🚫 Regrettably you have been locked out of diamond geezer
pending age verification protocols.
You may be UNDER 16 YEARS OF AGE and therefore you must not read anything here UNTIL YOU CAN PROVE THAT YOU’RE
NOT.
The government is taking urgent action to ensure that children are no longer able to access harmful social media apps. At the personal behest of the Prime Minister a raft of
carefully thought-through definitely-not-rushed non-kneejerk policies designed to restrict inappropriate content is to be introduced forthwith.
There is some absolutely terrible stuff online, much of which has already tarnished the minds of innocent youth. It is therefore imperative that all potentially terrible stuff must
now be wrapped in a secure plain cover and placed on the digital top shelf. It’s for everyone’s own good.
…
Despite being parody, diamond geezer’s new age-gating – which e.g. asks for personal information but, obviously, doesn’t actually block access to the site – somehow perfectly
straddles the line between “invasive” and “ineffective”… in exactly the same way that I expect the UK’s legal implementation will manage in a year or two.
Second: the language “committed suicide” is no longer appropriate. Princess Irenedied by suicide. “Committed” is the language of crime. For example,
one does not commit a heart attack.
…
You clearly feel strongly enough about this point to have committed it to writing.
(It’s obviously a cause that you’re committed to.)
I’m being sarcastic, of course, but there’s a point. While (like most mental health services) I’m not a fan of describing the act of suicide as “committing” suicide today, for exactly
the reasons you describe, it might be appropriate for a historical case.
That’s all I meant to say in a comment… but then I ended up going down a rabbithole.
Let’s sidestep into an example: I said “John William Gott committed blasphemy in 1921” that would be fair. His actions would not be considered criminal today: he was initially
arrested for selling pamphlets containing information on birth control but prosecutors tacked on a blasphemy charge because they figured they could get it to stick too, based on the
ways his literature was presented. But legally-speaking, Gott committed a crime; a crime that doesn’t exist today.
It’s not a coincidence I’ve lumped jumped from suicide to blasphemy: both were formerly criminalised in Britain and her empire (among many other places) as a direct result of Christian
religious tradition: you can probably blame Thomas Aquinas!
Language about the criminality of past offences gets very complicated, very quickly. Some contemporary values seem to be considered so fundamental that it feels wrong to
describe historical convictions as criminal. In some of these cases, we see pardons issued or other admissions of fault by the state. Take for example in recent years the payment of
compensation to former military personnel who were dishonourably discharged on account of their sexuality. But I’m not aware of anything like that happening related to past convictions
of suicide (or, indeed, blasphemy).
With that grounding: let’s take a deeper dive into Irene Duleep Singh, to decide whether or not her suicide would have been considered criminal at the time (it was certainly considered
shameful and taboo, even within societies that would not have considered it illegal, but that’s not what I’m interested in right now). Irene died by suicide in the Principality f Monaco
in 1926. At that time, Monaco was a protectorate of France with less independence than it is today, and for the most part its legal system seems to have paralleled that in France. I
can’t find a specific provision for suicide in Monaco, so it would probably not have been illegal (suicide was illegal under the Ancien Régime but was
effectively decriminalised by its omission from the Napoleonic Penal Codes). So: no crime.
Buuuut… Irene could also be considered a citizen of Britain, or of India, or of British India. Suicide was illegal in the UK prior to 1961 and in India
until 2024 (wait, what? yeah, really… well… kinda; it’s complicated, especially after 2018). So in her capacity as a citizen or subject of the British Empire, her suicide was
criminal.
Both John William Gott and Irene Duleep Singh may well both have committed crimes that would not be considered crimes today. In both cases, their crimes were things that, in my opinion,
should never have been criminalised in the first place. But that doesn’t make the historical fact any less-true.
And that’s why I picked up on this one line for my comment.
I absolutely agree that it’s inappropriate and unhelpful to talk about somebody have “committed suicide” today. The language creates a barrier to help and support, which is what should
be offered to people experiencing suicidal thoughts! But I don’t see the harm in using it when discussing a historical case from a century ago, at a time at which suicide was seen very
differently.
So long as it’s appropriately contextualised for the audience, it seems to me to be harmless. By which I mean to say: not worthy of being called-out by your one-liner… and even-less
worthy of my having gone down this long and complicated rabbithole which, somehow, has involved translating old French legislation, digging through the history of Monaco, and learning
about the courts of the British Raj.
I guess what I mean to say is that if your intention was to nerdsnipe me with this line… then well played, Sundeep, well played.
As I’ll demonstrate, it’s surprisingly easy to spin up your own VPN provider on a virtual machine hosted by your choice of the cloud providers. You pay for the hours you need
it2,
and then throw it away afterwards.
If you’d prefer to use GCP, AWS Azure, or whomever else you like: all you need is a Debian 13 VM with a public IP address (the cheapest one available is usually plenty!)
and this bash script.
If you prefer the command-line, Linode’s got an API. But we’re going for ‘easy’ today, so it’ll all be clicking buttons and things.
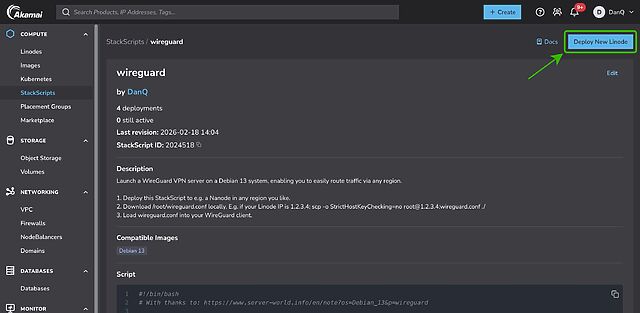
First, spin up a VM and run my script3.
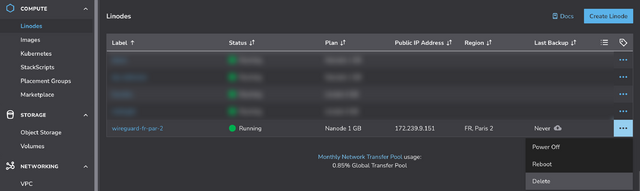
If you’re using Linode, you can do this by going to my StackScript and clicking ‘Deploy New Linode’.
You might see more configuration options than this, but you can ignore them.
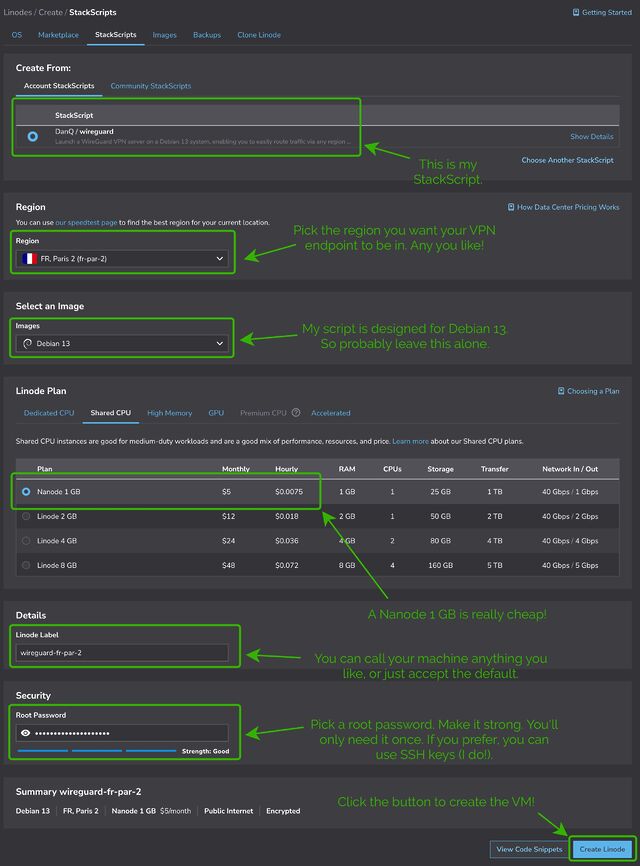
Choose any region you like (I’m putting this one in Paris!), select the cheapest “Shared CPU” option – Nanode 1GB – and enter a (strong!) root password, then click Create Linode.
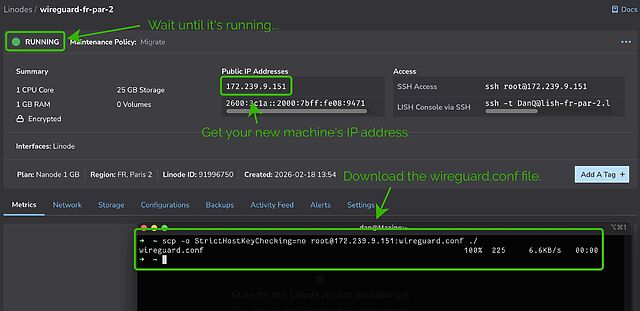
It’ll take a few seconds to come up. Watch until it’s running.
Don’t like SCP? You can SSH in and ‘cat’ the configuration or whatever else you like.
My script automatically generates configuration for your local system. Once it’s up and running you can use the machine’s IP address to download wireguard.conf locally. For
example, if your machine has the IP address 172.239.9.151, you might type scp -o StrictHostKeyChecking=no root@172.239.9.151:wireguard.conf ./ – note that I
disable StrictHostKeyChecking so that my computer doesn’t cache the server’s SSH key (which feels a bit pointless for a “throwaway” VM that I’ll never connect to a second time!).
If you’re on Windows and don’t have SSH/SCP, install one. PuTTY remains a solid choice.
File doesn’t exist? Give it a minute and try again; maybe my script didn’t finish running yet! Still nothing? SSH into your new VM and inspect
stackscript.log for a complete log of all the output from my script to see what went wrong.
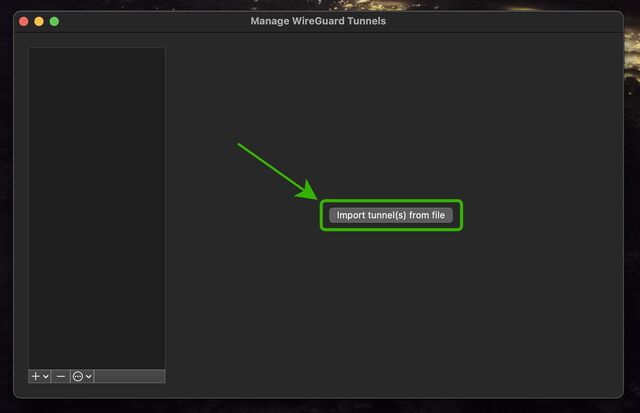
Not got WireGuard installed on your computer yet? Better fix that.
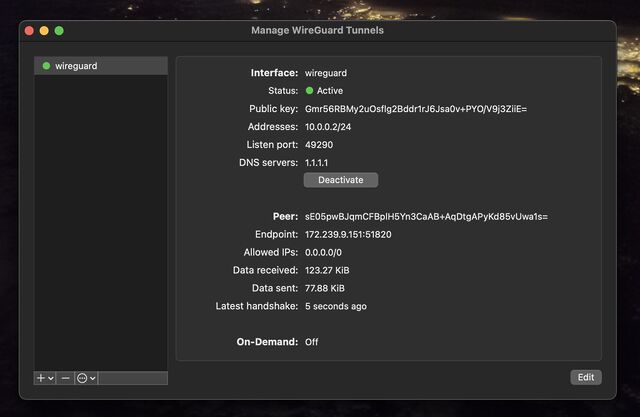
Open up WireGuard on your computer, click the “Import tunnel(s) from file” button, and give it the file you just downloaded.
You can optionally rename the new connection. Or just click “Activate” to connect to your VPN!
If you see the ‘data received’ and ‘data sent’ values changing, everything’s probably working properly!
You can test your Internet connection is being correctly routed by your VPN by going to e.g. icanhazip.com or ipleak.net: you should see the IP address of your new virtual machine and/or geolocation data that indicates that you’re in your selected region.
When you’re done with your VPN, just delete the virtual machine. Many providers use per-minute or even per-second fractional billing, so you can easily end up spending only a handful of
cents in order to use a VPN for a reasonable browsing session.
Again, you can script this from your command-line if you’re the kind of person who wants a dozen different locations/IPs in a single day. (I’m not going to ask why.)
When you’re done, just disconnect and – if you’re not going to use it again immediately – delete the virtual machine so you don’t have to pay for it for a minute longer than you
intend4.
I stopped actively paying for VPN subscriptions about a decade ago and, when I “need” the benefits of a VPN, I’ve just done things like what I’ve described above. Compared to a
commercial VPN subscription it’s cheap, (potentially even-more) private, doesn’t readily get “detected” as a VPN by the rare folks who try to detect such things, and I can enjoy my
choice of either reusable or throwaway IP addresses from wherever I like around the globe.
And if the government starts to try to age-gate commercial VPNs… well then that’s just one more thing going for my approach, isn’t it?
Footnotes
1 If you’re a heavy, “always-on” VPN user, you might still be best-served by one of the
big commercial providers, but if you’re “only” using a VPN for 18 hours a day or less then running your own on-demand is probably cheaper, and gives you some fascinating
benefits.
2 Many providers have coupons equivalent to hundreds of hours of free provision, so as
long as you’re willing to shuffle between cloud providers you can probably have a great and safe VPN completely for free; just sayin’.
3 Obviously, you shouldn’t just run code that strangers give you on the Internet unless
you understand it. I’ve tried to make my code self-explanatory and full of comments so you can understand what it does – or at least understand that it’s harmless! – but if you don’t
know and trust me personally, you should probably use this as an excuse to learn what you’re doing. In fact, you should do that anyway. Learning is fun.
4 Although even if you forget and it runs for an entire month before your billing cycle
comes up, you’re out, what… $5 USD? Plenty of commercial VPN providers would have charged you more than that!
But just sometimes, somebody asks2 “Yeah, but what does your birth
certificate say?”
My birth certificate says… Dan Q. Fuck the haters3.
It didn’t used to say “Dan Q”, but nowadays… yes, that’s exactly what my birth certificate says.
Y’see, I was born in Scotland, and Scottish law – in contrast to the law of England & Wales4
– permits a change of name to recorded retroactively for folks whose births (or adoptions) were
registered there.
And so, after considering it for a few months, I filled out an application form, wrote an explanatory letter to help the recipient understand that yes,
I’d already changed my name but was just looking for modify a piece of documentation, and within a few weeks I was holding an updated birth certificate. It was pretty
easy.
Somehow my modification does not make this Rick and Morty episode any more batshit-crazy than
it already was.
I flip-flopped on the decision for a while. Not only is it a functionally-pointless gesture – there’s no doubt what my name is! – but I was also concerned about what it
implies.
Am I trying to deny that I ever went by a different name? Am I trying to disassociate myself from my birth family? (No, and no, obviously.)
But it “feels right”. And as a bonus: I now know my way around yet another way for (some) Brits to change their names. Thanks to my work at FreeDeedPoll.org.uk I get an increasing amount of email from people looking for help with their name
changes, and now I’ve got first-hand experience of an additional process that might be a good choice for some people, some of the time5.
Footnotes
1 By the time you’ve got your passport, driving license, bank account, bills etc. in your
name, there’s really no need to be able to prove that you changed it. What it is is more-important anyway.
2 Usually with the same judgemental tone of somebody who insists that one’s “real” name is
the one assigned closest to birth.
3 If you’re zooming in on the details on that birth certificate and thinking “Hang on, he
told me he was an Aquarius but this date would make him a Capricon?”, then I’ve got news for you about that too.
4 Pedants might like to enjoy using the comments to point out the minority of
circumstances under which a birth certificate can be modified retroactively – potentially including name changes – under English law.
5 I maintain that a free, home-made deed poll is the easiest and cheapest way to change
your name, as a British citizen, and that’s exactly what FreeDeedPoll.org.uk helps people produce… and since its relaunch it does its processing entirely in-browser, which is totally badass from both a hosting and a user privacy perspective.
I’m writing up this information because Dreamwidth’s legal advocacy work has been largely underrecognized. I have not seen a scrap of mainstream news coverage out there that delves
into the unique role that Dreamwidth has played in the NetChoice lawsuits, and in a tech news landscape that inspires so much resignation and despair, I think people deserve to know
about how Dreamwidth is putting up a fight. Not only does Dreamwidth refuse to engage in intrusive tracking, it’s proactively participating in lawsuits against state governments
that try to force its hand. For all that many lawmakers are trying to make the web worse, Dreamwidth is leveraging itself as proof that a better web is possible.
…
If your mental model of Dreamwidth is “it’s like LiveJournal, but…” then you owe it to yourself to read Coyote’s excellent explanation of how
Dreamwidth is so much more: a beacon of privacy-centric and censorship-resistant blog hosting in a world that increasingly seems at-best uninterested and at-worst actively
hosting to such things.
That it’s not for me personally (I’m more a selfhost type) doesn’t mean it’s not a great choice for you: it’s got solid free and reasonably-priced premium tiers and all the kinds of
features you’d expect from a service live LiveJournal, or Tumblr, or Medium… but without all of the antifeatures that come with each of those.
And yeah, they’re on the side of the good guys:
I think there’s mileage in stealing repurposing this iconic line…
Coyote also wrote the excellent You Can Make A Website, if you’re looking for further reading from
the same author.
I got kicked off LinkedIn this week. Apparently there was “suspicious behaviour” on my account. To get back in, I needed to go through Persona’s digital ID check (this, despite the fact
that I’ve got a Persona-powered verification on my LinkedIn, less than six months old).
After looping around many times identifying which way up a picture of a dog was and repeatedly photographing myself, my passport, and my driving license, I eventually got back in.
Personally, I suspect they just rolled out some Online Safety Act functionality and it immediately tripped over my unusual name.
But let this be a reminder to anybody who (unlike me) depends upon their account in a social network: it can be taken away in a moment and be laborious (or impossible) to get
back. If you care about your online presence, you should own your own domain name; simple as that!
The tl;dr is: the court ruled that (a) piracy for the purpose of training an LLM is still piracy, so there’ll be a separate case about the fact that Anthropic did not pay for copies of
all the books their model ingested, but (b) training a model on books and then selling access to that model, which can then produce output based on what it has “learned” from those
books, is considered transformative work and therefore fair use.
Compelling arguments have been made both ways on this topic already, e.g.:
Some folks are very keen to point out that it’s totally permitted for humans to read, and even memorise, entire volumes, and then use what they’ve learned when they
produce new work. They argue that what an LLM “does” is not materially different from an impossibly well-read human.
By way of counterpoint, it’s been observed that such a human would still be personally liable if the “inspired” output they subsequently created was derivative
to the point of violating copyright, but we don’t yet have a strong legal model for assessing AI output in the same way. (BBC News article about Disney & Universal vs. Midjourney is going to be very interesting!)
Furthermore, it might be impossible to conclusively determine that the way GenAI works is fundamentally comparable to human thought. And that’s the thing that got
me thinking about this particular thought experiment.
A moment of philosophy
Here’s a thought experiment:
Support I trained an LLM on all of the books of just one author (plus enough additional language that it was able to meaningfully communicate). Let’s take Stephen King’s 65 novels and
200+ short stories, for example. We’ll sell access to the API we produce.
I suppose it’s possible that Stephen King was already replaced long ago with an AI that was instructed to churn out horror stories about folks in isolated Midwestern locales being
harassed by a pervasive background evil?
The output of this system would be heavily-biased by the limited input it’s been given: anybody familiar with King’s work would quickly spot that the AI’s mannerisms echoed his writing
style. Appropriately prompted – or just by chance – such a system would likely produce whole chapters of output that would certainly be considered to be a substantial infringement of
the original work, right?
If I make KingLLM, I’m going to get sued, rightly enough.
But if we accept that (and assume that the U.S. District Court for the Northern District of California would agree)… then this ruling on Anthropic would carry a curious implication.
That if enough content is ingested, the operation of the LLM in itself is no longer copyright infringement.
Which raises the question: where is the line? What size of corpus must a system be trained upon before its processing must necessarily be considered transformative
of its inputs?
Clearly, trying to answer that question leads to a variant of the sorites paradox. Nobody can ever say that, for example, an input of twenty million words
is enough to make a model transformative but just one fewer and it must be considered to be perpetually ripping off what little knowledge it has!
But as more of these copyright holder vs. AI company cases come to fruition, it’ll be interesting to see where courts fall. What is fair use and what is infringing?
And wherever the answers land, I’m sure there’ll be folks like me coming up with thought experiments that sit uncomfortably in the grey areas that remain.
Representation matters. That we have a trans former-judge, somebody both well-equipped and motivated to escalate this important challenge to the ECHR, is hugely
fortunate.
We need more representation (of trans people specifically, but many other groups too, and perhaps particularly in the intersections) in positions of power, expertise, and authority. To
defend the human rights of all of us.
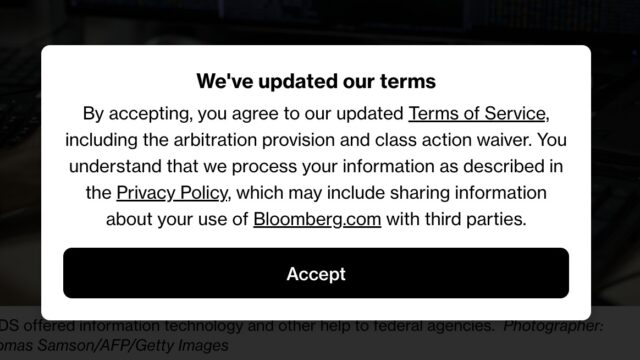
While perfectly legal, it is remarkable that to read a Bloomberg article, you must first agree to binding arbitration and waive your class action rights.
I don’t often see dialog boxes like this one. In fact, if I go to the URL of a Bloomberg.com article, I don’t see any popups: nothing about privacy, nothing about cookies,
nothing about terms of service, nothing about only being allowed to read a limited number of articles without signing up an account. I just… get… the article.
The reason for this is, most-likely, because my web browser is configured, among other things, to:
Block all third-party Javascript (thanks, uBlock Origin‘s “advanced mode”), except on domains where they’re explicitly allowed (and even then
with a few exceptions: thanks, Ghostery),
Delete all cookies 30 seconds after I navigate away from a domain, except for domains that are explicitly greylisted/allowlisted (thanks, Cookie-AutoDelete), and
But here’s the thing I’ve always wondered: if I don’t get to see a “do you accept our terms and conditions?” popup, is is still enforceable?
Obviously, one could argue that by using my browser in a non-standard configuration that explicitly results in the non-appearance of “consent” popups that I’m deliberately turning a
blind eye to the popups and accepting them by my continued use of their services1. Like: if I pour a McDonalds coffee on my lap having
deliberately worn blinkers that prevent me reading the warning that it’s hot, it’s not McDonalds’ fault that I chose to ignore their helpful legally-recommended printed warning on the cup, right?2
But I’d counter that if a site chooses to rely on Javascript hosted by a third party in order to ask for consent, but doesn’t rely on that same third-party in
order to provide the service upon which consent is predicated, then they’re setting themselves up to fail!
The very nature of the way the Internet works means that you simply can’t rely on the user successfully receiving content from a CDN. There are all kinds of reasons my browser might not
get the Javascript required to show the consent dialog, and many of them are completely outside of the visitor’s control: maybe there was a network fault, or CDN downtime, or my
browser’s JS engine was buggy, or I have a disability and the technologies I use to mitigate its impact on my Web browsing experience means that the dialog isn’t read out to me. In any
of these cases, a site visitor using an unmodified, vanilla, stock web browser might visit a Bloomberg article and read it without ever being asked to agree to their terms and
conditions.
Would that be enforceable? I hope you’ll agree that the answer is: no, obviously not!
It’s reasonably easy for a site to ensure that consent is obtained before providing services based on that consent. Simply do the processing server-side, ask for whatever
agreement you need, and only then provide services. Bloomberg, like many others, choose not to do this because… well, it’s probably a combination of developer laziness and
search engine optimisation. But my gut feeling says that if it came to court, any sensible judge would ask them to prove that the consent dialog was definitely viewed by
and clicked on by the user, and from the looks of things: that’s simply not something they’d be able to do!
tl;dr: if you want to fight with Bloomberg and don’t want to go through their arbitration, simply say you never saw or never agreed to their terms and conditions – they
can’t prove that you did, so they’re probably unenforceable (assuming you didn’t register for an account with them or anything, of course). This same recommendation applies to many,
many other websites.
Footnotes
1 I’m confident that if it came down to it, Bloomberg’s lawyers would argue
exactly this.
2 I see the plaintiff’s argument that the cups were flimsy and obviously her injuries were
tragic, of course. But man, the legal fallout and those “contents are hot” warnings remain funny to this day.
Obviously all of the 118 executive orders President Trump
signed into effect on 20 January fall somewhere on the spectrum between fucking ridiculous and tragically fascist. But there’s a moment of joy to be taken in the fact that now, by
Presidential executive order, one could argue that all Americans are legally female:
…
One of Trump’s order is titled “Defending Women from Gender Ideology Extremism and Restoring Biological Truth to the Federal Government.” In the definition, the order claims,
“‘Female’ means a person belonging, at conception, to the sex that produces the large reproductive cell.” It then says, “’Male’ means a person belonging, at conception, to the sex
that produces the small reproductive cell.”
What critics point out is the crucial phrase “at conception.” According to the Associated
Press, the second “order declares that the federal government would recognize only two immutable sexes: male and female. And they’re to be defined based on whether people are
born with eggs or sperm, rather than on their chromosomes, according to details of the upcoming order.”
…
So yeah, here’s the skinny: Trump and team wanted to pass an executive order that declared that (a) there are only two genders, and (b) it’s determined biologically and can be
ascertained at birth. Obviously both of those things are categorically false, but that’s not something that’s always stopped lawmakers in the past (I’m looking at you, Indiana’s 1897 bill to declare Pi to be 3.2 exactly…).
But the executive order is not well thought-out (well duh). Firstly, it makes the unusual and somewhat-complicated choice of declaring that a person’s gender is determined by whether or
not it carries sperm or egg cells. And secondly – and this is the kicker – it insists that the point at which the final and absolute point at which gender becomes fixed is… conception
(which again, isn’t quite true, but in this particular legal definition it’s especially problematic…).
At conception, you consisted of exactly one cell. An egg cell. Therefore, under US law, all Americans ever conceived were – at the point at which their gender became
concrete – comprised only of egg cells, and thus are legally female. Every American is female. Well done, Trump.
Obviously I’m aware that this is not what Mrs. Trump intended when she signed this new law into effect. But as much as I hate her policies I’d be a hypocrite if I didn’t respect her
expressed gender identity, which is both legally-enforceable and, more-importantly, self-declared. As a result, you’ll note that I’ve been using appropriate feminine pronouns for her in
this post. She’s welcome to get in touch with me if she uses different pronouns and I’ll respect those, too.
(I’m laughing on the outside, but of course I’m crying on the inside. I’m sorry for what your President is doing to you, America. It really sucks.)
Hypothetically-speaking, what would happen if convicted felon Donald Trump were assassinated in-between his election earlier this month and his inauguration in January?
There’ve been at least two assassination attempts so far, so it’s not beyond the realm of possibility that somebody will have another go at some point1.
Hello, Secret Service agents! Thanks for visiting my blog. I assume I managed to get the right combination of keywords to hit your watchlist. Just to be clear, this is
an entirely hypothetical discussion. I know that you’ve not always been the smartest about telling fiction from reality. But as you’ll see, I’m
just using the recent assassination attempts as a framing device to talk about the history of the succession of the position of President-Elect. Please don’t shoot me.
If the US President dies in office – and this happens around 18% of the time2 – the
Vice-President becomes President. But right now, convicted felon Donald Trump isn’t President. He’s President-Elect, which is a term used distinctly from
President in the US Constitution and other documents.
This card was pretty-much nerfed by Wizards’ ruling that Presidents-Elect, Vice-Presidents etc. were not (yet) kinds of President.
It turns out that the answer is that the Vice-President-Elect becomes President at the inauguration. This boring answer came to us through three different Constitutional Amendments,
each with its own interesting tale.
The Twelfth Amendment (1804) mostly existed to reform the Electoral College. Prior to the adoption of the Twelfth Amendment, the Electoral College members each cast two
ballots to vote for the President and Vice-President, but didn’t label which ballot was which position: the runner-up became Vice-President. The electors would carefully
and strategically have one of their number cast a vote for a third-party candidate to ensure the person they wanted to be Vice-President didn’t tie with the person they wanted to be
President. Around the start of the 19th century this resulted in several occasions on which the President and Vice-President had been bitter rivals but were now forced to work
together3.
While fixing that, the Twelfth Amendment also saw fit to specify what would happen if between the election and the inauguration the President-Elect died: that the House of
Representatives could choose a replacement one (by two-thirds majority), or else it’d be the Vice-President. Interesting that it wasn’t automatically the Vice-President,
though!
It didn’t happen like this. In real life, there was a lot less singing, and a lot more old white men.
The Twentieth Amendment (1933) was written mostly with the intention of reducing the “lame duck” period. Here in the UK, once we elect somebody, they take power
pretty-much immediately. But in the US, an election in November traditionally resulted in a new President being inaugurated almost half a year later, in March. So the Twentieth
Amendment reduced this by a couple of months to January, which is where it is now.
In an era of high-speed road, rail, and air travel and digital telecommunications even waiting from November to January seems a little silly, though. In any case, a secondary feature of
the Twentieth Amendment was that it removed the rule about the House of Representatives getting to try to pick a replacement President first, saying that they’d just fall-back on the
Vice-President in the first instance. Sorted.
Just 23 days later, the new rule almost needed to be used, except that Franklin D. Roosevelt’s would-be assassin Giuseppe Zangara missed his tricky shot.
The Twentieth Amendment (1967) aimed to fix rules-lawyering. The constitution originally said that f the President is removed from office, dies, resigns, or is
otherwise unable to use his powers and fulfil his duties, then those powers and duties go to the Vice-President.
Note the wording there. The constitution said that if a President died, their their duties and powers would go to the Vice-President. Not the Presidency itself. You’d
have a Vice-President, acting as President, who wasn’t actually a President. And that might not matter 99% of the time… but it’s the edge cases that get you.[foonote]Looking
for some rules-lawyering? Okay: what about rules on Presidential term limits? You can’t have more than two terms as President, but what if you’ve had a term as Vice-President
but acting with Presidential powers after the President died? Can you still have two terms? This is the kind of constitutional craziness that munchkin US history scholars get
off on.[/footnote]
It also insisted that if there’s no Vice-President, you’ve got to get one. You’d think it was obvious that if the office of Vice-President exists in part to provide a “backup” President
in case, y’know, the nearly one-in-five chance that the President dies… that a Vice-President who finds themselves suddenly the President would probably want to have one!
But no: 18 Presidents4served without a Vice-President for at least some of their
term: four of them never had a Vice-President. That includes 17th
President Andrew Johnson, who you’d think would have known better. Johnson was Vice-President under Abraham Lincoln until, only a month after the inauguration, Lincoln was assassinated,
putting Johnson in change of the country. And he never had a Vice-President of his own. He served only barely shy of the full four years without one.
Anyway; that was a long meander through the history of the Constitution of a country I don’t even live in, to circle around a question that doesn’t matter. The thought randomly came to
me while I was waiting for the traffic lights at the roadworks outside my house to change. And now I know the answer.
Very hypothetically, of course.
Footnotes
1 My personal headcanon is that the would-be assassins are time travellers from the
future, Chrononauts-style, trying to flip a linchpin and bring about a stable future in which he wasn’t elected. I
don’t know whether or not that makes Elon Musk one of the competing time travellers, but you could conceivably believe that he’s Squa Tront in disguise, couldn’t you?
2 The US has had 45 presidents, of whom eight have died during their time in office. Of
those eight, four – half! – were assassinated! It’s a weird job. 8 ÷ 45 ≈ 18%.
3 If you’re familiar with Hamilton, you’ll recall its characterisation of the
election of 1800 with President Thomas Jefferson dismissing his Vice-President Aaron Burr after a close competition for the seat of President which was eventually settled when
Alexander Hamilton instructed Federalist party members in the House of Representatives to back Jefferson over Burr. The election result really did happen like that – it seems that
whichever Federalist in the Electoral College that was supposed to throw away their second vote failed to do so! – but it’s not true that he was kicked-out by Jefferson: in fact, he
served his full four years as Vice-President, although Jefferson tried to keep him as far from actual power as possible and didn’t nominate him as his running-mate in 1804. Oh, and in
1807 Jefferson had Burr arrested for treason, claiming that Burr was trying to capture part of the South-West of North America and force it to secede and form his own country: the
accusation didn’t stick, but it ruined Burr’s already-faltering political career. Anyway, that’s a diversion.
4 17 different people, but that’s not how we could Presidents apparently.
Look at the following list of words and try to find the intruder:
wp-activate.php
wp-admin
wp-blog-header.php
wp_commentmeta
wp_comments
wp-comments-post.php
wp-config-sample.php
wp-content
wp-cron.php
wp engine
wp-includes
wp_jetpack_sync_queue
wp_links
wp-links-opml.php
wp-load.php
wp-login.php
wp-mail.php
wp_options
wp_postmeta
wp_posts
wp-settings.php
wp-signup.php
wp_term_relationships
wp_term_taxonomy
wp_termmeta
wp_terms
wp-trackback.php
wp_usermeta
wp_users
What are these words?
Well, all the ones that contain an underscore _ are names of the WordPress core database tables. All the ones that contain a dash - are WordPress core file
or folder names. The one with a space is a company name…
…
A smart (if slightly tongue-in-cheek) observation by my colleague Paolo, there. The rest of his article’s cleverer and worth-reading if you’re following the WordPress Drama (but it’s
pretty long!).
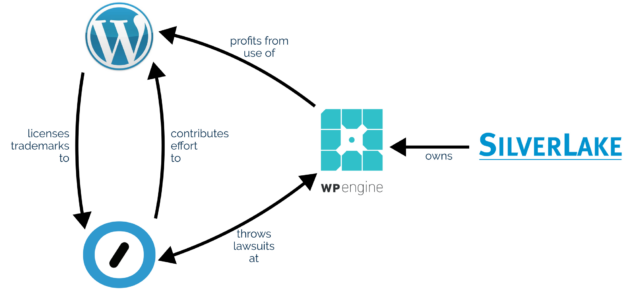
If you’re active in the WordPress space you’re probably aware that there’s a lot of drama going on right now between (a) WordPress hosting company WP Engine, (b) WordPress
hosting company (among quiteafewotherthings) Automattic1,
and (c) the WordPress Foundation.
If you’re not aware then, well: do a search across the tech news media to see the latest: any summary I could give you would be out-of-date by the time you read it anyway!
I tried to draw a better diagram with more of the relevant connections, but it quickly turned into spaghetti.
In particular, I think a lot of the conversation that he kicked off conflates three different aspects of WP Engine’s misbehaviour. That muddies the waters when it comes to
having a reasoned conversation about the issue3.
I’ve heard Matt speak a number of times, including in person… and I think he did a pretty bad job of expressing the problems with WP Engine during his Q&A at WCUS. In his defence,
it sounds like he may have been still trying to negotiate a better way forward until the very second he walked on stage that day.
I don’t think WP Engine is a particularly good company, and I personally wouldn’t use them for WordPress hosting. That’s not a new opinion for me: I wouldn’t have used them last year or
the year before, or the year before that either. And I broadly agree with what I think Matt tried to say, although not necessarily with the way he said it or the platform he
chose to say it upon.
Misdeeds
As I see it, WP Engine’s potential misdeeds fall into three distinct categories: moral, ethical4,
and legal.
Morally: don’t take without giving back
Matt observes that since WP Engine’s acquisition by huge tech-company-investor Silver Lake, WP Engine have made enormous profits from selling WordPress hosting as a service (and nothing else) while
making minimal to no contributions back to the open source platform that they depend upon.
If true, and it appears to be, this would violate the principle of reciprocity. If you benefit from somebody else’s
effort (and you’re able to) you’re morally-obliged to at least offer to give back in a manner commensurate to your relative level of resources.
The principle of reciprocity is a moral staple. This is evidenced by the fact that children (and some nonhuman animals) seem to be able to work it out for themselves
from first principles using nothing more than empathy. Companies, however aren’t usually so-capable. Photo courtesy Cotton.
Abuse of this principle is… sadly not-uncommon in business. Or in tech. Or in the world in general. A lightweight example might be the many millions of profitable companies that host
atop the Apache HTTP Server without donating a penny to the Apache Foundation. A heavier (and legally-backed) example might be Trump Social’s
implementation being based on a modified version of Mastodon’s code:
Mastodon’s license requires that their changes are shared publicly… but they don’t do until they’re sent threatening letters reminding them of their obligations.
I feel like it’s fair game to call out companies that act amorally, and encourage people to boycott them, so long as you do so without “punching down”.
Ethically: don’t exploit open source’s liberties as weaknesses
WP Engine also stand accused of altering the open source code that they host in ways that maximise their profit, to the detriment of both their customers and the original authors of
that code5.
It’s well established, for example, that WP Engine disable the “revisions” feature of WordPress6.
Personally, I don’t feel like this is as big a deal as Matt makes out that it is (I certainly wouldn’t go as far as saying “WP
Engine is not WordPress”): it’s pretty commonplace for large hosting companies to tweak the open source software that they host to better fit their architecture and business model.
But I agree that it does make WordPress as-provided by WP Engine significantly less good than would be expected from virtually any other host (most of which, by the way, provide much
better value-for-money at any price point).
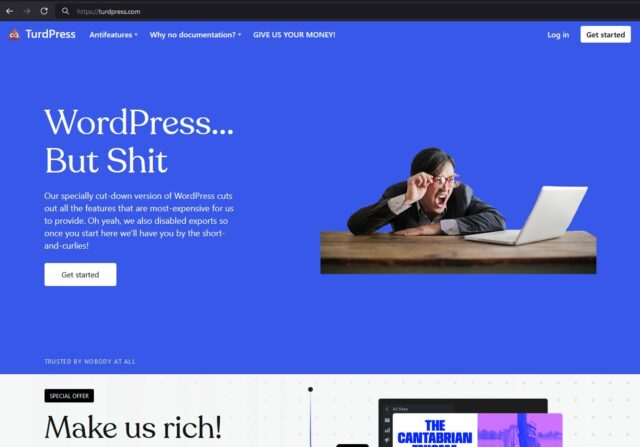
There’s nothing to stop me from registering TurdPress.com and providing a premium WordPress web hosting solution with all the best features disabled: I could even disable
exports so that my customers wouldn’t even be able to easily leave my service for greener pastures! There’s nothing stop me… but that wouldn’t make it
right7.
It also looks like WP Engine may have made more-nefarious changes, e.g. modifying the referral links in open source code (the thing that earns money for the original authors of
that code) so that WP Engine can collect the revenue themselves when they deploy that code to their customers’ sites. That to me feels like it’s clearly into the zone ethical bad
practice. Within the open source community, it’s not okay to take somebody’s code, which they were kind enough to release under a liberal license, strip out the bits that provide
their income, and redistribute it, even just as a network service8.
Again, I think this is fair game to call out, even if it’s not something that anybody has a right to enforce legally. On which note…
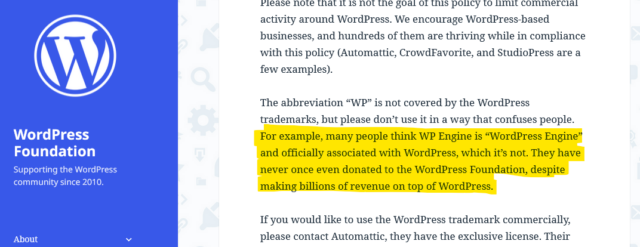
Obviously, this is the part of the story you’re going to see the most news media about, because there’s reasonable odds it’ll end up in front of a judge at some point. There’s a good
chance that such a case might revolve around WP Engine’s willingness (and encouragement?) to allow their business to be called “WordPress Engine” and to capitalise on any confusion that
causes.
I’m not going to weigh in on the specifics of the legal case: I Am Not A Lawyer and all that. Naturally I agree with the underlying principle that one should not be allowed to profit
off another’s intellectual property, but I’ll leave discussion on whether or not that’s what WP Engine are doing as a conversation for folks with more legal-smarts than I. I’ve
certainly known people be confused by WP Engine’s name and branding, though, and think that they must be some kind of “officially-licensed” WordPress host: it happens.
If you’re following all of this drama as it unfolds… just remember to check your sources. There’s a lot of FUD floating around on the Internet right now9.
In summary…
With a reminder that I’m sharing my own opinion here and not that of my employer, here’s my thoughts on the recent WP Engine drama:
WP Engine certainly act in ways that are unethical and immoral and antithetical to the spirit of open source, and those are just a subset of the reasons that I wouldn’t use them as
a WordPress host.
Matt Mullenweg calling them out at WordCamp US doesn’t get his point across as well as I think he hoped it might, and probably won’t win him any popularity contests.
I’m not qualified to weigh in on whether or not WP Engine have violated the WordPress Foundation’s trademarks, but I suspect that they’ve benefitted from widespread confusion about
their status.
Footnotes
1 I suppose I ought to point out that Automattic is my employer, in case you didn’t know,
and point out that my opinions don’t necessarily represent theirs, etc. I’ve been involved with WordPress as an open source project for about four times as long as I’ve had any
connection to Automattic, though, and don’t always agree with them, so I’d hope that it’s a given that I’m speaking my own mind!
2 Though like Manu, I don’t
think that means that Matt should take the corresponding blog post down: I’m a digital preservationist, as might be evidenced by the unrepresentative-of-me and frankly embarrassing
things in the 25-year archives of this blog!
3 Fortunately the documents that the lawyers for both sides have been writing are much
clearer and more-specific, but that’s what you pay lawyers for, right?
4 There’s a huge amount of debate about the difference between morality and ethics, but
I’m using the definition that means that morality is based on what a social animal might be expected to decide for themselves is right, think e.g. the Golden Rule etc., whereas ethics is the code of conduct expected within a particular community. Take stealing, for example,
which covers the spectrum: that you shouldn’t deprive somebody else of something they need, is a moral issue; that we as a society deem such behaviour worthy of exclusion is an
ethical one; meanwhile the action of incarcerating burglars is part of our legal framework.
5 Not that nobody’s immune to making ethical mistakes. Not me, not you, not anybody else.
I remember when, back in 2005, Matt fucked up by injecting ads into WordPress (which at that point didn’t have a reliable source of
funding). But he did the right thing by backpedalling, undoing the harm, and apologising publicly and profusely.
6 WP Engine claim that they disable revisions for performance reasons, but that’s clearly
bullshit: it’s pretty obvious to me that this is about making hosting cheaper. Enabling revisions doesn’t have a performance impact on a properly-configured multisite hosting system,
and I know this from personal experience of running such things. But it does have a significant impact on how much space you need to allocate to your users, which has cost
implications at scale.
7 As an aside: if a court does rule that WP Engine is infringing upon
WordPress trademarks and they want a new company name to give their service a fresh start, they’re welcome to TurdPress.
8 I’d argue that it is okay to do so for personal-use though: the difference for
me comes when you’re making a profit off of it. It’s interesting to find these edge-cases in my own thinking!
9 A typical Reddit thread is about 25% lies-and-bullshit; but you can double that for a
typical thread talking about this topic!
Sometimes I’ve seen signs on dual carriageways and motorways that seem to specify a speed limit that’s the same as the national speed
limit (i.e. 60 or 70 mph for most vehicles, depending on the type of road), which seem a bit… pointless? Today I learned why they’re there, and figured I’d share with you!
The first time I saw this sign, on the A1 near Edinburgh, I wondered why it wasn’t just a national speed limit/derestriction sign. Now I know.
To get there, we need a history lesson.
As early as the 1930s, it was becoming clear that Britain might one day need a network of high-speed, motor-vehicle-only roads: motorways. The first experimental part of this
network would be the Preston By-pass1.
Construction halted on several occasions owing to heavy rain, and only six weeks after opening the road needed to be closed for resurfacing after the discovery that water had
penetrated the material.
Construction wouldn’t actually begin until the 1950s, and it wasn’t just the Second World War that got in the way: there was a legislative challenge too.
When the Preston By-pass was first conceived, there was no legal recognition for roads that restricted the types of traffic that were permitted to drive on them. If a public highway
were built, it would have to allow pedestrians, cyclists, and equestrians, which would doubtless undermine the point of the exercise! Before it could be built, the government needed to
pass the Special Roads Act 1949, which enabled the designation of public roads as “special roads”, to which
entry could be limited to certain classes of vehicles2.
The original motorways had to spell out the regulations at their junctions.
If you don’t check your sources carefully when you research the history of special roads, you might be taken in by articles that state that special roads are “now known as motorways”,
which isn’t quite true. All motorways are special roads, by definition, but not all special roads are motorways.
There’s maybe a dozen or more non-motorway special roads, based on research by Pathetic Motorways (whose site was
amazingly informative on this entire subject). They tend to be used in places where something is like a motorway, but can’t quite be a motorway. In Manchester, a
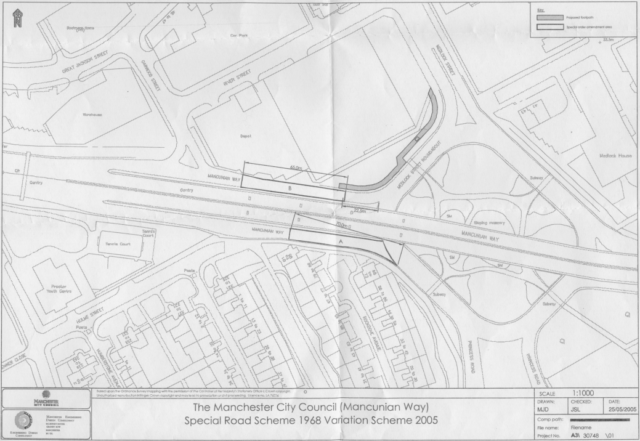
couple of the A57(M)’s sliproads have pedestrian crossings and so have to be designated special roads rather than motorways, for example3.
“…is hereby varied by adding Class IX of the Classes of Traffic set out in Schedule 4 to the Highways Act 1980 as a class of traffic permitted to use those lengths of the special
roads described in the Schedule to this Scheme and which…” /snoring sounds intensify/
Now we know what special roads are, that we might find them all over the place, and that they can superficially look like motorways, let’s talk about speed limits.
The Road Traffic Act 1934 introduced the concept of a 30mph “national speed limit” in built-up areas,
which is still in force today. But outside of urban areas there was no speed limit. Perhaps there didn’t need to be, while cars were still relatively slow, but automobiles
became increasingly powerful. The fastest speed ever legally achieved on a British motorway came in 1964 during a test by AC Cars, when driver Jack Sears reached 185mph.
The “M48” Severn Bridge is another example of a special road that appears to be part of a motorway. The cycle lane and footpath (which is not separated from the main carriageway by
more than a fence) is the giveaway that it’s not truly a “motorway” but a general-case special road.
In the late 1960s an experiment was run in setting a speed limit on motorways of 70mph. Then the experiment was extended. Then the regulation was made permanent.
There’ve been changes since then, e.g. to prohibit HGVs from going faster than 60mph, but fundamentally this is where Britain’s
national speed limit on motorways comes from.
I assume that it relates to the devolution of transport policy or to the separation of legislation that it replaces, but separate-but-fundamentally-identical acts were passed for
Scotland and Northern Ireland.
You’ve probably spotted the quirk already. When “special roads” were created, they didn’t have a speed limit. Some “special roads” were categorised as “motorways”, and “motorways” later
had a speed limit imposed. But there are still a few non-motorway “special roads”!
Putting a national speed limit sign on a special road would be meaningless, because these roads have no centrally-legislated speed limit. So they need a speed limit sign, even
if that sign, confusingly, might specify a speed limit that matches what you’d have expected on such a road4.
That’s the (usual) reason why you sometimes see these surprising signs.
As to why this kind of road are much more-common in Scotland and Wales than they are anywhere else in the UK: that’s a much deeper-dive
that I’ll leave as an exercise for the reader.
Footnotes
1 The Preston By-pass lives on, broadly speaking, as the M6 junctions 29 through 32.
2 There’s little to stop a local authority using the powers of the Special Roads Act and
its successors to declare a special road accessible to some strange and exotic permutation of vehicle classes if they really wanted: e.g. a road could be designated for cyclists and
horses but forbidden to motor vehicles and pedestrians, for example! (I’m moderately confident this has never happened.)
4 An interesting side-effect of these roads might be that speed restrictions based on the
class of your vehicle and the type of road, e.g. 60mph for lorries on motorways, might not be enforceable on special roads. If you wanna try driving your lorry at
70mph on a motorway-like special road with “70” signs, though, you should do your own research first; don’t rely on some idiot from the Internet. I Am Not A Lawyer etc. etc.
From 1696 until 1851 a “window tax” was imposed in England and Wales1.
Sort-of a precursor to property taxes like council tax today, it used an estimate of the value of a property as an indicator of the wealth of its occupants: counting the number of
windows provided the mechanism for assessment.
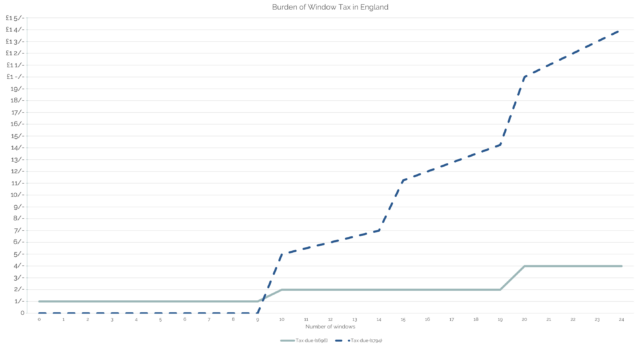
The hardest thing about retrospectively graphing the cost of window tax is thinking in “old money”2.
Window tax replaced an earlier hearth tax, following the ascension to the English throne of Mary II and William III of Orange. Hearth tax had come from a similar philosophy: that
you can approximate the wealth of a household by some aspect of their home, in this case the number of stoves and fireplaces they had.
(A particular problem with window tax as enacted is that its “stepping”, which was designed to weigh particularly heavily on the rich with their large houses, was that it similarly
weighed heavily on large multi-tenant buildings, whose landlord would pass on those disproportionate costs to their tenants!)
It’d be temping to blame William and Mary for the window tax, but the reality is more-complex and reflects late renaissance British attitudes to the limits of state authority.
Why a window tax? There’s two ways to answer that:
A window tax – and a hearth tax, for that matter – can be assessed without the necessity of the taxpayer to disclose their income. Income tax, nowadays the most-significant form of
taxation in the UK, was long considered to be too much of an invasion upon personal privacy3.
But compared to a hearth tax, it can be validated from outside the property. Counting people in a property in an era before solid recordkeeping is hard. Counting hearths is
easier… so long as you can get inside the property. Counting windows is easier still and can be done completely from the outside!
If you’re in Britain, finding older buildings with windows bricked-up to save on tax is pretty easy. I took a break from writing this post, walked for three minutes, and found
one.4
There were a few work-related/adjacent activities. But also a table football tournament, among other bits of fun.
One of the things I learned while on this trip was that the Netherlands, too, had a window tax for a time. But there’s an interesting difference.
The Dutch window tax was introduced during the French occupation, under Napoleon, in 1810 – already much later than its equivalent in England – and continued even after he was ousted
and well into the late 19th century. And that leads to a really interesting social side-effect.
My brief interest in 19th century Dutch tax policy was piqued during my team’s boat tour.
Glass manufacturing technique evolved rapidly during the 19th century. At the start of the century, when England’s window tax law was in full swing, glass panes were typically made
using the crown glass process: a bauble of glass would be
spun until centrifugal force stretched it out into a wide disk, getting thinner towards its edge.
The very edge pieces of crown glass were cut into triangles for use in leaded glass, with any useless offcuts recycled; the next-innermost pieces were the thinnest and clearest, and
fetched the highest price for use as windows. By the time you reached the centre you had a thick, often-swirly piece of glass that couldn’t be sold for a high price: you still sometimes
find this kind among the leaded glass in particularly old pub windows5.
They’re getting rarer, but I’ve lived in houses with small original panes of crown glass like these!
As the 19th century wore on, cylinder glass became the norm. This is produced by making an iron cylinder as a mould, blowing glass into it, and then carefully un-rolling the cylinder
while the glass is still viscous to form a reasonably-even and flat sheet. Compared to spun glass, this approach makes it possible to make larger window panes. Also: it scales
more-easily to industrialisation, reducing the cost of glass.
The Dutch window tax survived into the era of large plate glass, and this lead to an interesting phenomenon: rather than have lots of windows, which would be expensive,
late-19th century buildings were constructed with windows that were as large as possible to maximise the ratio of the amount of light they let in to the amount of tax for which
they were liable6.
Look at the size of those windows! If you’re limited in how many you can have, but you’ve got the technology, you’re going to make them as large as you possibly can!
That’s an architectural trend you can still see in Amsterdam (and elsewhere in Holland) today. Even where buildings are renovated or newly-constructed, they tend – or are required by
preservation orders – to mirror the buildings they neighbour, which influences architectural decisions.
Notice how each building has only between one and three windows on the ground floor, letting as much light in while minimising the tax burden.
It’s really interesting to see the different architectural choices produced in two different cities as a side-effect of fundamentally the same economic choice, resulting from slightly
different starting conditions in each (a half-century gap and a land shortage in one). While Britain got fewer windows, the Netherlands got bigger windows, and you can still see the
effects today.
…and social status
But there’s another interesting this about this relatively-recent window tax, and that’s about how people broadcast their social status.
This Google Street Canal (?) View photo shows a house on Keizersgracht, one of the richest parts of Amsterdam. Note the superfluous decorative window above the front door
and the basement-level windows for the servants’ quarters.
In some of the traditionally-wealthiest parts of Amsterdam, you’ll find houses with more windows than you’d expect. In the photo above, notice:
How the window density of the central white building is about twice that of the similar-width building on the left,
That a mostly-decorative window has been installed above the front door, adorned with a decorative
leaded glass pattern, and
At the bottom of the building, below the front door (up the stairs), that a full set of windows has been provided even for the below-ground servants quarters!
When it was first constructed, this building may have been considered especially ostentatious. Its original owners deliberately requested that it be built in a way that would attract a
higher tax bill than would generally have been considered necessary in the city, at the time. The house stood out as a status symbol, like shiny jewellery, fashionable clothes,
or a classy car might today.
I originally wanted to insert a picture here that represented how one might show status through fashion today. But then I remembered I don’t know anything about fashion7. But somehow my stock image search suggested this photo, and I
love it so much I’m using it anyway. You’re welcome.
How did we go wrong? A century and a bit ago the super-wealthy used to demonstrate their status by showing off how much tax they can pay. Nowadays, they generally seem
more-preoccupied with getting away with paying as little as possible, or none8.
Can we bring back 19th-century Dutch social status telegraphing, please?9
Footnotes
1 Following the Treaty of Union the window tax was also applied in Scotland, but
Scotland’s a whole other legal beast that I’m going to quietly ignore for now because it doesn’t really have any bearing on this story.
2 The second-hardest thing about retrospectively graphing the cost of window tax is
finding a reliable source for the rates. I used an archived copy of a guru site about Wolverhampton history.
3 Even relatively-recently, the argument that income tax might be repealed as incompatible
with British values shows up in political debate. Towards the end of the 19th century, Prime Ministers Disraeli and Gladstone could be relied upon to agree with one another on almost
nothing, but both men spoke at length about their desire to abolish income tax, even setting out plans to phase it out… before having to cancel those plans when some
financial emergency showed up. Turns out it’s hard to get rid of.
4 There are, of course, other potential reasons for bricked-up windows – even aesthetic ones – but a bit of a giveaway is if the
bricking-up reduces the number of original windows to 6, 9, 14 or 19, which are thesholds at which the savings gained by bricking-up are the greatest.
5 You’ve probably heard about how glass remains partially-liquid forever and how this
explains why old windows are often thicker at the bottom. You’ve probably also already had it explained to you that this is complete bullshit. I only mention it here to preempt any discussion in the comments.
6 This is even more-pronounced in cities like Amsterdam where a width/frontage tax forced
buildings to be as tall and narrow and as close to their neighbours as possible, further limiting opportunities for access to natural light.
7 Yet I’m willing to learn a surprising amount about Dutch tax law of the 19th century. Go
figure.























{kind=link}