is lowered while the Flag of the Philippines is raised during the Independence Day ceremonies on July 4, 1946.
As you might expect if you know anything about colonialism, there are absolutely horrible stories that could be told about any of those periods of history. So when I landed on the page
Governor-General of the Philippines, I decided that it might be cheerier to pick out a person from it.
And so I picked what I believe to be the person whose term as Governor-General of the Philippines was shortest: in post for just 16 days in August 1898: Wesley
Merritt.
Gen. Wesley Merritt, circa 1865.
Wesley was a cavalryman in the American Civil War during which, in 1863, he managed to leapfrog three ranks by getting promoted from Captain right up to Brigadier General. After the
Civil War he was posted to the Texan frontier where he commanded a cavalry regiment in the American Indian Wars. His success in… umm… “freeing up land” for American settlers (it turns out this post can’t escape from the ugliness of imperialism)… lead him to a new
role in using his troops to police the civilians rushing to “claim” land formerly occupied by native Americans.
But it’s right at the end of the 19th century that his story intersects with today’s random article.
“Uncle Sam’s Craving: Saving the island so it won’t get lost.” says this Spanish propaganda cartoon.
As the 19th century wore on, the world-spanning Spanish Empire came under serious threat. The Napoleonic Wars had cut Spain
off from its colonies, and one by one they lost control of Mexico, Peru, Colombia, Chile, Argentina,
and others (often with thanks to quiet support from Britain). But Spain had managed to
keep hold of Cuba and the Philippines, despite growing unrest and uprisings, which were often brutally suppressed.
At the time, the US was working to establish itself as a modern naval power, building new steel warships to compete with European powers and Brazil, and making plans for what would
eventually become the Panama Canal, and so this was a perfect opportunity to show off their armoured cruiser the USS
Maine.
Starboard bow view of USS Maine, shortly before her deployment to Cuba. Fun fact: the last surviving officer who was aboard on the day it sank, Wat Tyler Cluverius Jr., would go on to serve as an engineering officer on the new USS Maine, a pre-dreadnaught battleship that would still be in service at the time of the First World War
(although she was only used as a training ship because her coal efficiency was so terrible that it was no-longer sensible to have her cross an ocean).
The Maine got sent to Havana as a show of force and to protect American interests in Cuba, where, a couple of weeks later, she… blew up.
Probably what happened was that the bituminous coal stored in her bunkers was leaking methane out, which spontaneously ignited, starting a fire that ignited the ship’s powder store. But some, including Theodore Roosevelt (who was then assistant navy secretary and on his way to becoming vice-president) and much of the popular press, claimed that the ship must have been struck by a Spanish mine or
torpedo.
Neither the Spanish nor American official reports had been published before the newspapers were claiming that the Maine had been sunk deliberately. Fun fact: the inscription
on the monument to the victims that stands in Havana claims it was deliberate…
but by the Americans as a false-flag operation to justify a declaration of war against Spain! This interpretation was added by the communist government in 1961.
The next month, after Congress had had a chance to discuss the matter (do you remember when the US Congress used to have to be involved in the US declaring war on another country?), the
US declared war on Spain and began actively attacking her fleets and colonies in the Caribbean and the Pacific.
The US fleet steamed into Manilla Bay for what might be the most one-sided naval battle ever. The Spanish fleet at
Manilla would have been severely outmatched even were it not for the fact that the second-lead ship was unpowered, the shore batteries’ range was insufficient to be involved, and the
mines had been placed suboptimally. Only a single American sailor lost his life in the battle, and it was apparently as a result of a heart attack.
Battle of Manila Bay by James Gale Tyler (1898).
Okay, we’re at last up to Wesley Merritt‘s bit. Merritt was placed in command of the ground forces that were tasked with capturing Manilla. They sailed out of San Francisco, landed in
the Philippines, and prepared to attack the city.
Merritt and Admiral Dewey made a point not to coordinate with Emilio Aguinaldo y Famy, the leader of the Filipino resistance against the Spanish, who by this point had already taken control of
most of the Philippines and besieged Manilla, cutting off its water supply and beginning negotiations with the local Spanish leaders. It seems that Americans feared that if the
revolutionaries captured the city it would result in significant bloodshed as a result of violent looting and the murder of those who were seen to have collaborated with the Spanish,
and so they came up with an alternative plan: the American expeditionary force would attack and capture the city first!
Working through the Belgian consul to Manilla Édouard André, Merritt negotiated with the Spanish
Governor-General Fermín Jáudenes to arrange a “mock” battle. The ships in the bay would fire upon a fort that they knew was only used for storage and against defensive walls that they knew they were not capable of breaching,
and Spanish troops would be ordered to retreat as Merritt’s soldiers advanced. Then, Merritt would demand that the Spanish surrender the city, and they would comply, turning it over to
the American forces.
This would minimise casualties while allowing the Spanish Governor-General to avoid the shame of being seen to have lost the city to the revolutionaries (it being far more
politically-acceptable to lose to the might of the American invaders). Meanwhile, Aguinaldo’s troops initially saw the battle as genuine, which led to some casualties as Filipino
fighters advanced under fire; they joined the victims of other misunderstandings during the mock battle.
A drawing from Harper’s Pictorial History of the War with Spain. There’s a whole lot of pictures of flags getting rotated in this blog post!
Needless to say, the Filipinos deeply resented being told to stay out of the capital city that, given time, they might well have taken for themselves by force, had their efforts not
been leapfrogged by the USA. Ultimately this lead to a guerilla warfare campaign against the USA by Philippine
nationalists, which in turn contributed to growing concern in US political circles that America was becoming exactly the kind of imperialist power that it had opposed, at least on
paper, since its founding.
Anyway: on 13 August 1898 Wesley Merritt became the de facto Governor-General of the Philippines and the first American to hold that position. Two weeks later Major General Elwell Stephen Otis turned up and relieved him of the position, making Merritt the shortest ever Governor-General
of the Philippines.
Major General Wesley Merritt from Illustrated Roster of California Volunteer Soliders in the War with Spain (1898).
Merritt retired the next year and lived ten more years.
Anyway: that’s enough of today’s history lesson courtesy of a random Wikipedia page. I wonder what I’ll learn tomorrow! (If it’s as-interesting, I’ll let you know!)
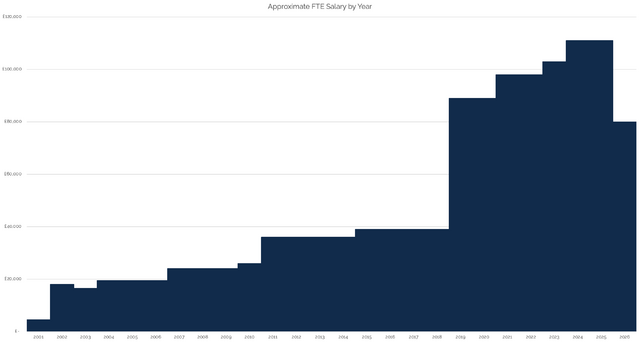
Jeremy Keith posted his salary history last week. I absolutely agree with him that employers exploit
the information gap created by opaque salary advertisement, and I think that our industry of software engineering is especially troublesome for this.
So I’m joining him (and others) in choosing to share my salary history. I’ve set up a new page for that purpose, but here’s the summary of its
initial state:
Understand
A few understandings and caveats:
For most of my career I’ve described myself as a “Full-Stack Web Applications Developer”, but I’ve worked outside of every one of those words and my job titles have often been more
like “CMS Developer” or “Senior Engineer (Security)”.
My specialisms and “hot areas” are security engineering, web standards, performance, and accessibility.
When I worked multiple roles in a year, I’ve tried to capture that, but there’ll be some fuzziness around the edges.
The salaries are rounded slightly to make nice readable numbers.
I’ve not always worked full-time; all salaries are translated into “full-time equivalent”1.
I’ve only included jobs that fit into my software engineering career2.
If the table below looks out-of-date then I’ve probably just forgotten to update it. Let me know!
Ad-hoc and hard to estimate.
Alongside full-time study.
What does that look like?
I drew a graph, but I don’t like it. Mostly because I don’t see my salary as a “goal” to aim for or some kind of “score”.
It’s gone up; it’s gone down; but I’ve always been more-motivated by what I’m working on, with whom, and for what purpose than I have been on how much I get paid for it3.
But if you want to see:
I’m not sure to what degree my career looks typical or not. But I guess I also don’t care! My motivations are probably different than most (a little-more idealistic, a little-less
capitalistic), I’d guess.
Footnotes
1 i.e. what I’d have earned if I had worked full-time
2 That summer back in college that I worked in a factory building striplight fittings
doesn’t appear, for example!
3 Pro-tip if you’re looking at my CV and pitching me an opportunity:
mention what you expect to pay, sure, but if you’re trying to win me over then tell me about the problems I’ll be solving and how that’ll make the world a better
place. That’s how you motivate me to accept your offer!
Second: the language “committed suicide” is no longer appropriate. Princess Irenedied by suicide. “Committed” is the language of crime. For example,
one does not commit a heart attack.
…
You clearly feel strongly enough about this point to have committed it to writing.
(It’s obviously a cause that you’re committed to.)
I’m being sarcastic, of course, but there’s a point. While (like most mental health services) I’m not a fan of describing the act of suicide as “committing” suicide today, for exactly
the reasons you describe, it might be appropriate for a historical case.
That’s all I meant to say in a comment… but then I ended up going down a rabbithole.
Let’s sidestep into an example: I said “John William Gott committed blasphemy in 1921” that would be fair. His actions would not be considered criminal today: he was initially
arrested for selling pamphlets containing information on birth control but prosecutors tacked on a blasphemy charge because they figured they could get it to stick too, based on the
ways his literature was presented. But legally-speaking, Gott committed a crime; a crime that doesn’t exist today.
It’s not a coincidence I’ve lumped jumped from suicide to blasphemy: both were formerly criminalised in Britain and her empire (among many other places) as a direct result of Christian
religious tradition: you can probably blame Thomas Aquinas!
Language about the criminality of past offences gets very complicated, very quickly. Some contemporary values seem to be considered so fundamental that it feels wrong to
describe historical convictions as criminal. In some of these cases, we see pardons issued or other admissions of fault by the state. Take for example in recent years the payment of
compensation to former military personnel who were dishonourably discharged on account of their sexuality. But I’m not aware of anything like that happening related to past convictions
of suicide (or, indeed, blasphemy).
With that grounding: let’s take a deeper dive into Irene Duleep Singh, to decide whether or not her suicide would have been considered criminal at the time (it was certainly considered
shameful and taboo, even within societies that would not have considered it illegal, but that’s not what I’m interested in right now). Irene died by suicide in the Principality f Monaco
in 1926. At that time, Monaco was a protectorate of France with less independence than it is today, and for the most part its legal system seems to have paralleled that in France. I
can’t find a specific provision for suicide in Monaco, so it would probably not have been illegal (suicide was illegal under the Ancien Régime but was
effectively decriminalised by its omission from the Napoleonic Penal Codes). So: no crime.
Buuuut… Irene could also be considered a citizen of Britain, or of India, or of British India. Suicide was illegal in the UK prior to 1961 and in India
until 2024 (wait, what? yeah, really… well… kinda; it’s complicated, especially after 2018). So in her capacity as a citizen or subject of the British Empire, her suicide was
criminal.
Both John William Gott and Irene Duleep Singh may well both have committed crimes that would not be considered crimes today. In both cases, their crimes were things that, in my opinion,
should never have been criminalised in the first place. But that doesn’t make the historical fact any less-true.
And that’s why I picked up on this one line for my comment.
I absolutely agree that it’s inappropriate and unhelpful to talk about somebody have “committed suicide” today. The language creates a barrier to help and support, which is what should
be offered to people experiencing suicidal thoughts! But I don’t see the harm in using it when discussing a historical case from a century ago, at a time at which suicide was seen very
differently.
So long as it’s appropriately contextualised for the audience, it seems to me to be harmless. By which I mean to say: not worthy of being called-out by your one-liner… and even-less
worthy of my having gone down this long and complicated rabbithole which, somehow, has involved translating old French legislation, digging through the history of Monaco, and learning
about the courts of the British Raj.
I guess what I mean to say is that if your intention was to nerdsnipe me with this line… then well played, Sundeep, well played.
Mike Cook wrote a provocative blog post this weekend; an
anti-preservationist argument for video games. The essence of his arguments seem to boil down to:
Emphasising creation over preservation is liberating, as demonstrated by the imagination in the livecoding community.
Archiving without intensive curation is building an emotional or intellectual safety net you never expect to be used.
Digital preservation is a lossy process: effort spent on accurately preserving some media is at the expense of other media, whose lossy preservation paints in inaccurate picture of
what is lost.
Recreation, rather than strict preservation, ensures the continuity of the most culturally-important parts of games
Art is important for culture, and it’s important for nostalgia, but it’s hard to draw the line between where one purpose ends and the other begins.
He concludes to say:
60 games are released on Steam every day.
There are 294 game jams active on Steam as I write this.
Preserve nothing. Make more.
To make is to preserve.
Let games die.
Digital preservationism
Philosophically-speaking, there’s no doubt that I am a digital preservationist. I argue against unnecessary URI changes. I donate to
The Internet Archive. Back at the Bodleian, I used to carve out free time from project work to spend time making sure the University’s “older”
exhibition websites could be made to survive1. My approach to running out of hard drive space is to buy more hard drives. Even my blog retains
content going back into the last millennium2!
My reimplementation of Pong had several distinct differences from the original… but to a layperson – for whom Pong are the target audience! – those differences are
irrelevant. To what level fidelity matters depends on many factors, and the biggest problem is that we don’t know what those factors are until it’s time to retrieve these historical
media.
This screenshot isn’t from the original site but from my homage to it. More on that later.
This makes it seem like I’m very much on the side of recreation, rather than preservation, but that’s not the case. In both of these projects I started by disassembling the
original works.
That I chose to make them accessible to a modern audience by reimplementation rather than by emulation was an artistic choice. I opted for lower fidelity by making something
mildly-transformative. I chose to appeal to the widest possible audience, at the expense of presenting an experience that was totally in-keeping with the original.
But I couldn’t have done that without access to the originals. Had I recreated Pong from memory rather than from re-playing it, I’d have doubtless introduced
inconsistencies that would have “felt wrong” to people whose memories of the game, while fundamentally accurate, differed from mine. Had I recreated Axe Feather without
first coming up with a mechanism to extract and reformat the video clips in the original I’d have failed to tap into the specific nostalgia of some of its users, which was tied to the
specific actor who performed in it3.
So I guess it’s important to me that somebody is preserving these things. So that I can use them to create new things. I stand for preservation for culture’s
sake, so that I personally can enjoy the benefits for nostalgia’s sake.
For all that I feel like I’m making the case for “preserve everything; work out what’s important later”, Mike’s argument gives me an uncomfortable cognitive dissonance. Because
I’ve also come to discover a joy in the ephemeral, too.
I don’t know who’ll preserve ARCC, with its permanently-capped 500-playerbase limit, but I’m happy that I’ll probably always hold
the highscore on driving/racing minigame M1.
Increasingly, I’m okay with just taking the experience of something with me. It bothers me that my memory is fallible and that I can’t necessarily recreate a digital
experience whose technology has been lost to time, but I am, for the most part, okay with it.
Some of the best gaming experiences I’ve ever had are impossible to “capture” in an archive anyway. They were conversations over the tabletop roleplaying table, or moments of tension
resulting from a videogame’s emergent gameplay, or random occurrences unlikely to be replicated. Those get preserved in my memory alone, retold as stories with
gradually-decreasing accuracy as new memories take their place.
That said…
Who decides what games get preserved?
I feel like the decision about what to preserve and how should be in the hands of the audience of a piece of art, not its creators. If a videogame (or film, or book, or
whatever) is culturally-significant enough to warrant a high-fidelity preservation, it ought to be ultimately up to the members of that culture to make that decision!
Transport Tycoon Deluxe met that bar, and it’s possible to play both faithful recreations or modern reimplementations (the latter having excellent new features)
courtesy of the OpenTTD project4.
But modern videogames are, perhaps, getting harder to preserve. Always-online features, insidious DRM, digital distribution, live updates, and games-as-a-service streaming
all shift the balance of power more-firmly into the hands of publishers5
rather than players. It’s already hard to play a randomly-selected thirty-year-old videogame today; I reckon it’ll be almost impossible to do the same thirty years
hence.
Saying “let games die” feels a bit like giving up to that inevitability. Like saying to the slimier publishers “it’s okay, we didn’t care about keeping that anyway” when they shut down
servers or remotely kill games. I know that’s not what Mike’s saying, but it could be wilfully misinterpreted that way.
Anyway: I don’t have a nice conclusion to any of this. Just a lot of mixed-up feelings.
2 Even where those writings don’t really represent me well any more.
3 It turns out that, for a significant number of folks who are mostly younger-than-me,
this advertisement represented a kind of sexual awakening, based on some of the comments and emails I’ve received about it!
4 Which I’ve also donated too. Turns out I’m happy to invest in both pure
preservation and in spiritual-successor reimplementation!
5 Supposing that Sonic Rumble Party somehow wasn’t a catastrophic
pay-to-win nightmare and somehow was deemed culturally-significant… how would you go about archiving it? Without Sega/Sonic Team’s consent, you’d be totally out of luck.
Many years ago, someone tried to get me into cryptocurrencies. “They’re the future of money!” they said. I replied saying that I’d rather wait until they were more useful, less
volatile, easier to use, and utterly reliable.
“You don’t want to get left behind, do you?” They countered.
That struck me as a bizarre sentiment. What is there to be left behind from? If BitCoin (or whatever) is going to liberate us all from economic drudgery, what’s the point
of “getting in early”? It’ll still be there tomorrow and I can join the journey whenever it is sensible for me.
…
100%. If I “get in early” on something, it’s because that thing interests me, not because I’m betting on its future. With a hundred new ideas a day and only one of them “making it”,
it’s a fools’ game to try to jump on board every bandwagon that comes along.
With cryptocurrencies, though, I’m fortunate enough to have an even better comeback at the cryptobros that try to shill me whatever made-up currency they’re “investing” in
today: I’ve already done better than they ever will, at them.
When Bitcoin first appeared, I took a technical interest in it. I genuinely never anticipated it’d take off (I made the same incorrect
guess with MP3s, too!), but I thought it was a fun concept to play about with. The only Bitcoins I ever paid for must’ve been worth an average of 50p each, or so.
I sold my entire wallet of Bitcoins when they hit around £750 each. I know a tulip economy when I see one, I thought. Plus: I was
no longer interested in blockchains now I was seeing how they were actually being used: my interest had been entirely in the technology and its applications, not in the actual idea of a
currency!
Sure, I kick myself ocassionally, given that I later saw the value rise to tens of thousands of pounds each. But hey, I was never in it for the money anyway.
So yeah, I tell cryptobros; I already made a 1500% ROI on cryptocurrency. And no, I’m not buying any cryptocurrencies any more. Whatever they think “getting in early” was, they’re
wrong, because I was there years ahead of them and I wasn’t even doing it to “get in early”; I did it because it was interesting. And honestly, isn’t that a better story to be able to
tell?
…
I feel the same way about the current crop of AI tools. I’ve tried a bunch of them. Some are good. Most are a bit shit. Few are useful to me as they are now.
…
If this tech is as amazing as you say it is, I’ll be able to pick it up and become productive on a timescale of my choosing not yours.
…
Yup, that’s the attitude I’m taking.
I play with new AI technologies, sometimes. I don’t do it because I’m afraid of being left behind because – as you say – if a technology is transformative, we’ll all get to catch up
eventually.
Do you think that people who had smartphones first are benefitting today because they “got in early” on something that later became mainstream?
Of course they’re not. Their experience is eventually exactly the same as everybody else’s, just like it was for everybody who “got in early” on hype trains whose final station came
early, like Compuserve GO-words, WAP, Beenz.com, WebTV, the CueCat, m-Commerce, HD-DVD, the JooJoo, or Google+.
A lot of attention was gained by Derek Sivers‘ post Offline 23 hours a day, the other week. I was particularly
impressed by the rebuttal by Rishi Dass:
…
Anyway, the reasoning behind this idea of disconnecting seems to be that they equate
being productive with having no internet or phone service. This implies that the tool (internet or the phone) is the problem. But is that entirely true?
They further argue that disconnection helps them create a vacuum through media silence, allowing their thoughts to expand and fill the space. While it’s understandable that you can
concentrate better when your attention is focused on one thing, there’s no reason you can’t stay online and do the work. If you’re able to work comfortably in a
library, you can do this.
…
Obviously, Derek’s approach is valid. It sounds like he’s found what works for him in terms of managing his time, life, mental energy, and the like, and that’s great! I’d be lying if I
said that I didn’t envy him at least a little: don’t we all enjoy “unplugging” sometimes?
I think Derek’s post is so appealing because it touches our nostalgia of a simpler, less-always-online time.
For a while I thought that this would be a sensation unique to folks who, like me, had their first experiences of the Internet in a very intermittent and deliberate way. In the 1990s, I
used to go on the Internet: a premeditated act that required being somewhere with a landline and the appropriate hardware, requiring that nobody was using or
intending to use the phone, booting up a computer, dialling-up to the local Internet Service Provider, and then going about what I wanted to do. At that time, it was uncommon to use the
‘net for trivial things like checking the weather or what’s on at the cinema, because picking up the local newspaper would probably be a faster way to achieve that!
Similarly, it wasn’t so-useful as a procrastination activity, because picking up a book or going for a walk was more accessible and reliable.
But this isn’t a generational thing, or at least not entirely. Gen Zs are seeing the joy in retro tech from before they were
born, which is something I’ve witnessed myself: I’m part of a couple of online communities that do quite a bit of retro-Web and other retro-tech stuff, and I’ve
been amazed at how young the demographics can skew in some of these groups! Like: there are people who were born after Facebook was founded who yearn to
recreate the kind of dial-up experience that I had, before their parents met.
(Obviously, I think this is great; I think there are great lessons to be learned from the more open, decentralised, distributed, transparent, and exploratory Internet of times gone by.
It just… initially surprised me to find so many younger folks showing such an interest in it, too.)
I still think this is nostalgia, though. Here’s why: none of us are born with unfettered and unfiltered access to the Internet. Unless they have the most hands-off parents
possible, even a child born today won’t be “always online” for the first decade or more of their life. And being a child, for most folks, is a time of safety and
wonderment: where there are other people to attend to our needs and filter our information intake and answer our questions in a protected environment. Growing up, we all have to learn
to do those things for ourselves. And in the information-saturated attention economy of the modern world, that shit is exhausting.
You don’t need to be reminiscing about dial-up to fantasise about a slower time, when pub quizzes couldn’t be cheated by a shithead in the corner unless you catch them in the act and
when your pocket computer wouldn’t beep for attention every 30 seconds because a half-remembered friend posted a holiday snap. Not having the extra cognitive load all the time is
liberating!
No wonder “going offline” seems like a luxury to people, and why Derek’s extreme approach is so intriguing! But it’s just the same as that curated holiday snap that your
friend-of-a-friend just posted to Instagram: it’s a snapshot into the best bits of somebody else’s life. It’s not reality. It’s your imagination, your
fantasy, projected onto somebody else’s solution. “This works for them,” you say to yourself, “It must work for me, too!”
Maybe it would! And I hope that a few people feel empowered by Derek’s post to fulfil their dream and go live in the woods. Good for them!
But Rishi’s rebuttal brings us a sense of balance. For most people, it’s not necessary to go live in the woods to “go offline”. If you really want to,
just… go offline. The power’s in your hands.
if you don’t want to be distracted by social media and games, close those accounts and take those apps off your device
if you don’t want to be interrupted by notifications, switch them off and check your inputs on your own schedule
if you don’t want to be online at all, set airplane mode or disconnect from the WiFi, and narrow your focus onto that book, board game, film, conversation, or daydream
if you don’t trust yourself not to be tempted to backslide… well, that’s a bigger problem of self-control that you need to work on, but in the meantime, try and experiment: leave
your device behind and take a walk!
I get wanting to disconnect. I have my own controls in place, too, and they’re great for my mental health. But my approach, Derek’s approach, anybody’s
approach… don’t have to be your approach.
Start the journey by working out what parts of the always-online world aren’t serving you. What things are more of a psychological drain than a boost? What’s bad for your mental
wellbeing on the whole (not just in the moment)? What habits would you like to kick? What excuses are you using to keep them?
Then, work out what you can do about them. Seek assistance if you need it; you might not have all the solutions. But beware the seductive approach of taking what works
for somebody else and trying to fit yourself to their mould.
Sure: maybe you need to go live in the woods with Derek. But make that choice because it solves your problems, not because it solves his!
It’s February, which means that (here in the UK) it’s LGBT+ History Month.1
And it feels like this year, it’s more important than ever to remember our country’s queer history.
By the time Western European countries traditionally seen as ‘socially conservative’ like Ireland and Switzerland are outranking the UK in LGBT+ rights rankings… it’s a clue that
something’s gone wrong, right?
This stuff affects everybody. When you build a community that is a safe space for queer people, and trans
people,6 everybody benefits7. So even if you’re
somehow not compelled by the argument that we should treat everybody fairly and with compassion, you should at least accept that it helps you, too,
when we do.
In many ways, queer rights in the UK have been a success story in recent decades. Within my lifetime, we’ve seen the harmonisation of the age of consent (2001), civil partnerships
(2004), the Gender Recognition Act (2004), the Equality Act (2010), same-sex marriage (2013; I was genuinely surprised this bill passed!) and the mass-pardoning of people previously
convicted under discriminatory sex act laws (2017). These are enormous and important steps and it’s little wonder that the UK topped ILGA Europe’s scoreboard for a while there.
But as recent developments have shown: we can’t rest on our laurels. There’s more to do. History shows us what’s possible; it’s up to us to decide whether we keep moving forward or let
it unravel.
So this LGBT+ History Month, don’t just remember the past: pay attention to the present, and push back where it’s slipping.
3 Georgia’s backslide is superficially similar to Hungary’s except that one can’t help but
feel the influence of partial occupier Russia – a frequent bottom-scorer in ILGA’s list – in that.
4 By the way: I just looked back at my own blog posts tagged
‘sexuality’, and man, that shit is on fire! Some fun things there if you’re new to my blog and just catching-up, if I may toot my own horn a little! (Is “toots own horn” a
protected identity? ‘Cos I do it a lot.)
One of my goals was to uncover the origin of the ubiquitous Winking Chef. We’ve all seen him – the chubby mustachioed man wearing a chef’s hat and often making a gesture of approval
with his hand. I dug around as much as I could – searching old magazines and websites looking for the origin of the image. Of course generic chef images go way back in print
advertising but I was looking for one image in particular, the one I grew up with on my pizza boxes in New Jersey. Who was this guy? Was the image based on a real person? What’s the
deal????
…
There are few people in this world who are more-obsessed with pizza than I, but Scott’s gotta be one of them. Since discovering this blog post of his I now really want to
go on one of his pizza-themed walking tours of New York City. But you might have guessed that.
Anyway: Scott – who has a collection of pizza boxes, by the way (in case you needed evidence that he’s even more pizza-fixated than me) – noticed the “winking chef” image,
traced its origin, and would love to tell you about it. An enjoyable little read.
Way back in the day, websites sometimes had banners or buttons (often 88×31 pixels, for complicated historical reasons) to indicate what screen
resolution would be the optimal way to view the site. Just occasionally, you still see these today.
Folks who were ahead of the curve on what we’d now call “responsive design” would sometimes proudly show off that you could use any resolution, in the same way as they’d
proudly state that you could use any browser1!
I saw a “best viewed at any size” 88×31 button recently, and it got me thinking: could we have a dynamic button that always
shows the user’s current resolution as the “best” resolution. So it’s like a “best viewed at any size” button… except even more because it says “whatever
resolution you’re at… that’s perfect; nice one!”
Anyway, I’ve made a website: best-resolution.danq.dev. If you want a “Looks best at [whatever my visitor’s screen
resolution is]” button, you can get one there.
1 I was usually in the camp that felt that you ought to be able to access my site with any
browser, at any resolution and colour depth, and get an acceptable and satisfactory experience. I guess I still am.
2 If you’re reading this via RSS or have JavaScript disabled then you’ll probably see an
“any size” button, but if you view it on the original page with JavaScript enabled then you should see your current browser inner width and height shown on the button.
Solving problems with LLMs is like solving front-end problems with NPM: the “solution” comes through installing more and more things — adding more and more context, i.e. more and
more packages.
LLM: Problem? Add more context.
NPM: Problem? There’s a package for that.
…
As I’m typing this, I’m thinking of that image of the evolution of the Raptor engine, where it evolved in simplicity:
This stands in contrast to my working with LLMs, which often wants more and more context from me to get to a generative solution:
…
Jim Nielsen speaks to my experience, here. Because a programming LLM is simply taking inputs (all of your code, plus your prompt), transforming it through statistical analysis, and then
producing an output (replacement code), it struggles with refactoring for simplicity unless very-carefully controlled. “Vibe coding” is very much an exercise in adding hacks upon hacks…
like the increasingly-ludicrous epicycles introduced by proponents of geocentrism in its final centuries before the heliocentric model became fully accepted.
This mess used to be how many perfectly smart people imagined the movements of the planets. When observations proved it couldn’t be right, they’d just add more
complexity to catch the edge cases.
I don’t think that AIs are useless as a coding tool, and I’ve successfully used them to good effect on
several occasions. I’ve even tried “vibe coding”, about which I fully agree with Steve Krouse‘s observation that
“vibe code is legacy code”. Being able to knock out something temporary, throwaway, experimental, or for personal use only… while I work on
something else… is pretty liberating.
For example: I couldn’t remember my Google Sheets API and didn’t want to re-learn it from the sprawling documentation site, but wanted a quick personal tool to manipulate such a sheet
from a remote system. I was able to have an AI knock up what I needed while I cooked dinner for the kids, paying only enough attention to check-in on its work. Is it accessible? Is it
secure? Is it performant? Is it maintainable? I can’t answer any of those questions, and so as a professional software engineer I have to reasonably assume the answer to
all of them is “no”. But its only user is me, it does what I needed it to do, and I didn’t have to shift my focus from supervising children and a pan in order to throw it together!
Anyway: Jim hits the nail on the head here, as he so often does.




.jpg)








_starboard_bow_view,_1898_(26510673494).jpg)
.jpg)
.jpg)

.JPG)