Yesterday I recommended that you go read Aaron Uglum‘s webcomic LABS which had just completed its final strip. I’m a big fan of “completed”
webcomics – they feel binge-able in the same way as a complete Netflix series does! – but Spencer quickly pointed out that it’s annoying
for we enlightened modern RSS users who hook RSS up to everything to have to binge completed comics in a different way to reading ongoing ones: what he wanted was an RSS feed covering the entire history of LABS.
With apologies to Aaron Uglum who I hope won’t mind me adapting his comic in this way.
So naturally (after the intense heatwave woke me early this morning anyway) I made one: complete RSS feed of
LABS. And, of course, I open-sourced the code I used to generate it so that others can jumpstart their
projects to make static RSS feeds from completed webcomics, too.
Even if you’re not going to read it via this medium, you should go read LABS.
After three and a half years, webcomic LABS today came to an end. For
those among you who like to wait until a webcomic has finished its run before you start to read it (you know who you are), start here.
Back in February my friend Katie shared with me an already four-year-old piece of interactive fiction, Bus Station: Unbound, that I’d somehow managed to miss the first time around. In the five months since then I’ve
periodically revisited and played through it and finally gotten around to writing a review:
All of the haunting majesty of its subject, and a must-read-thrice plot
Perhaps it helps to be as intimately familiar with Preston Bus Station – in many ways, the subject of the piece – as the protagonist. This work lovingly and faithfully depicts the
space and the architecture in a way that’s hauntingly familiar to anybody who knows it personally: right down to the shape of the rubberised tiles near the phone booths, the
forbidding shadows of the underpass, and the buildings that can be surveyed from its roof.
But even without such a deep recognition of the space… which, ultimately, soon comes to diverge from reality and take on a different – darker, otherworldly – feel… there’s a magic
to the writing of this story. The reader is teased with just enough backstory to provide a compelling narrative without breaking the first-person illusion. No matter how
many times you play (and I’ve played quite a few!), you’ll be left with a hole of unanswered questions, and you’ll need to be comfortable with that to get the most out of the story,
but that in itself is an important part of the adventure. This is a story of a young person who doesn’t – who can’t – know everything that they need to bring them comfort
in the (literally and figuratively) cold and disquieting world that surrounds them, and it’s a world that’s presented with a touching and tragic beauty.
Through multiple playthroughs – or rewinds, which it took me a while to notice were an option! – you’ll find yourself teased with more and more of the story. There are a few
frankly-unfair moments where an unsatisfactory ending comes with little or no warning, and a handful of places where it feels like your choices are insignificant to the story, but
these are few and far between. Altogether this is among the better pieces of hypertext fiction I’ve enjoyed, and I’d recommend that you give it a try (even if you don’t share the
love-hate relationship with Preston Bus Station that is so common among those who spent much of their youth sitting in it).
It’s no secret that I spent a significant proportion of my youth waiting for or changing buses at (the remarkable) Preston
Bus Station, and that doubtless biases my enjoyment of this game by tingeing it with nostalgia. But I maintain that it’s a well-written piece of hypertext interactive fiction with a
rich, developed world. You can play it starting from here, and you should. It looks like the story’s
accompanying images died somewhere along the way, but you can flick through them all here and get a feel for the shadowy,
brutalist, imposing place.
I can’t get enough of this comic. Despite the fact that it’s got no written dialogue at all I must’ve read it half a dozen times and seen more in it each time. Go read the whole thing…
The <a> tag is one of the most important building blocks of the Internet. It lets you create a hyperlink: a piece of text, usually colored blue, that you can use to go to a new
page. When you click on a hyperlink, your web browser downloads the new page from the server and displays it on the screen. Most web browsers also store the pages you previously
visited so you can quickly go back to them. The best part is, the <a> tag gives you all of that behavior for free! Just tell the browser
where you want to go, and it handles the rest.
Lately, though, that hasn’t been enough for website developers. The new fad is “client-side navigation”, where instead of relying on the browser to load new pages for you, you write
a bunch of JavaScript code to do it instead. It’s actually really hard to get it right—loading the new page is simple enough, but you also have to write code to display a loading
bar, make the Back and Forward buttons work, show an error page if the connection drops, and so on.
For a while, I didn’t understand why anyone did this. Was it just silly make-work, like how every social network redesigns their website every couple years for no discernable
reason? Do <a> tags interfere with some creepy ad-tracking technique? Was there some really complicated technical reason why you
shouldn’t use them?
…
Spoiler: good old-fashioned <a> hyperlinks tend to outperform Javascript-driven client-side navigation. We already learned about one reason for this – that adding more Javascript code just to get back what the browser gives you for free increases the payload you deliver to the user – but
Carter demonstrates that progressive rendering goes a long way to explaining it, too. You see: browsers understand traditional navigation and are well-equipped with a
suite of shortcuts to help them optimise for it. They can start rendering content before it’s all downloaded, offset (hinted-at) asynchronous data for later, and of course they already
contain a pretty solid caching engine and you don’t even have to implement it yourself.
Let’s talk about the point after WW2 where the Knights Hospitaller, of medieval crusading fame, ‘accidentally’ became a major European air power.
I shitteth ye not. ?️?️
So, if I asked you to imagine the Knights Hospitaller you probably picture:
1) Angry Christians on armoured horses
2) Them being wiped out long ago like the Templars.
3) Some Dan Brown bullshit
And you would be (mostly) wrong about all three. Which is sort of how this happened.
From the beginning (1113 or so), the Hospitallers were never quite as committed to the angry, horsey thing as the Templars. They had always (ostensibly) been more about
protecting pilgrims and healthcare.
They also quite liked boats. Which were useful for both.
Over the next 150 years (or so), as the Christian grip on the Holy Lands waned, both military orders got more involved in their other hobbies – banking for the Templars, mucking
around in boats for the Hospitaller.
This proved to be a surprisingly wise decision on the Hospitaller part. By 1290ish, both Orders were homeless and weakened.
As the Templars fatally discovered, being weak AND having the King of France owe you money is a bad combo.
Being a useful NAVY, however, wins you friends.
And this is why your first vision of the Hospitallers is wrong. Because they spent the next 500 YEARS, backed by France and Spain, as one of the most powerful naval forces in
the Mediterranean, blocking efforts by the Ottomans to expand westwards by sea.
To give you an idea of the trouble they caused: in 1480 Mehmet II sent 70,000 men (against the Knights 4000) to try and boot them out of Rhodes. He failed.
Suleiman the Magnificent FINALLY managed it in 1522 with 200,000 men. But even he had to agree to let the survivors leave.
The surviving Hospitallers hopped on their ships (again) and sailed away. After some vigorous lobbying, in 1530 the King of Spain agreed to rent them Malta, in return for a
single maltese falcon every year.
Because that’s how good rents were pre-housing crisis in Europe.
The Knights turned Malta into ANOTHER fortified island. For the next 200 years ‘the Pope’s own navy’ waged a war of piracy, slavery and (occasionally) pitched sea battles
against the Ottomans.
From Malta, they blocked Ottoman strategic access to the western med. A point that was not lost on the Ottomans, who sent 40,000 men to try and take the island in 1565 – the
‘Great Siege of Malta’.
The Knights, fighting almost to the last man, held out and won.
Now the important thing here is the CONTINUED EXISTENCE AS A SOVEREIGN STATE of the Knights Hospitaller. They held Malta right up until 1798, when Napoleon finally managed to
boot them out on his way to Egypt.
(Partly because the French contingent of the Knights swapped sides)
The British turned up about three months later and the French were sent packing, but, well, It was the British so:
THE KNIGHTS: Can we have our strategically important island back please?
THE BRITISH: What island?
THE KNIGHT: That island
THE BRITISH: Nope. Can’t see an island
After the Napoleonic wars no one really wanted to bring up the whole Malta thing with the British (the Putin’s Russia of the era) so the European powers fudged it. They said the
Knights were still a sovereign state and they tried to sort them out with a new country. But never did
The Russian Emperor let them hang out in St Petersburg for a while, but that was awkward (Catholicism vs Orthodox). Then the Swedes were persuaded to offer them Gotland.
But every offer was conditional on the Knights dropping their claim to Malta. Which they REFUSED to do.
~ wobbly lines ~
It’s the 1900s. The Knights are still a stateless state complaining about Malta. What that means legally is a can of worms NO ONE wants to open in international law but
they’ve also rediscovered their original mission (healthcare) so everyone kinda ignores them
The Knights become a pseudo-Red Cross organisation. In WW1 they run ambulance trains and have medical battalions, loosely affiliated with the Italian army (still do). In WW2
they do it too.
Italy surrenders. The allies move on then…
Oh dear.
Who wrote this peace deal again?
It turns out the Treaty of Peace with Italy should go FIRMLY into the category of ‘things that seemed a good idea at the time’.
This is because it presupposes that relations between the west and the Soviets will be good, and so limits Italy’s MILITARY.
This is a problem.
Because as the early Cold War ramps up, the US needs to build up its Euro allies ASAP.
But the treaty limits the Italians to 400 airframes, and bans them from owning ANYTHING that might be a bomber.
This can be changed, but not QUICKLY.
Then someone remembers about the Knights
The Knights might not have any GEOGRAPHY, but because everyone avoided dealing with the tricky international law problem it can be argued – with a straight face – that they are
still TECHNICALLY A EUROPEAN SOVEREIGN STATE.
And they’re not bound by the WW2 peace treaty.
Italy (with US/UK/French blessing) approaches the Knights and explains the problem.
The Knights reasonably point out that they’re not in the business of fighting wars anymore, but anything that could be called a SUPPORT aircraft is another matter.
So, in the aftermath of WW2, this is the ballet that happens:
The Italians transfer all of their support and training aircraft to the Knights.
This then frees up the ‘cap room’ to allow the US to boost Italy’s warfighting ability WITHOUT breaking the WW2 peace treaty.
This is why, in the late forties/fifties, a good chunk of the ‘Italian’ air force is flying with a Maltese Cross Roundel.
Because they were not TECHNICALLY Italian. They were the air force of the Sovereign Military Order of Malta.
And that’s how the Knights Hospitaller ended up becoming a major air power.
Eventually the treaties were reworked, and everything was quietly transferred back. I suspect it’s a reason why the sovereign status of the Knights remains unchallenged still
today though.
And that’s why today, even thought they are now fully committed to the Red-Cross-esque stuff, they can still issue passports, are a permanent observer at the UN, have a
currency…
One of the benefits of being in a camera club full of largely retired people who were all into photography long before digital was ever a thing, is that lots of them have old film,
paper and gear lying around they’re happy to give away.
Last year I was offered a photographic enlarger for making prints, but I initially turned it down because I didn’t think I’d have the space to set up a darkroom and use it. Well,
turns out with a little imagination our windowless bathroom actually converts into a pretty tidy darkroom with fairly minimal setup and teardown – thankfully we also have an
ensuite so my partner can cope with this arrangement with only minimal grumbling
…
My friend Rory tells the story of how he set up a darkroom in his (spare) windowless bathroom and shares his experience of becoming an
increasingly analogue photographer in an increasingly almost-completely digital world.
Dropped by following TomTrxsh’s log implying there was a problem with the cache container, but it seems to be fine. The lids on this kind of container can be completely removed but are
easy to put back on one you know the trick to it – see my video for a tutorial.
In October of this year – after eight years, six months, and five days with the Bodleian Libraries – I’ll be leaving for pastures new. Owing to a
combination of my current work schedule, holidays, childcare commitments and conferences, I’ve got fewer than 29 days left in the office.
I’ve been keeping a countdown on my whiteboard to remind my colleagues to hurry up and ask me anything they need in order to survive in my absence.
Instead, I’ll be starting work with Automattic Inc.. You might not have heard of them, but you’ve definitely used some of their
products, either directly or indirectly. Ever hear of WordPress.com, WooCommerce, Gravatar or Longreads? Yeah; that’s the guys.
It’s a gear stick. For an automatic car. ‘Cos I’m “shifting into Automattic”. D’you get it? Do you? Do you?
I’m filled with a mixture of joyous excitement and mild trepidation. It’s mostly the former, thankfully, but there’s still a little nervousness there too. Mostly it’s a kind of imposter syndrome, I guess: Automattic have for many, many years been on my “list of companies I’d love to work for, someday”, and
the nature of their organisation means that they have their pick of many of the smartest and most-talented geeks in the world. How do I measure up?
During my final months I’m taking the opportunity to explore bits of the libraries I’ve not been to before. Y’know, before they revoke my keycard.
It’s funny: early in my career, I never had any issue of imposter syndrome. I guess that when I was young and still thought I knew everything – fuelled by a little talent and a lot of
good fortune in getting a head-start on my peers – I couldn’t yet conceive of how much further I had to go. It took until I was well-established in my industry before I could begin to
know quite how much I didn’t know. I’d like to think that the second decade of my work as a developer has been dominated by unlearning all of the things that I did wrong, while flying
by the seat of my pants, in the first decade.
I’ll be mostly remote-working for Automattic, so I can guarantee that my office won’t be as pretty as my one at the Bod was. Far fewer Muses on the roof, too.
I’m sure I’ll have lots more to share about my post-Bodleian life in due course, but for now I’ve got lots of projects to wrap up and a job description to rewrite (I’m recommending that
I’m not replaced “like-for-like”, and in any case: my job description at the Bodleian does not lately describe even-remotely what I actually do), and a lot of documentation to
bring up-to-date. Perhaps then this upcoming change will feel “real”.
The other day, I saw someone on Twitter say (I’m not linking to the original tweet because I don’t want to pile-on the author):
I don’t bother with frameworks, I just use vanilla JS.
Roughly translated:
I’m smarter than the thousands of people who tried to solve the problems I’m about to solve. I’m an expert on security, a11y, browser support, and perf. I don’t care about ROI, I
just want to code.
Here’s the thing: frameworks don’t really help you with this stuff.
Very much this. People who use Javascript frameworks because they think they protect them from common web development pitfalls are simply trading away a set of known, solvable problems
and taking on a different set of unknown, unsolvable ones.
I’m not anti-framework, but I am pro-informed-developer. If security, accessibility, performance, and browser support are things you care about – and they absolutely should be – then
you need to know the impact that the tools you choose have upon those things. It’s easy to learn the impact that vanilla JS has on them, but
it’s harder to understand exactly what impact a framework might have or how that impact might be affected by interactions between it and all of the other frameworks and
libraries you mix-in. And many developers don’t bother to learn.
Use frameworks if they’re the right tool for your job. But you should work towards understanding your tools. Incidentally: in doing so, you’ll probably come to discover that
frameworks are the right tool for fewer jobs than you thought.
On this day 50 years ago launched the first mission to take people to the moon. As part of #GlobalRocketLaunch day the
5-year-old and I fired off stomp rockets and learned about the science and engineering of Apollo 11.
With IndieWebCamp Oxford 2019 scheduled to take place during the
Summer of Hacks, I drew a diagram (click to embiggen) of the current ecosystem that powers
and propogates the content on DanQ.me. It’s mostly for my own benefit – to be able to get a big-picture view of the ways my website talks to the world and plan for what
improvements I might be able to make in the future… but it also works as a vehicle to explain what my personal corner of the IndieWeb does and how it
does it. Here’s a summary:
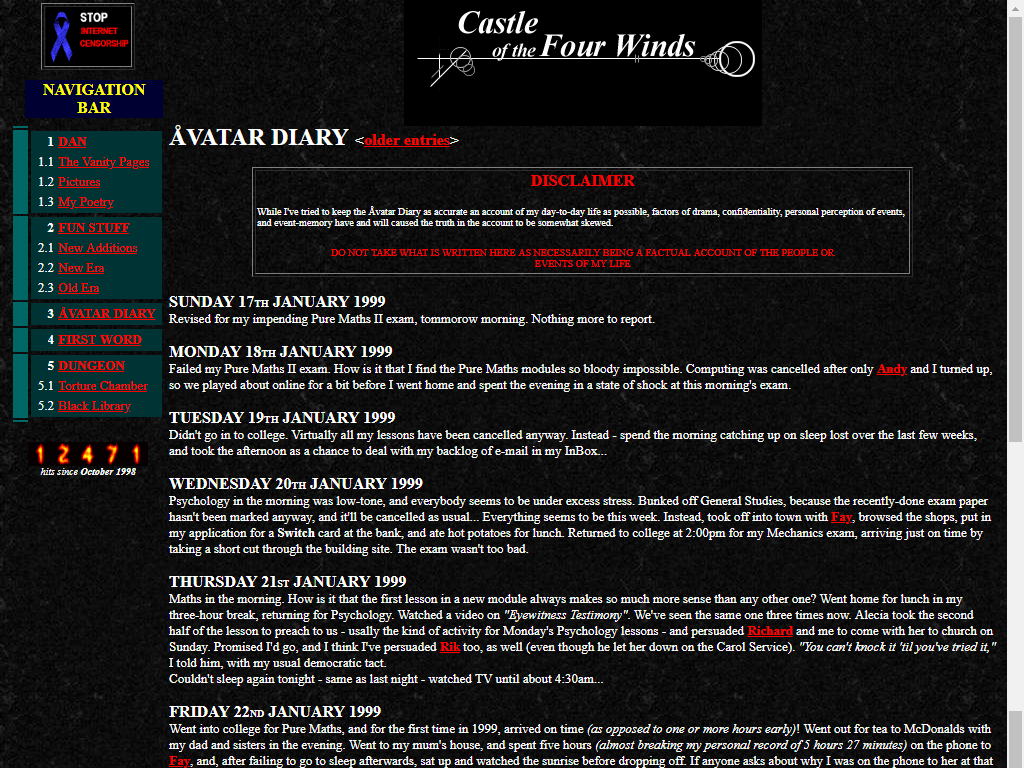
DanQ.me
Since fifteen years ago today, DanQ.me has been powered by a self-hosted WordPress installation. I
know that WordPress isn’t “hip” on the IndieWeb this week and that if you’re not on the JAMstack you’re yesterday’s news, but at 15 years and counting my
love affair with WordPress has lasted longer than any romantic relationship I’ve ever had with another human being, so I’m sticking with it. What’s cool in Web technologies comes and
goes, but what’s important is solid, dependable tools that do what you need them to, and between WordPress, half a dozen off-the-shelf plugins and about a dozen homemade ones I’ve got
everything I need right here.
I’d been “blogging” – not that we called it that, yet – since late 1998, but my original collection of content-mangling Perl scripts wasn’t all that. More history…
I write articles (long posts like this) and notes (short, “tweet-like” updates) directly into the site, and just occasionally
other kinds of content. But for the most part, different kinds of content come from different parts of the ecosystem, as described below.
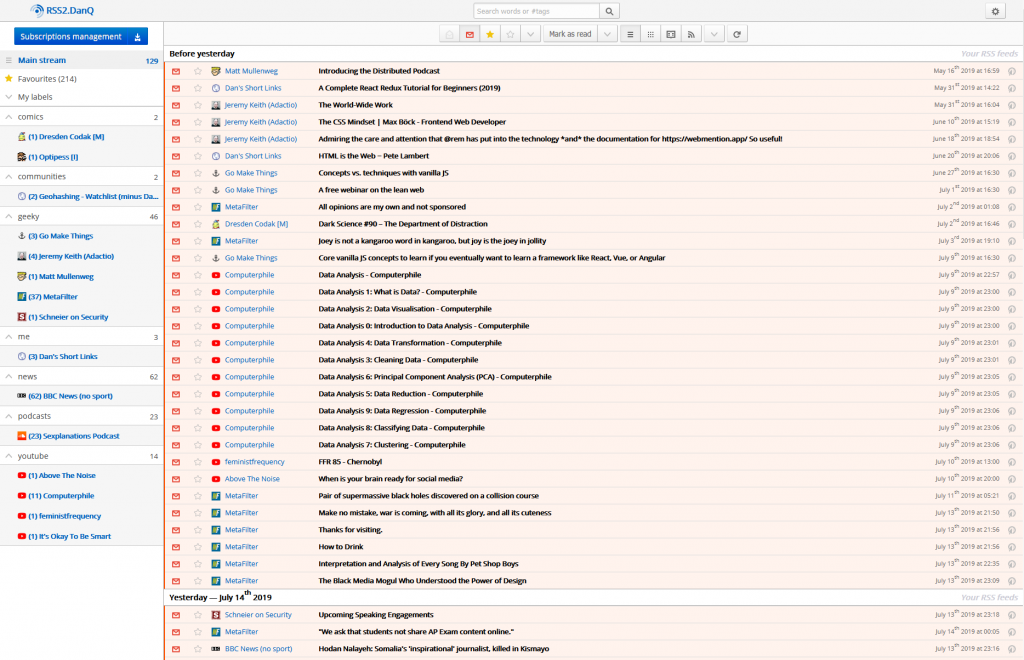
RSS reader
DanQ.me sits at the centre of the diagram, but it’s worth remembering that the diagram is deliberately incomplete: it only contains information flows directly relevant to my blog (and
it doesn’t even contain all of those!). The last time I tried to draw a diagram like this that described my online life in general, then my RSS reader found its way to the centre. Which figures: my RSS reader is usually the first
and often the last place I visit on the Internet, and I’ve worked hard to funnel everything through it.
129 unread items is a reasonable-sized queue: I try to process to “RSS zero”, but there are invariably things I want to return to on a second-pass and I’ve not yet reimplemented the
“snooze button” I added to my previous RSS reader.
Right now I’m using FreshRSS – plus a handful of plugins, including some homemade ones – as my RSS reader: I switched from Tiny Tiny RSS about a year ago to take advantage of FreshRSS’s excellent responsive
themes, among other features. Because some websites don’t have RSS feeds, even where they ought to, I use my own tool
RSSey to retroactively “fix” people’s websites for them, dynamically adding feeds for my
consumption. It’s also a nice reminder that open source and remixability were cornerstones of the original Web. My RSS reader
collates information from a variety of sources and additionally gives me a one-click mechanism to push content I enjoy to my blog as a repost.
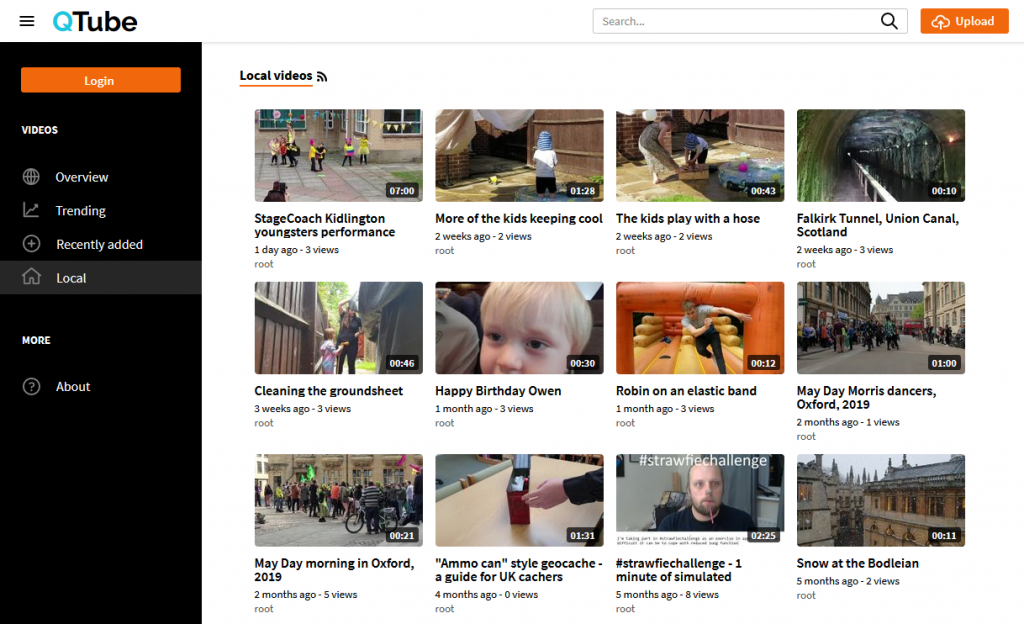
QTube
QTube is my video hosting platform; it’s a PeerTube node. If you haven’t seen it, that’s fine: most content
on it is consumed indirectly either through my YouTube channel or directly on my blog as posts of the “video” kind. Also, I don’t actually vlog very often. When I do publish videos onto QTube, their republication onto YouTube or DanQ.me is optional: sometimes I plan to
use a video inside an article post, for example, and so don’t need to republish it by itself.
I’m gradually exporting or re-uploading my backlog of YouTube videos from my current and previous channels to QTube in an effort to
recentralise and regain control over their hosting, but I’m in no real hurry. PeerTube certainly makes it easy, though!
Link Shortener
I operate a private link shortener which I mostly use for the expected purpose: to make links shorter and so easier to read out and memorise or else to make them take up less space in a
chat window. But soon after I set it up, many years ago, I realised that it could also act as a mechanism to push content to my RSS reader to “read later”. And by the time I’m using it for that, I figured, I might as well also be using it to repost content to my blog
from sources that aren’t things my RSS reader subscribes to. This leads to a process that’s perhaps unnecessarily
complex: if I want to share a link with you as a repost, I’ll push it into my link shortener and mark it as going “to me”, then I’ll tell my RSS reader to push it to my blog and there it’ll be published to the world! But it works and it’s fast enough: I’m not in the habit
of reposting things that are time-critical anyway.
Checkins
You know your sport is fringe when you need to reference another fringe sport to describe it. “Geohashing? It’s… a little like geocaching, but…”
I’ve been involved in brainstorming ways in which the act of finding (or failing to find, etc.) a geocache or reaching (or failing to
reach) a geohashpoint could best be represented as a “checkin“, and last year I open-sourced my plugin for pulling logs (with as much automation as is permitted by the terms of service of some of the
silos involved) from geocaching websites and posting them to WordPress blogs: effectively PESOS-for-geocaching. I’d prefer to be publishing on my own blog in the first instance, but syndicating my adventures from various
silos into my blog is “good enough”.
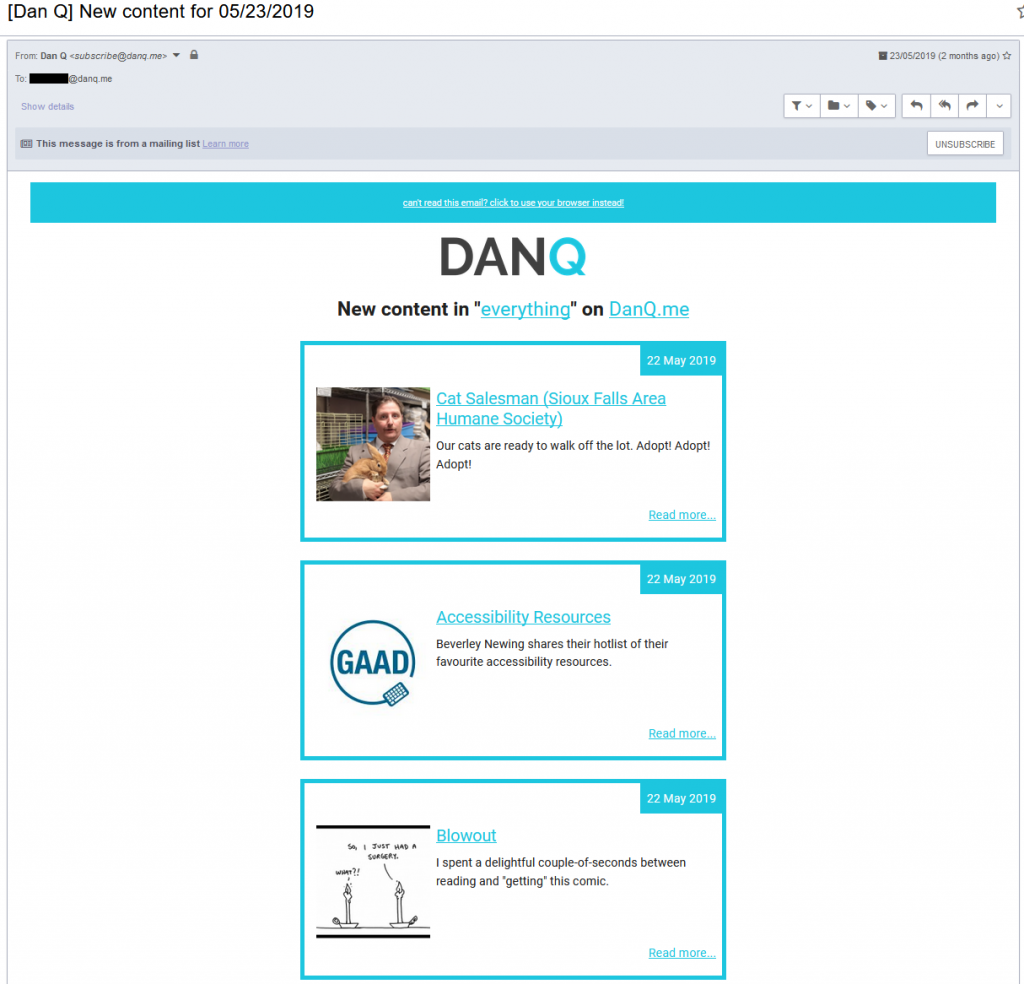
Syndication
New notes get pushed out to my Twitter account, for the benefit of my Twitter-using friends. Articles get advertised on Facebook, Twitter and LiveJournal (yes, really) in teaser form, for the benefit of friends
who prefer to get notifications via those platforms. Facebook have been fucking around with their APIs and terms of
service lately and this is now less-automatic than it used to be, which is a bit of an annoyance. My RSS feeds carry copies
of content out to people who prefer to subscribe via that medium, and I’ve also been using this to power an experimental MailChimp “daily digest” mailing list of “what Dan’s been up to”
to a small number of friends, right in their email inboxes: I’ve not made it available to everybody yet, but if you’re happy to help test it then give me a shout
and I’ll hook you up.
Most days don’t see an email sent or see an email with only one item, but some days – like this one – are busier. I still need to update the brand colours here, too!
Finally, a couple of IFTTT recipes push my articles and my reposts to Reddit communities: I don’t
really use Reddit myself, any more, but I’ve got friends in a few places there who prefer to keep up-to-date with what I’m up to via that medium. For historical reasons, my reposts to
Reddit don’t go directly via my blog’s RSS feeds but “shortcut” directly from my RSS reader: this is suboptimal because I don’t get to tweak post titles for Reddit but it’s not a big deal.
What IFTTT does isn’t magic, but it’s often indistinguishable from it.
I used to syndicate content to Google+ (before it joined the long list of Things Google Have Killed) and to Ello
(but it never got much traction there). I’ve probably historically syndicated to other places too: I’ve certainly manually-republished content to other blogs, from time to time, too.
I use Ryan Barrett‘s excellent Brid.gy to convert Twitter replies and likes back into Webmentions for publication as comments on my blog. This used to work for Facebook, too, but again: Facebook
fucked it over. I’ve occasionally manually backfed significant Facebook comments, but it’s not ideal: I might like to look at using similar technologies to RSSey to subvert
Facebook’s limitations.
I’ve never had a need for Brid.gy’s “publishing” (i.e. POSSE) features, but its backfeed features “just work”, and it’s awesome.
Reintegration
I’ve routinely retroactively reintegrated content that I’ve produced elsewhere on the Web. This includes my previous blogs (which is why you can browse my archives, right here on this
site, all the way back to some of the cringeworthy angsty-teenager posts I made in the 1990s) but also some Reddit posts,
some replies originally posted directly to other people’s blogs, all my old del.icio.us bookmarks, long-form forum
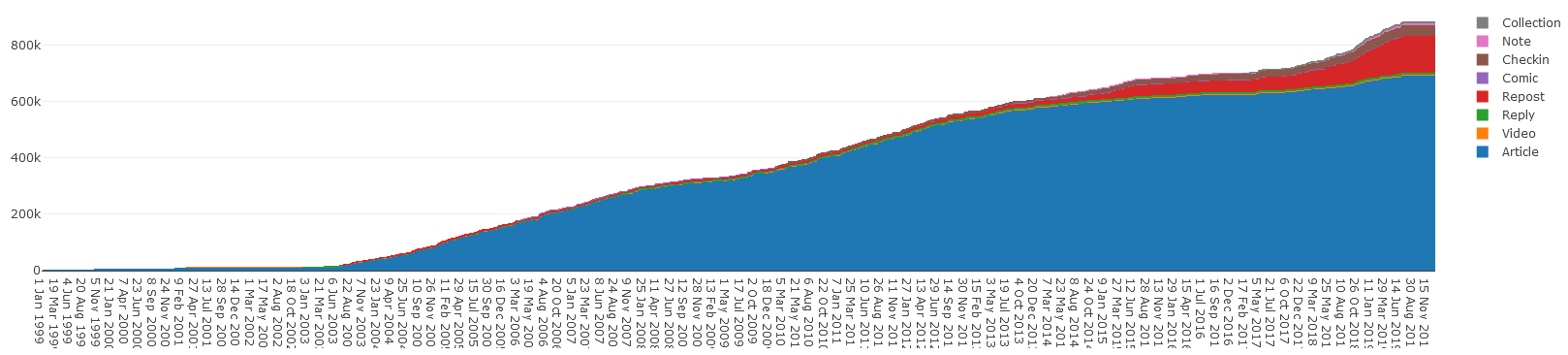
posts, posts I made to mailing lists and newsgroups, and more. As a result, there’s a lot of backdated content on this site, nowadays: almost a million words, and significantly
more than the 600,000 or so I counted a few years ago, before my biggest push for reintegration!
Cumulative wordcount per day, by content type. The lion’s share has always been articles, but reposts are creeping up as I’ve been writing more about the things I reshare, lately.
It’d be interesting to graph the differentiation of this chart to see the periods of my life that I was writing the most: I have a hypothesis, and centralising my own content under my
control makes it easier
Why do I do this? Because I really, really like owning my identity online! I’ve tried the “big” silo alternatives like Facebook, Twitter, Medium, Instagram etc., and they’ve eventually
always lead to disappointment, either because they get shut down or otherwise made-unusable, because
of inappropriately-applied “real names” policies, because they give too much power to
untrustworthy companies, because they impose arbitrary limitations on my content, because they manipulate output
promotion (and exacerbate filter bubbles), or because they make the walls of their walled gardens taller and stop you integrating with them how you used to.
A handful of silos have shown themselves to be more-trustworthy than the average – in particular, eschewing techniques that promote “lock-in” – and I’d love to tell you more about them
and what I think you should look for in a silo, another time. But for now: suffice to say that just like I don’t use YouTube like most people do, I
elect not to use Facebook or Twitter in the conventional ways either. And it’s awesome, thanks.
There are plenty of reasons that people choose to take control of their own Web presence – and everybody who puts content online ought to consider
it – but I imagine that few individuals have such a complicated publishing ecosystem as I do! Now you’ve got a picture of how my digital content production workflow works, and
perhaps start owning your online identity, too.




![Dan's whiteboard: "You have [29] work days left to ask Dan that awkward question".](https://bcdn.danq.me/_q23u/2019/07/20190719_154737-1024x498.jpg)