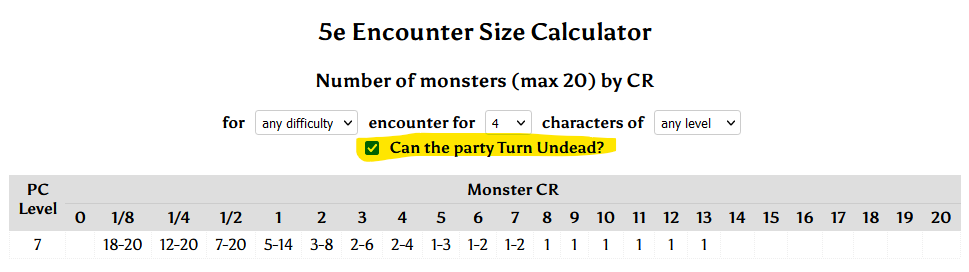
I dislike recipe posts that, before you get anywhere near the list of ingredients, tell you what feels like the entire life story of the author and their family.
“Every morning my mother would warm up the stove, and this was a wood-fired stove back in the day, and make these. We lived in Minnosota…” I don’t care. I can’t begin to tell you how much I don’t care. Just tell me how to make the damn muffins ‘cos the picture’s got me drooling.
This is different. This is the latest and so-far only exception. This, I care about:
When we moved into a house of our own, I bought us a tea kettle that whistled in harmony when it boiled. Rent was cheap, and we were happy. Those were the days of sweet potato hash, wilted kale, and increasingly exotic baked goods. There was the Me-Making-You-Tea-in-the-Morning-Because-You-Hated-Mornings Phase, but also the You-Making-Me-Tea-in-the-Morning-Because-You-Went-to-Work-at-5am Phase.
…
Lucy tells a story so rich and personal about her and her wife’s experience of life, cohabitation, food, and the beauty of everyday life. I haven’t even read the recipe for The Eggs, even though it sounds pretty delicious.
…
Over the years I’ve found words for people who have done what we’re doing now, but I’ve also found a deeper truth: our queer community doesn’t demand a definition. They know that chili oil can change a life just as much as a marriage. That love is in the making and unmaking of beds. The candlelit baths. The laughter. The proffered feast that nourishes.
Queerness makes room within it for these relationships, or rather: queerness spirals outward. It blooms and embraces. That is the process by which we broaden our palates, welcoming what might seem new to us, but which is actually older than we know.
…
It’s a great reminder about focussing on what’s important. About the value of an ally whether the world’s working with you or against you. And, of course, about how every relationship, no matter what shape, size, or form, can enjoy a little more queering once in a while. Go read it.



















{kind=link}
{kind=link}